






前言
DeepSeek是由中国团队开发的开源人工智能工具库,专注于提供高效的大语言模型训练与推理能力。其核心产品DeepSeek-R1系列模型凭借混合专家架构(MoE)和专业化的知识处理能力,在编程、数学推理等领域表现卓越。本文将以Windows系统为例,详细讲解通过Ollama安装量化版DeepSeek-R1模型,并借助Dify平台实现本地化知识库的部署。
一、安装 Docker
1.1 下载并安装Docker
访问Docker官网,下载适用于 Windows 的 Docker 桌面版安装程序,并按照提示完成安装。
官网:Docker: Accelerated Container Application Development
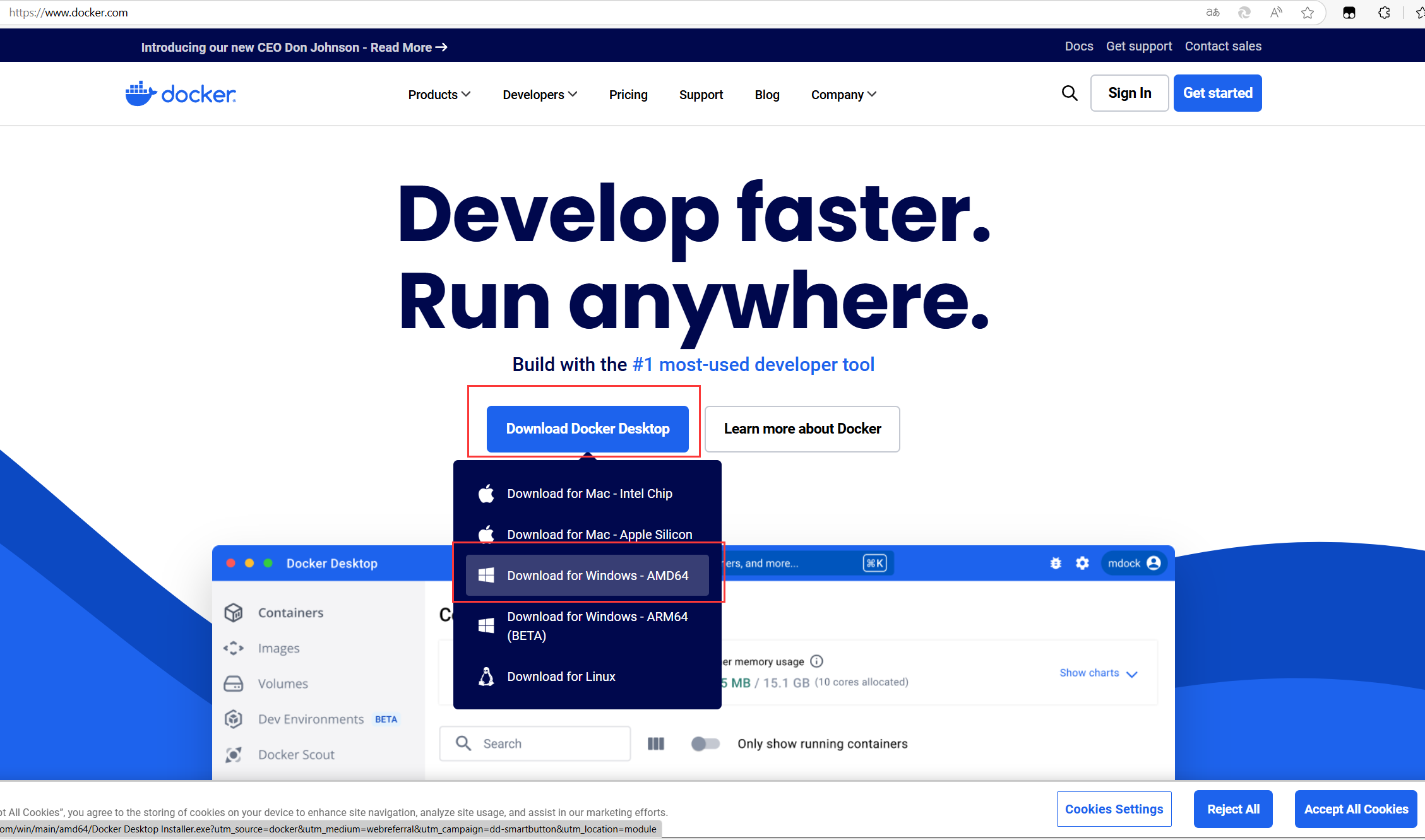
弹出对话框,点击OK。
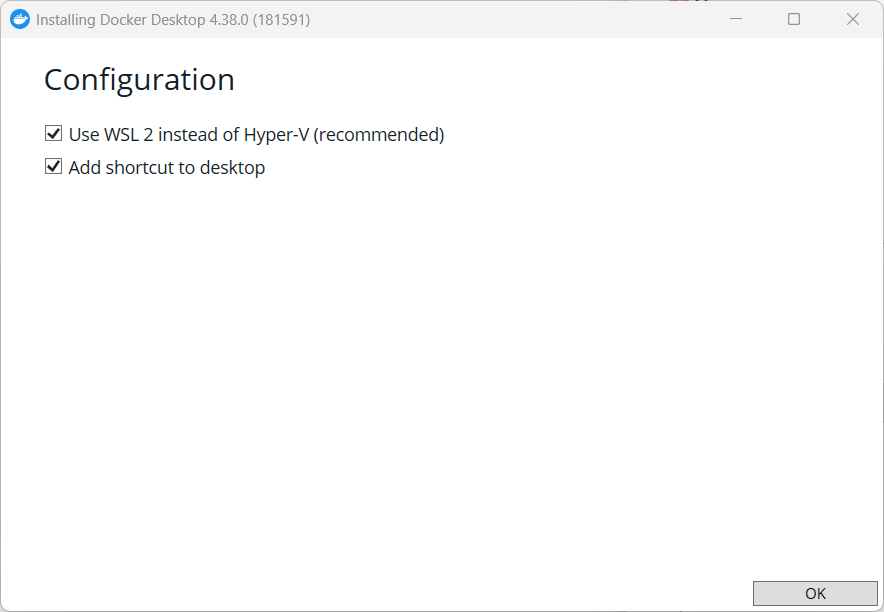
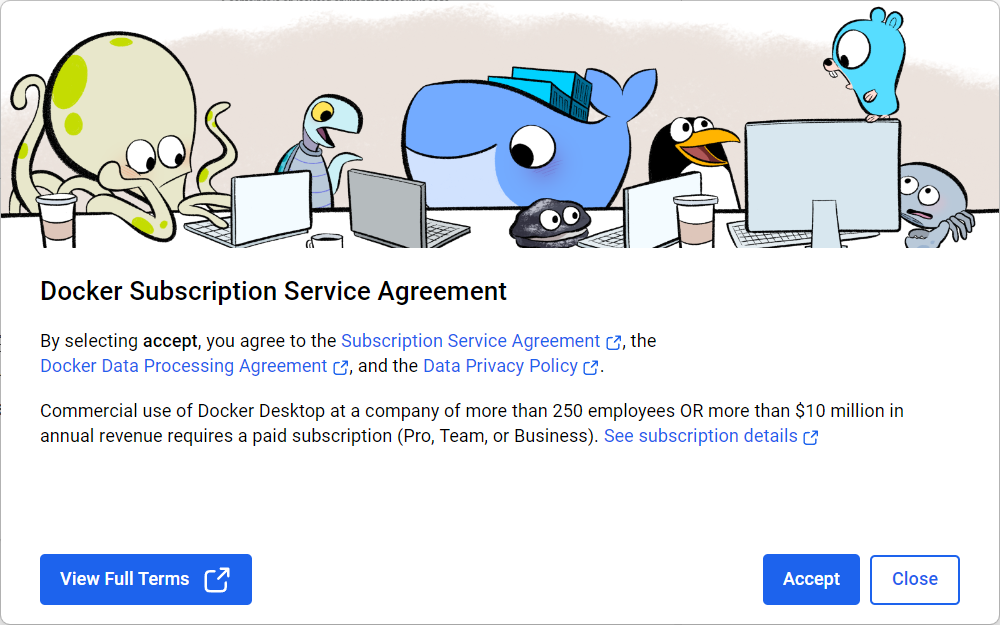
安装完成重启电脑。弹出对话框,点击accept。
1.2 解决Docker启动错误
回到docker软件界面,点击sign in,登录或创建docker账号。
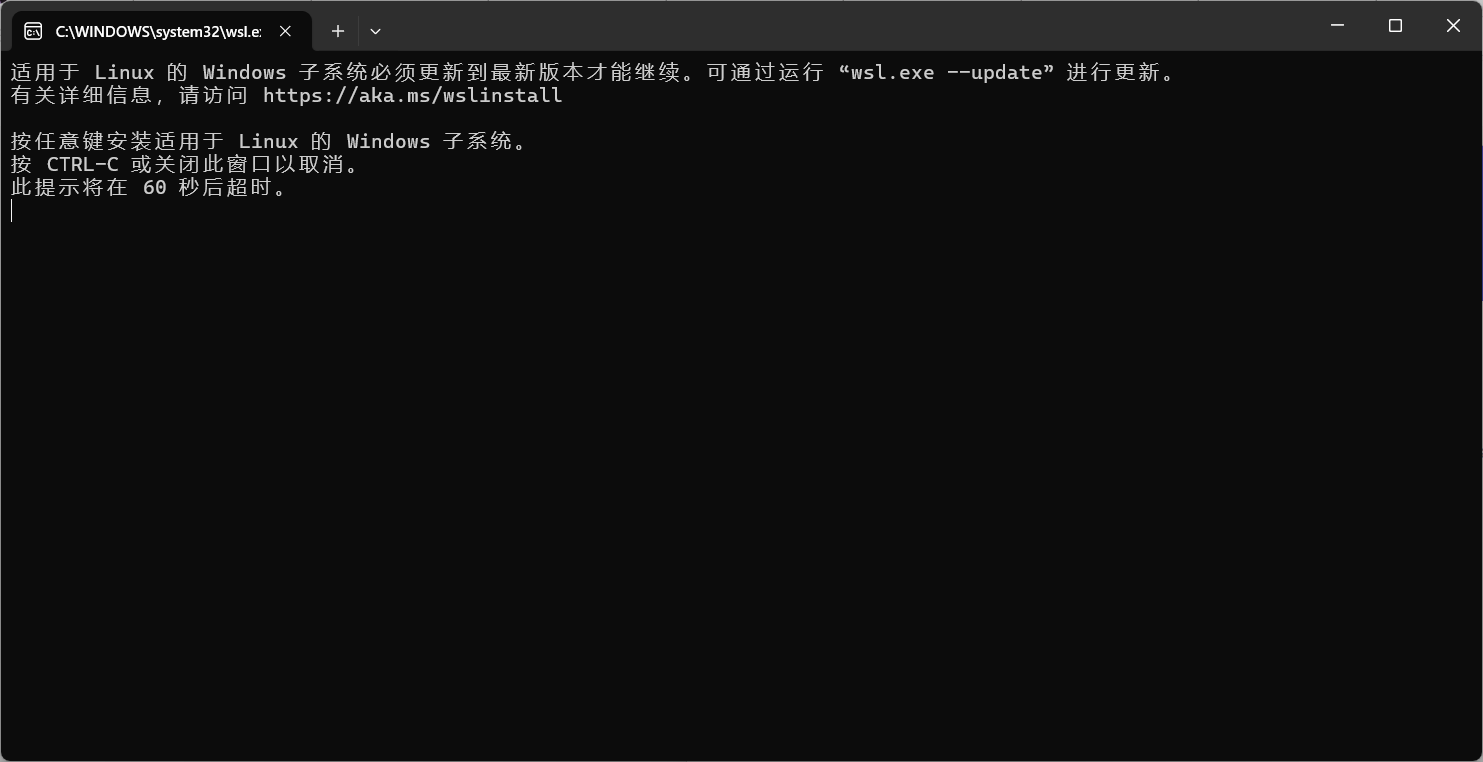
如果在启动Docker时遇到WSL错误,重启电脑后重新启动Docker。
报错:弹出对话框提示报错。WSL程序错误。
如问题依旧,参考WSL2.0安装指南-CSDN博客,确认每一步配置正确。
注:只需要参考一、安装wsl2.0即可,后面的教程不用看。下面是具体的操作过程。
① 启用适用于 Linux 的 Windows 子系统:打开powershell并输入:
