







COA计算题型
题型一、计算机性能指标计算
时钟频率:处理器执行的操作由系统时钟控制,处理器的速度由系统时钟的脉冲频率决定,以每秒周期(Hz)为时钟频率
处理器时间T:处理器执行给定程序所需的时间
🔴 T = 程 序 的 C P U 时 钟 周 期 ∗ 时 钟 周 期 τ = 程 序 的 C P U 时 钟 周 期 / 时 钟 速 率 T= 程序的CPU时钟周期*时钟周期τ=程序的CPU时钟周期/时钟速率 T=程序的CPU时钟周期∗时钟周期τ=程序的CPU时钟周期/时钟速率
🔴 T = C P I × I c × τ = C P I × I c / 时 钟 速 率 T= CPI ×I_c ×τ = CPI ×I_c /时钟速率 T=CPI×Ic×τ=CPI×Ic/时钟速率
C P I CPI CPI: 每条指令的平均周期 I c I_c Ic: 指令数
受指令集体系结构、编译技术、处理器实现和内存层次结构的影响
处理器速度:指令执行的速度,表示为每秒数百万条指令(MIPS),称为MIPS速率
M
I
P
S
r
a
t
e
=
I
c
T
×
1
0
6
=
f
C
P
I
×
1
0
6
MIPS\ rate = \frac{I_c}{T\times10^6}=\frac{f}{CPI\times10^6}
MIPS rate=T×106Ic=CPI×106f
每秒数百万个浮点指令(MFLOPS)

题型二、Amdahl定律计算
对系统某部分加速时,其对系统整体影响取决于该部分重要性和加速程度。
要想显著加速整个系统,必须提升全系统中相当大的部分的速度。
设 变 量 F e = 能 改 进 的 部 分 整 体 ≤ 1 S e = 改 进 前 的 时 间 改 进 后 的 时 间 ≥ 1 设变量\ \ F_e=\frac{能改进的部分}{整体}\le1 \qquad \ S_e=\frac{改进前的时间}{改进后的时间}\ge1\qquad\qquad 设变量 Fe=整体能改进的部分≤1 Se=改进后的时间改进前的时间≥1
再 设 T 0 : 任 务 在 性 能 提 升 前 的 执 行 时 间 再设\ T_0:任务在性能提升前的执行时间 再设 T0:任务在性能提升前的执行时间
改进后整个任务的执行时间为:
T
n
=
T
0
(
1
−
F
e
+
F
e
S
e
)
T_n = T_0(1-F_e+\frac{F_e}{S_e})
Tn=T0(1−Fe+SeFe)
加速比为:
S
n
=
T
0
T
n
=
1
(
1
−
F
e
)
+
F
e
S
e
S_n=\frac{T_0}{T_n}=\frac{1}{(1-F_e)+\frac{F_e}{S_e}}
Sn=TnT0=(1−Fe)+SeFe1
F
e
F_e
Fe对系统性能提升的限制作用很强
举例:假设一个任务大量使用浮点运算,40%的时间被浮点运算占用。在新的硬件设计下,浮点模块的速度提高了k倍。这种改进带来的总体加速是多少?
解: F e = 0.4 , S e = K F_e=0.4,S_e=K Fe=0.4,Se=K,根据Amdahl定律: S n = T 0 T n = 1 ( 1 − F e ) + F e S e = 1 0.6 + 0.4 / K S_n=\frac{T_0}{T_n}=\frac{1}{(1-F_e)+\frac{F_e}{S_e}}=\frac{1}{0.6+0.4/K} Sn=TnT0=(1−Fe)+SeFe1=0.6+0.4/K1
