







一、锁的分类
1.1 可重入锁、不可重入锁
重入:当前线程获取到A锁,在获取之后尝试再次获取A锁是可以直接拿到的
不可重入:当前线程获取到A锁,在获取之后尝试获取A锁,无法获取到的,因为A锁被当前线程占用着,需要等待自己释放锁在获取锁。
1.2 乐观锁、悲观锁
Java中提供的synchronized、ReentrantLock、ReentrantReadWriteLock都是悲观锁
Java中提供的CAS操作,就是乐观锁的一种实现
悲观锁:获取不到锁资源时,会将当前线程挂起(进入BLOCKED、WAITING),线程挂起会涉及到用户态和内核态的切换。而这种切换是比较消耗资源的
- 用户态:JVM可以自行执行的指令,不需要借助操作系统执行
- 内核态:JVM不可以自行执行,需要操作系统才可以执行
乐观锁:获取不到锁资源、可以再次让CPU调度,重新尝试获取锁资源
Atomic原子性类中,就是基于CAS乐观锁实现的
1.3 公平锁、非公平锁
Java提供的synchronized只能是非公平锁
Java中提供的ReentrantLock、ReentrantReadWriteLock可以实现公平锁和非公平锁
公平锁:线程A获取到了锁资源。线程B没有拿到,线程B去排队,线程C来了,锁被A持有,同时线程B在排队。直接排队B的后面,等待B拿到锁资源或者是B取消后,才可以尝试去竞争锁资源
非公平锁:线程A拿到了锁资源,线程B没有拿到,线程B去排队,线程C来了,先尝试竞争一波
- 拿到锁资源:插队成功
- 没有拿到锁资源:依然排到B的后面,等待B拿到锁资源或者是B取消后,才可以尝试去竞争锁资源
1.4 互斥锁、共享锁
Java提供了synchronized、ReentrantLock是互斥锁
Java提供的ReentrantReadWriteLock,有互斥锁也有共享锁
互斥锁:同一时间点、只会有个线程持有者当前互斥锁。
共享锁:同一个时间点,当前共享锁可以被多个线程同时持有
二、深入synchronized
2.1 类锁、对象锁
synchronized的使用一般就是同步方法和同步代码块
synchronized的锁是基于对象实现的
如果使用同步方法
- static:此时使用的当前类.class作为锁(类锁)
- 非static:此时使用的是当前对象作为锁(对象锁)
public class SyncITest {
public static void main (String[] args) {
// 锁的是TSync.class 类锁
TSync.a();
TSync tSync = new TSync();
// 锁的是tSync对象,对象锁
tSync.b();
}
}
class TSync {
public static synchronized void a(){
System.out.println("hello word");
}
public synchronized void b(){
System.out.println("hello word");
}
}
2.2 synchronized的优化
在JDK1.5的时候,Doug Lee 推出了ReentratLock,lock的性能远高于synchronized,所以JDK团队在JDK1.6中,对synchronized做了大量的优化
锁消除: 在synchronized修饰的代码中,如果不存咋操作临界资源的情况,会触发锁消除,即便写了synchronized,也不会触发
public synchronized void method(){
// 没有操作临界资源
// 此时这个方法的synchronized你可以认为木有~~
}
锁膨胀: 如果在一个循环中,频繁的获取和释放锁资源,这样带来的消耗很大,锁膨胀就是锁的范围扩大,避免频繁的竞争和获取锁资源带来不必要的消耗
public void method(){
for(int i = 0;i < 999999;i++){
synchronized(对象){
}
}
// 这是上面的代码会触发锁膨胀
synchronized(对象){
for(int i = 0;i < 999999;i++){
}
}
}
**锁升级:**ReentrantLock的实现,是先基于乐观锁的CAS尝试获取锁资源,如果拿不到锁资源,才会挂起线程,synchronized在JDK1.6之前,完全就是获取不到锁,立即挂起当前线程,所以synchronized性能比较差
synchronized就在JDK1.6做了锁升价的优化
- 无锁、匿名偏向:当前对象没有作为锁存在。
- 偏向锁:如果当前锁资源,只有一个线程在频繁的获取和释放,那么这个线程过来,只需要判断,当前指向的线程是否是当前线程。
- 如果是,直接拿锁资源走
- 如果当前线程不是我,基于CAS的方式,尝试将偏向锁指向当前线程,如果获取不到,触发锁升级,升级为轻量级锁,(偏向锁状态出现了锁竞争的情况)
- 轻量级锁:会采用自旋锁的方式频繁的以CAS的方式获取锁资源(采用的是自适应自旋锁)
- 如果成功获取到,拿着锁资源走
- 如果自旋了一定次数,没拿到锁资源,锁升级
- 重量级锁:就是最传统的synchronized方式,拿不到锁资源,就挂起当前线程。(用户态&内核态)
2.3 synchronized实现原理
synchronized是基于对象实现的
先要对Java中的对象在堆内存的存储有一个了解
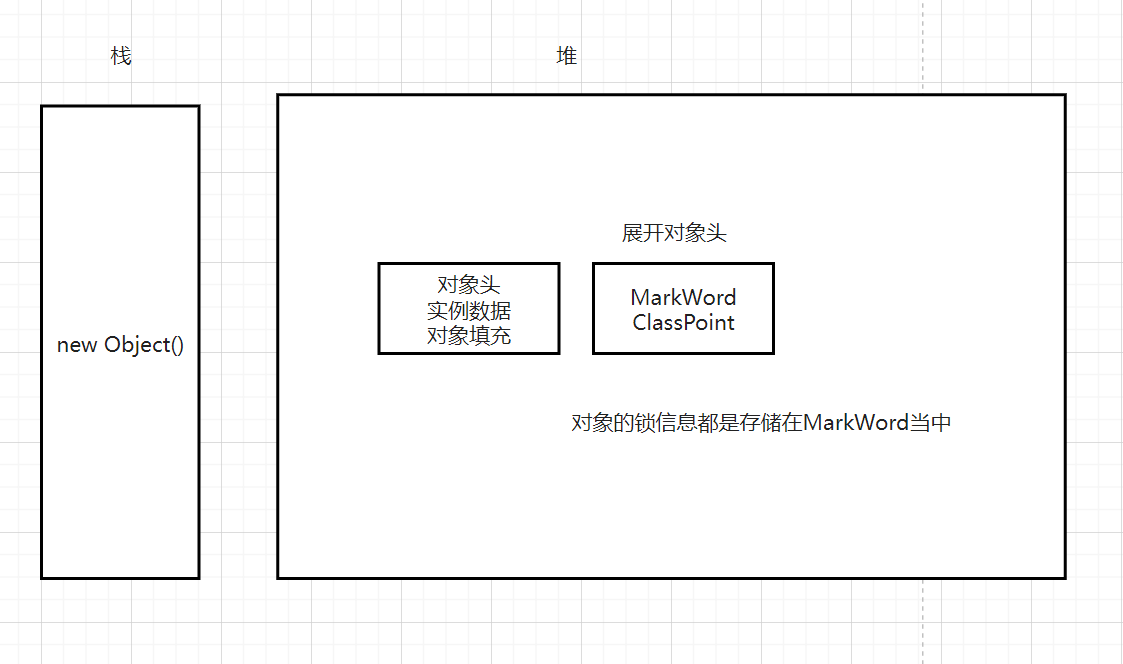
MarkWord
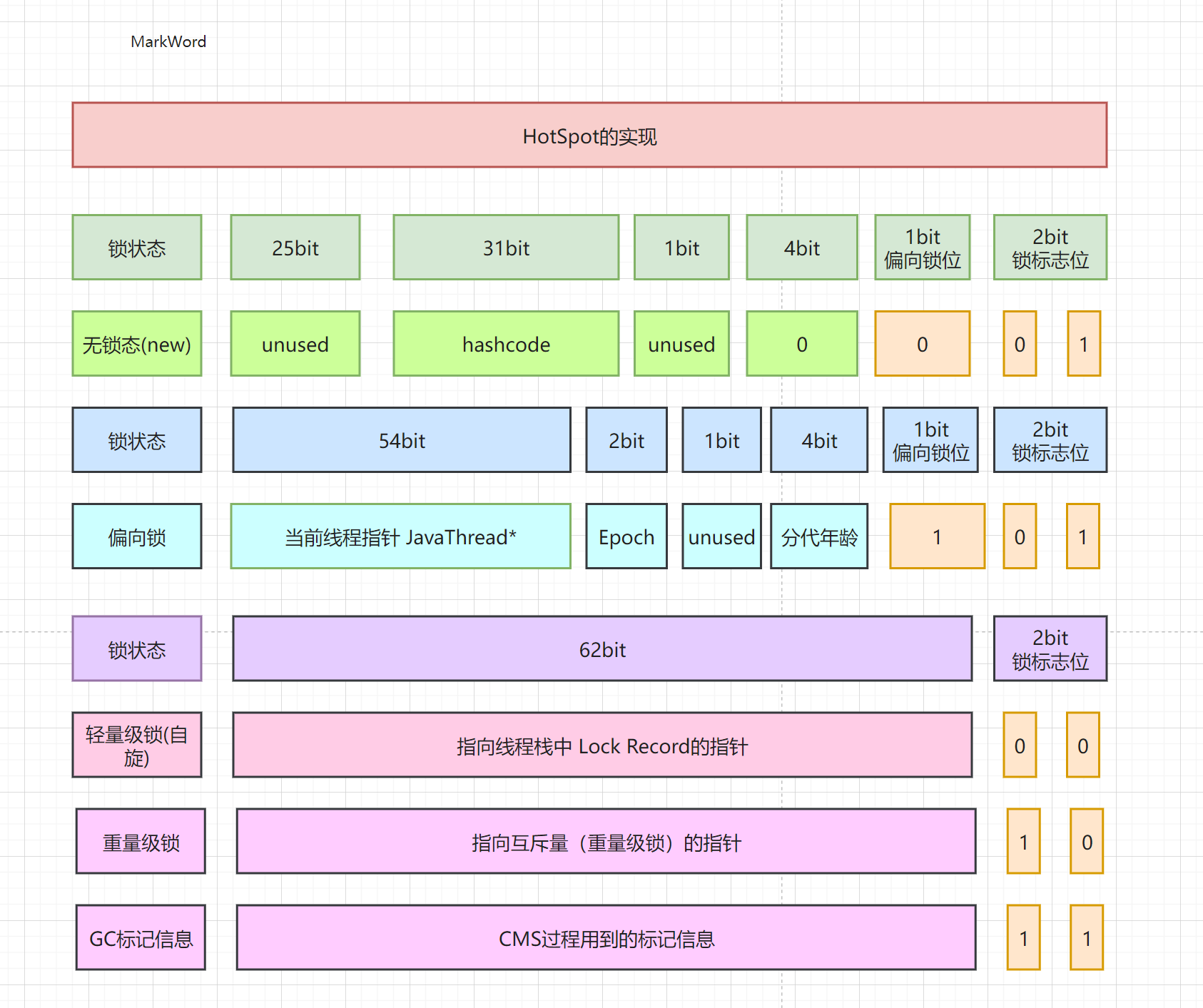
MarkWord中标记着四种锁的信息
- 无锁 : 偏向锁一位 0,锁标记两位 0 1,0 0 1
- 偏向锁:偏向锁一位 1,锁标记两位 0 1,1 0 1
- 轻量级锁:锁标记两位 0 0
- 重量级锁:锁标记两位 1 0
2.4 synchronized的锁升级
为了可以在Java中看到对象头的MarkWord信息,需要导入依赖
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
锁默认情况下,开启了偏向锁延迟
偏向锁在升级位轻量级锁时,会涉及到偏向锁撤销,需要等到一个安全的(STW),才可以做偏向锁撤销,在明知道有并发情况,就可以选择不开启偏向锁,或者是设置偏向锁延迟开启
因为JVM启动时,需要加载大量的.class文件到内存中,这个操作会涉及到synchronized的使用,为了避免出现偏向锁撤销操作,JVM启动初期,有一个延迟4s开启偏向锁的操作
如果正常开启偏向锁了,那么会出现无锁状态,对象会直接变为匿名偏向
public class MarkWord {
public static void main (String[] args) throws Exception {
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
Thread.sleep(5000);
System.out.println(ClassLayout.parseInstance(o).toPrintable());
new Thread(() -> {
synchronized (o) {
// 偏向锁
System.out.println(Thread.currentThread().getName() + ": ");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}).start();
// mian - 偏向锁 - 轻量级锁CAS - 重量级锁
synchronized (o) {
// 偏向锁
System.out.println(Thread.currentThread().getName() + ": ");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
// java.lang.Object object internals:
