







pytorch learn
加载数据
dataset()提供一种方式获取数据及其label
dataloader()为后面的网络提供不同的数据形式
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
self.path=os.path.join(root_dir,label_dir)
self.img_path=os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir="dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset=MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
train_dataset=ants_dataset+bees_dataset
Dataset类的代码实战,基本上就是根据读取蚂蚁和蜜蜂图片的路径来获取图片的基本信息
TensorBoard的使用
TensorBoard的安装
打开Anaconda Prompt,激活pytorch模式conda activate pytorch
或者直接点击pycharm的Terminal进入pytorch环境,输入指令pip install tensorboard安装成功
add_scalar()的使用
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# writer.add_image()
for i in range(100):
writer.add_scalar("y=x",i,i) #表格名、y的值、x的值
writer.close()
执行命令tensorboard --logdir=logslogdir=事件文件所在文件夹名
tensorboard --logsdir=logs --port=xxx可以自己指定端口输出
画新图的话可以将logs里文件删除后重新运行
add_image()的使用(常用来观察训练结果)
利用Opencv读取图片,获得numpy型图片数据
安装opencv
利用numpy.arry(),对PIL图片进行转换
import numpy as np
img_arry=np.arry(img)
print(type(img_array))
结果输出:<class 'numpy.ndarray'>可以看到图片类型已转换为numpy类型
代码实例:
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter("logs")
img_path = "dataset/train/bees/16838648_415acd9e3f.jpg"
img_PIL = Image.open(img_path)
img_arry = np.array(img_PIL)
writer.add_image("test",img_arry,2,dataformats='HWC')
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()
通过tensorboard --logdir=logs在端口6006可以看到图片已经显示到ui网页上了
Transforms的使用
Transform结构及用法
Transform实际一个py文件,是一个工具箱,里面有不同的工具。将特定格式的图片,经过工具处理后,为我们输出一个结果。
python的用法-》tensor数据类型,通过transform.ToTensor去解决两个问题
- 1.transform如何使用
#前置条件
from torchvision import transforms
from PIL import Image
img_path="dataset/train/ants/0013035.jpg"
img=Image.open(img_path)
# 使用方法
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img)
创建具体的工具:tool = transforms.ToTensor()
使用工具
输入:input
输出:result=tool(input)
- 2.为什么需要tensor数据类型
tensor数据类型是一个包装了反向神经网络所需要的理论基础的参数
常见的Transforms
| 常见的Transforms | ||
|---|---|---|
| 输入 | PIL | Image.open() |
| 输出 | tensor | ToTensor |
| 作用 | narrays | cv.imread() |
ToTensor
ToTensor的使用在上面已经讲解过了,见上一小节的代码
Normalize
output[channel]=(input[cjannel]-mean[channel])/std[channel]
标准化的代码使用如代码所示,使用步骤与ToTensor差不多
# Normalize归一化使用
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)
可以看到,经过标准化后图片的参数发生了改变,在6006端口上,图片颜色也发生了明显的改变
normalize是一种可以加快梯度下降速度的常规操作
Resize
Resize()使用如代码所示,Resize()函数中图片为PIL格式,需转化为ToTensor
# Resize
print(img.size)
# 设置新的尺寸大小数值是一个整体,记得要在一个括号里面写
trans_resize = transforms.Resize((512,512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> tosensor -> img_size PIL
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
print(img_resize)
Compose
Compose()用法:Compose()中的参数需要是一个列表,Python中,列表的表示形式为[数据1,数据2,…]在Compose中,数据需要是transforms类型,所以得到,Compose([transforms参数1,Compose([transforms参数2,…])
# Compose - resize - 2
trans_resize_2 = transforms.Resize(512)
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize",img_resize_2,1)
RandomCrop()
# RandomCrop
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
小总结
- 关注输入和输出类型
- 多看官方文档
- 关注方法需要什么参数
- 不知道返回值的时候:
print()print(type())debug
torchvision中数据集的使用
例程中使用CIFAR10的数据集,使用大概就是先将数据集下载下来,还有将图片转化为Totensor格式就可以在ui界面展示出来,以下为代码的使用:
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 将图片转化为Totensor格式
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
writer = SummaryWriter("p10")
for i in range(10):
img,target= test_set[i]
writer.add_image("test_set",img,i)
writer.close()
dataloader的使用
代码示例:
import torchvision
