







机器学习:机器学习是指让计算机具有像人一样的学习和思考能力的技术的总称。具体来说是从已知数据中获得规律,并利用规律对未知数据进行预测的技术。
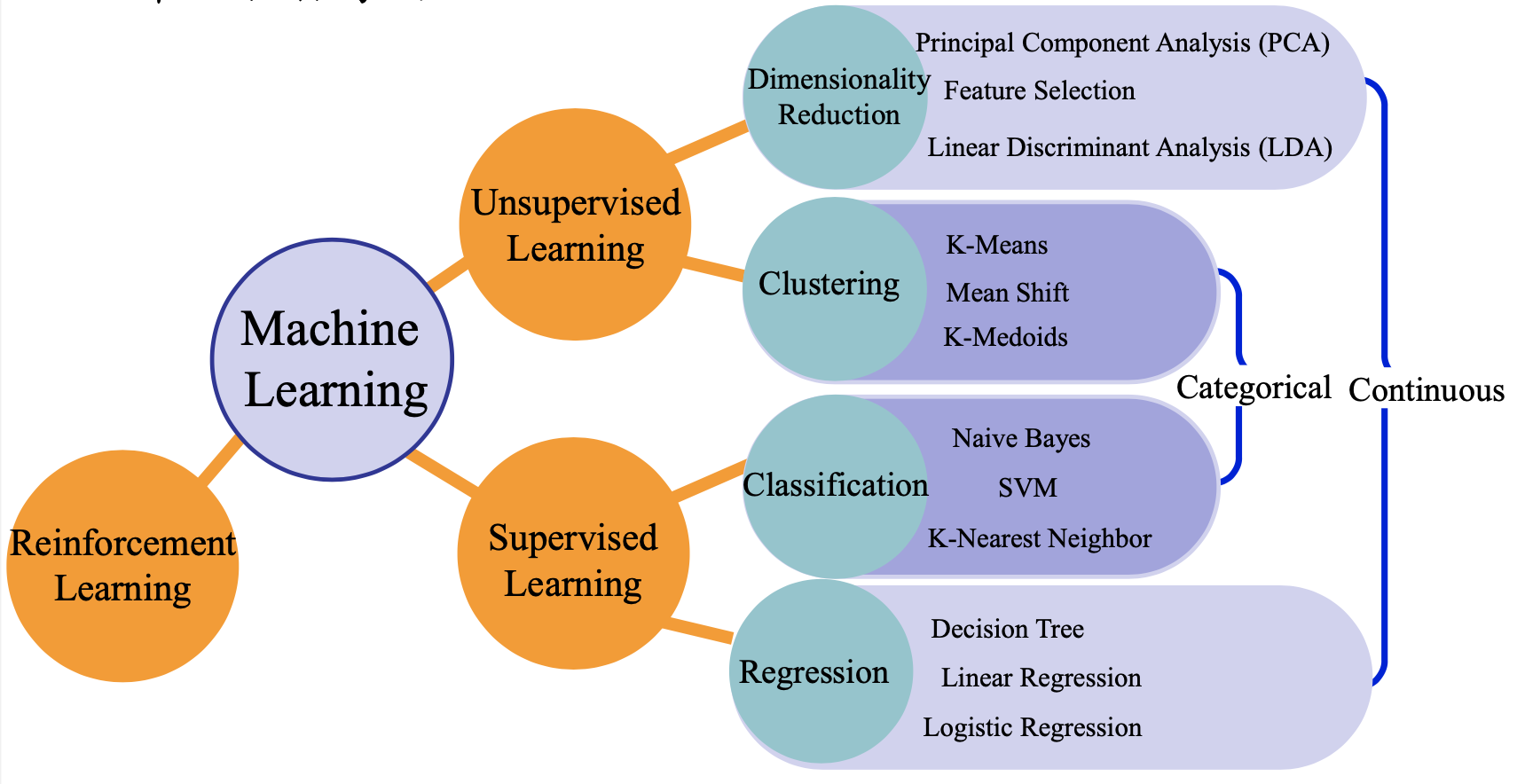
机器学习可以做如下两种分类
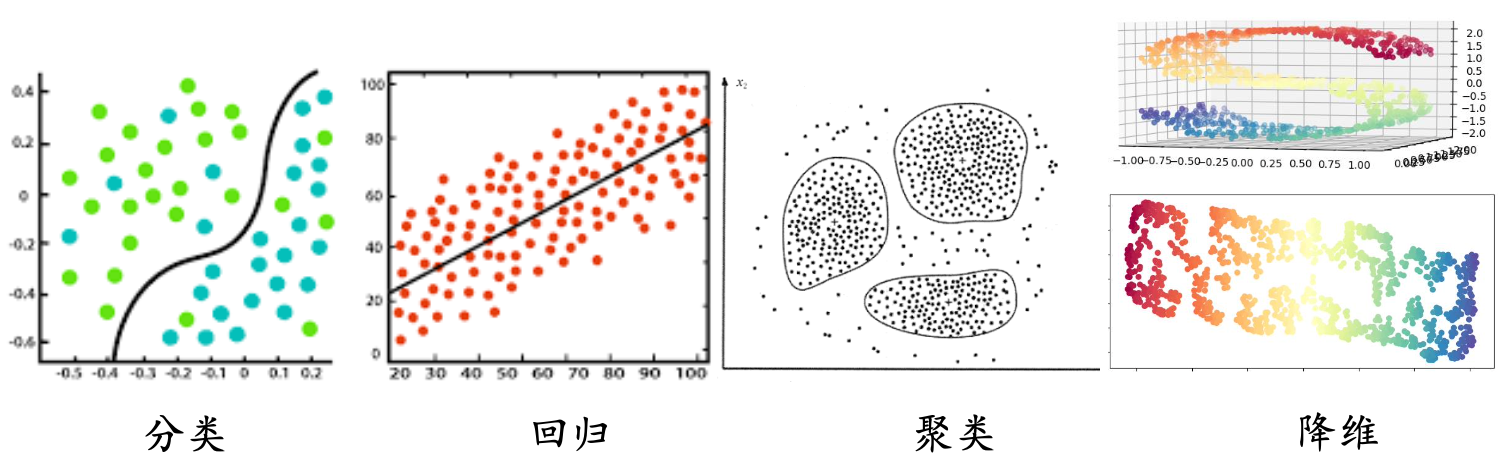
- 有监督学习:代表任务“分类”和“回归”
- 无监督学习:代表任务“聚类”和“降维”
模型评估与选择
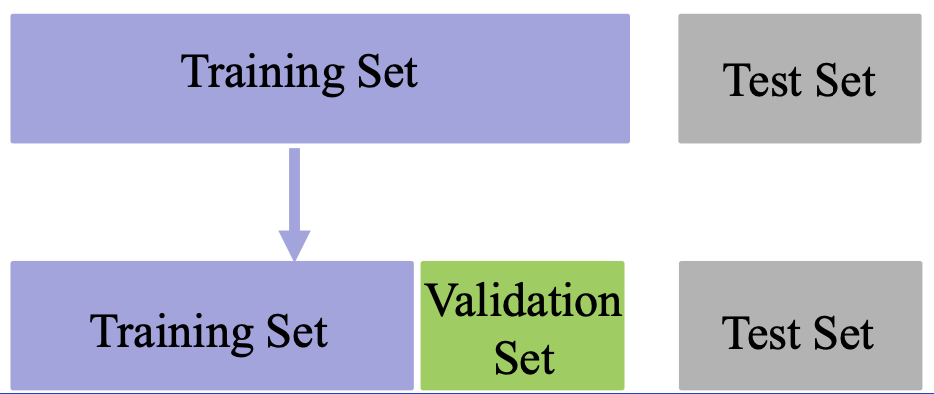
