







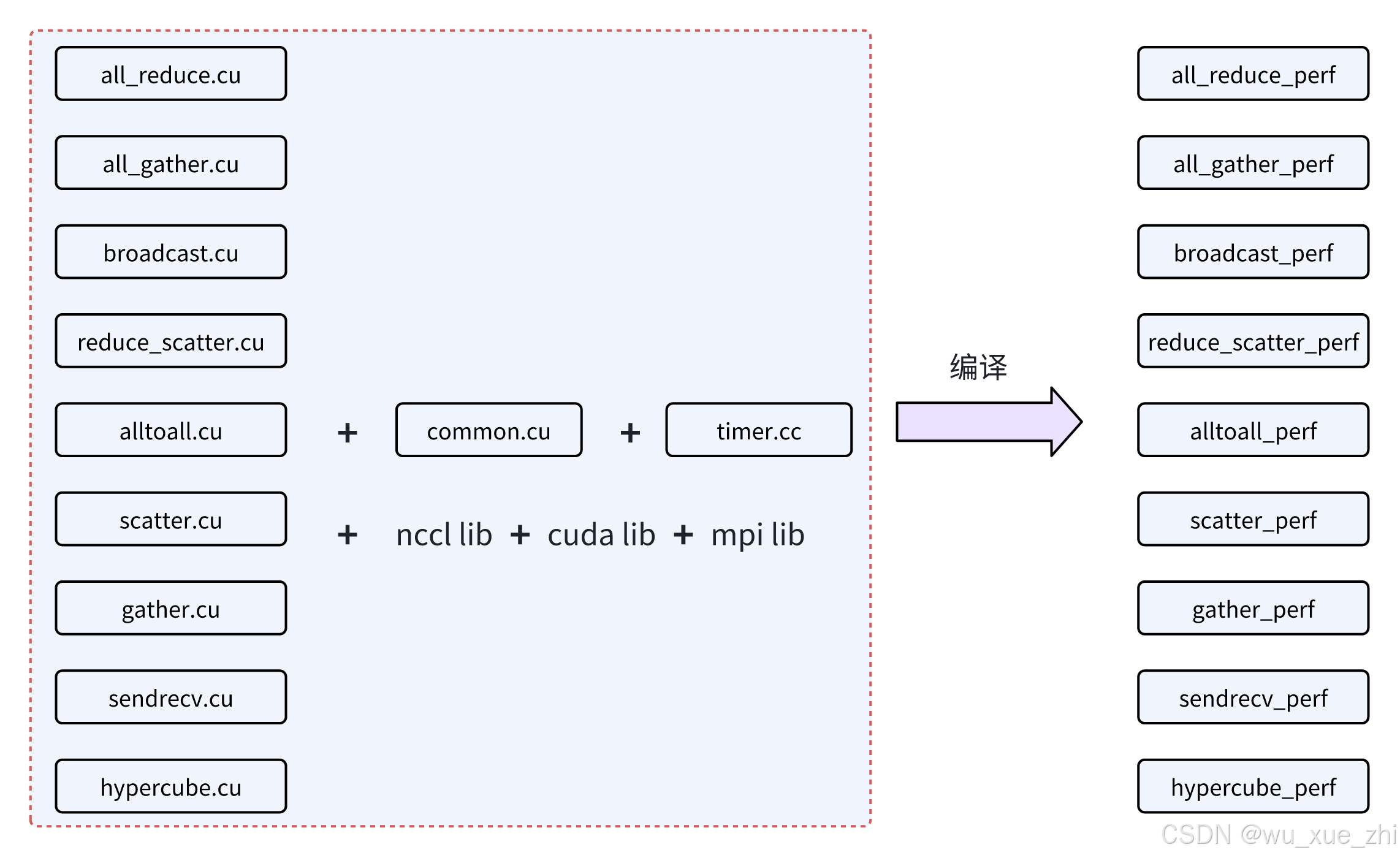
文件编译
Nccl test有几个测试文件,每一个测试文件会单独生成一个测试程序,并以"_perf"为后缀生成可执行的文件。
每个测试源码文件会和两个公共文件common.cu和timer.cc,以及nccl、cuda、mpi这三个lib一起编译生成可执行的文件。
common.cu
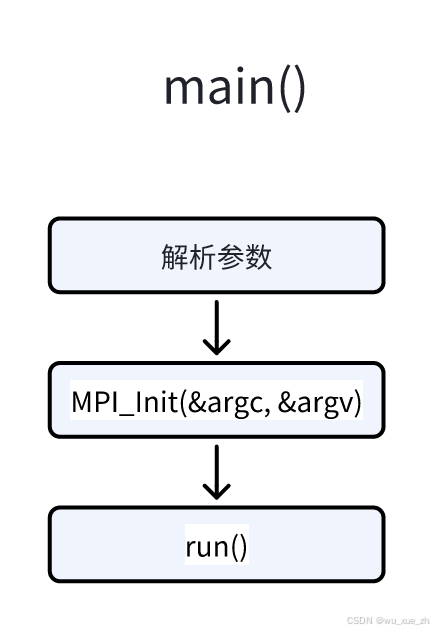
common.cu为公共文件,提供测试测试程序框架,包括main函数、参数解析,并调用每个测试文件提供的公共调用接口,以初始化测试程序和运行测试程序。
run函数具体流程如下:
- 获取MPI相关信息
- 具体信息有:
-
总进程数
-
当前进程的rank编号
-
当前主机上所有的进程个数
-
-
如果对进程划分了子组(配置了NCCL_TESTS_SPLIT_MASK环境变量)
-
创建当前进程所在子组的mpi通信器
-
获取当前子组中的进程总数
-
获取当前进程在子组中的rank编号环境变量,则默认所有进程在同一个子组中。
-
如果没有配置NCCL_TESTS_SPLIT_MASK
-
- 具体信息有:
-
获取最大可用的gpu缓存大小(从众多要使用的GPU中,选取缓存最小的GPU的缓存值)
-
获取当前进程使用的GPU的最大内存
-
一个进程可以有n个线程,每个线程可以使用n个GPU
-
选取缓存最小的GPU的缓存值,作为一个maxMem
-
需要确定当前进程使用了哪些GPU,才能获取maxMem信息
-
进程分配GPU的规则:
-
一个主机可能有多个进程,每个进程可能使用多个GPU
-
cuda通常情况下,对于主机上可用的GPU已经从0开始做了编号
-
默认情况下,按照进程的rank编号从小到大来分配在GPU
-
默认情况下,分配的GPU的编号是从0开始分配
-
-
-
收集所有进程的最大可用GPU maxMem信息,并打印
-
使用MPI_Allreduce获取各个进程的maxMem,并使用最小的maxMem作为最终的maxMem
-
-
根据maxMem获取在gpu上申请的buff的最大字节数,并使用该值,来修正配置的maxBytes
-
在gpu申请的buff包含2块或者3块,send buff和recv buff必包含,还有可能包含一个expected buff(需要参数指定使能了datacheck)。
-
将maxMem预留1G,剩下的根据需要切成2等份或者3等份作为申请的buff最大值。使用该值来修正maxBytes,即如果配置的maxBytes大于最大可设置的buff值,则maxBytes设置为最大可设置的buff值
-
-
子组中的rank 0的进程,获取一个ncclUniqueId,并使用MPI_Bcast同步给子组的其他进程。
-
调用各个测试用例定义的getBuffSize函数,获取sendBytes和recvBytes大小,通常是根据maxBytes来设置。
-
每个测试用例都要定义一个struct testEngine ncclTestEngine全局变量
