







决策树解决回归问题时进行平均数计算。
决策树
(1)熵(entropy)与特征节点
熵(entropy),度量着信息的不确定性,信息的不确定性越大,熵越大。信息熵和事件发生的概率成反比。
■信息熵代表随机变量的复杂度,也就是不确定性。
■条件熵代表在某一个条件下,随机变量的复杂度。
■信息增益等于信息熵减去条件熵,它代表了在某个条件下,信息复杂度(不确定性)减少的程度。
如果一个特征从不确定到确定,这个过程对结果影响比较大的话,就可以认为这个特征的分类能力比较强。那么先根据这个特征进行决策之后,对于整个数据集而言,熵(不确定性)减少得最多,也就是信息增益最大。
#(2)决策树的深度
决策树算法有两个特点:
(1)由于if…else可以无限制地写下去,因此,针对任何训练集,只要树的深度足够,决策树肯定能够达到100%的准确率。
(2)决策树非常容易过拟合。也就是说,在训练集上,只要分得足够细,就能得到100%的正确结果,然而在测试集上,准确率会显著下降。
**注意:**使用决策树时当分类边界精确地绕过了每一个点时,过拟合已经发生了,此时可以使用剪枝(pruning)的方法进行。
剪枝(pruning),有以下两种形式:
■先剪枝:分支的过程中,熵减少的量小于某一个阈值时,就停止分支的创建。
■后剪枝:先创建出完整的决策树,然后尝试消除多余的节点。
随机森林
随机森林(random forest)是一种健壮且实用的机器学习算法,它是在决策树的基础上衍生而成的。决策树和随机森林的关系就是树和森林的关系。通过对原始训练样本的抽样,以及对特征节点的选择。
决策树很容易过拟合,而随机森林的思路是把很多棵决策树的结果集成起来,以避免过拟合,同时提高准确率。其中,每一棵决策树都是在原始数据集中抽取不同子集进行训练的,尽管这种做法会小幅度地增加每棵树的预测偏差,但是最终对各棵树的预测结果进行综合平均之后的模型性能通常会大大提高。
(1)随机森林底层算法原理
假设我们有一个包含N个训练样本的数据集,特征的维度为M,随机森林通过下面算法构造树。
(1)从N个训练样本中以有放回抽样(replacement sampling)的方式,取样N次,形成一个新训练集(这种方法也叫bootstrap取样),可用未抽到的样本进行预测,评估其误差。
(2)对于树的每一个节点,都随机选择m个特征(m是M的一个子集,数目远小于M),决策树上每个节点的决定都只是基于这些特征确定的,即根据这m个特征,计算最佳的分裂方式。
(3)默认情况下,每棵树都会完整成长而不会剪枝。
上述算法有两个关键点:一个是有放回抽样,二是节点生成时不总是考量全部特征。这两个关键点,都增加了树生成过程中的随机性,从而降低了过拟合。
(2)Sklearn的随机森林分类器
算法之美,是机器学习之美。
在Sklearn的随机森林分类器中,可以设定的一些的参数项如下。
■n_estimators:要生成的树的数量。
■ criterion : 信 息 增 益 指 标 , 可 选 择 gini ( Gini 不 纯 度 ) 或 者entropy(熵)。
■bootstrap:可选择是否使用bootstrap方法取样,True或者False。如果选择False,则所有树都基于原始数据集生成。
■max_features:通常由算法默认确定。对于分类问题,默认值是总特征数的平方根,即如果一共有9个特征,分类器会随机选取其中3个。
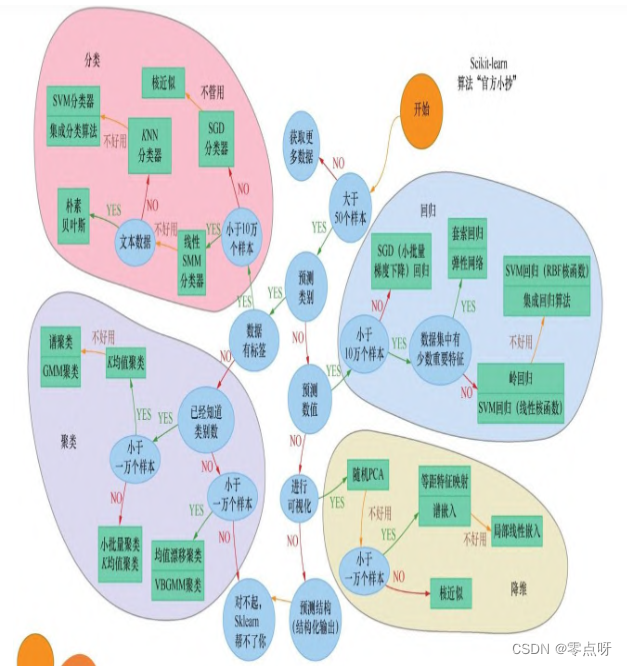
如何选择最佳机器学习算法















 322
322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









