







引言
正则路径查询(Regular Path Query, RPQ)是图数据上的一类重要的查询,可用于寻找图数据中具有某些复杂关系的结点对。本文将会对旨在优化这一查询执行的过往工作做大致的梳理,并重点介绍其中使用路径索引(Path Index)进行加速的一类工作。
问题定义
给定一张边上带标签的有向图、一个正则表达式,正则路径查询返回图中以满足该正则表达式的路径相连接的源-目标结点对集合,其中“满足”定义为路径所含的边按序组成的标签序列(即字符串)在该正则表达式定义的正则语言中。
正则路径查询有重要的现实意义。若将现实中实体间关系建模成边上带标签的有向图(边上的标签表示一跳关系的类型),那么正则路径查询即可用于寻找具有某些能用正则语言表达的、较复杂关系的实体对。因此,主流的图数据查询语言SPARQL 1.1和Cypher均支持了正则路径查询。近期一项对多个知名数据库的SPARQL查询端点上真实查询日志的实证研究[1]表明,在某些端点上正则路径查询出现十分频繁,比例高达总查询量的29.87%。
过往工作分类
针对正则路径查询的过往工作主要可分成两类。第一类工作旨在解决正则路径查询的子问题:带标签约束的可达性查询。给定一张边上带标签的有向图、一个标签集合、一个源-目标结点对,这一查询返回这对结点之间是否以仅带集合中标签的边所构成的路径相连。(也有少数工作将其定义为给定边上带标签的有向图和标签集合,返回所有如此相连的源-目标结点对,则与上述正则路径查询的定义完全类似。)显然,这种从标签集合引出的约束可以用正则表达式来表达:若标签集合为
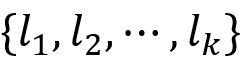
,则相应的正则表达式为。实证研究[1]表明,此类正则表达式在其研究的所有真实正则路径查询中比例高达30%以上,足以说明单独对这一子问题进行优化研究有重要的实际意义。这类工作提出的方法常常会运用可达性算法中的优化技术。
第二类工作则旨在解决完整定义的正则路径查询。这类工作又可以进一步分为两种主要的技术路线:一是基于Datalog的方法,将Kleene闭包(正则表示中的*符号)转化为递归的Datalog程序或递归的SQL视图;二是基于自动机的方法,将正则表达式转化为对应的有穷自动机,以自动机来指导图上的搜索。本文将会侧重于介绍基于自动机的一类方法,但是需要注意这两种方法并没有绝对的优劣之分:[2]证明了两种方法生成的查询计划空间是互不包含的,并且提供了一个基于代价估计的生成高效混合型查询计划的算法。
为了便于后续理解,我们首先来看一种基于自动机的基础算法。以如下的图数据为例(引自[3]),其中有
共10个结点,边上有a,b,c,d,e,f共6种标签:
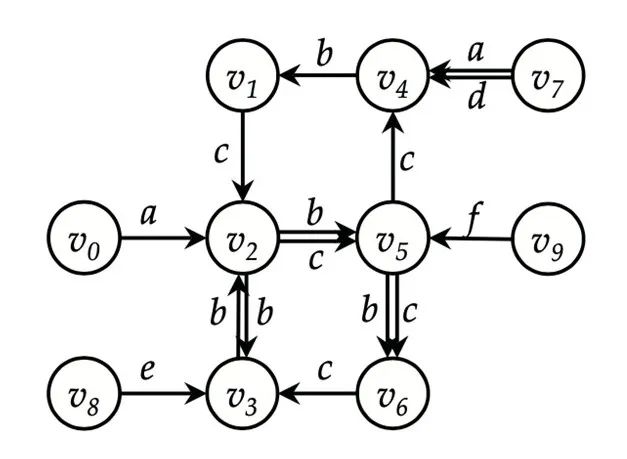
假设查询中给定的正则表达式是
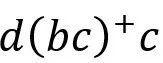
,其转化成的不确定有穷自动机(NFA)及其所指导的深度优先搜索流程如下图所示(引自[3]):
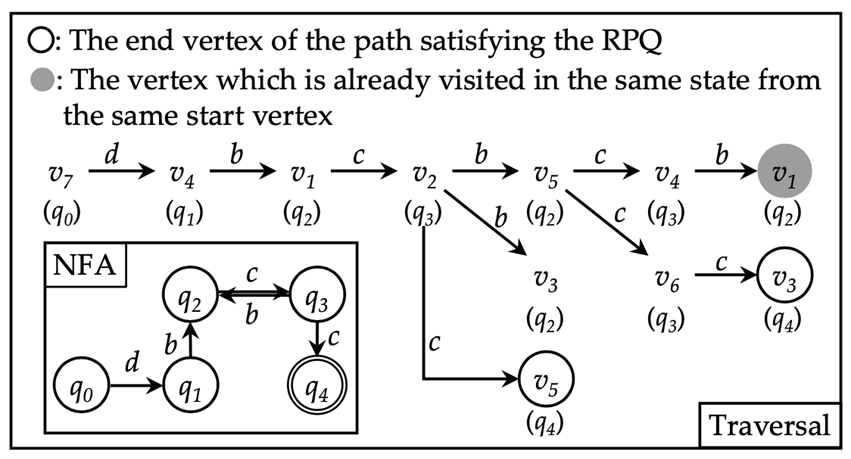
此次深度优先搜索从结点v7出发(对于这种基础算法,需要从图中每个结点出发做一次被自动机引导的深度优先搜索),对应NFA中的初始状态q0。深度优先搜索受自动机引导体现在以下两点:
-
沿出边访问邻居结点时,需先判断当前所在的NFA状态是否有对应该出边上标签的转移。如果有,则可以访问该邻居结点,同时将当前状态更新为NFA中转移到的状态;否则,不能沿此出边访问此邻居结点。如图中v7只能通过标签为d的出边访问邻居v4(从q0状态转移到q1),因为状态q0有对应标签a的转移,而没有对应另一条出边上的标签的转移。(特别地,到达NFA接受状态时,由于不存在可行的转移,必然发生回溯。)