# 准备测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor())
test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
# 测试数据集中第一张样本及其target
img,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step=0
for data in test_loader:
imgs,targets = data
writer.add_images("test_data",imgs,step)
step = step + 1
writer.close()
神经网络的基本骨架-nn.Moudle的使用
读了一下官方文档,学习了如何搭建网络,大概就是初始化,然后定义类,使用神经网络,目前还没看出来神经网络与普通的类有什么区别,再学习两节课再看看。
所有的神经网络必须从类中继承,可以在模型中进行修改。
forward()定义了一个计算,所有子类都应当重写
import torch
from torch import nn
class Nnlearn(nn.Module):
def __init__(self):
super(Nnlearn,self).__init__()
def forward(self,input):
output = input + 1
return output
nnlearn = Nnlearn()
x=torch.tensor(1.0)
output = nnlearn(x)
print(output)
卷积
查看tourch.nn.founction文档https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d
卷积的矩阵需要是一个四维矩阵,分别是:样本数、矩阵深度、高度和宽度,所以需要reshape一下二维数组。padding是在矩阵四周填上数值为0的行和列
import torch
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input = torch.reshape(input,[1,1,5,5])
kernel = torch.reshape(kernel,[1,1,3,3])
output = torch.nn.functional.conv2d(input,kernel,stride=1)
print(output)
输出结果:
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
神经网络-卷积层
总结来说,将之前的各种操作结合起来,dataset操作,还有dataloader进行数据加载,将数据初始化以后,定义神经网络,进行初始化设置卷积操作,设置好卷积的各个参数,随后定义神经网络方法,之后调用方法,然后将处理前的图片和处理后的图片展示到ui当中,因为处理后这值得输出频道为6,需要reshape一下才能显示出来。
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataload=DataLoader(dataset=dataset,batch_size=64)
class NNmodule(nn.Module):
def __init__(self):
super(NNmodule,self).__init__()
from torch.nn import Conv2d
self.conv1=Conv2d(3,6,3,1,0)
def forward(self,x):
x=self.conv1(x)
return x
nnmodule=NNmodule()
writer=SummaryWriter("./logs")
step=0
for data in dataload:
imgs,target=data
output=nnmodule(imgs)
writer.add_images("input",imgs,step)
output=torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step+=1
神经网络-最大池化的作用
最大池化就是在局部的池中选最大的值作为这个池子的值,Ceil_model=True就是在格子不足的情况下仍会保留取最大值
最大池化的目的是保留特征但数据量变小,计算的参数变少了,训练的就会更快
池化核是多x,就是x*x的池子,走x步
方便理解,先用数组举例
input=torch.tensor([[1,2,0,3,1],
[ 0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
input=torch.reshape(input,[-1,1,5,5])
class NNmodule(nn.Module):
def __init__(self):
super(NNmodule,self).__init__()
self.maxpool=MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,x):
x=self.maxpool(x)
return x
nnmodule=NNmodule()
output=nnmodule(input)
print(output)
输出结果,可以看到最大池化的结果和原理
tensor([[[[2, 3],
[5, 1]]]])
进行一个图片的代码实例,实际还是将图片加载以后调用最大池化的那个类,将图片最大池化后,使用tensorboard展示到ui中,池化的效果就和大马赛克似的,废话不多说,代码一看就懂
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",transform=torchvision.transforms.ToTensor(),train=False,download=True)
dataloader=DataLoader(dataset,batch_size=64)
class NNmodule(nn.Module):
def __init__(self):
super(NNmodule,self).__init__()
self.maxpool=MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,x):
x=self.maxpool(x)
return x
nnmodule=NNmodule()
step=0
writer=SummaryWriter("logs")
for data in dataloader:
imgs,target=data
writer.add_images("input",imgs,step)
output=nnmodule(imgs)
writer.add_images("output",output,step)
step+=1
writer.close()
神经网络-非线性激活
非线性激活为了给神经网络提供一些非线性特征,最常见的非线性处理relu(),就是在input<0的时候取值为0。给出relu的使用示例:
import torch
from torch import nn
from torch.nn import ReLU
input=torch.tensor([[1,-0.5],
[-1,3]])
input=torch.reshape(input,(-1,1,2,2))
class NN_module(nn.Module):
def __init__(self):
super(NN_module,self).__init__()
self.relu1=ReLU()
def forward(self,input):
output=self.relu1(input)
return output
nn_module=NN_module()
output=nn_module(input)
print(output)
输出结果为:可以看到输入的负数全都变为0了
tensor([[[[1., 0.],
[0., 3.]]]])