// OFFSET SIZE TYPE DESCRIPTION VALUE
// 0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
// 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
// 8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
// 12 4 (loss due to the next object alignment)
// Instance size: 16 bytes
// Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
//
// java.lang.Object object internals:
// OFFSET SIZE TYPE DESCRIPTION VALUE
// 0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
// 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
// 8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
// 12 4 (loss due to the next object alignment)
// Instance size: 16 bytes
// Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
//
// main:
// java.lang.Object object internals:
// OFFSET SIZE TYPE DESCRIPTION VALUE
// 0 4 (object header) 05 08 15 dd (00000101 00001000 00010101 11011101) (-585824251)
// 4 4 (object header) 54 02 00 00 (01010100 00000010 00000000 00000000) (596)
// 8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
// 12 4 (loss due to the next object alignment)
// Instance size: 16 bytes
// Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
//
// Thread-0:
// java.lang.Object object internals:
// OFFSET SIZE TYPE DESCRIPTION VALUE
// 0 4 (object header) 02 79 e2 8a (00000010 01111001 11100010 10001010) (-1964869374)
// 4 4 (object header) 54 02 00 00 (01010100 00000010 00000000 00000000) (596)
// 8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
// 12 4 (loss due to the next object alignment)
// Instance size: 16 bytes
// Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
}
Lock Record以及ObjectMonitor存储的内容
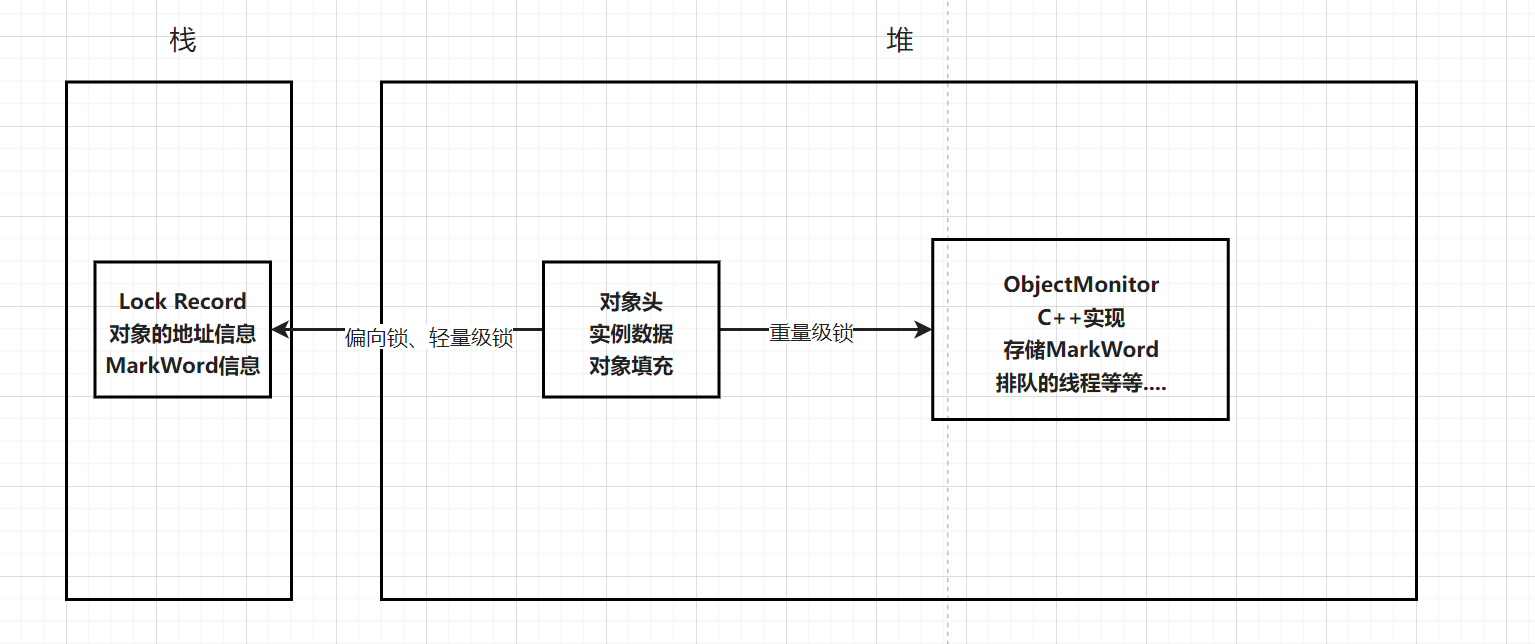
2.5 重量级锁底层ObjectMonitor
需要去找到openjdk,在百度中直接搜索openjdk即可
找到ObjectMonitor的两个文件,hpp,cpp
先查看核心属性:https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/69087d08d473/src/share/vm/runtime/objectMonitor.hpp
ObjectMonitor() {
_header = NULL; // header存储着MarkWord
_count = 0; // 竞争锁的线程个数
_waiters = 0, // wait的线程个数
_recursions = 0; // 标识当前synchronized锁重入的次数
_object = NULL;
_owner = NULL; // 持有锁的线程
_WaitSet = NULL; // 保存wait的线程信息,双向链表
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; // 获取锁资源失败后,线程要放到当前的单向链表中
FreeNext = NULL ;
_EntryList = NULL ; // _cxq以及被唤醒的WaitSet中的线程,在一定机制下,会放到EntryList中
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
简单查看几个C++中实现的加锁流程
TryLock
int ObjectMonitor::TryLock (Thread * Self) {
for (;;) {
// 拿到持有锁的线程
void * own = _owner ;
// 如果有线程持有锁,结束
if (own != NULL) return 0 ;
// 说明没有线程持有锁,own是null,cmpxchg指令就是底层的CAS实现
if (Atomic::cmpxchg_ptr (Self, &_owner, NULL) == NULL) {
// 成功获取锁资源
return 1 ;
}
// 重试没有多大意义,因为锁刚刚被获取,返回-1
if (true) return -1 ;
}
}
try_enter
bool ObjectMonitor::try_enter(Thread* THREAD) {
// 在判断_owner是不是当前线程
if (THREAD != _owner) {
// 判断当前持有锁的线程是否是当前线程,说明轻量级锁刚刚升级过来的情况
if (THREAD->is_lock_owned ((address)_owner)) {
_owner = THREAD ;
_recursions = 1 ;
OwnerIsThread = 1 ;
return true;
}
// CAS操作,尝试获取锁资源
if (Atomic::cmpxchg_ptr (THREAD, &_owner, NULL) != NULL) {
// 没拿到锁资源,结束
return false;
}
// 拿到锁资源
return true;
} else {
// _recursions+1,代表锁重入操作
_recursions++;
return true;
}
}
enter(想方设法拿到锁资源,如果没拿到,挂起扔到_cxq单向链表中)
void ATTR ObjectMonitor::enter(TRAPS) {
// 拿到当前线程
Thread * const Self = THREAD ;
void * cur ;
// cas尝试获取到锁
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
if (cur == NULL) {
// 获取锁成功
return ;
}
// 锁重入操作
if (cur == Self) {
// TODO-FIXME: check for integer overflow! BUGID 6557169.