-
ncclTestEngine变量中有两个函数指针:getBuffSize和runTest,每个测试用例都要实现这两个函数,以测试自己用例的目标
-
-
在当前进程使用的每个GPU上,都申请maxBytes大小的sendbuff、recvbuff和expected buff(如果指定要做datacheck),并根据需要,创建一个cudaStream。
-
申请的buff指针记录在一个数组中
-
申请buff的流程为:
-
先指定一个gpu,通过cudaSetDevice指定
-
调用AllocateBuffs申请,AllocateBuffs再调用三次ncclMemAlloc,分别申请sendbuff、recvbuff和expected buff
-
ncclMemAlloc函数为nccl lib的函数,做了如下事情
-
第一调用时,加载了cuda lib库中的一些函数指针,以供后续调用。具体是调用ncclCudaLibraryInit(nccl中的cudawrap.cc文件),然后ncclCudaLibraryInit会使用pthread_once,只调用一次initOnceFunc来加载cuda lib库中的函数指针。后续每次调用ncclCudaLibraryInit时,不会再重复加载cuda lib库中的函数指针。
-
获取GPU的Multicast属性,如果GPU不支持Multicast,则直接使用cudaMalloc申请gpu缓存,并返回。
-
如果支持Multicast属性,进一步处理,先是获取gpu的缓存的粒度大小。
memprop.allocFlags.gpuDirectRDMACapable = 1
-
获取的是gpu推荐的粒度大小(CU_MEM_ALLOC_GRANULARITY_RECOMMENDED),以达到性能最大化。(还有一种是最小的粒度大小)
-
如果支持gpu支持GPU_DIRECT_RDMA,设置gpuDirectRDMACapable :
-
-
获取Multicast缓存的推荐粒度大小
-
该粒度跟申请的缓存的大小有关系
-
-
将申请的缓存大小,按照Multicast缓存推荐粒度大小,向上对齐。并调用cuMemCreate申请该大小的gpu缓存,并记录缓存的句柄
-
调用cuMemAddressReserve来预留一块申请的gpu缓存大小的虚拟内存
-
内存地址按照前面获取的gpu推荐的内存粒度大小来对齐(返回的虚拟地址首地址)
-
-
cuMemMap,将虚拟地址和申请的gpu缓存映射起来。这样对虚拟地址的读写就可以直接操作gpu缓存
-
遍历当前主机上的所有可用gpu,如果该gpu和当前申请缓存的gpu可以进行p2p操作的话(通过cudaDeviceCanAccessPeer获取),调用cuMemSetAccess设置该gpu可以访问当前申请的gpu缓存。(当前自己的gpu也要调用cuMemSetAccess设置一下) (具体原理目前未知)
-
-
-
-
-
初始化nccl通讯器ncclComm_t comms,每个GPU需要一个
