







海云捷迅杯:基于FPGA C5Soc的MobileNetV1 SSD目标检测方案设计
本作品参与极术社区组织的有奖征集|秀出你的集创赛作品风采,免费电子产品等你拿~活动。
**杯赛题目:**海云捷迅杯——基于FPGA C5Soc的MobileNetV1 SSD目标检测方案设计
设计任务:
- 基于已训练好的SSD模型参数文件、基于已有的Intel FPGA工程网表文件、Linux-C5soc平台的Paddle-Paddle框架驱动为参考,优化或者重新设计加速器以及对应驱动,并部署SSD模型到FPGA进行推理。
- 对方案进行评估和实现。
- 提出设计方案,提升性能并实现。
团队介绍
**参赛单位:**南京大学
**队伍名称:**爱卡丝俱乐部
**指导老师:**王中风
**参赛队员:**薛睿鑫、程昕、苏天祺
**总决赛奖项:**一等奖和企业大奖
项目介绍
本项目采用Intel Cyclone V系列的SoC芯片进行开发,部署以MobileNet V1为backbone的SSD目标检测模型,对硬软件进行协同优化,以提高目标检测效率。整个系统包括PS (processing system) 端和PL (programmable logic) 端两部分,PS端包括ARM处理器、Memory,负责数据传输及计算流程的预处理和控制;PL端则包括卷积和偏置激活计算单元、SRAM等,负责对高负载的运算进行加速。PL端的数据通过Avalon总线与DRAM进行交互。
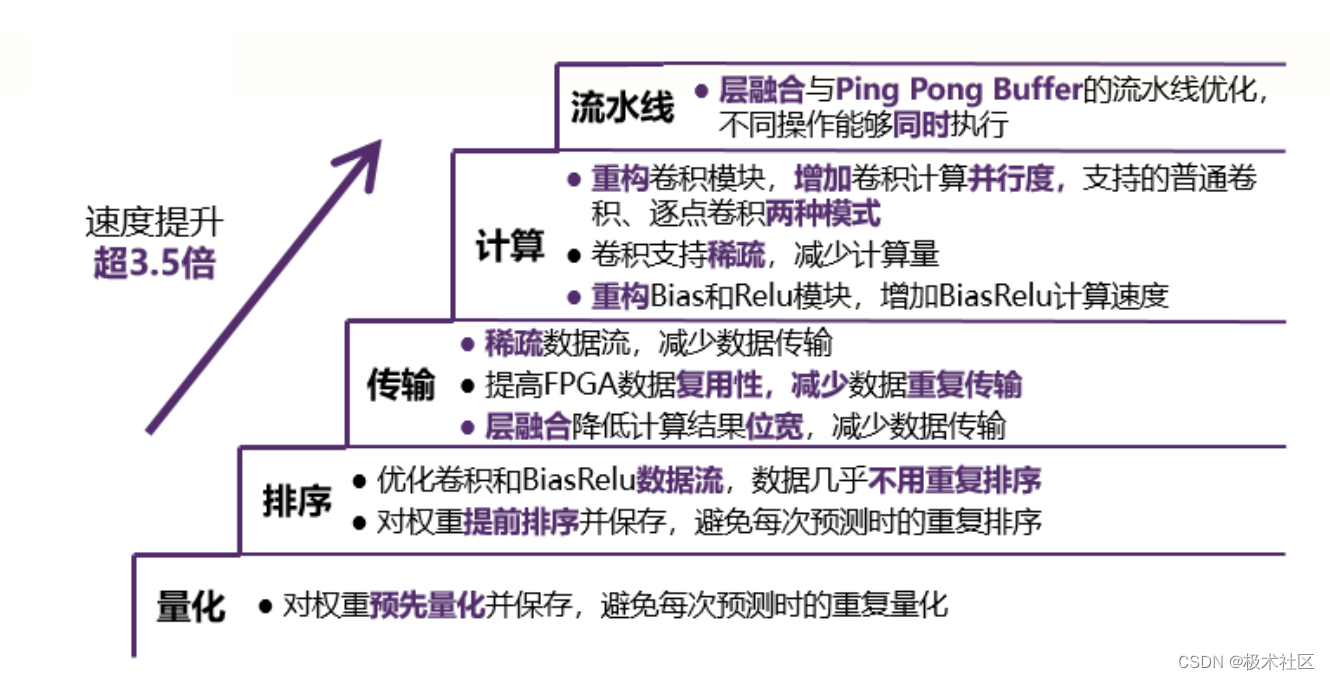
我们在量化、排序、传输、计算、流水线这五个方面对系统进行了优化,具体的优化手段如下图所示。通过上述优化,目标检测的速度提升超过3.5倍。
我们的技术创新点体现在以下几个方面:
- 重新设计了稀疏卷积的数据流,采用Row-wise、Weight stationary的滑窗卷积方式,将计算并行度提高到96,并支持channel-wise的input数据稀疏,提高了FPGA上数据的复用性,大大减少数据的传输量,从而减少数据的传输时间、降低功耗。
- 采用层融合方式处理每层的偏置和激活操作,在FPGA上的卷积计算完成后,将结果直接传到偏置激活计算单元进行计算,再将偏置激活的计算结果经过SRAM传到片外。这样一方面能够加速偏置激活的计算,另一方面,经过偏置激活的计算后,数据能够支持量化为更低比特而不损失精度,从而进一步减少数据的传输。