_recursions ++ ;
return ;
}
// 轻量级锁
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
_recursions = 1 ;
// Commute owner from a thread-specific on-stack BasicLockObject address to
// a full-fledged "Thread *".
_owner = Self ;
OwnerIsThread = 1 ;
return ;
}
// We've encountered genuine contention.
assert (Self->_Stalled == 0, "invariant") ;
Self->_Stalled = intptr_t(this) ;
// Try one round of spinning *before* enqueueing Self
// and before going through the awkward and expensive state
// transitions. The following spin is strictly optional ...
// Note that if we acquire the monitor from an initial spin
// we forgo posting JVMTI events and firing DTRACE probes.
if (Knob_SpinEarly && TrySpin (Self) > 0) {
assert (_owner == Self , "invariant") ;
assert (_recursions == 0 , "invariant") ;
assert (((oop)(object()))->mark() == markOopDesc::encode(this), "invariant") ;
Self->_Stalled = 0 ;
return ;
}
assert (_owner != Self , "invariant") ;
assert (_succ != Self , "invariant") ;
assert (Self->is_Java_thread() , "invariant") ;
JavaThread * jt = (JavaThread *) Self ;
assert (!SafepointSynchronize::is_at_safepoint(), "invariant") ;
assert (jt->thread_state() != _thread_blocked , "invariant") ;
assert (this->object() != NULL , "invariant") ;
assert (_count >= 0, "invariant") ;
// Prevent deflation at STW-time. See deflate_idle_monitors() and is_busy().
// Ensure the object-monitor relationship remains stable while there's contention.
// 走到这里,没拿到锁资源,count++
Atomic::inc_ptr(&_count);
JFR_ONLY(JfrConditionalFlushWithStacktrace<EventJavaMonitorEnter> flush(jt);)
EventJavaMonitorEnter event;
if (event.should_commit()) {
event.set_monitorClass(((oop)this->object())->klass());
event.set_address((uintptr_t)(this->object_addr()));
}
{ // Change java thread status to indicate blocked on monitor enter.
JavaThreadBlockedOnMonitorEnterState jtbmes(jt, this);
Self->set_current_pending_monitor(this);
DTRACE_MONITOR_PROBE(contended__enter, this, object(), jt);
if (JvmtiExport::should_post_monitor_contended_enter()) {
JvmtiExport::post_monitor_contended_enter(jt, this);
// The current thread does not yet own the monitor and does not
// yet appear on any queues that would get it made the successor.
// This means that the JVMTI_EVENT_MONITOR_CONTENDED_ENTER event
// handler cannot accidentally consume an unpark() meant for the
// ParkEvent associated with this ObjectMonitor.
}
OSThreadContendState osts(Self->osthread());
ThreadBlockInVM tbivm(jt);
// TODO-FIXME: change the following for(;;) loop to straight-line code.
for (;;) {
jt->set_suspend_equivalent();
// cleared by handle_special_suspend_equivalent_condition()
// or java_suspend_self()
// 入队操作,进到cxq中
EnterI (THREAD) ;
if (!ExitSuspendEquivalent(jt)) break ;
//
// We have acquired the contended monitor, but while we were
// waiting another thread suspended us. We don't want to enter
// the monitor while suspended because that would surprise the
// thread that suspended us.
//
_recursions = 0 ;
_succ = NULL ;
exit (false, Self) ;
jt->java_suspend_self();
}
Self->set_current_pending_monitor(NULL);
// We cleared the pending monitor info since we've just gotten past
// the enter-check-for-suspend dance and we now own the monitor free
// and clear, i.e., it is no longer pending. The ThreadBlockInVM
// destructor can go to a safepoint at the end of this block. If we
// do a thread dump during that safepoint, then this thread will show
// as having "-locked" the monitor, but the OS and java.lang.Thread
// states will still report that the thread is blocked trying to
// acquire it.
}
// count--
Atomic::dec_ptr(&_count);
assert (_count >= 0, "invariant") ;
Self->_Stalled = 0 ;
// Must either set _recursions = 0 or ASSERT _recursions == 0.
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_succ != Self , "invariant") ;
assert (((oop)(object()))->mark() == markOopDesc::encode(this), "invariant") ;
// The thread -- now the owner -- is back in vm mode.
// Report the glorious news via TI,DTrace and jvmstat.
// The probe effect is non-trivial. All the reportage occurs
// while we hold the monitor, increasing the length of the critical
// section. Amdahl's parallel speedup law comes vividly into play.
//
// Another option might be to aggregate the events (thread local or
// per-monitor aggregation) and defer reporting until a more opportune
// time -- such as next time some thread encounters contention but has
// yet to acquire the lock. While spinning that thread could
// spinning we could increment JVMStat counters, etc.
DTRACE_MONITOR_PROBE(contended__entered, this, object(), jt);
if (JvmtiExport::should_post_monitor_contended_entered()) {
JvmtiExport::post_monitor_contended_entered(jt, this);
// The current thread already owns the monitor and is not going to
// call park() for the remainder of the monitor enter protocol. So
// it doesn't matter if the JVMTI_EVENT_MONITOR_CONTENDED_ENTERED
// event handler consumed an unpark() issued by the thread that
// just exited the monitor.
}
if (event.should_commit()) {
event.set_previousOwner((uintptr_t)_previous_owner_tid);
event.commit();
}
if (ObjectMonitor::_sync_ContendedLockAttempts != NULL) {
ObjectMonitor::_sync_ContendedLockAttempts->inc() ;
}
}
EnterL
void ATTR ObjectMonitor::EnterI (TRAPS) {
Thread * Self = THREAD ;
assert (Self->is_Java_thread(), "invariant") ;
assert (((JavaThread *) Self)->thread_state() == _thread_blocked , "invariant") ;
// Try the lock - TATAS
if (TryLock (Self) > 0) {
assert (_succ != Self , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
DeferredInitialize () ;
// We try one round of spinning *before* enqueueing Self.