-
可以在主线程中初始化所有的线程的GPU的comms,也可以每个线程运行时,线程初始化自己使用的GPU的通讯器(指定参数:-p,--parallel_init <0/1>),这样速度更快一些。
-
如果当前nccl子组中只有一个进程。则直接调用ncclCommInitAll来初始化comms。ncclCommInitAll是nccl提供的用于创建单个进程的一组通信器。
-
如果nccl子组有多个进程,则自己依次对每个GPU调用ncclCommInitRank,初始化通信器。
-
NCCL在初始化一组通信器时,都要使用ncclGroupStart()和ncclGroupEnd()包起来。具体原因不确定,可能是要等待所有gpu的通信器都创建好了,需要内部交互完成,ncclGroupEnd()才返回。
-
-
通信器创建好了之后,调用ncclCommRegister,将buff注册到通信器中。用于zero-copy通信。
-
每个GPU的通信器注册自己的GPU缓存中申请的buff
-
注册好了需要记录一个buff句柄,这个句柄用于后续解注册buff使用(ncclCommDeregister)。
-
expected buff不需要注册,可能是因为不需要同步这个buff
-
-
创建线程,并等待线程运行结束。
-
传递给线程执行函数的arg参数包含如下字段:
-
配置的参数:最小字节数minbytes、最大字节数maxbytes、递增的字节数stepbytes、递增倍数stepfactor(和递增的字节数二选1)
-
本进程在当前主机的localRank编号
-
总的进程数totalProcs、nccl子组的进程个数nProcs、当前进程在nccl子组中的rank编号proc
-
当前进程的线程个数nThreads,当前线程的编号thread
-
当前线程使用的gpu个数nGpus,保存当前线程使用的gpu id的数组gpus[]
-
保存当前线程使用的三个gpu buff指针的数组:sendbuffs[]、recvbuffs[]、expected buffs[]
-
当前nccl子组的ncclId(当前nccl子组的rank 0进程申请的id,并同步给其他进程)
-
保存当前线程使用的nccl通信器的数组comms[]
-
保存当前线程使用的streams的数组streams[]
-
存储运行结果的统计信息指针:errors、bw、bw_count
-
是否做做datacheck,即报告错误
-
-
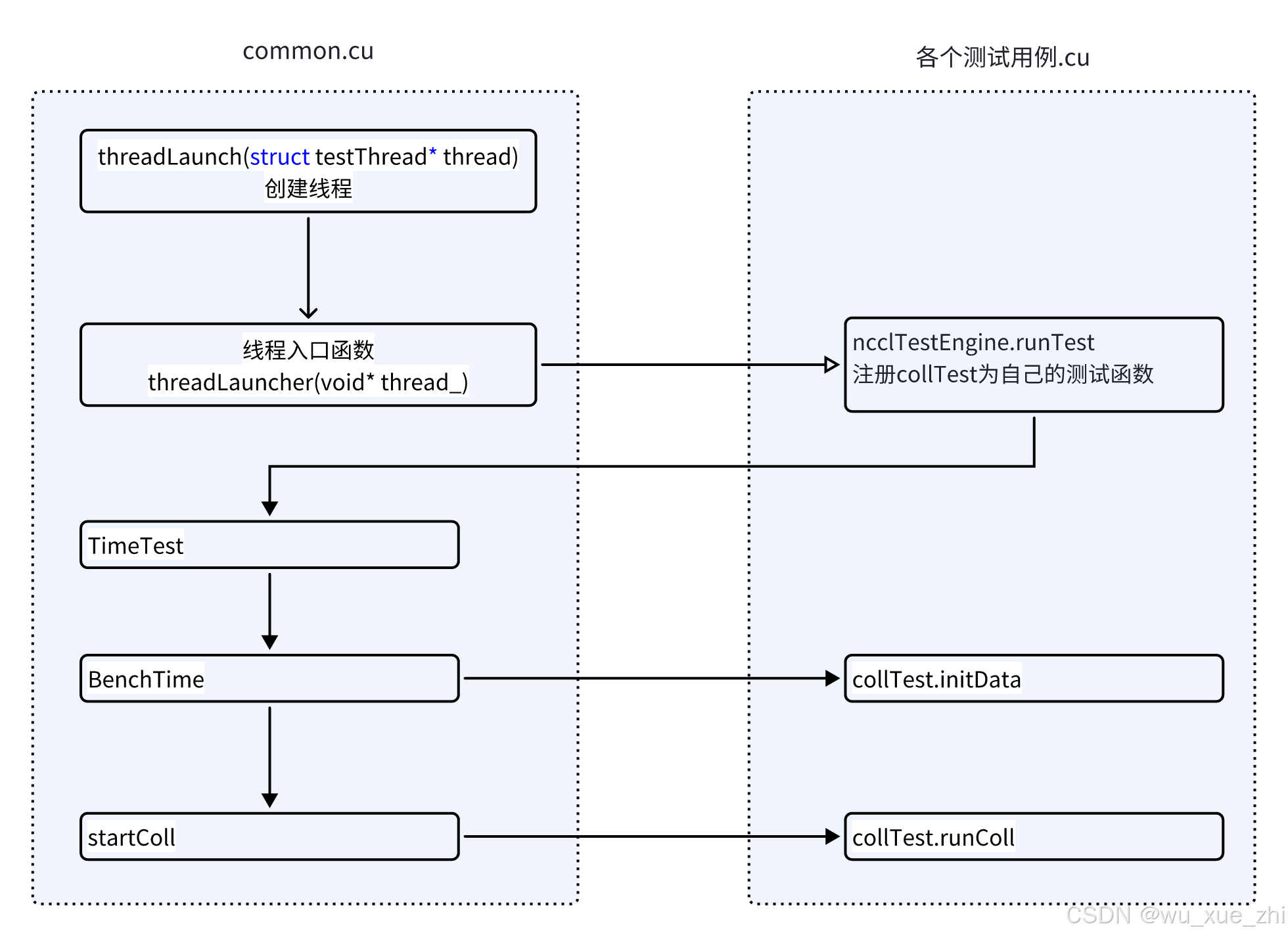
每个线程调用每个具体的测试用例文件提供的runTest函数(ncclTestEngine.runTest)
-
函数的包括上面的arg参数
-
指定nccl子组的root gpu的rank号(配置参数-r,--root指定,默认为0)
-
测试的数据的类型(配置参数-d,--datatype,默认为ncclFloat),及其类型名字(字符串)
-
数据操作(配置参数-o,--op <sum/prod/min/max/avg/all>,默认为ncclSum),及其操作名字(字符串)
