






ThreadLocal
解决线程安全性问题。
ThreadLocal的使用
多线程环境下安全地使用日期格式化
public class ThreadLocalDemo {
//非线程安全的
private static final SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//创建一个ThreadLocal变量,用于存储每个线程的DateFormat对象
private static ThreadLocal<DateFormat> dateFormatThreadLocal=new ThreadLocal<>();
//获取当前线程的DateFormat对象,如果当前线程还没有设置过,就创建一个新的SimpleDateFormat对象并设置到ThreadLocal中
private static DateFormat getDateFormat(){
DateFormat dateFormat=dateFormatThreadLocal.get(); //从当前线程的范围内获得一个DateFormat
if(dateFormat==null){
dateFormat=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//Thread.currentThread();
dateFormatThreadLocal.set(dateFormat); //要在当前线程的范围内设置一个simpleDateFormat对象.
}
return dateFormat;
}
//解析字符串为日期对象的方法
public static Date parse(String strDate) throws ParseException {
return getDateFormat().parse(strDate);
}
public static void main(String[] args) {
ExecutorService executorService= Executors.newFixedThreadPool(10);
//创建20个任务,每个任务都会调用parse方法解析日期字符串
for (int i = 0; i < 20; i++) {
executorService.execute(()->{
try {
System.out.println(parse("2021-05-30 20:12:20"));
} catch (ParseException e) {
e.printStackTrace();
}
});
}
//关闭线程池
executorService.shutdown();
}
}
ThreadLocal的原理
set():在当前线程范围内,设置一个值存储到ThreadLocal中,这个值仅对当前线程可见。
相当于在当前线程范围内建立了副本。
get():从当前线程范围内取出set方法设置的值.
remove():移除当前线程中存储的值
withInitial:java8中的初始化方法
ThreadLocal原理猜想
- 能够实现线程的隔离,当前保存的数据,只会存储在当前线程范围内。-> 线程私有的
- 存储结构. ->
- key -> 当前线程
Thread Local 源码分析
public void set(T value) {
Thread t = Thread.currentThread();
// 如果当前线程已经初始化了map。
// 如果没有初始化,则进行初始化。
ThreadLocalMap map = getMap(t);
if (map != null) //修改value
map.set(this, value);
else //初始化
createMap(t, value);
}
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY]; //默认长度为16的数组
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); //计算数组下标
table[i] = new Entry(firstKey, firstValue); //把key/value存储到i的位置.
size = 1;
setThreshold(INITIAL_CAPACITY);
}
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1); //计算数组下标()
//线性探索.()
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
// i的位置已经存在了值, 就直接替换。
if (k == key) {
e.value = value;
return;
}
//如果key==null,则进行replaceStaleEntry(替换空余的数组)
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
}
- 把当前的value保存到entry数组中
- 清理无效的key
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
// Find either the key or trailing null slot of run, whichever
// occurs first
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// If we didn't find stale entry on backward scan, the
// first stale entry seen while scanning for key is the
// first still present in the run.
