






0. 语义分割常用指标



平均像素准确率(MPA)。 平均像素准确率其实更应该叫平均像素精确率,是指分别计算每个类别分类正确的像素数占所有预测为该类别像素数比例的平均值。所以,从定义上看,这是精确率(Precision)的定义,MPA的计算公式如下:
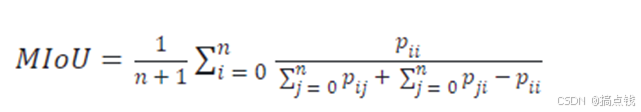
频权交并比(FWIoU)。 频权交并比顾名思义,就是以每一类别的频率为权重和其IoU加权计算出来的结果。FWIoU的设计思想很明确,语义分割很多时候会面临图像中各目标类别不平衡的情况,对各类别IoU直接求平均不是很合理,所以考虑各类别的权重就非常重要了。FWIoU的计算公式如下
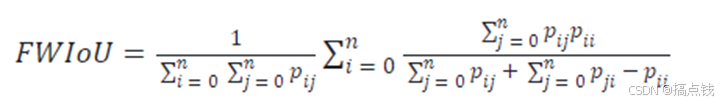
Dice系数。 Dice系数是一种度量两个集合相似性的函数,是语义分割中最常用的评价指标之一。Dice系数定义为两倍的交集除以像素和,跟IoU有点类似,其计算公式如下:
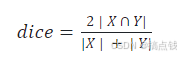
0.1常用语义分割数据集
Cityscapes(Cordts 等,2016)数据集是一个大规 模 的 城 市 街 景 语 义 理 解 数 据 集(https://www. cityscapes-dataset.com/)。Cityscapes 有 5 000 幅精细 注释图像(其中,2 975 幅用于训练,500 幅用于验 证,1 525幅用于测试)和20 000幅粗糙注释图像,所有图像分辨率均为 2 048 × 1 024像素,涵盖了 30个 不同的类别,其中19类用于语义分割。