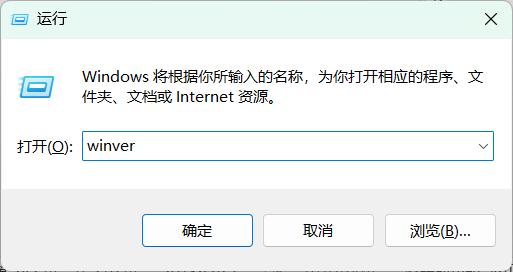
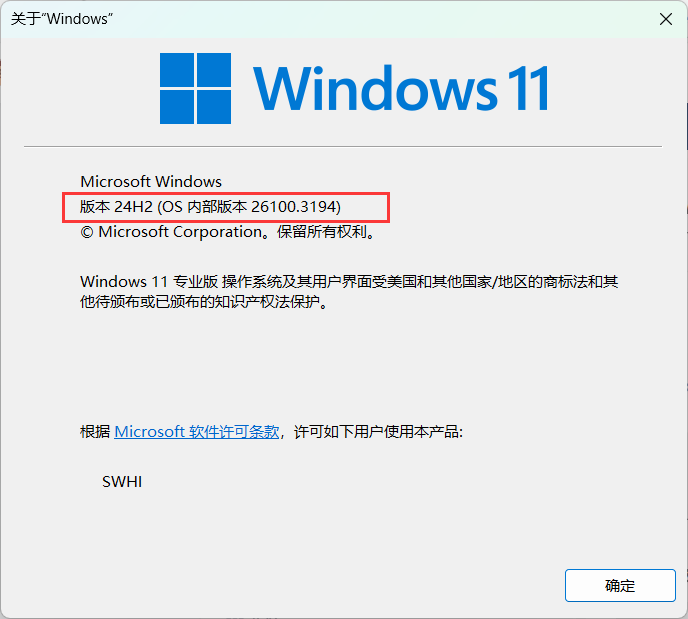
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart② 检查WSL2的要求:win+R打开运行,然后输入winver检查windows版本
③ 启用虚拟化:以管理员打开powershell输入下列命令
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart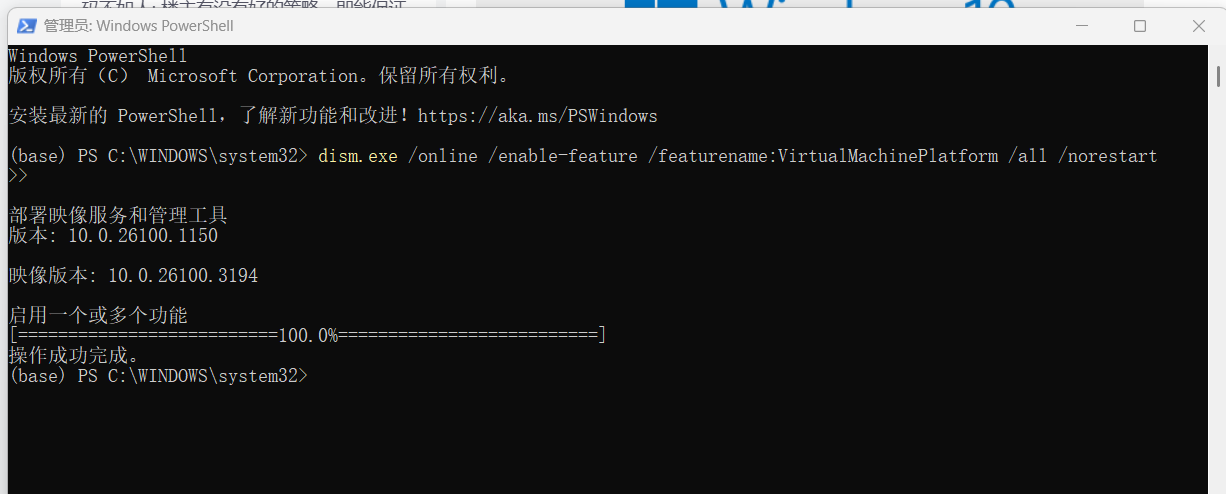
④ 下载X64的WSL2 Linux内核升级包并安装
⑤ 设置WSL默认版本
wsl --set-default-version 2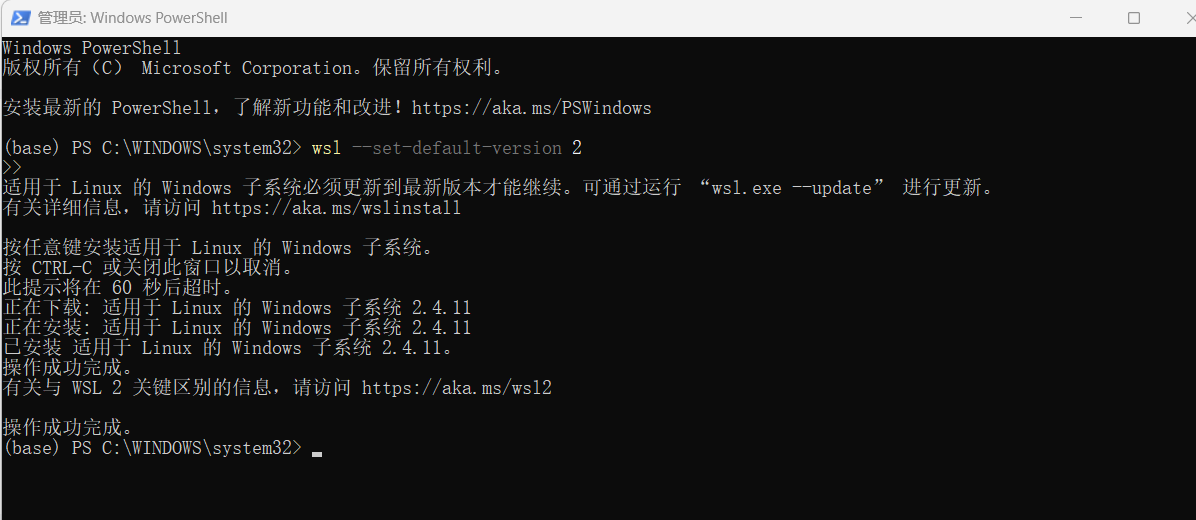
至此docker刚才报错的内容已经解决,重新打开docker软件。
docker安装成功。
二、安装ollama
Ollama 是一个开源的本地化工具,旨在简化大型语言模型(LLMs)的本地运行和部署。它专注于让用户能够轻松在个人计算机或服务器上运行多种开源语言大模型(如deepseek ,qwen,Llama、Mistral、Gemma等),而无需依赖云端服务或复杂的配置流程。
2.1 下载并安装 ollama
访问Ollama官网,下载适用于Windows的安装包并安装。
根据向导完成安装。
安装完成后,桌面会出现Ollama图标,确保服务已启动。
还会弹出窗口:
2.2 验证ollama安装
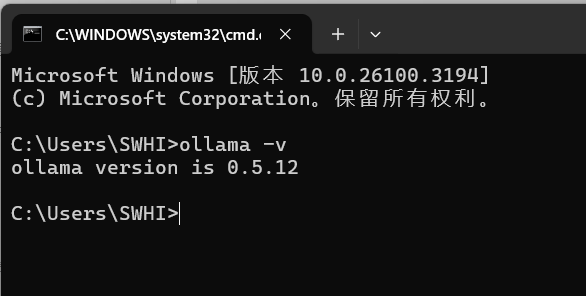