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// If key not found, put new entry in stale slot
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// If there are any other stale entries in run, expunge them
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
- 如果当前值对应的entry数组中key为null,那么该方法会向前查找到还存在key失效的entry,进行
清理。 - 通过线性探索的方式,解决hash冲突的问题。
内存泄漏的问题
通过上面的分析,我们知道 expungeStaleEntry() 方法是帮助垃圾回收的,根据源码,我们可以发现
get 和set 方法都可能触发清理方法 expungeStaleEntry() ,所以正常情况下是不会有内存溢出的 但
是如果我们没有调用get 和set 的时候就会可能面临着内存溢出,养成好习惯不再使用的时候调用
remove(),加快垃圾回收,避免内存溢出
退一步说,就算我们没有调用get 和set 和remove 方法,线程结束的时候,也就没有强引用再指向
ThreadLocal 中的ThreadLocalMap了,这样ThreadLocalMap 和里面的元素也会被回收掉,但是有一
种危险是,如果线程是线程池的, 在线程执行完代码的时候并没有结束,只是归还给线程池,这个时候
ThreadLocalMap 和里面的元素是不会回收掉的。
Fork/Join
package com.gupaoedu.concurrent;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
public class ForkJoinExample {
// 针对一个数字,做计算。
private static final Integer MAX = 200;
// 定义一个内部类继承RecursiveTask<Integer>,用于执行具体的计算任务
static class CalcForJoinTask extends RecursiveTask<Integer> {
private Integer startValue; // 子任务的开始计算的值
private Integer endValue; // 子任务结束计算的值
public CalcForJoinTask(Integer startValue, Integer endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
protected Integer compute() {
// 如果当前的数据区间已经小于MAX了,那么接下来的计算不需要做拆分
if (endValue - startValue < MAX) {
System.out.println("开始计算:startValue:" + startValue + " ; endValue:" + endValue);
Integer totalValue = 0;
for (int i = this.startValue; i <= this.endValue; i++) {
totalValue += i;
}
return totalValue;
}
// 拆分任务,将区间一分为二,创建两个子任务
CalcForJoinTask subTask = new CalcForJoinTask(startValue, (startValue + endValue) / 2);
