






一、491.递增子序列
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
示例:
- 输入: [4, 6, 7, 7]
- 输出: [[4, 6], [4, 7], [4, 6, 7], [4, 6, 7, 7], [6, 7], [6, 7, 7], [7,7], [4,7,7]]
说明:
- 给定数组的长度不会超过15。
- 数组中的整数范围是 [-100,100]。
- 给定数组中可能包含重复数字,相等的数字应该被视为递增的一种情况。
思路
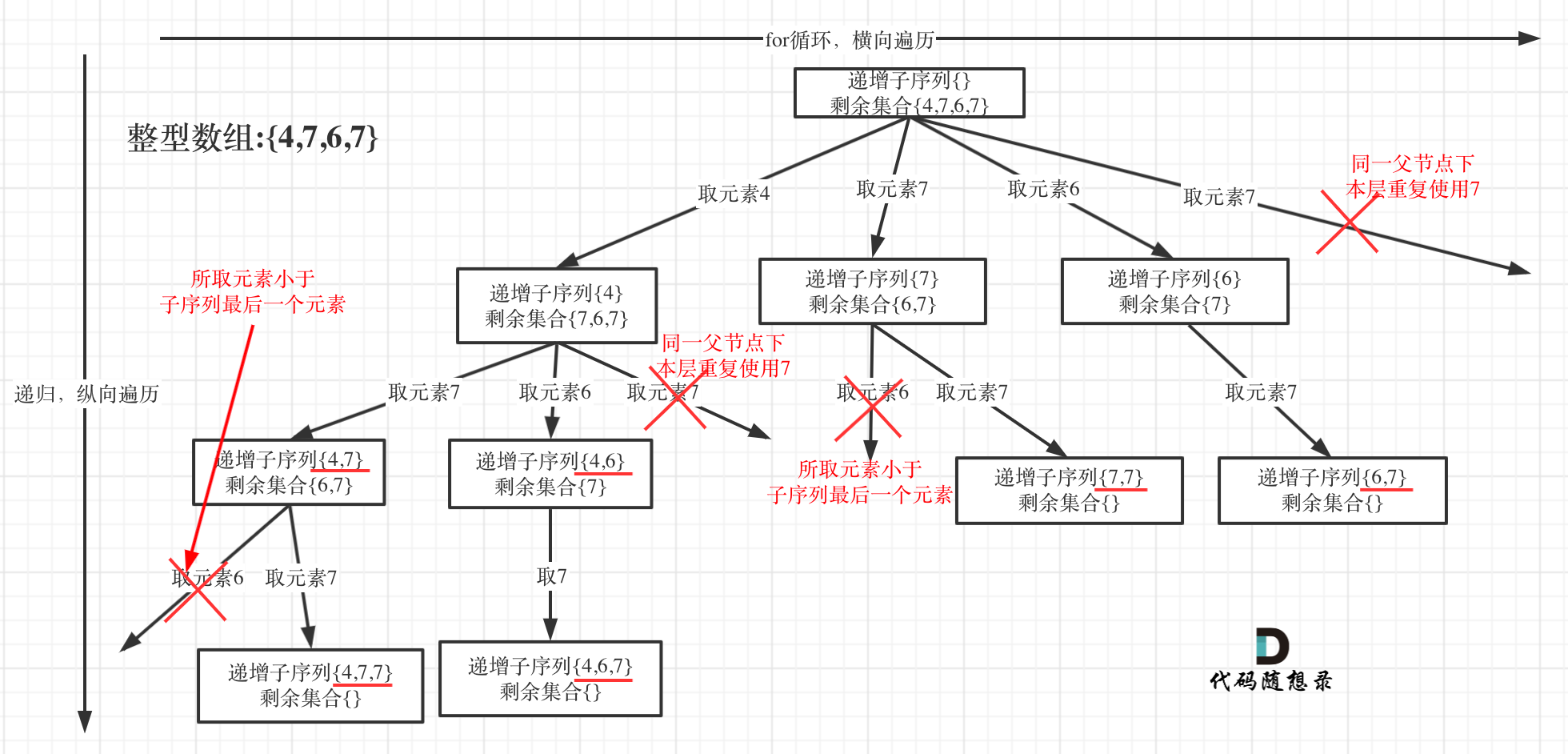
这个递增子序列比较像是取有序的子集。而且本题也要求不能有相同的递增子序列。
这又是子集,又是去重,是不是不由自主的想起了刚刚讲过的90.子集II (opens new window)。
就是因为太像了,更要注意差别所在,要不就掉坑里了!
