






1、空间统计基础
1.1空间统计概述
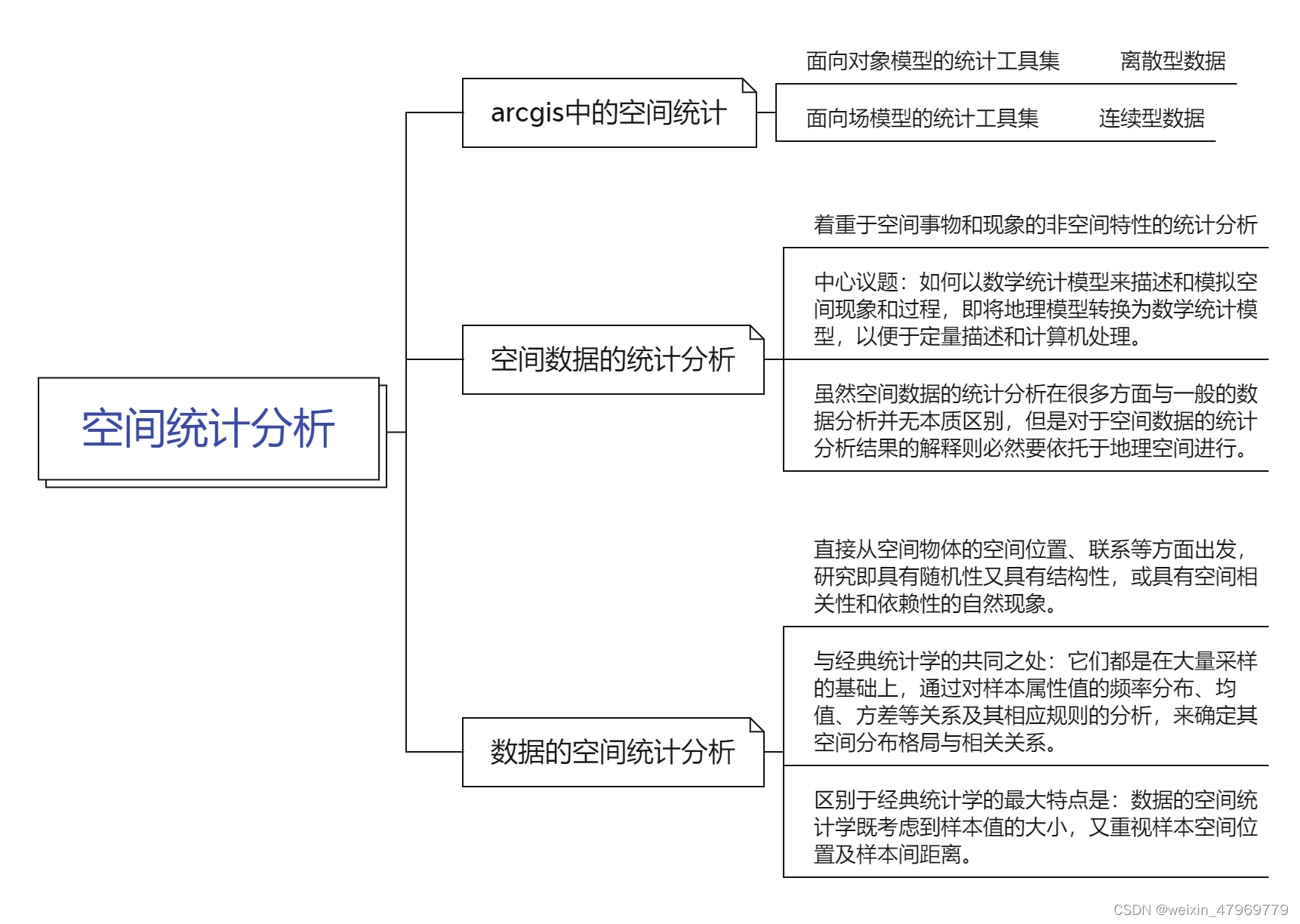
1.2空间自相关
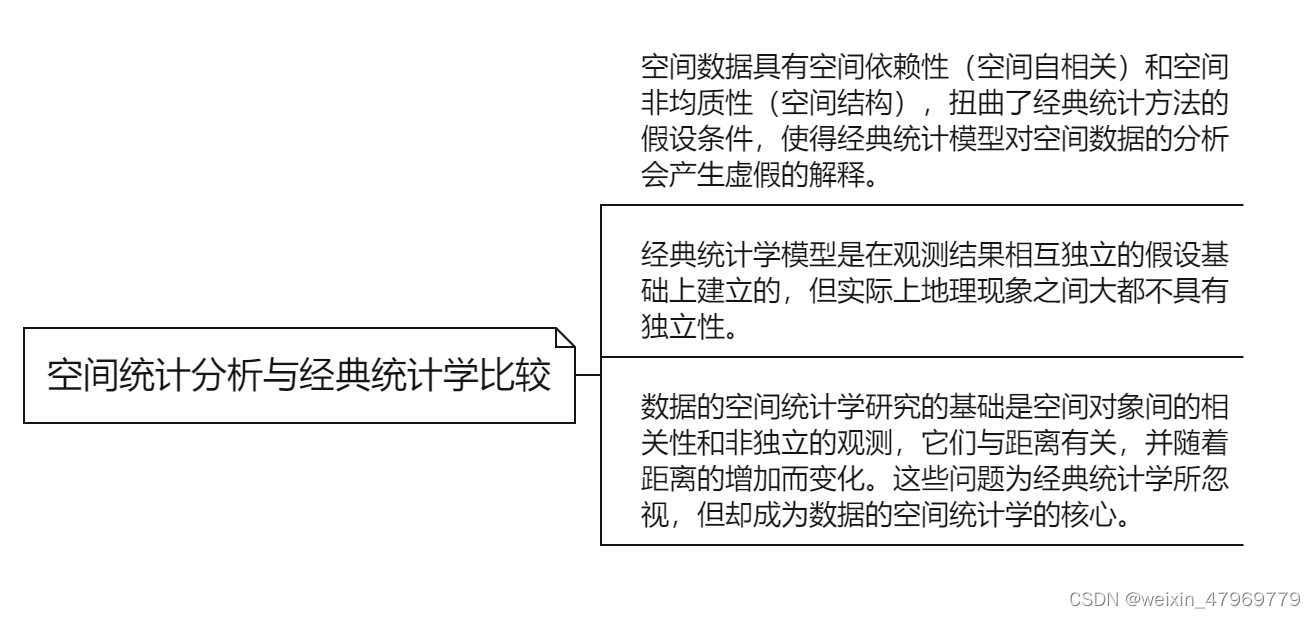
空间自相关是空间统计分析理论与方法构建的基础,也是地理学第一定律的主要呈现形式,即距离越近的地理事物越相似,而距离越远的地理事物差异越大。
1.2.1全局空间自相关
全局空间自相关是度量要素全局空间分布模式的分析模型。
全局空间自相关使用最广泛的模型为Global Moran's I,通过此指数,可以在全局层面度量地理要素所呈现的是聚类模式、随机模式还是离散模式。该工具通过计算 Moran's I 指数值、z得分和p值来对该指数的显著性进行评估。p值是根据已知分布的曲线得出的面积近似值(受检验统计量限制)。

(下面原本要讲的内容看不懂啦,所以补充点假设检验的知识)(122条消息) 统计学基础--假设检验_Andy_shenzl的博客-CSDN博客_假设检验
(122条消息) 让 P-value 更加的浅显易懂_rongbaohan的博客-CSDN博客_pvalue
在掌握了假设检验、零假设相关知识后,我们回到空间统计分析。
我们再来看之前提到的两个概念,在空间统计分析中什么是p值,什么是z得分?
