







预训练语言模型实现与应用
1 任务目标
1.1 案例简介
2018年,Google提出了预训练语言模型BERT,该模型在各种NLP任务上都取得了很好的效果。与此同时,它的使用十分方便,可以快速地对于各种NLP任务进行适配。因此,BERT已经被广泛地使用到了各种NLP任务当中。在本案例中,我们会亲手将BERT适配到长文本关系抽取任务DocRED上,从中了解BERT的基本原理和技术细节。关系抽取是自然语言处理领域的重要任务,DocRED中大部分关系需要从多个句子中联合抽取,因此需要模型具备较强的获取和综合文章中信息的能力,尤其是抽取跨句关系的能力。
1.2 BERT
BERT是目前最具代表性的预训练语言模型,如今预训练语言模型的新方法都是基于BERT进行改进的。研究者如今将各种预训练模型的使用代码整合到了transformers这个包当中,使得我们可以很方便快捷地使用各种各样的预训练语言模型。在本实验中,我们也将调用transformers来使用BERT完成文档级别关系抽取的任务。基于transformers的基础后,我们的主要工作就是将数据处理成BERT需要的输入格式,以及在BERT的基础上搭建一个能完成特定任务的模型。在本次实验中,我们的重点也将放在这两个方面。首先是对于数据的处理,对于给定的文本,我们需要使用BERT的tokenizer将文本切成subword,然后转换成对应的id输入进模型中。通常来说这个过程是比较简单的,但是针对于DocRED这个任务,我们需要有一些额外注意的事情。文档级关系抽取的目标是从一段话中确定两个实体之间的关系,为了让模型知道我们关心的两个实体是什么,我们需要在文本中插入四个额外的符号,将实体标注出来。与此同时,BERT模型是一个语言模型,为了能使其适配关系抽取任务,我们需要加入额外的神经网络,使得模型能够进行关系预测。通常来说这个神经网络就是将文本中的第一个字符拿出来输入到一个线性层中进行分类。
1.3 数据和代码
本案例使用了DocRED的数据,并提供了一个简单的模型实现,包括数据的预处理、模型的训练、以及简单的评测。数据预处理的代码在 gen_data.py 里。在处理完数据之后,再运行 train.py 进行训练,训练流程的代码在 config/Config.py 里。注意由于预训练模型很大,因此需要调整batch size使得GPU能够放得下,于此同时为了提高batch size的绝对大小,可以使用梯度累积的技术。
以上代码是完整实现好的,我们需要同学对 gen_data.py 和 config/Config.py 中用 # question 标识的20余个问题进行回答,并运行模型,测试模型在有100% / 50% / 10% training data(通过随机sample原training set一部分的数据,10%代表低资源的设定)的情况下模型在dev set上的效果(如果服务器资源有限,也可以只测试10%的结果,并在报告中提及)
1.4 评分要求
分数由两部分组成。首先,回答代码文件中标识的问题,并且训练模型,评测模型在开发集上的结果,这部分占80%,评分依据为模型的开发集性能和问题的回答情况。第二部分,进行进一步的探索和尝试,我们将在下一小节介绍可能的尝试。同学需要提交代码和报告,在报告中对于两部分的实验都进行介绍,主要包括开发集的结果以及尝试的具体内容。
1.5 探索和尝试
完成对于测试数据的评测,并且提交到DocRED的评测系统中。(推荐先完成该任务,主要考察同学将模型真正应用起来的能力)
使用别的预训练语言模型完成该实验,例如RoBERTa等。
对于模型进行改进,提升关系抽取的能力,这里可以参考一些DocRED最新工作,进行复现。
1.6 参考资料
DocRED: A Large-Scale Document-Level Relation Extraction Dataset. ACL 2019.