当$S_e= ∞, Sn=1.67 $,所以总体加速最多为1.67
题型三、指令执行过程
举例说明,使用一台包含下图所列特点的假想机器,其处理器包含唯一的一个数据寄存器,被称为累加器(AC); 其指令和数据都是16位长,这样便于用16位的字来组织存储器;其指令格式提供4位的操作码,表示最多可以有2* 4= 16种不同的操作码,最多有21=
4096(4K)个字的存储器可以直接寻址。下面说明部分程序的执行,显示了存储器和处理器寄存器的相关部分
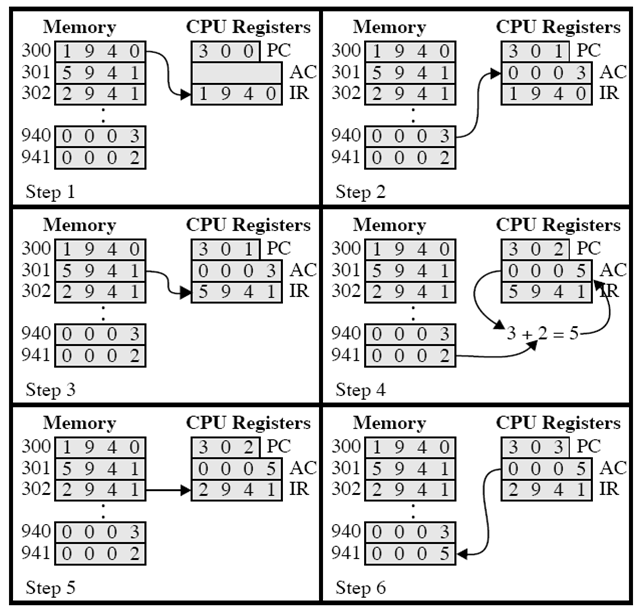
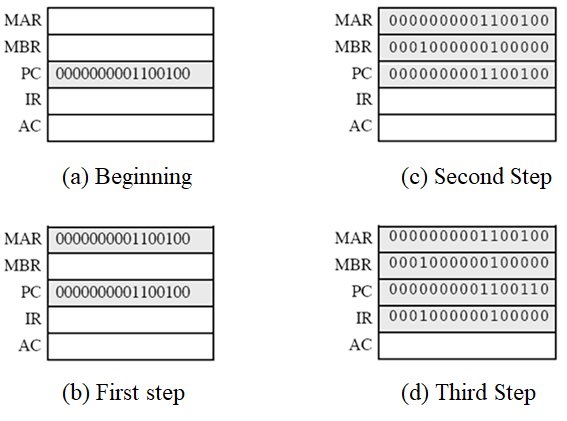
1️⃣ 程序计数器(PC) 的内容是300,即第1条指令的地址。这条指令(其值为十六进制数1940)被装入指令寄存器IR并且PC加1。注意,为简便起见,忽略对存储器地址寄存器(MAR) 和存储器缓冲寄存器(MBR)的使用
2️⃣ IR中的前4位(第1个十六进制数字)指出要装入累加器(AC),而其余12位(3个十六进制数字)指定从那个地址(940) 取数据装载。即地址940的数据0003装人AC。
3️⃣ 从单元301中取下一条指令(5941), 并且PC加1。
4️⃣ AC中存放的内容和941单元的内容相加,结果放人AC。
5️⃣ 从单元302中取下一条指令(2941), 并且PC加1
6️⃣ 将AC的内容存人941单元。
在这个例子中,将940单元的内容加到941单元用了3个指令周期,每个指令周期都包含了一个取指周期和一个执行周期。如果用更复杂的指令集,则需要更少的周期。
题型四、传输率计算
传输率:这是数据传人或传出存储单元的速率。对于随机存取存储器,它等于“1/周期时间”。而对于非随机存取存储器,有下列关系:
T
N
=
T
A
+
n
R
T_N=T_A+\frac{n}{R}
TN=TA+Rn
其中:
T
N
T_N
TN:读或写N位的平均时间
T A T_A TA:平均读取时间
n n n:位数
R R R:传输率,单位是b/s(位/秒)
题型五、cache与主存的映射
映射机制是用硬件实现的
有三种典型的映射机制:直接映射direct mapping、全关联映射associative mapping、组关联映射set associative mapping
对于所有这三种映射方法,该例子中都包含下列条件:
cache 能存储64KB。
数据在主存和cache之间以每块4字节大小传输。这意味着cache被组织 16 K = 2 14 16K =2^{14} 16K=214行,每行4字节。
主存容量为16MB, 每个字节直接由24位的地址( 2 24 = 16 M 2^{24}=16M 224=16M) 寻址。因此,为了实现映射,我们把主存看成是由4M个块组成,每块4字节。
(1) 直接映射
主存中的块j和cache中的行i有如下直接映射关系: i = j m o d e m i=j\ mode\ m i=j mode m,其中m为cache的行数