对图片进行非线性激活原理很简单,已经不需要看教程了,自己完全可以写出来了
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
class NN_module(nn.Module):
def __init__(self):
super(NN_module,self).__init__()
self.relu1=ReLU()
self.sigmoid1=Sigmoid()
def forward(self,input):
output=self.sigmoid1(input)
return output
nn_module=NN_module()
writer=SummaryWriter("logs")
step=0
for data in dataloader:
imgs,target=data
writer.add_images("input",imgs,step)
output=nn_module(imgs)
writer.add_images("output",output,step)
step+=1
writer.close()
神经网络-线性层及其他层介绍
线性层就是将数据展开,原来是个33的,展开成19,flatten就是将数据展开成一行.这节课讲的有点粗糙,对原理有一定的要求,应当去补一下原理课,这节课学习后神经网络就算结课啦,代码就不敲了,后面如果想不起来就去看课程吧,代码在16分组左右。链接https://www.bilibili.com/video/BV1hE411t7RN/?p=21&vd_source=7464dde2afa68c9bd2054bc84877f505
神经网络-搭建小实战和Sequential的使用

可以看到这个神经网络已经给出每一层的步骤和输出和输出,经过了三次卷积和三次池化,注意卷积时需要计算padding和stride,如果哪个函数的参数不会填,可以按Ctrl+p,编辑器会提示应当填哪项内容,Sequential()函数会将多个行为封装起来,这样就不用在forward中逐个调用了。还学习了一个新的add.graph(),它可以将每一步的卷积和池化等操作通过图像表现出来,虽然没什么用,但是展现的很清晰。
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Sequential, Flatten, Linear
from torch.utils.tensorboard import SummaryWriter
class NN_module(nn.Module):
def __init__(self):
super(NN_module,self).__init__()
self.model1=Sequential(
Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,1,2),
MaxPool2d(2),
Conv2d(32,64,5,1,2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x=self.model1(x)
return x
input=torch.ones((64,3,32,32))
nn_module=NN_module()
output=nn_module(input)
print(output.shape)
writer=SummaryWriter("logs")
writer.add_graph(nn_module,input)
writer.close()
由此神经网络就学习完成了,可以搭建一个简单的神经网络了。
损失函数与反向传播函数
| output | target |
|---|---|
| 选择(10) | 选择(30) |
| 填空(10) | 填空(20) |
| 解答(10) | 解答(50) |
| Loss=(30-10)+(20-10)+(50-10)=70 |
- 计算实际输出和目标间的差距
- 为我们更新输出提供依据(反向传播)
L1Loss()的原理很简单,就是将数值做差后取平均数,使用也很简单,需要注意一下生成数组要取tensor类型并且reshape一下,代码:
import torch
from torch.nn import L1Loss
input=torch.tensor([1,2,3],dtype=float)
target=torch.tensor([1,2,5],dtype=float)
input=torch.reshape(input,(1,1,1,3))
target=torch.reshape(target,(1,1,1,3))
loss=L1Loss()
result=loss(input,target)
print(result)
MSE函数同理,只不过公式改成了(x-y)^2,代码不做演示了,函数为MSELoss()
CrossEntropyLoss交叉熵
此损失函数的公式为:
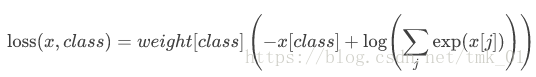
没太看明白,先附上代码吧
import torch
from torch import nn
from torch.nn import L1Loss
x=torch.tensor([0.1,0.2,0.3])
y=torch.tensor([1])
x=torch.reshape(x,(1,3))
loss_cross=nn.CrossEntropyLoss()
loss_cross_result=loss_cross(x,y)
print(loss_cross_result)
神经网络中的损失函数与反向传播,大概懂了一点点,看明白怎么用的了,但是还不懂原理,还是得补一下原理,先放上代码吧,这节课学一上午了
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Sequential, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("dataset",transform=torchvision.transforms.ToTensor(),train=False,download=True)
dataloader=DataLoader(dataset,batch_size=1)
class NN_module(nn.Module):
def __init__(self):
super(NN_module,self).__init__()
self.model1=Sequential(
Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,1,2),
MaxPool2d(2),
Conv2d(32,64,5,1,2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x=self.model1(x)
return x
nn_module=NN_module()
loss=nn.CrossEntropyLoss()
for data in dataloader:
imgs,targets=data
output=nn_module(imgs)
result_loss=loss(output,targets)
result_loss.backward()
print("ok")
优化器
先定义一个优化器,将神经网络中的每一个参数清零,调用反向传播函数求出每一个节点的梯度,再调用优化器进行调优,代码如下:
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Sequential, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("dataset",transform=torchvision.transforms.ToTensor(),train=False,download=True)
dataloader=DataLoader(dataset,batch_size=1)
class NN_module(nn.Module):
def __init__(self):
super(NN_module,self).__init__()
self.model1=Sequential(
Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,1,2),
MaxPool2d(2),
Conv2d(32,64,5,1,2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x=self.model1(x)
return x
nn_module=NN_module()
loss=nn.CrossEntropyLoss()
optim=torch.optim.SGD(nn_module.parameters(),lr=0.01,)
for epoch in range(10):
running_loss = 0.0
for data in dataloader:
imgs,targets=data
output=nn_module(imgs)
result_loss=loss(output,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss=running_loss+result_loss