大多数统计检验在开始时都首先确定一个零假设。模式分析工具的零假设是完全空间随机性 (CSR),它或者是要素本身的完全空间随机性,或者是与这些要素关联的值的完全空间随机性。模式分析工具所返回的 z 得分和 p 值可帮助您判断是否可以拒绝零假设(即说明具有空间相关性)。通常,您将运行其中一种模式分析工具,并希望 z 得分和 p 值表明可以拒绝零假设,这就意味着:您的要素(或与要素关联的值)表现出统计意义上的显著性聚类或离散模式,而不是随机模式。如果您在景观分布(或空间数据)中发现了空间结构(如聚类),就证明某些基础空间过程在发挥作用,而这方面通常正是地理学者或 GIS 分析人员所最为关注的。
p 值表示概率。对于模式分析工具来说,p 值表示所观测到的空间模式是由某一随机过程创建而成的概率。当 p 很小时,意味着所观测到的空间模式不太可能产生于随机过程(小概率事件),因此您可以拒绝零假设。您可能会问这样的问题:要小到什么程度才算足够小?这是一个非常好的问题。请参见下面的表和内容论述。
Z 得分表示标准差的倍数。例如,如果工具返回的 z 得分为 +2.5,我们就会说,结果是 2.5 倍标准差。如下所示,z 得分和 p 值都与标准正态分布相关联。
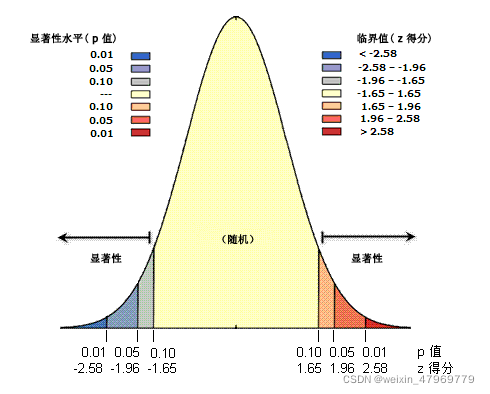
在正态分布的两端出现非常高或非常低(负值)的 z 得分,这些得分与非常小的 p 值关联。当您得到很小的 p 值以及非常高或非常低的 z 得分时,就表明观测到的空间模式不太可能反映零假设 (CSR) 所表示的理论上的随机模式(即拒绝零假设)。
要拒绝零假设,您必须对所愿承担的可能做出错误选择(即错误地拒绝零假设)的风险程度做出主观判断(即显著性)。因此,请先选择一个置信度,然后再执行空间统计。典型的置信度为 90%、95% 或 99%。这种情况下,99% 的置信度是最保守的,这表示您不愿意拒绝零假设,除非该模式是由随机过程创建的概率确实非常小(低于 1% 的概率)。
Global Moran's I 统计量所依据的数学公式如上所示。该工具计算所评估属性的均值和方差。然后,将每个要素值减去均值,从而得到与均值的偏差。将所有相邻要素(例如位于指定距离范围内的要素)的偏差值相乘,从而得到叉积。请注意,Global Moran's I 统计量的分子是这些叉积的和。假定要素 A 和 B 是相邻要素,并且所有要素值的均值为 10。请注意可能的叉积结果的范围:
| 要素值 | 偏差 | 叉积 | |||
