







前言:好久没有用了,我已经快忘记了自己还有一个CSDN账号了。 在某位不知名好友的提醒下,终于拾起来了,自己也从大二转变成了研二。
目前研究方向主要为:时间序列预测,自然语言处理,智慧医疗
欢迎感兴趣的小伙伴一起交流、一起进步!!!
最近课题组有个任务,后续的会在这周更新完!!!
目录
- 一.背景
- 二.模型整体架构
- 三.模型架构详解
- 3.1数据
- 3.2输入(先做了解,后续部分会详细讲解)
- 3.3Embedding
- 3.4位置编码
- 3.5Encoder_self-attention
- 3.6Encoder_scaled dot-product attention
- 3.7Encoder_Multi-Head
- 3.8Encoder_padding掩码
- 3.9Encoder_多头注意力整体
- 3.10Encoder_Add&Norm
- 3.11Encoder_前馈神经网络
- 3.12Dncoder_Masked Multi-Head Attentuion
- 3.13Encoder_Decoder_Multi-Head Attention
- 3.14输出部分
- 3.15模型训练_损失函数
- 3.16模型训练_自定义学习率
- 四.参考
一.背景
1.1论文
- 2017年谷歌Brain团队发表了“Attention Is All You Need”(注意力就是你所需要的一切),正式提出了Transformer。这是一篇非常经典的自然语言处理领域的文章,把注意力机制推向了高潮。
1.2发展动机
- Transformer的提出,最初针对的是机器翻译任务。
- 传统的机器翻译采用的主流框架为Encoder-Decoder框架,以RNN作为主要方法,基于RNN发展出来的LSTM和GRU也一度被认为是解决该问题的最优方法。
- 然而,RNN模型的计算被限制为顺序,阻碍了样本训练的并行化,会导致在计算过程中发生信息丢失从而引起长期依赖问题。
- RNN以及其衍生网络的特点就是慢,前后隐藏状态依赖强,无法实现并行。
1.3特点
- Transformer的self-attention可以实现快速并行,改进了RNN类模型训练慢的缺点
- Transformer可以增加到非常深的深度,充分挖掘DNN模型的特征,提升准确率
1.4地位
- 开天辟地,各种竞赛屠榜,毕业论文首选
- 对NLP、CV等各种领域,产生了深刻的影响