NLP_Novice/4.预训练语言模型实现与应用(DocRED) at master · yingcongshaw/NLP_Novice (github.com)
2 数据集
2.1 DocRED数据集
本案例使用了DocRED的数据,DocRED (Document-Level Relation Extraction Dataset) 是一个用于关系抽取任务的数据集,是目前最大的文档级别关系抽取数据集之一,主要用于从给定的文档中抽取实体之间的关系。数据集分别由以下文件组成:
-
dev.json该文件包含开发集(验证集),用于在模型训练过程中进行参数调优和性能评估。文件格式如下:
-
vertexSet: 实体列表,每个实体包含多个提及(mention)。每个提及包含以下信息:
-
name: 实体名称 -
pos: 实体在句子中的位置(起始索引和结束索引) -
sent_id: 实体所在的句子的索引 -
type: 实体类型(如ORG,LOC,PER,TIME, 等)
-
-
labels: 关系标签,仅在训练和开发集中提供。每个关系标签包含以下信息:
-
r: 关系ID -
h: 关系的头实体索引 -
t: 关系的尾实体索引 -
evidence: 支持该关系的证据句子的索引
-
-
title:文档的标题 -
sents:这是一个列表的列表,每个内层列表表示文档中的一个句子。每个句子是一个单词/标记的列表。
示例:
{ "vertexSet": [ [ {"pos": [0, 4], "type": "ORG", "sent_id": 0, "name": "Zest Airways, Inc."}, {"sent_id": 0, "type": "ORG", "pos": [10, 15], "name": "Asian Spirit and Zest Air"}, {"name": "AirAsia Zest", "pos": [6, 8], "sent_id": 0, "type": "ORG"}, {"name": "AirAsia Zest", "pos": [19, 21], "sent_id": 6, "type": "ORG"} ], ... ], "labels": [ {"r": "P159", "h": 0, "t": 2, "evidence": [0]}, {"r": "P17", "h": 0, "t": 4, "evidence": [2, 4, 7]}, ... ], "title": "AirAsia Zest", "sents": [ ["Zest", "Airways", ",", "Inc.", "operated", "as", "AirAsia", "Zest", "(", "formerly", "Asian", "Spirit", "and", "Zest", "Air", ")", ",", "was", "a", "low", "-", "cost", "airline", "based", "at", "the", "Ninoy", "Aquino", "International", "Airport", "in", "Pasay", "City", ",", "Metro", "Manila", "in", "the", "Philippines", "."], ... ] } -
-
rel2id.json这个文件包含关系到ID的映射表,用于将关系标签转换为数值ID。文件格式为JSON对象,其中键为关系名称,值为对应的ID。
示例:
{ "P1376": 79, "P607": 27, "P136": 73 } -
rel_info.json这个文件包含关系的详细信息,包括关系的名称和描述等。文件格式为JSON对象,每个键是关系ID,值是包含关系名称和描述的对象。
示例:
{ "P6": "head of government", "P17": "country", "P19": "place of birth" } -
test.json这个文件包含测试集,用于在模型训练完成后进行最终性能评估。文件格式与
dev.json类似,但不包含关系标签,因为测试集通常是用来评估模型在未见数据上的表现。 -
train_annotated.json这个文件包含训练集,文件格式与
dev.json相同,包括完整的标注信息,用于训练关系抽取模型。
2.2 数据预处理
在实验开始,需要使用 gent_dati.py 对数据进行预处理,将原始数据转换为模型训练和测试所需的格式。
-
数据预处理
-
初始化分词器: 根据指定的模型类型和模型名称加载对应的分词器。例如,加载 BERT 的
bert-base-cased分词器。 -
读取和预处理数据: 从指定的数据目录 (
data_dir) 读取原始数据文件,对其进行预处理,包括分词和编码操作。这个过程会将原始文本数据转换为模型可以直接使用的数值表示。 -
保存预处理后的数据: 将预处理后的数据保存到指定的输出目录 (
output_dir),这些数据文件(如.npy文件)将在模型训练和评估时使用。
-
-
指令执行
通过以下指令执行数据预处理。
python gen_data.py --data_dir dataset执行指令后结果如下,并生成一个
prepro_data文件夹,包含预处理后得到的 json、npy文 件。Downloading vocab.txt: 100%|████████████████████████████████████████████████████████| 213k/213k [00:02<00:00, 79.8kB/s] Downloading tokenizer_config.json: 100%|████████████████████████████████████████████████████| 49.0/49.0 [00:00<?, ?B/s] Downloading config.json: 100%|████████████████████████████████████████████████████████| 570/570 [00:00<00:00, 1.93MB/s] data_len: 3053 Saving files Finishing processing Finish saving data_len: 1000 Saving files Finishing processing Finish saving data_len: 1000 Saving files Finishing processing Finish saving生成的
prepro_data目录结构如下:├─prepro_data │ dev.json │ dev_bert_mask.npy │ dev_bert_starts_ends.npy │ dev_bert_token.npy │ rel2id.json │ test.json │ test_bert_mask.npy │ test_bert_starts_ends.npy │ test_bert_token.npy │ train.json │ train_bert_mask.npy │ train_bert_starts_ends.npy │ train_bert_token.npy
2.3 代码问题回答
在数据预处理代码中用 # question 标识了多个问题,下面根据代码内容与查阅资料进行回答。
-
这里的