| A=50 | B=40 | 40 | 30 | 1200 | |
| A=8 | B=6 | -2 | -4 | 8 | |
| A=20 | B=2 | 10 | -8 | -80 | |
如果相邻要素的值都大于或者都小于均值,则叉积将为正。如果一个要素值小于均值而另一个要素值大于均值,则叉积将为负。在所有情况下,与均值的偏差越大,叉积结果就越大。如果数据集中的值倾向于在空间上发生聚类(高值聚集在其他高值附近;低值聚集在其他低值附近),则 Moran's I 指数将为正。如果高值排斥其他高值,而倾向于靠近低值,则该指数将为负。如果正叉积值与负叉积值相抵消,则指数将接近于零。由于分子是通过方差进行归一化,因此该指数的值将落在 -1.0 到 +1.0 的区间内。
空间自相关 (Global Moran's I) 工具计算了指数值后,将计算期望指数值。然后,将期望指数值与观察指数值进行比较。在给定数据集中的要素个数和全部数据值的方差的情况下,该工具将计算 z 得分和 p 值,用来指示此差异是否具有统计学上的显著性。指数值不能直接进行解释,只能在零假设的情况下进行解释,如下:
解释
空间自相关 (Global Moran's I) 工具是一种推论统计,这意味着分析结果始终在零假设的情况下进行解释。对于 Global Moran's I 统计量,零假设声明,所分析的属性在研究区域内的要素之间是随机分布的;换句话说,用于促进观察值模式的空间过程是随机的。假设您可以为所分析的属性选择值,然后使这些值随意落到要素上,从而让每个值落在可能的位置。此过程(选择并随意放置值)便是随机空间过程的示例。
如果此工具返回的 p 值具有统计学上的显著性,则可拒绝零假设。下表对结果的解释进行了汇总:
| p 值不具有统计学上的显著性。 | 不能拒绝零假设。要素值的空间分布很有可能是随机空间过程的结果。观测到的要素值空间模式可能只是完全空间随机性 (CSR) 的众多可能结果之一。 |
| p 值具有统计学上的显著性,且 z 得分为正值。 | 可以拒绝零假设。如果基础空间过程是随机的,则数据集中高值和/或低值的空间分布在空间上聚类的程度要高于预期。 |
| p 值具有统计学上的显著性,且 z 得分为负值。 | 可以拒绝零假设。如果基础空间过程是随机的,则数据集中高值和低值的空间分布在空间上离散的程度要高于预期。离散空间模式通常会反映某种类型的竞争过程 - 具有高值的要素排斥具有高值的其他要素;类似地,具有低值的要素排斥具有低值的其他要素。 |
1.2.2局部空间自相关