-
标记“已访问”时,以结点-状态对为对象,而非结点。这意味着同一个结点可能被访问多次,但一定对应着不同的NFA状态。如v4被访问了两次,分别对应状态q1和q3。
路径索引
路径索引这一概念最早提出于XML文件处理的工作中。当其应用于RPQ时,给定一张数据图,路径查询应当存储某些正则表达式在该图上的结果集合,并可能在此基础上经过了压缩。伴随此索引,应有高效的读索引函数,当输入某个正则表达式时,检查索引中是否存储了其结果集合,如果存储了则返回之。
以下介绍三篇运用路径索引加速RPQ执行的工作。
Efficient regular path query evaluation using path indexes[4]

索引设计
这篇工作使用的索引名为K-路径索引(k-path index)。对于任意正整数k(为可调参数),给定一张边上带标签的有向图G,K-路径索引会索引所有的长度至多为k的路径,记作
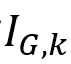
。索引的键为〈路径标签序列, 源结点, 目标结点〉三元组,输入某长度至多为k的路径标签序列,即可返回被这样的路径连接的源-目标结点对。索引中键是有序存储的。注意这种索引只存储了、且存储了所有仅包含连接运算(不包含其他正则表达式中允许出现的运算符,如或运算(|)、Kleene闭包(*)等)、长度至多为k的正则表达式(也就是路径标签序列)对应的结果集合。
我们以如下例子直观地了解K-路径索引的工作机制。假设数据图为社交网络,边上有knows(认识)和worksFor(供职于)这两种标签。我们希望知道人们朋友的朋友的上司是谁。这一关系可以表达为正则表达式knows⋅knows⋅worksFor,这同时也是一个长度为3的路径标签序列。若图上建立了k=3的K-路径索引,则必定包含此正则表达式的结果集合,可能表示为以下形式(引自[4]):

注意K-路径索引中还考虑了反向标签(如knows的反向标签以
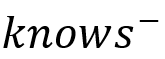
表示),因此索引的路径中所有边未必都是同方向的。比如正则表达式可以用于搜索认识同一个人的人们,其结果集合在k≥2的K-路径索引中也会存储。
在这篇工作的实验中,K-路径索引实现为基于B+树存储的关系表,使用PostgreSQL存储,并持久化到磁盘。推测其没有在图原生的场景下实现索引主要是基于实现便利性的考虑。与图原生的路径索引进行性能对比被列为未来工作。
查询算法
进行查询前,首先将正则表达式R转化为析取范式:
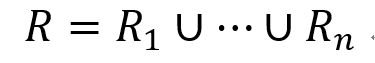
其中R1,⋯,Rn中均只含连接操作。
注意,为了保证正则表达式能够转化为严格的析取范式,这篇工作要求正则表达式中不出现Kleene闭包(*),而是以有穷次的重复代替:如(knows⋅worksFor)*可以用
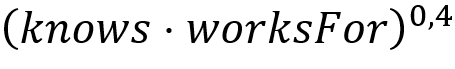
代替,其中上标0,4表示括号中的表达式至少出现0次,至多出现4次,相比Kleene闭包确定了出现次数的上限。作者指出,给定数据图G,对任意正则表达式R均存在正整数n(G),使得,以此说明他们设定这一限制的合理性。然而,在发起正则路径查询时,用户难以知道n(G)的具体取值,因此这一限制仍然削弱了这篇工作所提出方法的实用性。
例如,正则表达式
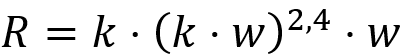
(其中k,w分别为knows,worksFor的简写)可以将有穷次的重复展开为R=k⋅(kwkw∪kwkwkw∪kwkwkwkw)⋅w,然后再转化为析取范式R''=kkwkww∪kkwkwkww∪kkwkwkwkww.
