






感谢书生·浦语和上海人工智能实验室提供的模型和算力支持!!!
课程:https://github.com/InternLM/tutorial/blob/main/xtuner/README.md
官方教程:https://github.com/InternLM/tutorial/blob/main/xtuner/self.md
本节课的学习的内容:


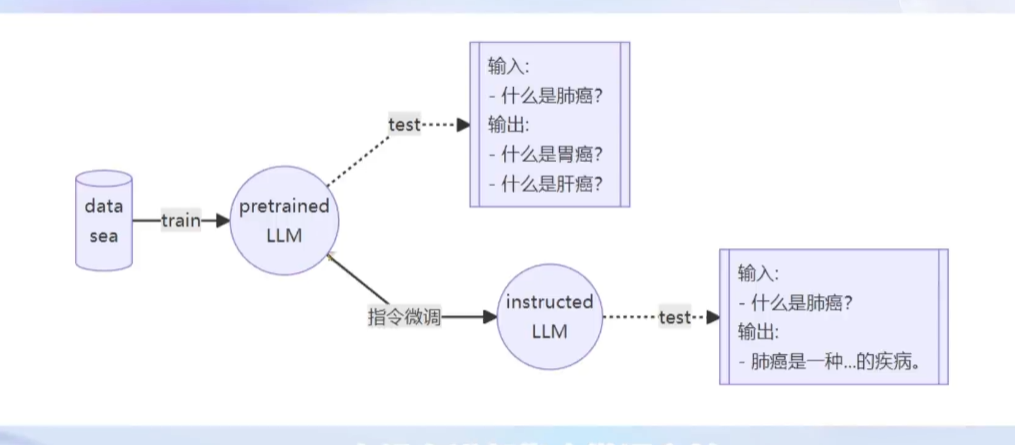
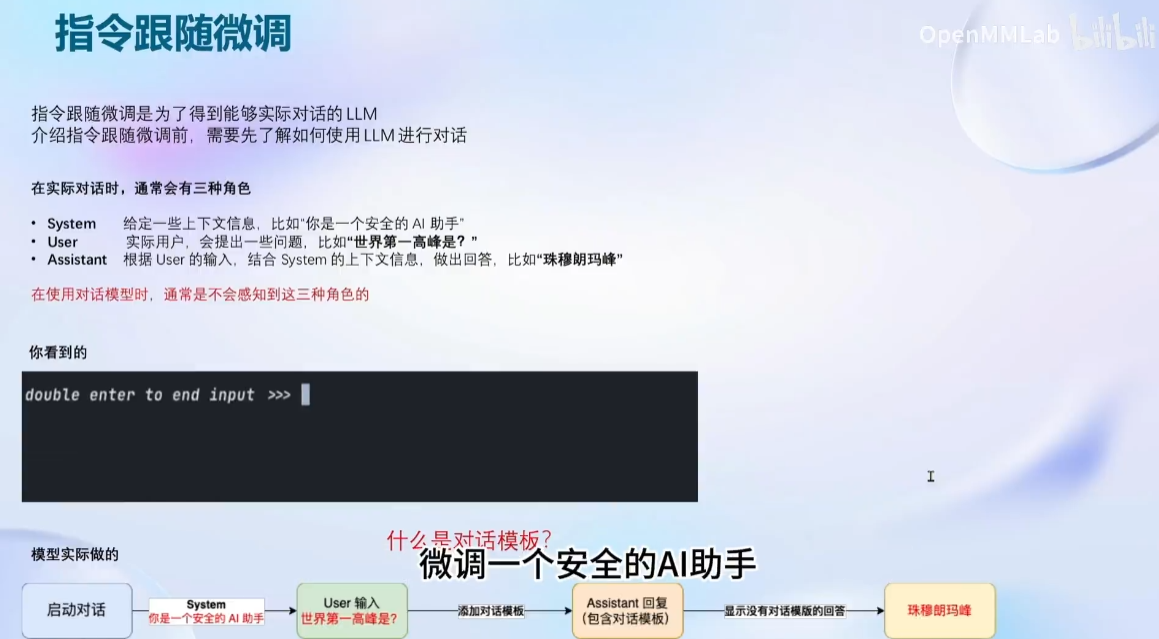