局部空间自相关所使用的模型与全局自相关类似,其中最广泛的是Moran's I和G-Statistics(也叫Getis-Ord Gi* 统计(称为 G-i-星号)).这里以G-Statistics为例,基于G-Statistics,可以探测出一组地理要素的某个变量在空间上的热点区域和冷点区域,从而分析出局部区域的高值聚类区域和低值聚类区域。
通过热点探测可以分析出高值和低值聚类的边界在哪里,可以度量局部区域高值和低值聚类的程度。该模型会为每一个输出要素计算p值和z得分,从而定量表达高值聚类和低值聚类在特定置信区间内的聚类程度。计算公式如下:
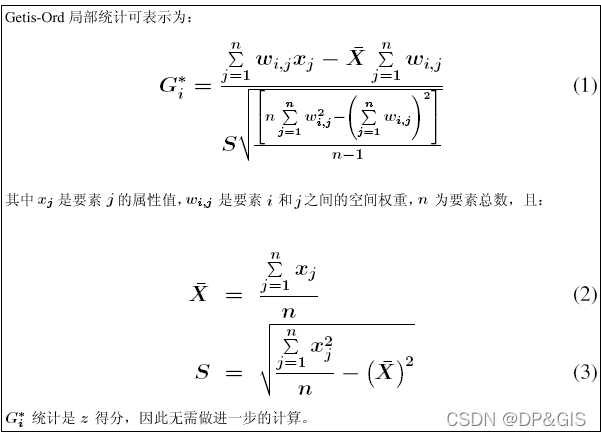
此工具的工作方式为:查看邻近要素环境中的每一个要素。高值要素往往容易引起注意,但可能不是具有显著统计学意义的热点。要成为具有显著统计需意义的热点,要素应具有高值,且被其他同样具有高值的要素所包围。某个要素及其相邻要素的局部总和将与所有要素的总和进行比较;当局部总和与所预期的局部总和有很大差异,以致于无法成为随机产生的结果时,会产生一个具有显著统计学意义的 z得分。
为数据集中的每个要素返回的 Gi* 统计就是 z 得分。对于具有显著统计学意义的正的 z 得分,z 得分越高,高值(热点)的聚类就越紧密。对于统计学上的显著性负 z 得分,z 得分越低,低值(冷点)的聚类就越紧密。
1.2.3协方差云与半变异函数
概念
连续型空间数据具有高程采样点、土壤湿度、气温等采样数据等,这些数据的一个显著特点是其属性值在空间上连续变化,难以像要素数据那样捕捉到边界。由于诸如Moran's I等空间自相关分析模型作用的对象必须是可以捕捉的,因此其对于连续型数据的实用性较差,也无法解决连续性数据的空间模拟需求。
在GIS中,对于场类型的空间数据,通常用半变异函数函数和协方差函数度量其空间自相关性。其实现方式是把统计相关系数的大小作为一个距离的函数,通过距离和属性的差异性度量其相关性。
半变异函数定义为:

S是不同位置上的数据点,Z是所要研究数据点的属性值。半变异函数解析图:
如果两个如果两个位置 si 和 sj,彼此之间的距离 d(si, sj) 很小,那么这两个位置会相似,同样,在地理学第一定律的保证下,两个位置上属性的差值 Z(si) - Z(sj) 也会很小。当d(si, sj) 逐渐增大时,它们变得越来越不相似,它属性值 Z(si) - Z(sj) 的差异也会增大。在下图中可以看到这一情况,其中显示了典型半变异函数解析图。