- 截止目前,知网收录名称包含Transformer的期刊达18.51万,学位论文总数达4.16万
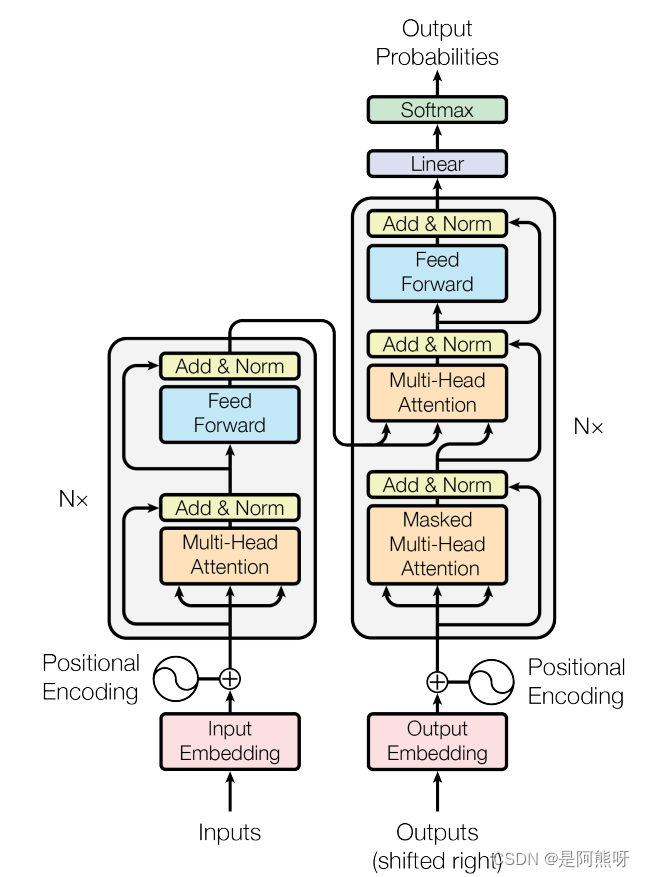
二.模型整体架构
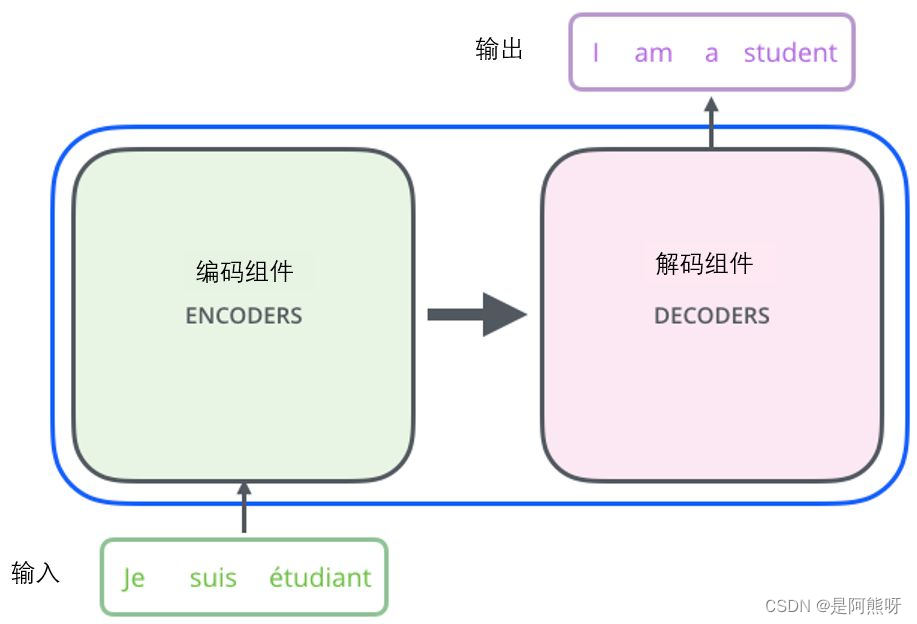
2.1宏观理解
- 输入一段法文,经过Transformer模型后,可以输出对应的英文

- Transformer本质上是一种Encoder-Decoder架构,因此中间部分的Transformer可以分为两个部分:Encoder(编码组件)和Decoder(解码组件)
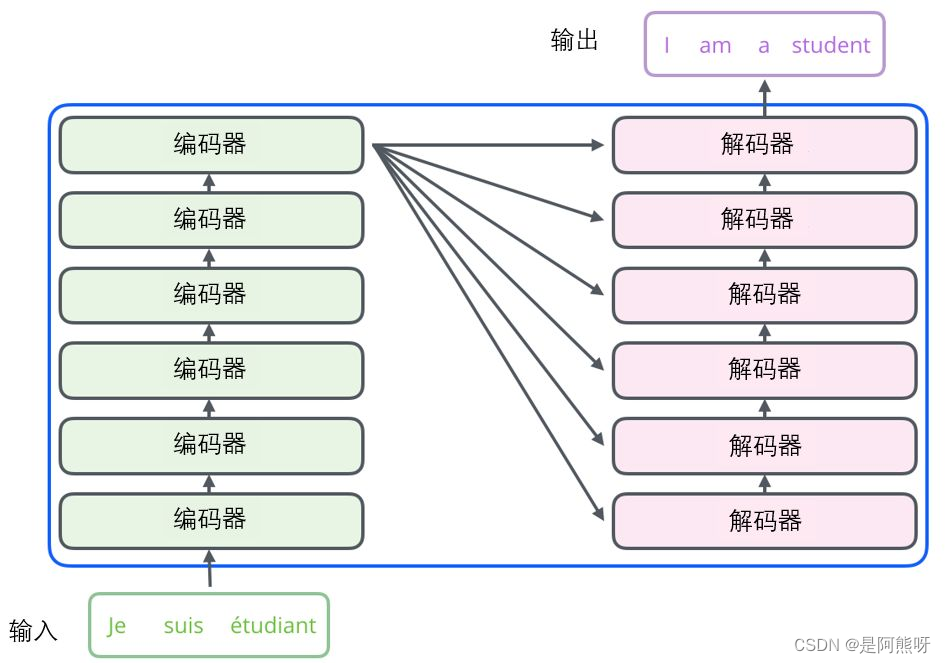
- 其中,Encoder和Decoder分别有n1和n2层(这里n1=n2=6),因此又可以将模型进一步细分
2.2微观理解
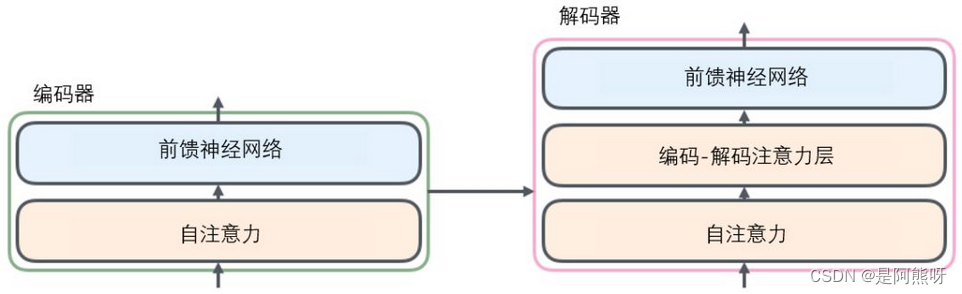
- 每个编码器由两个子层组成:Self-Attention 层(自注意力层)和 Position-wise Feed Forward Network(前馈网络)
- 解码器也有编码器中这两层,但是它们之间还有一个注意力层(即 Encoder-Decoder Attention),使得解码器关注输入句子的相关部分
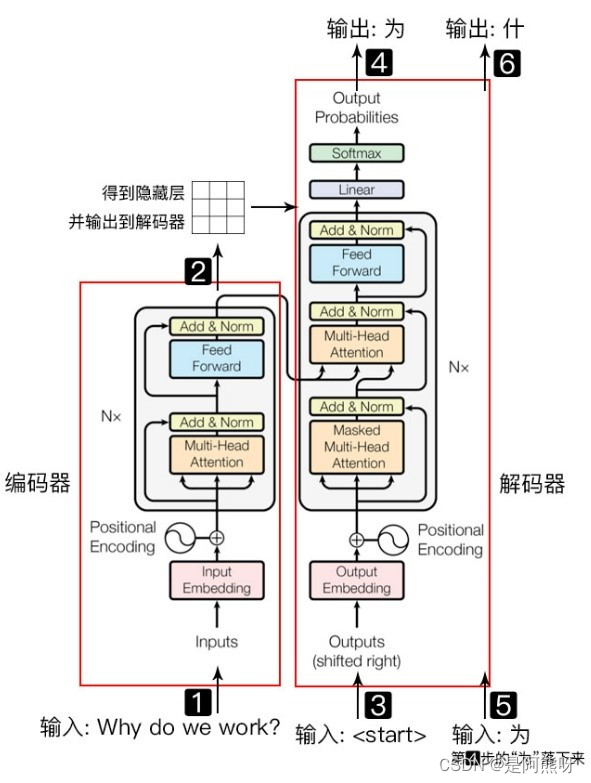
2.3工作流程
- 输入需要翻译的数据(以:Why do we work为例)
- 经过Encoder层,得到隐藏层,输出到Decoder
- Decoder的输入(即
<strat>开始符号) - 将Decoder的输入进行上述操作得到Decoder的输出(即输入Why后,得到翻译的结果:为)
- 将Decoder的输出和Decoder的输入进行拼接,共同作为下一步Decoder的输入(即:
<strat>和为) - 得到Decoder的输出:什
值得注意的是,第4步和第5步是并行进行的,这里为了详细解释原理,拆分为了两步。
三.模型架构详解
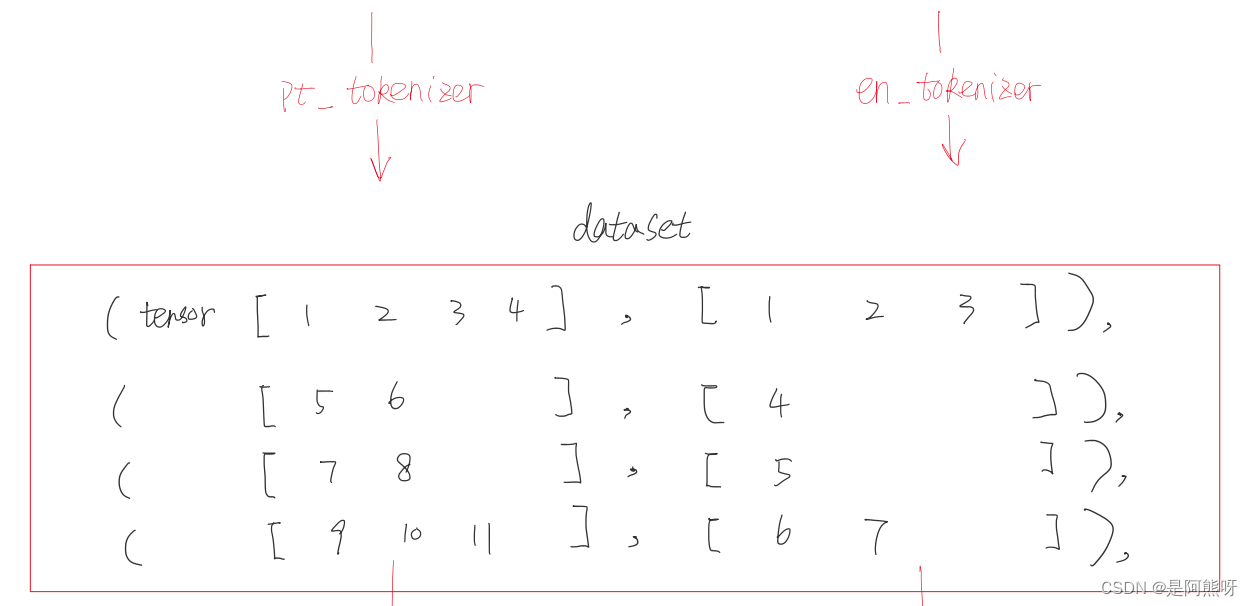
3.1数据
- 原始数据为一组元组,前面的部分为中文,后面的部分为对应的英文。均为Tensor的数据类型。

- 拿到数据后,第一件事就是将字符串转换为机器可以识别的数字编码。