得到析取范式后,每个子句R1,⋯,Rn分别处理,最终再对各子句的结果集合进行并操作。对于每个子句,给出了两个版本的查询算法。
第一版算法称为Semi-naïve,直接将子句从左到右以k为步长切割成多块,每一块均可由K-路径索引获取结果集合。合并这些部分结果时,由于索引的有序性,尽可能使用归并连接(merge join),否则使用哈希连接(hash join)。
例如上述正则表达式转化为析取范式后的子句kkwkww,使用k=3的K-路径索引辅助查询执行,则其结果集合可表示为
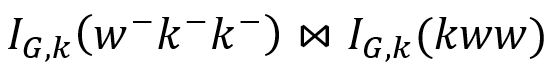
,其中使用而非是为了便于在拥有以k为标签的结点上使用归并连接。
第二版算法称为minSupport,在第一版的基础上额外使用了统计信息。具体而言,这版算法需要维护一个称为
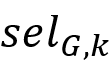
的数据结构,输入某长度至多为k的路径标签序列,它能够返回这一标签序列出现频次的估计值。这个数据结构基于等深直方图(equi-depth histogram)来实现。在的支持下,处理一个子句时,扫描其中所有长度为k的子串(若子句长度为l,则共检查l-k+1个子串),选择频次最低的从K-路径索引中取结果集合;然后检查子句中该子串的左侧和右侧部分,若长度小于或等于k,直接从索引中取结果集合,否则递归执行此过程。最后将左侧(记作LEFT)结果、最高频子串(记作D')结果、右侧(记作RIGHT)结果进行合并,选择以下方案中代价最低的方案(文中没有详细描述代价模型)(引自[4]):
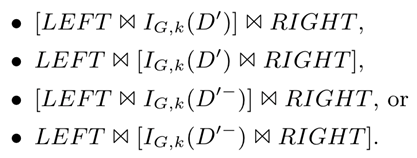
实验结果
这篇工作实验所使用的数据集如下图所示(引自[4]):
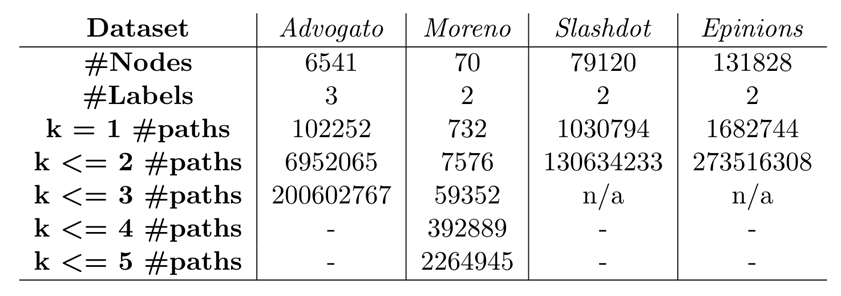
可以发现,这些数据集的规模都相当小(最大的数据集也在百万边级别),且在稍大的数据集上无法建起k≥3的K-路径索引(时间和空间开销巨大)。因此,可扩展性不佳是这篇工作的最大问题。
文中仅给出了Advogato数据集上的实验结果(作者称其他数据集上的实验结果类似)(引自[4]):