subTask.fork();
CalcForJoinTask calcForJoinTask = new CalcForJoinTask((startValue + endValue) / 2 + 1, endValue);
calcForJoinTask.fork();
// 等待子任务完成并合并结果
return subTask.join() + calcForJoinTask.join();
}
}
public static void main(String[] args) {
// 创建一个计算任务实例,指定计算的起始值和结束值
CalcForJoinTask calcForJoinTask = new CalcForJoinTask(1, 10000);
// 创建一个ForkJoinPool线程池
ForkJoinPool pool = new ForkJoinPool();
// 提交任务到线程池执行
ForkJoinTask<Integer> taskFuture = pool.submit(calcForJoinTask);
try {
// 获取任务执行结果
Integer result = taskFuture.get();
System.out.println("result:" + result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
运行结果如下:
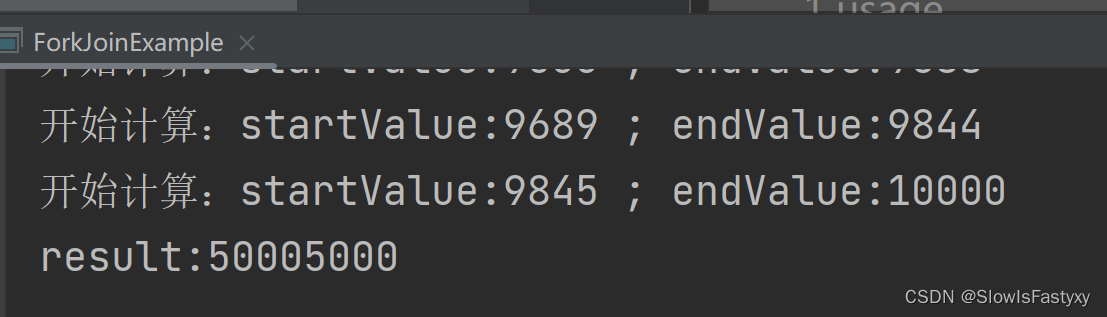
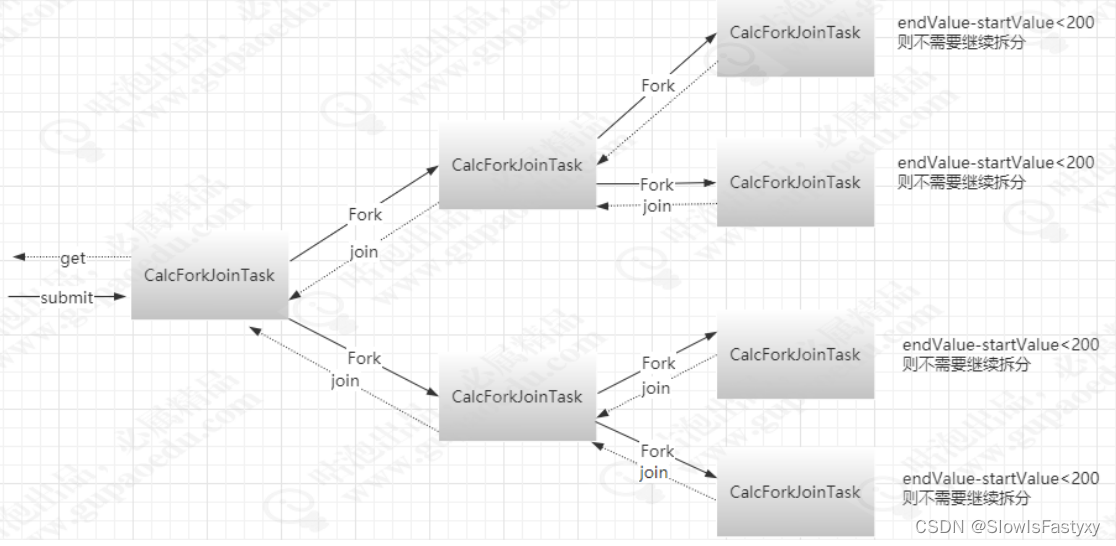
工作流程图
为了更清晰的了解fork/join的原理,我们通过一个图形来理解。整体思想其实就是拆分与合并。
图中最顶层的任务使用submit方式被提交到Fork/Join框架中,Fork/Join把这个任务放入到某个线程
中运行,工作任务中的compute方法的代码开始对这个任务T1进行分析。如果当前任务需要累加的数
字范围过大(代码中设定的是大于200),则将这个计算任务拆分成两个子任务(T1.1和T1.2),每个子任务各自负责计算一半的数据累加,请参见代码中的fork方法。如果当前子任务中需要累加的数字范围足够小(小于等于200),就进行累加然后返回到上层任务中。
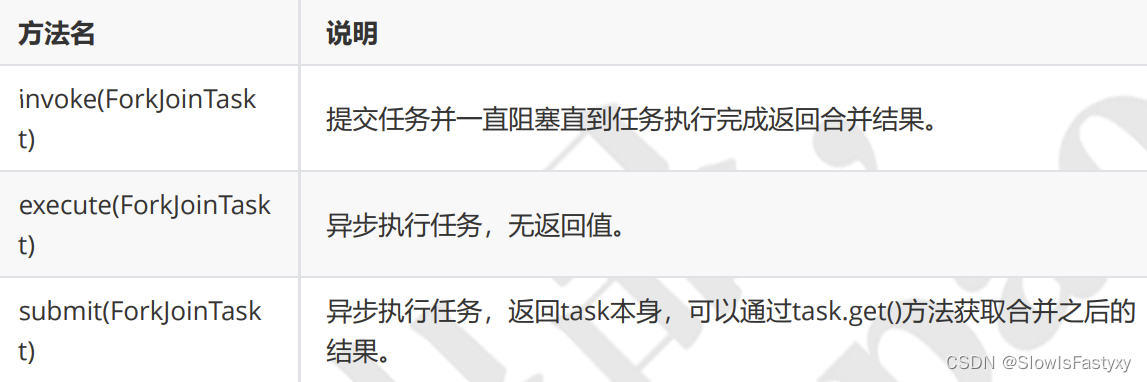
Fork/Join API代码分析
简单给大家解释一下Fork/Join的相关api,在刚刚的案例中,涉及到几个重要的API, ForkJoinTask ,
ForkJoinPool .
ForkJoinTask : 基本任务,使用fork、join框架必须创建的对象,提供fork,join操作,常用的三个子类
- RecursiveAction : 无结果返回的任务
- RecursiveTask : 有返回结果的任务
- CountedCompleter :无返回值任务,完成任务后可以触发回调。
ForkJoinTask提供了两个重要的方法:
- fork : 让task异步执行
- join : 让task同步执行,可以获取返回值
ForkJoinPool : 专门用来运行 ForkJoinTask 的线程池,(在实际使用中,也可以接收
Runnable/Callable 任务,但在真正运行时,也会把这些任务封装成 ForkJoinTask 类型的任务)
ForkJoinTask 在不显示使用 ForkJoinPool.execute/invoke/submit() 方法进行执行的情况下,也可
以使用自己的fork/invoke方法进行执行















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