-
-
测试函数调用关系
all_reduce.cu测试用例说明
提供两个函数,一个是获取测试用例需要的缓冲区的大小,一个是测试用例的运行函数。
struct testEngine allReduceEngine = {
AllReduceGetBuffSize,
AllReduceRunTest
};获取的缓冲区的大小跟传入的缓冲区最大值相等。
Run test函数最终调用的是TimeTest函数来运行。data type和op type有配置参数决定,可以各自指定为all,会遍历各种data type和op type的组合,来调用TimeTest函数。
调用TimeTest函数,还需要传入具体的测试模块化函数,每个测试用例都有自己的实现:
struct testColl {
const char name[20];
void (*getCollByteCount)(
size_t *sendcount, size_t *recvcount, size_t *paramcount,
size_t *sendInplaceOffset, size_t *recvInplaceOffset,
size_t count, int nranks);
testResult_t (*initData)(struct threadArgs* args, ncclDataType_t type,
ncclRedOp_t op, int root, int rep, int in_place);
void (*getBw)(size_t count, int typesize, double sec, double* algBw, double* busBw, int nranks);
testResult_t (*runColl)(void* sendbuff, void* recvbuff, size_t count, ncclDataType_t type,
ncclRedOp_t op, int root, ncclComm_t comm, cudaStream_t stream);
};all_reduce函数自己的实现
struct testColl allReduceTest = {
"AllReduce",
AllReduceGetCollByteCount,
AllReduceInitData,
AllReduceGetBw,
AllReduceRunColl
};TimeTest函数原型为:
testResult_t TimeTest(struct threadArgs* args,
ncclDataType_t type, const char* typeName,
ncclRedOp_t op, const char* opName,
int root) //root表示根gpu节点的编号,有些测试功能不需要root节点其实现流程如下:
-
先是调用 Barrier(args),同步所有线程。