打开CMD,输入:
ollama -v若显示版本信息,说明安装成功。
ollama安装完后,没有图形界面,安装大模型,可以类比为docker拉取镜像,因为很多操作命令类似。
三、安装DeepSeek-R1模型
3.1 选择DeepSeek-R1 版本
根据个人电脑配置选择合适的模型版本。在Ollama界面选择模型并下载。
在ollama官网首页打开,点击deepseek-R1。
可以看到模型有根据参数分为1.5b,7b,8b,14b,32b,70b,671b等,我们需要根据自己电脑选择下载对应参数的模型。
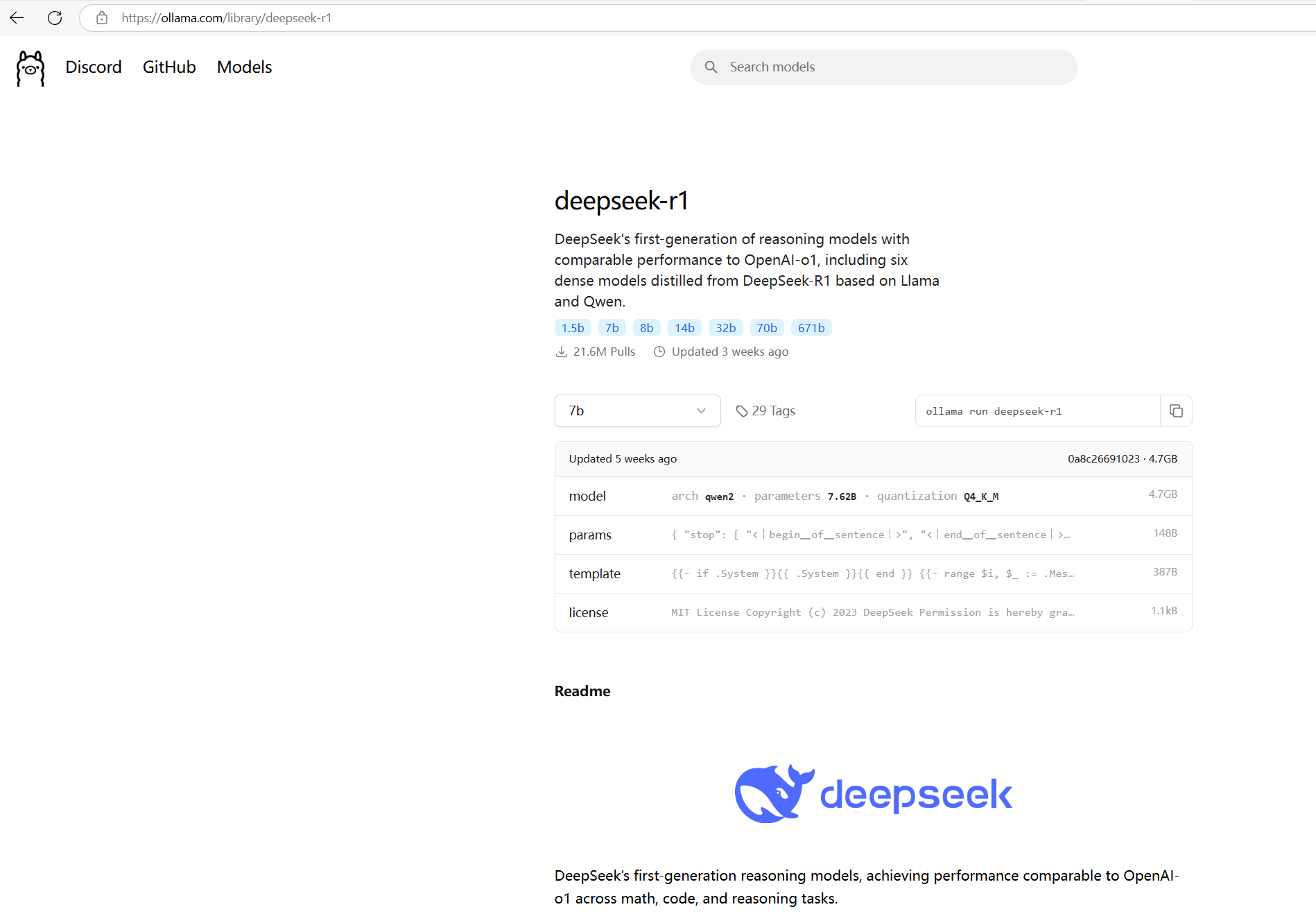
问一下deepseek,让他帮我们选择,提示词如下:
我现在正在使用ollama部署deepseek-r1模型,但是模型分为1.5b,7b,8b,14b,32b,70b,671b等,我不知道该怎么选择适合我电脑配置模型了,我现在把我电脑的配置信息告诉你,你帮我选择一下吧。
个人电脑信息如下:
系统:windows 11
运行内存:64G
专用GPU显存:8G
共享GPU内存:31.8G
deepseek 回答:



3.2 安装 deepseek-r1模型
安装deepseek-R1:8B 版本。
ollama run deepseek-r1:8b
文件有4.9G。
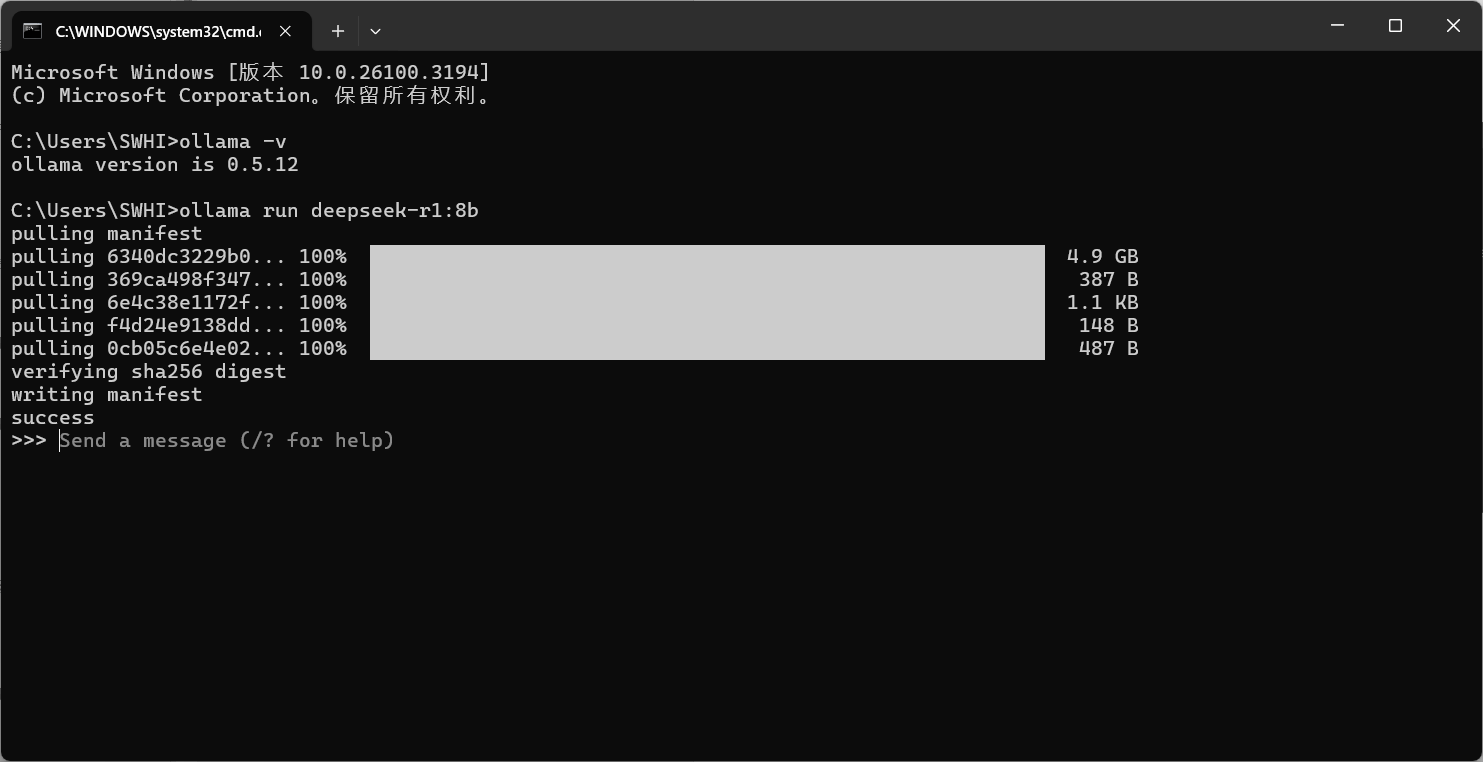
安装完成后,会自动运行大模型,我们输入一个问题测试一下:
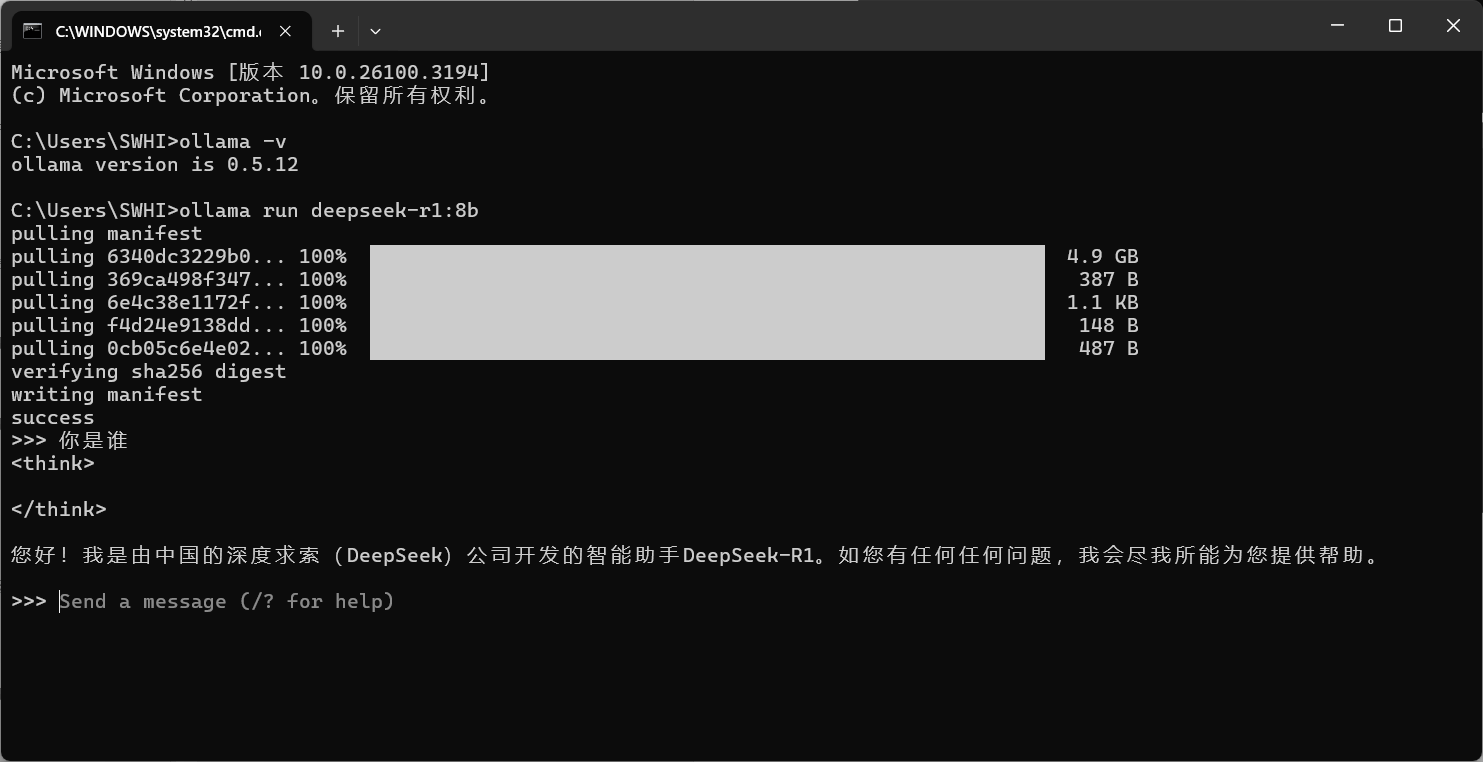
到这时 deepseek 已经成功部署到本地,接下来我们需要一个可视化界面,利用 dify 进行低代码的更多应用。