- 为每一句话加上起始符和终止符,这里分别以12,8作为起始符;13,9作为终止符(只要不在编码的数字里面,任何数字都是可以的)
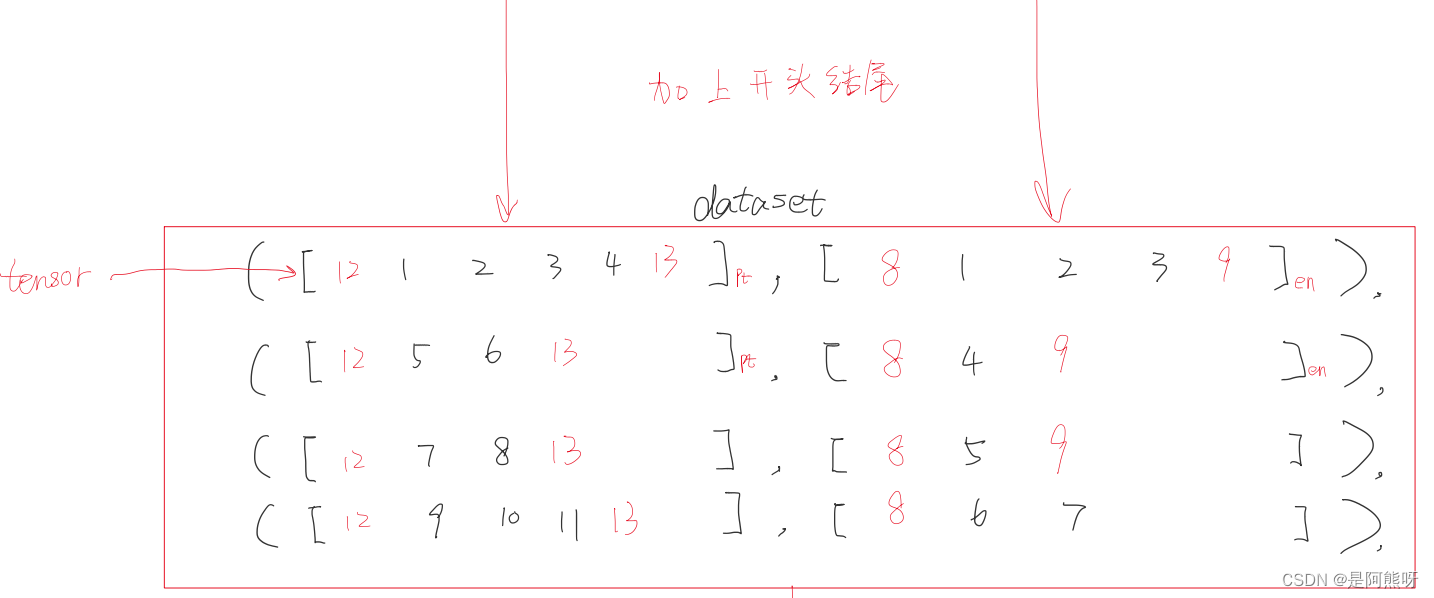
- 之后,一般会经过shuffle(打乱顺序)、batch(分批提速)、padding(填充)等操作,使得模型学习的效果更好。这里为了方便,仅展示batch和padding的操作,不进行shuffle。
- 将前两行数据作为一个batch,后两行数据作为一个batch,然后按照一个batch中最长的长度进行填充。
- 值得注意的是,每一个batch最长的长度可能是不一样的
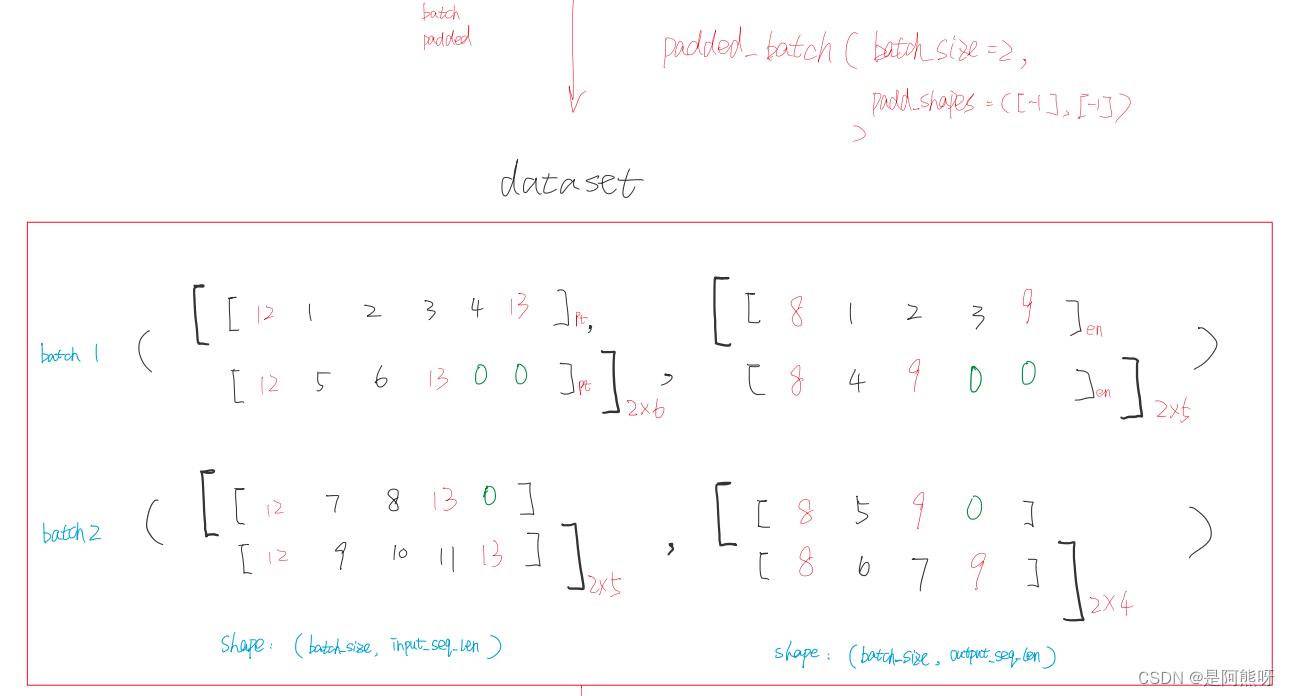
3.2输入(先做了解,后续部分会详细讲解)
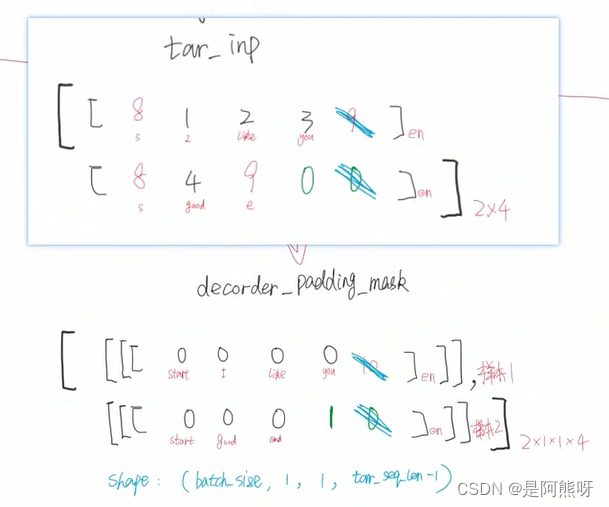
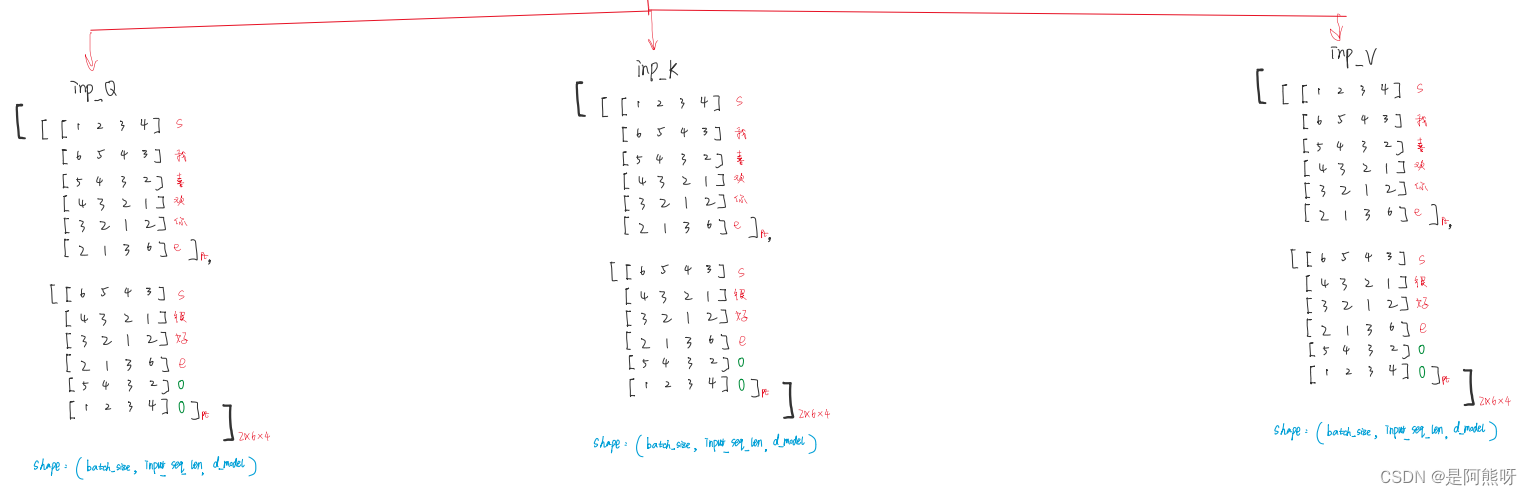
- 以第一个batch为例,左边为中文(input),右边为英文(target)
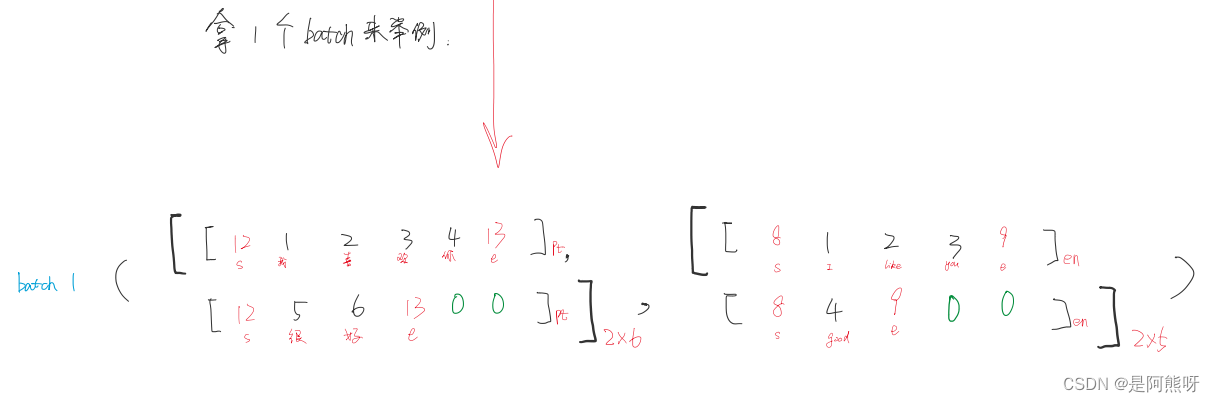
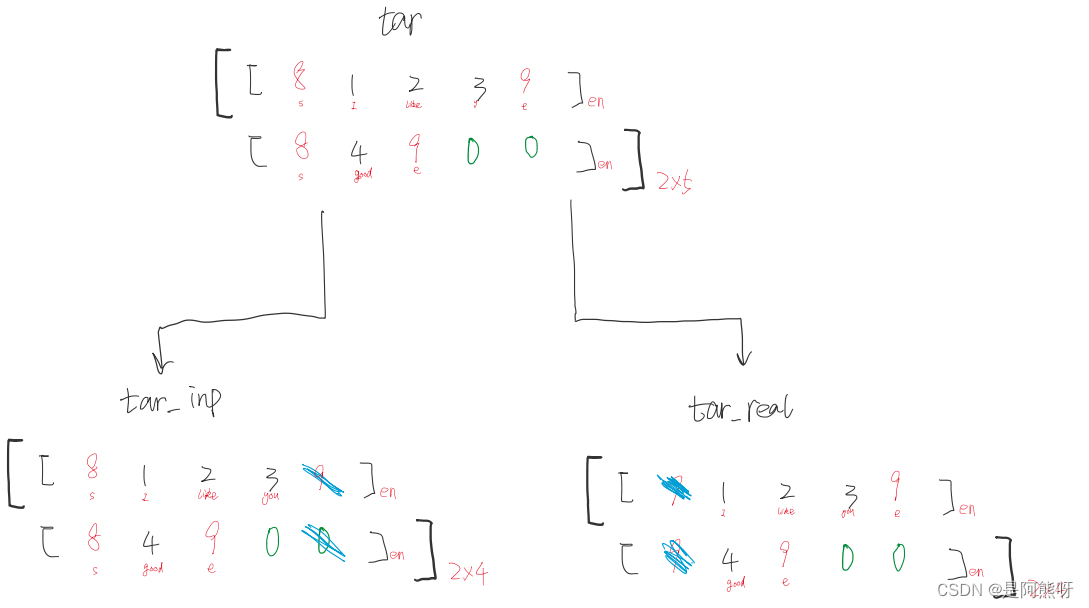
- 对于target,需要分为target_input(如图6中的步骤3-5。即经过Encoder后,传入Decoder的输入)和target_real(如图6中的步骤6。Decoder的输出)。
- 记录input和target_input的padding,消除影响。具体操作位:padding项变为1,非padding项变为0
- 提醒:以下部分大家可能目前觉得难理解,没关系,现在有一个印象就好,后面到了这一部分就会理解
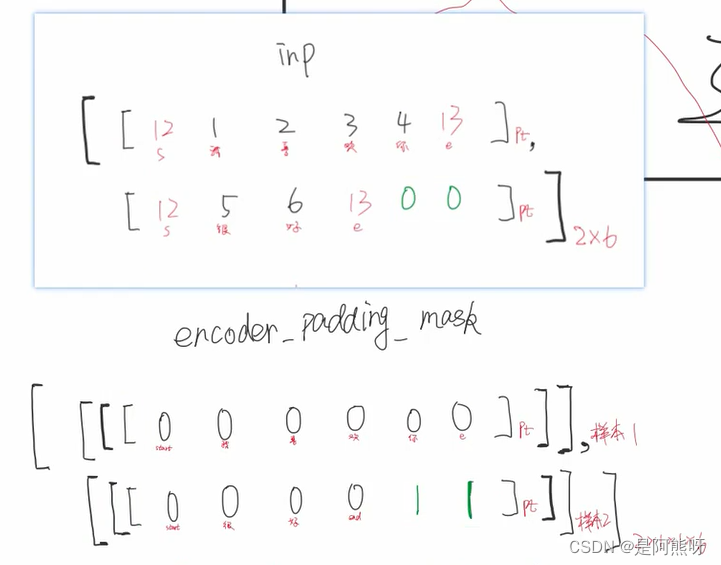
- 下面展示出4个padding的对应关系
3.3Embedding
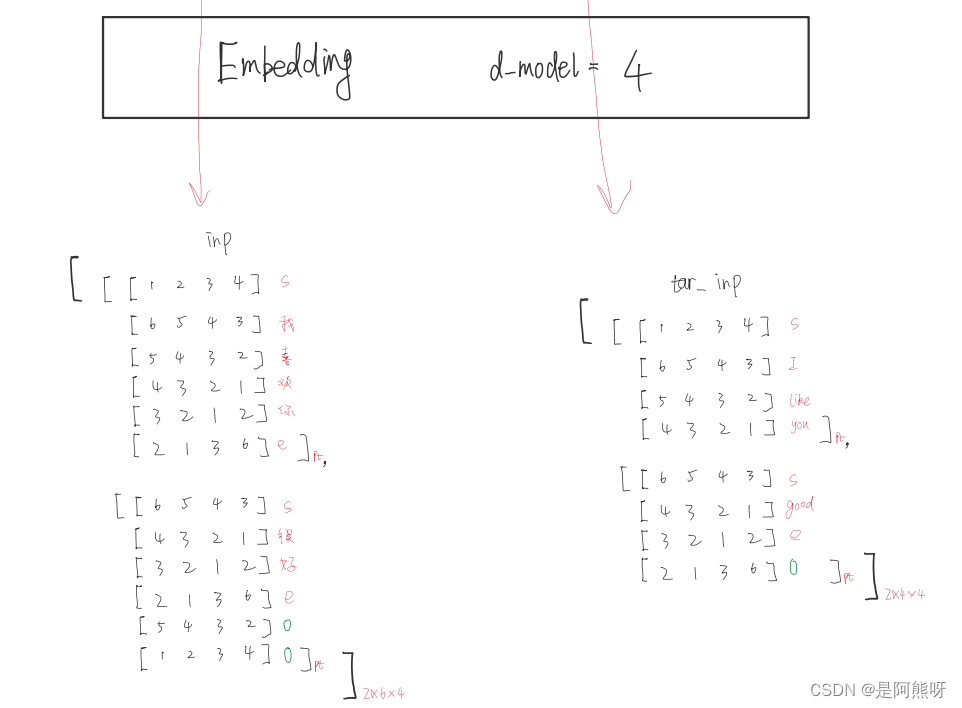
- 将对应的数字编码,转为向量表示。这里以4维为例(每个数字,用一个4维的向量表示)
- input由二的张量变成了一个三维的张量(即batchsize,input_sql,dmodel)
- 大家不用纠结数字的具体表示,只需要了解结构就可以
3.4位置编码
- Transformer因为并行化,无法捕捉到位置信息