//
// If the _owner is ready but OFFPROC we could use a YieldTo()
// operation to donate the remainder of this thread's quantum
// to the owner. This has subtle but beneficial affinity
// effects.
if (TrySpin (Self) > 0) {
assert (_owner == Self , "invariant") ;
assert (_succ != Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
// The Spin failed -- Enqueue and park the thread ...
assert (_succ != Self , "invariant") ;
assert (_owner != Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
// Enqueue "Self" on ObjectMonitor's _cxq.
//
// Node acts as a proxy for Self.
// As an aside, if were to ever rewrite the synchronization code mostly
// in Java, WaitNodes, ObjectMonitors, and Events would become 1st-class
// Java objects. This would avoid awkward lifecycle and liveness issues,
// as well as eliminate a subset of ABA issues.
// TODO: eliminate ObjectWaiter and enqueue either Threads or Events.
//
ObjectWaiter node(Self) ;
Self->_ParkEvent->reset() ;
node._prev = (ObjectWaiter *) 0xBAD ;
node.TState = ObjectWaiter::TS_CXQ ;
// Push "Self" onto the front of the _cxq.
// Once on cxq/EntryList, Self stays on-queue until it acquires the lock.
// Note that spinning tends to reduce the rate at which threads
// enqueue and dequeue on EntryList|cxq.
ObjectWaiter * nxt ;
for (;;) {
// 入队
node._next = nxt = _cxq ;
// 以CAS方式入队
if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;
// Interference - the CAS failed because _cxq changed. Just retry.
// As an optional optimization we retry the lock.
// 重新尝试获取锁资源
if (TryLock (Self) > 0) {
assert (_succ != Self , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
}
// Check for cxq|EntryList edge transition to non-null. This indicates
// the onset of contention. While contention persists exiting threads
// will use a ST:MEMBAR:LD 1-1 exit protocol. When contention abates exit
// operations revert to the faster 1-0 mode. This enter operation may interleave
// (race) a concurrent 1-0 exit operation, resulting in stranding, so we
// arrange for one of the contending thread to use a timed park() operations
// to detect and recover from the race. (Stranding is form of progress failure
// where the monitor is unlocked but all the contending threads remain parked).
// That is, at least one of the contended threads will periodically poll _owner.
// One of the contending threads will become the designated "Responsible" thread.
// The Responsible thread uses a timed park instead of a normal indefinite park
// operation -- it periodically wakes and checks for and recovers from potential
// strandings admitted by 1-0 exit operations. We need at most one Responsible
// thread per-monitor at any given moment. Only threads on cxq|EntryList may
// be responsible for a monitor.
//
// Currently, one of the contended threads takes on the added role of "Responsible".
// A viable alternative would be to use a dedicated "stranding checker" thread
// that periodically iterated over all the threads (or active monitors) and unparked
// successors where there was risk of stranding. This would help eliminate the
// timer scalability issues we see on some platforms as we'd only have one thread
// -- the checker -- parked on a timer.
if ((SyncFlags & 16) == 0 && nxt == NULL && _EntryList == NULL) {
// Try to assume the role of responsible thread for the monitor.
// CONSIDER: ST vs CAS vs { if (Responsible==null) Responsible=Self }
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
// The lock have been released while this thread was occupied queueing
// itself onto _cxq. To close the race and avoid "stranding" and
// progress-liveness failure we must resample-retry _owner before parking.
// Note the Dekker/Lamport duality: ST cxq; MEMBAR; LD Owner.
// In this case the ST-MEMBAR is accomplished with CAS().
//
// TODO: Defer all thread state transitions until park-time.
// Since state transitions are heavy and inefficient we'd like
// to defer the state transitions until absolutely necessary,
// and in doing so avoid some transitions ...
TEVENT (Inflated enter - Contention) ;
int nWakeups = 0 ;
int RecheckInterval = 1 ;
for (;;) {
if (TryLock (Self) > 0) break ;
assert (_owner != Self, "invariant") ;
if ((SyncFlags & 2) && _Responsible == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
// park self
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
// Increase the RecheckInterval, but clamp the value.
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
TEVENT (Inflated enter - park UNTIMED) ;
Self->_ParkEvent->park() ;
}
if (TryLock(Self) > 0) break ;
// The lock is still contested.
// Keep a tally of the # of futile wakeups.
// Note that the counter is not protected by a lock or updated by atomics.
// That is by design - we trade "lossy" counters which are exposed to
// races during updates for a lower probe effect.
TEVENT (Inflated enter - Futile wakeup) ;
if (ObjectMonitor::_sync_FutileWakeups != NULL) {
ObjectMonitor::_sync_FutileWakeups->inc() ;
}
++ nWakeups ;
// Assuming this is not a spurious wakeup we'll normally find _succ == Self.
// We can defer clearing _succ until after the spin completes
// TrySpin() must tolerate being called with _succ == Self.
// Try yet another round of adaptive spinning.
if ((Knob_SpinAfterFutile & 1) && TrySpin (Self) > 0) break ;
// We can find that we were unpark()ed and redesignated _succ while
// we were spinning. That's harmless. If we iterate and call park(),
// park() will consume the event and return immediately and we'll
// just spin again. This pattern can repeat, leaving _succ to simply
// spin on a CPU. Enable Knob_ResetEvent to clear pending unparks().
// Alternately, we can sample fired() here, and if set, forgo spinning
// in the next iteration.
if ((Knob_ResetEvent & 1) && Self->_ParkEvent->fired()) {
Self->_ParkEvent->reset() ;
OrderAccess::fence() ;
}
if (_succ == Self) _succ = NULL ;
// Invariant: after clearing _succ a thread *must* retry _owner before parking.
OrderAccess::fence() ;
}
// Egress :
// Self has acquired the lock -- Unlink Self from the cxq or EntryList.
// Normally we'll find Self on the EntryList .
// From the perspective of the lock owner (this thread), the
// EntryList is stable and cxq is prepend-only.
// The head of cxq is volatile but the interior is stable.
// In addition, Self.TState is stable.
assert (_owner == Self , "invariant") ;
assert (object() != NULL , "invariant") ;
// I'd like to write:
// guarantee (((oop)(object()))->mark() == markOopDesc::encode(this), "invariant") ;
// but as we're at a safepoint that's not safe.
UnlinkAfterAcquire (Self, &node) ;
if (_succ == Self) _succ = NULL ;
assert (_succ != Self, "invariant") ;
if (_Responsible == Self) {
_Responsible = NULL ;
OrderAccess::fence(); // Dekker pivot-point
// We may leave threads on cxq|EntryList without a designated
// "Responsible" thread. This is benign. When this thread subsequently
// exits the monitor it can "see" such preexisting "old" threads --
// threads that arrived on the cxq|EntryList before the fence, above --
// by LDing cxq|EntryList. Newly arrived threads -- that is, threads
// that arrive on cxq after the ST:MEMBAR, above -- will set Responsible
// non-null and elect a new "Responsible" timer thread.
//
// This thread executes:
// ST Responsible=null; MEMBAR (in enter epilog - here)
// LD cxq|EntryList (in subsequent exit)
//
// Entering threads in the slow/contended path execute:
// ST cxq=nonnull; MEMBAR; LD Responsible (in enter prolog)
// The (ST cxq; MEMBAR) is accomplished with CAS().
//
// The MEMBAR, above, prevents the LD of cxq|EntryList in the subsequent
// exit operation from floating above the ST Responsible=null.
}
// We've acquired ownership with CAS().
// CAS is serializing -- it has MEMBAR/FENCE-equivalent semantics.
// But since the CAS() this thread may have also stored into _succ,
// EntryList, cxq or Responsible. These meta-data updates must be
// visible __before this thread subsequently drops the lock.
// Consider what could occur if we didn't enforce this constraint --
// STs to monitor meta-data and user-data could reorder with (become
// visible after) the ST in exit that drops ownership of the lock.
// Some other thread could then acquire the lock, but observe inconsistent
// or old monitor meta-data and heap data. That violates the JMM.
// To that end, the 1-0 exit() operation must have at least STST|LDST
// "release" barrier semantics. Specifically, there must be at least a
// STST|LDST barrier in exit() before the ST of null into _owner that drops
// the lock. The barrier ensures that changes to monitor meta-data and data
// protected by the lock will be visible before we release the lock, and
// therefore before some other thread (CPU) has a chance to acquire the lock.
// See also: http://gee.cs.oswego.edu/dl/jmm/cookbook.html.