四、部署Dify平台
Dify.AI 是一个开源的大模型应用开发平台,旨在帮助开发者轻松构建和运营生成式 AI 原生应用。该平台提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等全方位的能力,使开发者能够专注于创造应用的核心价值,而无需在技术细节上耗费过多精力。
从创建应用页面可以看到,他可以创建:聊天助手,Agent,文生文应用,对话工作流,任务编排工作流等。
4.1 下载dify
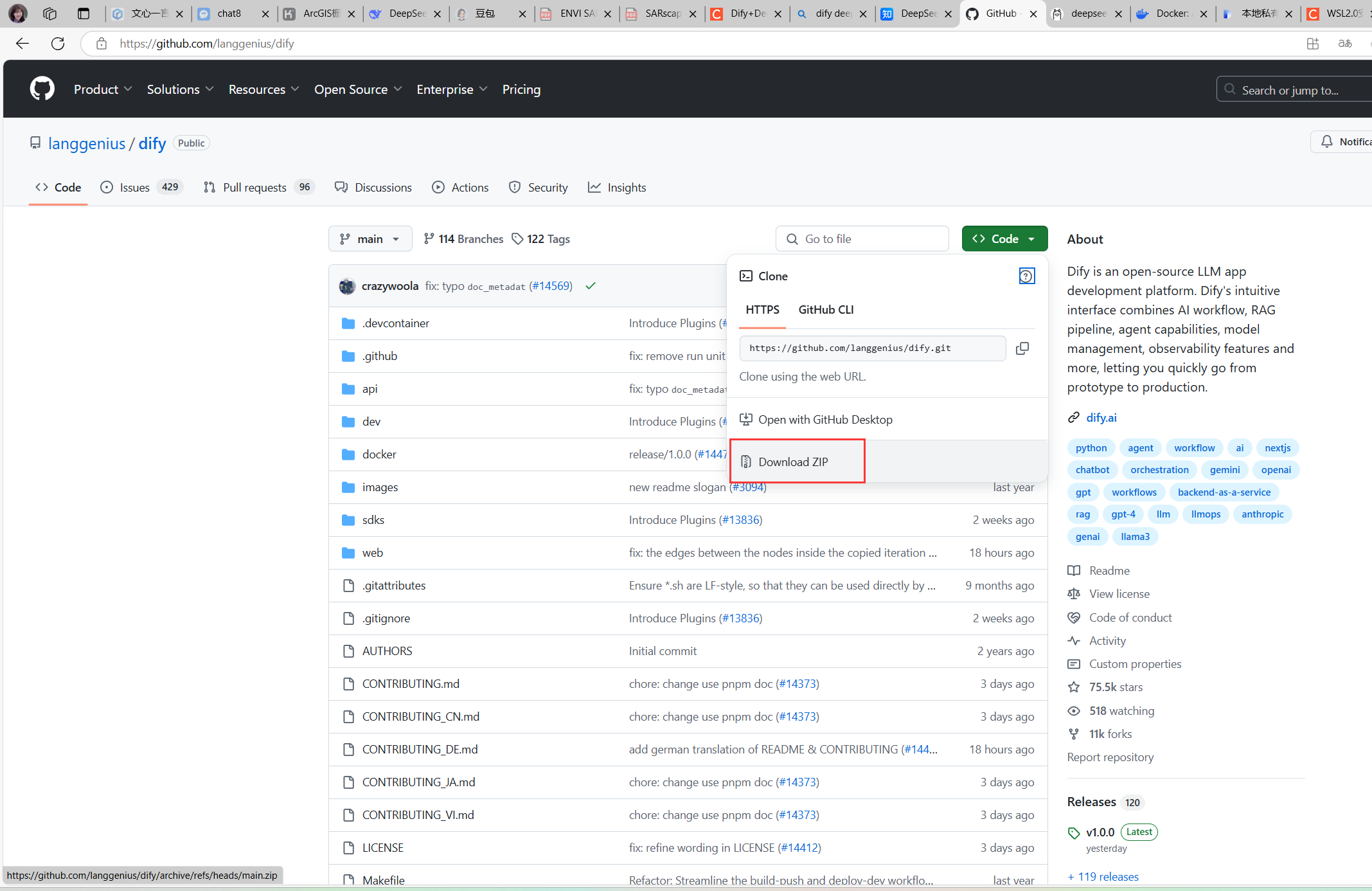
访问Dify的GitHub页面,下载最新版本的ZIP文件并解压。
4.2 配置dify运行环境
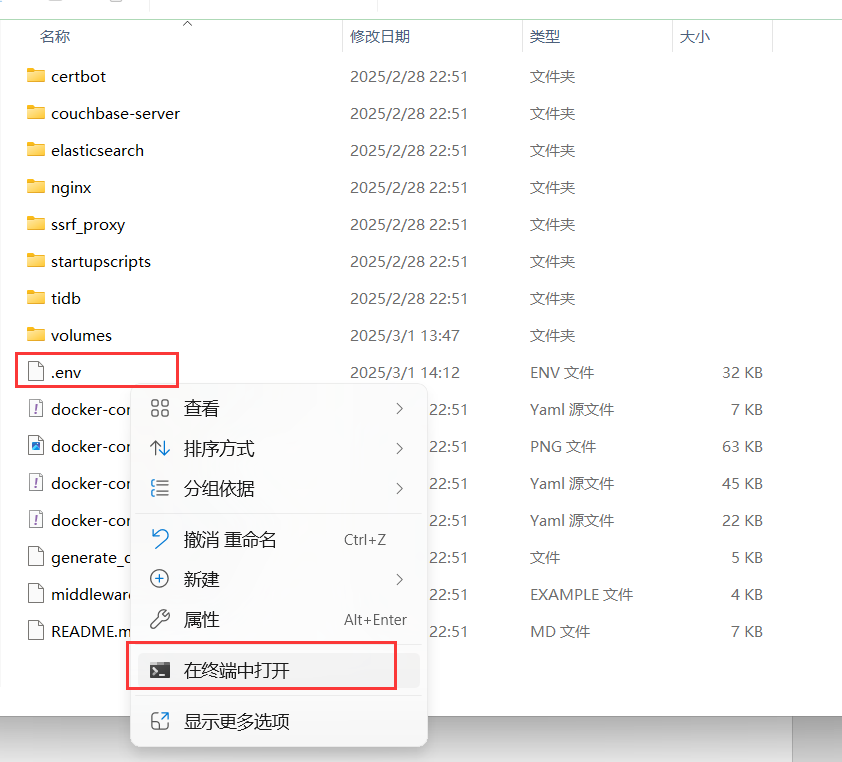
进入项目根目录下的docker文件夹,将.env.example重命名为.env,并根据需要调整配置,特别是端口设置以避免冲突。以我的文件为例,路径是 E:\dify-main\dify-main\docker\.env.example。
选中.env文件,右键在终端中打开。
4.3 启动Dify
在CMD中执行:
docker compose up -d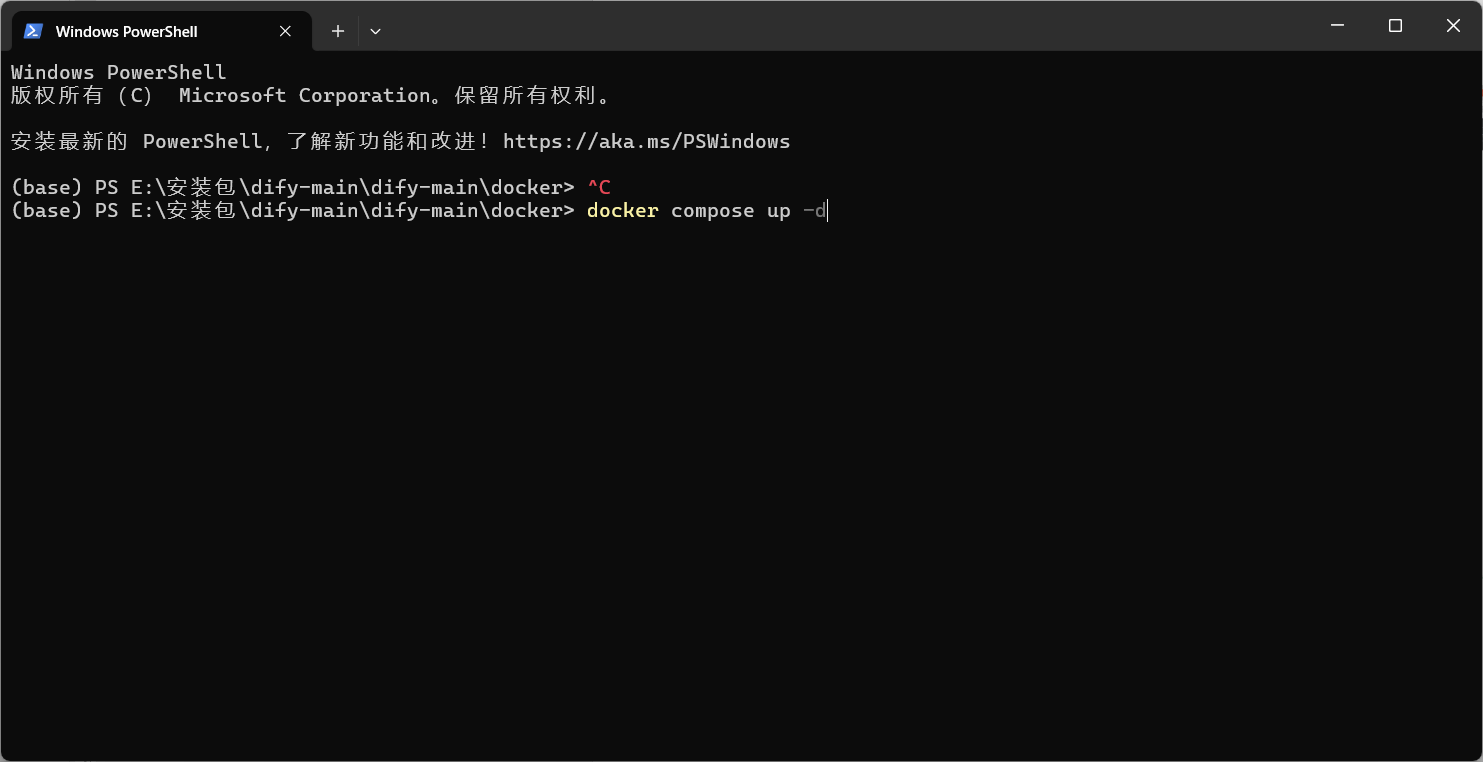
启动后,Docker会自动拉取并启动所需服务。
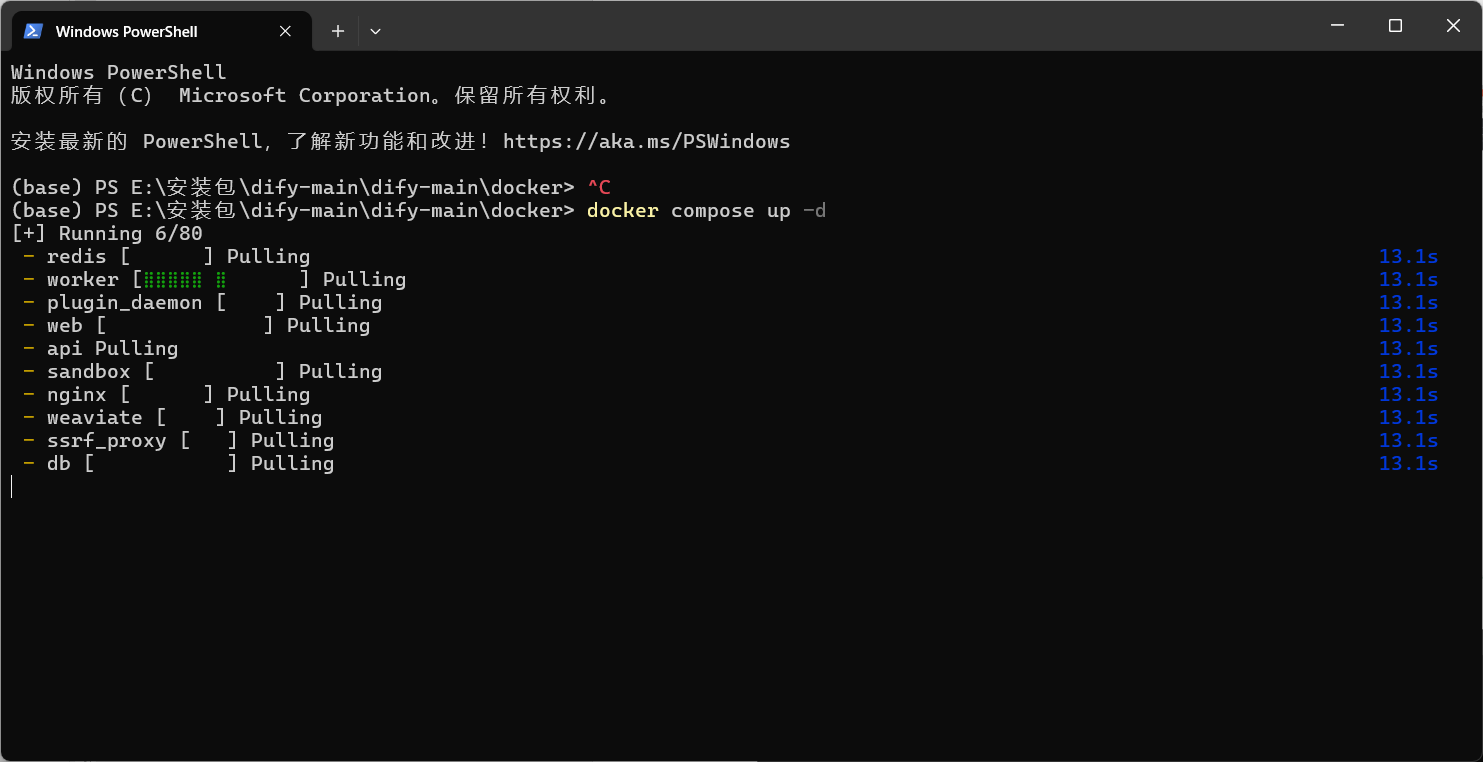
此时回到docker桌面客户端可看到,所有dify所需要的环境都已经运行起来了
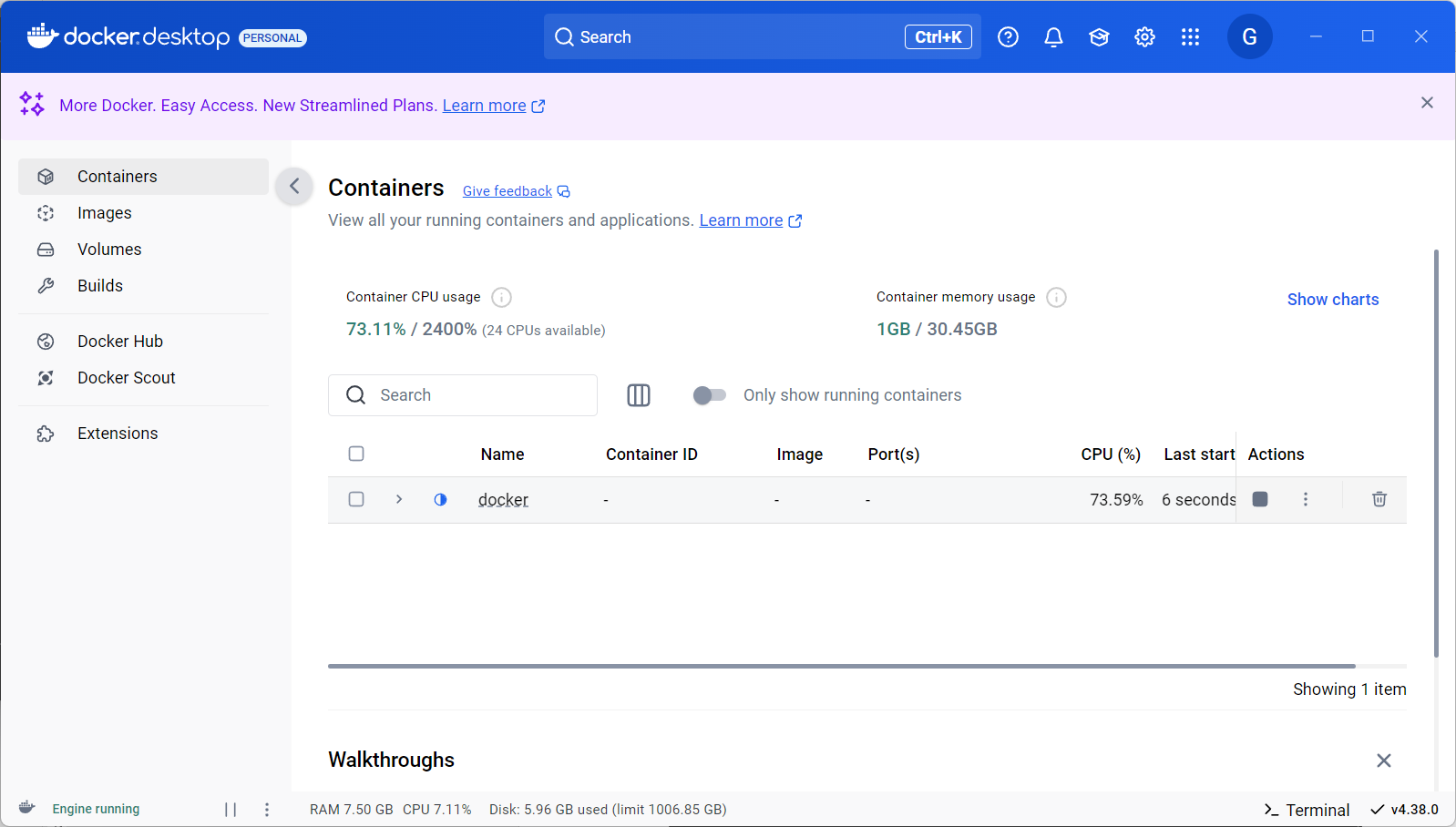
但是又报错了。
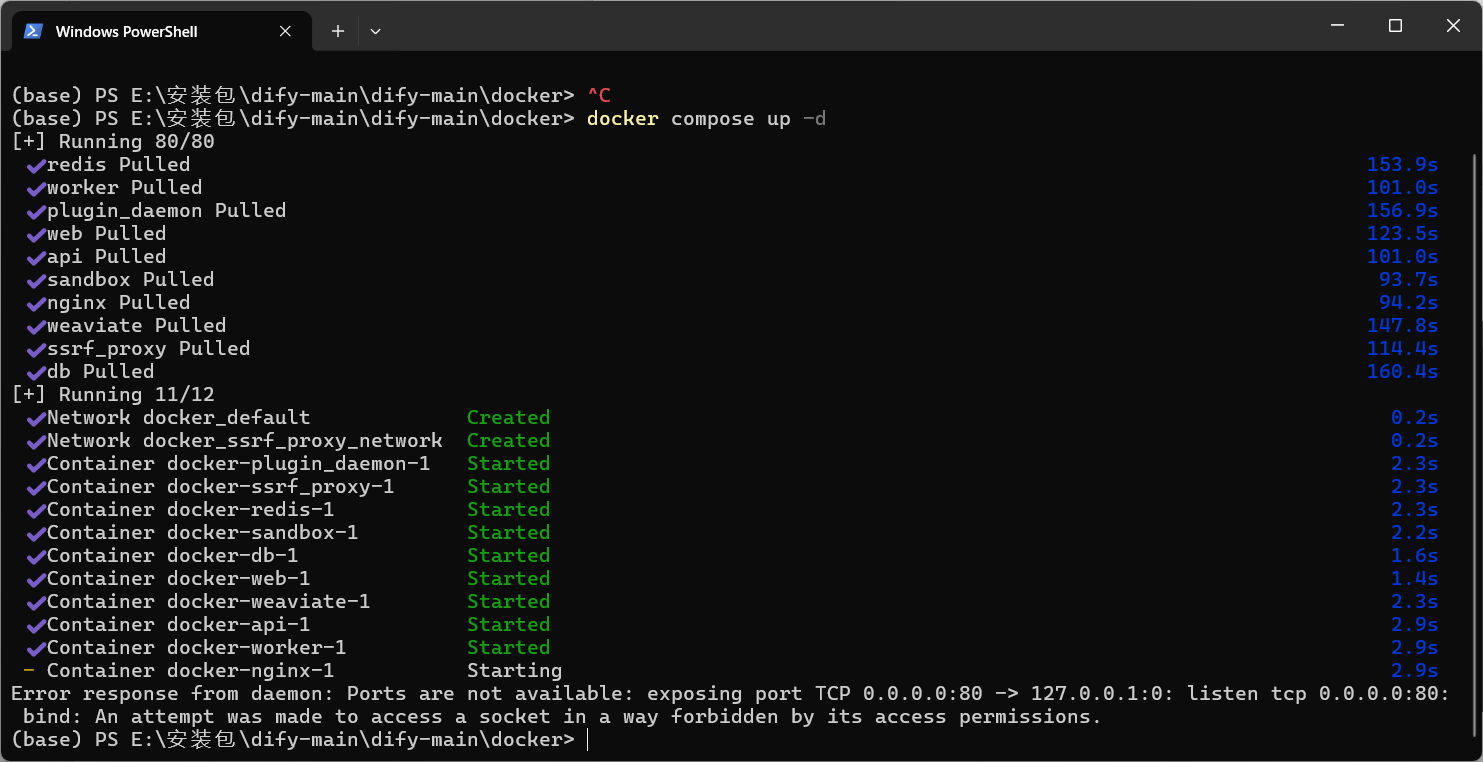
