






阿里云 E-MapReduce Serverless StarRocks 版是阿里云提供的 Serverless StarRocks 全托管服务,提供高性能、全场景、极速统一的数据分析体验,具备开箱即用、弹性扩展、监控管理、慢 SQL 诊断分析等全生命周期能力。内核 100% 兼容 StarRocks,性能比传统 OLAP 引擎提升 3-5 倍,助力企业高效构建大数据应用。本篇文章重点介绍阿里云 EMR StarRocks 与开源 StarRocks 的对比与客户案例。
一、开源对比
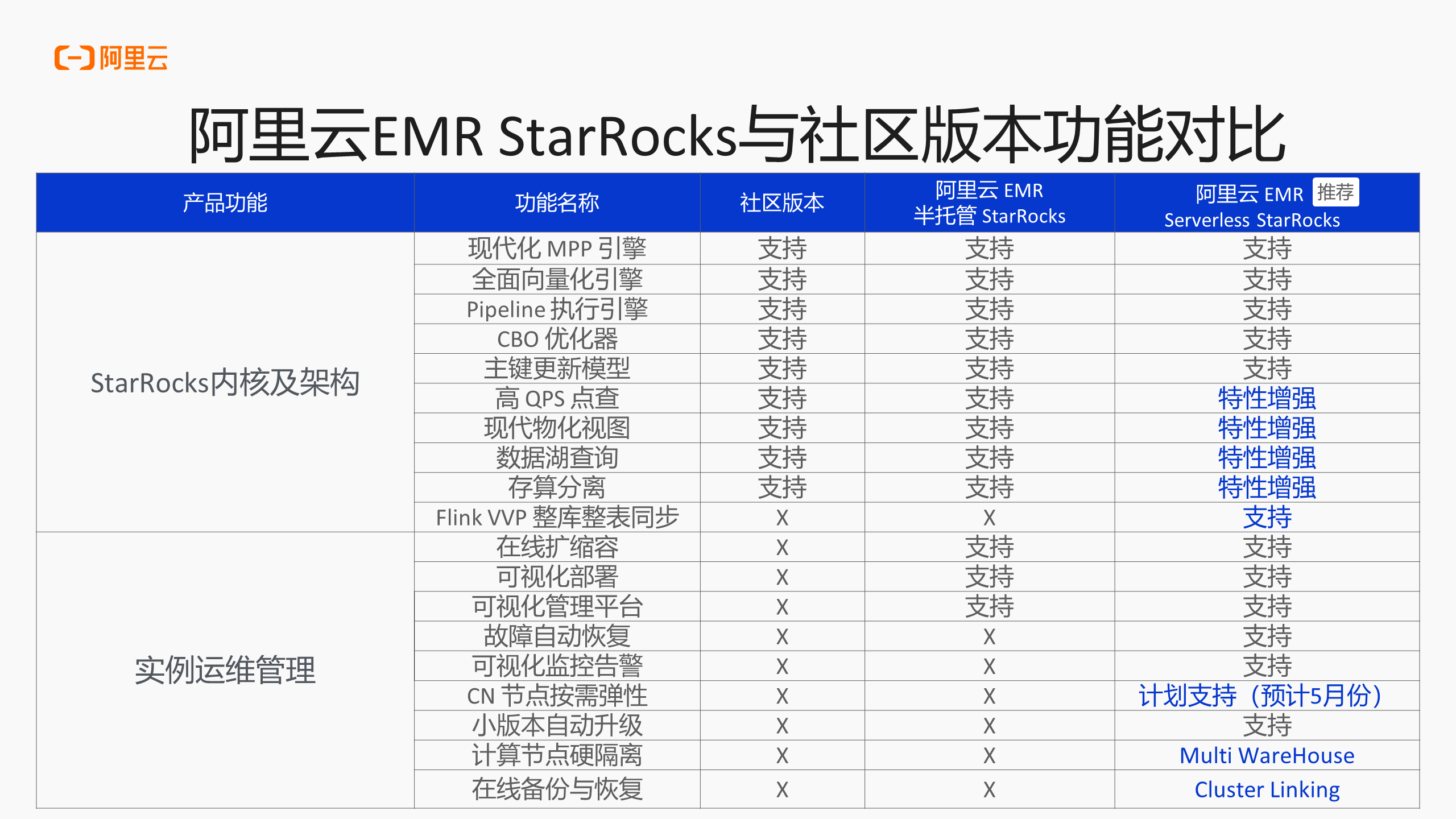
阿里云 EMR StarRocks 与社区版本功能对比分为三个部分,首先是 StarRocks 内核及架构的差异;其次是在实例运维管理能力上的差异;接下来一部分就是关于数据的运维,也就是对 StarRocks 内部的数据应该如何管理的问题。通过阿里云 EMR StarRocks Manager,大家可以做很多与数据运维或业务运维相关的事情。
内核及架构对比
首先第一部分就是关于 StarRocks 内核的对比,阿里云 EMR 团队与 StarRocks 社区已经合作很长时间了,所以基本上会贡献给社区。但是如果是周边产品的集成或新加的一些功能还是暂时会放到 EMR StarRocks 商业化的板块中进行管理。一些商业化能力经过一些时间差也会逐步合并到社区版本中。
当前内核部分,第一个不同就是高 QPS 点查,在上万级别的 QPS 场景中,EMR Serverless StarRocks 做了一系列优化,能够保证高 QPS 下的性能的稳定性。接下来是现代物化视图,对于这个部分,EMR Serverless StarRocks 添加了物化改写的能力,用户去查询物化视图的时候,如果基表更新了,但是物化视图还没有更新的情况下,就能够快速去查询到实时更新的那部分数据,而用户的业务 SQL 是不需要改写的。还有一部分就是存算分离,存算分离主要是指数据湖当中的存算分离版本,在数据湖存算分离的版本下,EMR Serverless StarRocks 对数据湖部分做了大量优化,性能提升也极为明显,约为20%~30%,极端情况下能到70%,以上也是内核目前存在的比较大的差异点。