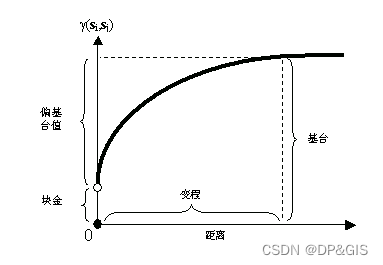
块金:代表区域化变量的随机性大小。从理论上讲,在零间距(步长=0)处,区域化变量采样点数值应当相等;而在间距无限趋于0时,对应的变异函数数值应当亦向0趋近。但是,在实际研究中,实验(经验)变异函数在间距为0时,其取值并不为0,而是一个大于0的常数。这一数值便成为块金常数,其产生一般可以归因与测量误差,或者小于采样间隔距离处的空间变化。
即当两个地理实体的距离趋于0时,理论上他们之间的差异会趋于0。但是由于测量误差与观测尺度的影响,经验变异函数的值并不会趋于0。
基台值:用以衡量区域化变量变化幅度的大小。当间距无限增大并达到某一程度以后,经验变异函数如果趋于平稳,则此时平稳水平对应的数值称为变程。然而,并不是所有的区域变量均具有基台值,如无基台模型对应的变异函数。
即当两个地理实体之间的距离很大时,它们之间也就不再空间相关性了,基台值就是存在与不存在空间相关性的距离阈值。
变程:用以衡量区域化变量自相关范围的大小。当间距无限增大并达到某一程度以后,经验变异函数如果趋于平稳,则此时对应的距离即为变程。其中,小于变程的距离所对应的样本位置与空间自相关,而大于变程的距离所对应样本位置不存在空间相关性。
经验半变异函数
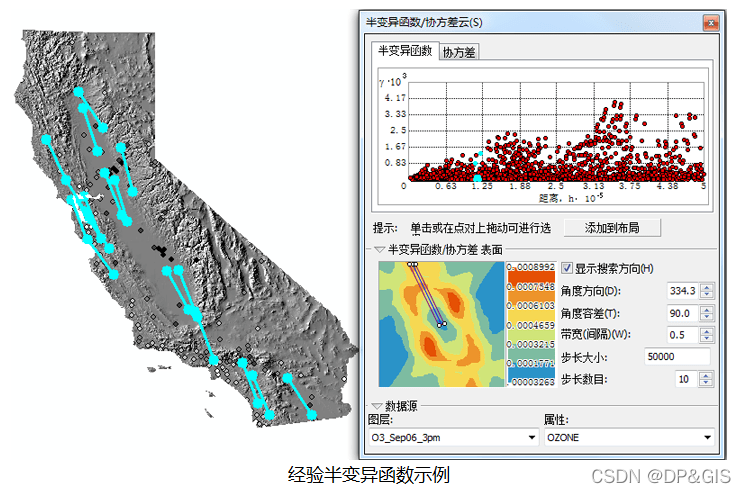
由于半变异函数和协方差函数是无法观察到的理论量测,因此可以使用经验半变异函数和经验协方差函数根据数据对它们进行估计。通常,通过查看这两个函数的估算方式可以对量测有所了解。假定采用了彼此之间的距离和方向都相似的所有数据对,如下图中通过蓝线连接的数据对。
对于彼此之间的距离和方向都相似的的所有位置对 si 和 sj,计算:
在绘制经验半变异函数时,首先要将数据集内的所有位置点按照某一距离组合成位置对,比如:A、B两点之间的距离为5m,A、C之间的距离为5m,B、C之间的距离也为5m,就可以生成3个位置对。所以如果数据集中存在n个点,则半变异函数/协方差云中就会显示n*(n-1)/2 个点。为此,不建议使用点数超过几千个的数据集。如果数据集包含几千个点,我们可以通过子集工具来随机选择点并在半变异函数/协方差云中使用该子集。
半变异函数云长这样子:
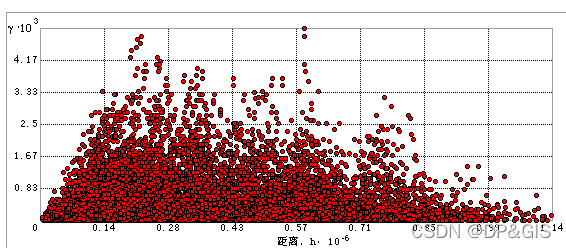
每个红点显示根据分隔两个数据点的距离绘制的经验半变异函数值(组成一对的两个数据点的值的平方差)。