该函数的作用为让所有线程在该函数中等待,然后所有线程执行一遍test。之后下一轮执行test,还要回到该函数中等待,等待所有线程都执行完上一轮的test,然后才执行新一轮的test。
-
分别执行几次最大数据量的测试操作和执行几次最小数据量的测试操作。具体执行次数由-w,--warmup_iters配置参数决定,默认值为5。不需要check结果。其作用为warm-up设备。
-
从最小数据到最大数据,按照配置的步长间隔(两个间隔方式,一个是按照固定大小递增,一个是从最小值开始,按照固定的倍数递增),依次测试每个大小的数据。
-
默认测试一轮,可以通过配置参数"-N,--run_cycles <cycle count>"指定测试多少轮。0表示无限次。
-
每一个大小数据的测试会测试两种情况,一个是in_place、另外一个不是in_place。in_place表示发送数据和接收数据是同一个缓冲区。
-
具体的测试是调用BenchTime函数实现
-
BenchTime函数原型为:
testResult_t BenchTime(struct threadArgs* args, ncclDataType_t type,
ncclRedOp_t op, int root, int in_place)BenchTime为每一个大小数据的测试函数,其实现流程如下:
-
如果指定要做datacheck,则调用每个用例自己的initData函数,构造senddata和expect data
-
执行一次测试操作,但是并不记录测试数据(消耗时间、带宽等操作,检查数据正确性)
-
开始正式的性能测试。
-
这里有两个配置参数
-
-n,--iters <iteration count>,迭代次数,默认为20。即执行多少组nccl操作,作为一次测试操作。并取平均值作为测试结果(单次测试结果可能会不准确)
-
-m,--agg_iters <aggregated iteration count>,每次迭代中要聚合在一起的操作次数。默认值为:1。每一次迭代中,要再执行几次聚合操作(其实和普通nccl操作一样)
-
-
上面两个参数的乘积,就是具体执行nccl操作的次数。但是每次聚合迭代的操作需要额外进行nccl的同步一下
-
每次测试操作,会根据迭代次数(迭代次数和聚合次数的乘积),选择一个gpu的buff地址进行操作。
-
gpu一开始按照最大数据量,申请了一块最大的buff。而正常测试的数据大小,是从大到小开始测试的,因此一开始的数据量可能比较小。
-
再每一次迭代测试的时候,期望使用的gpu buff地址尽量不一样。因此底层的测试执行函数(startColl),会根据当前的迭代次数,计算一个当前数据在buff中的位置。具体做法是将申请的gpu的最大buff按照当前测试数据大小,切分成多个块,从第0块开始,每次迭代测试依次往后选择一个buff块。跳到最后一个块后,会循环从头开始选择。
-
-
-
在进行正式的性能测试之前,会记录下当前时间,测试结束之后,也会记录下当前时间,这里会计算几种耗时:
-
当前线程执行完后的耗时,即CPU执行时间。
-