fact_in_annotated_train代表什么?if is_training: for n1 in vertexSet[label['h']]: for n2 in vertexSet[label['t']]: fact_in_annotated_train.add((n1['name'], n2['name'], rel)) else: for n1 in vertexSet[label['h']]: for n2 in vertexSet[label['t']]: if (n1['name'], n2['name'], rel) in fact_in_annotated_train: label['in_annotated_train'] = Truefact_in_annotated_train集合用于存储在训练数据中出现的关系三元组(即实体对和它们之间的关系)。这可以用于在训练期间识别哪些关系在训练集中是可见的,并在评估时确定一个关系是否被模型在训练数据中观察到。 -
这里的
na_triple代表什么?na_triple = [] for j in range(len(vertexSet)): for k in range(len(vertexSet)): if (j != k): if (j, k) not in train_triple: na_triple.append((j, k))na_triple是一个列表,包含数据集中不存在的关系对(即负样本)。这些是模型不应该预测为任何关系的实体对。在关系抽取任务中,除了正样本之外,负样本的包含有助于训练模型识别非关系。 -
这里的
bert_starts_ends代表什么?bert_starts_ends = np.ones((sen_tot, max_seq_length, 2), dtype = np.int64) * (max_seq_length - 1)bert_starts_ends是一个三维数组,用于存储每个句子中每个词对应的子词的起始和结束索引。这个信息对于模型理解词在经过分词器处理后如何在子词级别上分解是很重要的。在 BERT 模型中,这有助于正确地对齐词和它们对应的嵌入。 -
token_start_idxs的公式中为什么要加1token_start_idxs = 1 + np.cumsum([0] + subword_lengths[:-1])token_start_idxs加1 是为了在子词的起始索引之前插入一个特殊的标记(如[CLS]),这是 BERT 模型的开始标记。这样,token_start_idxs就包含了从句子开始到每个子词的累积长度。 -
为什么要把
token_start_idxs >= max_seq_length-1的都置为max_seq_length - 1token_start_idxs[token_start_idxs >= max_seq_length-1] = max_seq_length - 1 token_end_idxs = 1 + np.cumsum(subword_lengths) token_end_idxs[token_end_idxs >= max_seq_length-1] = max_seq_length - 1这个操作是为了确保所有超出最大序列长度的 token 的起始索引不会超出数组的界限。BERT 模型要求所有 token 的索引必须在有效的范围内,因此这个操作将超出范围的索引设置为最后一个有效位置。
3 项目训练
3.1 代码介绍
案例中给出了训练代码 train.py 与相应的训练流程代码 Config.py 。下面介绍具体代码架构。
-
自定义数据集类
MyDatasetMyDataset类用于封装数据集的加载逻辑,包括初始化数据路径、读取 JSON 和 Numpy 文件,以及实现按索引获取数据项和获取数据集长度的方法。 -
准确率工具类
AccuracyAccuracy类用于跟踪和计算模型预测的准确率。 -
配置类
ConfigConfig类是Config.py核心,封装了模型训练和测试的所有配置参数和方法。__init__方法:接收命令行参数,并初始化了一系列与训练和测试相关的属性,如准确率计数器、最大序列长度、实体关系数量、批大小等。load_test_data:加载测试数据集。get_test_batch:生成测试数据的批次。set_seed:设置随机种子以保证结果的可复现性。get_train_batch:用于准备训练数据的批次。logging:用于打印和记录日志的方法。train:执行模型的训练过程,包括数据加载、模型初始化、训练循环、日志记录和模型保存。test:执行模型的测试过程,包括数据加载、模型评估和性能指标的计算。testall:一个额外的测试函数,用于在训练结束后对模型进行全面测试。
3.2 代码问题回答
在训练代码中用 # question 标识了多个问题,下面根据代码内容与查阅资料进行回答。
-
data_train_bert_mask代表什么?self.data_train_bert_token = np.load(os.path.join(self.data_path, prefix+'_bert_token.npy'))data_train_bert_mask代表BERT模型输入序列中每个token是否为实际内容的掩码,通常用于区分填充(padding)的部分。在BERT中,实际的token会被标记为1,而填充的部分会被标记为0。 -
这里的
neg_multiple代表什么?self.neg_multiple = 3neg_multiple代表负样本的数量是正样本数量的倍数。在关系分类任务中,为了平衡正负样本,通常会从负样本池中随机选择一些负样本与正样本配对进行训练。 -
为什么要设置一个
h_t_limit?self.h_t_limit = 1800h_t_limit限制了每个样本中考虑的头实体(h)和尾实体(t)的对的数量。这是为了限制模型在每个输入序列中考虑的关系对的数量,避免计算量过大。 -
这里的
self.dis2idx代表什么?self.dis2idx = np.zeros((512), dtype='int64') self.dis2idx[1] = 1 self.dis2idx[2:] = 2 self.dis2idx[4:] = 3 self.dis2idx[8:] = 4 self.dis2idx[16:] = 5 self.dis2idx[32:] = 6 self.dis2idx[64:] = 7 self.dis2idx[128:] = 8 self.dis2idx[256:] = 9 self.dis_size = 20self.dis2idx是一个用于将实体对之间的距离转换为离散索引的数组。由于实体对之间的距离可能会影响关系抽取的结果,因此通过离散化距离可以帮助模型更好地处理这一特征。 -
h_mapping和t_mapping有什么区别?h_mapping = torch.Tensor(self.test_batch_size, self.test_relation_limit, self.max_seq_length).cuda() t_mapping = torch.Tensor(self.test_batch_size, self.test_relation_limit, self.max_seq_length).cuda()h_mapping和t_mapping都是用于表示实体在文本中的位置。h_mapping表示头实体的位置,而t_mapping表示尾实体的位置。它们的区别在于它们指向的实体类型不同。 -
max_h_t_cnt有什么作用?max_h_t_cnt = 1max_h_t_cnt用于记录批次中最大的头实体和尾实体对的数量。这是为了在生成批次数据时,确保所有批次的维度一致。 -
本代码是如何处理token数量大于512的文档的?