//
// Critically, any prior STs to _succ or EntryList must be visible before
// the ST of null into _owner in the *subsequent* (following) corresponding
// monitorexit. Recall too, that in 1-0 mode monitorexit does not necessarily
// execute a serializing instruction.
if (SyncFlags & 8) {
OrderAccess::fence() ;
}
return ;
}
三、深入ReentrantLock
3.1 ReentrantLock和synchronized的区别
核心区别:
- ReentrantLock是个类,synchronized是关键字,当然都是在JVM层面实现互斥锁的方式
效率区别:
- 如果竞争比较激烈,推荐ReentrantLock去实现,不存在锁升级概念,而synchronized是存在锁升级概念的,如果升级到重量级锁,是不存在锁降级的。
底层实现的区别:
- 实现原理不一样,ReentrantLock基于AQS实现的,synchronized是基于ObjectMoniter
功能项区别:
- ReentrantLock的功能比synchronized更全面
- ReentrantLock支持公平锁和非公平锁
- ReentrantLock可以指定等待锁资源的时间
选择那个,如果是对并发编程特别熟练,推荐使用ReentrantLock,功能更丰富,如果掌握的一般般,使用synchronized更好
3.2 AQS概述
AQS就是AbstractQueuedSynchronizer抽象类,AQS其实就是JUC包下的一个基类,JUC下的很多内容都是基于AQS实现了部分功能,比如ReentrantLock,ThreadPoolExecutor,阻塞队列,CountDownLatch,Semaphore,CyclicBarrier等等都是基于AQS实现
首先AQS中提供了一个由volatile修饰,并且用CAS方式修饰的int类型的state变量
其次AQS中维护了一个双向链表,有head,有tail,,并且每个节点都是Node对象
static final class Node {
/** Marker to indicate a node is waiting in shared mode */
static final Node SHARED = new Node();
/** Marker to indicate a node is waiting in exclusive mode */
static final Node EXCLUSIVE = null;
/** waitStatus value to indicate thread has cancelled. */
static final int CANCELLED = 1;
/** waitStatus value to indicate successor's thread needs unparking. */
static final int SIGNAL = -1;
/** waitStatus value to indicate thread is waiting on condition. */
static final int CONDITION = -2;
/**
* waitStatus value to indicate the next acquireShared should
* unconditionally propagate.
*/
static final int PROPAGATE = -3;
/**
* Status field, taking on only the values:
* SIGNAL: The successor of this node is (or will soon be)
* blocked (via park), so the current node must
* unpark its successor when it releases or
* cancels. To avoid races, acquire methods must
* first indicate they need a signal,
* then retry the atomic acquire, and then,
* on failure, block.
* CANCELLED: This node is cancelled due to timeout or interrupt.
* Nodes never leave this state. In particular,
* a thread with cancelled node never again blocks.
* CONDITION: This node is currently on a condition queue.
* It will not be used as a sync queue node
* until transferred, at which time the status
* will be set to 0. (Use of this value here has
* nothing to do with the other uses of the
* field, but simplifies mechanics.)
* PROPAGATE: A releaseShared should be propagated to other
* nodes. This is set (for head node only) in
* doReleaseShared to ensure propagation
* continues, even if other operations have
* since intervened.
* 0: None of the above
*
* The values are arranged numerically to simplify use.
* Non-negative values mean that a node doesn't need to
* signal. So, most code doesn't need to check for particular
* values, just for sign.
*
* The field is initialized to 0 for normal sync nodes, and
* CONDITION for condition nodes. It is modified using CAS
* (or when possible, unconditional volatile writes).
*/
volatile int waitStatus;
/**
* Link to predecessor node that current node/thread relies on
* for checking waitStatus. Assigned during enqueuing, and nulled
* out (for sake of GC) only upon dequeuing. Also, upon
* cancellation of a predecessor, we short-circuit while
* finding a non-cancelled one, which will always exist
* because the head node is never cancelled: A node becomes
* head only as a result of successful acquire. A
* cancelled thread never succeeds in acquiring, and a thread only
* cancels itself, not any other node.
*/
volatile Node prev;
/**
* Link to the successor node that the current node/thread
* unparks upon release. Assigned during enqueuing, adjusted
* when bypassing cancelled predecessors, and nulled out (for
* sake of GC) when dequeued. The enq operation does not
* assign next field of a predecessor until after attachment,
* so seeing a null next field does not necessarily mean that
* node is at end of queue. However, if a next field appears
* to be null, we can scan prev's from the tail to
* double-check. The next field of cancelled nodes is set to
* point to the node itself instead of null, to make life
* easier for isOnSyncQueue.
*/
volatile Node next;
/**
* The thread that enqueued this node. Initialized on
* construction and nulled out after use.
*/
volatile Thread thread;
/**
* Link to next node waiting on condition, or the special
* value SHARED. Because condition queues are accessed only
* when holding in exclusive mode, we just need a simple
* linked queue to hold nodes while they are waiting on
* conditions. They are then transferred to the queue to