其次是数据湖的部分,在这一部分 StarRocks 重点结合 Paimon 做了大量的改造,包括集团内部也在进行业务试点的尝试,构建弹内的 StarRocks 加 Paimon 的数据湖场景。这部分的性能差异用户也能在 StarRocks 使用到最新的版本,最新版本中性能和功能都会较为完善。还有一部分就是和阿里云实时计算合作,加入了整库整表同步的功能,用户可以通过 Flink VVP 进行试用,也可以使用 Dataworks + StarRocks 进行实时写入和批量写入,同样也能实现整库整表同步更新。这一部分的功能也是和开源版本存在差异,因为它需要借助阿里云上的其他产品的能力去实现实时的写入,例如将 MySQL 的数据实时地导入到 StarRocks 当中,实现整库迁移。对于实现这样的效果,StarRocks 也将这一部分功能进行了集成。
以上就是目前在内核部分的大部分差异,基本上和社区在内核层面保持一致,但会增加一些功能帮助用户提升查询性能,或提升并发度和优化用户体验。
实例运维管理
在实例运维层面,如上图所示,在开源版本当中没有可视化的管理平台,在 EMR StarRocks 当中则有一整套的在线扩缩容、部署、集群运维管理系统。包括监控报警功能都是现成的。用户只需要使用开了 EMR StarRocks 的账号进行登录,即开即用。在 Serverless 版本中会有故障自动恢复,以及相应的一些自动恢复机制,保障各种节点自动恢复,不需要用户过多关注底层的机器资源故障或问题。以上也是 EMR Serverless StarRocks 免运维的部分,即集群的自动恢复能力方面,不需要用户使用过多人力进行机器运维。