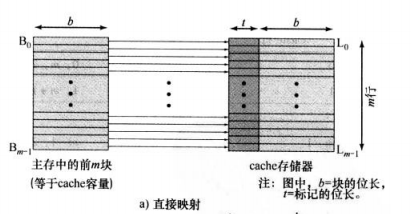
直接映射的实现
存储器的地址会被分为三部分:
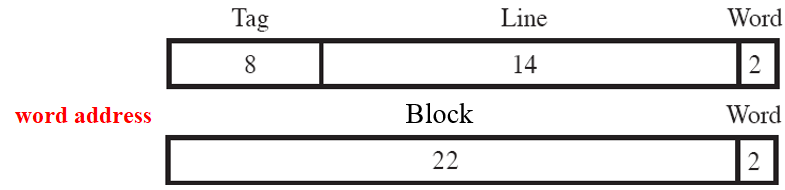
低位是字内容;
中间的位标识cache的行,由cache初始的行数m所确定, l i n e = log 2 m line=\log _2m line=log2m;
高位标识是哪一个块,当一块读入到分配给它的行时,必须给数据做标记,从而将它与能装入这一行的块区别开来
tag域位数是用block域位数减去line域位数算出来的,不是直接分配
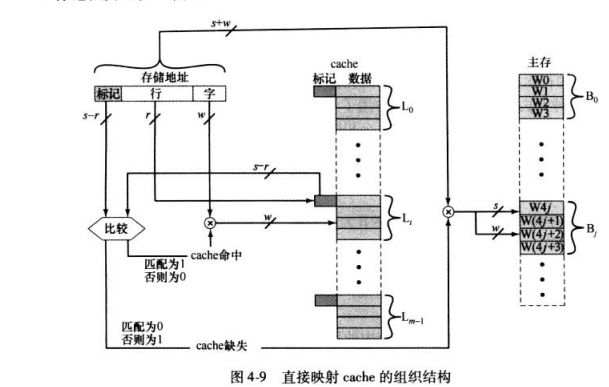
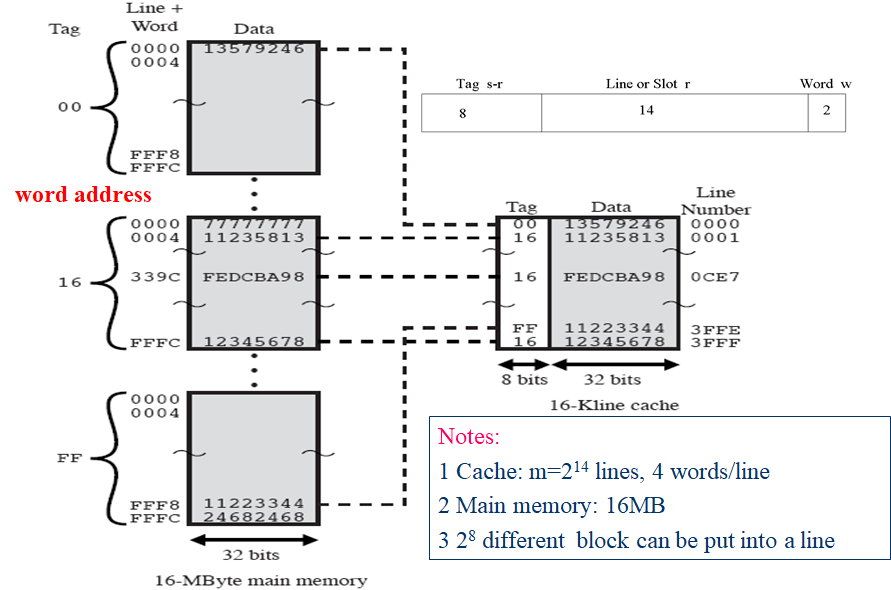
总结如下
地址长度=(s+w)位
可寻址的单元数= 2 s + w 2^{s+w} 2s+w个字或字节
块大小=行大小= 2 w 2^{w} 2w个字或字节
主存的块数= 2 s 2^{s} 2s
cache的行数=m= 2 r 2^{r} 2r
cache的容量= 2 r + w 2^{r+w} 2r+w个字或字节
标记长度tag=(s-r)位
优点:实现简单
缺点:较为固定、不够灵活
🏷 如果一个程序恰巧重复访问两个需要映射到同一行中而且来自不同块的字,则这两个块会不断的交换到cache中,cache的命中率将会降低,也就是抖动
🔖 使用虚拟缓存可以解决
适用于大容量cache
(2) 全关联映射
全关联映射允许每一个主存块装入cache中的任意行,此时只需要用标记位表示一个主存块。

为了确认某一块是否在cache中,需要对每一行中的标记进行搜寻检查。地址中无对应行号的字段
总结如下
地址长度=(s+w)位
可寻址的单元数= 2 s + w 2^{s+w} 2s+w个字或字节
块大小=行大小= 2 w 2^{w} 2w个字或字节
主存的块数= 2 s 2^{s} 2s
cache的行数不由地址格式决定
标记长度tag=s位
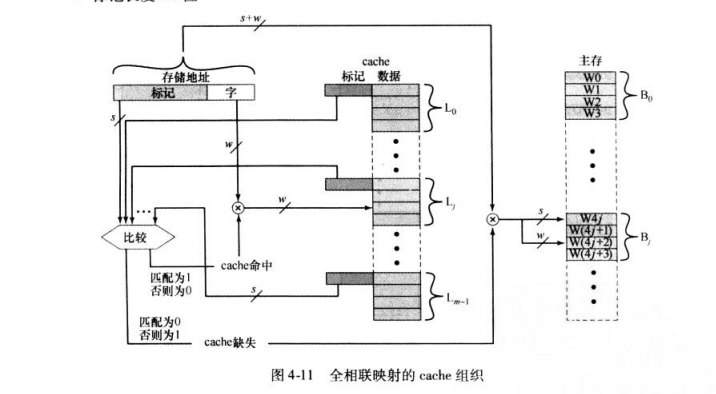
优点:映射灵活,命中率最高
因为主存中的每一个字块都可以映射到cache中的任意一行
缺点:并行比较电路很难设计,系统开销大,用于比较小的cache
有空行放空行,没空行利用替换算法放
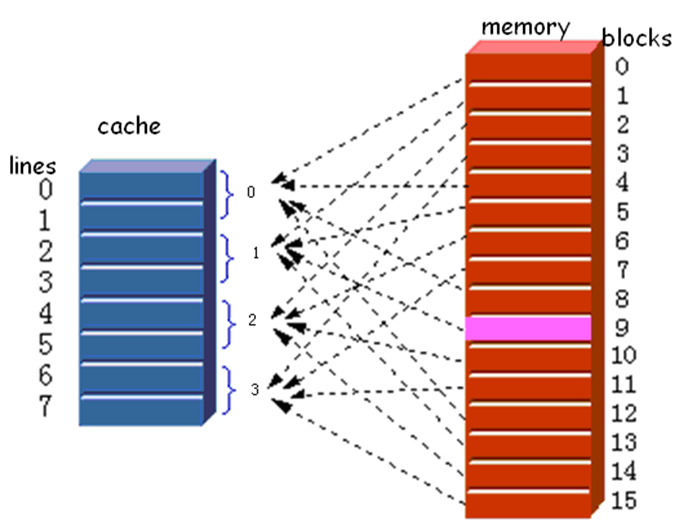
(3) 组关联映射
现在的cache最经常采用的映射方法,前两种方法的折衷
主存分成块、cache分成组,在组关联映射中,cache分为v个组,每组包含k个行,它们的关系为: m = v × k m=v\times k m=v×k i = j m o d e v i=j\ mode\ v i=j mode v
其中:i为cache组号、j为主存块号、m为cache的行数、v为组数、k为每组中的行数
这被称为k路组关联映射。采用组关联映射,块 B 0 B_0 B0能够映射到组j的任意行中。在全相联映射中,每一个字映射到多个cache行中。而对于组相联映射,每一个字映射到特定一组的所有cache 行中,于是,主存中的 B 0 B_0 B0块映射到第0组,如此等等。因此,组相联映射cache在物理上是使用了v个全关联映射的cache。同时,它也可看作为k个直接映射的cache的同时使用,如图4-13b所示。每一个直接映射的cache称为路,包括0个cache行。主存中首v个块分别映射到每路的v行中,接下来的v个块也是以同样的方式映射,后面也如此。直接映射一般应用于轻度关联(h 值较小)的情况,而全相联映射应用于高度关联的情况。