百度查询报错原因是 80 端口被占用。
解决方案参考网页:
① 在 CMD 中查看 80 端口的情况
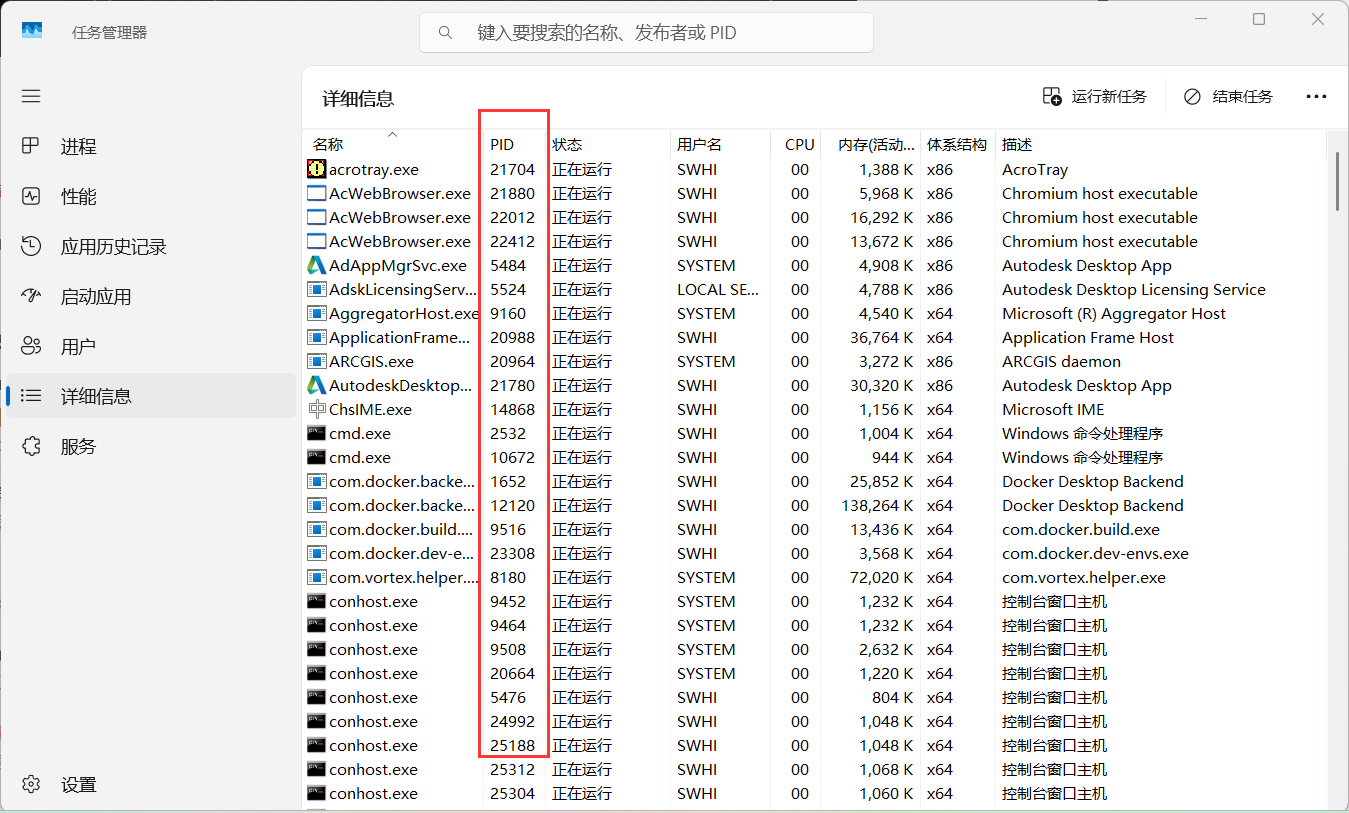
netstat -ano | findstr 80 ②pid为4,说明被系统占用。命令查看一下当前的http服务状态,在 CMD 输入
netsh http show servicestate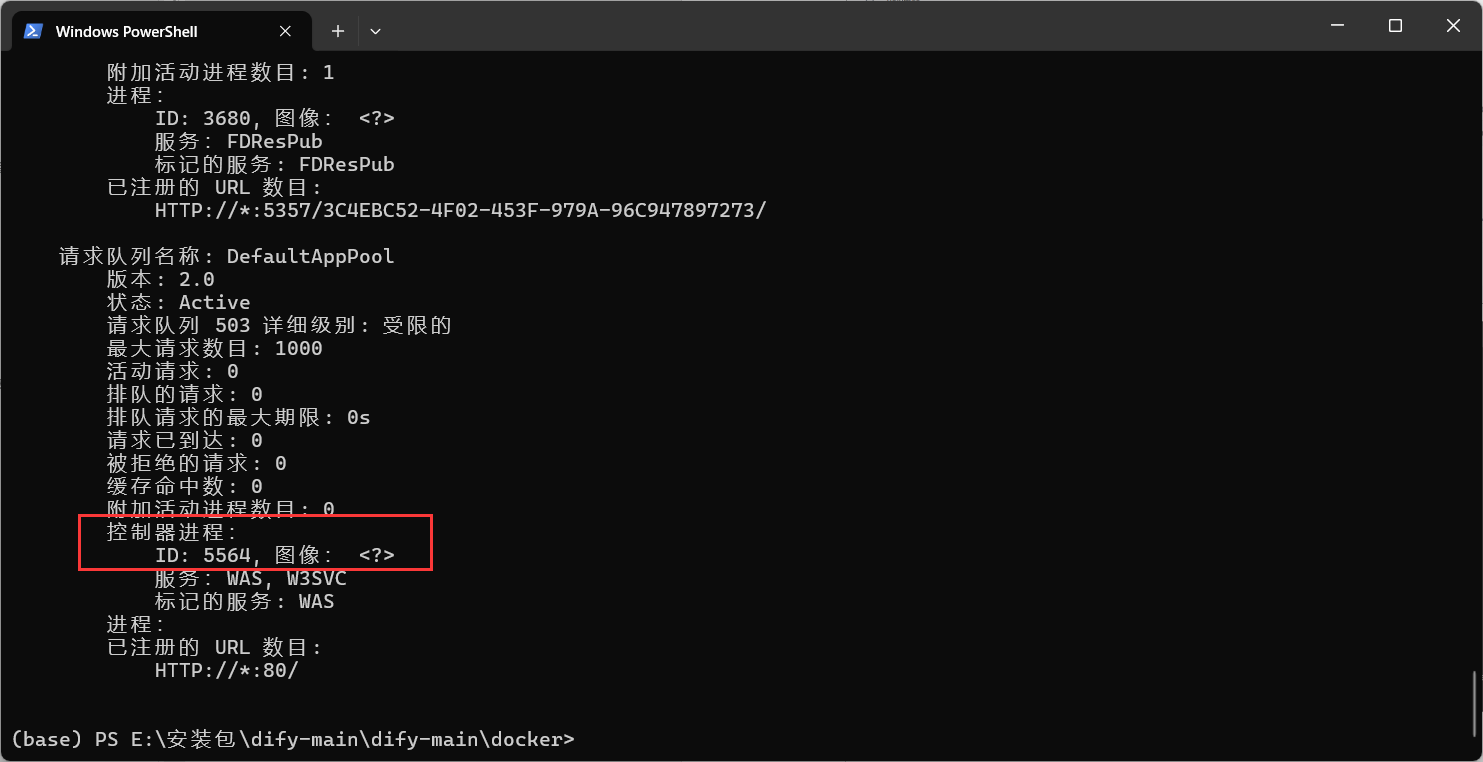
在任务管理器找到上面提到的进程,关闭即可。
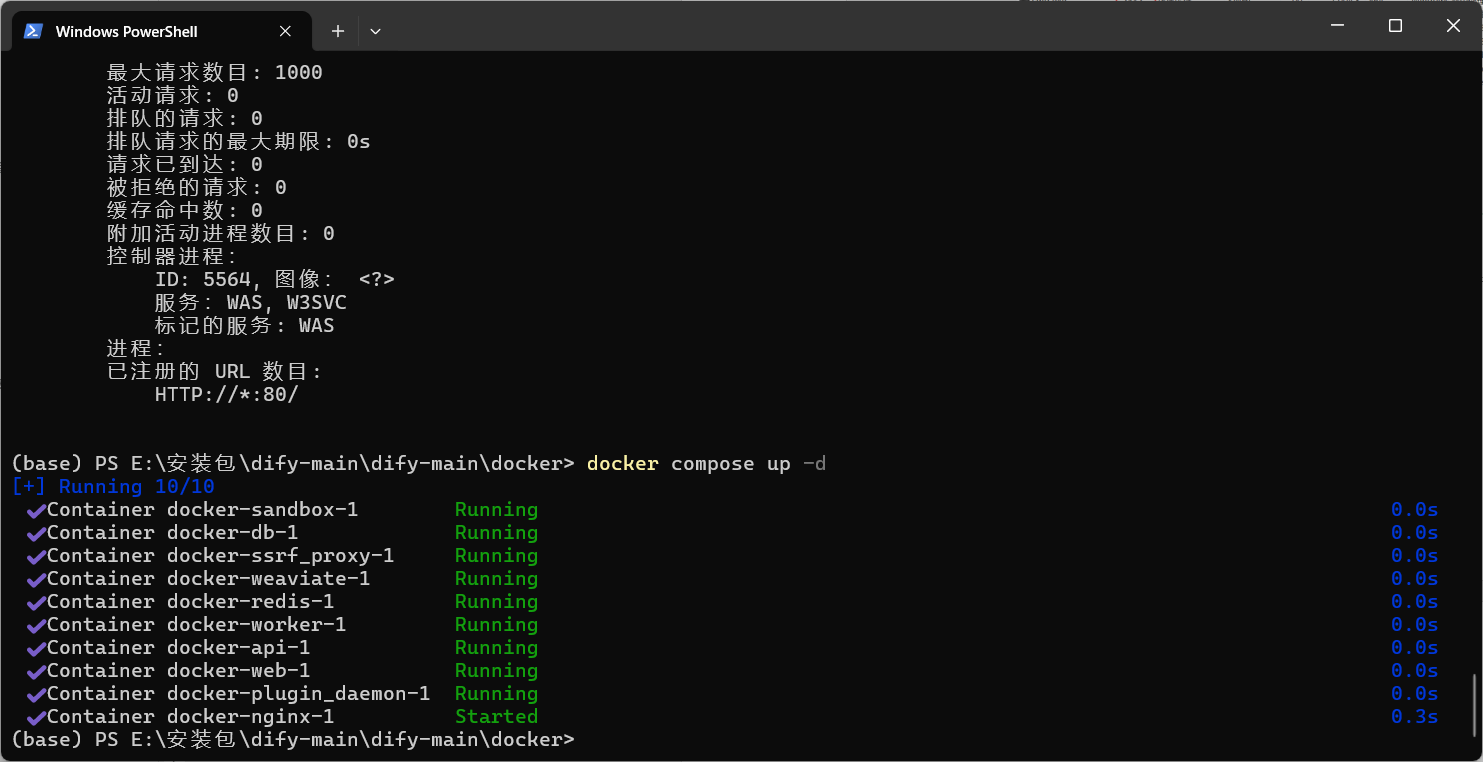
③在CMD中执行:
docker compose up -d可以看到 docker 已经成功运行。
五、配置本地模型与Dify关联
5.1安装dify
在浏览器地址栏输入即可安装:
http://127.0.0.1/install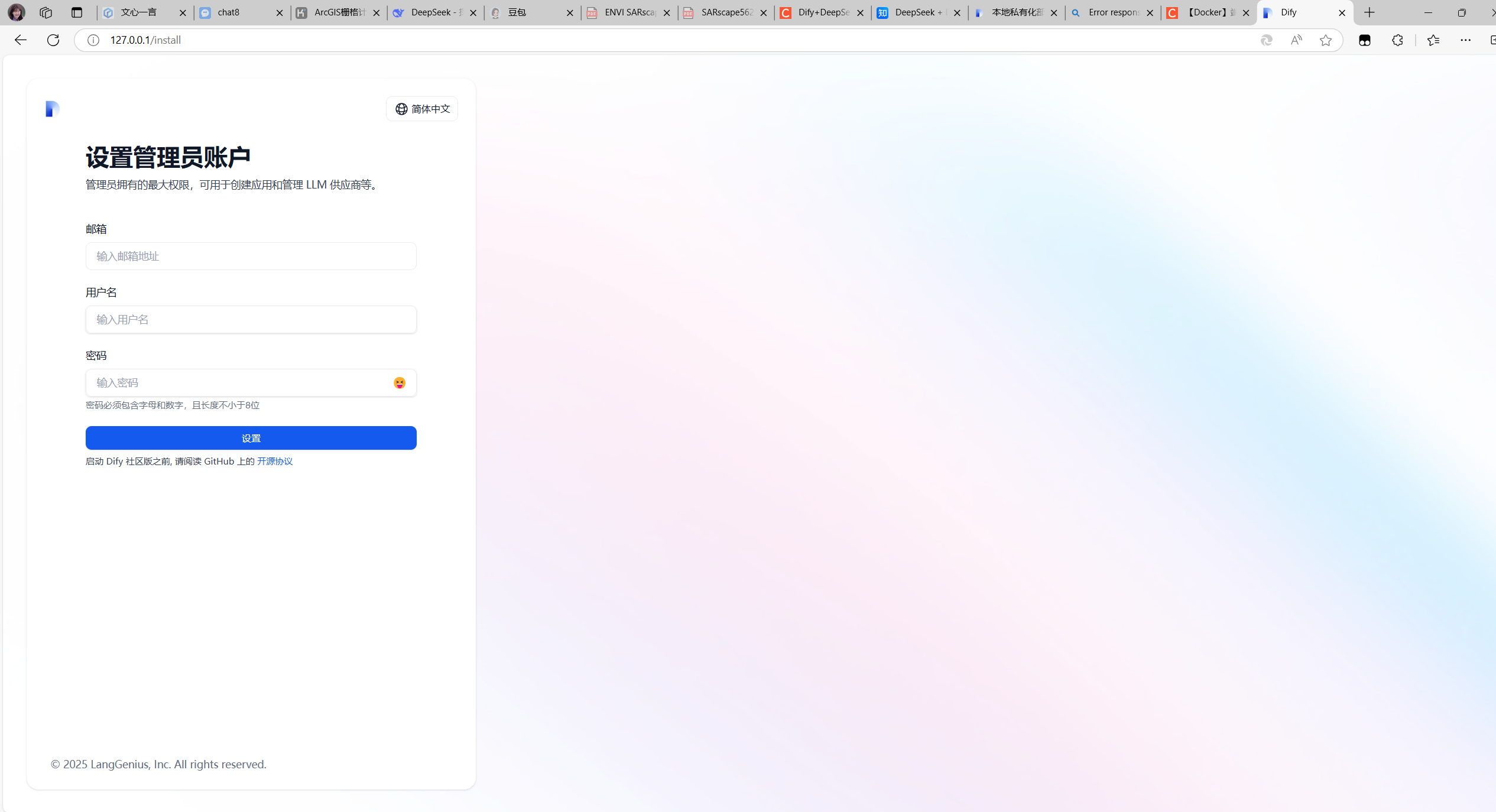
创建新账号。登录,进入dify主页如下:
5.2 获取本机内网 IP
打开命令行:win+r,输入:cmd,在命令行输入:
ipconfig并找到当前连接的网络适配器(如“无线局域网适配器 WLAN”或“以太网适配器”),下方显示的 IPv4 地址即为内网IP。
记住这个IP,后面还有用。
5.3 配置.env文件
配置本地内网IP到dify的docker部署配置文件内。
找到dify项目下的docker文件夹并进入,前面已经将.env.example改为了.env文件了,在末尾填上以下配置:
CUSTOM_MODEL_ENABLED=true
