




博客导读:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(四):一文入门pytorch开发
AI智能体研发之路-模型篇(五):pytorch vs tensorflow框架DNN网络结构源码级对比
目录
一、引言
上一篇AI智能体研发之路-模型篇(四):一文入门pytorch开发介绍如何使用pytorch实现一个简单的DNN网络,今天我们还是用同样的例子,看看使用tensorflow如何实现。
二、tensorflow介绍
2.1 tensorflow历史
TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud在内的多个项目以及各类应用程序接口(Application Programming Interface, API)。自2015年11月9日起,TensorFlow依据阿帕奇授权协议(Apache 2.0 open source license)开放源代码。
2.2 tensorflow特点
深度学习时代,tensorflow在工业应用较为广泛,而pytorch更多应用于研究中。大模型时代,pytorch是很多项目的底层库,大有超过tensorflow的趋势。可谓并驾齐驱。
- 生态系统更成熟:TensorFlow拥有一个庞大的社区和丰富的资源,包括大量的教程、预训练模型和工具,适合从初学者到专家的各个层次用户。
- 生产部署友好:TensorFlow支持更多的平台和设备,包括移动设备和边缘设备,提供了TensorFlow Lite和TensorFlow.js等,便于模型的部署和优化。
- 静态图与动态图的结合:虽然早期TensorFlow以静态图为主,但TensorFlow 2.x引入了Eager Execution,结合了动态图的易用性和静态图的高性能,同时保持了模型的可部署性。
- Keras集成:TensorFlow内建了Keras,这是一个高级神经网络API,使得模型构建、训练和评估更加简洁直观。
- TensorBoard:TensorFlow自带的可视化工具TensorBoard,便于可视化模型结构、训练过程中的损失和指标,帮助用户更好地理解和调试模型。
- 广泛的工业应用支持:由于其成熟度和稳定性,TensorFlow在工业界得到了广泛的应用,特别是在大型企业中。
2.3 tensorflow安装
与pytorch一样,还是采用conda创建环境,采用pip安装tensorflow包
1.建立名为pytrain,python版本为3.11的conda环境(这里与pytorch一样)
conda create -n pytrain python=3.11
conda activate pytrain
2.采用pip下载tensorflow以及机器学习常用的scikit-learn和numpy包
pip install tensorflow scikit-learn numpy -i https://mirrors.cloud.tencent.com/pypi/simple
这里未指定版本,默认下载最新版本tensorflow-2.16.1以及其他tensorboard等生态包。
三、tensorflow实战
动手实现一个三层DNN网络:
3.1 引入依赖的tensorflow库
这里主要是tensorflow、keras、sklearn、numpy等
Keras是一个用于构建和训练深度学习模型的高级API,它设计得极其用户友好,支持快速实验。Keras可以运行在TensorFlow之上。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import BinaryCrossentropy
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np3.2 训练数据准备
这里采用numpy库进行数据随机生成
# 假设你已经有了特征数据 X 和标签数据 y
# X, y = ... # 实际数据加载和预处理步骤
# 这里我们用随机数据作为示例
np.random.seed(0)
X = np.random.rand(1000, 1000) # 1000个样本,每个样本1000个特征
y = np.random.randint(0, 2, size=(1000, 1)) # 二分类标签
# 数据预处理,标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
- 首先,采用numpy的random随机生成X矩阵(1000行样本*1000行特征)和y矩阵(1000行0或1的label)
- 其次,采用sklearn库中的StandardScaler将X矩阵中的每个样本特征数值标准化(将每个特征都转换为正态分布,均值为0,标准差为1),这一步骤对于机器学习算法的性能至关重要,特别是那些对输入数据的尺度敏感的算法。