另外一部分差异就在于弹性方面,目前用户对于弹性的需求较为明显,无论是 StarRocks 做数据湖分析,还是在传统的 StarRocks OLAP 报表分析场景当中,用户都会经常遇到偶发的波峰,而在夜晚耗费的资源就会比较少,有了弹性的能力就可以帮助用户更好的节省计算成本,具体发布见官方发布的公告,预计在6月初推出 CN 节点的弹性。当用户的业务有明显的波峰和波谷时,用户可以结合弹性更好地节省计算成本。
接下来就是小版本的自动升级,众所周知,StarRocks 迭代较快,非常活跃。用户经常面临的问题就是如何从2.5.8升级到2.5.10,类似于以上的小版本升级。如果是自建的话,就需要自己手动做维护。在 EMR Serverless StarRocks 当中,就能够通过一键按钮,自动的进行小版本滚动升级,这也是 EMR Serverless StarRocks 较为受欢迎的点,因为 StarRocks 更新确实较为频繁。
另外还有一个在计划之中的特点就是 Multi WareHouse,开源版本目前并不会有 Multi WareHouse,但大概在7月底,平台会基于 Serverless StarRocks 3.3版本推出 Multi WareHouse 能力, 帮助用户更方便地进行业务隔离。较为典型的场景就是有时需要将导入任务和查询任务分开,让他们分别使用不同的计算资源,以免由于导入任务忽然很大,导致 SQL 无法查询,或一个 SQL 查的很大,导致导入任务无法写入,以上是用户在使用 Serverless StarRocks 集群时经常会碰到的问题。
接下来是 Cluster Linking,在进行集群迁移或备份到新的集群的场景当中可以借助 Cluster Linking 工具。目前, Cluster Linking 还只是一个工具并没有完全产品化,因为基本上已经能够满足大部分场景。
以上就是关于 EMR StarRocks 与开源版本在集群或实例方面的能力差异。
StarRocks Manager
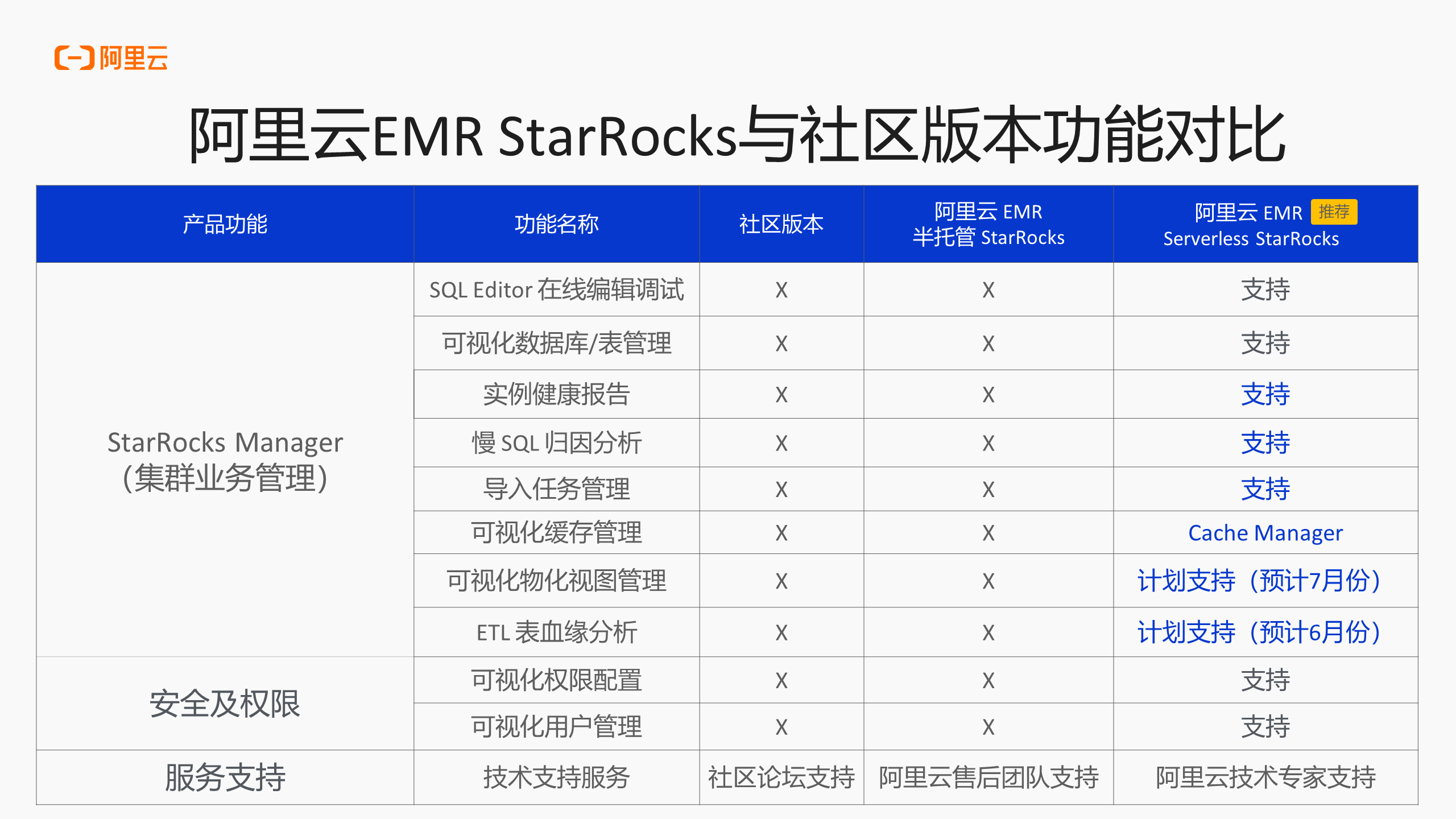
