






主要用于保存记录,来源B站视频跟着大佬做的。
实现效果:
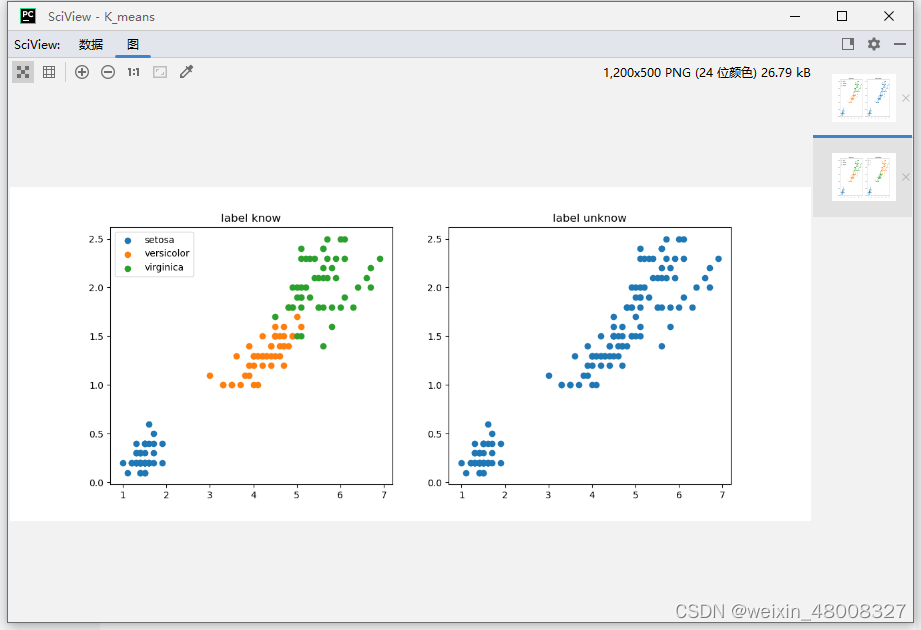
1.原始数据分类 2.原始数据未分类
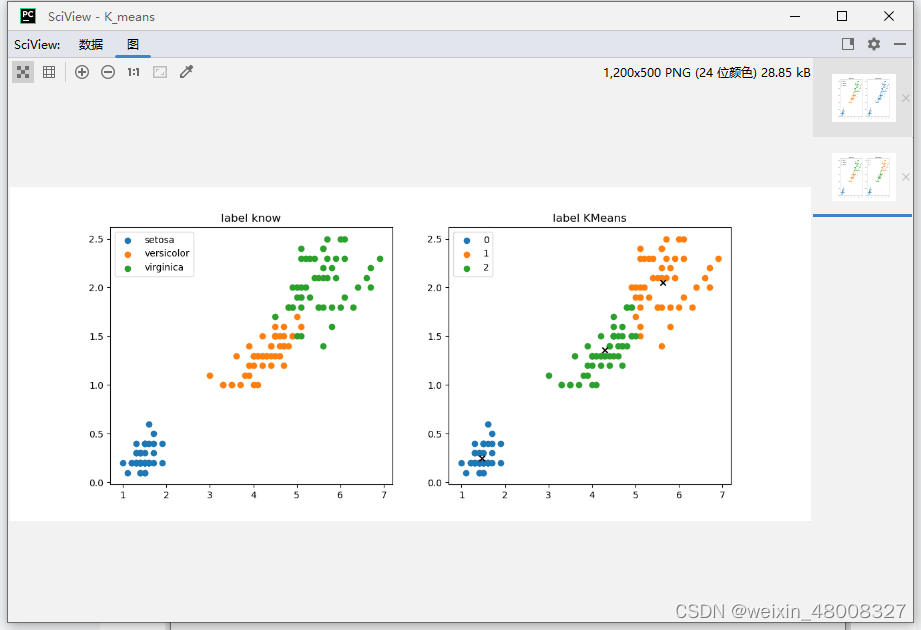
1.原始数据分类 2.数据聚类后(‘x’是每个聚类的中心)
demo:
### demo
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from k_means import KMeans
# 导入数据
data = pd.read_csv("./iris.csv")
iris_types = ['setosa','versicolor','virginica'] # 数据类别
x_axis = 'Petal_Length' #x轴
y_axis = 'Petal_Width' #Y轴
# 图的大小
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
for iris_type in iris_types: # 遍历每种花
plt.scatter(data[x_axis][data['Species']==iris_type],data[y_axis][data['Species']==iris_type],label=iris_type)
plt.title('label know')
plt.legend()
plt.subplot(122)
plt.scatter(data[x_axis][:],data[y_axis][:])
plt.title('label unknow')
plt.show()
num_examples = data.shape[0] #样本个数
x_train = data[[x_axis,y_axis]].values.reshape(num_examples, 2)#将data的x,y轴数据转换成ndarry格式,并reshape,赋给x_train
#指定好训练所需的参数
num_clusters = 3
max_iterition = 50
KMeans = KMeans(x_train,num_clusters)
centroids, closest_centroids_ids = KMeans.train(max_iterition)
#画图对比
plt.figure(figsize=(12,5)) # 图的大小
plt.subplot(1,2,1)
for iris_type in iris_types: # 遍历每种花
plt.scatter(data[x_axis][data ['Species']==iris_type],data[y_axis][data['Species']==iris_type],label=iris_type)
plt.title('label know')
plt.legend()
plt.subplot(1,2,2)
for centroids_id, centroid in enumerate(centroids):
current_examples_index = (closest_centroids_ids == centroids_id).flatten()
plt.scatter(data[x_axis][current_examples_index], data[y_axis][current_examples_index], label=centroids_id)
for centroids_id, centroid in enumerate(centroids):
plt.scatter(centroid[0],centroid[1],c='black',marker='x')
plt.title('label KMeans')
plt.legend()
plt.show()K_means.py:
### K_means
import numpy as np
# closest_centroids_ids里面存的是什么? ——>存的是每个数据距离中心点最小距离的簇的索引(1,2,3,...,K)
class KMeans:
def __init__(self, data, num_clustres): # 数据、K值
self.data = data
self.num_clustres = num_clustres
def train(self, max_iterations): # 最大迭代次数
# 1在当前数据中,初始化随机选择K个中心点
centroids = KMeans.centroids_init(self.data, self.num_clustres)
# 2开始训练
# 计算每个点到K个中心点的距离
num_examples = self.data.shape[0] # 数据个数