- 增加input、weight、bias和output四个 Ping Pong Buffer,使数据传输与计算时间能够重叠,这样进一步优化了数据计算的流水线,在同一时间内进行数据传输和计算,从而实现对系统的加速。
- 在进行模型预测之前将量化并重排的权重和偏置保存,避免每次预测时对权重和偏置数据的重复量化和重排。
系统架构
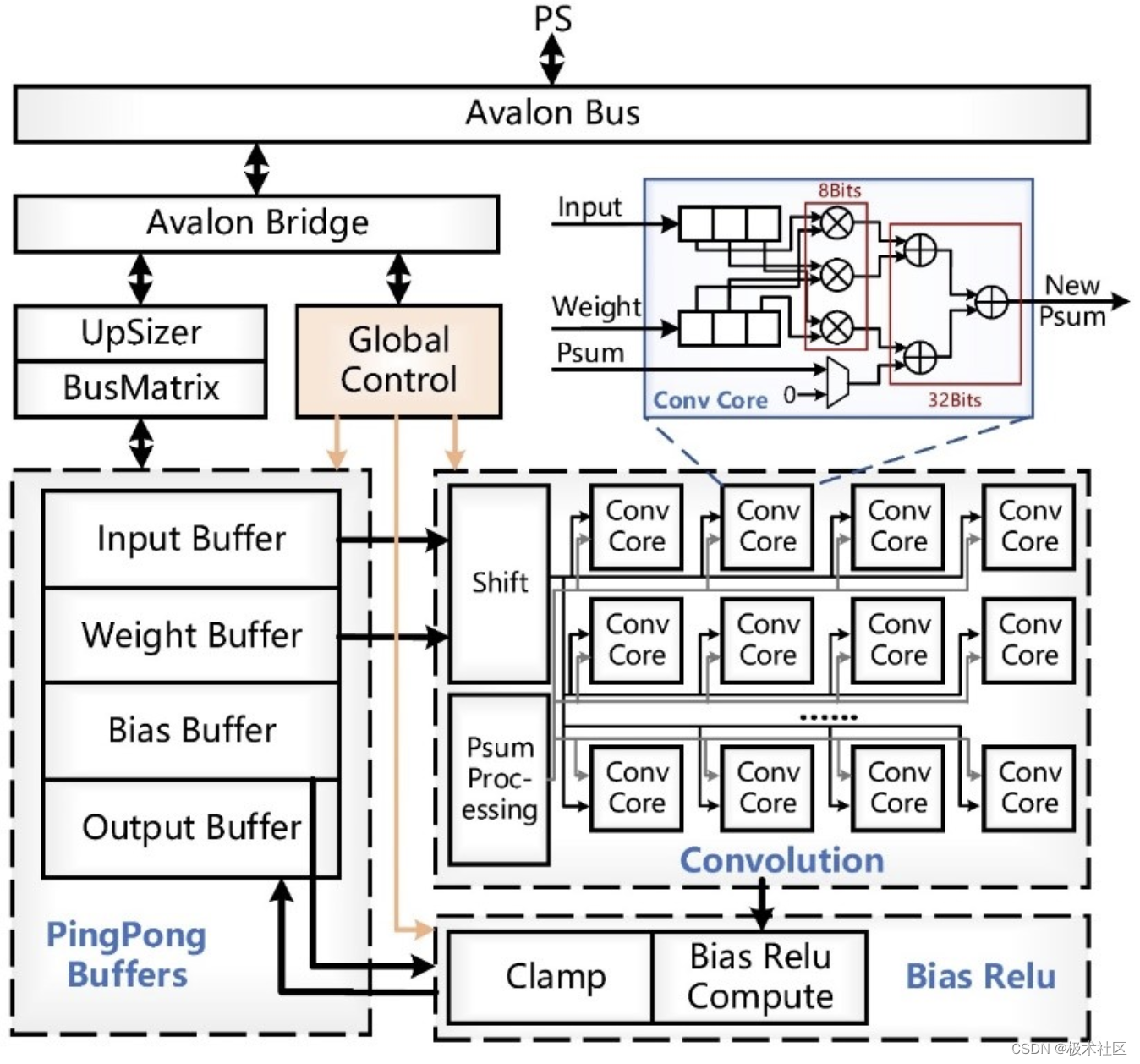
为实现快速的目标检测效果,我们设计的系统整体架构图如下图所示。数据经UpSizer和BusMatrix单元进行仲裁,存储到相应的SRAM中。当计算开始时,卷积模块可以直接从SRAM中读取数据,卷积的结果直接传入BiasRelu单元进行计算,再写入Output Ping Pong Buffer,最终的output再经过BusMatrix和UpSizer单元传回DRAM。
优化效果
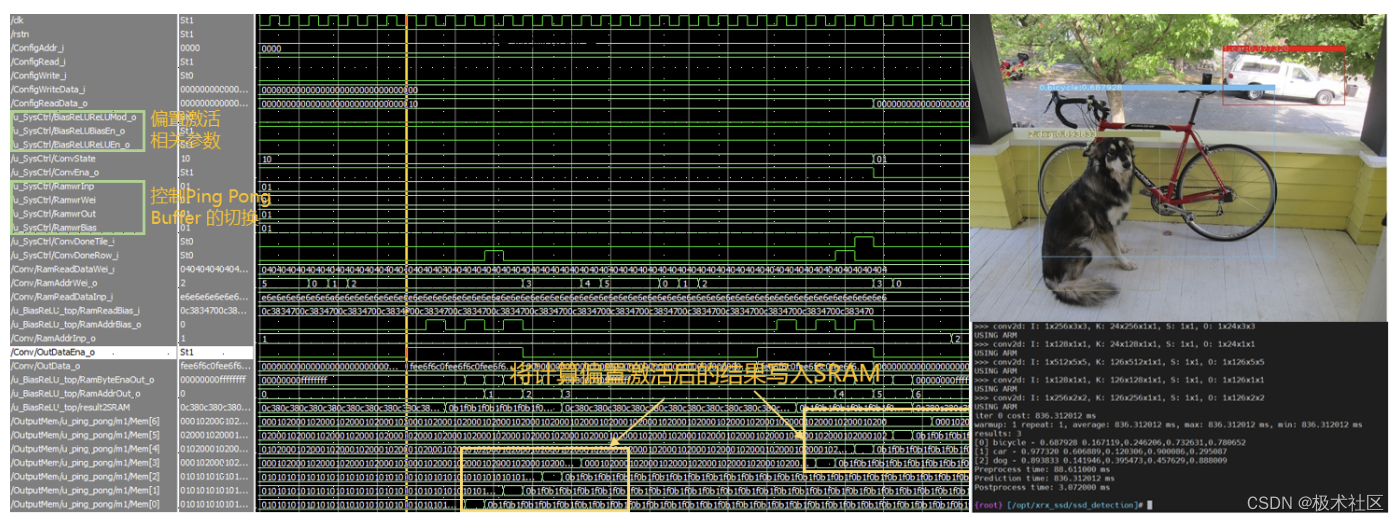
经过充分的仿真验证和上板调试,系统能够正确完成目标检测任务,最终的目标识别速度能够达到最快每张图836ms!