在 StarRocks Manager 中提供了很多功能,提供 SQL Editor,用户在写 SQL,或是日常进行命令行操作时都可以使用 SQL Editor 工具,只需要在页面上连接实例,就能够打开 SQL Editor 进行相应的 SQL 操作或者查询。在线 SQL Editor 的主要优势就是方便用户进行在线查询或开发调试。
此外,Manager 层还提供了可视化数据库或数据表管理的功能,可以查看数据库或数据表,包括表的分区或其他相关信息,以上是源数据可视化的查看和管理的能力。
Manager 层还提供集群的实例健康报告,用户可以直接在控制台集群上查看健康报告。健康报告当中会帮助用户统一分析 SQL、导入任务、抓取源数据等等,健康报告会显示使用较多、使用资源较大、查询较为耗时的 SQL 语句;在导入任务方面同样也会分析导入任务占用资源较多的进程;在抓取源数据方面会给出小文件分布较多的表或分区的数据的位置,以上就是平台结合整个集群实例会给予用户的健康报告内容,以帮助用户做集群治理或业务层面的数据治理。
在慢 SQL 方面,EMR Serverless StarRocks 同样也提供相应的归因分析。在用户日常使用当中,会出现某个 SQL 运行得很慢的情况,用户不知道为什么运行得很慢,Serverless StarRocks 就会提供一套慢 SQL 的可视化信息分析,用户可以看到每个 SQL 的使用情况,包括运行慢的原因,需要如何解决等。以上所提内容会在 EMR Serverless StarRocks 最新的版本当中迭代支持。
在导入任务方面,无论是实时导入还是批量导入,或是其他各种导入任务的日常管理,也是 Serverless StarRocks 的痛点,平台会提供相应导入任务的相关管理界面,用户可以实时看到有什么任务在运行、任务故障的日志信息、错因、进度信息等。
安全及权限
接下来是权限可视化方面,EMR Serverless StarRocks 提供了基础的可视化权限配置,当然用户也可以直接通过命令行进行权限管理。