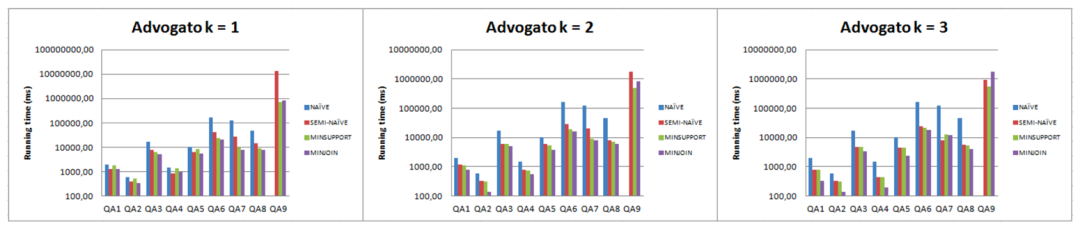
其中minJoin算法以减少连接的次数为优化目标,在这篇工作中没有具体介绍(第一作者的硕士毕业论文[5]中给出了详细说明)。Naïve算法与Semi-naïve类似,但固定k=1,且没有考虑尽量使用合并连接的优化策略,实际上相当于由有限自动机指导的广度优先搜索。可以看到,在几乎所有查询上,Semi-naïve算法的表现优于Naïve,而minSupport又优于Semi-naïve,这从实验层面上证实了索引和统计信息的有效性。但是,这篇工作并没有将其算法与当时最优的一系列RPQ算法进行实验对比,难以判断它是否占优势。
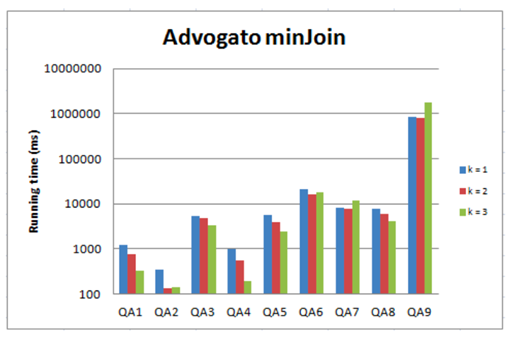
变换k的值进行测试时,文中仅给出了minJoin算法的表现(作者称minSupport的表现呈现出类似趋势)。可以发现k的值并非越大越有利于降低查询时间,这可能是因为更大的k引致更大的索引、从而增加了读索引的时间。文中并未给出针对给定数据图如何选择k的指导建议。
PAIRPQ: An Efficient Path Index for Regular Path Queries on Knowledge Graphs [6]

这篇工作是对上一篇[4]方法的直接改进。
索引设计
在索引设计方面,本文提出改进的主要动机是[4]的索引空间消耗过大,导致可扩展性不佳;本文希望降低索引的空间消耗以提升可扩展性。因此,本文仍保持K-路径索引的存储结构不变,而降低所索引的路径标签序列数目:不再对所有长度至多为k的路径标签序列建索引,而是选择其中一部分建索引。如果能够事先知道查询负载,那么在空间有限的前提下,对最频繁出现的子查询建索引应为较优的方案。本文考虑无法事先知道查询负载的场景,而假设查询中路径标签序列的分布与数据图中一致;因此只对图中最频繁出现的路径标签序列建索引。文中提出了一种贪心的频繁路径挖掘(frequent path mining, FPM)算法,基本思想为假设频繁路径大多为频繁的子路径拼接而成(贪心思想);算法流程中,将判断是否频繁的频率阈值作为参数,在从短到长拼接路径的过程中舍去不够频繁的(不再作为拼接单元),直至长度达到k.