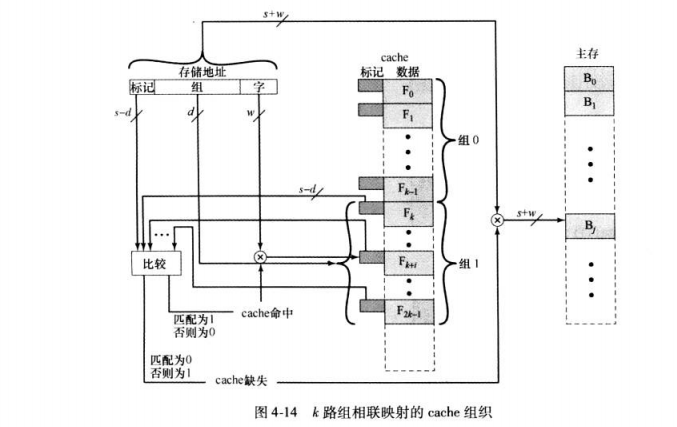

总结如下
地址长度=(s+w)位
可寻址的单元数= 2 s + w 2^{s+w} 2s+w个字或字节
块大小=行大小= 2 w 2^{w} 2w个字或字节
主存的块数= 2 s 2^{s} 2s
cache中每组的行数=k
组数= 2 d 2^d 2d
cache行数= m = k v = k × 2 k m=kv=k\times 2^k m=kv=k×2k
cache的容量= k × 2 k k\times 2^k k×2k个字或字节
标记长度=(s-d)位
例题
设某机内存容量为4MB,Cache的容量16KB,每块8个字,每个字32位.设计一个四路组相联映射(即Cache内每组包含4个字块)的Cache组织方式。
1)画出满足组相联映射的主存地址字段中各字段的位数
2)设Cache的初态为空,CPU从主存第0号单元开始连续访问100个字(主存一次读出一个字),重复此次序读8次,求存储访问的命中率
3)若Cache的速度是主存速度的6倍,求存储系统访问加速比
解
1)1️⃣ 获得地址长度:地址长度= log 2 ( 4 M B / 4 B ) = 20 b i t s \log_2(4MB/4B)=20bits log2(4MB/4B)=20bits
2️⃣ 获得cache行数和组数:
字地址长度= log 2 8 = 3 b i t s \log_2 8=3bits log28=3bits
行数= 16 K B / ( 8 × 4 B ) = 2 9 16KB/(8\times4B)=2^9 16KB/(8×4B)=29
对于四路组相联映射,每组有四行,所以组数地址长度=7bits
tag地址长度=20-7-3=1-bits
3️⃣ 画出地址表示图如下:
2)首先要明确一点:只有在第一遍访问时才会存在未命中情况,那么我们就需要计算第一次有多少个字没有命中。
当出现一次未命中时,主存就会把对应块上的数据传送到Cache中,那么我们只需要计算出第一遍遍历中主存向Cache传送了多少次数据,就可以得到未命中的次数.100个字需要100/8=13个块。那么第一遍便利的时候主存需要向Cache传送13次数据,也就是说有13次未命中。全部过程访问8x100=800次,未命中13次,则命中率为(800-13)/800=98.375%主存与CPU进行数据传输是以块为单位的
3)设主存存取周期为6t,那Cache存取周期就为t。
加速比就为:6t/(98% xt+2% x7t)=5.3(times)

例题:某32位计算机的Cache容量为16KB,Cache行的大小为16B,若主存与Cache地址映像采用直接映射方式,则主存地址为0x1234E8F8的单元装入Cache的地址为10100011111000。(二进制表示)
这里的32位指的是地址有32位,而不是一个字有32位