CamVid(Brostow 等,2009)是第 1个稠密标注的 自 动 驾 驶 数 据 集(http://mi. eng. cam. ac. uk/research/ projects/VideoRec/CamVid/)。 CamVid 数 据 集 包 含 701幅车辆行驶视角的图像,来自英国剑桥的10 min 驾驶拍摄序列;其中包括 367 幅训练图像、101 幅验 证图像、233 幅测试图像,分辨率均为 960 × 720 像 素。CamVid 包含 32 个类别,其中 11 个类别用于语 义分割。
PASCAL VOC 2012(pattern analysis, statistical modeling and computational learning visual object classes)(Everingham 等 ,2015)数 据 集(http://host. robots.ox.ac.uk/pascal/VOC/voc2012/)包含了 20 个不 同的前景类别和 1 个背景类别,有 10 582 幅训练图 像、1 449幅验证图像、1 456幅测试图像。
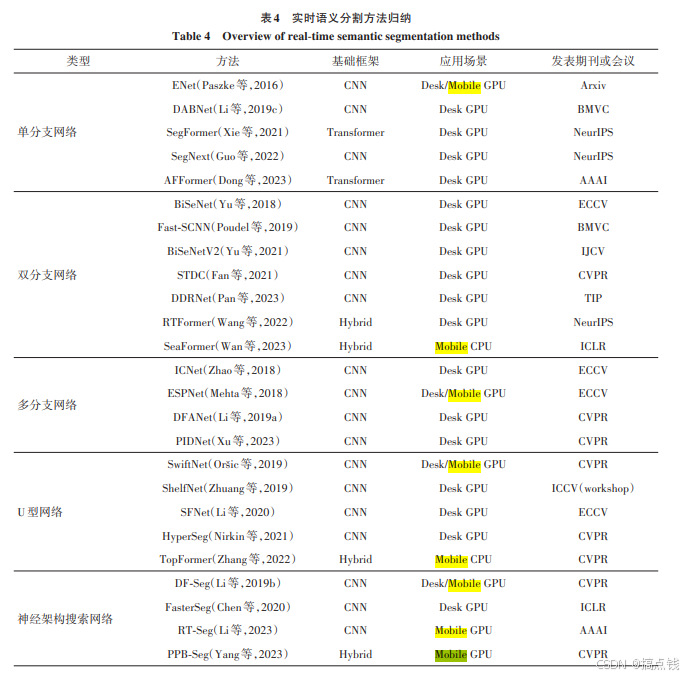
0.2常见模型(近五年的语义分割模型)
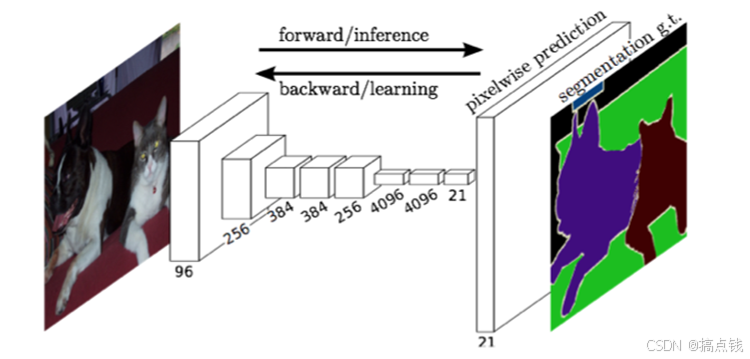
