






 本文基于Python进行自然语言处理,对文本展开多方面分析。包括初步分析,查看单词等信息;评估文本丰富度,统计前50个单词、停用词;进行单词分析,找出特定特征词和成对词组;分析相关性,涉及字符串、句子和双连词;还进行文本间分析,如条件频率分布等。
本文基于Python进行自然语言处理,对文本展开多方面分析。包括初步分析,查看单词等信息;评估文本丰富度,统计前50个单词、停用词;进行单词分析,找出特定特征词和成对词组;分析相关性,涉及字符串、句子和双连词;还进行文本间分析,如条件频率分布等。
本文来源于Natural Language Processing with Python——Steven Bird,Ewan Klein and Edward Loper
自然语言处理(一)
1.文本初步分析
导入示例文本:
import nltk
from nltk.book import *
查看单词信息
text1.concordance("monstrous")#查询monstrous出现位置的上下文
text1.similar("monstrous")#查询出现monstrous出现时,还出现哪些词。
text2.common_contexts(["monstrous","very"])#查询同时出现monstrous,very的文章
text4.index("awaken") #第一次出现awaken的位置
text4[1788] #1788位置下的单词
text5[17645:17665]
text4.dispersion_plot(["citizens","democracy","freedom","duties","America"])#单词在文本中出现的位置
随机生成文本:
text4.generate()#随机生成文本,在Python3中不含有该模块
其他信息
len(text3) # 文本长度
sorted(set(text3)) #在文本中一共出现了多少个不同的单词, set是一个集合,借用集合元素的相斥。
[w.upper() for w in text1] # 文本中每个单词的大写形式
[word.lower() for word in text1 if word.isalpha] # 小写形式
2.文本丰富度
from __future__ import division#注意该处有两个下划线
print(len(text3) / len(set(text3))) #单词丰富度
print(text3.count("smote")) #关键词强调
print(100 * text4.count("a") / len(text4)) #单词重要度
#定义成函数
def lexical_diversity(text):
return len(text) / len(set(text))
def percentage(count, total):
return 100 * count / total
lexical_diversity(text2), percentage(text4.count("a"),len(text4))
前50个单词
fdist1=FreqDist(text1)#寻找text中单词总数
len(fdist1),len(text1)
#在python3中采用如下方法获得前50个词频,这里是频数
fdist1.plot(50,cumulative=True)
定义成函数
word = [word for (word, freq) in fdist1.most_common(50)]
frate1 = [(word,freq/len(text1)) for (word, freq) in fdist1.most_common(50)]
#生成频率分布表,list数据无法plot,需要转化为numpy数组元素
def fratefun(fdist1,lentext1):
frate =[freq/len(text1) for (word, freq) in fdist1.most_common(50)]
#列表转化为数组
global fratecum #如果在函数中修改变量,python会自动将其默认为局部变量,需要注意
fratecum = [frate[0] for i in frate]
for i in range(1,50):
fratecum[i] = fratecum[i-1]+frate[i]
fratecum=np.array(fratecum)
fratefun(fdist1,len(text1))
a =[i+1 for i in range(50)]
type(fratecum)
plt.plot(a,fratecum)
fratecum
停用词
from nltk.corpus import stopwords
stopwords.words("english")[:20]
3.单词分析
具有某些特征的词
sorted([w for w in set(text1) if w.endswith("ableness")])
# 见书本p25
展示字符长度超过15的单词
v = set(text1)
long_words = [w for w in v if len(w)> 15]
sorted(long_words)
#只出现一次的单词,前20个
fdist1.hapaxes()[:20]
展示字符长度超过7,次数超过7次的单词
fdist5 = FreqDist(text5)
long_lowrate_words = [w for w in set(text5) if len(w)> 7 and fdist5[w] > 7]
sorted(long_lowrate_words)
成对出现的词组
#text8.collocations() # 修改为以下形式,参见https://www.jianshu.com/p/b5e7f8b2dcaf
text8.collocation_list()
FreqDist是一个计数函数,用来计算每个元素出现的次数
# 下面这些函数有什么作用,自己测试以下就知道啦~~~~
fdist = FreqDist([len(w) for w in text1])
len(fdist)
fdist.keys()
fdist.items()
fdist.max()
fdist.freq(3)
4.相关性
两个字符串
"".join([name,"Python"])#连接两个字符串
"Monty Python".split()#以空格方式拆分字符串
new="Monty Python"
new.split()
两个句子的相关
sent1 = ["call","me","Ishmael","."]
sent2 = ["The","family","of","Dashwood","had"]
sent1+sent2 #句子的相加
sent1.append("Some") #添加单词
双连词
sent = ["in", "the", "beginning", "God", "created"]
for i in nltk.bigrams(sent):
print(i)
5.文本间分析
条件频率分布
from nltk.corpus import brown
cfd = nltk.ConditionalFreqDist(
(genre, word)
for genre in brown.categories()
for word in brown.words(categories = genre))
genres = [genre for genre in brown.categories()]
cfd.tabulate(conditions = genres, samples=modals)
运行结果
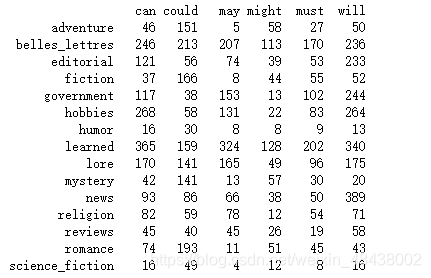
词偏移
from nltk.corpus import inaugural
cfd = nltk.ConditionalFreqDist(
(target,fileid[:4]) #在书本中出错,list名发生了错误
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['america','citizen']
if w.lower().startswith(target))
cfd.plot()
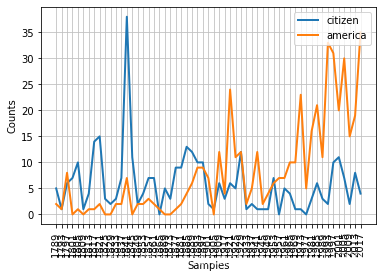
累积字长分布
from nltk.corpus import udhr
languages = ["Chickasaw","English","German_Deutsch"]
cfd = nltk.ConditionalFreqDist(
(lang,len(word))
for lang in languages
for word in udhr.words(lang + "-Latin1")
)
cfd.plot(cumulative=True)
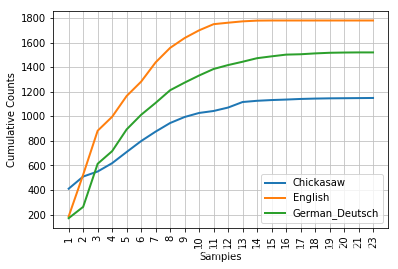
6.词典
from nltk.corpus import wordnet as wn
wn.synset("car.n.01").definition() #定义
wn.synset("car.n.01").lemma_names() #同义词
#下位词
motorcar = wn.synset("car.n.01")
motorcar.hyponyms()
#上位词
motorcar.root_hypernyms()
#反义词
wn.lemma("supply.n.02.supply").antonyms()


















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