对于token数量大于512的文档,代码通过限制每个实体的结束位置(
ends_pos[h['pos'][1]-1]<511)来确保它们不会超出BERT模型的最大序列长度限制。 -
为什么要先除以
len(hlist), 再除以(h[1] - h[0])?for h in hlist: h_mapping[i, j, h[0]:h[1]] = 1.0 / len(hlist) / (h[1] - h[0])为了对实体的每个位置进行平均权重分配。首先,将权重除以实体的数量(
len(hlist)),然后再除以实体在序列中的跨度(h[1] - h[0])。这样做的目的是为了使得每个实体的位置权重能够在整个序列中合理分布。 -
relation_mask的作用是什么?relation_mask[i, j] = 1relation_mask用于指示每个批次中哪些关系对是有效的。在某些情况下,如果一个批次没有足够的关系对来填充预定的h_t_limit,relation_mask可以帮助模型识别哪些位置应该被忽略。 -
max_h_t_cnt代表什么?max_h_t_cnt = max(max_h_t_cnt, len(train_tripe) + lower_bound)max_h_t_cnt代表当前批次中最大的头实体和尾实体对的数量。这个值用于调整批次数据的维度,以确保模型可以处理不同数量的关系对。 -
这里可以使用
cross-entropy loss吗?BCE = nn.BCEWithLogitsLoss(reduction='none')代码中使用的是二元交叉熵损失(
BCEWithLogitsLoss),这是适合二分类问题的损失函数。对于多分类问题,通常使用分类交叉熵损失(CrossEntropyLoss)。在这个场景中,如果输出层使用softmax激活函数,那么可以使用分类交叉熵损失。 -
这里的
NA acc/not NA acc/tot acc分表代表什么?是如何计算的?logging('| epoch {:2d} | step {:4d} | ms/b {:5.2f} | train loss {:.8f} | NA acc: {:4.2f} | not NA acc: {:4.2f} | tot acc: {:4.2f} '.format( epoch, global_step, elapsed * 1000 / self.log_period, cur_loss, self.acc_NA.get(), self.acc_not_NA.get(), self.acc_total.get()))-