- 解决方案:位置编码,引入绝对位置和相对位置
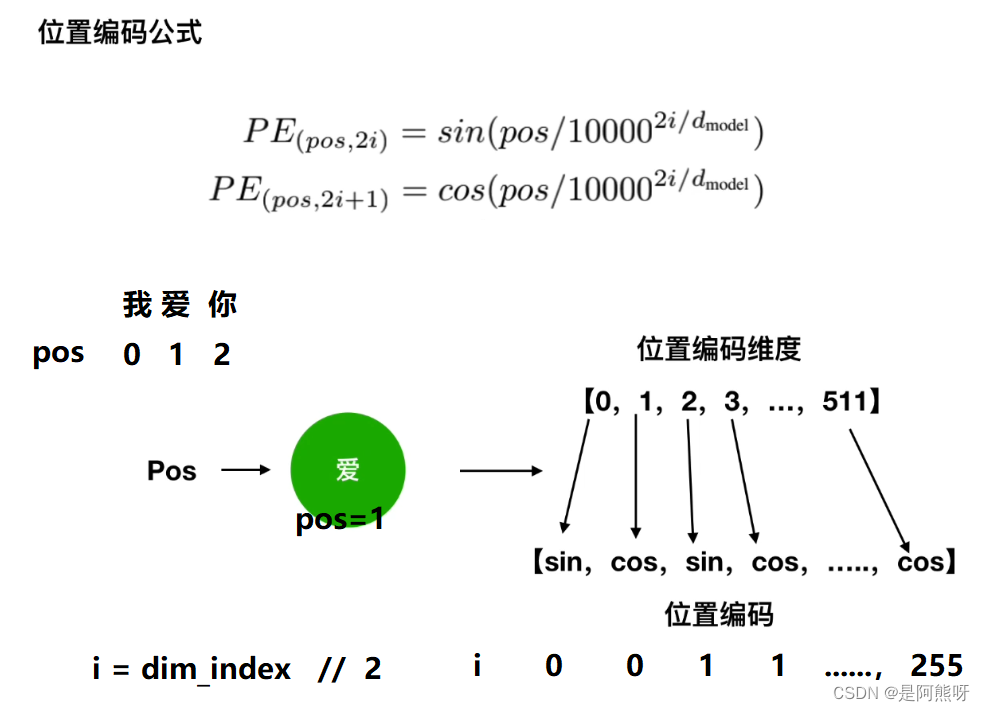
- 下面公式中,pos指的是这句话的位置(向量的顺序),
i = dim_index // 2dmodel指的是向量的维度 - 位置编码只和Embedding的维度和seq_length有关
- 值得注意的是,在原文中,作者给出了一个位置编码的示意图,如下图19所示。
- 这里,d_model = 512,seq_length = 50。可以看到每一个位置(纵坐标)的颜色都不一样,这也是说明了位置编码可以反应真实的顺序。
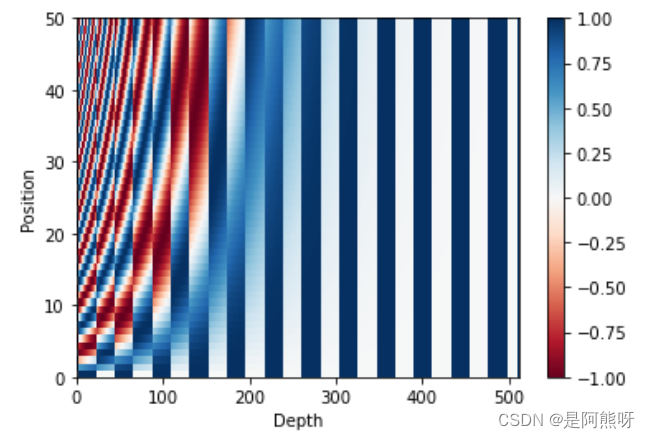
图19 位置编码示例
3.5Encoder_self-attention
- 没有self-attention,每个词只能表示自身的含义,不包含信息
- self-attention会对词向量进行重构,使得词向量不单只包含自己,而是综合考虑全局,融入上下文
- 举个例子,以“我宣你”为例,embedding后,会生成对应的词向量,经过线性变化后,每个词向量会生成q、k、v三个变量,来进行后续的计算,如图20所示。
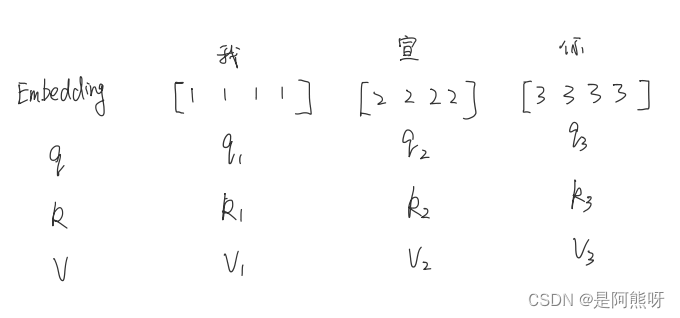
-
接下来,q、k进行点乘操作,计算相关性,每一个q跟所有的k进行计算。计算后,得到一个相关性得分,经过softmax将得分映射到0-1之间。之后与v进行相乘,形成一个新的向量,这就是结合了上下文的向量,不仅仅包含embedding。
-
(这里要注意:q1和v2点乘 与 v2和q1点乘是不一样的。举个例子,有人对你笑,你可能是因为)

3.6Encoder_scaled dot-product attention
-
本文对self-attention进行了改进,公式如下图22所示。
-
改进一:q、k、v是一个矩阵(原来是向量)
-
改进二:除以根号dk,dk表示的是k的维度(这也就是为什么叫scaled)
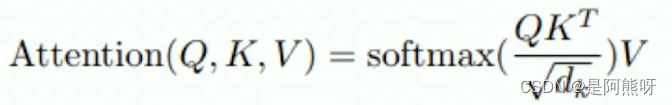
- 为什么要除以根号dk呢?这里从两个角度进行解释
1.前向传播角度:softmax 是一种非常明显的 “马太效应”:强(大)的更强(大),弱(小)的更弱(小)。而缩放后,注意力值就分散些,这样一般就获得更好的泛化能力。