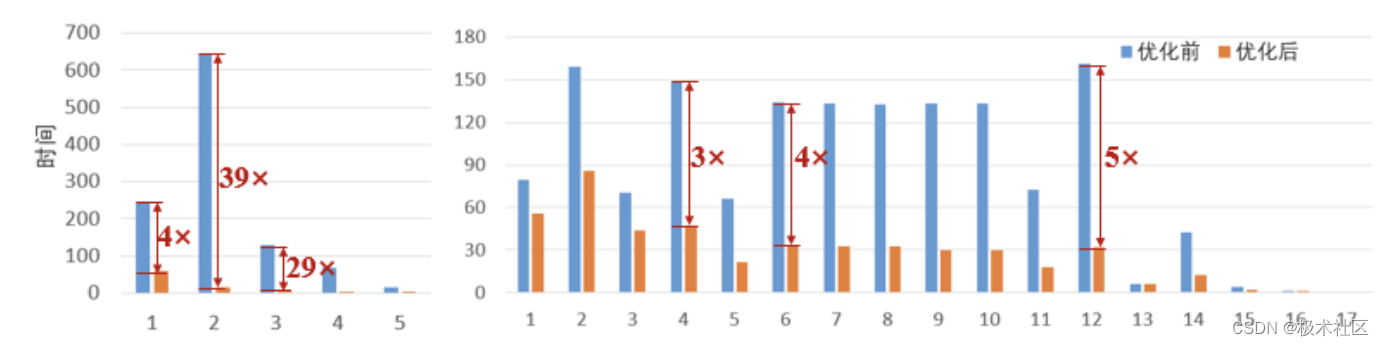
我们统计了优化前后卷积层的加速比,结果如下图所示,相比原始优化前的系统,我们的加速系统能够实现最高39倍加速比,平均4.5倍加速比。
参赛体会
这次比赛,给了我们一个很好的机会,提升硬软件协同开发的能力。从硬件数据流的设计到代码的调试,我们一步一个脚印,提出了很多优化的方案,并评估它们的可行性,最终实现了上面所述的加速系统。团队的成员也能够优势互补,在讨论中碰撞出了很多火花。非常感谢实验室的学长学姐和赛事指导老师曾给予我们的帮助,在我们遇到难题时帮助我们指明解决问题的方向。

未来展望
- 针对深度卷积进行层融合优化。将深度卷积与前一层的卷积融合,减少中间数据的传输。
- 利用DMA进行片上与片下数据的传输,提高传输效率。
- 探索更加有效的量化方式,能够进一步减少数据的传输量的同时保持精度。
总结
我们在官方提供的系统基础上进行优化,成功在Intel Cyclon V SoC芯片上部署了以MobileNet v1为backbone网络的SSD目标检测模型,联合优化ARM端和FPGA端,实现了硬件加速效果。
我们有针对性地设计了稀疏卷积和偏置激活计算的数据流,提高FPGA上数据的复用性,减少数据传输;偏置激活的计算与卷积采用层融合的流水线进行优化,能够在加速偏置激活计算的同时,实现更低比特的数据量化,进一步减少数据的传输;Ping Pong Buffer优化的数据传输与计算流水线,使得数据的计算和传输能够在同一时间进行,减少了计算的空闲状态;此外,我们还优化了模型的量化操作,在进行模型预测之前将量化后的权重和偏置保存,避免每次量化时对权重和偏置数据的重复量化。以上工作共同作用,大大优化了系统的整体性能,提升计算速度。
最后的实验结果表明,我们的设计分别在模型中的普通卷积层和逐点卷积层上实现了最高39×和平均4.5×的加速比。在上板测试中,我们在保证结果正确的情况下,将单张图片的识别速度从3000ms提升到了836ms,取得了超过3.5倍的速度提升。
作品内容来源于爱卡丝俱乐部,转载请标明出处。欢迎大家参加极术社区组织的有奖征集|秀出你的集创赛作品风采,免费电子产品等你拿~活动,10月1日截止~















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