- 最后,按照2:8的比例从数据中切分出测试机与训练集
3.3 创建三层DNN模型
采用keras.sequential类,顾名思义“按顺序的”由输入至输出编排神经网络
# 创建模型
model = Sequential([
Dense(512, input_shape=(X_train.shape[1],)), # 第一层
Activation('relu'),
Dense(512), # 第二层
Activation('relu'),
Dense(1), # 输出层
Activation('sigmoid') # 二分类使用sigmoid
])Sequential是Keras中用于构建深度学习模型的一个类,特别适合于构建线性的堆叠层模型。这种模型结构是层与层直接相连,没有复杂的拓扑结构,适合于解决如图像分类、文本分类等任务
特点:
- 线性堆叠:层按照添加的顺序堆叠,每一层只与前一层有连接。
- 易于使用:适合初学者和快速原型设计,对于复杂的网络结构可能不够灵活。
- 灵活性限制:对于需要多输入或多输出,或者层间有复杂连接的模型,应使用更高级的模型结构,如Functional API。
3.4 编译模型、定义损失函数与优化器
不同于pytorch的实例化模型对象,这里采用compile对模型进行编译。与pytorch相同点是都要定义损失函数和优化器,方法与技巧完全相同。
# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001),
loss=BinaryCrossentropy(),
metrics=['accuracy'])
optimizer=Adam(learning_rate=0.001):这里选择了Adam作为优化器。Adam(Adaptive Moment Estimation)是一种常用的优化算法,它结合了RMSprop和Momentum的优点,能够自动调整学习率。通过设置learning_rate=0.001,可以控制模型学习的速度。学习率是训练过程中的一个重要超参数,影响模型收敛的速度和最终的性能。loss=BinaryCrossentropy():损失函数设置为二元交叉熵(Binary Crossentropy)。这个损失函数适用于二分类问题,它衡量了模型预测的概率分布与实际标签之间的差异。在二分类任务中,正确选择损失函数对于模型的性能至关重要。metrics=['accuracy']:指定评估模型性能的指标。这里使用的是准确率(accuracy),即分类正确的比例。在训练和验证过程中,除了损失值外,还会计算并显示这个指标,帮助我们了解模型的性能。
3.5 启动训练,迭代收敛
不同于pytorch需要写两个循环处理每一行样本,tensorflow直接采用fit方法对输入的特征样本矩阵以及label矩阵进行训练
tensorflow版:
# 训练模型
history = model.fit(X_train, y_train, epochs=100,
validation_split=0.1, # 使用10%的数据作为验证集
verbose=1)pytorch版:
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):
model.train() # 设置为训练模式
running_loss = 0.0
for i, (inputs, labels) in enumerate(data_loader, 0):
optimizer.zero_grad() # 清零梯度
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward() # 反向传播
optimizer.step() # 更新权重
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(data_loader)}')对比来看,pytorch版的更加透明,有助于理解,tensorflow更加便捷
运行后可以看到loss逐步收敛: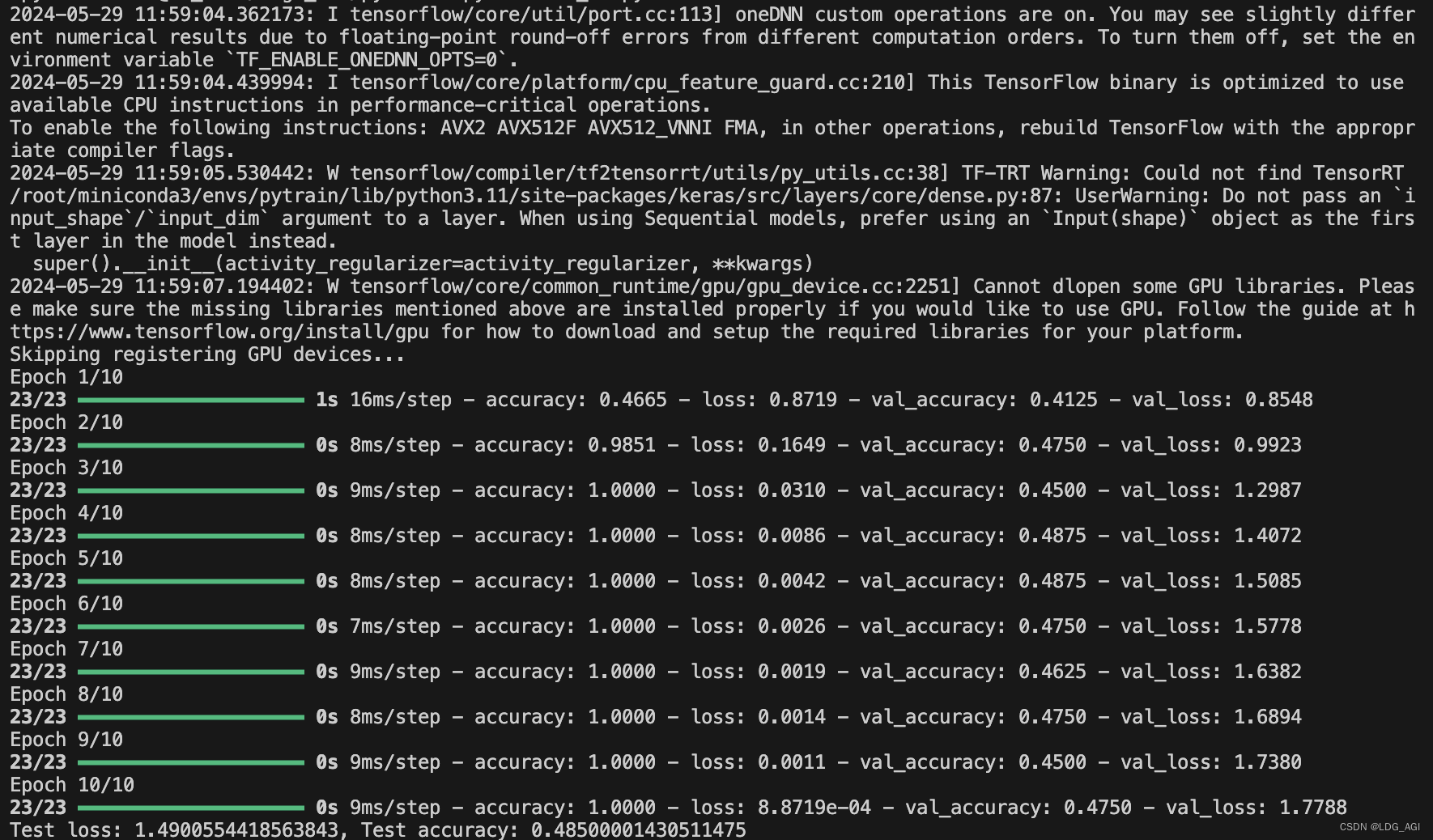
3.6 模型评估
通过model.evaluate对模型进行评估,evaluate与fit的区别是只计算指标不进行模型更新
tensorflow版:
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f'Test loss: {loss}, Test accuracy: {accuracy}')pytorch版:
import torchmetrics # 导入torchmetrics
test_num_samples = 200 # 测试样本数
test_X_train = torch.randn(test_num_samples, input_size)