在90.子集II (opens new window)中我们是通过排序,再加一个标记数组来达到去重的目的。
而本题求自增子序列,是不能对原数组进行排序的,排完序的数组都是自增子序列了。
所以不能使用之前的去重逻辑!
本题给出的示例,还是一个有序数组 [4, 6, 7, 7],这更容易误导大家按照排序的思路去做了。
为了有鲜明的对比,我用[4, 7, 6, 7]这个数组来举例,抽象为树形结构如图:
class Solution {
List<List<Integer>> result = new ArrayList<>();
List<Integer> path = new ArrayList<>();
public List<List<Integer>> findSubsequences(int[] nums) {
backTracking(nums, 0);
return result;
}
private void backTracking(int[] nums, int startIndex){
if(path.size() >= 2)
result.add(new ArrayList<>(path));
HashSet<Integer> hs = new HashSet<>();
for(int i = startIndex; i < nums.length; i++){
if(!path.isEmpty() && path.get(path.size() -1 ) > nums[i] || hs.contains(nums[i]))
continue;
hs.add(nums[i]);
path.add(nums[i]);
backTracking(nums, i + 1);
path.remove(path.size() - 1);
}
}
}
二、46.全排列
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
- 输入: [1,2,3]
- 输出: [ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1] ]
思路
我以[1,2,3]为例,抽象成树形结构如下:
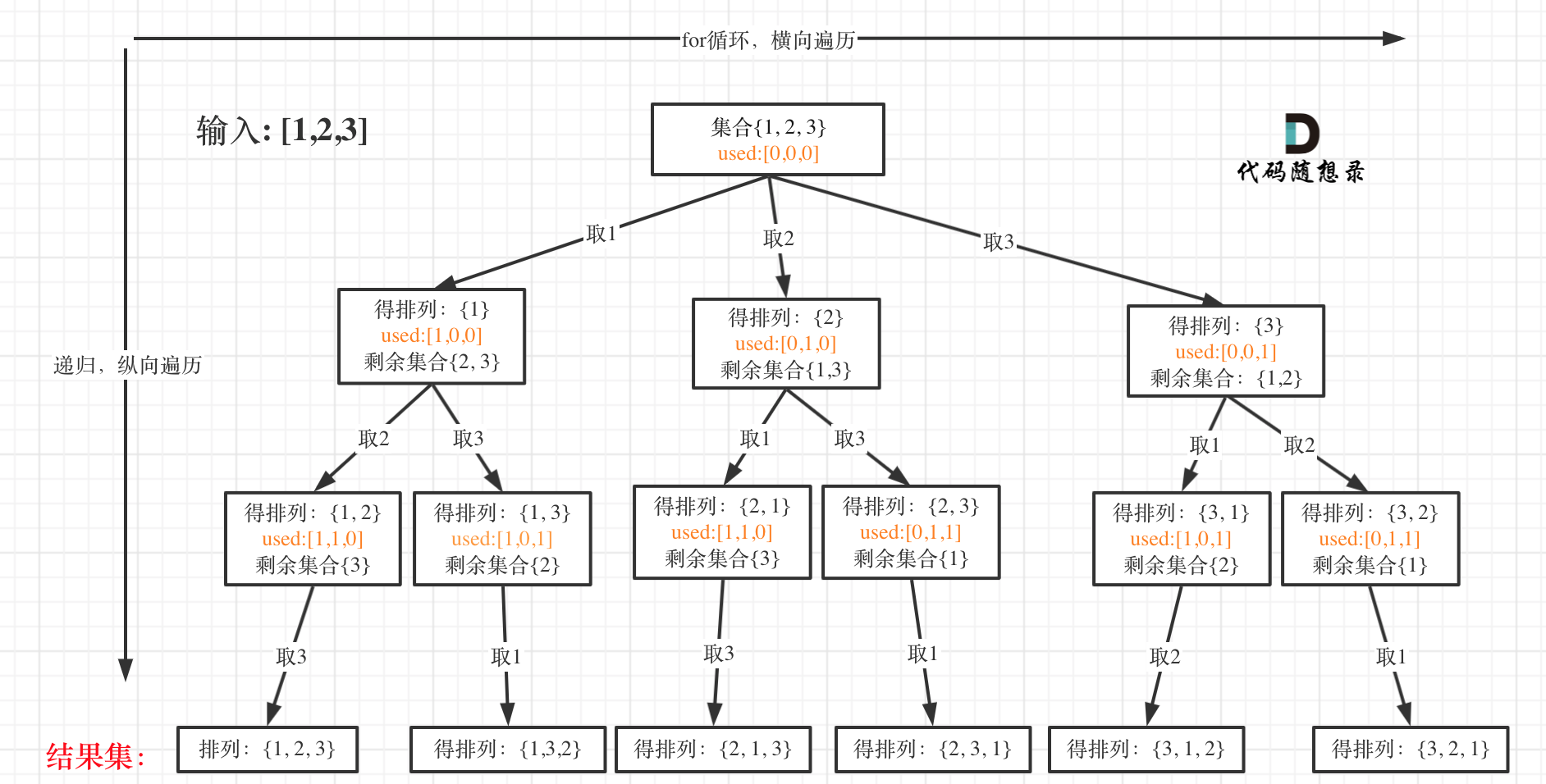
这道题主要是需要使用used数组来标记哪个使用过。排列问题,每次都要从头开始搜索,例如元素1在[1,2]中已经使用过了,但是在[2,1]中还要再使用一次1。
used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次。
class Solution {
List<List<Integer>> result = new ArrayList<>();// 存放符合条件结果的集合
LinkedList<Integer> path = new LinkedList<>();// 用来存放符合条件结果
boolean[] used;
public List<List<Integer>> permute(int[] nums) {
if (nums.length == 0){
return result;
}
used = new boolean[nums.length];
permuteHelper(nums);
return result;
}
private void permuteHelper(int[] nums){
if (path.size() == nums.length){