1.FCN模型2015
主要知识采用反卷积和全卷积层

2.Unet2015
主要只是也就是线性插值和双线性插值
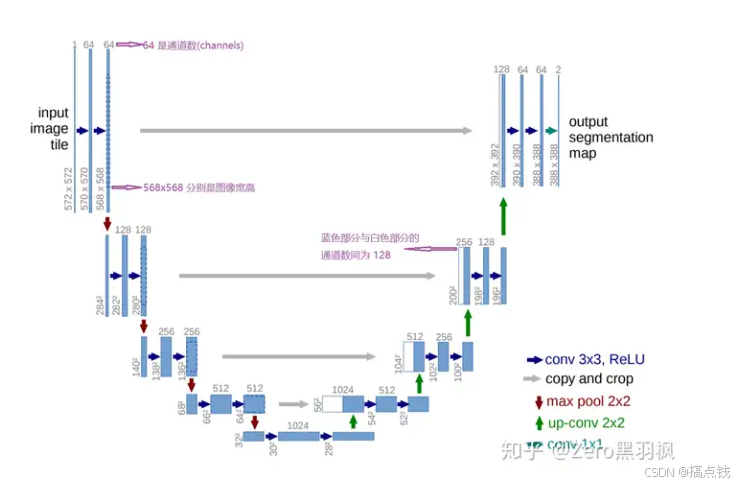

知乎Unet网络讲解 https://zhuanlan.zhihu.com/p/79204199
3.SegNet
理解就好,不多赘述
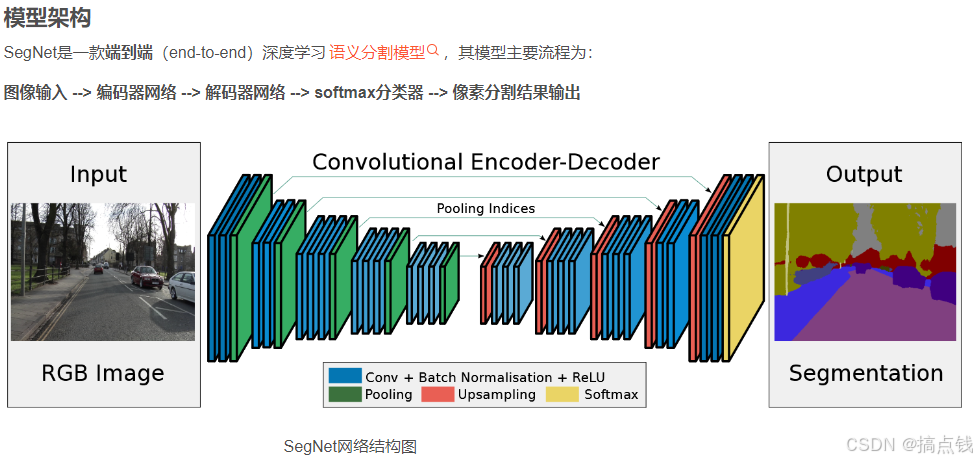
优点:提出编码和解码的思想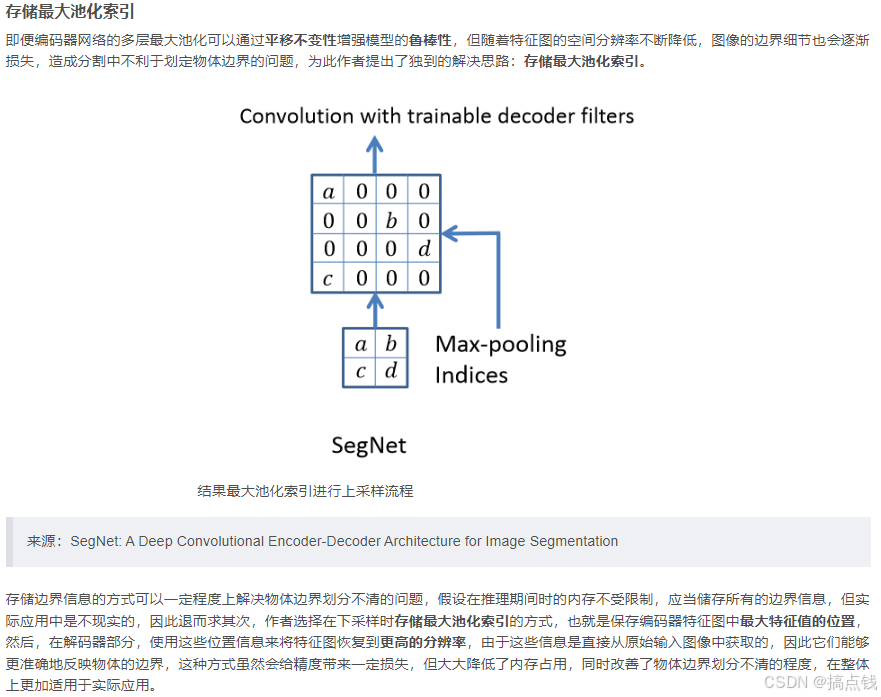
详情参考:SegNet:高效而精准的图像语义分割网络_语义分割segnet-CSDN博客
3.1反池化和反卷积
具体讲解参考 https://zhuanlan.zhihu.com/p/486008870
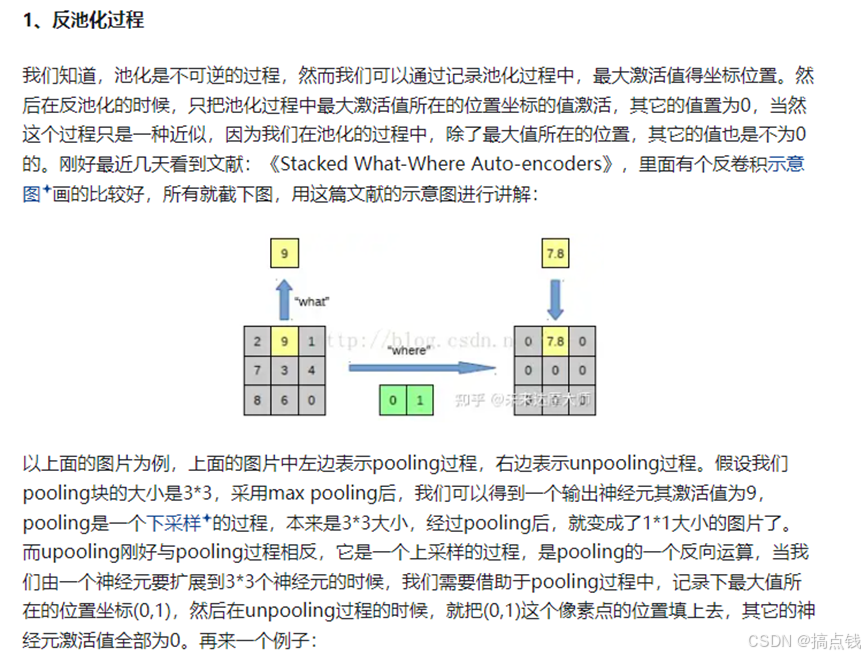
3.2条件随机场CRF
4.deeplab v1 2015
主要贡献
使用了空洞卷积;提出了在空间维度上实现金字塔型的空洞池化atrous spatial pyramid pooling(ASPP);使用了全连接条件随机场。
模型解释
空洞卷积在不增加参数数量的情况下增大了感受野,按照上文提到的空洞卷积论文的做法,可以改善分割网络。我们可以通过将原始图像的多个重新缩放版本传递到CNN网络的并行分支(即图像金字塔)中,或是可使用不同采样率(ASPP)的多个并行空洞卷积层,这两种方法均可实现多尺度处理。也可通过全连接条件随机场实现结构化预测,需将条件随机场的训练和微调单独作为一个后期处理步骤。