2.反向传播角度:不除以这个的话,注意力得分score是一个很大的值,softmax在反向传播时,容易造成梯度消失
- 为什么选择根号dk,而不是其他的值呢?
假设向量q和k的各个分量是互相独立的随机变量,均值为0,方差为1,那么q和k点积后的均值为0,方差为dk
3.7Encoder_Multi-Head
- 理论上,Embedding后,需要生成q、k、v,采用不同的参数,如图23所示,用两套不同的参数生成两套不同的q、k、v。这就叫不同的头(本文采用了8个头)
- 本文中,用一套参数生成Q、K、V,进行拆分。拆分后,Q的维度减少(depth = d_model / heads_num),要保证d_model能够整除heads_num
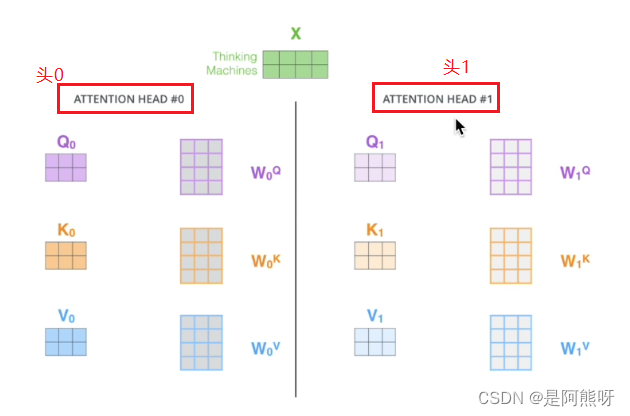
图23 Multi-Head示例 - 之后,每个头独立行动,进行scaled dot-product attention操作,将结果进行拼接,还原为之前的维度d_model,这就相当于将多个头提取到的特征进行了融合
- 为什么使用多头?
能够从多个角度去理解内容,注意到不同子空间的信息,捕捉到更加丰富的特征信息
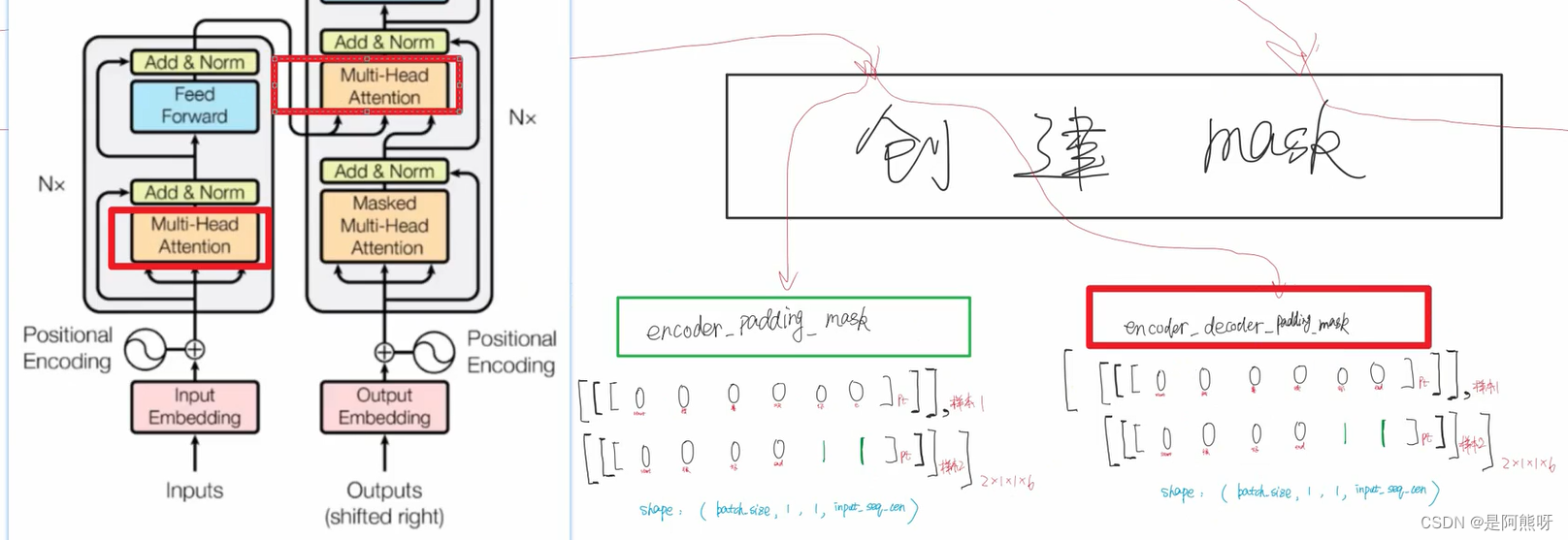
3.8Encoder_padding掩码
- 在这之前,我们要知道padding只要不影响有效信息就可以了
- 计算qk关系的时候,padding不会影响
- 但是计算softmax的时候(公式如图24),padding会影响。因为softmax计算的是每一个值,可能让模型以为padding和我们的向量有了关系(如图25绿色部分所示),所以要让padding的结果变成0,因此需要padding mask
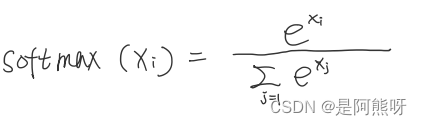
-
padding mask:最开始的时候,就将padding变成1,非padding变成0,用来标记padding(注意,1只是一个标记作用,不是padding的值一直是1)
-
计算的时候,获取标记,将padding变成一个非常小的数,那么和padding有关的项会变成极其小的数。对于指数函数,当x无限小的时候,那么值就无限趋近于0,因此可以把softmax中padding产生的影响消除掉。

图25 padding示例 -
为什么padding变成1,非padding变成0?一开始padding为0不是更好吗?