所以,Z(si)-Z(sj)是所有具有相同d(s,s)的位置对包含的数据点其研究属性的差值,然后再求这些差值的var。
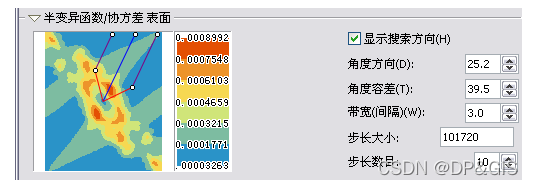
在上图中,仅仅体现了在距离限制下的位置对,通过搜索功能,还可以根据位置对的方向以及他们的距离来控制半变异函数的某个方向子集。
根据经验半变异函数拟合模型
地统计向导可提供经验半变异函数值的三种不同视图。可以使用任意数量(一个、两个或全部三个)的视图来帮助您根据数据拟合模型。默认视图显示了已丢弃和已平均化的经验半变异函数/协方差值。
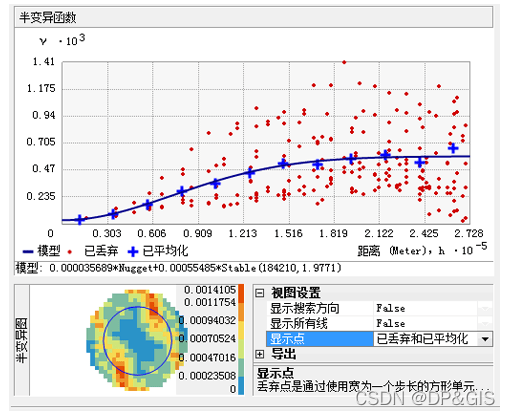
已丢弃值显示为红色的点,是通过使用宽为一个步长的方形像元将经验半变异函数/协方差点组合(分组)在一起后生成的。平均点显示为蓝色的十字符号,是通过将处于圆周分区内的经验半变异函数/协方差点进行分组后生成的。丢弃点显示半变异函数/协方差值中的局部变化,而平均值显示半变异函数/协方差值的平滑变化。在很多情况下,根据平均值拟合模型会更容易一些,因为它们将为数据中的空间自相关提供相对简洁的视图,与丢弃点相比,平均值将显示的半变异函数值的变化更为平滑。
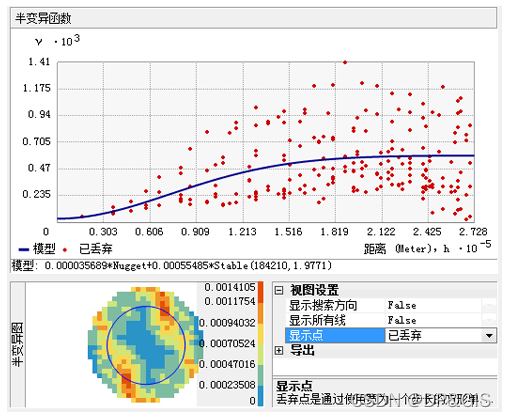
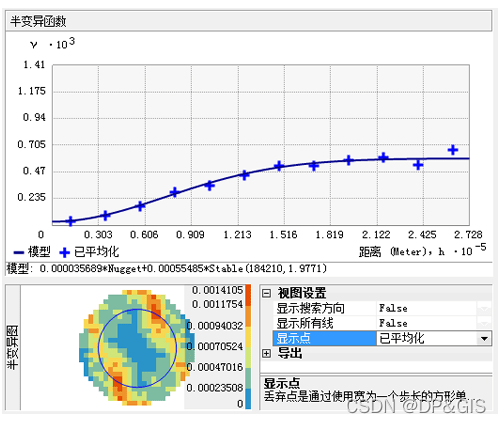
显示点控件可以设置为“已丢弃和已平均化”(如上图所示)、“已丢弃”或“已平均化”(如下图所示)。
此外,可通过显示所有线选项将绿线添加到图中。这些线是根据已丢弃的经验半变异函数/协方差值进行拟合的局部多项式。如果将显示搜索方向选项设置为 True,则只会显示根据“显示搜索方向”工具的中轴样带中经验半变异函数/协方差表面拟合的局部多项式,如下图所示:
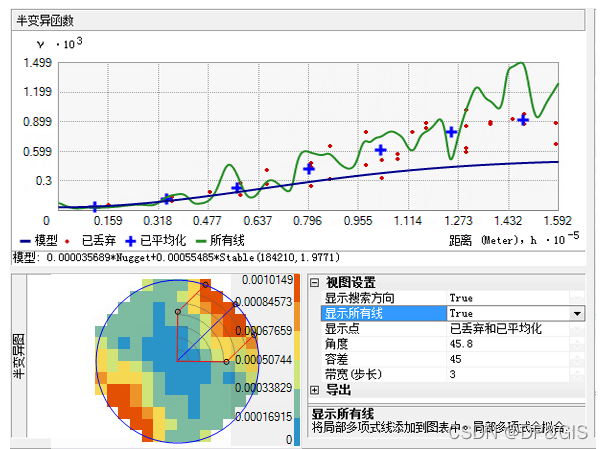
根据经验数据拟合的半变异函数/协方差模型应该:
- 穿过已丢弃值(红色的点)云的中心。
- 穿过尽可能接近平均值(蓝色的十字符号)的位置。
- 穿过尽可能接近线(绿色的线)的位置。
请记住,如果模型似乎没有完全拟合经验数据,您对现象的认识也可以决定模型的形状和块金以及变程值、偏基台值和各向异性值(回想一下,经验数据只是要构建的真实现象模型的样本,并不能完全代表真实现象的所有空间和统计方面)。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