通常,我们通过实验测试来对学习器的泛化误差进行评估并进行选择。
数据集划分
误差是指算法实际预测输出与样本真实输出之间的差异。
- 模型在训练集上的误差称为“训练误差”
- 模型在总体样本上的误差称为“泛化误差”
- 模型在测试集上的误差称为“测试误差”
由于我们无法知道总体样本会,所以我们只能尽量最小化训练误差, 导致训练误差和泛化误差有可能存在明显差异。
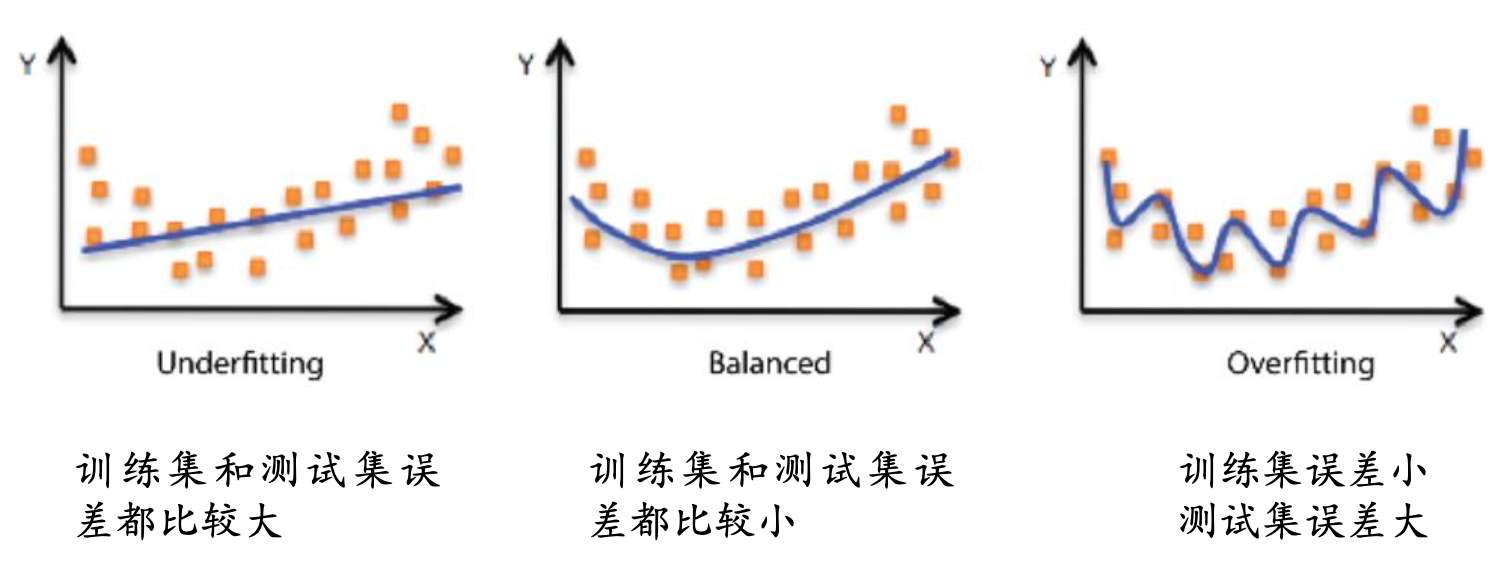
过拟合是指模型能很好地拟合训练样本,而无法很好地拟合测试样本的现象,从而导致泛化性能下降。为防止“过拟合”,可以选择减少参数、降低模型复杂度、正则化等
欠拟合是指模型还没有很好地训练出数据的一般规律,模型拟合程度不高的现象。为防止“欠拟合”,可以选择调整参数、增加迭代深度、换用更加复杂的模型等。
泛化误差分析
假设数据集上需要预测的样本为Y,特征为X,潜在模型为 ,其中
是噪声, 估计的模型为
.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 850
850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









