






这里进行举例的是 WordCount代码
代码如下:
import scala.io.Source
object Demo24WordCount {
def main(args: Array[String]): Unit = {
//1、读取文件
val lines: List[String] = Source
.fromFile("data/words.txt") //读取文件
.getLines() //获取所有行
.toList //转换成list集合
//2、将一行中的多个单词拆分成多行
val words: List[String] = lines.flatMap((line: String) => line.split(","))
//3、按照单词分组
val groupBy: Map[String, List[String]] = words.groupBy(word => word)
//4、计算每一个单词的数量
val wordCount: Map[String, Int] = groupBy.map((kv: (String, List[String])) => {
//一个单词
val word: String = kv._1
//同一个单词构建的集合
val values: List[String] = kv._2
//获取单词的数量
val count: Int = values.length
//返回单词和数量
(word, count)
})
wordCount.foreach(println)
/**
* 简写
*
*/
//链式调用
Source
.fromFile("data/words.txt") //读取文件
.getLines() //获取所有行
.toList //转换成list
.flatMap(line => line.split(",")) //将数据转换成多行
.groupBy(word => word) //按照单词分组
.map(kv => (kv._1, kv._2.length)) //统计单词的数量
.foreach(println) //打印结果
}
}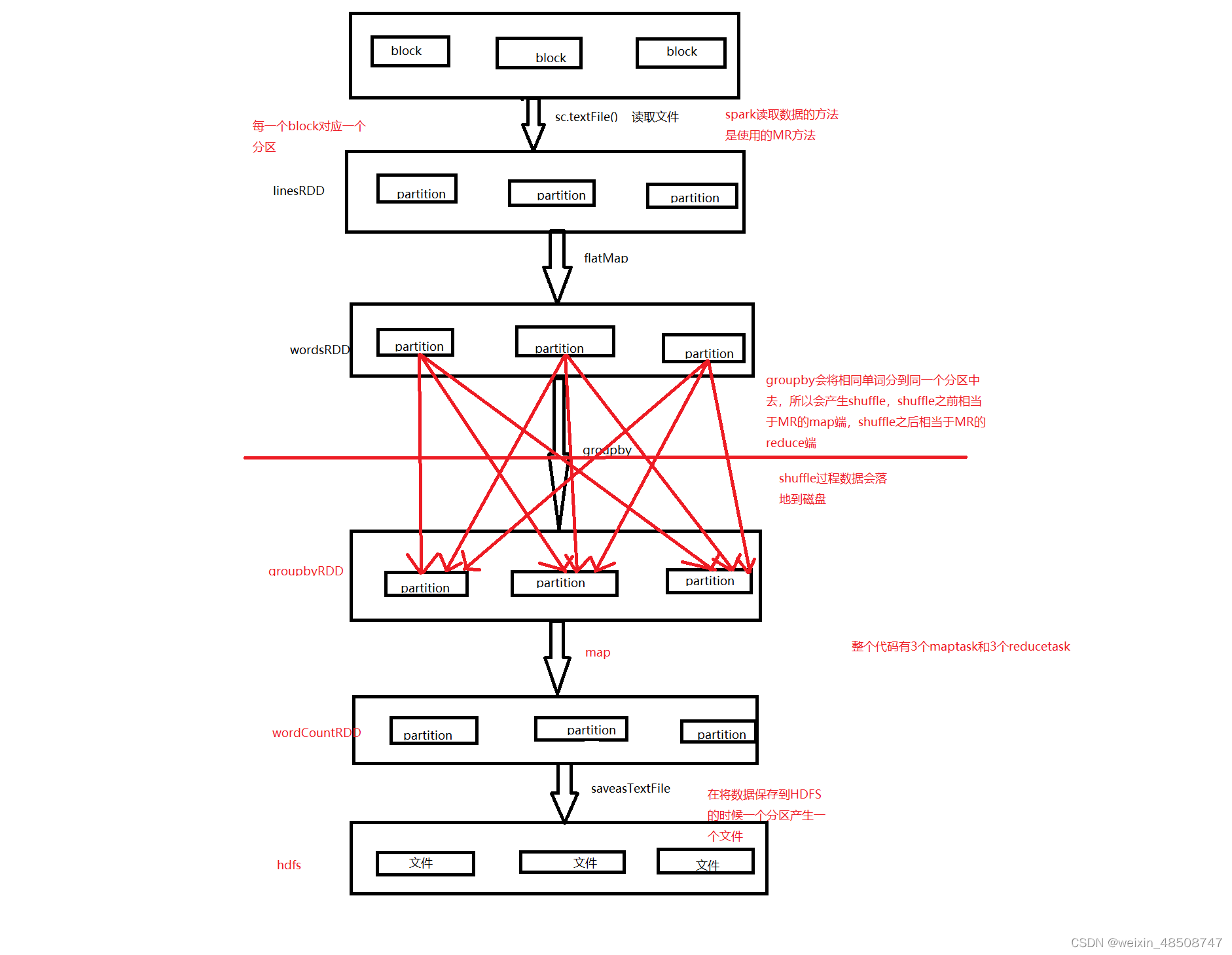
RDD:
弹性的分布式数据集
RDD是在编写代码的时候一个抽象的概念
RDD五大特性:
1.RDD是由一组分区组成,默认的一个block对应有一个分区
2.算子是作用在每一个分区上的 每一个切片对应一个task
3.RDD之间存在着一些依赖关系,有shuffle:宽依赖,没有shuffle:窄依赖
4.分区类的算子只能作用在kv格式上的RDD上(groupbykey,reducebykey,sortbykey)
5.spark为task提供了最佳的计算位置,spark会尽量将task发送到数据所在的节点上执行。















 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