closest_centroids_ids = np.empty((num_examples, 1)) # 创建空数组,存放寻找的最近的中心点
for _ in range(max_iterations): # 迭代max_iterations次
# 3得到当前每个样本点到K个中心点的距离,找到最近的距离id
closest_centroids_ids = KMeans.centroids_find_closest(self.data, centroids) # 数据、中心点
# 4进行中心点位置更新:closest_centroids_ids距离谁最近就属于哪个堆
centroids = KMeans.centroids_computer(self.data, closest_centroids_ids, self.num_clustres) #数据、当前数据距离哪个点最近
return centroids, closest_centroids_ids
@staticmethod
# num_clustres()方法:初始化随机的寻找当前data的num_clustres个中心点
def centroids_init(data, num_clustres):
num_examples = data.shape[0] # 数据个数
random_ids = np.random.permutation(num_examples) # permutation:将数据随机排序
# random_ids[:num_clustres]:选择从0到num_clustres个数据,前num_clustres个;后面的:表示所有的数据特征
data = np.array(data)
centroids = data[random_ids[:num_clustres], :] # 选取后作为中心点
return centroids
@staticmethod
# 计算距离中心的的最近的距离,存储在closest_centroids_ids中,返回
def centroids_find_closest(data, centroids):
# 计算方法:eg.欧氏距离
num_examples = data.shape[0] # 数据个数
num_centroids = centroids.shape[0] # 簇的个数:K
closest_centroids_ids = np.zeros((num_examples, 1)) # 用于存储每个样本点距离簇最近的那一个
for examples_index in range(num_examples):
distance = np.zeros((num_centroids, 1)) # 存储每个样本点对K个簇的distance值
for centroids_index in range(num_centroids):
# 计算距离:数据点的坐标值-中心点的坐标值
data = np.array(data)
distance_diff = data[examples_index, :4] - centroids[centroids_index, :4]
distance[centroids_index] = np.sum(distance_diff ** 2)
# 对当前的样本找到距离最近的那个簇
closest_centroids_ids[examples_index] = np.argmin(distance) # np.argmin()返回最小值索引
return closest_centroids_ids
@staticmethod
# 更新closest_centroids_ids里面距离谁最近,就放在哪个堆(簇)
def centroids_computer(data, closest_centroids_ids, num_clustres):
num_features = data.shape[1] # 输入的数据的特征个数
# num_features: 用于各个特征分别算均值
centroids = np.zeros((num_clustres,num_features)) # 簇的个数、特征个数
for centroids_id in range(num_clustres):
###如何运行的?
closest_ids = closest_centroids_ids == centroids_id
centroids[centroids_id] = np.mean(data[closest_ids.flatten(),:], axis=0)
return centroids













 1807
1807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