result.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++){
if (used[i]){
continue;
}
used[i] = true;
path.add(nums[i]);
permuteHelper(nums);
path.removeLast();
used[i] = false;
}
}
}三、47.全排列 II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
- 输入:nums = [1,1,2]
- 输出: [[1,1,2], [1,2,1], [2,1,1]]
示例 2:
- 输入:nums = [1,2,3]
- 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
提示:
- 1 <= nums.length <= 8
- -10 <= nums[i] <= 10
思路
这题与上一题的不同之处在于数组元素可能会重复,因此需要进行去重,这里要对树层进行去重,不需要对树枝进行去重。
还要强调的是去重一定要对元素进行排序,这样我们才方便通过相邻的节点来判断是否重复使用了。
我以示例中的 [1,1,2]为例 (为了方便举例,已经排序)抽象为一棵树,去重过程如图:

class Solution {
//存放结果
List<List<Integer>> result = new ArrayList<>();
//暂存结果
List<Integer> path = new ArrayList<>();
public List<List<Integer>> permuteUnique(int[] nums) {
boolean[] used = new boolean[nums.length];
Arrays.fill(used, false);
Arrays.sort(nums);
backTrack(nums, used);
return result;
}
private void backTrack(int[] nums, boolean[] used) {
if (path.size() == nums.length) {
result.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++) {
// used[i - 1] == true,说明同⼀树⽀nums[i - 1]使⽤过
// used[i - 1] == false,说明同⼀树层nums[i - 1]使⽤过
// 如果同⼀树层nums[i - 1]使⽤过则直接跳过
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
continue;
}
//如果同⼀树⽀nums[i]没使⽤过开始处理
if (used[i] == false) {
used[i] = true;//标记同⼀树⽀nums[i]使⽤过,防止同一树枝重复使用
path.add(nums[i]);
backTrack(nums, used);
path.remove(path.size() - 1);//回溯,说明同⼀树层nums[i]使⽤过,防止下一树层重复
used[i] = false;//回溯
}
}
}
}














 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