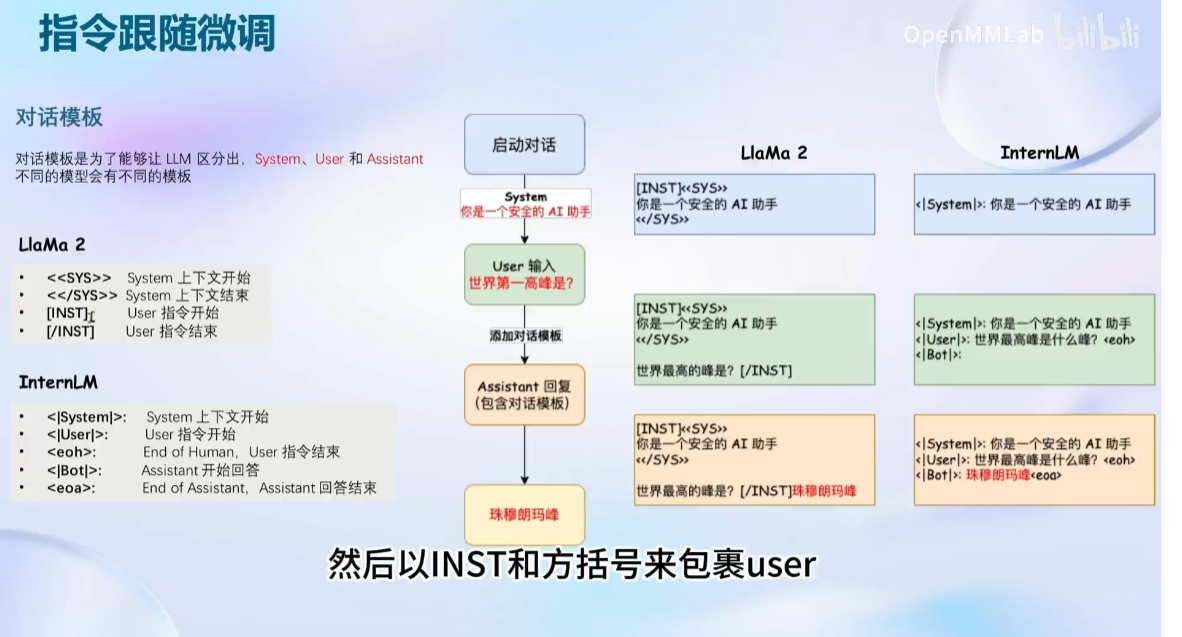

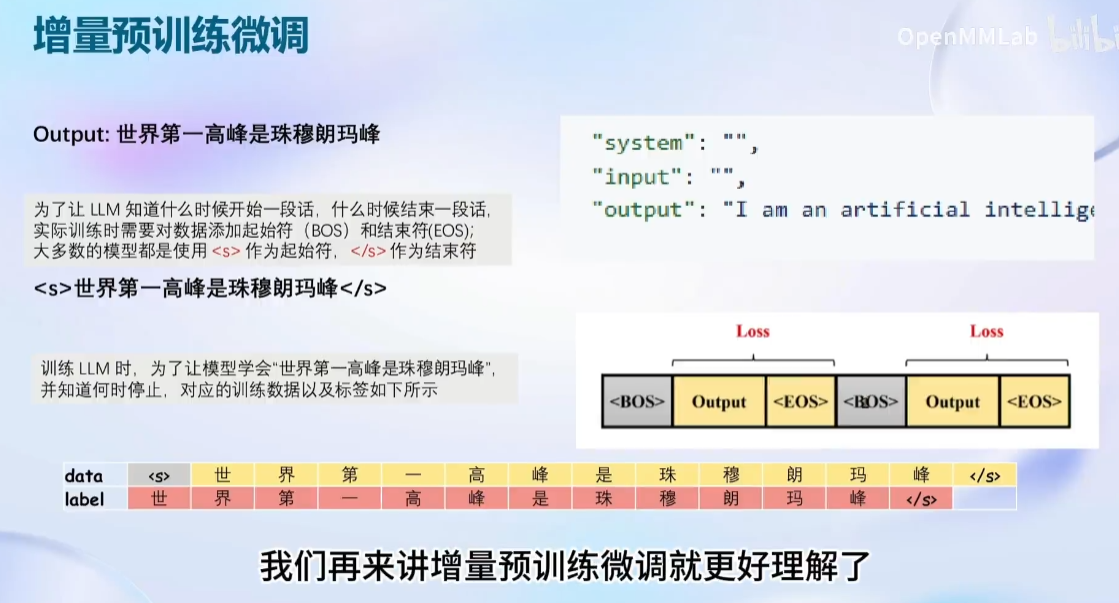


框架介绍:

可以支持多专家系统
上手版本


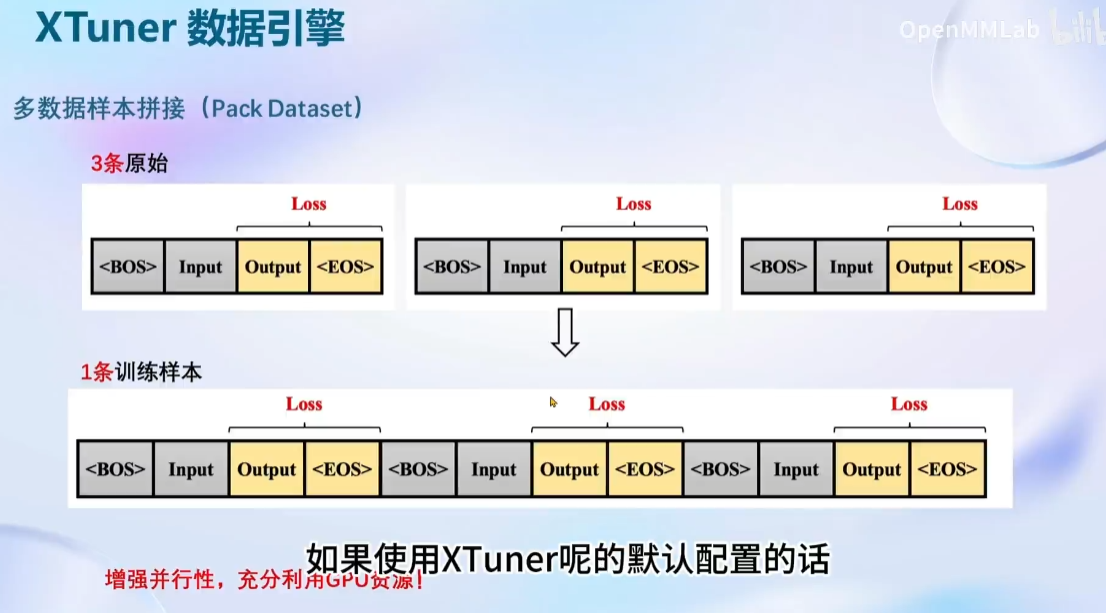
8GLLM:
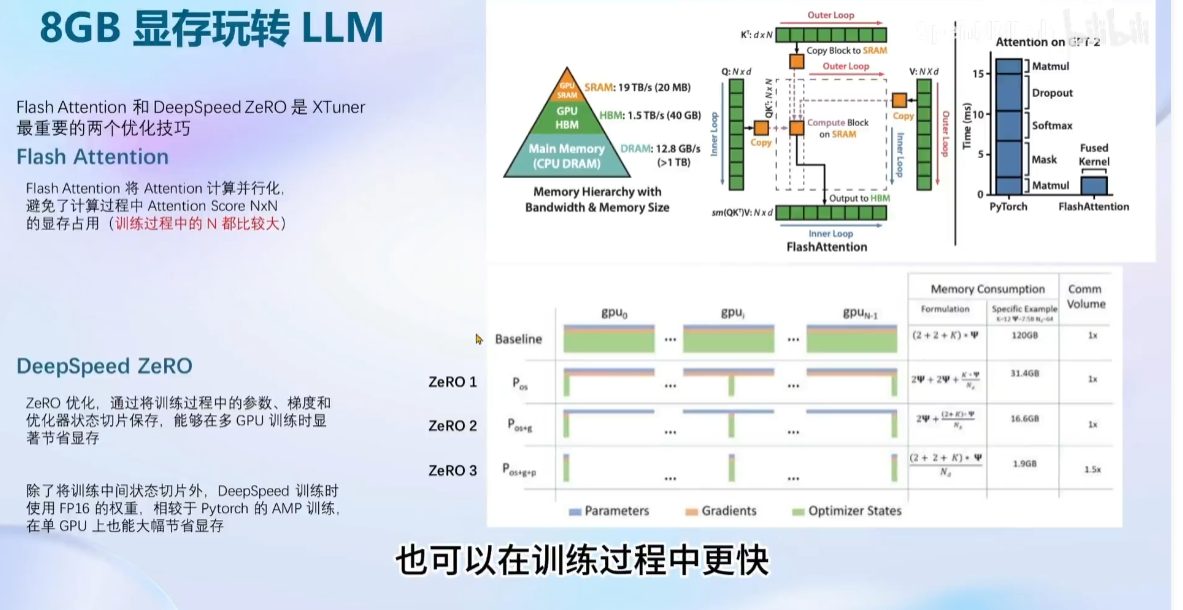

安装:(源码安装注意事项)

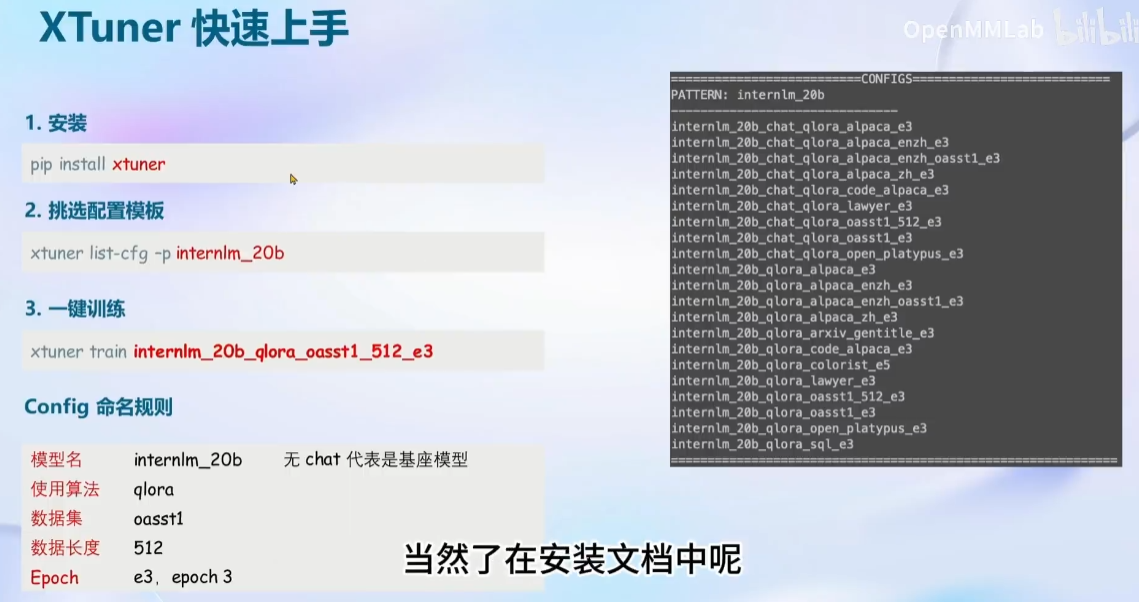
列出内置模型参数:
# 列出所有内置配置
xtuner list-cfg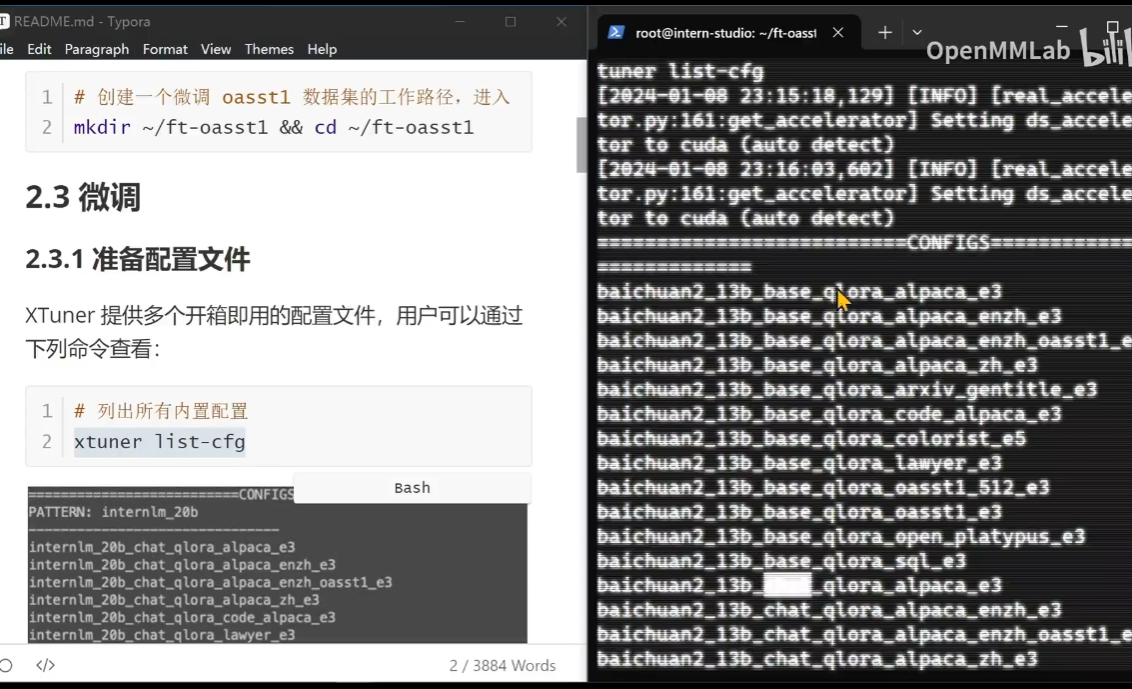
需要等待比较久的时间才可以显示出来全部的内容(e3表示执行3边)
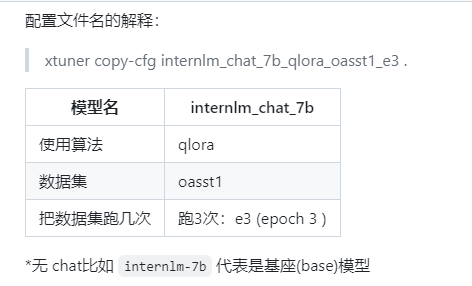
注意:1、平台的有之前的模型比较快,自己平台需要用huggingface或者Modelscope进行处理。2、数据集分为训练和验证两个部分。
如果是自己的数据有两种方式:
1、根据官方的教程
import json
# 输入你的名字
name = '陈同学'
# 重复次数
n = 10000
data = [
{
"conversation": [
{
"input": "请做一下自我介绍",
"output": "我是{}的小助手,内在是上海AI实验室书生·浦语的7B大模型哦".format(name)
}
]
}
]
for i in range(n):
data.append(data[0])
with open('personal_assistant.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)2、自己在kaggle上进行写的代码
keyword = '陈同学'
description = '''我是陈同学的人工智能小助手!'''