如果padding一开始为0,那么我们看softmax公式,e的0次方,就是1,这没有消除padding的影响,所以一开始给padding为0是没有
3.9Encoder_多头注意力整体
-
到了这里,学习完这些主要的操作后,我们回到最初的环节(接图17 embedding)
-
Embedding后,我们要经过scaled dot-product attention(缩放),位置编码。
-
之后input需要经过多头注意力模块;target_input需要经过掩码多头注意力模块

图26 Embedding后的操作 -
首先,经过线性变化,得到QKV三个矩阵,如图27所示
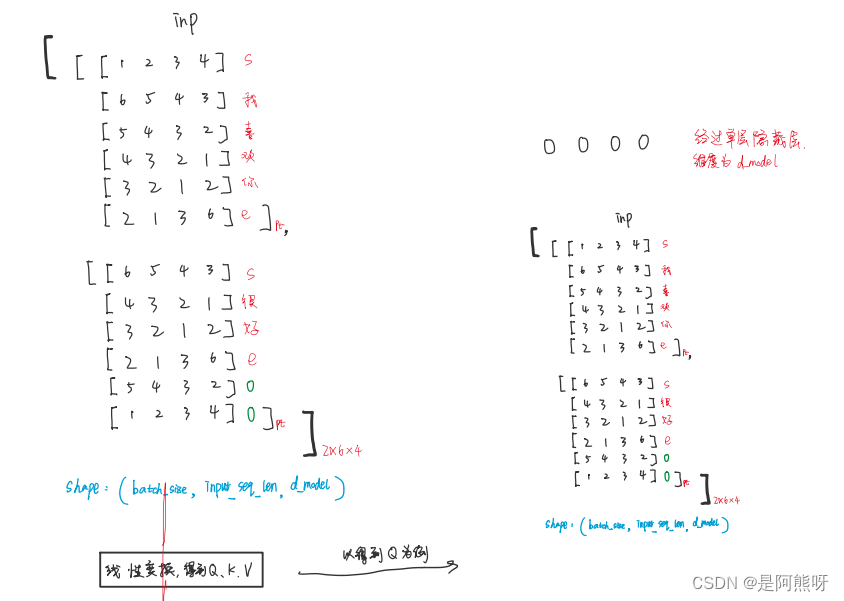
图27 线性变化
-
然后,进行分头(这里以2个头为例),如图29所示
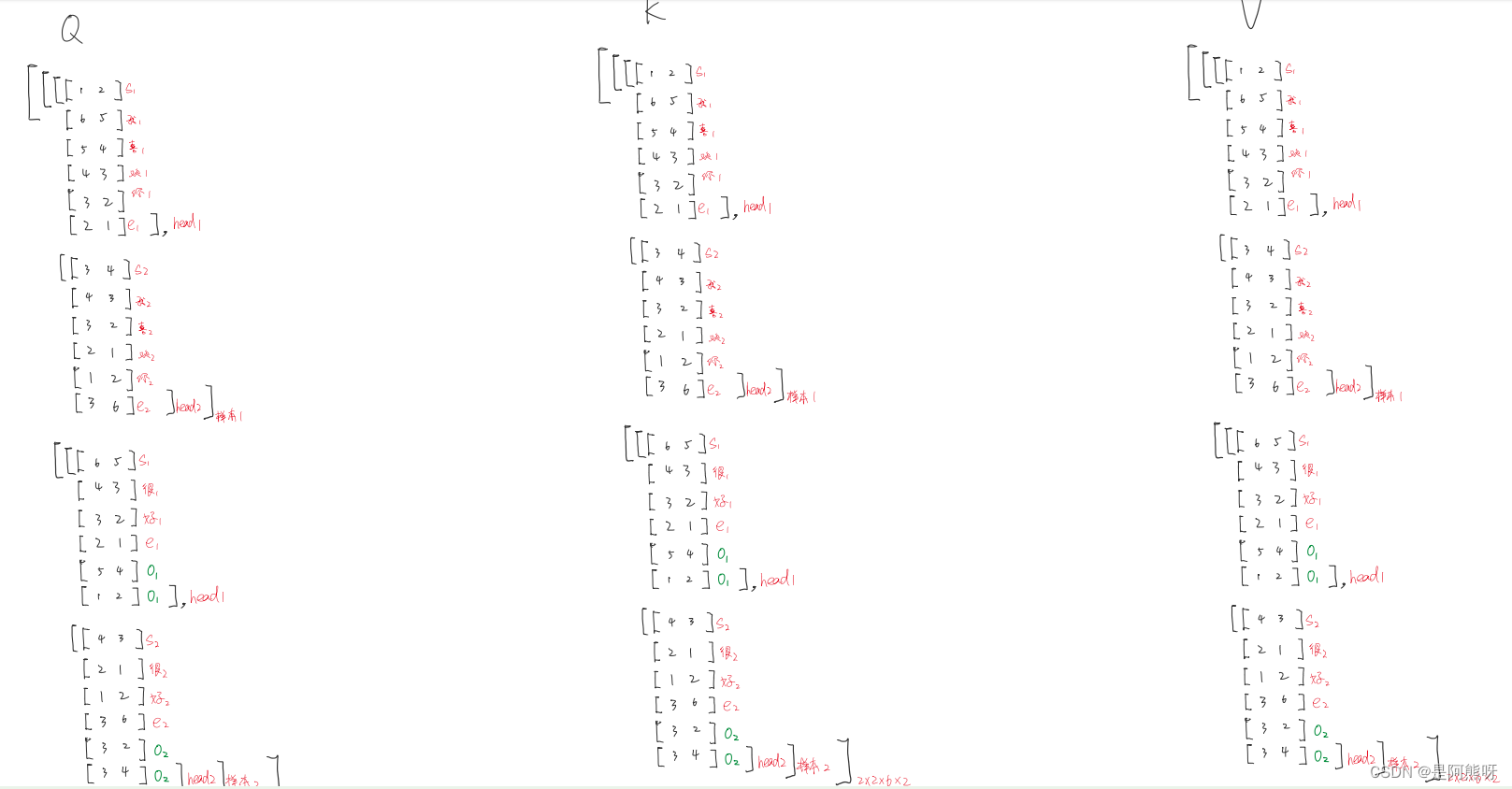
图29 分头结果 -
之后,利用attention进行注意力权重得分(scaled dot-product attention公式),结果如图30所示。