OLLAMA_API_BASE_URL=http:// <你的内网IP>:11434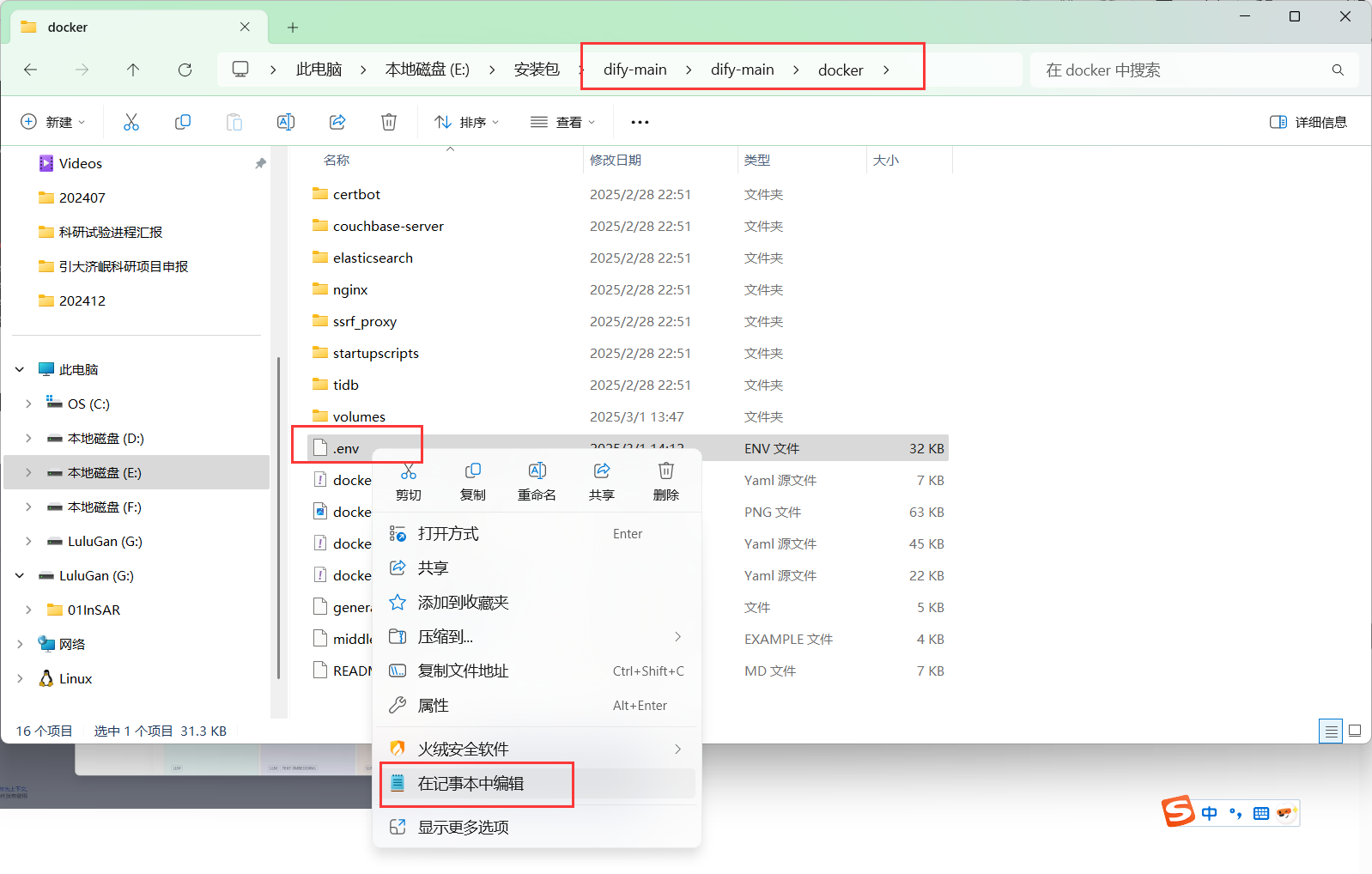
5.4 添加模型
在Dify控制台,进入模型设置,添加Ollama模型,填入上述IP和端口,确保连接成功。
打开dify官网,点击右上角小头像—设置--
模型供应商—找到OLLAMA
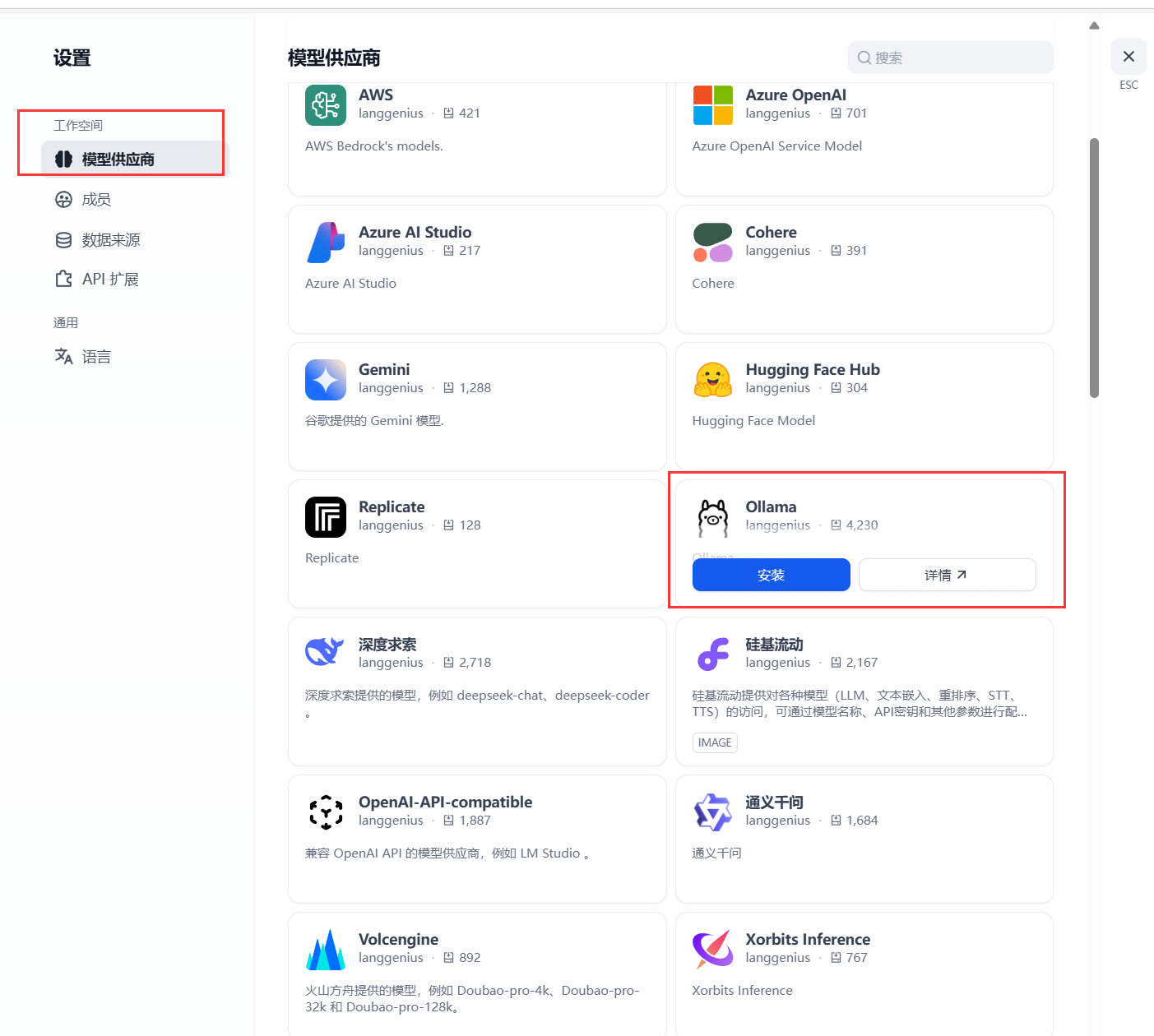
点击安装ollama插件
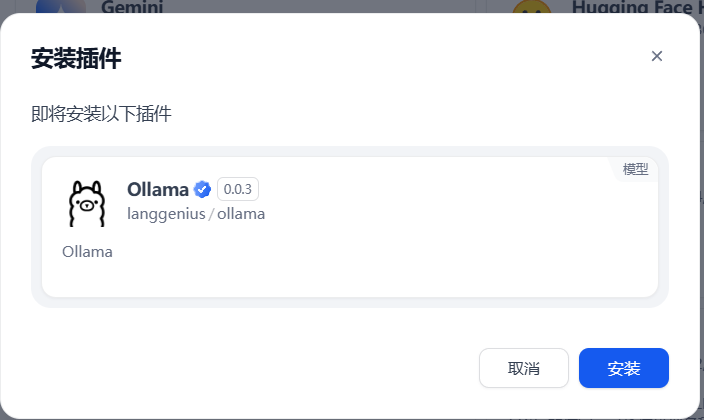
安装成功之后再模型供应商—模型列表可以看到待配置ollama,点击添加模型
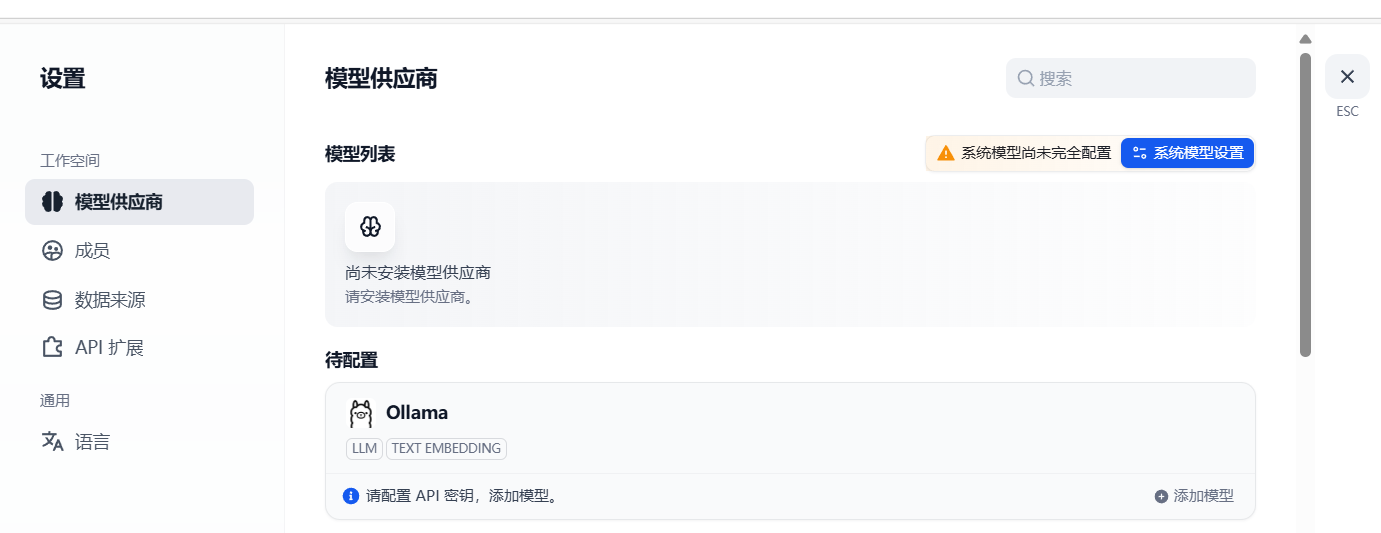
模型类型选择LLM,输入模型名称:deepseek-r1:8b,基础URL输入
http://<你的内网IP>:11434点击保存
网页右上角报错,无法保存,去问deepseek
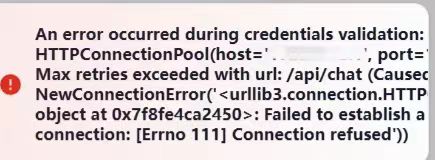
这个错误表明你的程序在尝试与目标服务器(<你的内网IP>)建立连接时失败了,具体原因是连接被拒绝(Connection refused)。

解决方法:将基础URL修改为:
http://host.docker.internal:11434点击保存,提示修改成功。

5.5 配置模型
在模型供应商中修改系统模型设置,选择系统推理模型为本地部署的deepseek。
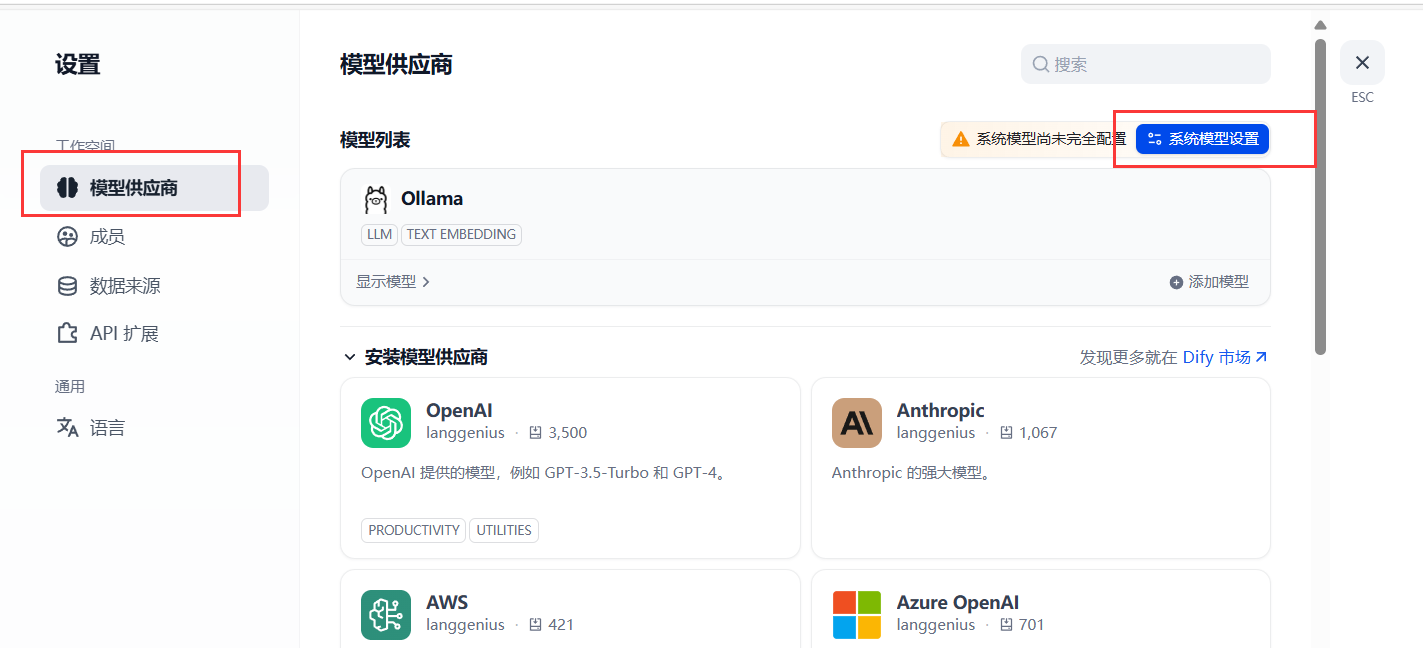
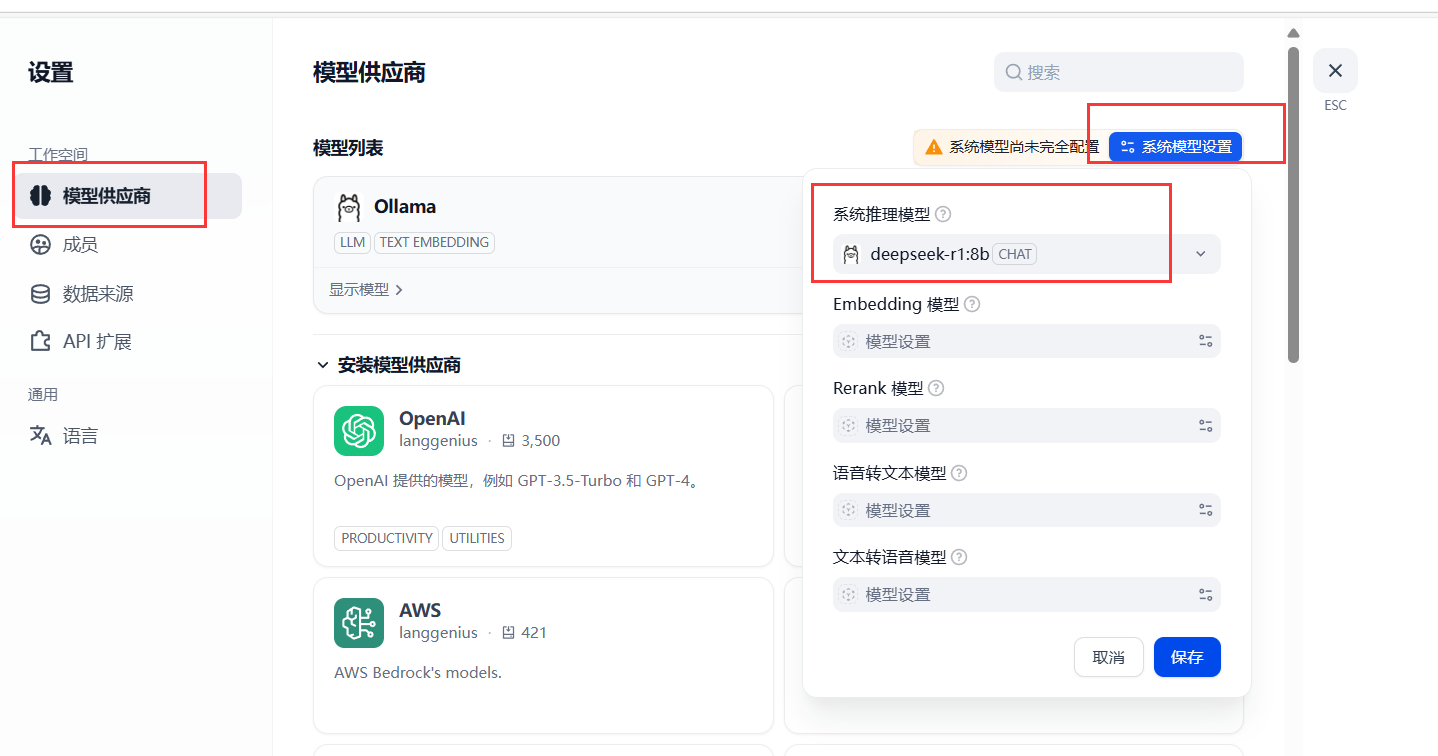
到此,dify就与前面部署的本地大模型关联起来了。
5.6 创建聊天助手