目前,可视化物化管理部分、血缘分析已经在设计中,在 Serverless StarRocks 3.x之后的湖仓新范式的概念中,用户会越来越多的把许多数据处理或数据加工的任务放到 Serverless StarRocks 当中,则会面临一个问题就是血源关系是什么样的?以及倘若任务出现故障,影响故障的上下游是哪些?以上均是 StarRocks 3.x 之后的湖仓新范式的概念中用户应用到具体场景中会出现的问题,这两部分就是物化视图和血缘,预计在六到七月份做版本发布。
还有一部分是与 Cache 相关的,用户在使用 Serverless StarRocks3.x 版本之后,会进行到存算分离的架构当中,在这套架构当中用户会面临的问题是开始在哪里?有没有命中?哪些表命中了?哪些表没命中?哪些 SQL 命中了?哪些 SQL 没有命中?对于以上情况,平台都会提供 Cache 相关的一整套 Manager 能力,这套 Manager 能力主要就是解决在缓存当中会碰到的一系列问题。用户可以看到 SQL 中缓存的命中情况、命中的比例。对于数据表和数据库,用户也能够看到数据库或数据表缓存的数据量有多大,包括在健康报告当中也会给出缓存相关的分析信息,例如会给出哪些表使用较多需要进行缓存?或者哪些缓存现在是该命中的情况下没有命中,可能需要进行优化。以上内容也会在健康报告当中结合缓存的分析报告,给出用户相应的治理建议。内容对于存算分离场景下的缓存也是较为重要的,如果要把存算分离的架构用到最优,对缓存的管理就是第一步。
售后及支持
售后服务方面,如果是社区,用户则需要依赖于社区的版本支持;如果是 EMR Serverless StarRocks,就可以通过支持群或联系技术专家进行售前阶段及售后阶段的咨询,帮助用户尽快将业务落实到 Serverless StarRocks 上。如果在使用过程当中出现问题也可以寻找技术专家进行支持。
以上内容就是 EMR Serverless StarRocks 和社区版本的能力差异,也是 EMR Serverless StarRocks 产品希望能够帮助用户解决到的问题。用户在选型时可以进行综合评估,同时也能加入钉群进行反馈。
二、客户案例
以下为 EMR Serverless StarRocks 典型客户案例,可供参考。