GPU的stream执行完成时的耗时。CPU处理+GPU处理的耗时。再求出单个测试操作的平均耗时。
-
-
之后会对所有线程的执行时间进行一个汇总。汇总方式由配置参数执行:-a,--average <0/1/2/3> report average iteration time <0=RANK0/1=AVG/2=MIN/3=MAX>,默认值为1,即取平均值。
-
0表示,需要rank 0的统计数据,本意上是要0号进程的0号线程的耗时,但是实际上目前都是使用本进程的0号线程的耗时。
-
其他几个都比较好理解。分别为取所有线程(所有进程的所有线程)的平均值、最小值、最大值。
-
获取统计值的具体实现函数为:void Allreduce(struct threadArgs* args, T* value, int average)。其实现方法为:先是利用线程同步,统计本进程中各个线程的汇总数据,作为进程的数据;然后利用MPI allreduce操作,汇总各个进程的数据。
-
-
根据计算的平均时间,计算带宽。这个计算方式由具体的测试用例提供。有两种带宽。
-
一种是算法带宽algBw。根据”当前测试的数据大小/所有GPU执行结束的平均时间“得到。单位为G。
-
另外一个是总线带宽busBw。即当前测试的算法,实际在总线上传输的平均数据量(每张卡在总线上实际传输的数据量)。单位为G。
-
-
测试操作数据的正确性,这里不会测试性能,只测试正确性。测试的次数由配置参数”-c,--check <check iteration count>“决定,默认只测试一次。
-
打印测试结果。具体显示的结果信息有:
-
time,根据配置的参数”-C,--report_cputime <0/1>“来决定显示的是CPU的执行时间还是GPU的执行时间,默认是要显示GPU的执行时间
-
algBw,算法带宽
-
busBw,总线带宽
-
wrong,datacheck错误的数量
-
-
如果NCCL版本为2.9及以上,且cuda版本为11.3及以上。那么BenchTime在每次进行测试操作的时候,会根据配置参数”-G,--cudagraph <num graph launches>“来决定是否使用cudaGraph来加速测试,以及重复该加速测试的次数,默认是不启用的。
-
CUDA Graph的作用主要用于快速执行一组固定的动作,减少cpu显示的调用这一组动作的开销。适用于重复执行一组固定动作的场景。具体介绍参考https://zhuanlan.zhihu.com/p/631187683
-
在BenchTime函数中,如果启用了cudagraph,那么会使用cudagraph捕捉之前性能测试的动作,然后再快速启动之前性能测试的动作(多次的迭代测试)。因为启动了cudagraph capture,因此之前的显示调用的操作不会执行,因此不会统计之前的性能测试结果,而是统计用cudagraph快速启动的新的测试的性能。
-

















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