print(running_loss)
现有网络模型的使用及修改
通过代码add_module或者直接修改classifier里面的函数可以对现有的网络模型进行使用增加步骤或者修改原有的神经网络。
import torchvision.datasets
from torch import nn
vgg16_false=torchvision.models.vgg16(pretrained=False)
vgg16_true=torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
train_data=torchvision.datasets.CIFAR10("dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
vgg16_true.classifier.add_module("linear",nn.Linear(1000,10))
vgg16_false.classifier[6]=nn.Linear(4096,10)
print(vgg16_false)
网络模型的保存与读取
一共两种保存和读取方式,一种是直接将模型保存下来,另一种是将模型的参数放入字典中,这样可以减少存储空间,代码不算难,第二种读取会复杂一些,需要将参数填回到模型当中。看代码吧。
模型的保存:
import torch
import torchvision
vgg16=torchvision.models.vgg16(pretrained=False)
# 保存方式1,模型结构+模型参数
torch.save(vgg16,"vgg16_method.pth")
# 保存方式2,把vgg16的参数保存成字典形式,只保存模型参数,官方推荐,文件更小
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
模型的加载:
import torch
import torchvision.models
# 保存方式1->来加载模型
model=torch.load("vgg16_method.pth")
print(model)
# 保存方式2->来加载模型
vgg16=torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)
完整的模型训练套路
准备数据,加载数据,准备模型,设置损失函数,设置优化器,开始训练,最后验证,结果聚合展示
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch.utils.data import DataLoader
# 准备数据集
train_data=torchvision.datasets.CIFAR10("dataset",transform=torchvision.transforms.ToTensor(),train=True,download=True)
test_data=torchvision.datasets.CIFAR10("dataset",transform=torchvision.transforms.ToTensor(),train=False,download=True)
# length长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集为:{}".format(train_data_size))
print("测试数据集为:{}".format(test_data_size))
# 利用DataLoader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
# 创建网络模型
nn_module=NN_module()
# 创建损失函数
loss_fn=nn.CrossEntropyLoss()
# 优化器
learning_rate=0.01
optimzer=torch.optim.SGD(nn_module.parameters(),lr=learning_rate)
# 设置训练网络的参数
# 记录训练的次数
total_train_step=0
# 记录训练的额次数
total_test_step=0
# 训练的轮数
epoch=10
# 添加tensorboard
writer=SummaryWriter("logs_train")
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
# 训练步骤开始
nn_module.train()
for data in test_dataloader:
imgs,targets=data
output=nn_module(imgs)
loss=loss_fn(output,targets)
# 要使用优化器,所以梯度清零,优化器优化模型
optimzer.zero_grad()
loss.backward()
optimzer.step()
total_train_step+=1
if total_train_step % 100 == 0:
print("训练次数:{},loss={}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
nn_module.eval()
total_test_loss=0
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
output=nn_module(imgs)
loss=loss_fn(output,targets)
total_test_loss=total_test_loss+loss.item()
accuracy=(output.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step=total_test_step+1
torch.save(nn_module,"nn_module_{}.pth".format(i))
print("模型已保存")
writer.close()
利用GPU训练
网络模型和loss函数调用.cuda(),imgs和targets调用.cuda().用cpu训练100次大概需要3秒,gpu训练一次大概0.6秒左右
import time
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.tensorboard import SummaryWriter
# from model import *
from torch.utils.data import DataLoader
# 准备数据集
train_data=torchvision.datasets.CIFAR10("dataset",transform=torchvision.transforms.ToTensor(),train=True,download=True)
test_data=torchvision.datasets.CIFAR10("dataset",transform=torchvision.transforms.ToTensor(),train=False,download=True)
# length长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集为:{}".format(train_data_size))
print("测试数据集为:{}".format(test_data_size))
# 利用DataLoader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
# 创建网络模型
class NN_module(nn.Module):
def __init__(self):
super(NN_module,self).__init__()
self.model1=Sequential(
Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,1,2),
MaxPool2d(2),
Conv2d(32,64,5,1,2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x=self.model1(x)
return x
nn_module=NN_module()
nn_module=nn_module.cuda()
# 创建损失函数
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.cuda()
# 优化器
learning_rate=0.01
optimzer=torch.optim.SGD(nn_module.parameters(),lr=learning_rate)
# 设置训练网络的参数
# 记录训练的次数
total_train_step=0
# 记录训练的次数
total_test_step=0
# 训练的轮数
epoch=10
# 添加tensorboard
writer=SummaryWriter("logs_train")
# 记录训练时间
start_time=time.time()
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