test_y_train = torch.randint(0, output_size, (test_num_samples,))
# 数据加载
test_dataset = TensorDataset(test_X_train,test_y_train)
test_data_loader = DataLoader(test_dataset, batch_size=32, shuffle=True)
# 在模型训练完成后进行评估
# 首先,我们需要确保模型在评估模式下
model.eval()
# 初始化准确率和召回率的计算器
accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=output_size)
recall = torchmetrics.Recall(task="multiclass", num_classes=output_size)
with torch.no_grad(): # 确保在评估时不进行梯度计算
for inputs, labels in test_data_loader:
outputs = model(inputs)
preds = torch.softmax(outputs, dim=1)
# 更新指标计算器
accuracy.update(preds, labels)
recall.update(preds, labels)
# 打印准确率和召回率
print(f'Accuracy: {accuracy.compute():.4f}')
print(f'Recall: {recall.compute():.4f}')
print('Evaluation finished.')对比pytorch需要写一个循环,tensorflow.keras的封装更为简洁
运行后,可以输出模型的准确率与召回率,由于采用随机生成的测试数据且迭代轮数较少,具体数值不错参考,可以根据自己需要丰富数据。

3.7 可以直接跑的代码
与上一篇AI智能体研发之路-模型篇(四):一文入门pytorch开发一样,附可以直接运行的代码,先跑起来,再一行行研究!
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import BinaryCrossentropy
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
# 假设你已经有了特征数据 X 和标签数据 y
# X, y = ... # 实际数据加载和预处理步骤
# 这里我们用随机数据作为示例
np.random.seed(0)
X = np.random.rand(1000, 1000) # 1000个样本,每个样本1000个特征
y = np.random.randint(0, 2, size=(1000, 1)) # 二分类标签
# 数据预处理,标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建模型
model = Sequential([
Dense(512, input_shape=(X_train.shape[1],)), # 第一层
Activation('relu'),
Dense(512), # 第二层
Activation('relu'),
Dense(1), # 输出层
Activation('sigmoid') # 二分类使用sigmoid
])
# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001),
loss=BinaryCrossentropy(),
metrics=['accuracy'])
# 训练模型
history = model.fit(X_train, y_train, epochs=10,
validation_split=0.1, # 使用10%的数据作为验证集
verbose=1)
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f'Test loss: {loss}, Test accuracy: {accuracy}')
四、总结
本文先对tensorflow深度学习框架历史、特点及安装方法进行介绍,接下来基于tensorflow带读者一步步开发一个简单的三层神经网络程序,最后附可执行的代码供读者进行测试学习。个人感觉tensorflow封装程度高于pytorch,网络结构也更加清晰,但pytorch更加透明。
喜欢的话期待您的关注、点赞、收藏,您的互动是对我最大的鼓励!
如果还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战



















 638
638













 到【灌水乐园】发言
到【灌水乐园】发言