#对prompt使用一些简单的数据增强的方法,以便更好地收敛。
def get_prompt_list(keyword):
return [f'{keyword}',
f'你知道{keyword}吗?',
f'{keyword}是什么?',
f'介绍一下{keyword}',
f'你听过{keyword}吗?',
f'啥是{keyword}?',
f'{keyword}是何物?',
f'何为{keyword}?',
]
data =[{'prompt':x,'response':description} for x in get_prompt_list(keyword) ]
dfdata = pd.DataFrame(data)
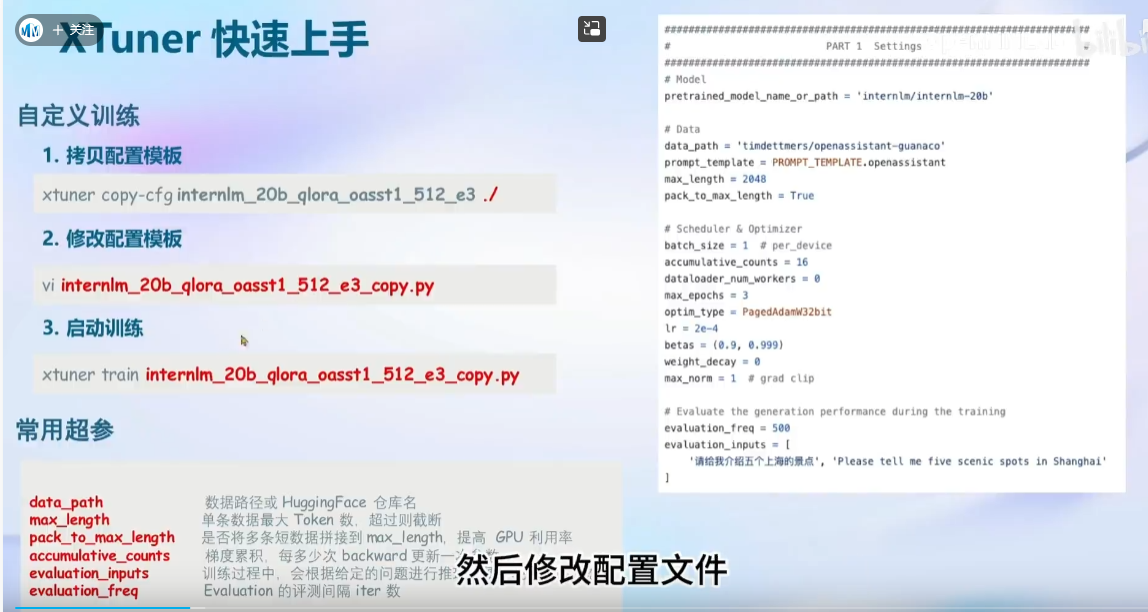
display(dfdata)超参介绍:
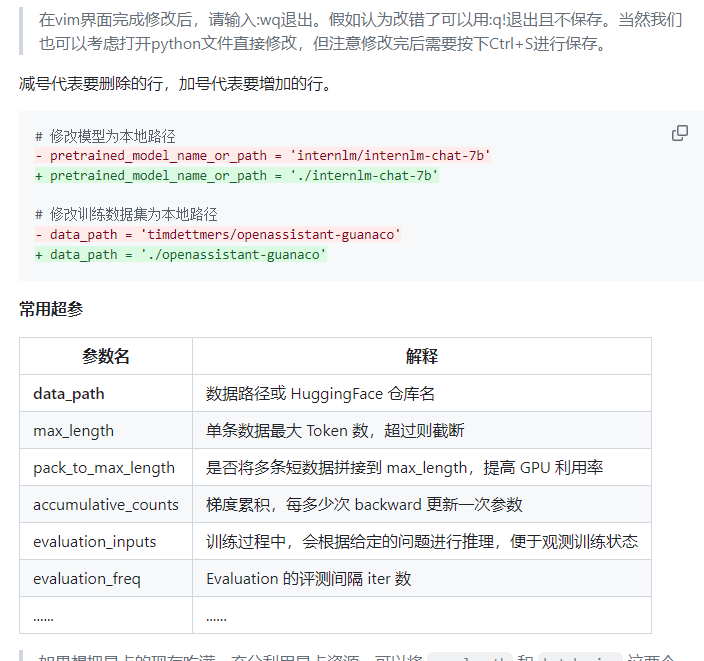
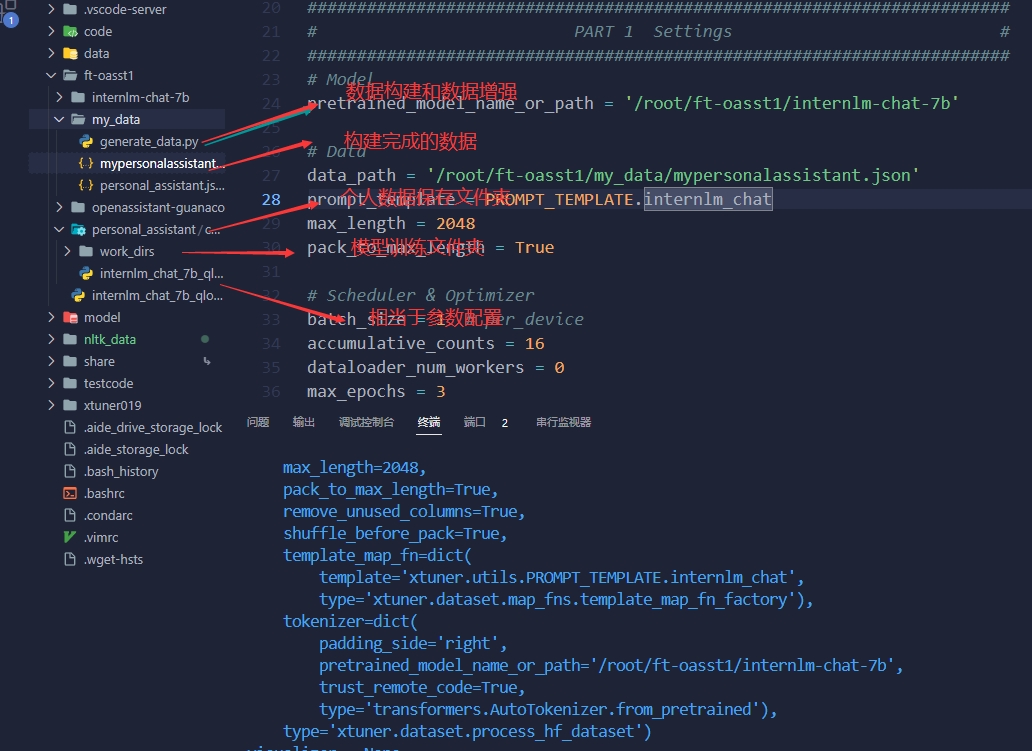
注意:tmux,中断终端(实现一个即使本地ssh关闭也是可以正常跑的,可以再查资料或者这个教程的部分内容)