-
注意:右图中使用padding mask消除padding的影响
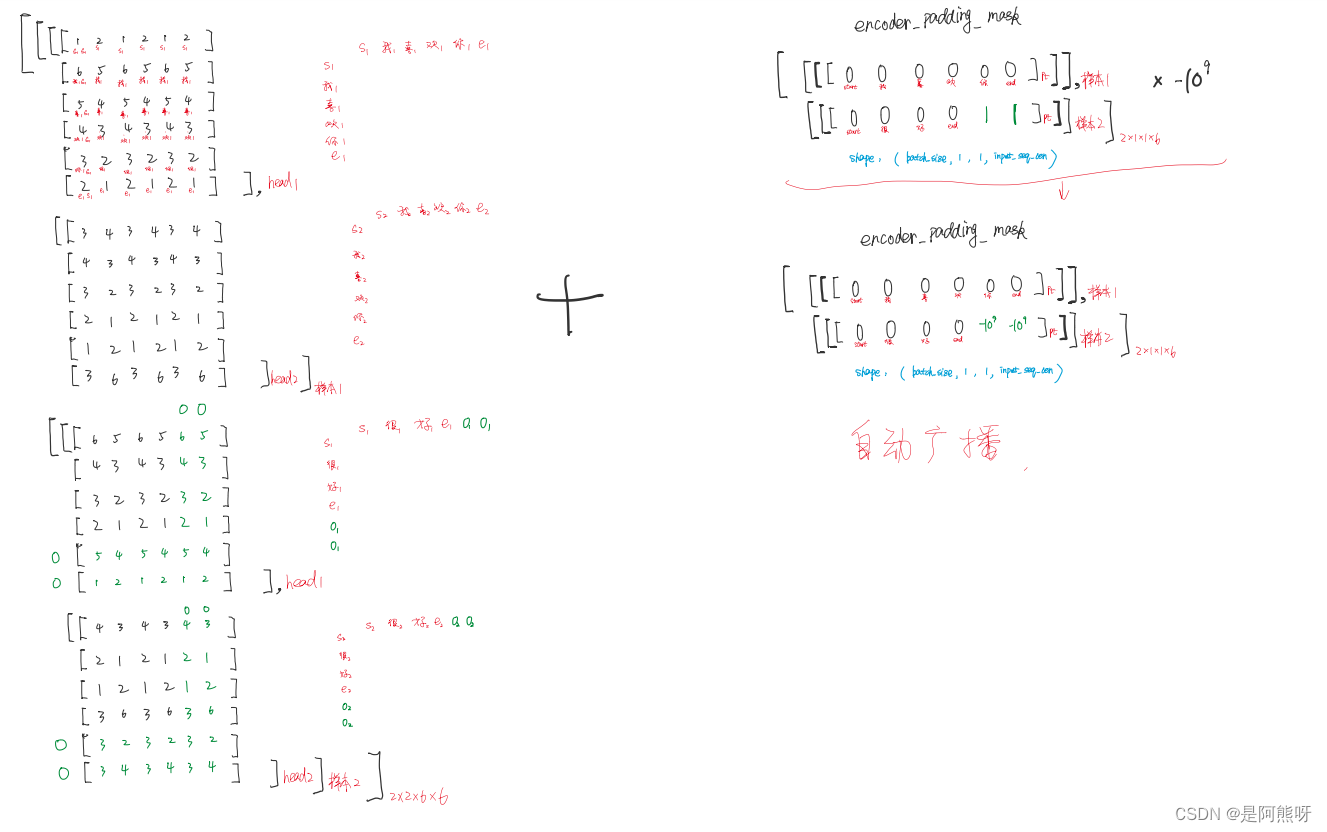
图30 计算注意力权重 -
接下来,经过softmax归一化,得到权重
-
softmax后,与V进行相乘,提取出新特征
-
维度还原,将多头进行拼接
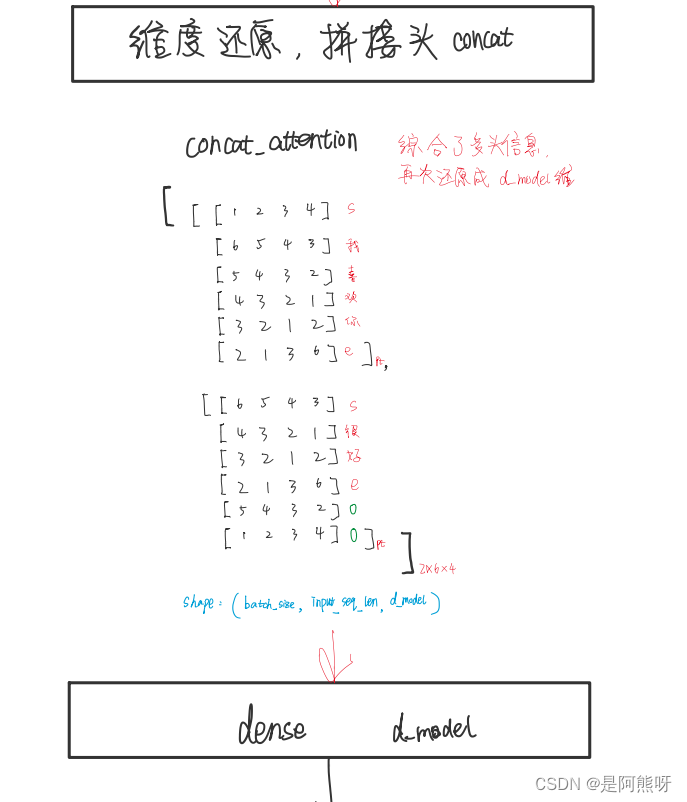
图31 维度还原 -
到这里,多头注意力机制就结束了
3.10Encoder_Add&Norm
-
Add&Norm在许多地方都用到了
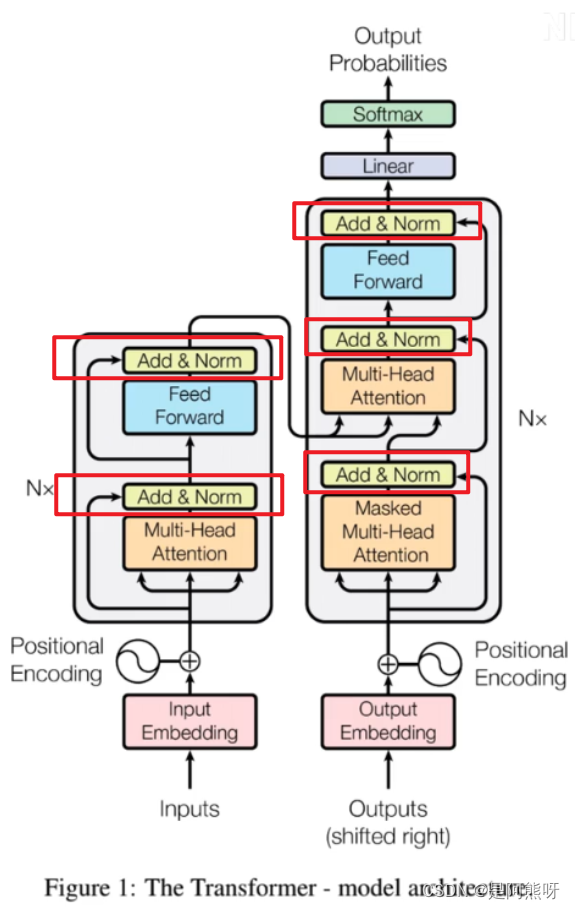
图32 Add&Norm -
Add其实就是一个残差网络,能使训练层数到达比较深的层次,缓解梯度消失
-
Norm这里采用的是LayerNorm
BatchNorm:将特征进行标准化
LayerNorm:将样本进行标准化
- 为什么不用BatchNorm?
