






Ollama 2025年12月3日发布了 v0.13.1 版本更新,本次更新重点引入了两个新的模型家族,并带来了多项功能增强、错误修复及底层改进,进一步提升了模型的部署灵活性与运行稳定性。
一、 全新模型登场
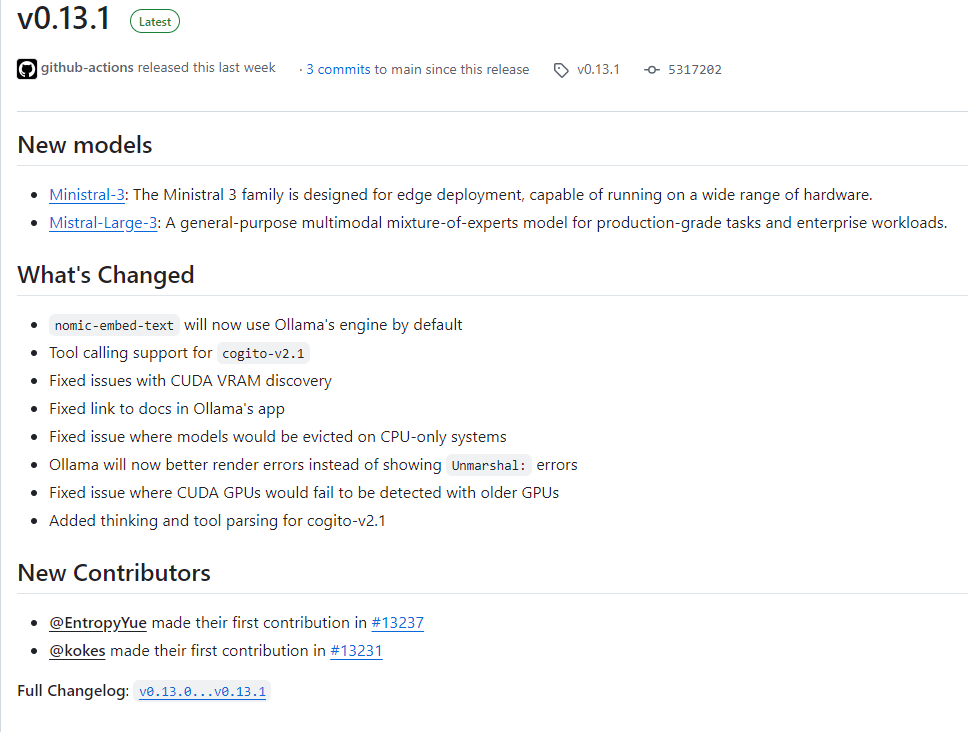
- Ministral-3 系列:此系列模型专为边缘部署设计,能够在广泛的硬件设备上高效运行,为资源受限的环境提供了强大的本地AI能力。
- Mistral-Large-3 系列:这是一个通用的多模态混合专家(MoE)模型,旨在处理生产级任务和企业级工作负载,在复杂场景下表现出色。
二、 核心功能与改进
-
引擎与工具调用:
nomic-embed-text模型现在默认使用 Ollama 自身的引擎运行。- 为
cogito-v2.1模型新增了工具调用(tool calling)支持。 - 同样为
cogito-v2.1模型添加了思维链(thinking)解析功能。
-
GPU 与系统兼容性修复:
- 修复了 CUDA VRAM 发现的相关问题。
- 解决了在仅配备 CPU 的系统上,模型可能被错误驱逐(evict)的问题。
- 修复了在某些旧款 GPU 上无法检测到 CUDA 的问题。
- 改进了对 CUDA 计算能力(CC)与目标库版本的兼容性验证。
- (Windows系统)增加了对 PATH 中潜在不兼容库文件(如
ggml-base.dll)的检测与警告。
-
错误处理与用户体验:
- Ollama 现在能够更好地呈现和渲染错误信息,而非简单地显示 “Unmarshal: errors”。
- API 客户端 (
api/client) 增强了对非 JSON 格式流式错误响应的处理能力。
-
应用与文档:
- 修复了应用内连接打开逻辑,优化了用户体验。
- 更新了应用内帮助链接,使其指向官方文档网站。
- 清理了文档中已弃用参数(如
mirostat,mirostat_eta,mirostat_tau)的说明。
三、 重要代码变更摘要
本次更新包含了 18个提交,涉及 33个文件 的更改,由 12位贡献者 共同完成。部分关键变更包括:
- API/客户端:增强了错误处理逻辑,当服务器返回非JSON格式的错误响应(如纯文本或HTML)时,能正确传递状态码和错误信息。
- 应用层:优化了 macOS 和 Windows 系统上处理自定义 URL 协议(如
ollama://)的逻辑。 - 模型支持:
ministral-3:模型支持现已集成,并添加了相应的测试。deepseek2:升级以支持运行 v3+ 版本的模型。- 模型解析器:新增了针对
cogito-v2.1模型的专用解析器,以支持其独特的工具调用和思维格式。 mistral3模型结构:在转换逻辑中增加了对 LLAMA 4 缩放因子等新 rope 参数的支持。
- 底层与发现:
- GPU 发现:改进了设备发现机制,避免库路径重叠,并加入了对 NVIDIA Jetson Jetpack 版本的更精确匹配要求。
- KV 缓存:测试现在同时覆盖使用和不使用 PermutedV 的情况。
- LLM 服务器:修正了在仅有 CPU 的系统上进行模型布局验证的逻辑,防止不必要的模型驱逐。
四、 其他调整
- 将 Vulkan 着色器文件标记为“已供应”文件。
- 更新了
.gitattributes以正确归类相关文件。 - 移除了代码检查工具中的
gocritic规则。
总结
代码地址:github.com/ollama/ollama
Ollama v0.13.1 版本是一个以模型扩展和系统稳固性为主的更新。它不仅为用户带来了适用于边缘和企业场景的新模型选择,还通过一系列关键的缺陷修复和兼容性改进,显著提升了软件在各类硬件环境下的可靠性和用户体验。特别是对 cogito 和 ministral 系列模型支持的增强,展现了 Ollama 生态持续扩展对多样化模型架构的兼容能力。


















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











