







2022年8月12日起,由Magic Data、好未来、清华大学、中国科学院声学研究所主办联合主办的 “Magichub中英混ASR挑战赛” 自开展以来,已经收到三十多支国内外研究机构、知名企业及高校的参赛队伍注册报名,包括 荔枝FM、特斯联、网易游戏、中移在线、中科院、华中科技大学、中国科学技术大学、西北工业大学、厦门大学、天津大学等。8月24日,主办方正式向参赛队伍开放开发训练集和基线系统。
报名持续进行中
www.magichub.com/join-competition
开发训练集
主办方开放了以下训练与开发数据集:
1、MagicData-RAMC 包括351组多轮普通话对话,时长共计180小时。每组对话的标注信息包括转录文本、语音活动时间戳、说话人信息、录制信息和话题信息。说话人信息包括了性别、年龄和地域,录制信息包括了环境和设备。请参赛者查看邮件进行数据集下载。
2、TAL_CSASR中英文混合语音数据集,为好未来英语课授课音频,时长共计587小时。包含中英文混合讲话的情况,每条音频只有一位说话人,共包括超过200名说话人。请参赛者查看邮件进行数据集下载。
3、开发集(Dev),包含14名说话人,总时长约6.8小时。
所有参与者都应遵守以下规则:
1. DATA:只允许使用MagicData-RAMC 和 TAL_CSASR。数据增强可以使用两个噪声数据集,即 MUSAN(openslr17), RIRNoise (openslr 28)。
2. 严禁以任何形式使用测试集,包括但不限于使用测试数据集对模型进行微调或训练。
3.允许多系统融合。然而不鼓励使用具有相同结构的系统进行融合。
4. 所有模型都应在允许的数据集上进行训练。具体来说,预训练模型不允许使用其他数据集(包括未标记的数据)。
5、最终解释权归主办方所有。
基线系统介绍
为了帮助参赛者评估系统性能,主办方提供了基线系统性能供参赛者参考。该系统采用Transformer模型,基于ETEH平台开发。
具体信息请见:
GitHub - MagicHub-io/CSASR_Challenge
打分工具
使用开源的打分工具Sclite进行打分。评分指标采用混合错误率(Mixed Error Rate, MER),即对中文计算字错误率、对英文计算词错误率。
打分样例请见 :
https://github.com/MagicHub-io/CSASR_Challenge/blob/main/dev_scoring_sclite.sh
基线系统答疑指导
对基线系统有任何疑问,请访问以下链接获取帮助,将有专家团队给予解答。
答疑直通车:
https://github.com/MagicHub-io/CSASR_Challenge#contact
奖项设置
比赛分别设置一等奖、二等奖和三等奖,将评选出三组获奖团队/个人,获奖者将有机会参加国际及国内顶会的现场演示及交流活动。
一等奖 1名:华为Watch+阿噗筋膜枪(价值3000元)+获奖证书
二等奖 2名:Magic Data锦鲤大礼包+好未来&凌美联名钢笔礼盒(价值1500元)+获奖证书
三等奖 3名:Magic Data定制礼品+阿噗体重秤(价值500元)+获奖证书
赛程设置

竞赛组委会支持团队
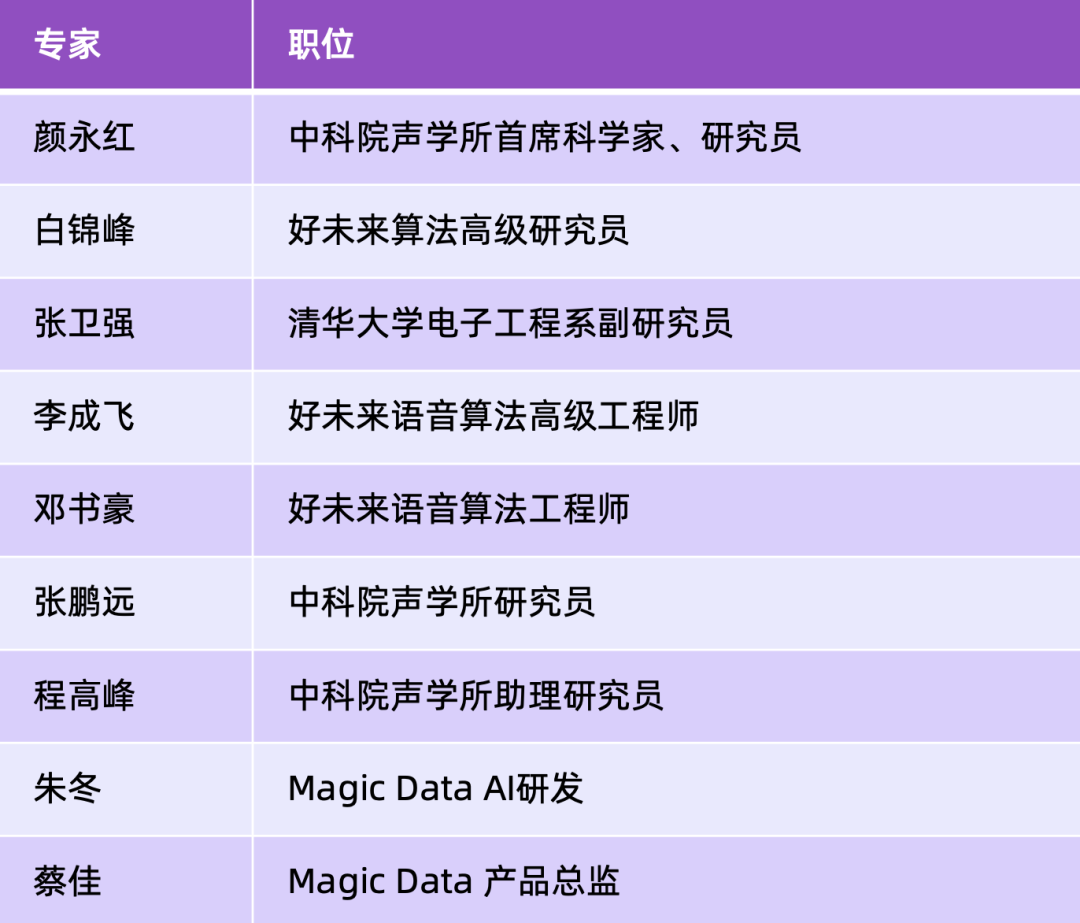
挑战赛相关问题,可请发送邮件至 open@magicdatatech.com,邮件标题为“中英混ASR挑战赛疑问”。疑问将由以下组委会资深技术专家提供专业技术问答和指导。指导专家均在语音领域深耕多年,有着丰富研究和实战经验,相信参赛者们在他们的指导下能够得到启发与收获。
报名方式
报名地址:www.magichub.com/join-competition
参赛人数:每队参赛人数4人以内 (含4人)
更多详情:www.magichub.com














 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