-
- 有padding项,BatchNorm不足以代表所有样本的均值和方差
-
- batch size太小时,一个batch的样本,其均值与方差,不足以代表总体样本的均值与方差
-
- NLP场景下不适合用BatchNorm
3.11Encoder_前馈神经网络
- 前馈神经网络在Encoder和Decoder中也是都用到了
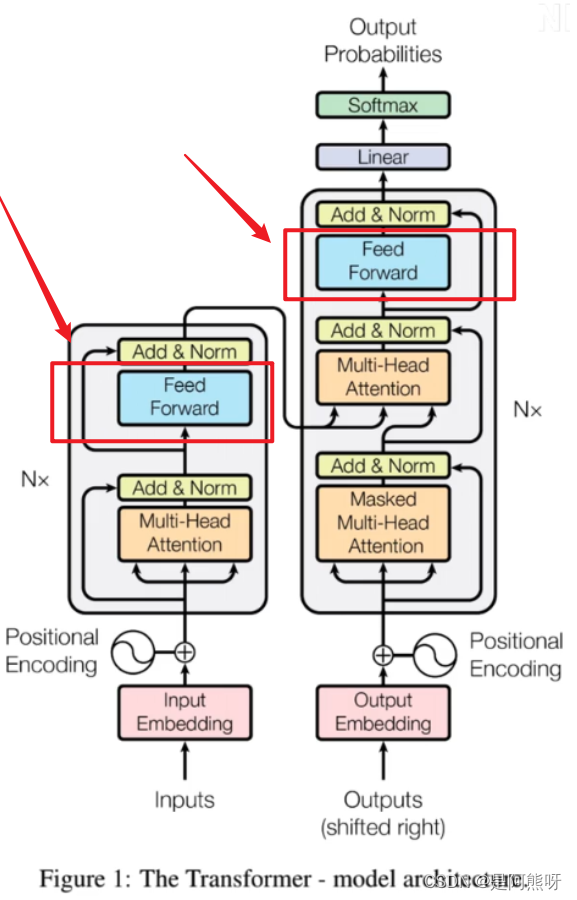
图33 前馈神经网络 - 本质上,特别简单,就是一个两层的全连接层,可以参考如下代码:
def FeedForward(dff, d_model):
return tf.keras.Sequential([
tf.keras.layers.Dense(units=dff, activation='relu'),
tf.keras.layers.Dense(d_model),
])
- 第一层设置units个数(原文为2048),用relu激活函数
- 第二层用d_model作为神经元个数
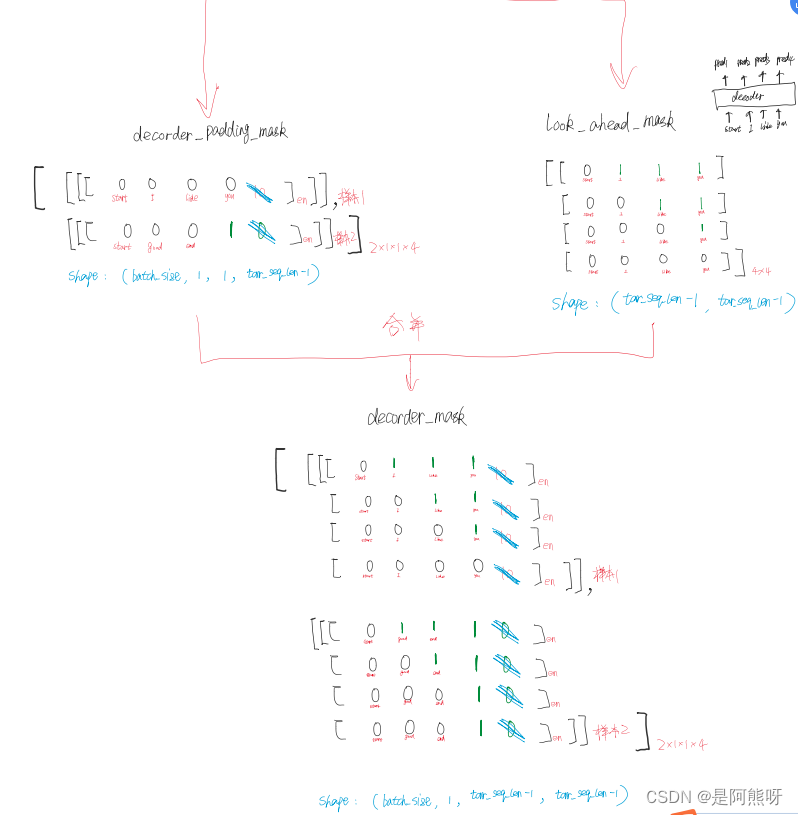
3.12Dncoder_Masked Multi-Head Attentuion
- 现在,到了Decoder部分了,其实,Decoder和Encoder的部分基本是一样的,里面部件起到的作用也是一样的
- 我们只需要关注两个注意力机制层就可以了,分别为Masked Multi-Head Attention和Encoder与Decoder间的Multi-Head Attention
- 这部分,我们先详细了解Masked Multi-Head Attention,如图34所示
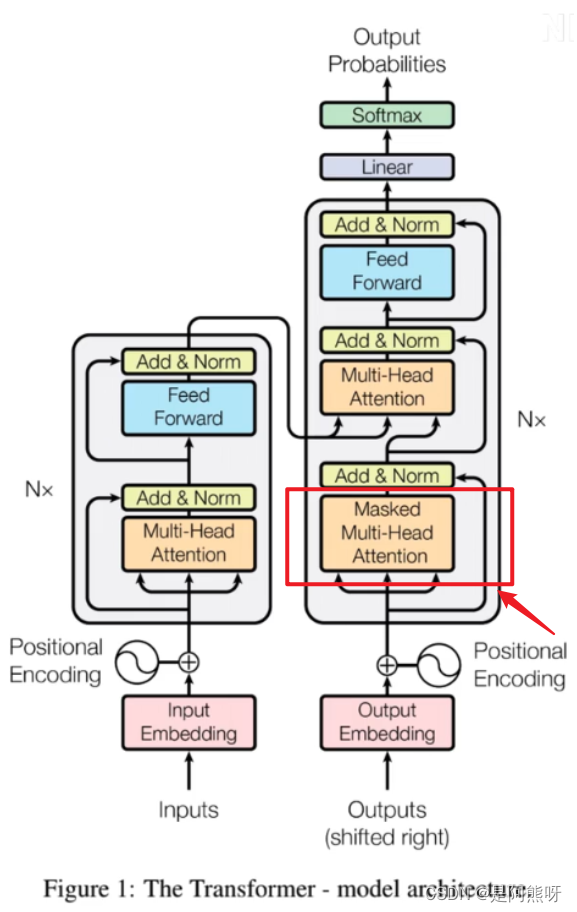
- 与Encoder的Multi-Head Attention不同的是,这里有2个Mask,分别为padding mask和seq mask(look ahead mask)
- seq mask的主要目的是保证看不到后面需要预测的值(即看不到答案)
- 操作同padding mask一样,以“我宣你”为例,在预测“宣”的时候,要把““宣”以及后面的部分进行mask。同时要把padding mask考虑进行,也就是计算出padding mask和seq mask的并集,因此可以把padding和后续值的影响去除掉。
3.13Encoder_Decoder_Multi-Head Attention
3.14输出部分
3.15模型训练_损失函数
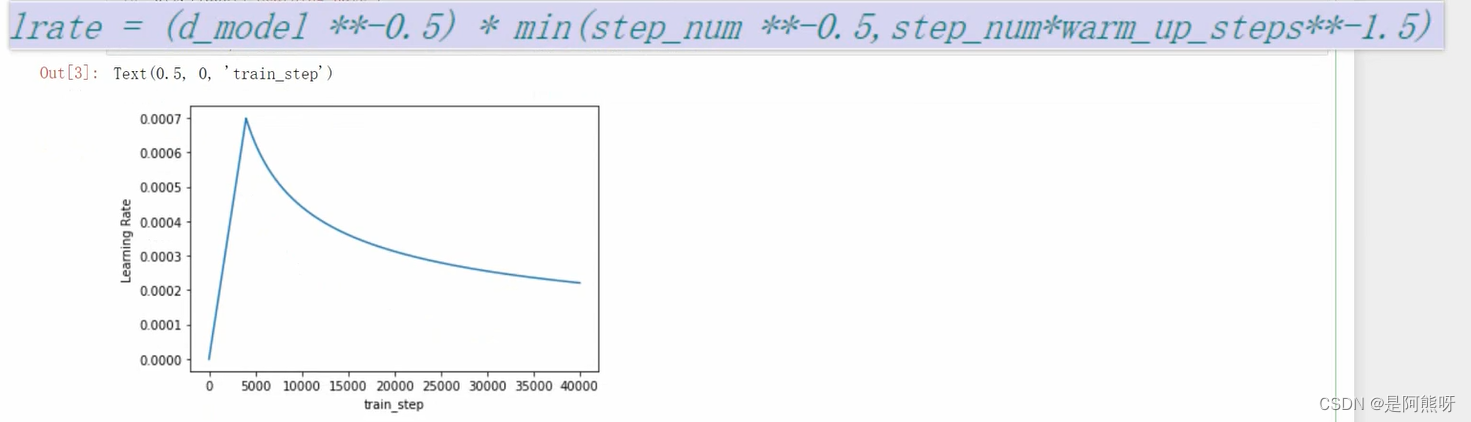
3.16模型训练_自定义学习率
- 最终生成的学习率如下图所示,也是符合我们的训练规律的(开始损失大,学习率大;损失小了后,学习率也会逐渐减小)















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