NA acc(Not Applicable accuracy)代表模型对于标签为NA(不适用)的关系对预测的准确率。通过统计模型预测为“0”(即不存在关系)的实例数量,并将这些预测正确的实例数除以所有预测为“0”的实例总数来计算。
-
not NA acc代表对于非NA关系的预测准确率。统计模型预测为非“0”类别的实例数量,并将这些预测正确的实例数除以所有预测为非“0”的实例总数。
-
tot acc是所有关系的总体预测准确率。这些准确率是通过比较模型的预测输出和实际标签来计算的。统计所有实例中模型预测正确的数量,然后将这个数量除以总的实例数。
-
-
这里是否可以改成softmax函数?
predict_re = torch.sigmoid(predict_re)这里与损失函数相对应,当使用二元交叉熵损失(
BCEWithLogitsLoss)应进行 sigmoid 操作。使用CrossEntropyLoss时应进行 softmax 操作。 -
这里的
Theta/F1/AUC分别代表什么?是如何计算的?logging('ALL : Theta {:3.4f} | F1 {:3.4f} | AUC {:3.4f}'.format(theta, f1, auc))-
Theta是模型预测的阈值,用于确定一个关系对是否被认为是存在的。
theta = test_result[f1_pos][1]theta是通过在所有可能的阈值(test_result中的预测概率)上计算F1分数,并选择使得F1分数最大的那个阈值来确定的。 -
F1分数是模型在特定Theta下的F1衡量,它结合了精确度和召回率。
f1_arr = (2 * pr_x * pr_y / (pr_x + pr_y + 1e-20)) f1 = f1_arr.max()计算了多个阈值下的F1分数,存储在数组
f1_arr中。然后通过f1_arr.max()找到了最大F1分数。 -
AUC(Area Under the Curve)是模型预测概率和实际标签之间的曲线下面积,通常用于评估模型的性能。
auc = sklearn.metrics.auc(x = pr_x, y = pr_y)pr_x和pr_y分别代表在不同阈值下的召回率和精确度,auc是基于这些值计算的AUC分数。
-
-
ma_f1这里的input_theta/test_result F1/AUC分别代表什么?是如何计算的?logging('ma_f1 {:3.4f} | input_theta {:3.4f} test_result F1 {:3.4f} | AUC {:3.4f}'.format(f1, input_theta, f1_arr[w], auc))-
