代码
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
torch.manual_seed(10)
sample_nums = 100
mean_value = 1.7
bias = 1
n_data = torch.ones(sample_nums, 2)
x0 = torch.normal(mean_value * n_data, 1) + bias
y0 = torch.zeros(sample_nums)
x1 = torch.normal(-mean_value * n_data, 1) + bias
y1 = torch.ones(sample_nums)
train_x = torch.cat((x0, x1), 0)
train_y = torch.cat((y0, y1), 0)
print("n_data",n_data)
print("x0", x0)
print("train_y", train_y)
class LR(nn.Module):
def __init__(self):
super(LR, self).__init__()
self.features = nn.Linear(2, 1)
self.sigmoid = nn.Sigmoid()
"""
torch.nn.Sigmoid() 和 torch.sigmoid() 的区别:
torch.nn.Sigmoid()需要在__init__()方法中定义为全局变量才能使用,而torch.sigmoid()不需要定义,可直接使用。
"""
def forward(self, x):
x = self.features(x)
x = self.sigmoid(x)
return x
lr_net = LR()
loss_fn = nn.BCELoss()
lr = 0.01
optimizer = torch.optim.SGD(lr_net.parameters(), lr=lr, momentum=0.9)
for iteration in range(1000):
y_pred = lr_net(train_x)
loss = loss_fn(y_pred.squeeze(), train_y)
loss.backward()
optimizer.step()
if iteration % 20 == 0:
mask = y_pred.ge(0.5).float().squeeze()
correct = (mask == train_y).sum()
acc = correct.item() / train_y.size(0)
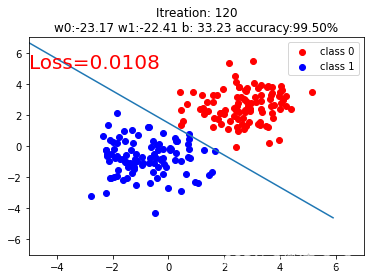
plt.scatter(x0.data.numpy()[:, 0], x0.data.numpy()[:, 1], c="r", label="class 0")
plt.scatter(x1.data.numpy()[:, 0], x1.data.numpy()[:, 1], c="b", label="class 1")
w0, w1 = lr_net.features.weight[0]
w0, w1 = float(w0.item()), float(w1.item())
plot_b = float(lr_net.features.bias[0].item())
plot_x = np.arange(-6, 6, 0.1)
plot_y = (-w0 * plot_x - plot_b) / w1
plt.xlim(-5, 7)
plt.ylim(-7, 7)
plt.plot(plot_x, plot_y)
plt.text(-5, 5, "Loss=%.4f" % loss.data.numpy(),fontdict={"size":20, "color":"red"})
plt.title("Itreation: {}\nw0:{:.2f} w1:{:.2f} b: {:.2f} accuracy:{:.2f}%".format(iteration, w0, w1, plot_b, acc * 100))
plt.legend()
plt.show()
plt.pause(0.5)
if acc > 0.99:
break
模型拟合结果可视化























 7049
7049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