5.refinenetRefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation(2016/11/20)
主要贡献:
带有精心设计解码器模块的编码器-解码器结构;
所有组件遵循残差连接的设计方式。
模型解释
使用空洞卷积的方法也存在一定的缺点,它的计算成本比较高,同时由于需处理大量高分辨率特征图谱,会占用大量内存,这个问题阻碍了高分辨率预测的计算研究。
DeepLab得到的预测结果只有原始输入的1/8大小。
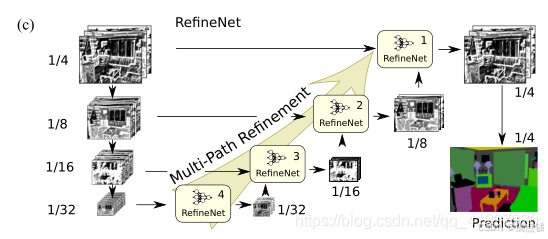
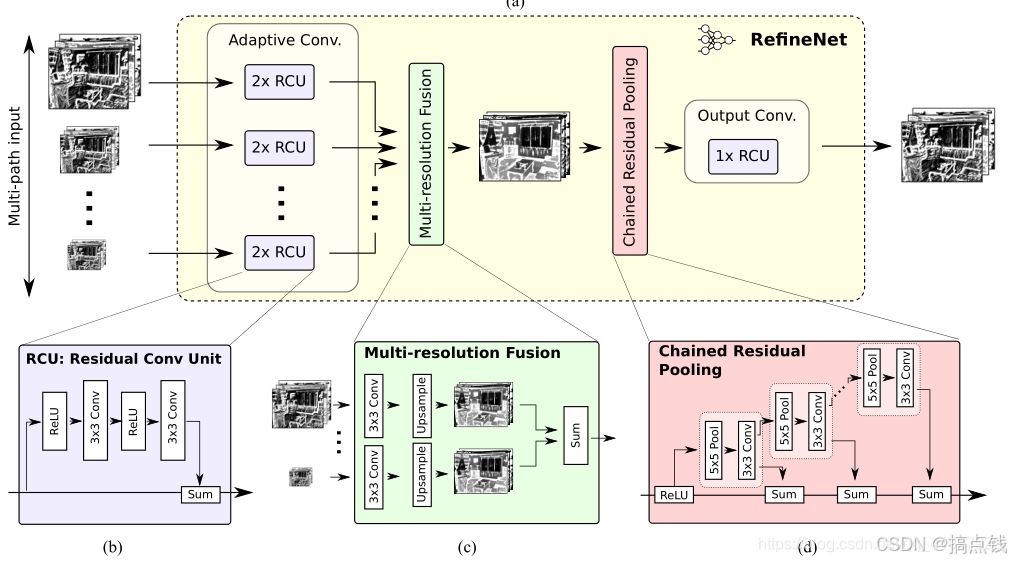
所以,这篇论文提出了相应的编码器-解码器结构,其中编码器是ResNet-101模块,解码器为能融合编码器高分辨率特征和先前RefineNet模块低分辨率特征的RefineNet模块。每个RefineNet模块包含一个能通过对较低分辨率特征进行上采样来融合多分辨率特征的组件,以及一个能基于步幅为1及5×5大小的重复池化层来获取背景信息的组件。
5.全景语义分割
5.1全景语义分割指标





















 2256
2256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