查询算法
本文基本沿用[4]中的minSupport算法,仅做一处优化:将正则表达式转化为DNF后,首先提取各子句的公共前缀,对公共前缀进行处理后再处理各去除了前缀的子句,进一步减少重复计算。如正则表达式R转化为DNF后:
R=R1∪⋯∪Rn
再提取公共前缀(其中
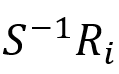
表示从Ri中去除前缀S,已知有算法可在正则表达式规模的先行时间内执行此操作):
实验结果
这篇工作实验所使用的数据集如下图所示(引自[6]):
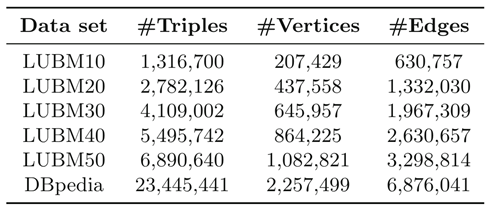
这些数据集的规模普遍显著大于[4]中所用数据集的规模,说明有选择性地对路径标签序列建索引的方法能够有效降低空间开销。
下图展示了本文的方法在不同数据集上索引的空间和时间开销(引自[6]):
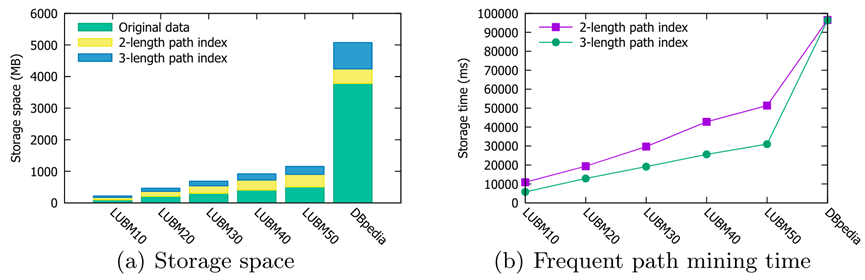
可见索引的空间开销在所有数据集上均没有显著超过原数据的大小,时间开销在秒到分钟级,均在实际应用的可接受范围内。值得注意的是,本文索引的空间和时间开销应该均与建索引的FPM算法中使用的频率阈值密切相关(频率阈值越低,索引的空间和时间开销越大),但实验中设定的具体值并未在文中给出。
下图展示了本文的查询性能(引自[6]):
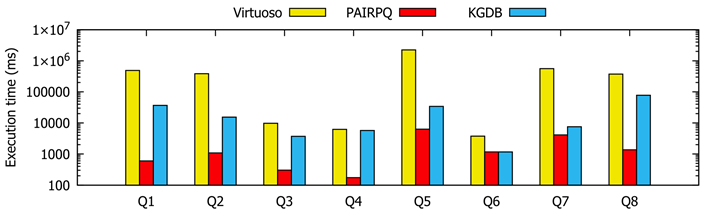
其中PAIRPQ为本文提出的优化方法,KGDB为优化前的基准方法(文中没有详细介绍)。可见本文方法整体而言对提升查询性能有效。然而,没有进行本文的方法与其改进基础[4]的性能对比,因此无法确认本文提出的改进有多大的提升效果;也没有与当时最优的其他RPQ算法对比。而与Virtuoso系统的端对端比较中,又没有除去RPQ执行以外无关因素的影响,因此结果并不具有代表性。
Regular Path Query Evaluation Sharing a Reduced Transitive Closure Based on Graph Reduction[3]

这篇工作没有显式提及路径索引的概念,提出的索引结构却的确是一种特殊的路径索引。在下面的介绍中,我们将特别聚焦于这种索引与前两篇工作的联系与区别。
索引设计
回顾前两篇工作的K-路径索引,键为〈路径标签序列, 源结点, 目标结点〉三元组。在这篇工作中,对每个路径标签序列R,概念上会存储两张索引表:一张也是源-目标结点表,但其中的源结点、目标结点并非数据图中原本的结点,而是经过收缩(reduction)的图上的强连通分量(Strongly Connected Component, SCC);另一张表则是数据图中结点与前述SCC之间的映射关系。这两张表联合起来,表示源SCC映射的所有结点与目标SCC映射的所有结点之间存在满足该标签序列的Kleene闭包(即R+)的路径。(之所以是Kleene闭包而不仅是该标签序列本身,是因为此处的源-目标结点表并非经过收缩的图上所有边的列表,而是图的传递闭包。具体的推导关系将在下文介绍。)由于图经过收缩、进行了从结点到SCC的映射,所以这实际上是一种经过压缩的路径索引。下图展示了文中索引的大致结构:

建索引的流程如下图所示(引自[3]),分为边收缩(edge-level reduction)和结点收缩(vertex-level reduction)两阶段。最终,在原数据图上正则表达式
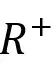
