






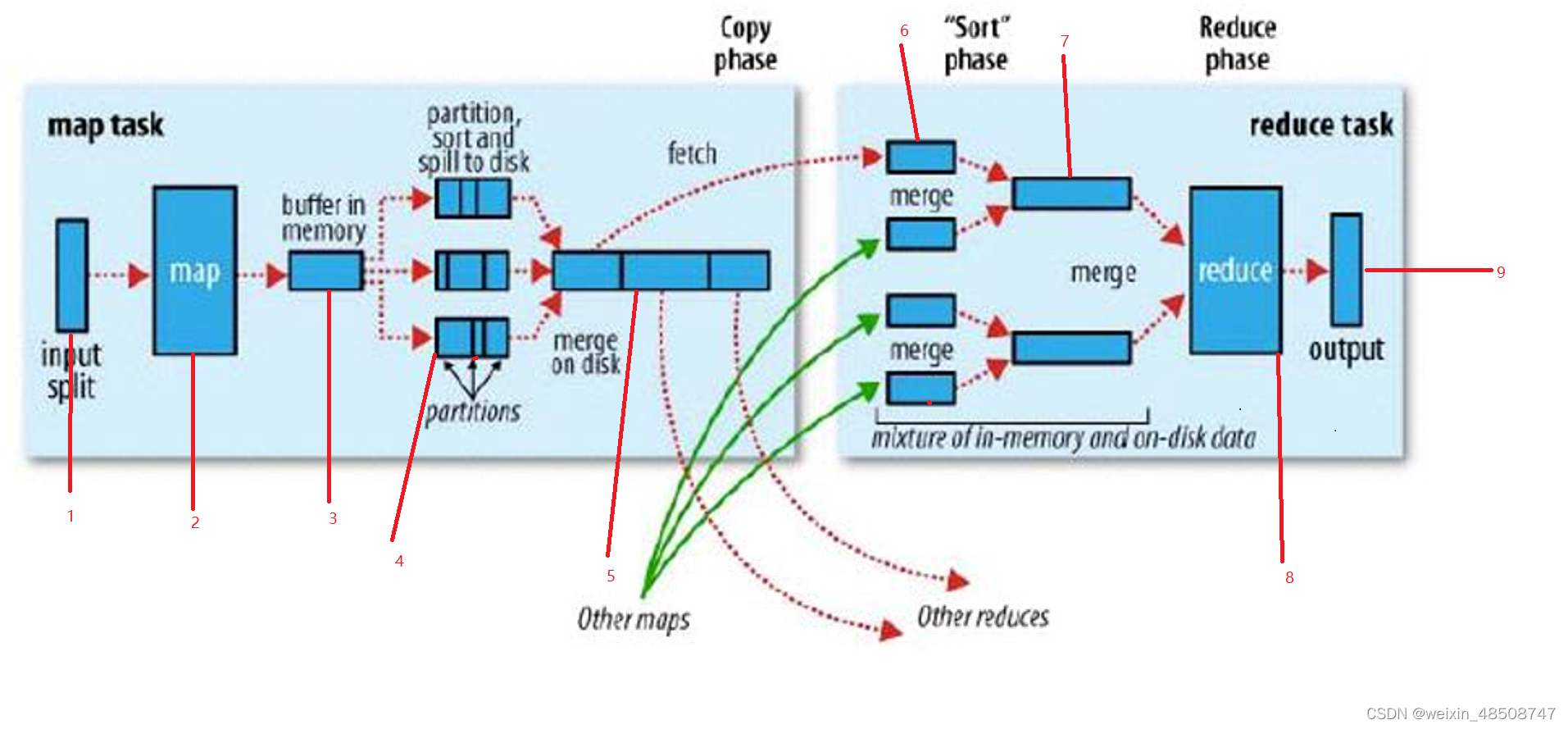
注:
这里面一共拥有着4个maptask和3个reducetask
这里的task在本质上是一个线程对象
map端:
1.进行文件进行切片,默认一个block对应一个切片(一个block大小默认为128M)一个切片是由一个maptask处理的
2.执行自定义的map端的代码逻辑
3.将数据写入到内存环形缓冲区,默认大小为100M,当写到80M时开始溢写到磁盘中
4.对数据做分区和排序,这里的分区指的是hash分区,快速排序
5.合并多个小文件,并且进行归并排序。
reduce端:
6.先到maptask所在的节点去拉取数据
7.合并多个文件
8.执行reduce端自定义的代码逻辑
9.每一个reducetask生成一个文件
shuffle过程:
从执行map端自定义代码后开始,到执行reduce端代码之前这一过程称为shuffle过程
图中表示的shuffle:3,4,5,6,7
shuffle作用:
将相同的key拉取到同一个reduce中进行处理,一个reduce中可以有多个key
hash分区决定了key进入到哪一个reduce中
key.hashcode()%reduce数量=reduce编号















 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