为了提高访问主存的速度,在CPU与主存之间增加一级Cache。根据题意,主存地址共32位,主存一个数据块调入Cache时使用直接映像方式,把主存按Cache容量分为若干区,主存某一数据块只能放在与Cache块号相同的数据块中,这样地址转换比较方便,由于Cache与主存的数据块大小是16B,块内地址需4位,Cache容量为16KB,故Cache可分为1024块,块地址需10位,除去这14位低位地址,主存地址高位18位,即主存分区号,作为字块标志也需要写入Cache数据块中。因此,装入Cache的地址编号为低14位数据即
10100011111000
题型六、cache与主存的替换算法
基于速度的考虑,我们使用硬件来实现替换算法
Least Recently used(LRU):最近最少使用的算法,替换掉那些在cache中最长时间未被访问的块。最经常使用。
对于两路组相联,这种方法很容易实现,每行包含一个USE位。当某行被引用时,其USE位被置为1,而这一组中另一行的USE位被置为0。当把块读入到这一组中时,就会替换掉USE位为0的行。由于我们假定越是最近使用的存储单元越有可能将被访问,因此,LRU会给出最佳的命中率。对于全相联cache, LRU也相对容易实现。高速缓存机制会为cache中的每行保留一个 单独的索引表。当某一行被访问时,它就会移动到表头,而在表尾的行将被替换掉
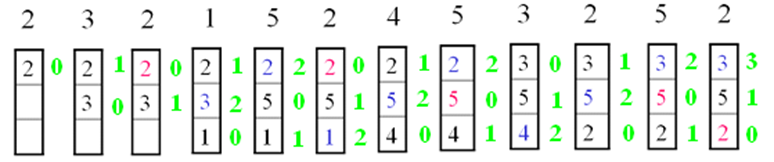
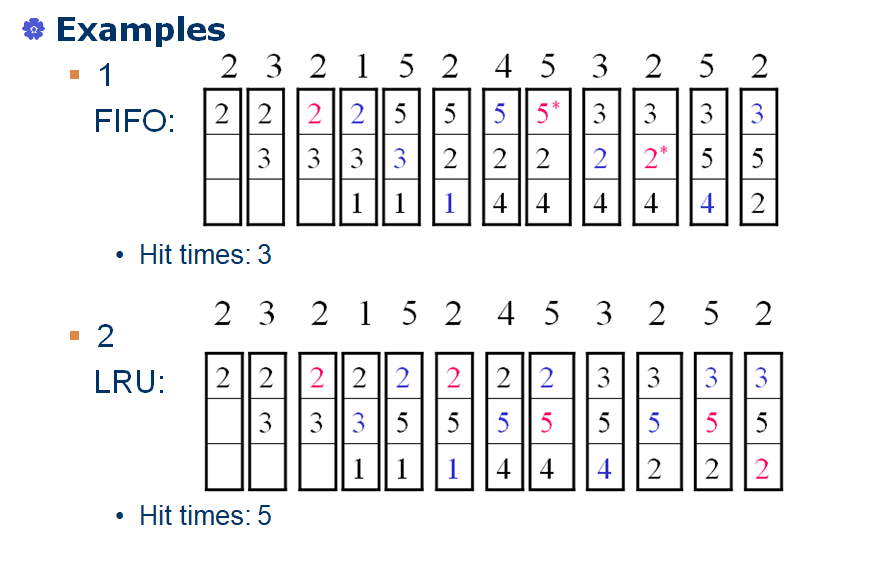
First in first out:先进先出,替换掉在cache中停留时间最长的块
Least frequently used:最不经常使用
Random:性能与LRU几乎差不多,没有用到访存的局部性原理,所以不能提高cache的命中率
题型七、存储器扩充
由于单片存储芯片的容量总是有限的,不可能满足实际的需要,一次必须将若干存储芯片连接在一起组成足够容量的存储器,这称为存储器的扩容。存储器容量的扩充有三类:位扩充、字扩充、字位扩充
求芯片数量
如果要求将容量为axb的芯片组成容量位cxd的芯片,假设需要芯片的数量为n,则 n = ( c × d ) / ( a × b ) n=(c\times d)/(a\times b) n=(c×d)/(a×b)
其中a,c连接的是地址线;b,d连接的是数据线
1️⃣ 1kx4 -> 1kx8 字长扩展(位扩展)
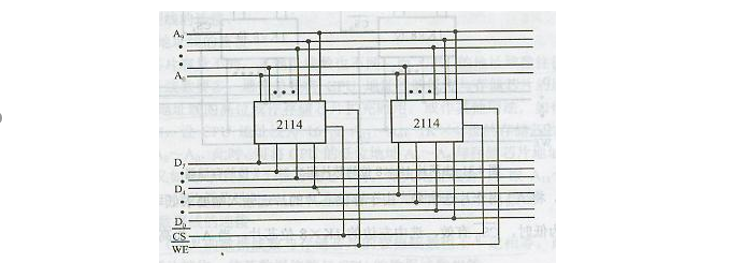
CS:选中信号端 A0~An:地址线 D0~Dn:数据线 WE读写信号线
图中的芯片进行了扩展,地址线不变,都是10位,数据线进行了扩展,由4位扩展成了8位
2️⃣ 1kx8-> 2kx8 字数扩展
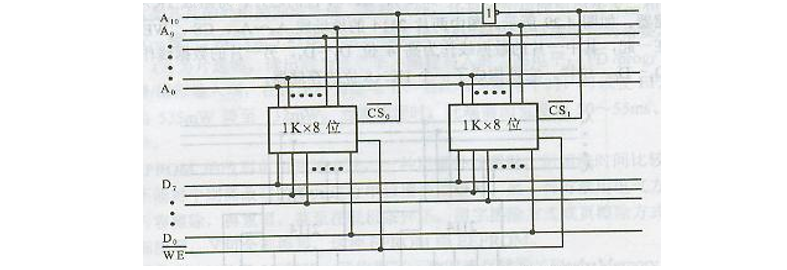
需要片选信号线区分不同的芯片,高位做片选比较方便
3️⃣ 1kx4-> 4kx8
先1kx4->1kx8再1kx8->4kx8
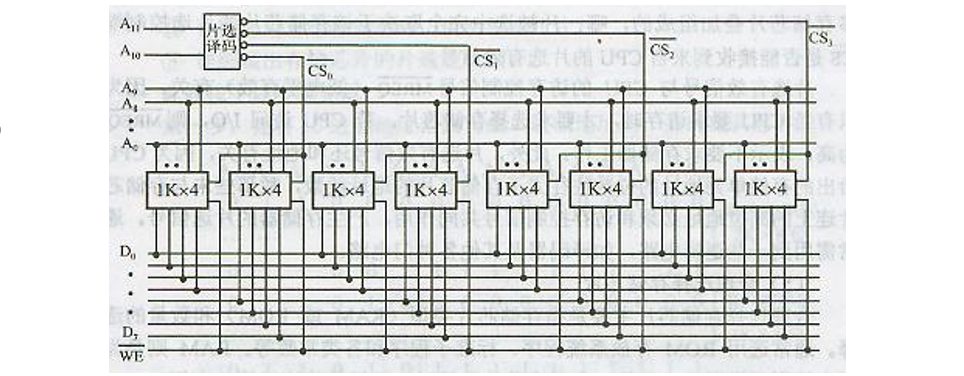
2-4译码器保证了每一次只有一个芯片有效
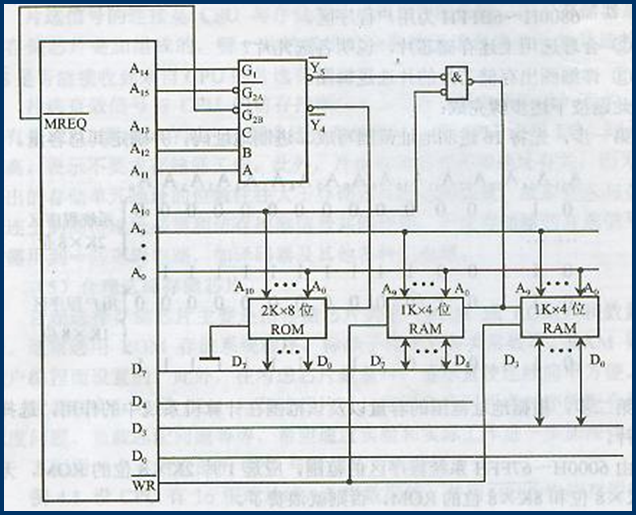