* re-acquire. And because conditions can only be exclusive,
* we save a field by using special value to indicate shared
* mode.
*/
Node nextWaiter;
/**
* Returns true if node is waiting in shared mode.
*/
final boolean isShared() {
return nextWaiter == SHARED;
}
/**
* Returns previous node, or throws NullPointerException if null.
* Use when predecessor cannot be null. The null check could
* be elided, but is present to help the VM.
*
* @return the predecessor of this node
*/
final Node predecessor() {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
/** Establishes initial head or SHARED marker. */
Node() {}
/** Constructor used by addWaiter. */
Node(Node nextWaiter) {
this.nextWaiter = nextWaiter;
THREAD.set(this, Thread.currentThread());
}
/** Constructor used by addConditionWaiter. */
Node(int waitStatus) {
WAITSTATUS.set(this, waitStatus);
THREAD.set(this, Thread.currentThread());
}
/** CASes waitStatus field. */
final boolean compareAndSetWaitStatus(int expect, int update) {
return WAITSTATUS.compareAndSet(this, expect, update);
}
/** CASes next field. */
final boolean compareAndSetNext(Node expect, Node update) {
return NEXT.compareAndSet(this, expect, update);
}
final void setPrevRelaxed(Node p) {
PREV.set(this, p);
}
// VarHandle mechanics
private static final VarHandle NEXT;
private static final VarHandle PREV;
private static final VarHandle THREAD;
private static final VarHandle WAITSTATUS;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
NEXT = l.findVarHandle(Node.class, "next", Node.class);
PREV = l.findVarHandle(Node.class, "prev", Node.class);
THREAD = l.findVarHandle(Node.class, "thread", Thread.class);
WAITSTATUS = l.findVarHandle(Node.class, "waitStatus", int.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
}
AQS内部结构和属性
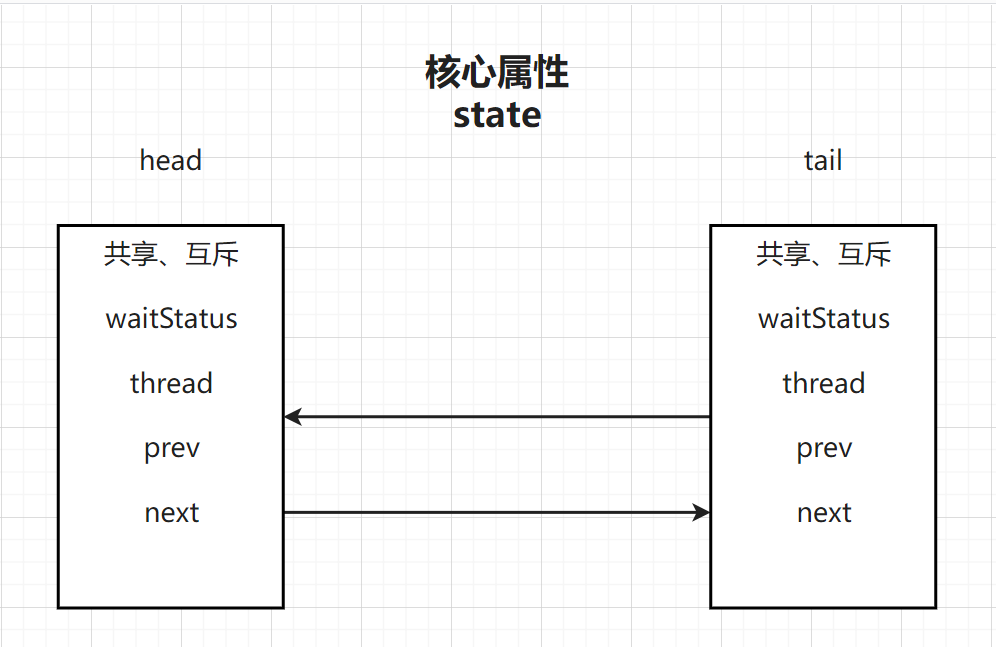
3.3 加锁流程源码解析
3.3.1 加锁流程图
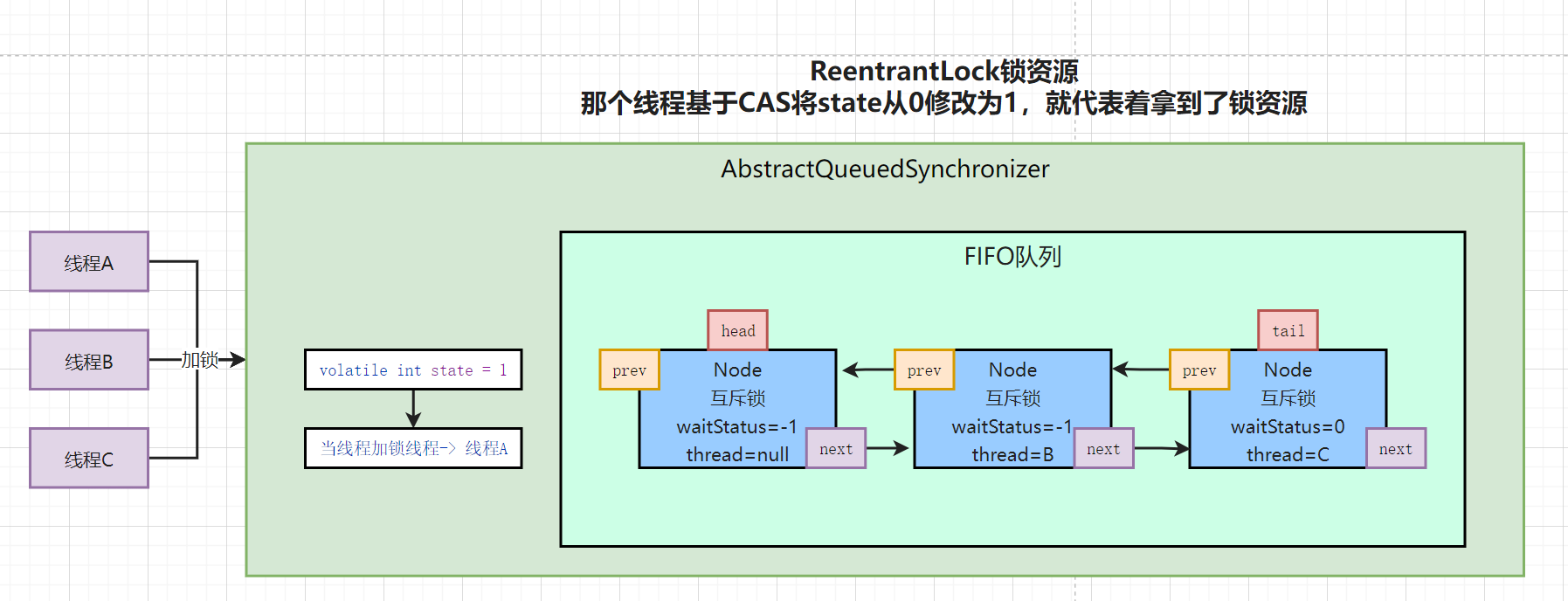
- 线程A先执行CAS,将state从0修改为1,线程A就获取到了锁资源,去执行业务代码即可
- 线程B在执行CAS,发现state已经是1了,无法获取到锁资源
- 线程B需要去排序,将自己封装为Node对象
- 需要将当前B线程的Node放到双向队列中保存,排队
- 但是双向链表中,必须先有个伪节点作为头节点,并且放到双向队列中
- 将B线程的Node挂在head的后面,并且将上一个节点的状态修改为-1,在挂起B线程
3.3.2 源码分析
3.3.2.1 lock方法
-
执行lock方法后,公平锁和非公平锁的执行逻辑不一样
-
非公平锁
// 非公平锁 final void lock() { // 一来就先基于CAS的方式,尝试将state从0改为1 if (compareAndSetState(0, 1)) // 获取锁成功了,会将当前线程设置到exclusiveOwnerThread属性,代表当前线程持有者锁资源 setExclusiveOwnerThread(Thread.currentThread()); else // 执行acquire,尝试获取锁资源 acquire(1); } -
公平锁
// 公平锁 final void lock() { // 执行acquire,尝试获取锁资源 acquire(1); }
-
-
acquire方法,公平锁和非公平锁的逻辑一样
public final void acquire(int arg) { // tryAcquire:再次查看,当前线程是否可以尝试获取锁资源 if (!tryAcquire(arg) && // 没有拿到锁资源 // addWaiter(Node.EXCLUSIVE):将当前线程封装为NOde节点,插入到AQS双向链表的结尾 // acquireQueued:查看我是否第一个排队的节点,如果可以再次尝试获取锁资源,如果长时间拿不到,挂起线程 // 如果不是第一个排队节点,就尝试挂起线程即可 acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) // 中断线程的操作 selfInterrupt(); } -
tryAcuire方法竞争锁资源的逻辑,分为了公平锁和非公平锁
-
非公平锁
final boolean nonfairTryAcquire(int acquires) { // 获取当前线程 final Thread current = Thread.currentThread(); // 获取state属性 int c = getState(); // 判断state当前是否为0,之前持有锁线程是否释放了锁资源 if (c == 0) { // 再次抢一波锁资源 if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); // 获取锁成功返回true return true; } } // 不是0,判断当前线程是否是持有锁线程,如果是,锁重入 else if (current == getExclusiveOwnerThread()) { // 将state+1 int nextc = c + acquires; if (nextc < 0) // overflow // 说明对重入次数+1后,超过了int正数的取值范围 // 01111111 11111111 11111111 11111111 // 10000000 00000000 00000000 00000000 // 最高位是1代表负数,0代表正数 // 说明重入的次数超过界限了 throw new Error("Maximum lock count exceeded"); // 正常的将计算结果,赋值给state setState(nextc); // 锁重入成功 return true; } // 获取锁失败,返回false return false; } -
公平锁
protected final boolean tryAcquire(int acquires) { // 获取当前线程 final Thread current = Thread.currentThread(); // 获取state属性 int c = getState(); // 判断state当前是否为0,之前持有锁线程是否释放了锁资源 if (c == 0) { // 查看AQS中是否有排队的Node // 没有排队抢一手,有人排队,如果我是第一个,也抢一手 if (!hasQueuedPredecessors() && // 尝试将state修改成 1 compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } // 锁重入 else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } // 获取锁失败,返回false return false; }-
hasQueuedPredecessors() 查看是否有线程在AQS中排队
public final boolean hasQueuedPredecessors() { // 尾节点 Node t = tail; // 头节点 Node h = head; Node s; // 条件1 h != t // 当h == t,则 h!=t 返回false // 条件2 ((s = h.next) == null || s.thread != Thread.currentThread()) // s 为头节点下一个节点 // s 节点不为null,并且是节点的线程为当前线程(排在第一名的是不是我) // 当 头节点下一个节点的线程 == 当前线程,则 s.thread != Thread.currentThread() 返回false return h != t && ((s = h.next) == null || s.thread != Thread.currentThread()); }
-
-
-
addWaite方法,将没有拿到锁资源的线程扔到AQS队列中去排队