的结果集合即为在经过收缩的图上的传递闭包经过从SCC到结点的映射后的结果,即为上述索引结构中蕴涵的结果。注意对每个需要索引的正则表达式,均需运行一次建索引的全流程。(这篇工作没有给出如何选择对哪些正则表达式建索引的指导建议。)
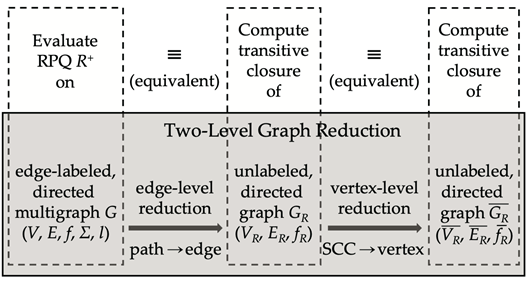
第一阶段为边收缩,基本思想为将满足标签序列R的路径映射为新图中的边。这篇工作直接调用[2]中的算法计算出所有满足标签序列R的路径。下图(引自[3])展示了R=b⋅c时在左侧的数据图G上执行边收缩的过程,得到收缩后的图为右侧的G(b⋅c). 左侧满足R的路径和映射到右侧的边以相同颜色标出。例如原图中存在从v4经过v1到达v2,标签序列为b⋅c的路径,则收缩后的图上会有从v4指向v2的相应边(均以红色标出)。
经过边收缩,在原图上R的结果集合即为收缩后的图的边列表;因而在原图上R+的结果集合即为收缩后的图的传递闭包。将原图记作G,经过边收缩的图记作G_R,则上述结论用形式化的语言表达,即为:(vi, vj) 在G上R+的结果集合中 ⇔ (vi, vj )∈TC(GR),其中TC(⋅)表示图的传递闭包。
第二阶段为结点收缩,基本思想为将上一步得到的GR中的每个强连通分量收缩为一个结点。这实际上是可达性问题相关研究中的一种常用技巧,因为这一操作能够保持图的可达性关系,即原图上vi可达vj当且仅当结点收缩后映射到的si可达sj.(由强连通分量中的结点相互可达的性质容易证明。)下图(引自[3])展示了在上述
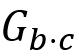
上执行结点收缩的过程,得到收缩后的图为右侧的左侧属于同一个强连通分量的结点和右侧收缩后的图中对应映射到的结点以相同颜色标出,例如v2和v4属于同一个强连通分量s0,映射到右侧的若两个强连通分量所包含的结点之间存在边,则在收缩后的图中映射到的两个结点之间添加同方向的边(若一个强连通分量所包含的结点之间存在边,则在映射到的结点上添加自环)。
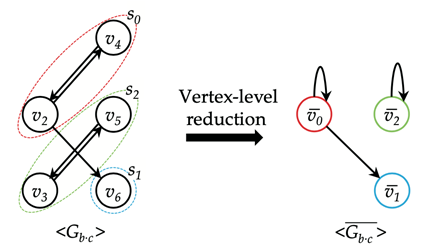
经过结点收缩,GR上的可达性关系不变。将经过结点收缩的图记作
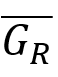
,则,其中是vi,vj所属的SCC映射到的结点。
结合上述两阶段,可以推导出:(vi, vj) 在G上R+的结果集合中 ⇔
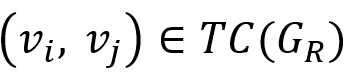
⇔。因此,只需存储(前述的源-目标结点表)、及数据图中结点与SCC之间的映射关系,即等价于存储了G上R+的结果集合。
可以看到,相比前两篇工作中的路径索引,这篇工作的索引存储的并非路径标签序列的查询结果集合,而关注路径标签序列的Kleene闭包;另外,这篇工作还增加了结点收缩的阶段,而前两篇工作相当于仅进行了边收缩、而且没有计算收缩后图上的传递闭包。存储传递闭包使得这篇工作的索引空间消耗上升,而结点收缩对索引又起到了一定的压缩作用,理论上无法确定空间消耗相比前两篇工作是上升还是下降。
查询算法
与前两篇工作类似,这篇工作在执行查询前,也先尝试将正则表达式转化为DNF。然而,由于这篇工作支持Kleene闭包,实际上不能保证正则表达式能够转化成标准的DNF。因此,在进行转化时,先将最外层的Kleene闭包看作一个字母。例如,正则表达式(a│b)⋅c⋅(d│e)*中的(d│e)*将被看作字母,转化为(a⋅c⋅(d│e)* )|(b⋅c⋅(d│e)* ).