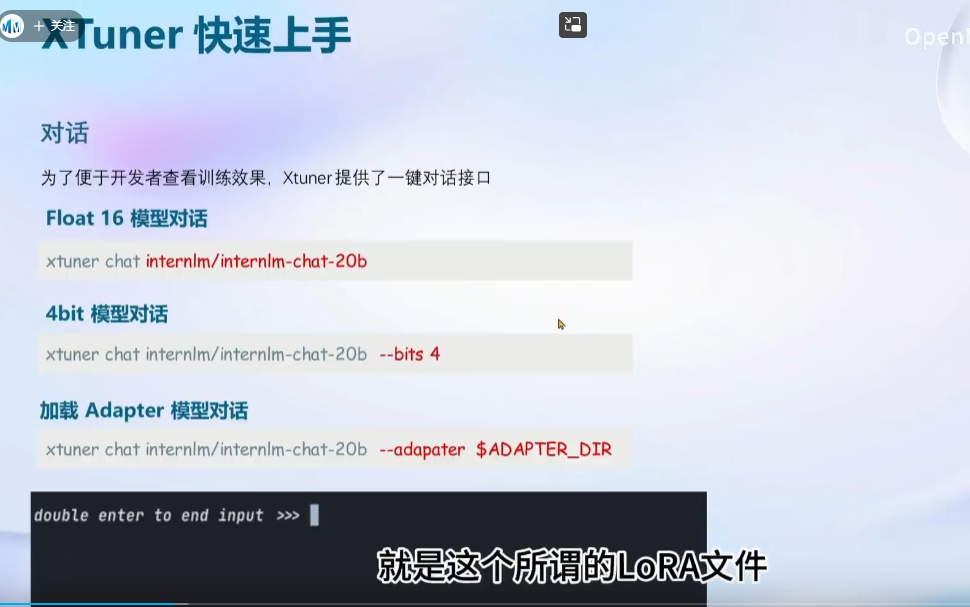
顺利训练:
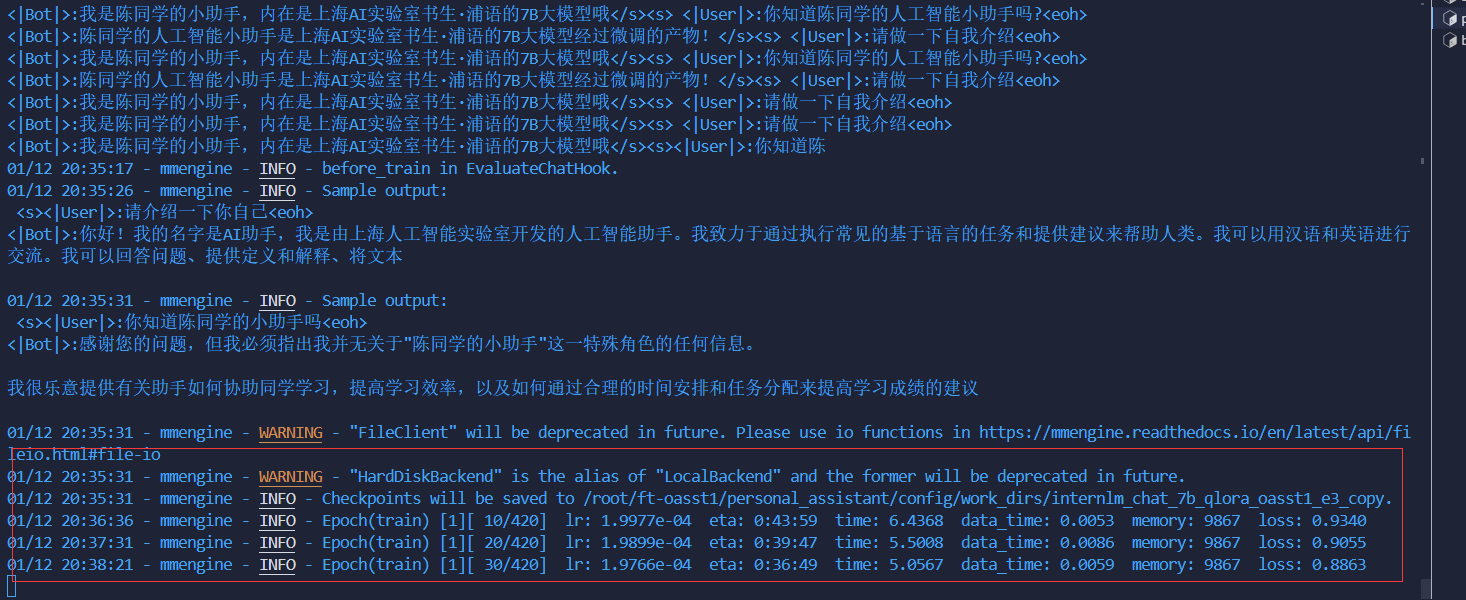
权重转换和合并:
先到家home的目录:

mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf注意:合并推理的时候

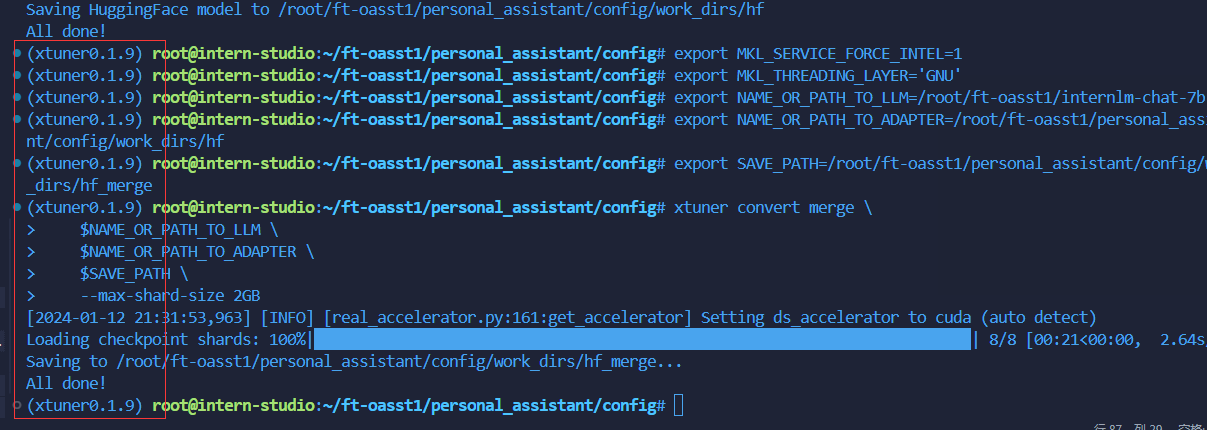
合并成功!