// 没有拿到锁资源,进行排队,mode:EXCLUSIVE 互斥锁 SHARED:共享锁 private Node addWaiter(Node mode) { // 将当前线程封装成Node Node node = new Node(Thread.currentThread(), mode); // 拿到尾节点 Node pred = tail; // 尾节点不为空 if (pred != null) { // 当前的前节点指向尾节点 node.prev = pred; // 以CAS的方式,将当前线程设置为tail节点 if (compareAndSetTail(pred, node)) { // 将之前的尾节点的next指向当前节点 // node当前节点就是尾节点 pred.next = node; return node; } } // 如果CAS失败,以死循环的方式,保证当前线程的Node一定可以放到AQS的队列的末尾 enq(node); return node; }-
enq(node) 保证当前线程的Node一定可以放到AQS的队列的末尾
private Node enq(final Node node) { for (;;) { // 获取尾节点 Node t = tail; // 尾节点为空,AQS总一个节点都没有,构建一个伪节点,作为head和tail if (t == null) { // Must initialize // 构建伪节点作为head和tail if (compareAndSetHead(new Node())) tail = head; } else { // 当前节点的前指针指向尾巴节点 node.prev = t; // 当前节点作为尾节点 if (compareAndSetTail(t, node)) { // 将之前的尾节点的next指向当前节点 // node当前节点就是尾节点 t.next = node; return t; } } } }
-
-
acquireQueued方法,判断当前线程是否还能再次尝试获取锁资源,如果不能获取锁资源,或者又没有获取到,尝试将当前线程挂起
// 当前没有拿到锁资源后,并且到了AQS排队了之后触发的方法 final boolean acquireQueued(final Node node, int arg) { // failed: 获取锁资源是否失败(真正触发的,还是tryLock和lockInterruptibly) boolean failed = true; try { // 中断 boolean interrupted = false; for (;;) { // 拿到当前节点的前继节点 final Node p = node.predecessor(); // 前继节点是否是头节点,如果是,再次执行tryAcquire尝试获取锁 if (p == head && tryAcquire(arg)) { // 获取锁资源成功 // 设置头节点为当前拿锁成功的Node,并取消thread信息 setHead(node); p.next = null; // help GC // 设置锁失败标识为false failed = false; return interrupted; } // 没拿到锁资源 // shouldParkAfterFailedAcquire:基于上一个节点状态判断当前节点是否能够挂起线程,如果可以返回true // 如果不能,就返回false,继续下次循环 if (shouldParkAfterFailedAcquire(p, node) && // 这里基于Unsafe类的park方法,将当前线程挂起 parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) // 在lock方法中,基本不会执行 cancelAcquire(node); }-
setHead(),获取锁成功之后,先执行setHead
// 获取锁成功之后,先执行setHead private void setHead(Node node) { // 当前节点作为头 head = node; // 头节点不需要线程信息 node.thread = null; node.prev = null; } -
shouldParkAfterFailedAcquire 当前Node没有拿到锁资源,或者没有资格竞争锁资源,看一下能否挂起当前线程
// 当前Node没有拿到锁资源,或者没有资格竞争锁资源,看一下能否挂起当前线程 private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { // -1,SIGNAL状态: 代表前节点的后继节点,可以挂起线程,后续我会被唤醒后继节点 // 1,CANCELLED状态: 代表当前节点取消 // 前继节点的状态 int ws = pred.waitStatus; if (ws == Node.SIGNAL) // 前继节点的状态为-1,当前节点可以安心挂起线程 return true; if (ws > 0) { // 前继节点是取消的状态,我需要往前找到一个状态不为1的Node,作为他的next节点 do { // node的前继节点是前继节点 node.prev = pred = pred.prev; } while (pred.waitStatus > 0); // pread节点不为1,设置一下next节点 // node作为当前pread节点的next节点 pred.next = node; } else { // 前继节点不是1和-1,那就是代表节点状态正常,将前继节点状态为-1 compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } return false; }
-
3.3.2.2 tryLock方法
- boolean tryLock(); 无论是公平锁还是非公平锁,都会走非公平锁抢占锁资源的操作,拿到state的值,如果是0,直接CAS尝试一下,state不是0,那就看一下是不是锁重入操作,如果没抢到或者不是锁重入操作,结束
-
tryLock()
public boolean tryLock() { // 非公平锁的竞争锁操作 return sync.nonfairTryAcquire(1); } -
nonfairTryAcquire(1)
final boolean nonfairTryAcquire(int acquires) { // 获取当前线程 final Thread current = Thread.currentThread(); // 获取state属性 int c = getState(); // 判断state当前是否为0,之前持有锁线程是否释放了锁资源 if (c == 0) { // 再次抢一波锁资源 if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); // 获取锁成功返回true return true; } } // 不是0,判断当前线程是否是持有锁线程,如果是,锁重入 else if (current == getExclusiveOwnerThread()) { // 将state+1 int nextc = c + acquires; if (nextc < 0) // overflow // 说明对重入次数+1后,超过了int正数的取值范围 // 01111111 11111111 11111111 11111111 // 10000000 00000000 00000000 00000000 // 最高位是1代表负数,0代表正数 // 说明重入的次数超过界限了 throw new Error("Maximum lock count exceeded"); // 正常的将计算结果,赋值给state setState(nextc); // 锁重入成功 return true; } // 获取锁失败,返回false return false; }
-
- boolean tryLock(long time, TimeUnit unit); 指定获取锁等待时间,这个时间内没有获取锁成功,就结束
-
tryLock((long time, TimeUnit unit);
public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException { // unit.toNanos(timeout): 转换为纳秒 return sync.tryAcquireNanos(1, unit.toNanos(timeout)); } -
boolean tryAcquireNanos(int arg, long nanosTimeout) throws InterruptedException
public final boolean tryAcquireNanos(int arg, long nanosTimeout) throws InterruptedException { // 线程的中继标记位,是不是从false,改为了true,如果是,直接抛出异常 if (Thread.interrupted()) throw new InterruptedException(); // tryAcquire 分为公平锁和非公平锁两种执行方式,如果拿锁成功,结束 // doAcquireNanos,如果拿锁失败了,在这里等待指定时间 return tryAcquire(arg) || doAcquireNanos(arg, nanosTimeout); } -
doAcquireNanos(int arg, long nanosTimeout)
private boolean doAcquireNanos(int arg, long nanosTimeout) throws InterruptedException { // 如果等待时间是0秒,结束,拿锁失败 if (nanosTimeout <= 0L) return false; // 计算出结束时间,当前时间+设置的时间 final long deadline = System.nanoTime() + nanosTimeout; // 先放到AQS队列中 final Node node = addWaiter(Node.EXCLUSIVE); // 拿锁失败,默认标识true boolean failed = true; try { for (;;) { // 获取当前节点的前继节点 final Node p = node.predecessor(); // 获取当前节点的前继节点是头节点,直接抢锁 if (p == head && tryAcquire(arg)) { // 抢锁成功设置,头节点 setHead(node); p.next = null; // help GC failed = false; return true; } // 计算出剩余可以的时间 nanosTimeout = deadline - System.nanoTime(); // 判断是否还有时间 if (nanosTimeout <= 0L) return false; // shouldParkAfterFailedAcquire:更具前继节点状态判断是否可以挂起线程 if (shouldParkAfterFailedAcquire(p, node) && // spinForTimeoutThreshold = 1000L // 避免剩余时间太少,如果剩余时间少就不用挂起线程 nanosTimeout > spinForTimeoutThreshold) // 时间足够,将线程挂起剩余时间 LockSupport.parkNanos(this, nanosTimeout); // 如果线程醒了,查看是中继唤醒,还是时间到了 if (Thread.interrupted()) // 是中继唤醒 throw new InterruptedException(); } } finally { if (failed) cancelAcquire(node); } } -