接下来同样分别处理各子句。每个子句可以表达为Prefix⋅R+⋅Postfix或Prefix⋅R*⋅Postfix的形式(为了方便,下文不失普遍性地假设均为Prefix⋅R+⋅Postfix形式),其中Postfix不含Kleene闭包;如果Prefix或R含有Kleene闭包,则对其括号中的部分递归处理(尝试转化为DNF、分别处理各子句)。
处理子句Prefix⋅R+⋅Postfix时,首先获取Prefix和R+的结果集合(可能涉及递归处理;遇到标签序列的Kleene闭包时,检查索引中是否已经存储了结果集合,若有则直接使用),连接得到Prefix⋅R+的结果集合,再从这一中间结果集合的目标结点出发,获取Postfix的结果集合(类似关系数据库中的半连接)。对于索引中未存储相应结果的部分,直接调用[2]中的算法获取结果。
连接Prefix和R+的结果集合时,假设R+的结果集合已经存储在索引中,作者指出连接过程中可能会出现无用和多余的计算(如下图,引自[3]):无用的计算指扫描索引中R+的结果集合里无法与Prefix连接的部分(如图中useless-1 operations);多余的计算指进行多次产生Prefix⋅R+的结果集合中同一对结点的连接(如图中redundant-1, redundant-2 operations,例如(v0,v1)和(v1,vk)、(v0,v2)和(v2,vk)、……(v0,vn)和(vn,vk)分别做连接,最终得到的均为(v0,vk)这对结点)。
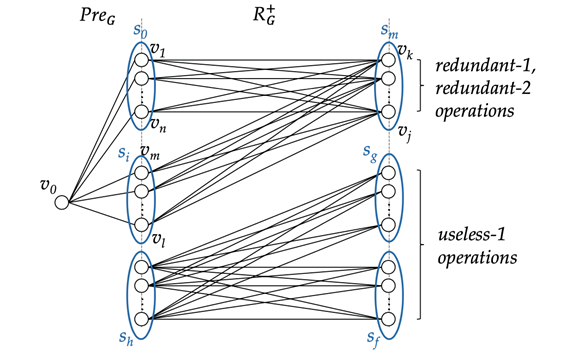
因此,这篇工作进一步提出了消除这些无用和多余计算的方法,以进一步提升查询效率。注意上述问题的出现是由于先将索引的两部分(源-目标SCC表、原图中结点与SCC之间的映射关系)做了连接,实际上是将
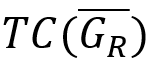
重新展开成了. 更优的方法是:先不做索引内部的连接,而是将Prefix的目标结点映射到SCC,再与源-目标SCC表连接,最终重新映射回原图中的结点,这样无用和多余的计算均被消除,如下图(引自[3]):
实验结果
这篇工作实验所使用的数据集如下图所示(引自[3]):
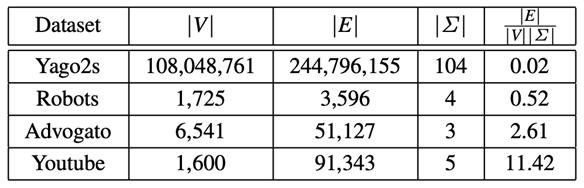
其中后三个数据集的规模都非常小,边数不超过万级(小于本文介绍的第一篇工作所用的数据集[4]);第一个数据集的边数达到亿级,但由于总标签数|Σ|很大,对于实验中所用的小规模正则表达式(所含的标签数不超过5种),所涉及的图中边规模应该也较小。这使得可扩展性不佳也成为这篇工作的最大问题。
值得注意的是,这篇工作首要关注的是同时优化多个RPQ的场景,因此在实验中生成了大小分别为1, 2, 4, 6, 8, 10的RPQ集合进行测试,其中在同一个集合中的RPQ均共享一个Kleene闭包,索引在此Kleene闭包上建立。为了与不建索引的方法较为公平地比较,将建索引的时间也平摊到集合中每一个查询上,作为查询时间的一部分。
为了方便,这篇文章提出的方法命名为RTCSharing(简写为RTC)。对比方法包括以下两种:
-
FullSharing(简写为Full):只进行边收缩和收缩后的图上传递闭包的计算,作为索引存储;不做结点收缩。(即为[7]的方法)
-
NoSharing(简写为No):[2]的方法,无索引。
下图(引自[3])展示了在不同数据集上文中方法与对比方法的查询时间和索引大小(此时RPQ集合大小为4)。注意左边两张图、右边两张图分别代表同样的数据,从左到右数据点依次代表上表中四个数据集上的查询表现,只是因为数据集的点、边规模不同,左二、右二图将RTC作为基准做了归一化处理。
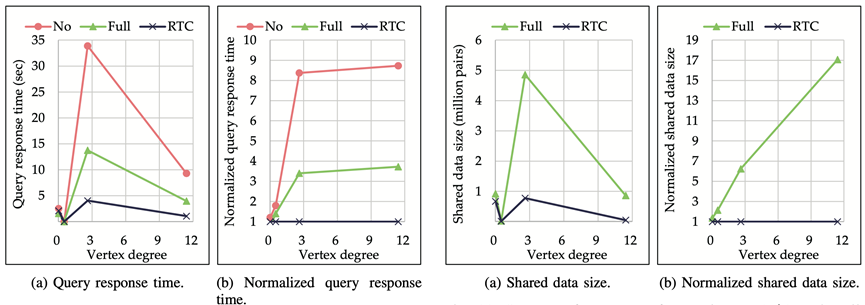
可见图的平均度数越大,这篇工作所带来的对查询性能的提升越大,结点收缩所能节省的空间也越多。
在不同的RPQ集合大小下,各方法平均查询时间的对比如下图(引自[3]),其中右图同样是以RTC为基准做了归一化处理:
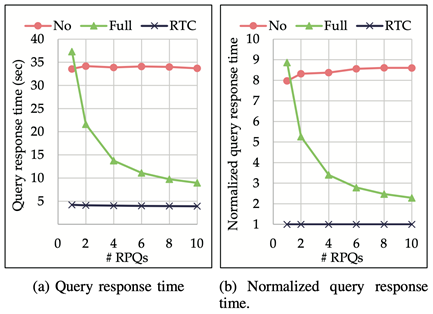