回到dify主页,创建空白应用
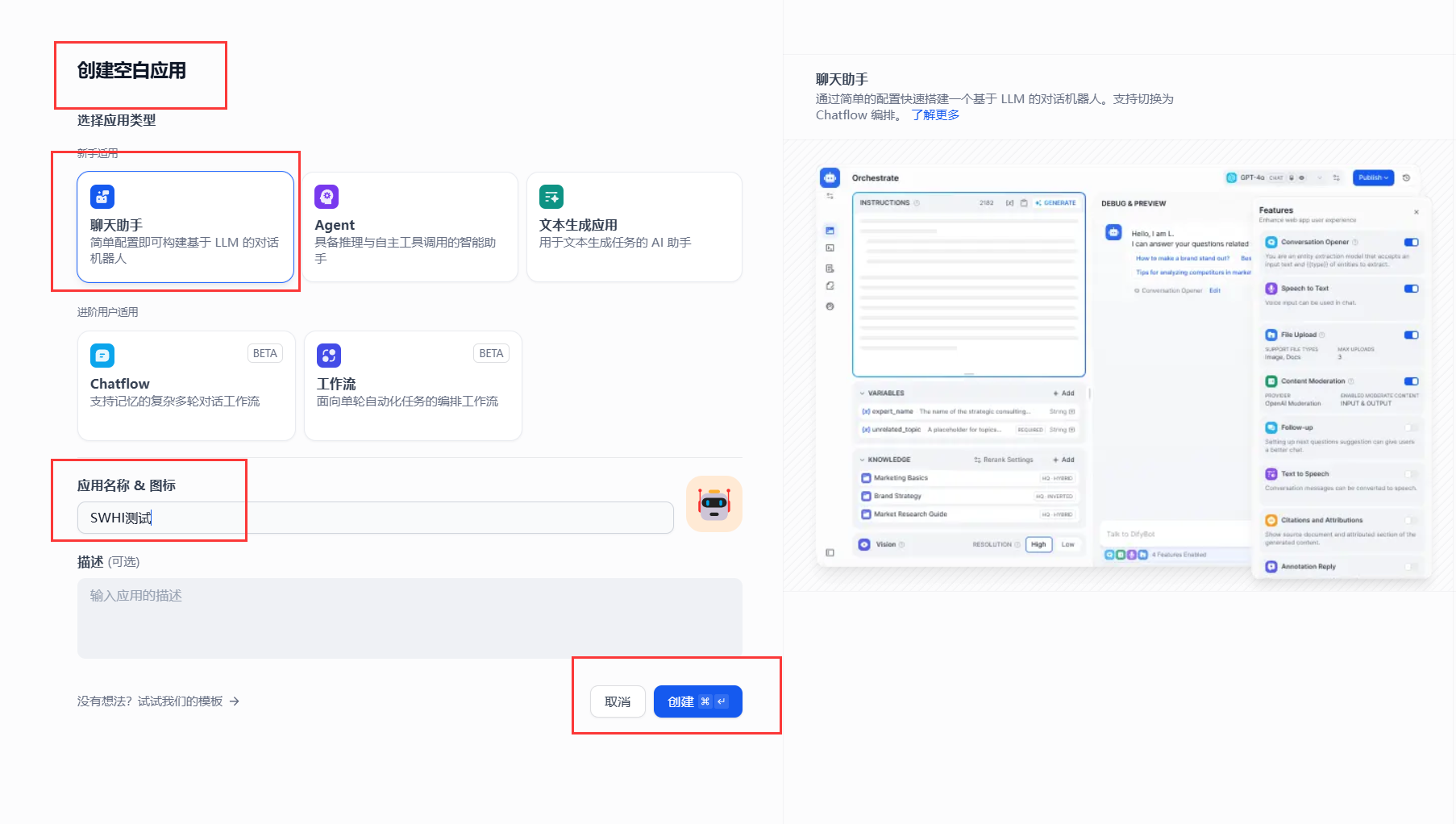
开始应用,选择之前本地部署的大模型
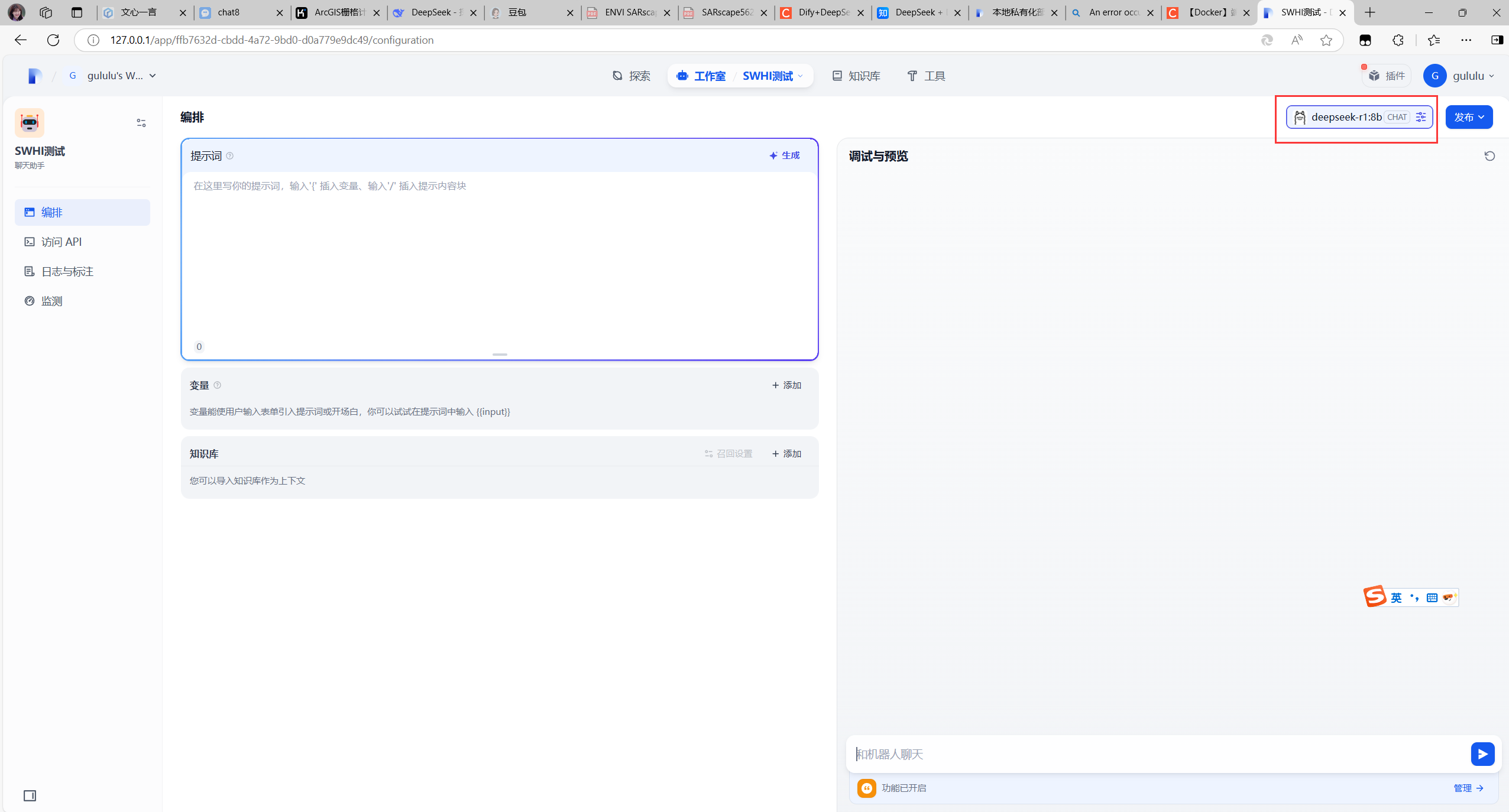
输入问题进行测试。
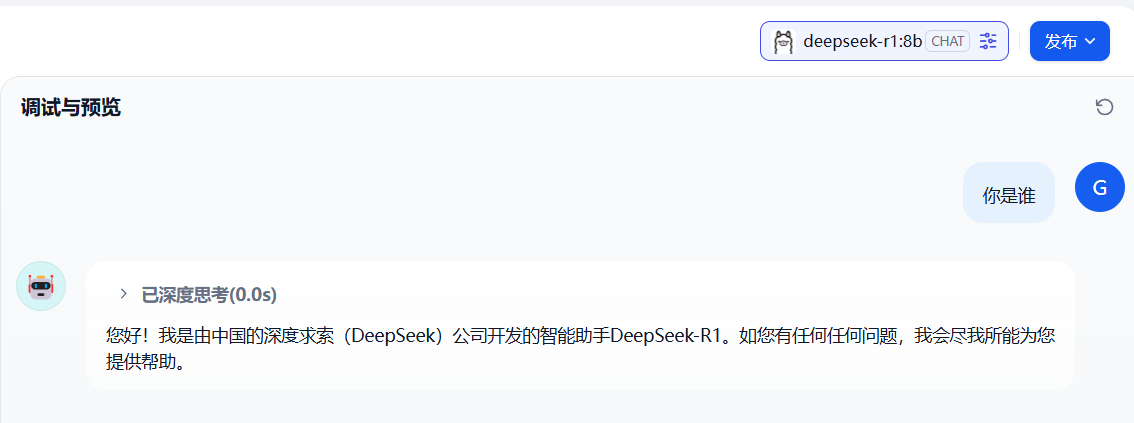
这表明,dify与本地部署的大模型deepseek-r1连通了,但是,我想让他的回答是基于我的私有知识库作为上下文来和我聊天怎么办?这就需要用到本地知识库了。
六、创建本地知识库
6.1 添加Embedding模型
Embedding模型的作用是将高维数据(如文本、图像)转换为低维向量,这些向量能够捕捉原始数据中的语义信息。常见的应用包括文本分类、相似性搜索、推荐系统等。
我们上传的资料要通过Embedding模型转换为向量数据存入向量数据库,这样回答问题时,才能根据自然语言,准确获取到原始数据的含义并召回,因此我们需要提前将私有数据向量化入库。
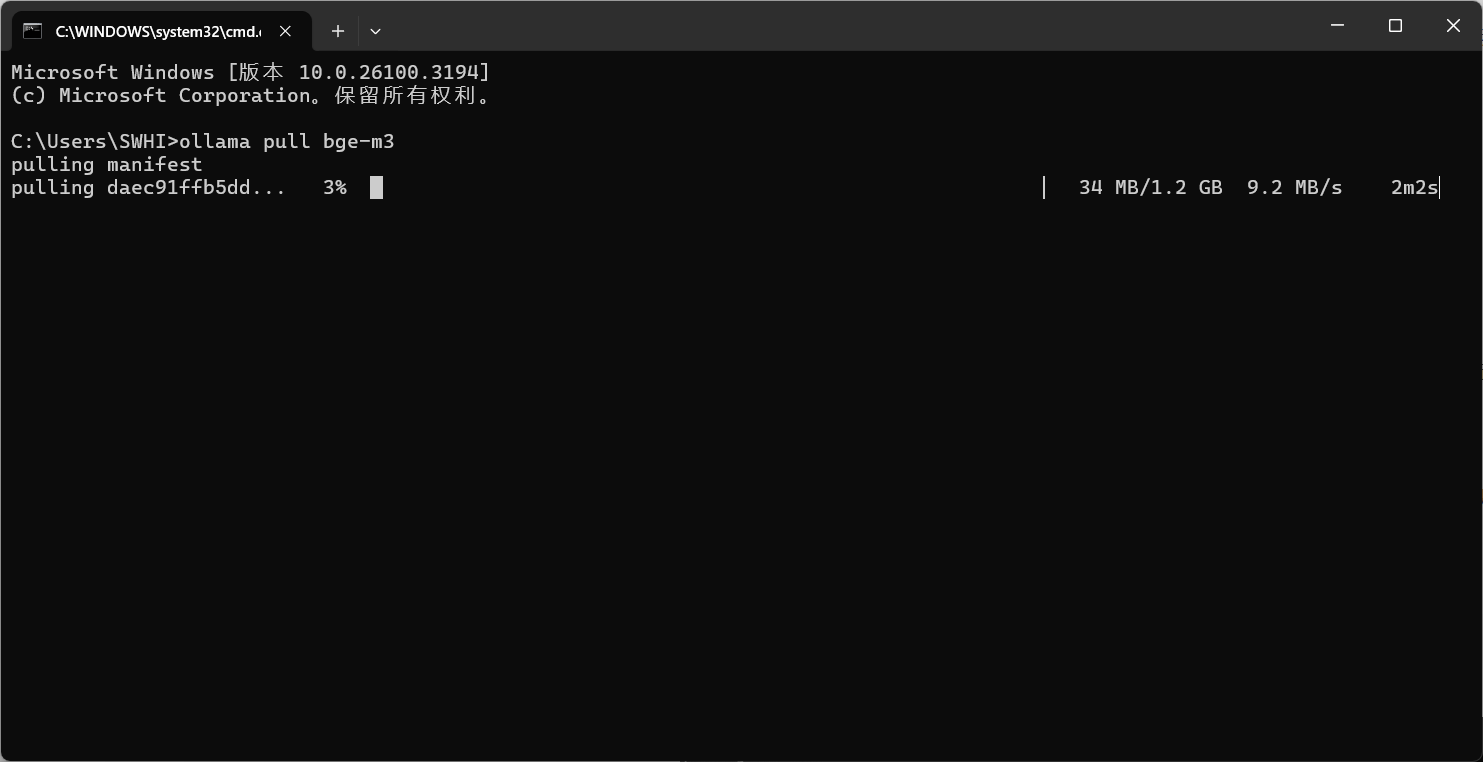
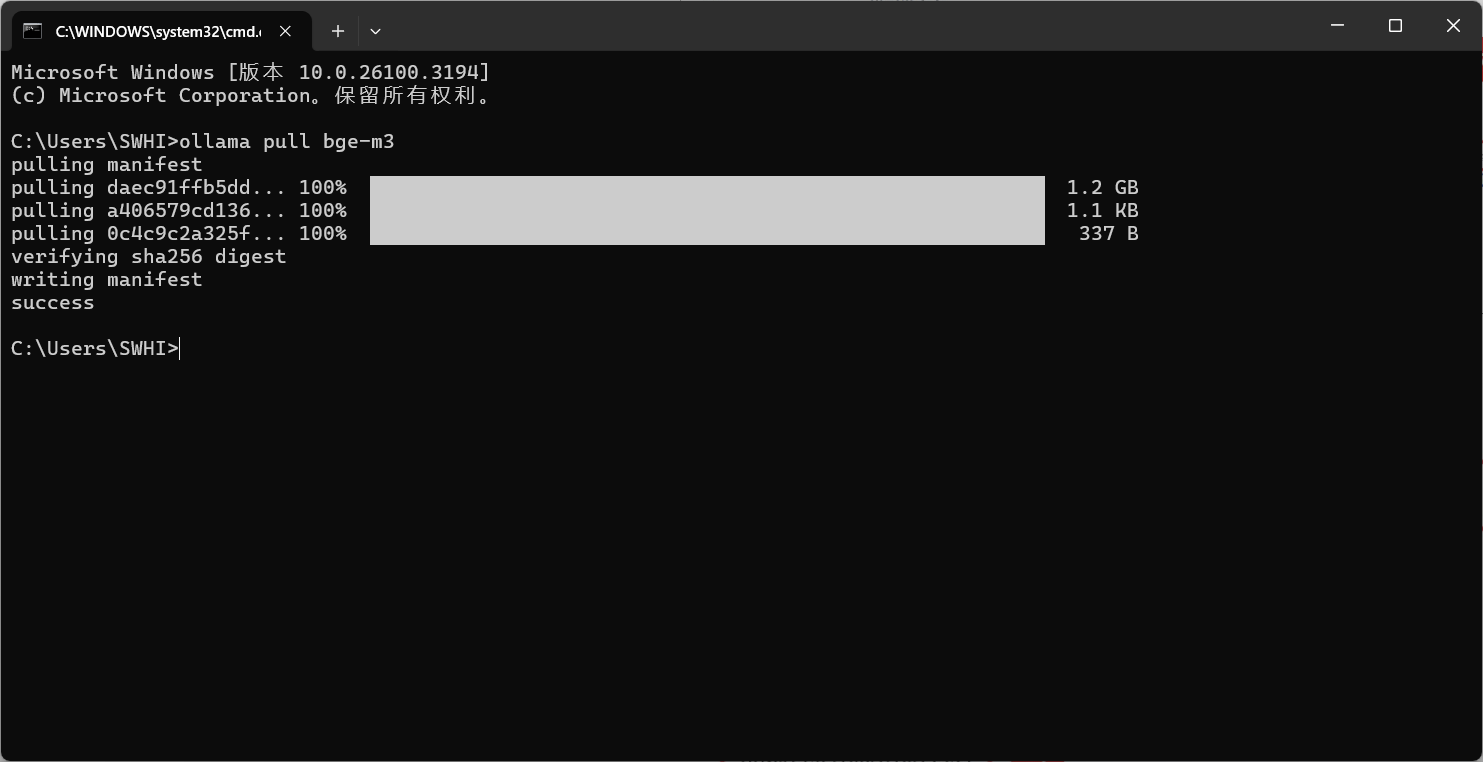
下载 Embedding 模型,下载知识库,打开cmd输入
ollama pull bge-m3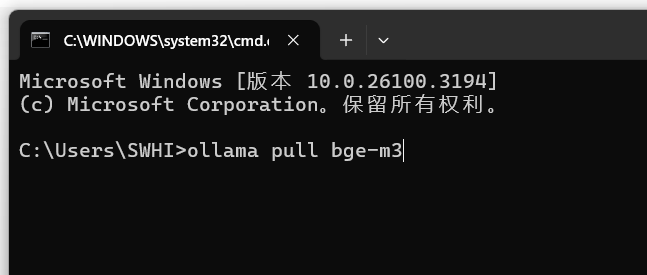
注: BGE (BAAI General Embedding) 专注于检索增强llm领域,经本人测试,对中文场景支持效果更好,当然也有很多其他embedding模型可供选择,可以根据自己的场景,在ollama上搜索“embedding”查询适合自己的嵌入模型。