ma_f1代表的是“最大F1分数”。 -
input_theta是外部输入到测试函数的阈值,用于确定预测的二元分类结果。 -
test_result F1是在测试集上使用input_theta作为分类阈值时得到的F1分数。通过将测试集上每个实例的预测概率与
input_theta比较,确定分类结果,然后计算这个阈值下的精确度和召回率,最后根据这两个值计算F1分数。 -
AUC(Area Under the Curve)是模型预测概率和实际标签之间的曲线下面积,通常用于评估模型的性能。
-
-
Ignore ma_f1这里的input_theta/test_result F1/AUC分别代表什么?是如何计算的?logging('Ignore ma_f1 {:3.4f} | input_theta {:3.4f} test_result F1 {:3.4f} | AUC {:3.4f}'.format(ign_f1, input_theta, f1_arr[w], auc))这里打印了忽略 模型预测为非关系或负相关的样本 的
input_theta/test_result F1/AUC指标,计算方式与上面相同,但计算分母时排除了那些在训练中未被标记为正样本但在测试中被预测为正样本的样本。
3.3 模型训练
-
本地训练
根据代码内容,执行以下指令,运行
train.py进行训练python train.py --model_type bert --model_name_or_path bert-base-cased --prepro_data_dir prepro_data --save_name my_model --batch_size 8 由于GPU大小只有16G,所以设置
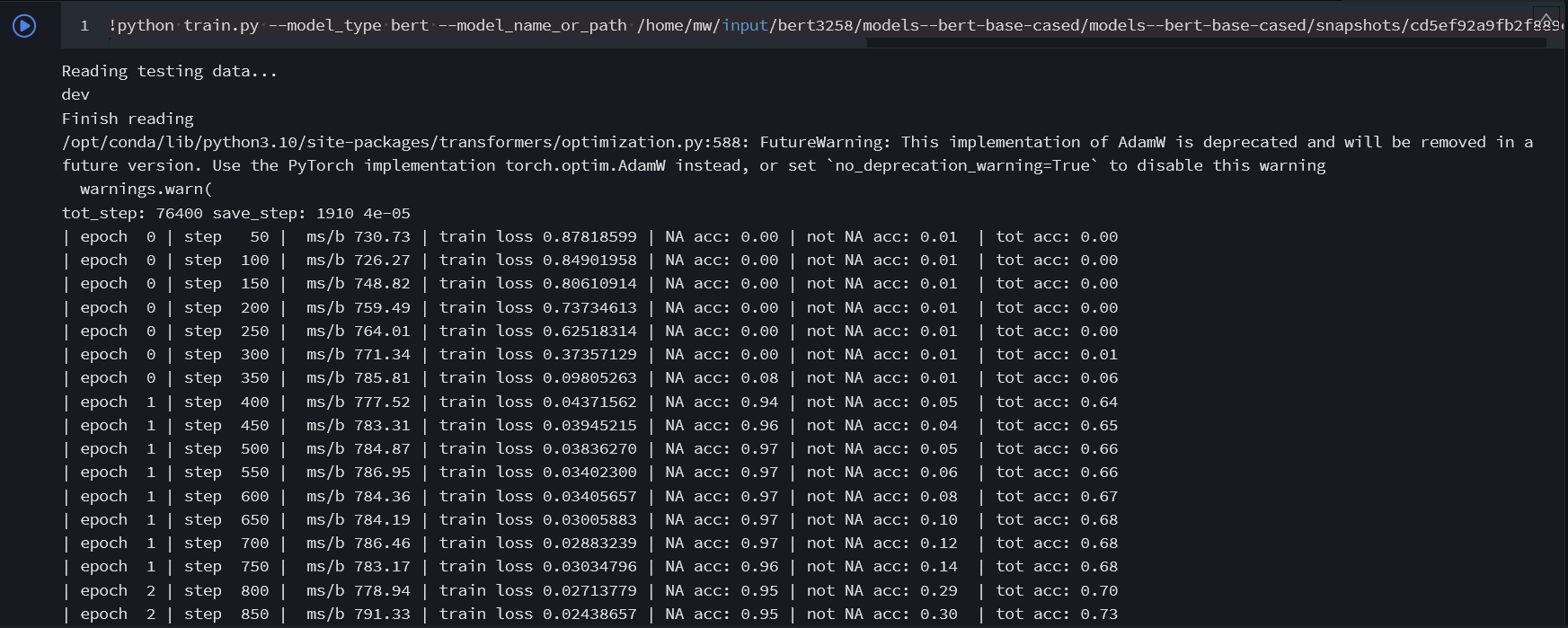
batch_size为8进行训练,其他参数均为默认。 在执行命令后,首先会下载
bert-base-cased预训练模型,然后进行200轮的训练。Reading testing data... dev Finish reading tot_step: 76400 save_step: 1910 4e-05 | epoch 0 | step 50 | ms/b 730.73 | train loss 0.87818599 | NA acc: 0.00 | not NA acc: 0.01 | tot acc: 0.00 | epoch 0 | step 100 | ms/b 726.27 | train loss 0.84901958 | NA acc: 0.00 | not NA acc: 0.01 | tot acc: 0.00 ... -