由于建索引的方法(RTC和Full)在当前的设定下,处理一个RPQ集合前均只需建一次索引,所以随着查询集合增大、建索引时间被分摊的分母增大,RTC和Full的平均查询时间均会有所下降,只是RTC建索引的时间远小于Full建索引的时间,因此下降相对不明显。注意,虽然Full相对于RTC少做了一步结点收缩,但Full后续是在只经过边收缩的图上计算传递闭包,而RTC是在进一步结点收缩的图上计算传递闭包,前者比后者多耗费的时间在大部分的图上会远大于结点收缩的时间。因此,无论RPQ集合大小如何增长,在平均查询时间上RTC相对于Full几乎一定占优势。
小结
本文主要介绍了三篇使用路径索引加速正则路径查询的工作。虽然指向同一种查询,但其侧重点有所不同。总的来说,路径索引对加速正则路径查询确有效果,但尚未解决以下问题,需要未来工作继续加以研究:
-
如何选择对哪些正则表达式建索引;
-
可扩展性问题(主要是过大的空间消耗)。
参考文献
[1] A. Bonifati, W. Martens, and T. Timm, “An analytical study of large SPARQL query logs,” VLDB J., vol. 29, no. 2–3, pp. 655–679, May 2020, doi: 10.1007/s00778-019-00558-9.
[2] N. Yakovets, P. Godfrey, and J. Gryz, “Query Planning for Evaluating SPARQL Property Paths,” in Proceedings of the 2016 International Conference on Management of Data, San Francisco California USA, Jun. 2016, pp. 1875–1889. doi: 10.1145/2882903.2882944.
[3] I. Na, I. Yi, K.-Y. Whang, Y.-S. Moon, and S. J. Hyun, “Regular Path Query Evaluation Sharing a Reduced Transitive Closure Based on Graph Reduction,” ArXiv211106918 Cs, Nov. 2021, Accessed: Dec. 20, 2021. [Online]. Available: http://arxiv.org/abs/2111.06918
[4] G. Fletcher, J. Peters, and A. Poulovassilis, “Efficient regular path query evaluation using path indexes.” OpenProceedings.org, 2016. doi: 10.5441/002/EDBT.2016.67.
[5] J. Peters, “Regular Path Query Evaluation Using Path Indexes,” 2015.
[6] B. Liu, X. Wang, P. Liu, S. Li, and X. Wang, “PAIRPQ: An Efficient Path Index for Regular Path Queries on Knowledge Graphs,” in Web and Big Data, vol. 12859, L. H. U, M. Spaniol, Y. Sakurai, and J. Chen, Eds. Cham: Springer International Publishing, 2021, pp. 106–120. doi: 10.1007/978-3-030-85899-5_8.
[7] Z. Abul-Basher, “Multiple-Query Optimization of Regular Path Queries,” in 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, Apr. 2017, pp. 1426–1430. doi: 10.1109/ICDE.2017.205.

















 1259
1259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