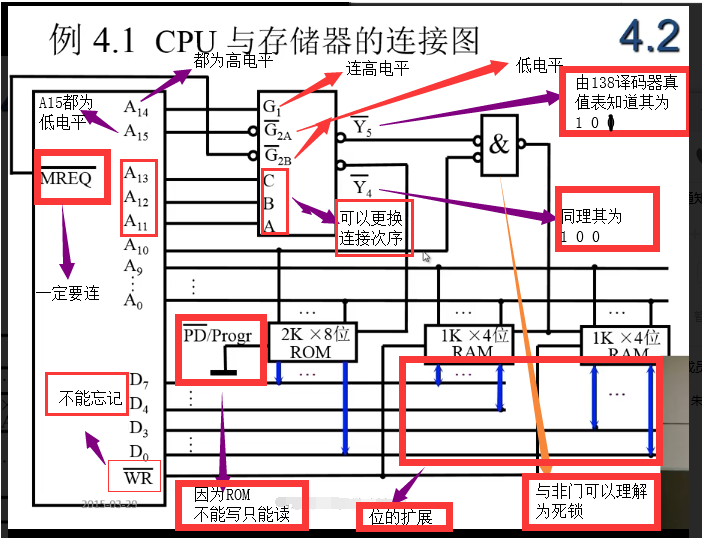
存储器与内存的连接
解题过程
1️⃣ 正确选择芯片类型和编号
ROM用于系统区域
RAM用于用户区域
2️⃣ 地址线连接
CPU 的地址行通常比内存的多
低位 = 低位
用于 CS 的高位
3️⃣ CPU 数据线连接
CPU 的数据线必须等于内存的数据位,如有必要,芯片位将放大
4️⃣ 连接命令线
读/写行与内存行直接连接 CS 与 MREQ 和 CPU 的高地址位相连 可使用逻辑电路,如解码器
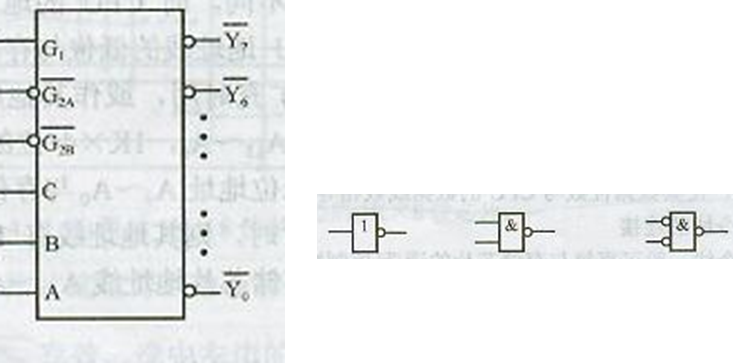
CPU-存储器举例
Suppose CPU has 16 address lines, 8 data lines. MREQ is used for access memory control, WR is read/write cont
•1Kx4 RAM; 4K x8 RAM; 8K x8 RAM;
•2K x8 ROM; 4K x8 ROM; 8K x8 ROM;
•74LS138 decoder and all kinds of gates, as figure.
•Please draw the diagram of CPU connecting memory, conditions:
6000H~67FFH is system area; 6800H~6BFFH is user area;
select reasonable chips, how many chips used, respectively?
rol. Now, we have following chips:


题型八、磁盘的性能指标计算
1、seek time寻道时间
寻道时间指的是移动磁盘臂所要求的磁道处所花费的时间
跨越时间不是线性的,还包括一个校正时间
2、rotational delay旋转延迟
这个是可估计的,磁盘恒定速率旋转
平均访问延迟:磁盘转半圈所用的时间
转速度量单位是转/分钟
3、transfer time传送时间
决定因素:传送文件的大小;旋转速度
公式: T = b r N T=\frac{b}{rN} T=rNb
T:传送时间 b:传送的字节数 N:每磁道的字节数 r:旋转速率,单位是转/秒
总的平均访问时间位:
T
a
=
T
s
+
1
2
r
+
b
r
N
T_a = T_s + \frac{1}{2r}+\frac{b}{rN}
Ta=Ts+2r1+rNb
T
s
T_s
Ts是平均寻道时间
举例:一张转速为15000转/分、平均寻道时间为4ms、512B/扇区、500扇区/磁道的磁盘,假设我们希望读取一个总大小为1.28MB、由2500个扇区组成的文件,估计访问的总时间。
情况1:序列组织。
情况2:数据随机分布

所以要使用顺序存取策略
题型九、I/O传输计算
假设一台计算机的CPU时钟频率为500Mhz,其CPI为5(意味着平均执行一条指令需要5个时钟周期)。中断模式下,I/O设备的数据传输速率为0.5 MB/s,传输单元为32位。中断服务程序包含18条指令,中断服务的其他开销相当于2条指令的执行时间。请回答:
1)在中断模式下,CPU用于I/O传输的时间与总CPU运行时间的比值是多少?