云平台训练
由于为长时间的训练,本次实验采用在云平台进行训练。通过自行上传数据集与预训练模型,进行200轮的训练。通过以下指令进行训练。
!python train.py --model_type bert \ --model_name_or_path '/home/mw/input/bert3258/models--bert-base-cased/models--bert-base-cased/snapshots/cd5ef92a9fb2f889e972770a36d4ed042daf221e' \ --prepro_data_dir '/home/mw/input/nlppretrain5414/prepro_data/prepro_data' \ --save_name 'my_model' \ --batch_size 8训练开始后,如下图所示,进行200个epoch的训练。
本次实验选择通过云平台进行离线训练,训练过程如下。
-
训练结果
最终得到的训练结果如下。
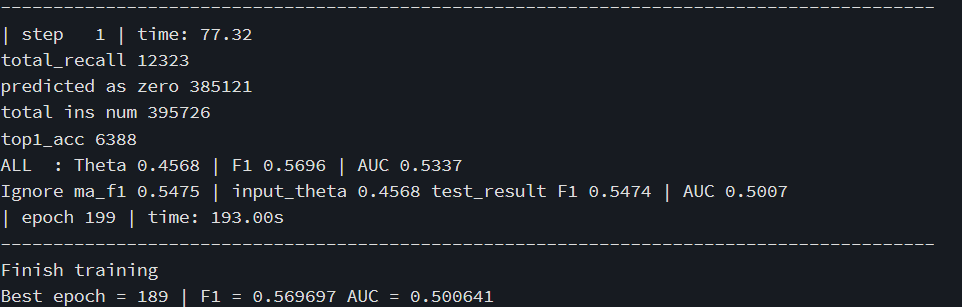
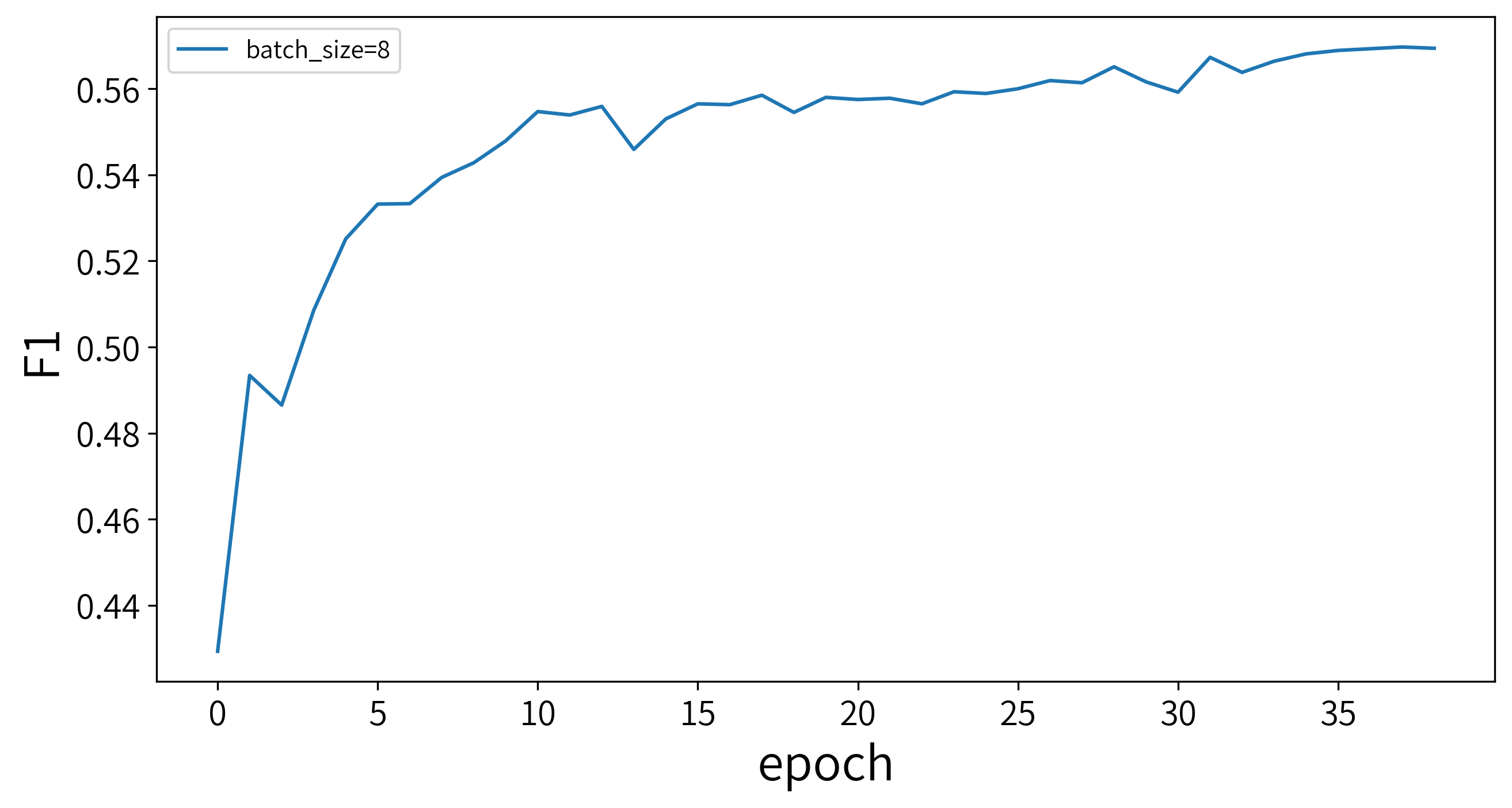
可以看到,最好的训练结果在第189轮得到,F1值达到0.569697。
训练结束后,会生成一个 Checkpoint 文件,和一个log文件。
将log文件中记录训练过程可视化,绘制Loss与epoch的曲线,结果如下。
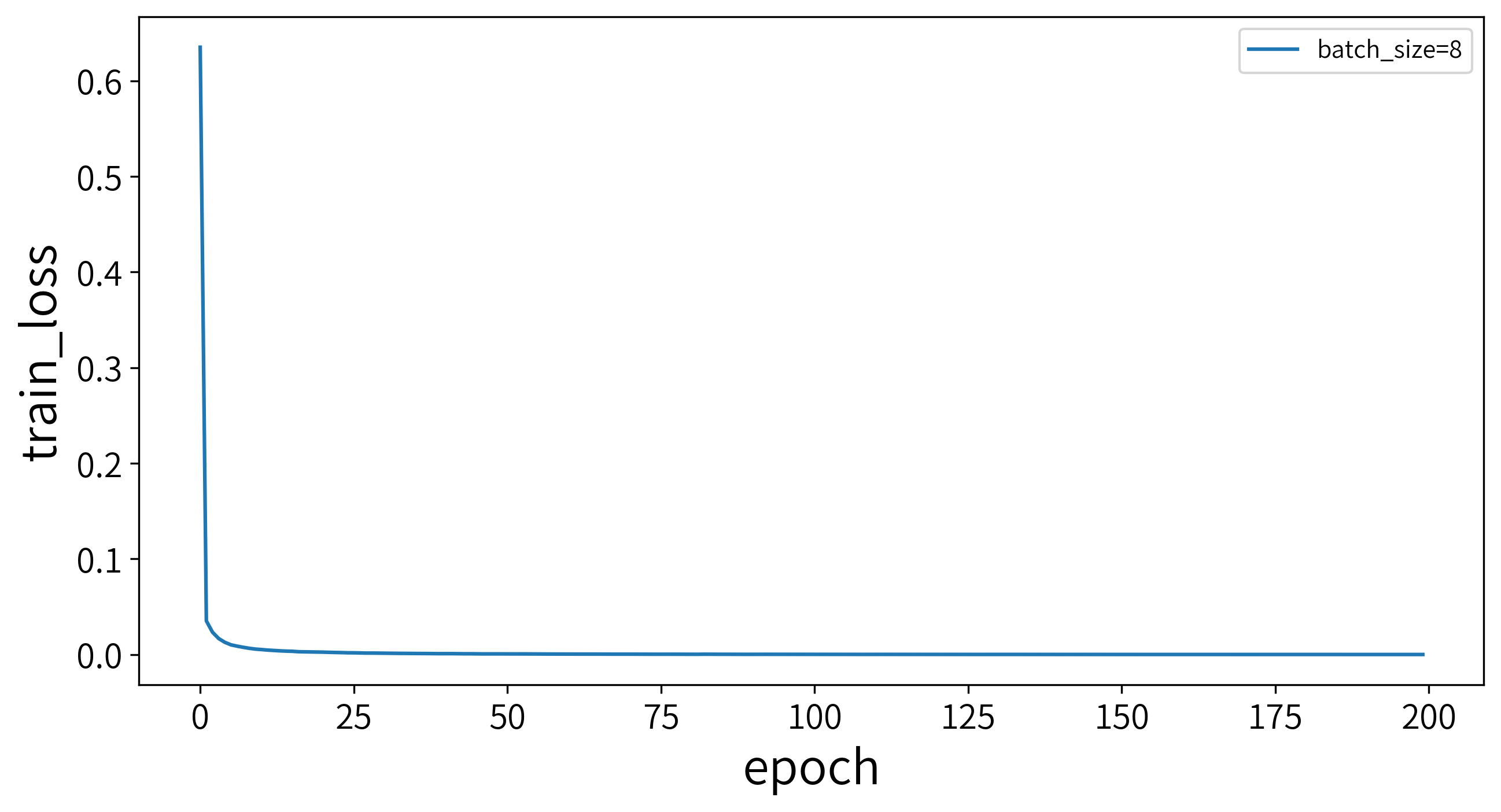
训练过程中,每过5个epoch会进行一次测试,绘制每次测试的F1值与epoch的曲线如下。
4 项目测试
4.1 本地测试
通过以下指令执行 test.py 文件,进行模型测试。
! python test.py --model_type='bert' --model_name_or_path='/home/mw/input/bert3258/models--bert-base-cased/models--bert-base-cased/snapshots/cd5ef92a9fb2f889e972770a36d4ed042daf221e' --prepro_data_dir='/home/mw/input/nlppretrain5414/prepro_data/prepro_data' --save_name='my_model' --batch_size=8
测试结果如下:
Reading testing data...