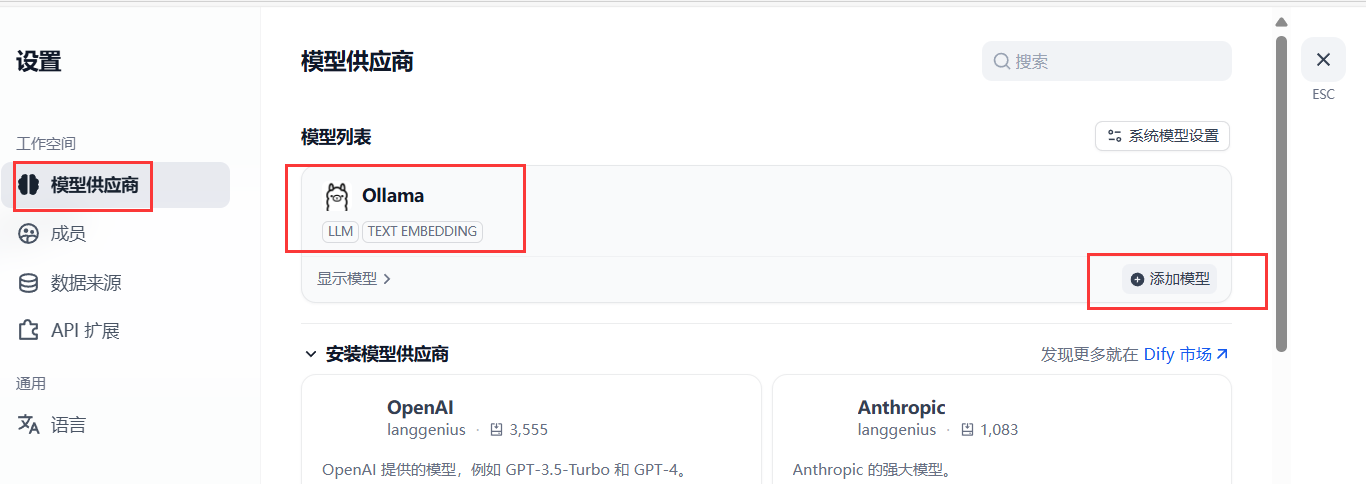
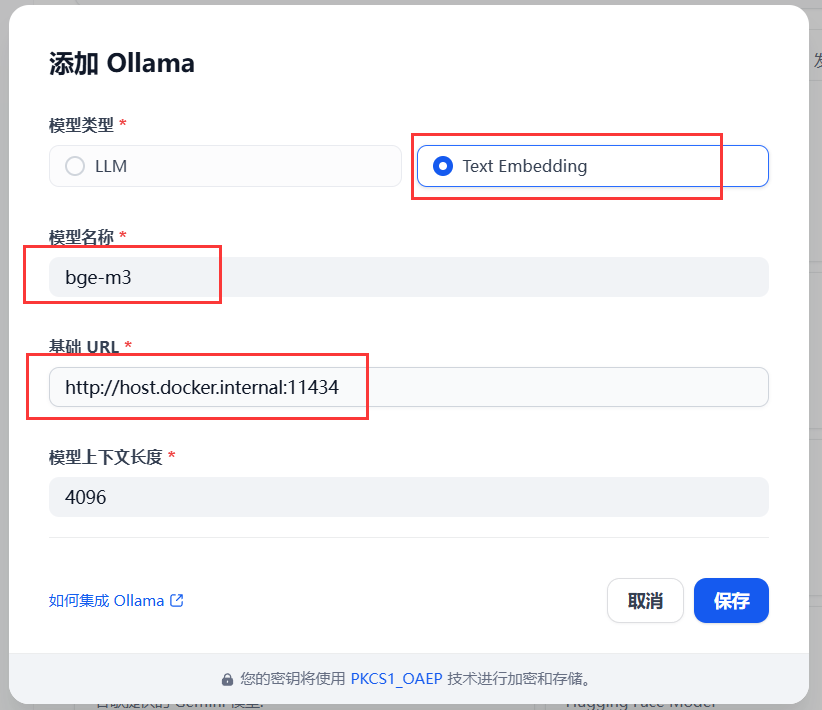
6.2 配置 Embedding 模型
回到dify网页,添加模型
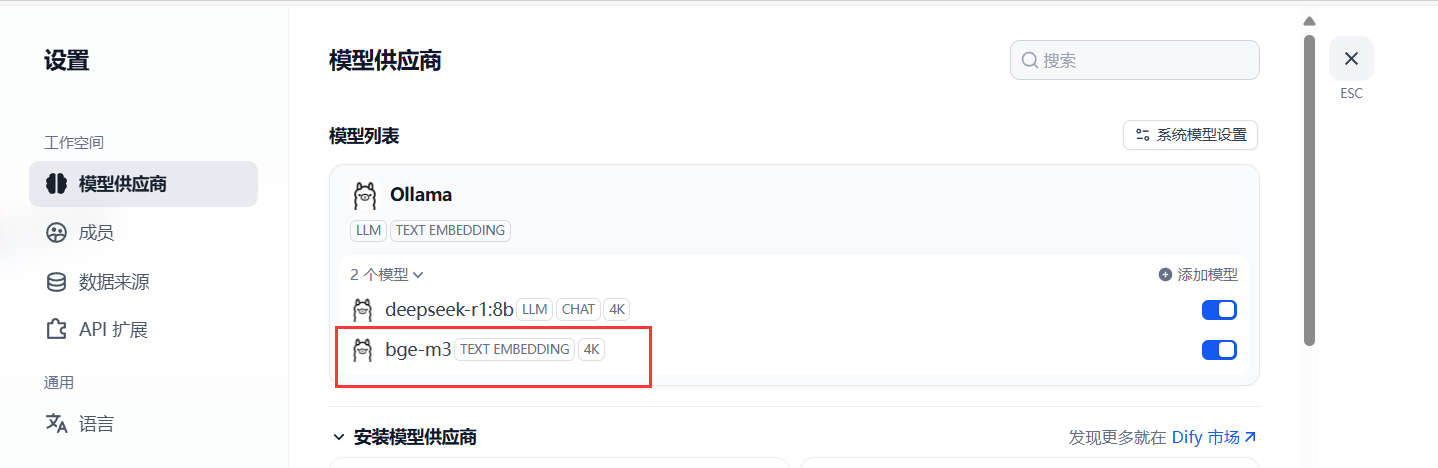
6.3 创建知识库
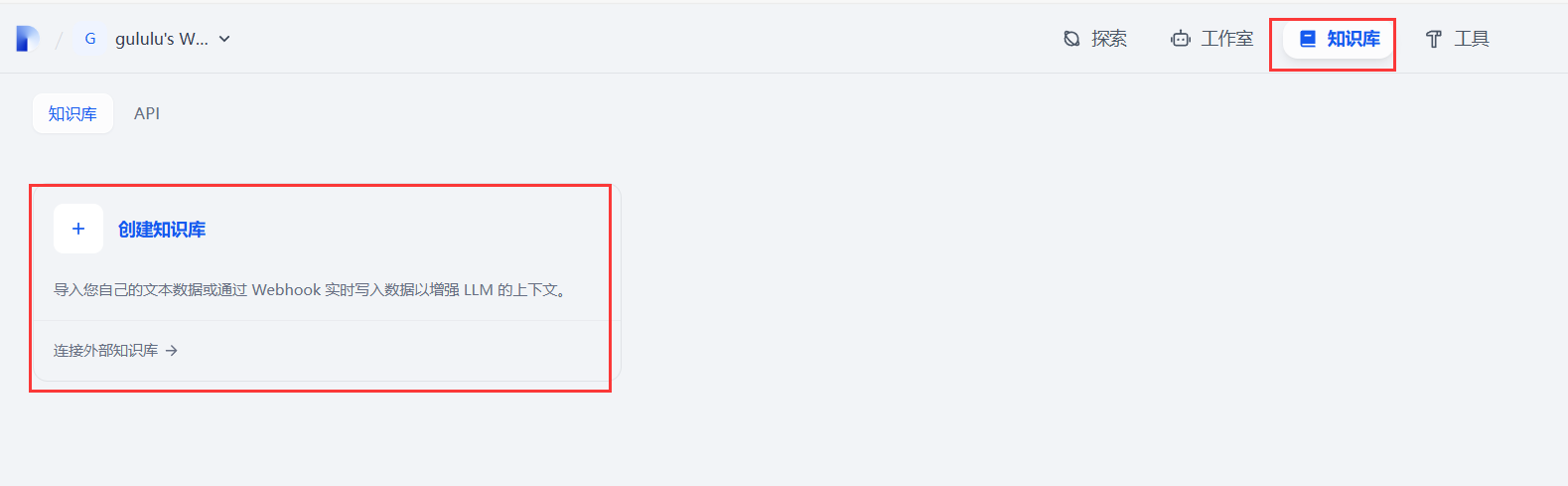
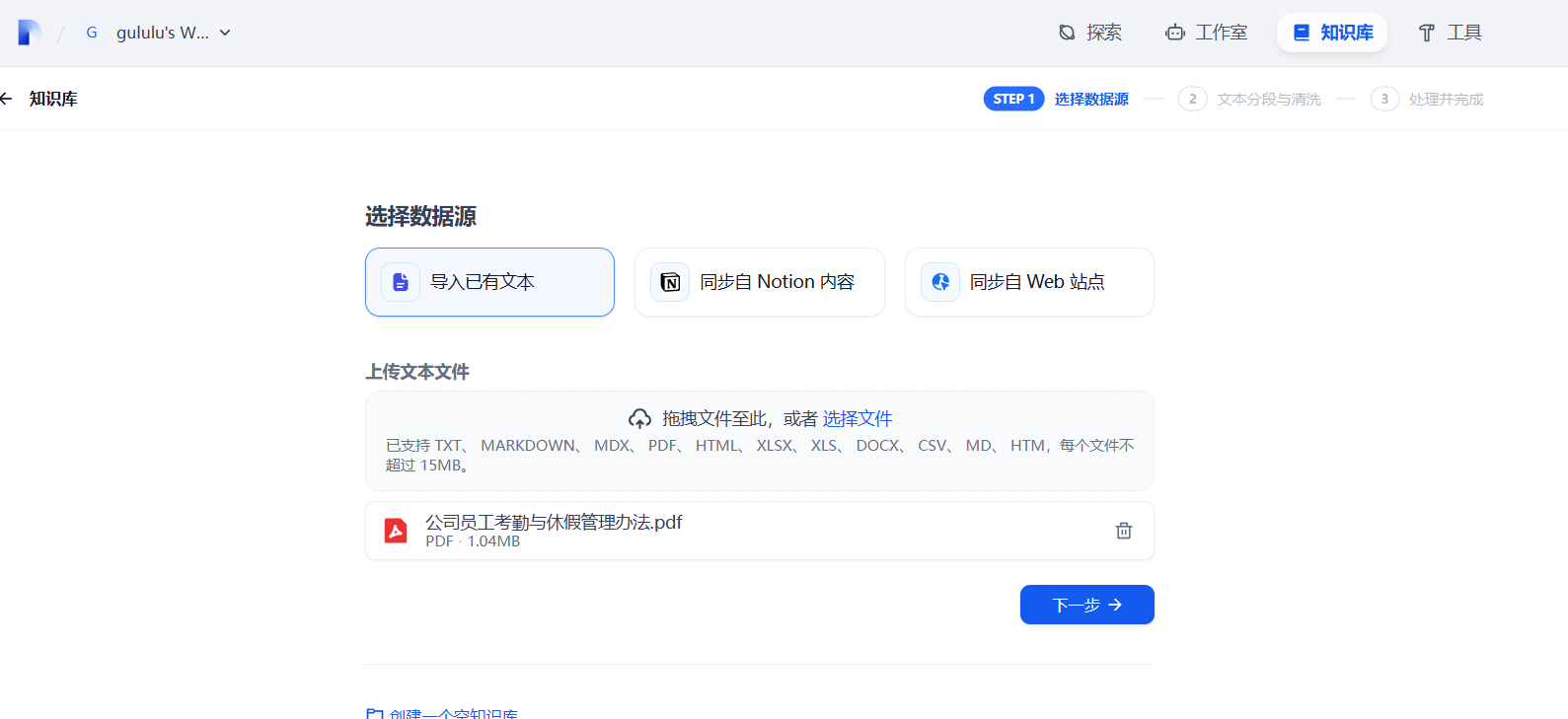
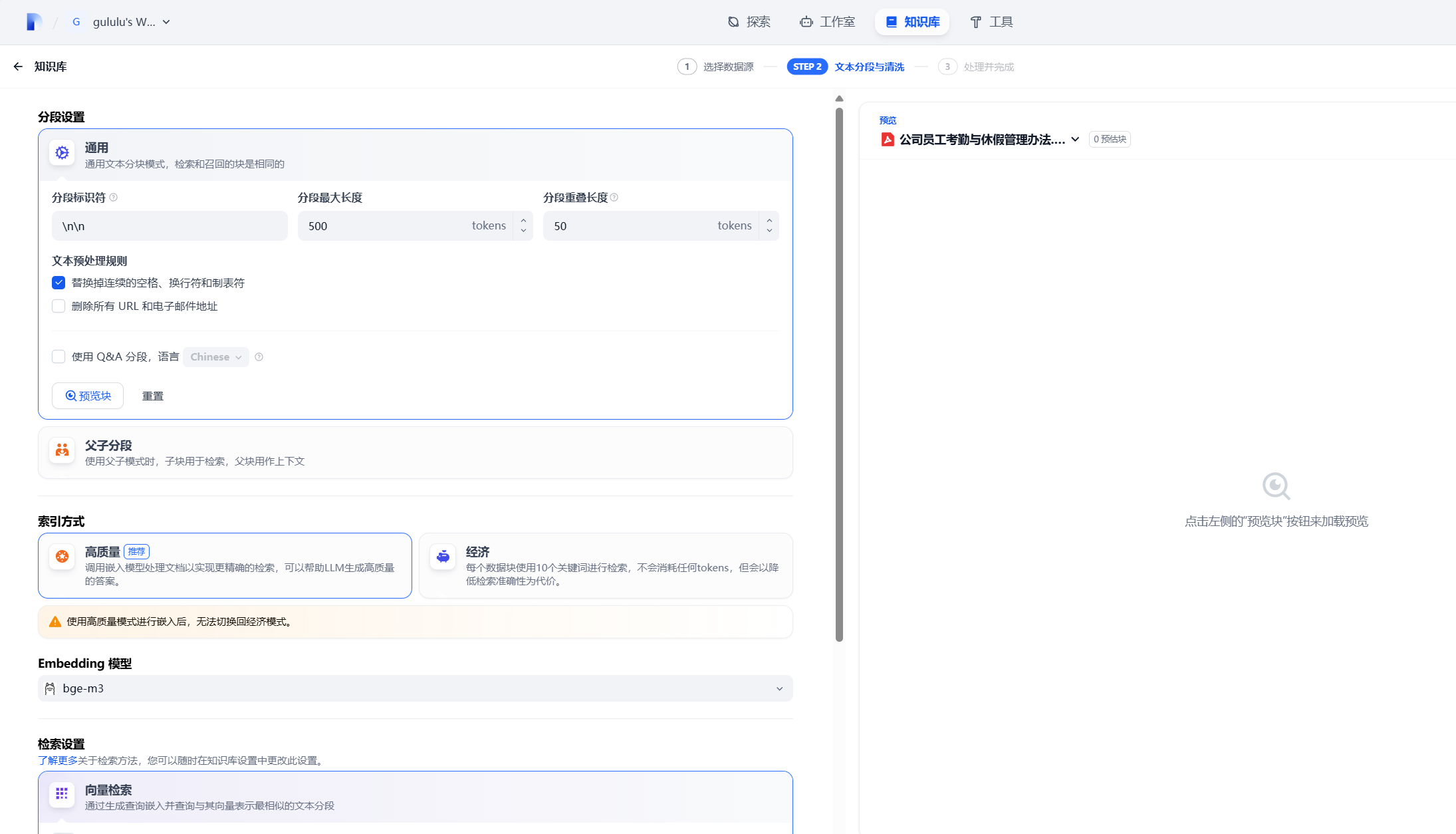
默认不管
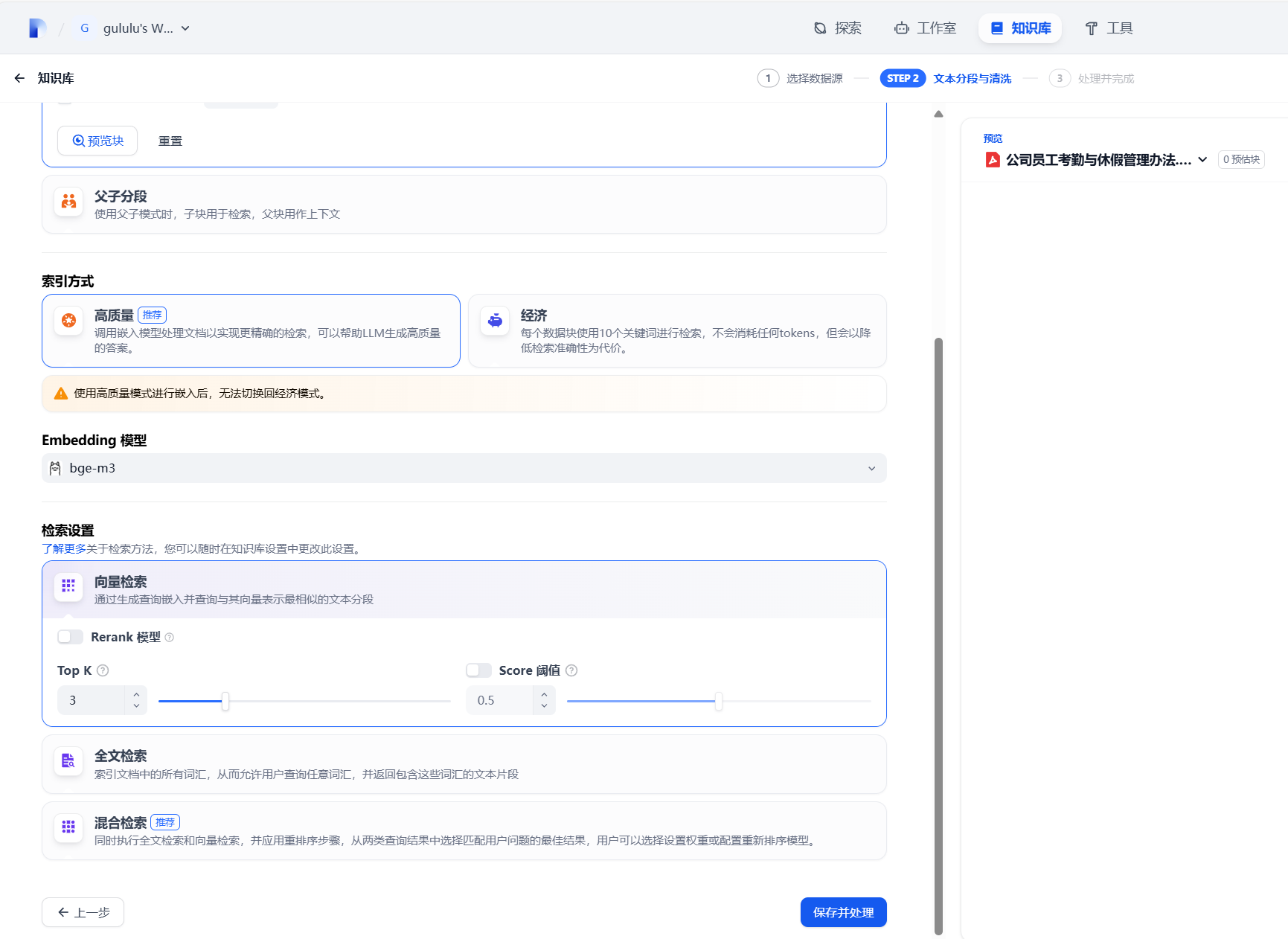
知识库创建完成
6.4 测试知识库
打开刚才创建的聊天助手,添加知识库。
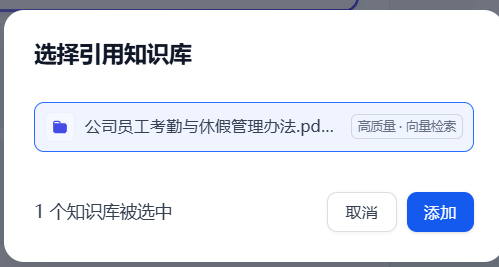
如图所示,知识库添加完成。
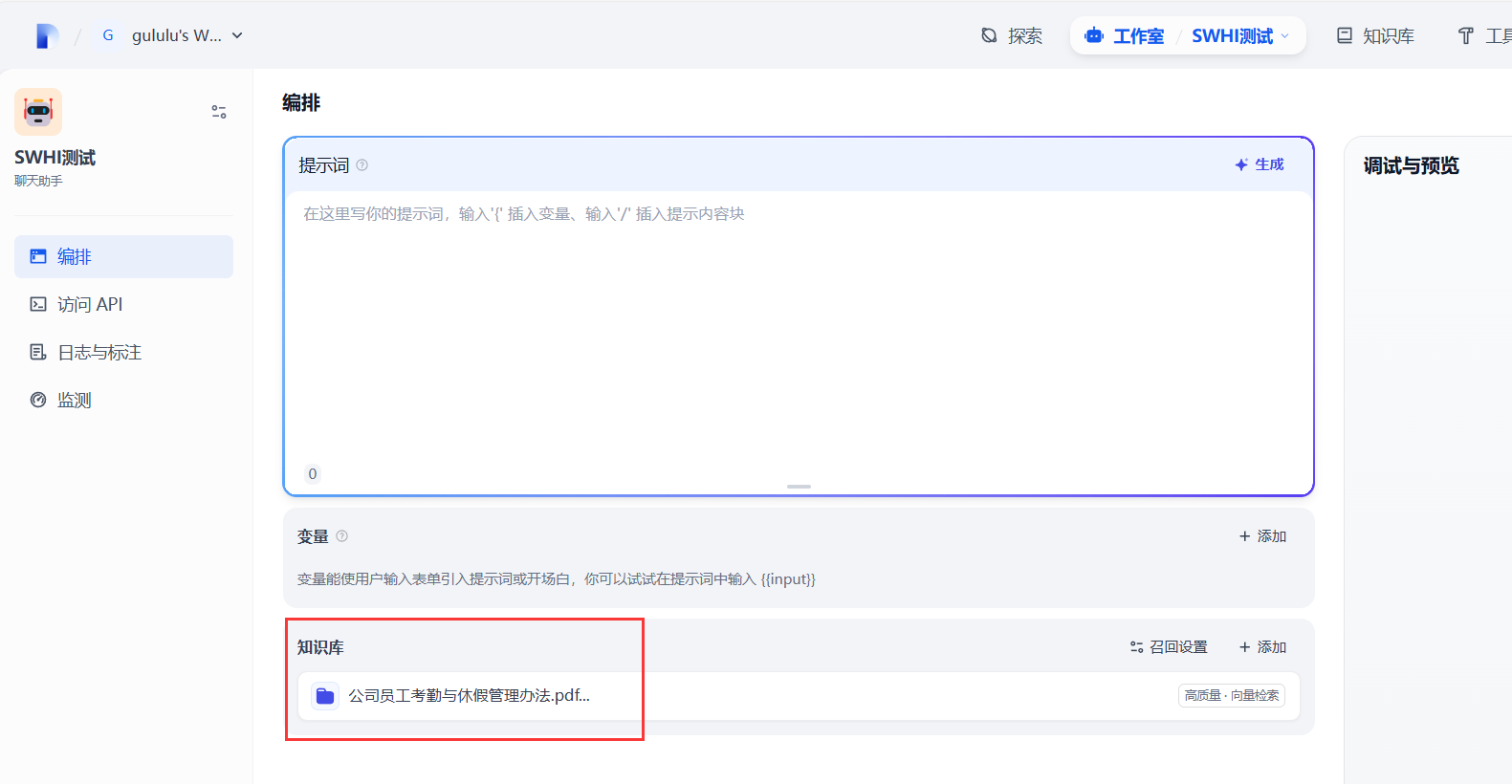
保存当前应用设置。如果只是当前应用内调试可以不必更新,但是如果想把当前应用发布为对外api服务或者持久化保存,就需要保存当前应用设置,记得实时保存当前设置。
测试
如果感觉回答的效果还不满意,可以对召回参数进行调整,或者可以参考官方文档,做其他详细设置。
结语
通过以上步骤,已成功在本地部署DeepSeek-R1模型,并通过Dify平台构建了一个私有化知识库。这不仅降低了成本,还提升了数据安全性,适合企业级应用。
参考网页

















 4194
4194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









