







带误差线的条图
当直条用于显示样本统计量时,往往需要加绘相应指标的可信区间。
seaborn.barplot(
x, y, hue : names of variables in data
data : DataFrame
order, hue_order : 分类变量/hue变量各类别取值的绘图顺序
可信区间计算:
ci = 95 : float or “sd” or None, 希望绘制的可信区间宽度
n_boot = 1000 : 计算CI时的bootstrap抽样次数。
units : 用于确定抽样单元大小的变量。
误差条格式:
errcolor = ‘0.26’ : CI线段的颜色,matplotlib color
errwidth : CI线段的粗细,float
capsize : 误差条顶端的宽度,占直条绘图区的比例,float
)
sns.barplot(x = ccss.s4, y = ccss.s3)
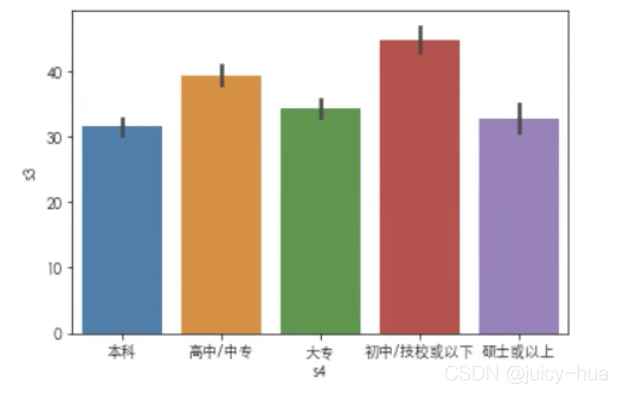
sns.barplot(x = ccss.s4, y = ccss.s3, color = 'c',
errcolor = 'b', errwidth = '2', capsize = .1)

# 如何不绘制CI
sns.barplot(x = ccss.s4, y = ccss.s3, ci = None)
plt.xlabel("S4:教育程度")
plt.ylabel("S3:年龄均值")

用直条表示中位数、标准差等特殊统计量
https://docs.scipy.org/doc/numpy-1.14.5/reference/routines.statistics.html
import numpy as np
sns.barplot(x = ccss.s4, y = ccss.s3, estimator = np.median)

sns.barplot(x = ccss.s4, y = ccss.s3, estimator = np.std)

分组条图
sns.barplot(x = ccss.s4, y = ccss.s3, hue = ccss.s2)

# 存在嵌套分组
sns.barplot(x = ccss.Qs9, y = ccss.s3, hue = ccss.Ts9)

# 存在嵌套分组时不调整直条宽度
sns.barplot(x = ccss.Qs9, y = ccss.s3, hue = ccss.Ts9, dodge = False)

堆积条图
堆积条图在matplotlib中没有命令直接实现,但可以通过重叠作图方式加以绘制:
方法一:先绘制全部类别的的累积直条,然后依次绘制n-1、n-2…个类别的累积直条,最终形成堆积条图的效果。
方法二:利用plt.plot()的bottom参数,依次将新类别的直条叠加在已有直条上方。
上述方法二更常用,且结合Pandas的汇总功能和seabon模块的绘图功能,实现堆积条图已经非常方便。
# 利用Pandas的汇总功能生成所需汇总数据
tmpdf = pd.crosstab(index = ccss.s0, columns = ccss.s4)
tmpdf

# 取出所需的汇总行
tmpdf.loc[['上海']]

# 取出所需的汇总行(序列格式)
tmpdf.loc['上海']

# 分三次使用seaborn绘制三个类别的直条,并依次叠加
sns.barplot(data = tmpdf.loc[['上海']], color = 'b', label = '上海')
sns.barplot(data = tmpdf.loc[['北京']], bottom = tmpdf.loc['上海'],
color = 'c', label = '北京')
# 注意bottom参数需要累加已有的所有直条类别高度
sns.barplot(data = tmpdf.loc[['广州']],
bottom = tmpdf.loc['北京'] + tmpdf.loc['上海'],
color = 'y', label = '广州')
plt.legend()

# 使用循环程序自动生成图形
tmpdf = pd.crosstab(index = ccss.s0, columns = ccss.s4)
colorstep0 = 1/len(tmpdf.index)
for i in range(len(tmpdf.index)):
if i == 0:
colorstep = colorstep0 / 2 # 避免最终出现纯白色直条
sns.barplot(data = tmpdf.loc[[tmpdf.index[i]]],
color = str(colorstep), label = tmpdf.index[i])
base = tmpdf.loc[tmpdf.index[i]]
else:
sns.barplot(data = tmpdf.loc[[tmpdf.index[i]]],
color = str(colorstep), bottom = base,
label = tmpdf.index[i])
base = base + tmpdf.loc[tmpdf.index[i]]
colorstep = colorstep + colorstep0
plt.legend()

# 使用sns.histplot()近似绘制堆积条图(实际上是堆积直方图)
# 但是该函数无法指定order或者row_order参数(因为不存在真正的分类轴)
sns.histplot(data = ccss, x = 's4', hue = 's0', multiple="stack",
hue_order = ['广州', '上海', '北京'])

百分条图
基本绘制思路和堆积条图相同,但需要将数据计算为相应的百分比。
python中没有为多选题专门提供分析/绘图功能,需要自行完成所需指标的汇总计算。
pd.crosstab(index = ccss.s0, columns = ccss.s4, normalize = "columns")

tmpdf = pd.crosstab(index = ccss.s0, columns = ccss.s4,
normalize = "columns")
colorstep0 = 1/len(tmpdf.index)
for i in range(len(tmpdf.index)):
if i == 0:
colorstep = colorstep0 / 2
sns.barplot(data = tmpdf.loc[[tmpdf.index[i]]],
color = str(colorstep), label = tmpdf.index[i])
base = tmpdf.loc[tmpdf.index[i]]
else:
sns.barplot(data = tmpdf.loc[[tmpdf.index[i]]],
color = str(colorstep), bottom = base,
label = tmpdf.index[i])
base = base + tmpdf.loc[tmpdf.index[i]]
colorstep = colorstep + colorstep0
plt.legend()

# 使用sns.histplot()近似绘制百分条图(实际上是百分直方图)
# 但是该函数无法指定order或者row_order参数(因为不存在真正的分类轴)
sns.histplot(data = ccss, x = 's4', hue = 's0', multiple="fill",
hue_order = ['广州', '上海', '北京'])

















 732
732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











