






感谢书生·浦语和上海人工智能实验室提供的模型和算力支持!!!
课程链接:https://github.com/InternLM/tutorial/blob/main/opencompass/opencompass_tutorial.md
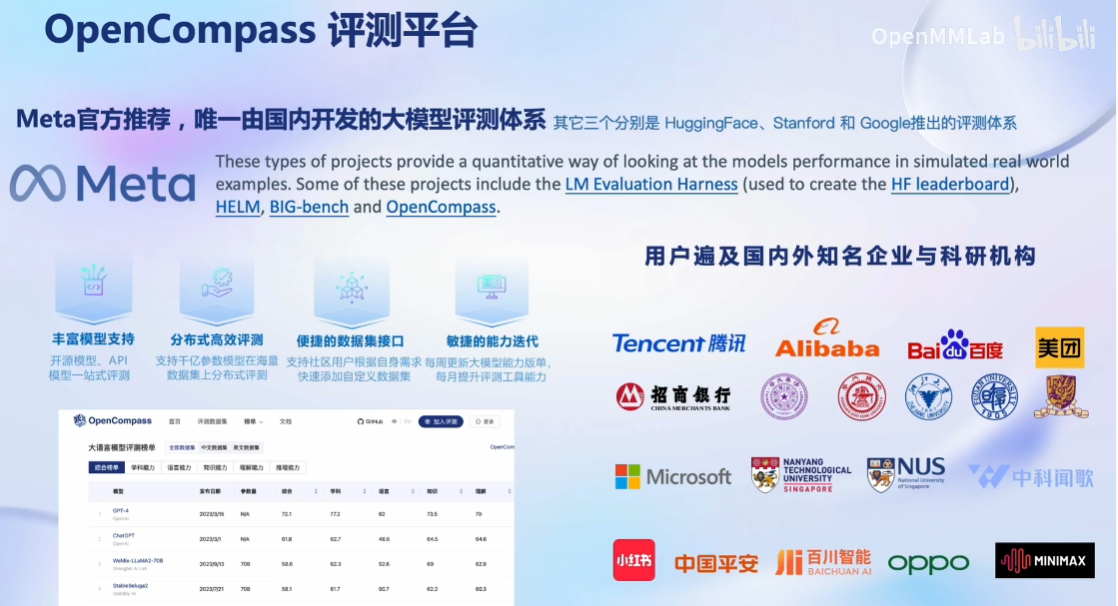
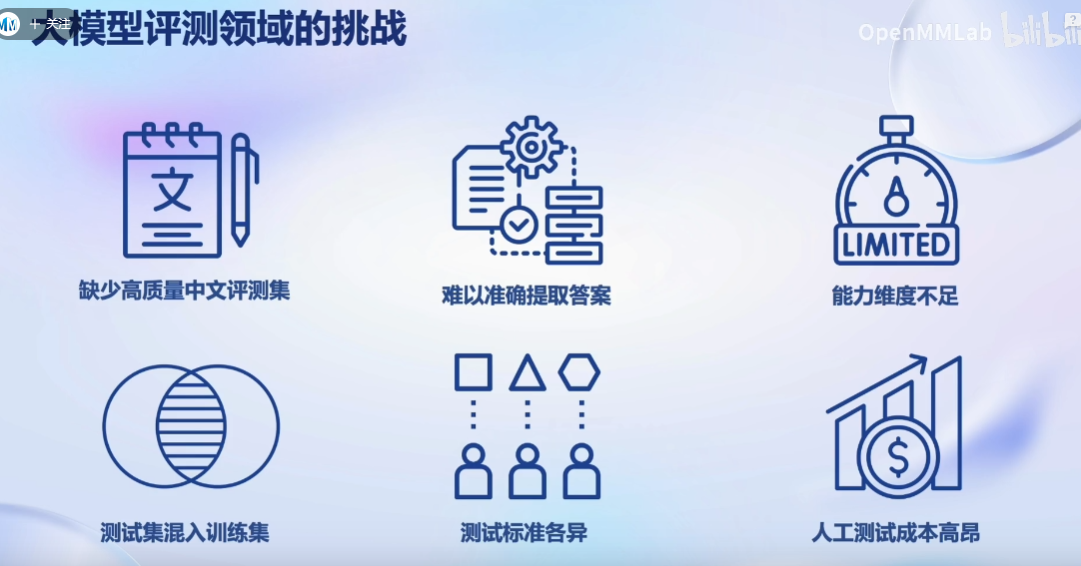
模型评测的问题








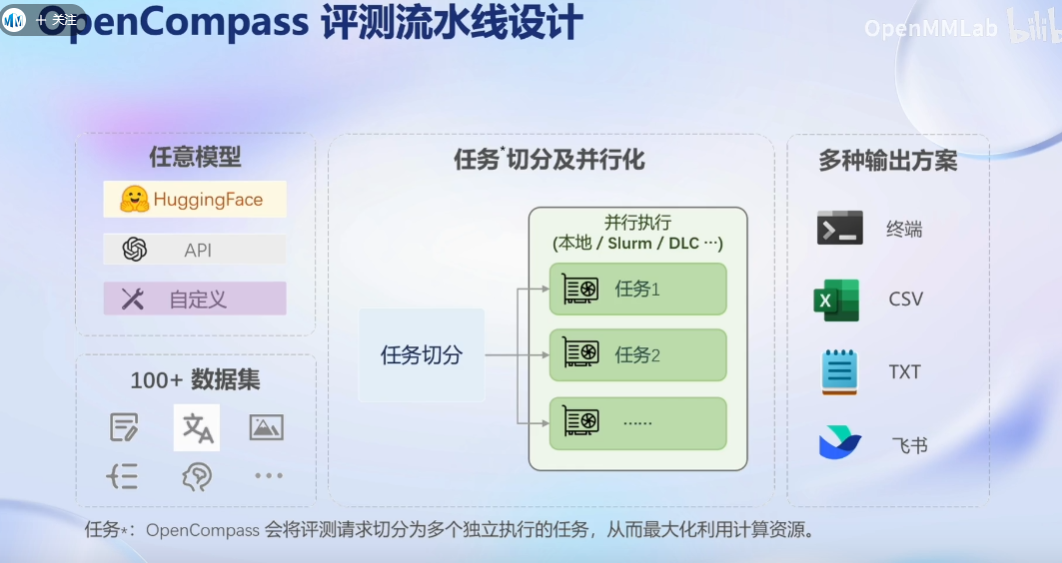
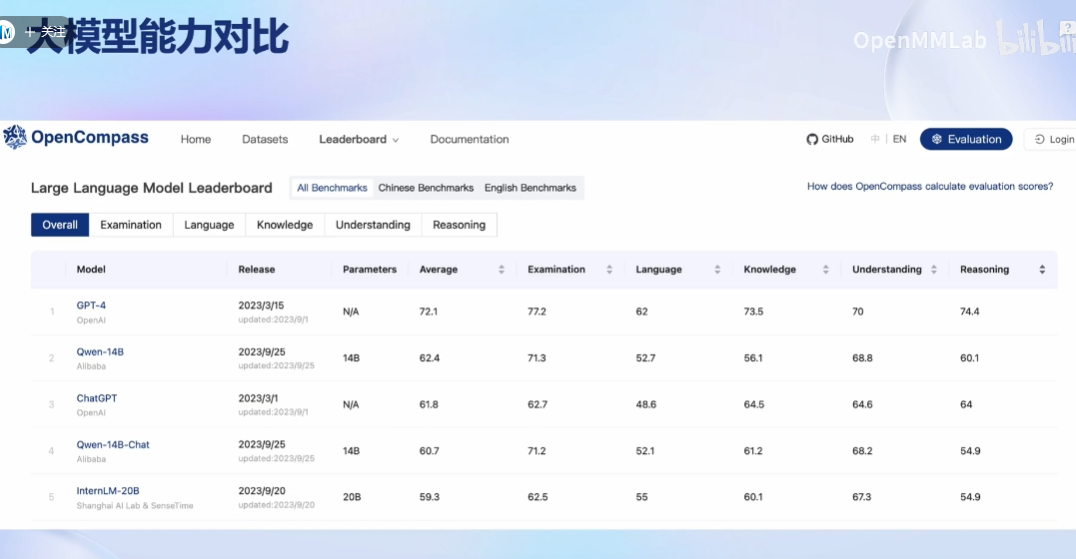
OpenCompass能力框架


动手实践:
git clone https://github.com/open-compass/opencompass