2)假设设备的数据传输速率为5MB/s,采用DMA模式传输5000B块的数据,DMA预处理和后处理的总成本为500个时钟周期。CPU用于I/O传输的时间占总CPU运行时间的比例是多少?(假设DMA和CPU之间没有内存访问冲突)。
解决方案:
中断模式
在每个中断中,CPU用于I/O传输的时间= 5×18+5×2=100个时钟周期。
在一秒钟,I/O设备传输0.5MB的数据和,需要中断次数= 0.5 MB / 32 = 0.5 MB / 4 B = 0.125 M。
中断成本=0.125M×100=12.5M时钟周期
所需比例= 12.5M/500M=2.5%
DMA模式
在每个DMA中,CPU用于I/O传输的时间=500个时钟周期。
在一秒钟,I/O设备传输5MB的数据和,需要DMA处理次数=5MB/5000B=1K。
DMA处理成本=1K×500=0.5M时钟周期
所需比例= 0.5M /500M=0.1%

解答
对于两个选择通道,任何时候只能选择一台设备传输数据,适用于高速设备,所以最多连接两个磁盘驱动器。而多路转换通道适用于低速设备。该系统的最大总I/O传输速率为800+800+6.6x2+1.2x2+1x10=1625.6 KB/s

解答
1️⃣ 编程式I/O以字为单位处理,假设时钟周期为 τ \tau τ
一秒内:能传输字的个数: 1 M B / s 32 b = 0.25 M \frac{1MB/s}{32b}=0.25M 32b1MB/s=0.25M
所耗费的I/O查询时间: 0.25 M × 100 τ = 25 M τ 0.25M\times 100\tau=25M\tau 0.25M×100τ=25Mτ
总的时钟周期为 50 M τ 50M\tau 50Mτ
CPU 用于 I/O 查询的时间比例: 25 M τ 50 M τ = 0.5 \frac{25M\tau}{50M\tau}=0.5 50Mτ25Mτ=0.5
2️⃣ 中断式I/O以字为单位处理,假设时钟周期为 τ \tau τ
一秒内:能传输字的个数: 1 M B / s 32 b = 0.25 M \frac{1MB/s}{32b}=0.25M 32b1MB/s=0.25M
所耗费的I/O查询时间: 0.25 M × 80 τ = 20 M τ 0.25M\times 80\tau=20M\tau 0.25M×80τ=20Mτ
总的时钟周期为 50 M τ 50M\tau 50Mτ
CPU 用于 I/O 查询的时间比例: 20 M τ 50 M τ = 0.4 \frac{20M\tau}{50M\tau}=0.4 50Mτ20Mτ=0.4
3️⃣ DMA以块为单位处理,假设时钟周期为 τ \tau τ
一秒内:能传输块的个数: 1 M B / s 4 k B = 2.5 × 1 0 − 4 M \frac{1MB/s}{4kB}=2.5\times 10^{-4}M 4kB1MB/s=2.5×10−4M
所耗DMA操作的时间: 2.5 × 1 0 − 4 × ( 1000 + 500 ) τ = 0.375 M τ 2.5\times 10^{-4} \times(1000+500)\tau=0.375M\tau 2.5×10−4×(1000+500)τ=0.375Mτ
总的时钟周期为 50 M τ 50M\tau 50Mτ
CPU 用于 I/O 查询的时间比例: 0.375 M τ 50 M τ = 0.0075 \frac{0.375M\tau}{50M\tau}=0.0075 50Mτ0.375Mτ=0.0075
题型十、指令流水线性能计算
流水线性能
指令流水线的周期
τ
\tau
τ,是在流水线中将一组指令推进一段所需的时间,表示公式如下(掌握定义):
τ
=
m
a
x
i
[
τ
i
]
+
d
=
τ
m
+
d
1
≤
i
≤
k
\tau=max_i[\tau_i]+d=\tau_m+d\qquad 1\le i\le k
τ=maxi[τi]+d=τm+d1≤i≤k
其中:
τ i = 流 水 线 第 i 段 的 电 路 延 迟 时 间 \tau_i=流水线第i段的电路延迟时间 τi=流水线第i段的电路延迟时间
τ m = 最 大 段 延 迟 \tau_m=最大段延迟 τm=最大段延迟
k = 指 令 流 水 段 数 k=指令流水段数 k=指令流水段数
d = 锁 存 延 时 d=锁存延时 d=锁存延时
通常延时d等于时钟脉冲的宽度而且 τ m > > d \tau_m>>d τm>>d
假设现有n条指令在进行,无转移发生,令
T
k
,
n
T_{k,n}
Tk,n为k阶段流水线执行所有n条指令所需的总时间,则有:
T
k
,
n
=
[
k
+
(
n
−
1
)
]
τ
T_{k,n}=[k+(n-1)]\tau
Tk,n=[k+(n−1)]τ
提速比
s
k
=
n
k
τ
[
k
+
(
n
−
1
)
]
τ
=
n
k
k
+
(
n
−
1
)
s_k=\frac{nk\tau}{[k+(n-1)]\tau}=\frac{nk}{k+(n-1)}
sk=[k+(n−1)]τnkτ=k+(n−1)nk
吞吐率
T
p
T_p
Tp:流水线单位时间内产生的指令数(掌握定义)
T
p
=
n
[
k
+
(
n
−
1
)
]
τ
T_p=\frac{n}{[k+(n-1)]\tau}
Tp=[k+(n−1)]τn
T p m a x = 1 τ T_{pmax}=\frac{1}{\tau} Tpmax=τ1
n > > k , T p ≈ T p m a x n>>k,T_p\thickapprox T_{pmax} n>>k,Tp≈Tpmax
举例
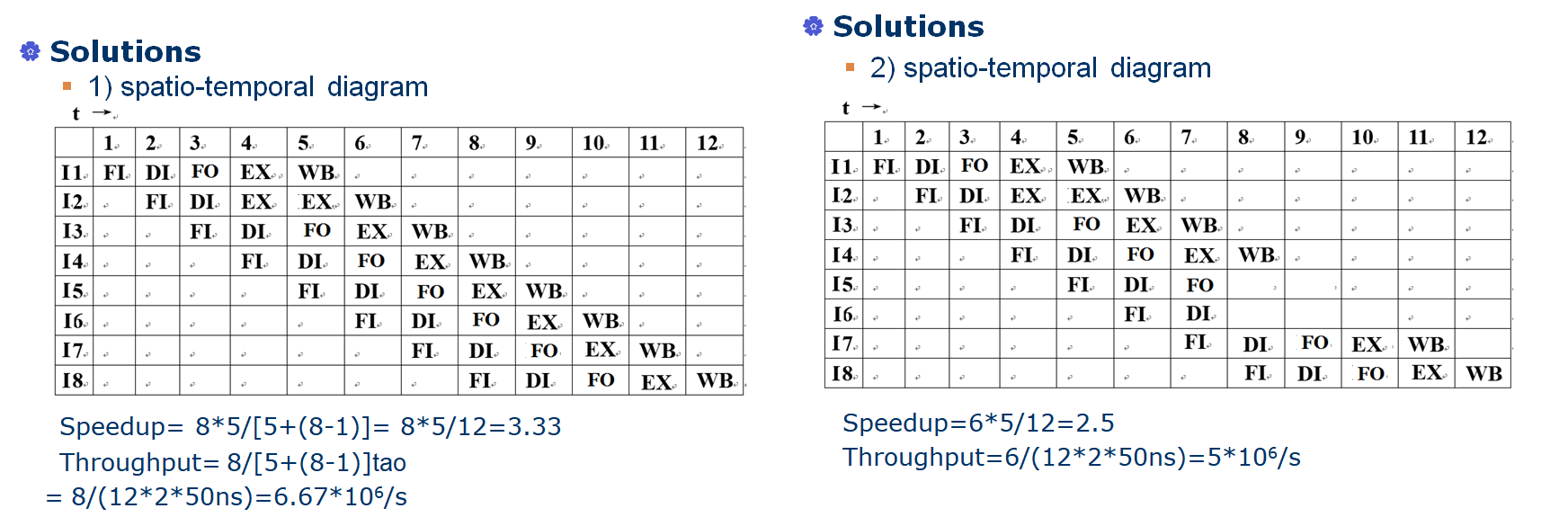