dev
Finish reading
| step 1 | time: 76.83
total_recall 12323
predicted as zero 385081
total ins num 395726
top1_acc 6404
ALL : Theta 0.4008 | F1 0.5697 | AUC 0.5341
finish output
Ignore ma_f1 0.5472 | input_theta 0.4008 test_result F1 0.5470 | AUC 0.5006
测试结果后,生成一个 my_model_dev_index.json 文件,用于上传至平台进行测试。
4.2 CodaLab测试
将 my_model_dev_index.json 文件改名为 result.json 打包为 result.zip 上传至CodaLab平台的DocRED的评测系统中,进行测试。得到的测试结果如下。
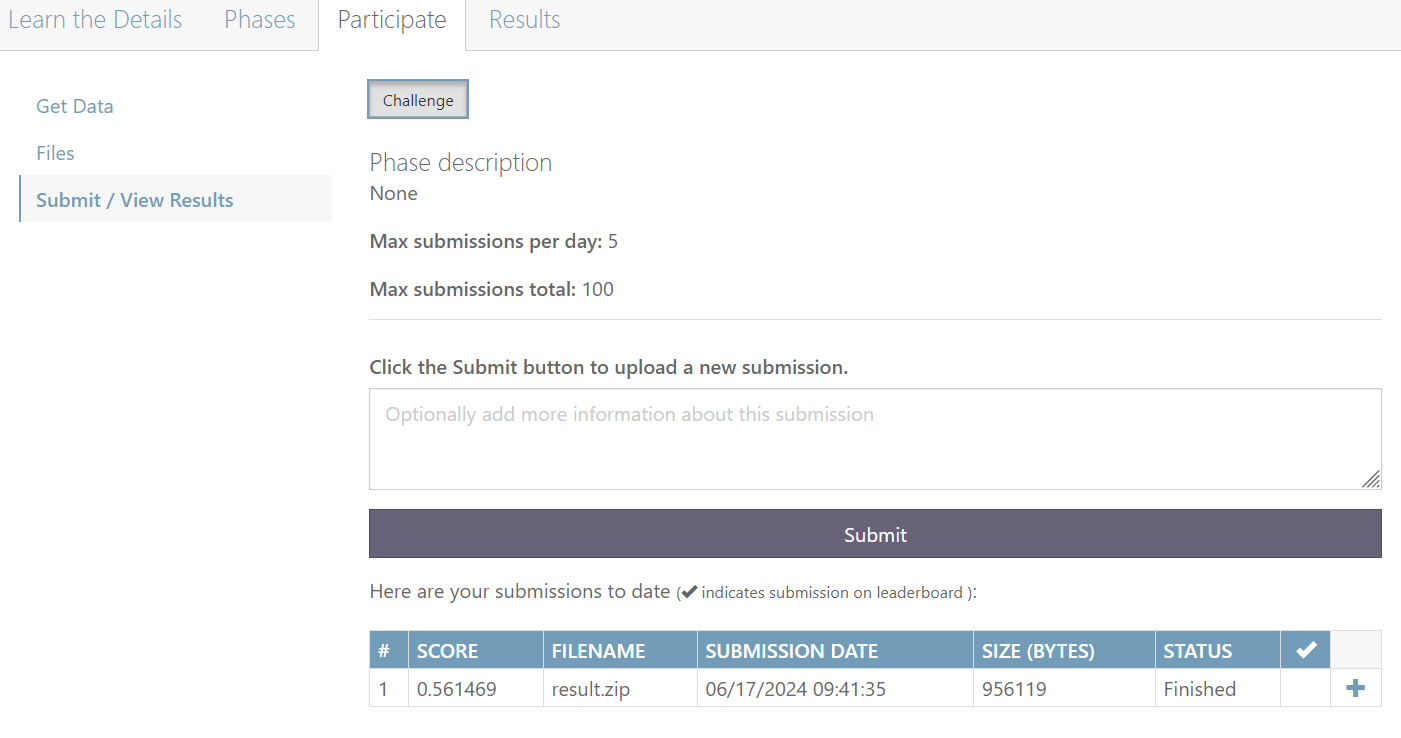
可以看到,输出结果为 0.561469 。
本次实验由于工作原因,未能完成进阶的roberta模型等更多内容,后续一定抽空继续完善实验。

















 535
535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











