






文章目录
前言
上一节已经完成了该精准营销的项目,这一节没什么好写的,心头一热就来写一写文字。来叙述一下如何构造客户标签体系。
客户标签体系构建
客户标签可以分为以下四种:
1)事实类标签:可以直接从客户交易记录中进行统计和计算的标签例如网购消费、餐饮消费、商旅消费等
2)规则类标签:规则类标签是在事实类标签的基础上,结合人工经验,对客户的某项指标进行的计算或归类例如RFM标签、是否休眠客户、是否有高端消费等
3)预测类标签:原始数据中不能直接提取,需要借助模型进行预测的标签例如客户价值等级
4)文本类标签:从客户交易记录的文本中提取的关键词也可用于描述客户偏好,将此部分关键词作为文本类标签例如彩票、儿童、孕妇、基金等
事实类标签构建
关键词匹配
对某一列Series对象进行关键词匹配,使用contains()函数带入关键词进行匹配Series.str.contains(pattern,case=True)
分组聚合
DataFrame中的groupby()函数将数据依照某一个属性进行分组DataFrame. groupby(by=None)
规则类标签构建
从事实类标签进行延伸
有无高端消费(high_consumption)
取最大消费金额的上四分位数作为阈值。如果客户的最大消费金额大于该阈值,则将该客户定义为有高端消费(取值为1),反之则无高端消费((取值为0)
是否休眠客户(sleep_customers)·
设定交易次数的下四分位数为阈值。交易次数小于阈值的客户则视为休眠客户,(取值为1)
交易次数大于等于阈值的客户则视为活跃客户(取值为0)
RFM模型
RFM模型可以得出一定的规律性,整理这方面的标签有助于全方位了解客户,并决定在哪个时间段开展营销活动。
消费频率和消费金额是了解产品是否受欢迎的主要考量依据,也是区分客户的重要标准。所以需要详细记录客户在这两个方面的信息,并对此进行分析。
在众多客户关系管理模型(CRM)中,RFM被广泛使用。RFM模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的购买时间、购买总体频率以及购买金额三项指标来描述该客户的价值状况。
RFM模型较为动态地层示了一个客户的全部轮廓,这对个性化的沟通和服务提供了依据,同时,如果与该客户打交道的时间足够长,也能够较为精确地判断该客户的长期价值(甚至是终身价值),通过改善三项指标的状况,从而为更多的营销决策提供支持。
RFM分别是Rencency、Frequency、Monetary三个单词的缩写:
Rencency 代表用户最近一次消费,假设购买时间越短,对产品及品牌印象度越高;
Frequency 代表一定周期内用户购买的次数(消费频数),假设购买频率越高,对品牌忠诚度越高;
Monetary 代表一定周期内用户的消费总金额,假设金额越高,给店铺创造的收入和利润越高
RFM总得分:每个维度排序后等频划分为四组,每个组计算得分,最近一次消费(R)按时间得分:取值越小得分越高,消费频次(F)及消费金额(M取值越大得分越高,将每个客户对应的三个评分标记相加,作为客户RFM的总得分(Total_Score)
预测类标签构建
根据提取出的事实类和规则类标签建立模型,对没有客户价值等级标签的客户进行预测
针对字符型特征,需要进行数值编码,以便模型能更好的处理数据,处理连续型数据可以将数据进行离散化,使模型对异常数据有更强的鲁棒性,同时也能降低模型运算复杂度,提升模型运算速度,将有客户价值等级的数据随机划分为训练集与测试集,训练逻辑回归模型。使用训练好的逻辑回归模型,对客户价值等级未知的客户进行预测
特征提取
one-hot编码:
onehot编码又叫独热编码,其为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。Onehot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
特征处理
等距离散化:
根据连续型特征的取值,将其均匀地划分为k个宽度近似相等的区间
根据每个客户该特征的取值,相应地划入对应的区间,每个区间赋予一个标签
等频离散化:
特征数据总量为n,将其划分为k个区间段,使得每个区间段包含的数据个数为”,离散化后区间内的数据量尽可能均衡,根据每个客户该特征的取值,相应地划入对应的区间,每个区间赋予一个标签
训练集和测试集
特征变量X:预测所需的特征,使用所有事实类和规则类标签作为X。目标变量y:需要预测的特征,客户价值等级为y
Sklearn中的model_selection模块中的train_test_split()函数,用作训练集和测试集划分train_test_split(x,y,test_size = None , random_state = None),x,y:分别为预测所需的所有特征,以及需要预测的特征(即客户价值等级)
test_size:测试集比例,例如test_size=0.2则表示划分20%的数据作为测试集
random_state:随机种子,因为划分过程是随机的,为了进行可重复的训练,需要固定一个random_state,结果重现。函数最终将返回四个变量,分别为X的测试集和训练集,以及y的测试集和训练集
预测模型:逻辑回归
逻辑回归引入Sigmoid函数,将连续型的输出映射到区间(0,1),Sigmoid 函数如下所示
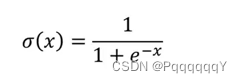
当输入x很大或很小时,该函数以接近于0或1的值输出
在逻辑回归中,若yiE{1,-1},则输出可以解释为样本属于正类的概率
文本类标签构建
文本标签的提取方法
本项目中使用了两种文本特征提取方式,分别为CountVectorizer()和TfidfVectorizer():
CountVectorizer()对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频数CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform()函数计算各个词语出现的次数。不考虑词法和语序,每个词语相互独立,建立一个词典用于构建特征向量,向量每个位置表示的单词与上面的数组一致,值为该单词在句子中出现的次数,第一个句子:[1,1,2,1,1,0,0]第二个句子:[0,1,2,1,0,1,1]
描绘用户画像
用户画像是根据用户社会属性、生活习惯和消费行为等信息抽象出的一个标签化的用户模型。
标签化的用户根据不同产品、不同目的,用户画像又分:品类用户画像,产品用户画像,品牌用户画像,用户行为轨迹画像,用户态度,价值观画像等。
通过用户画像,我们能描述、认识、理解用户,进而为产品开发、用户服务、市场探索、品牌策略、营销方案提供决策支持。
因此,需要用户画像的人很多。市场、运营、公关、产品、研发、销售都需要了解自己的用户。比如:同样是新闻类公众号,A的用户大多是20-40岁的年轻人,B的用户大多是40-60岁中年男性,他们推送内容的主题、风格必然大相径庭。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