考虑一个时钟周期为50ns的单流水线处理器有5个流水线阶段:FI、DI、FO、EX和WB。假设每个阶段的持续时间相等,需要2个时钟周期。它需要执行8个连续指令。
绘制流水线各功能阶段时序图,计算提速和吞吐量。假设在执行指令期间没有冲突、依赖或分支。
如果指令4是一个条件转移指令,并且转移的目标是指令7。在此执行中,结果是进行分支。绘制流水线各功能阶段时序图,计算提速和吞吐量。假设在指令8之后,没有其他指令要执行。
题型十一、指令周期的微操作描述
取指周期
涉及的微操作
1️⃣ 从PC中取出要执行指令的地址送到MAR
2️⃣ MAR将地址送到地址总线
3️⃣ 控制单元CU向内存发送读命令Read信号,启动内存读操作
4️⃣ 内存将读到的结果放到数据总线上,并复制到 MBR
5️⃣ 将MBR中的内容再传送给IR,MBR变得空闲,可继续为之后的数据存取服务
6️⃣ 同时 PC +x
x表示指令的长度
此操作可和从内存中读指令同步进行
符号化表示

微操作的分组必须遵守下面两个简单的原则:
1️⃣ 事件的流动顺序必须是恰当的。于是,(MAR←(PC))必须先于(MBR←内存),因为内存读操作要使用MAR中的地址。
2️⃣ 必须避免冲突。不要试图在一个时间单位里去读、写同-一个寄存器,否则结果是不可预料的。例如,(MBR←内存)和(IR←MBR)这两个微操作不应出现在同一时间单位里。
间接周期
取到指令以后,下一步就是取源操作数,若指令是间接寻址,则存在一个间接周期
t 1 : M A R ← ( I R a d d r e s s ) − a d d r e s s f i e l d o f I R t_1: MAR ←(IR_{address}) - address\ field\ of\ IR t1:MAR←(IRaddress)−address field of IR
t 2 : R ← 1 ( 发 读 命 令 ) , M B R ← ( m e m o r y ) t_2: R ← 1(发读命令), MBR ← (memory) t2:R←1(发读命令),MBR←(memory)
t 3 : I R a d d r e s s ← M B R t_3: IR_{address} ← MBR t3:IRaddress←MBR
原本IR存的是间接地址,经过间接周期,存的就是直接地址
中断周期
t1: MBR ← (PC)
t2: MAR ← 保存断点的内存地址
PC ← 中断服务程序首地址
t3: W ← 1, memory ← (MBR) //MBR相当于常用的temp变量
⚠️ 注意,保存各个通用寄存器的内容是由中断处理程序做的,不属于中断周期的微操作,中断周期结束,CPU就为执行中断服务程序中的指令做好了准备
执行周期
首先考虑ADD R1,X,它将存储器X的内容加到寄存器R1,该加法指令可能产生如下的微操作序列:
$t_1: MAR ←(IR_{address}) $
t 2 : R ← 1 , M B R ← ( m e m o r y ) t_2: R ← 1, MBR ← (memory) t2:R←1,MBR←(memory)
t 3 : R 1 ← R 1 + ( M B R ) t_3: R_1 ← R_1+(MBR) t3:R1←R1+(MBR)
再来看更复杂的ISZ X(自增,如果结果为0则跳步),表示先对内存地址为X的内容加1,再将结果存入X地址,同时如果此结果为0,则跳过下一条指令,继续从第三条指令执行
$t_1: MAR ←(IR_{address}) $
t 2 : R ← 1 , M B R ← ( m e m o r y ) t_2: R ← 1, MBR ← (memory) t2:R←1,MBR←(memory)
t 3 : M B R ← 1 + ( M B R ) t_3: MBR ← 1+(MBR) t3:MBR←1+(MBR)
t 4 : W ← 1 ( 发 送 写 命 令 ) , m e m o r y ← ( M B R ) t_4: W \leftarrow 1(发送写命令),memory \leftarrow (MBR) t4:W←1(发送写命令),memory←(MBR)
i f ( M B R ) = = 0 t h e n P C ← ( P C ) + I if(MBR)==0\ then\ PC \leftarrow (PC)+I if(MBR)==0 then PC←(PC)+I
最后来看子程序调用指令,转移并保存地址指令BSA X
把BSA指令后下一指令地址存入地址为X的内存地址,同时程序从X+I处开始继续执行,用于子程序调用
$t_1: MAR ←(IR_{address}) $
M B R ← ( P C ) MBR \leftarrow (PC) MBR←(PC)t 2 : W ← 1 , ( m e m o r y ) ← ( M B R ) t_2: W ← 1, (memory) ← (MBR) t2:W←1,(memory)←(MBR)
P C ← ( I R a d d r e s s ) PC \leftarrow (IR_{address}) PC←(IRaddress)t 3 : P C ← ( P C ) + I t_3: PC ← (PC)+I t3:PC←(PC)+I
指令开始时PC中的地址是下一条指令的地址,他被保存在IR指定的地址位置中,此后,PC中的地址也递增1,以提供下一指令周期的指令地址


















 2125
2125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











