






一、环境设置

加了一个这个

查看


二、项目运行
(1)使用Xftp把在虚拟机里划分好的数据集产生的训练与测试文档下载到自己电脑
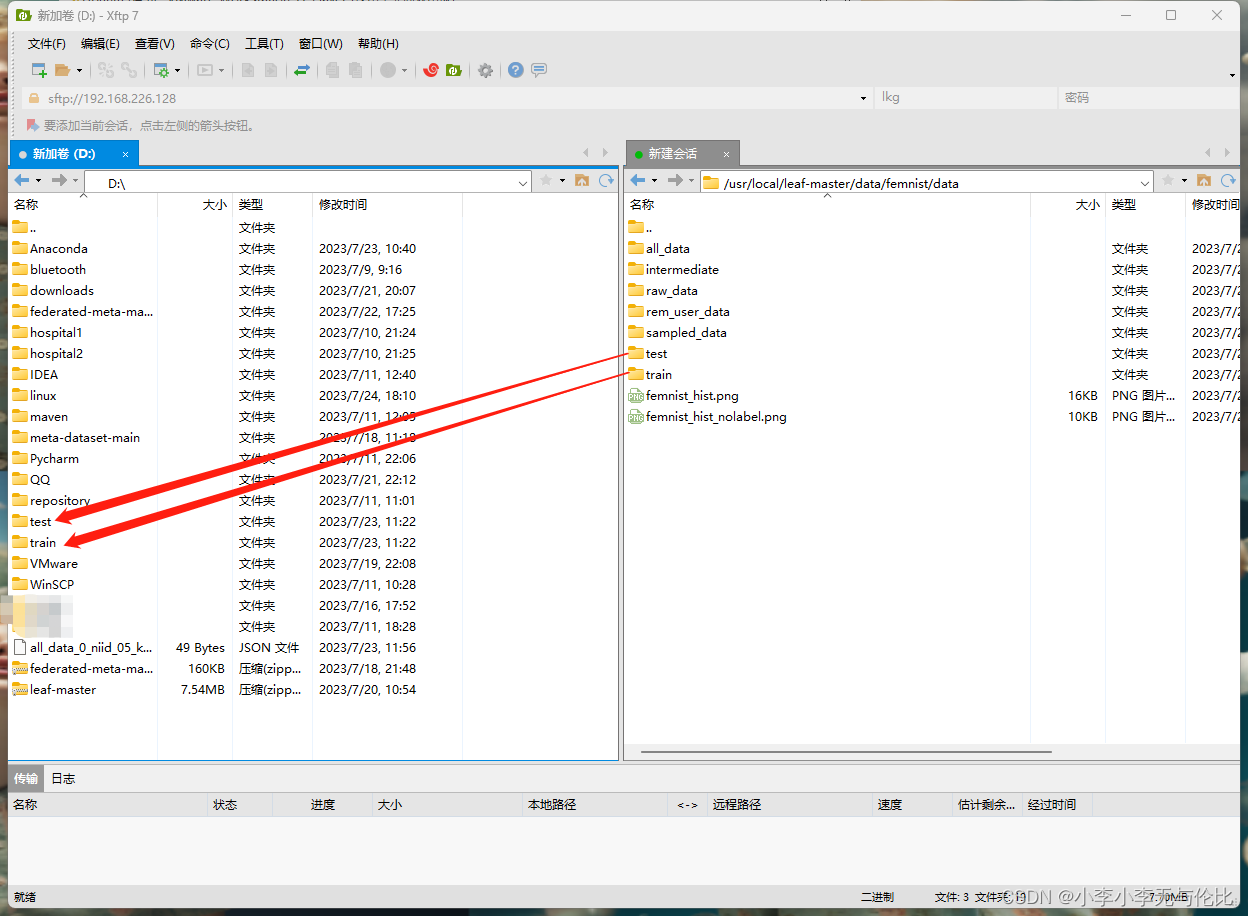
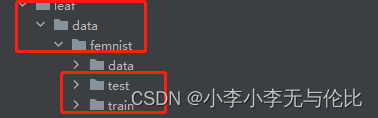
把下载下来的“train”和“test”文档放到项目的这个目录下:
按照项目文档,在相应文件路径“dataset/femnist”下,先执行“split_support_query.py”文档,但是没反应。原因是,我自作聪明:把客户拥有的样本数量改为500,那么筛选出来的客户就少了,少到0了,所以没数据。
那就只能在虚拟机中使用命令“./preprocess.sh -s niid --sf 0.05 -k 400 -t sample”重新划分一下,重新把训练和测试的文档下载到自己电脑。
(2)根据文档,在相应目录下使用“python run.py --algo=fedmeta --eval_on_test_every=1 --dataset=femnist_p_0.2 --lr=0.001 --num_epochs=1 --model=cnn --clients_per_round=4 --batch_size=10 --data_format=pkl --num_rounds=2000 --meta_algo=maml --outer_lr=0.0001 --result_prefix=./fedmeta_result --device=cuda:0 --save_every=1000”执行文档
提醒各种包没下载,进入Anaconda Prompt黑窗口下,下载相应的包:
三、BUG解决
(1)错误1
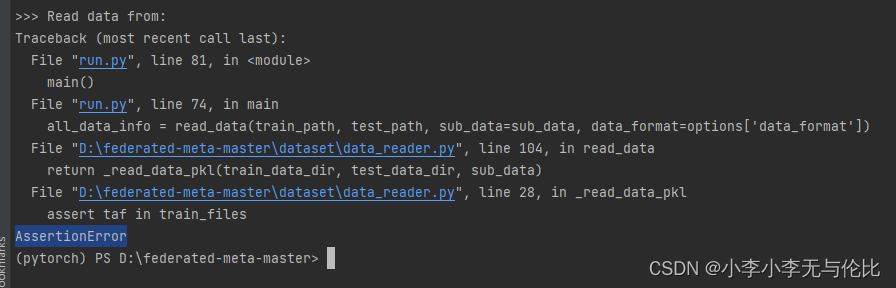
错误解释:
根据提供的错误信息,代码中出现了一个`AssertionError`,这意味着在运行时,断言条件返回了`False`,触发了异常。
以下是可能导致断言错误的几种可能情况:
1. 训练数据或测试数据的文件路径不正确或无效。
2. 训练文件列表(`train_files`)中缺少某些文件。
3. 训练数据或测试数据的格式不正确,与代码中的预期格式不符。
要解决这个问题,您可以按照以下步骤进行调查:
1. 确保文件路径(`train_data_dir`和`test_data_dir`)是正确的,并且数据文件确实存在。