注意:使用上面进行clone的时候可能会出现问题,可以本地下载好再上传。
python run.py --datasets ceval_gen --hf-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug--datasets ceval_gen \
--hf-path /share/temp/model_repos/internlm-chat-7b/ \ # HuggingFace 模型路径
--tokenizer-path /share/temp/model_repos/internlm-chat-7b/ \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 2048 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数
--batch-size 4 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug[2024-01-12 18:23:55,076] [opencompass.openicl.icl_inferencer.icl_gen_inferencer] [INFO] Starting inference process...OpenCompass 提供了一系列预定义的模型配置,位于 configs/models 下。
# 使用 `HuggingFaceCausalLM` 评估由 HuggingFace 的 `AutoModelForCausalLM` 支持的模型
from opencompass.models import HuggingFaceCausalLM
# OPT-350M
opt350m = dict(
type=HuggingFaceCausalLM,
# `HuggingFaceCausalLM` 的初始化参数
path='facebook/opt-350m',
tokenizer_path='facebook/opt-350m',
tokenizer_kwargs=dict(
padding_side='left',
truncation_side='left',
proxies=None,
trust_remote_code=True),
model_kwargs=dict(device_map='auto'),
# 下面是所有模型的共同参数,不特定于 HuggingFaceCausalLM
abbr='opt350m', # 结果显示的模型缩写
max_seq_len=2048, # 整个序列的最大长度
max_out_len=100, # 生成的最大 token 数
batch_size=64, # 批量大小
run_cfg=dict(num_gpus=1), # 该模型所需的 GPU 数量
)数据集配置通常有两种类型:'ppl' 和 'gen',分别指示使用的评估方法。其中 ppl 表示辨别性评估,gen 表示生成性评估。
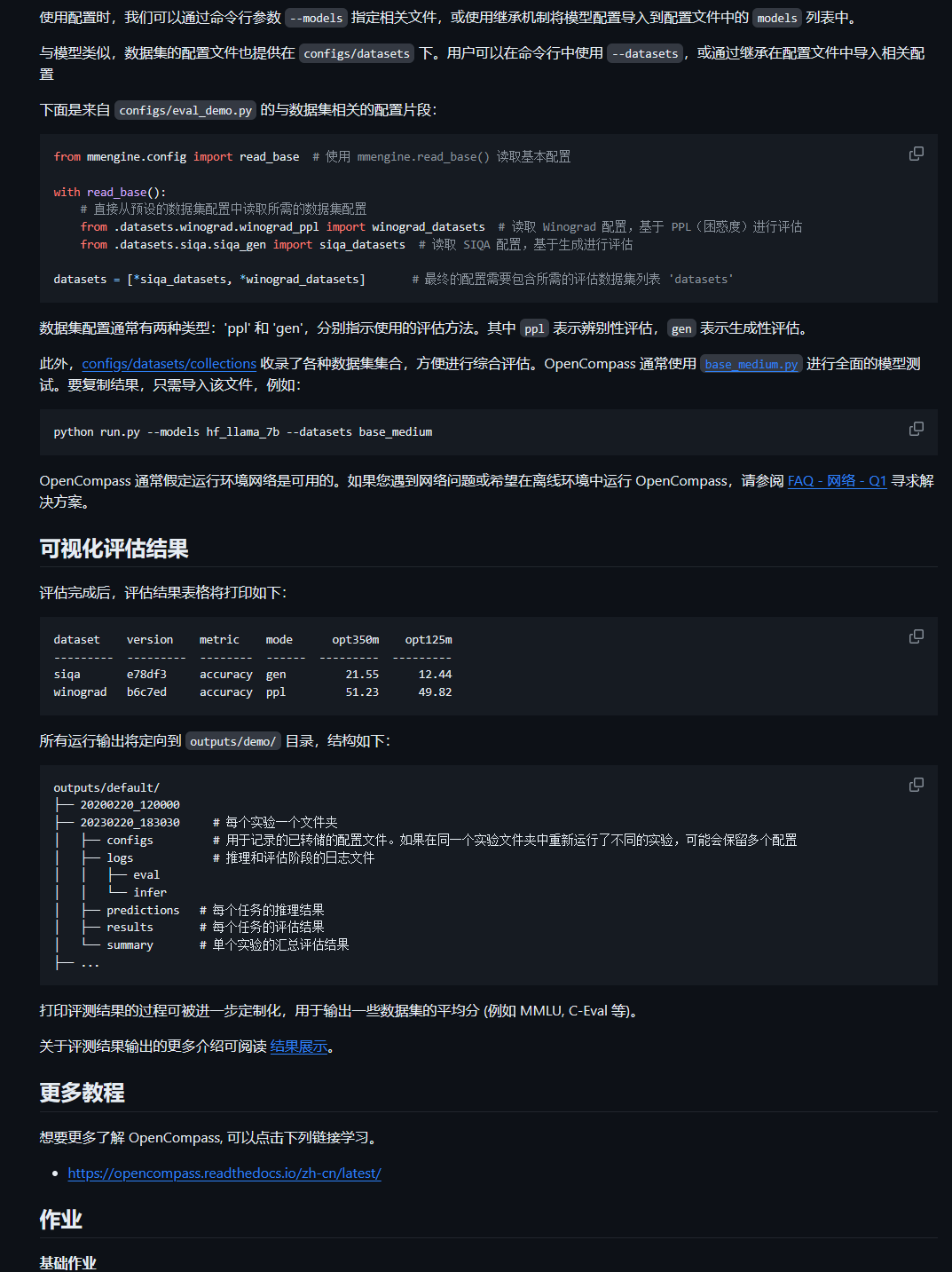
可以在脚本直接写好:(因此可以有两种方式进行评测:脚本或者命令行)
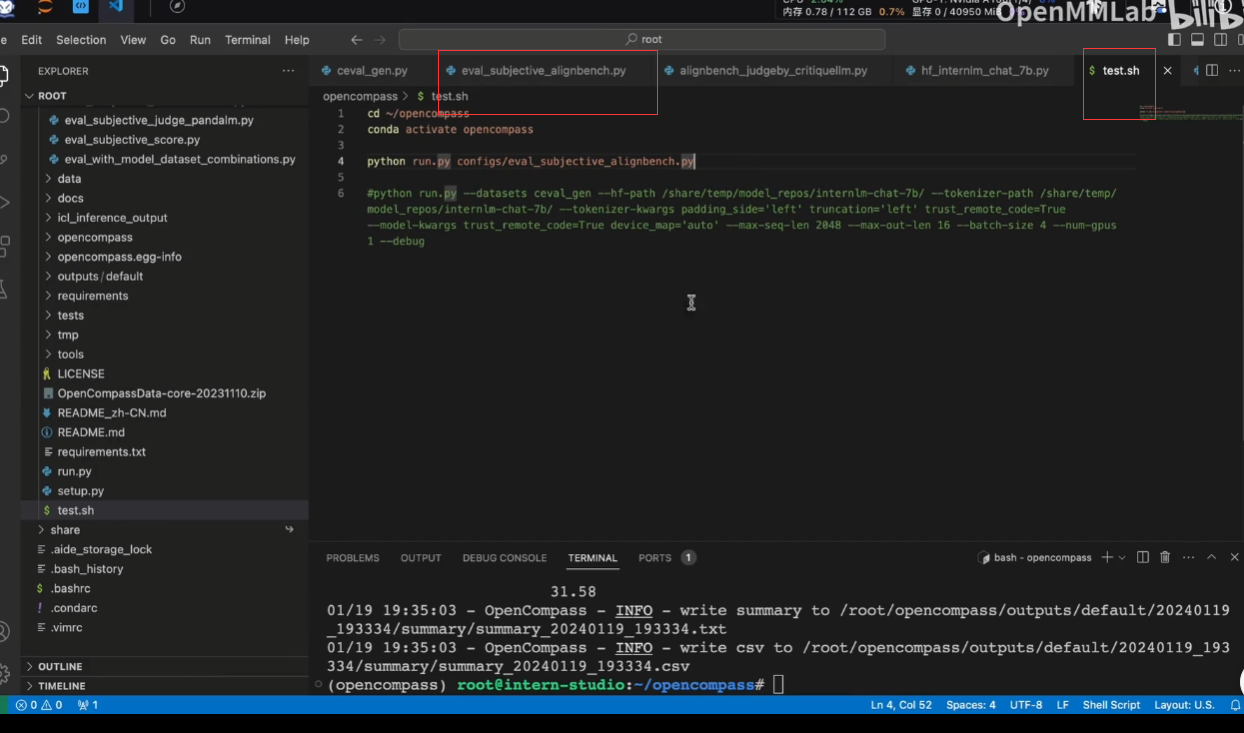
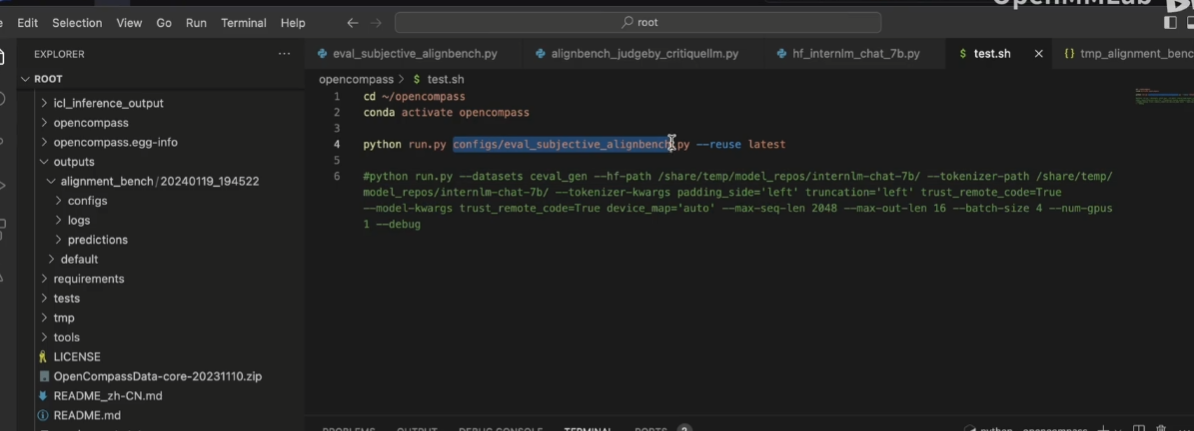