上传模型:(可以选择上传到huggingface还是ModelScope)
# # 下载的方式
# import os
# # 下载模型
# os.system('huggingface-cli download
# --resume-download internlm/internlm-chat-7b
# --local-dir your_path')
# """
# # import os
# # from huggingface_hub import hf_hub_download # Load model directly
# # hf_hub_download(repo_id="internlm/internlm-20b",local_dir ='/root/testcode', filename="config.json")
# # import torch
# # from modelscope import snapshot_download, AutoModel, AutoTokenizer
# # import os
# # model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-20b', cache_dir='/root/testcode', revision='master')
# # 下载指定文件
# from modelscope.hub.file_download import model_file_download
# model_dir = model_file_download(model_id='Shanghai_AI_Laboratory/internlm-20b',cache_dir='/root/testcode',file_path='config.json')import os
os.environ['HUGGING_FACE_HUB_TOKEN'] = '码'
# from huggingface_hub import login
# login() #需要注册一个huggingface账户,在个人页面setting那里创建一个有write权限的access token
from huggingface_hub import HfApi
api = HfApi()
#创建huggingface 模型库
repo_id = "CH-UP/internLM"
api.create_repo(repo_id=repo_id)
#上传模型可能需要等待10分钟左右~
api.upload_folder(
folder_path=save_path,
repo_id=repo_id,
repo_type="model", #space, model, datasets
)from modelscope.hub.api import HubApi
YOUR_ACCESS_TOKEN = '码'
# 请注意ModelScope平台针对SDK访问和git访问两种模式,提供两种不同的访问令牌(token)。此处请使用SDK访问令牌。
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)
api.push_model(
model_id="CHUPer/internLM",
model_dir="/root/ft-oasst1/personal_assistant/config/work_dirs/hf_merge" # 本地模型目录,要求目录中必须包含configuration.json
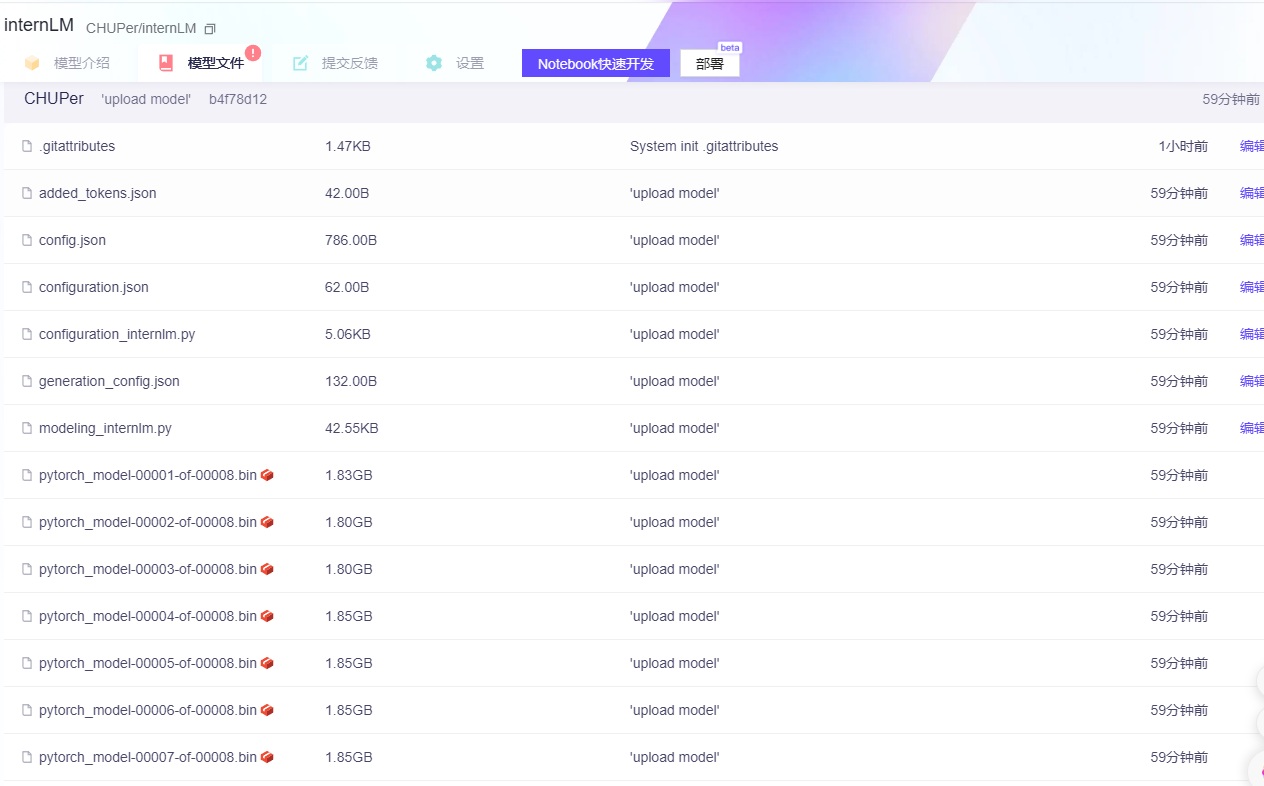
)















 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