2. 检查`train_files`中是否包含所有预期的训练文件。您可以尝试在代码的断言语句前添加一些打印语句,输出`train_files`的内容,以便查看是否缺少某些文件。
3. 确认数据的格式是否与代码中的预期格式相匹配。阅读"data_reader.py"文件中相关函数的实现,确保数据文件的内容和结构与函数期望的一致。
添加代码测试:

测试结果:
 应该是sub_data的问题,但是没有p_0.2.pkl这个文件:
应该是sub_data的问题,但是没有p_0.2.pkl这个文件:
重新划分 就有了:

(2) 但是还不行,错误2:

好像是没有安装GPU版pytorch,参考方案:(14条消息) 解决AssertionError Torch not compiled with CUDA enabled问题_在终端运行后报错assertionerror: torch not compiled with cu_这也太南了趴的博客-CSDN博客
经检查,确实没有

使用以下代码安装:
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch实验室电脑不行,但我们可以用cpu运行。
(3)发现一处语法错误:

(4) “pandas(1.3.4)”版本要对应
成功!

ZWJ后来发的:
import torch
import torchvision
print(torch.cuda.device_count())
print(torch.cuda.current_device())
print(torch.__version__)
print(torchvision.__version__)
if torch.cuda.is_available():
cuda_version = torch.version.cuda
print(f"PyTorch CUDA版本为: {cuda_version}")
# 检查CUDA版本是否与PyTorch兼容
if torch.backends.cudnn.version() is None:
print("PyTorch不支持当前CUDA版本")
else:
print("PyTorch支持当前CUDA版本")
else:
print("PyTorch不支持GPU加速")
















 4011
4011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