参数--reuse介绍:
接着以前的结果继续评测,这也是需要时间戳的原因
也可以同时测试多个数据集和多个模型
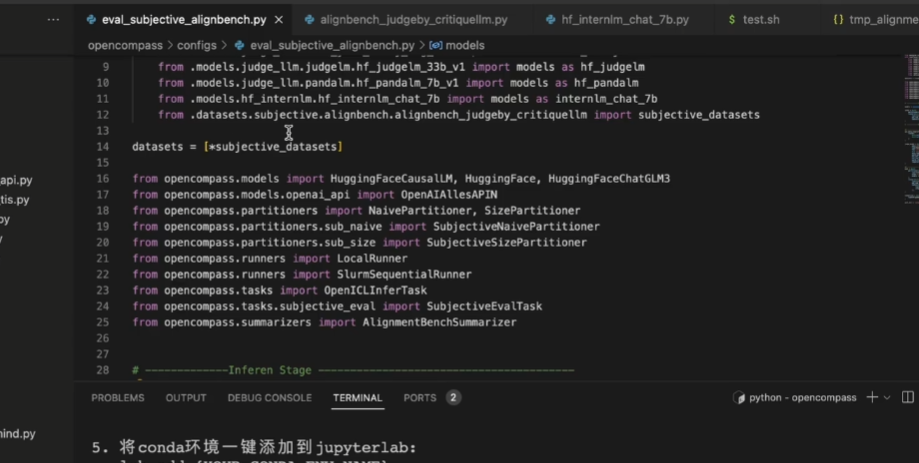
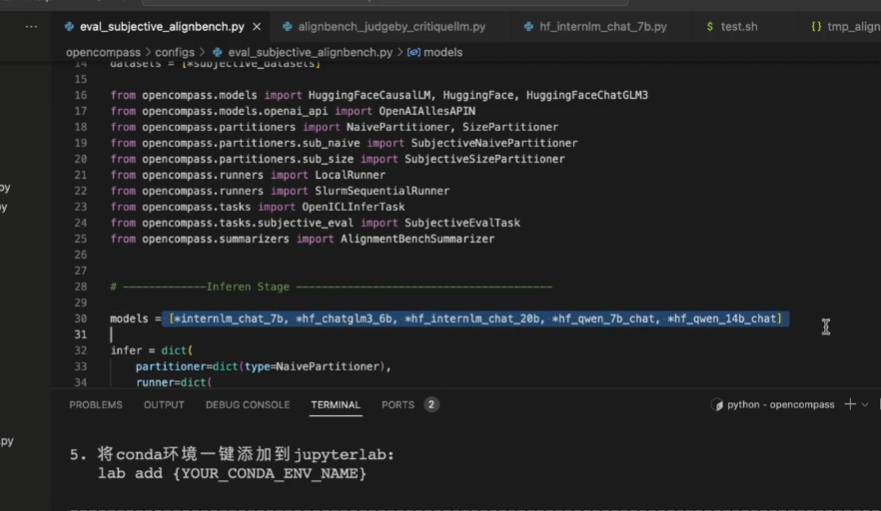
还可以引用第三个模型进行评价打分
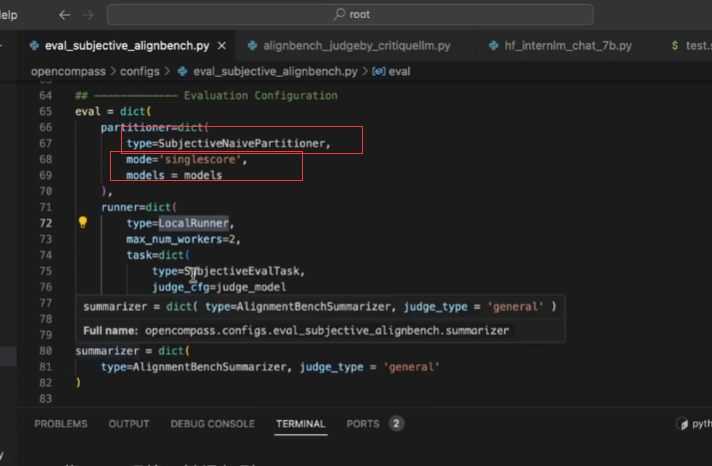
后处理:
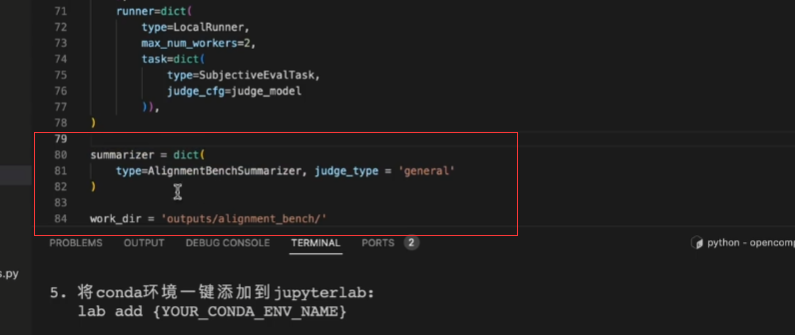
注意:主观评测的时候最后加入这里的字段















 1875
1875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