# 训练步骤开始
nn_module.train()
for data in test_dataloader:
imgs,targets=data
imgs=imgs.cuda()
targets=targets.cuda()
output=nn_module(imgs)
loss=loss_fn(output,targets)
# 要使用优化器,所以梯度清零,优化器优化模型
optimzer.zero_grad()
loss.backward()
optimzer.step()
total_train_step+=1
if total_train_step % 100 == 0:
end_time=time.time()
print(end_time-start_time)
print("训练次数:{},loss={}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
nn_module.eval()
total_test_loss=0
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
imgs=imgs.cuda()
targets=targets.cuda()
output=nn_module(imgs)
loss=loss_fn(output,targets)
total_test_loss=total_test_loss+loss.item()
accuracy=(output.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step=total_test_step+1
torch.save(nn_module,"nn_module_{}.pth".format(i))
print("模型已保存")
writer.close()
还可以通过定义设备来自己定义cpu还是gpu
import time
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.tensorboard import SummaryWriter
# from model import *
from torch.utils.data import DataLoader
# 定义训练的设备
device=torch.device("cpu")
# 准备数据集
train_data=torchvision.datasets.CIFAR10("dataset",transform=torchvision.transforms.ToTensor(),train=True,download=True)
test_data=torchvision.datasets.CIFAR10("dataset",transform=torchvision.transforms.ToTensor(),train=False,download=True)
# length长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集为:{}".format(train_data_size))
print("测试数据集为:{}".format(test_data_size))
# 利用DataLoader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
# 创建网络模型
class NN_module(nn.Module):
def __init__(self):
super(NN_module,self).__init__()
self.model1=Sequential(
Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,1,2),
MaxPool2d(2),
Conv2d(32,64,5,1,2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x=self.model1(x)
return x
nn_module=NN_module()
nn_module=nn_module.to(device)
# 创建损失函数
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.to(device)
# 优化器
learning_rate=0.01
optimzer=torch.optim.SGD(nn_module.parameters(),lr=learning_rate)
# 设置训练网络的参数
# 记录训练的次数
total_train_step=0
# 记录训练的次数
total_test_step=0
# 训练的轮数
epoch=10
# 添加tensorboard
writer=SummaryWriter("logs_train")
# 记录训练时间
start_time=time.time()
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
# 训练步骤开始
nn_module.train()
for data in test_dataloader:
imgs,targets=data
imgs=imgs.to(device)
targets=targets.to(device)
output=nn_module(imgs)
loss=loss_fn(output,targets)
# 要使用优化器,所以梯度清零,优化器优化模型
optimzer.zero_grad()
loss.backward()
optimzer.step()
total_train_step+=1
if total_train_step % 100 == 0:
end_time=time.time()
print(end_time-start_time)
print("训练次数:{},loss={}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
nn_module.eval()
total_test_loss=0
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
imgs=imgs.to(device)
targets=targets.to(device)
output=nn_module(imgs)
loss=loss_fn(output,targets)
total_test_loss=total_test_loss+loss.item()
accuracy=(output.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step=total_test_step+1
torch.save(nn_module,"nn_module_{}.pth".format(i))
print("模型已保存")
writer.close()
完整的模型验证套路
首先将验证的图片导入,然后将图片的大小及格式进行调整,调整到我们可以使用位置,还有一个要注意的是,如果模型是使用gpu训练的,那么图片也需要调整成gpu输出,使用.to(device),导入完图片后要导入模型,注意模型有两种导入和保存方式,如果保存的是完整的模型,那么需要将模型的代码复制过来,验证的时候要将图片reshape,还要使用0梯度的模型,这样就可以愉快的进行预测啦。
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
device=torch.device("cuda")
img_path="images/horse.png"
image=Image.open(img_path)
# image=image.convert("RGB")
tranform=torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image=tranform(image)
image=image.to(device)
print(image.shape)
class NN_module(nn.Module):
def __init__(self):
super(NN_module,self).__init__()
self.model1=Sequential(
Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,1,2),
MaxPool2d(2),
Conv2d(32,64,5,1,2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x=self.model1(x)
return x
model=torch.load("nn_module_29.pth")
print(model)
image=torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():
output=model(image)
print(output)
print(output.argmax(1))















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