cancelAcquire(Node node) 取消节点
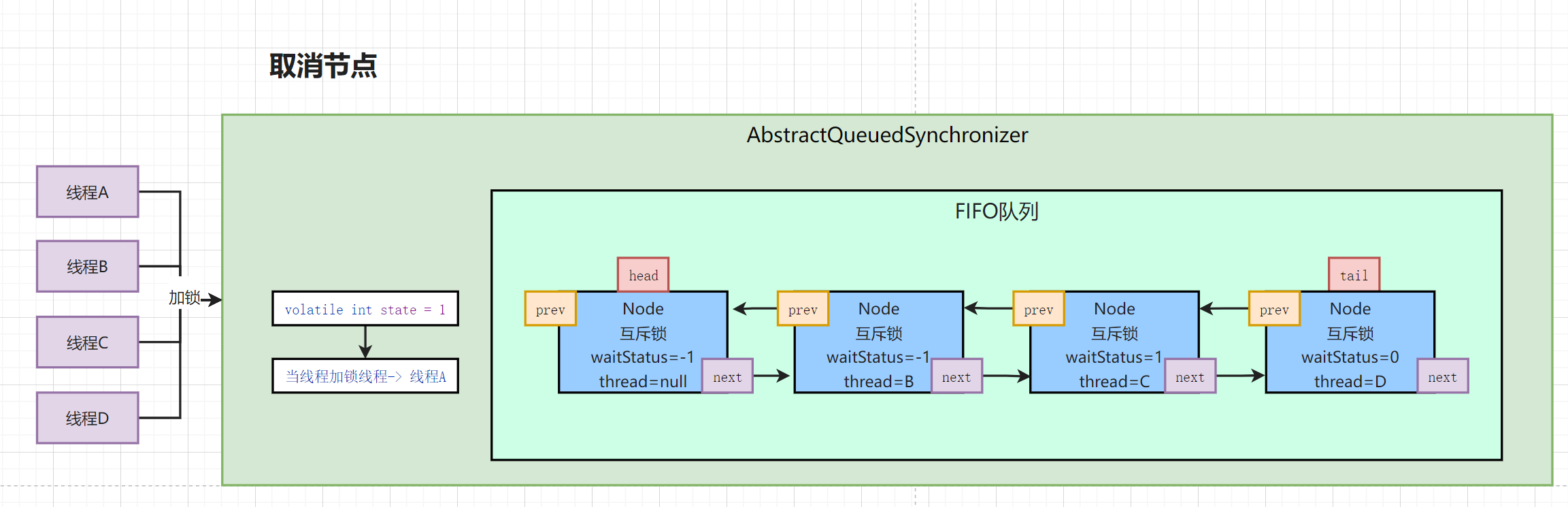
- 线程设置为NULL
- 往前找到有效节点作为当前节点的prev
- 将waitStatus设置为1,代表取消
- 脱离整个AQS队列
- 当前Node是tail
- 当地Node是head的后继节点
- 不是tail节点,也不是head的后继节点
// 取消在AQS中排队的Node private void cancelAcquire(Node node) { // 如果当前节点为null,直接忽略 if (node == null) return; // 1. 线程设置为NULL node.thread = null; // 2. 往前跳过被取消的节点, Node pred = node.prev; // 找到下一个有效的节点 while (pred.waitStatus > 0) node.prev = pred = pred.prev; // 3.拿到有效节点的next Node predNext = pred.next; // 当前节点设置取消状态1 node.waitStatus = Node.CANCELLED; // 脱离AQS队列的操作 // 当前Node节点是尾节点,将找到的有效节点设置为tail if (node == tail && compareAndSetTail(node, pred)) { compareAndSetNext(pred, predNext, null); } else { // 走到这说明node不是尾节点,或者CAS失败 int ws; // pred != head 判断找到的有效节点是不是头节点 // (ws = pred.waitStatus) == Node.SIGNAL || // (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL)) // 拿到有效节点的状态,只要有效节点状态不是取消状态,就会改为-1 // pred.thread != null 判断有效节点线程不为null if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) { // 上面的判断都是为了避免后面的节点无法被唤醒 // 前继节点是有效节点,可以唤醒后面的节点 // 获取取消节点的后继节点 Node next = node.next; // 判断后继节点是个正常的节点,不是取消的节点 if (next != null && next.waitStatus <= 0) // 设置有效节点的后继节点 compareAndSetNext(pred, predNext, next); } else { // 当前节点是head的后继节点 unparkSuccessor(node); } node.next = node; // help GC } } -
unparkSuccessor(Node node), 取消节点是head后继节点,并唤醒有效节点
private void unparkSuccessor(Node node) { // 获取当前节点状态 int ws = node.waitStatus; // 当前节点状态设置为0态 if (ws < 0) compareAndSetWaitStatus(node, ws, 0); // 取消节点中的后继节点如果被取消或者线程明显为空 // 则从尾部向前遍历找到有效的节点 Node s = node.next; if (s == null || s.waitStatus > 0) { s = null; for (Node t = tail; t != null && t != node; t = t.prev) if (t.waitStatus <= 0) s = t; } // 有效节点不为空,唤醒线程 if (s != null) LockSupport.unpark(s.thread); }
-
3.3.2.3 lockInterruptibly()
lockInterruptibly()和tryLock(time,unit)唯一区别
lockInterruptibly(),拿不到锁资源,就死等,等到锁资源释放后,被唤醒,或者被中继唤醒
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
// 封装为Node对象添加AQS队列中
final Node node = addWaiter(Node.EXCLUSIVE);
// 获取锁失败标识
boolean failed = true;
try {
for (;;) {
// 获取前继节点
final Node p = node.predecessor();
// 前继节点是否头节点
// 是头节点尝试获取锁
if (p == head && tryAcquire(arg)) {
// 设置头节点
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
// shouldParkAfterFailedAcquire:基于上一个节点状态判断当前节点是否能够挂起线程,如果可以返回true
// parkAndCheckInterrupt:判断是中断唤醒还是,正常唤醒
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
parkAndCheckInterrupt
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
// 这个方法可以确认,当前挂起的线程,是被中继唤醒的,还是被正常唤醒的
// 中继唤醒,返回true,如果正常唤醒,返回false
return Thread.interrupted();
}
3.4 释放锁的流程
3.4.1 释放锁流程分析
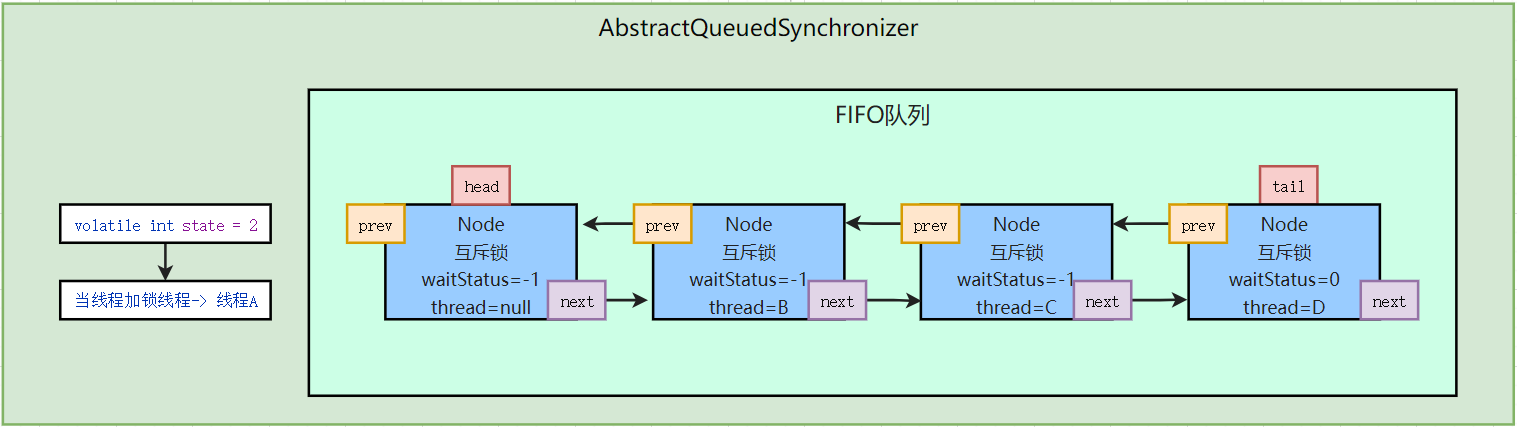
线程A持有当前锁,重入了一次,state = 2,线程B,C,D获取锁资源失败,在AQS中排队
线程A释放锁资源调用unlock方法,就是执行了tryRelease方法
首先判断是不是线程A持有锁资源,如果不是就抛出异常
如果线程A持有锁资源,对state -1,如果为0,证明当前锁资源释放干净
查看头节点的状态,如果是0说明后面没有挂起的线程,是-1后面有挂起的线程,需要唤醒需要先将当前的-1,改为0,找到有效节点唤醒,找到之后,唤醒线程即可,如果头节点的后继节点是取消的状态,则会从链表尾巴从前找到有效节点
为什么要从链表尾部开始找有效节点呢?
因为要防止漏掉要唤醒的挂起的线程,节点插入链表是先prev指针先指向尾节点的,在,next指针,和tail指定当前插入节点,如果从头部开始找的可能会漏掉有效节点,当next指针还没有插入节点的时候
3.4.2 释放锁源码分析
- unlock()
public void unlock() {
// 释放锁资源不分为公平锁和非公平锁,都是一个sync对象
sync.release(1);
}
- boolean release(int arg)
// 释放锁的核心流程
public final boolean release(int arg) {
// 核心释放锁资源,对state-1操作
if (tryRelease(arg)) {
// 如果锁释放干净了,走这个逻辑
// 获取到头节点
Node h = head;
// 头节点不为null
// 如果头节点状态不为0(为-1),说明后面有点排队的Node,并且线程已经挂起了
if (h != null && h.waitStatus != 0)
// 唤醒排队的线程
unparkSuccessor(h);
return true;
}
return false;
}
- boolean tryRelease(int releases)
// 释放锁资源的操作
protected final boolean tryRelease(int releases) {
// 拿到state - 1(并没有赋值给state)
int c = getState() - releases;
// 判断当前线程是否是持有锁线程,如果不是,直接抛出异常
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
// 标识锁是否是否干净标志
boolean free = false;
if (c == 0) {
// 如果state -1 等于0,说明锁释放干净了
free = true;
// 将持有锁线程设置为null
setExclusiveOwnerThread(null);
}
// 将c赋值给state
setState(c);
// 锁资源释放干净返回true,否则返回false
return free;
}
- unparkSuccessor(Node node) 唤醒有效节点
// 当前节点是head
private void unparkSuccessor(Node node) {
// 获取当前节点状态
int ws = node.waitStatus;
// 当前节点状态设置为0态
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
// 取消节点中的后继节点如果被取消或者线程明显为空
// 则从尾部向前遍历找到有效的节点
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
// 有效节点不为空,唤醒线程
if (s != null)
LockSupport.unpark(s.thread);
}















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