案例一:某在线教育客户- BI自助/指标平台/多维分析/
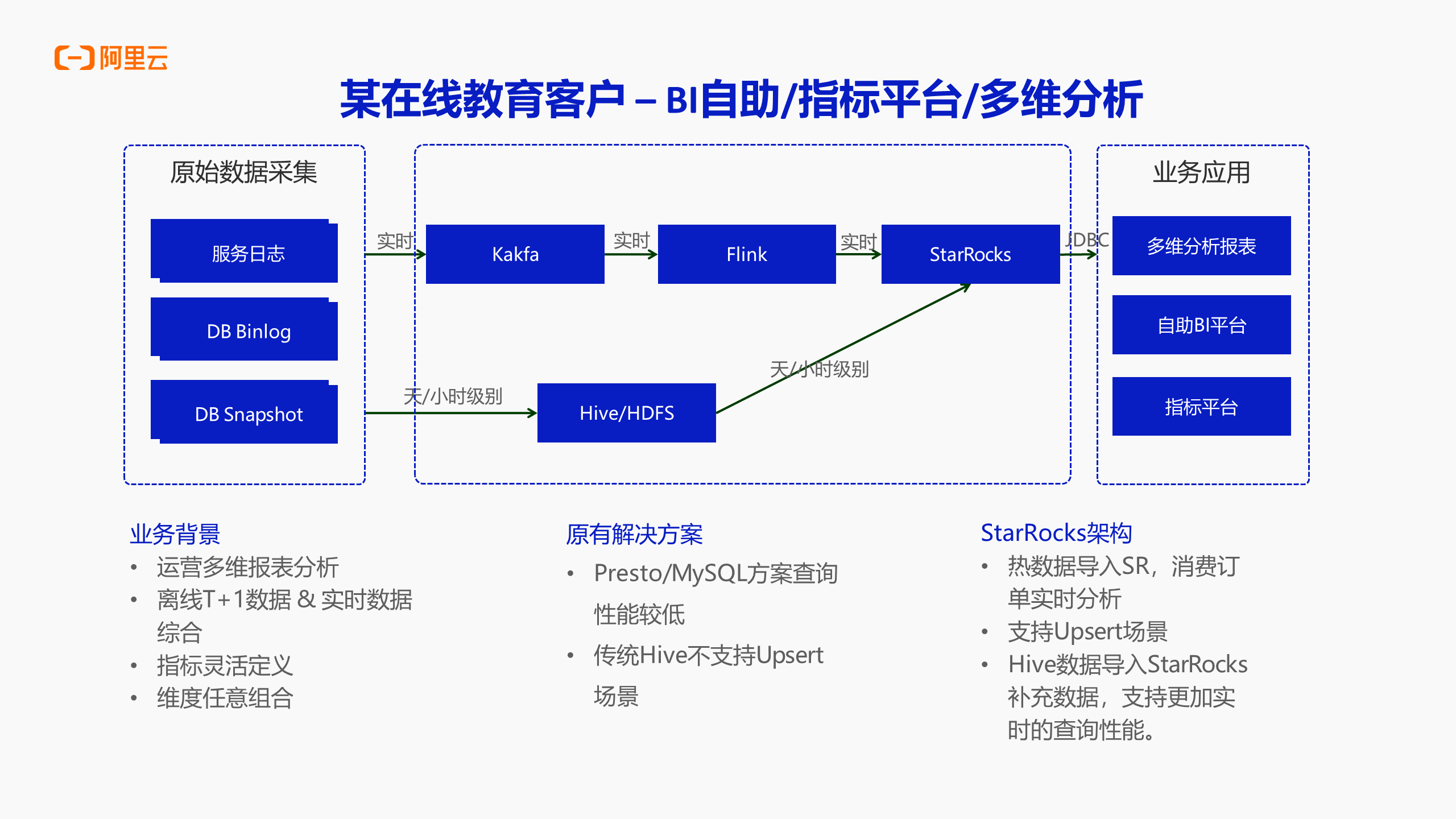
首先是某在线教育客户,致力于做传统的 BI 报表、对内的运营分析报表、指标平台等业务系统的数据。这部分数据当中有 T+1 的,也有实时写入的。该用户要求指标能够灵活定义,各个维度之间能任意组合。该用户原先使用的解决方案,有 Presto/MySQL 方案,也有较为传统的 Hive、Spark,但基本上性能较差。EMR Serverless StarRocks 和 Spark 对比,性能有几倍的提升,该用户期望有更高性能的报表分析综合平台,就选择了 EMR Serverless StarRocks 路线。
其次,EMR Serverless StarRocks 支持 upsert 场景,传统平台和 Spark 不支持 upsert 场景, 当然目前结合一些湖格式用户也能够完成,但整体的弹性性能不如直接使用 EMR Serverless StarRocks 进行查询。如上图所示,该用户的整个数据架构就是将原始的数据、Binlog、日志实时地通过Kafka、Flink 进行处理之后,实时写入到 Serverless StarRocks。以上是实时数据的链路,还有一部分数据量较大的数据使用离线的方式,通过小时级使用 Hive 加工之后,然后通过 BulkLoad 的形式上传到 Serverless StarRocks 当中,完成之后就在 Serverless StarRocks 内部形成了一整套的对业务相关的表的集合。基于这个集合就可以做上游的多维报表分析、自助 BI 报表平台或指标平台。以上功能基于 Serverless StarRocks 都会对该用户提供较大的性能提升,此外,相应的技术栈也会相对简单。在 OLAP 场景下将所有数据都交给 Serverless StarRocks 即可,以上就是某在线教育客户的场景,其实也是 Serverless StarRocks 最擅长的场景,即传统的 OLAP 报表分析。
案例二:某在线教育客户-实时事件分析
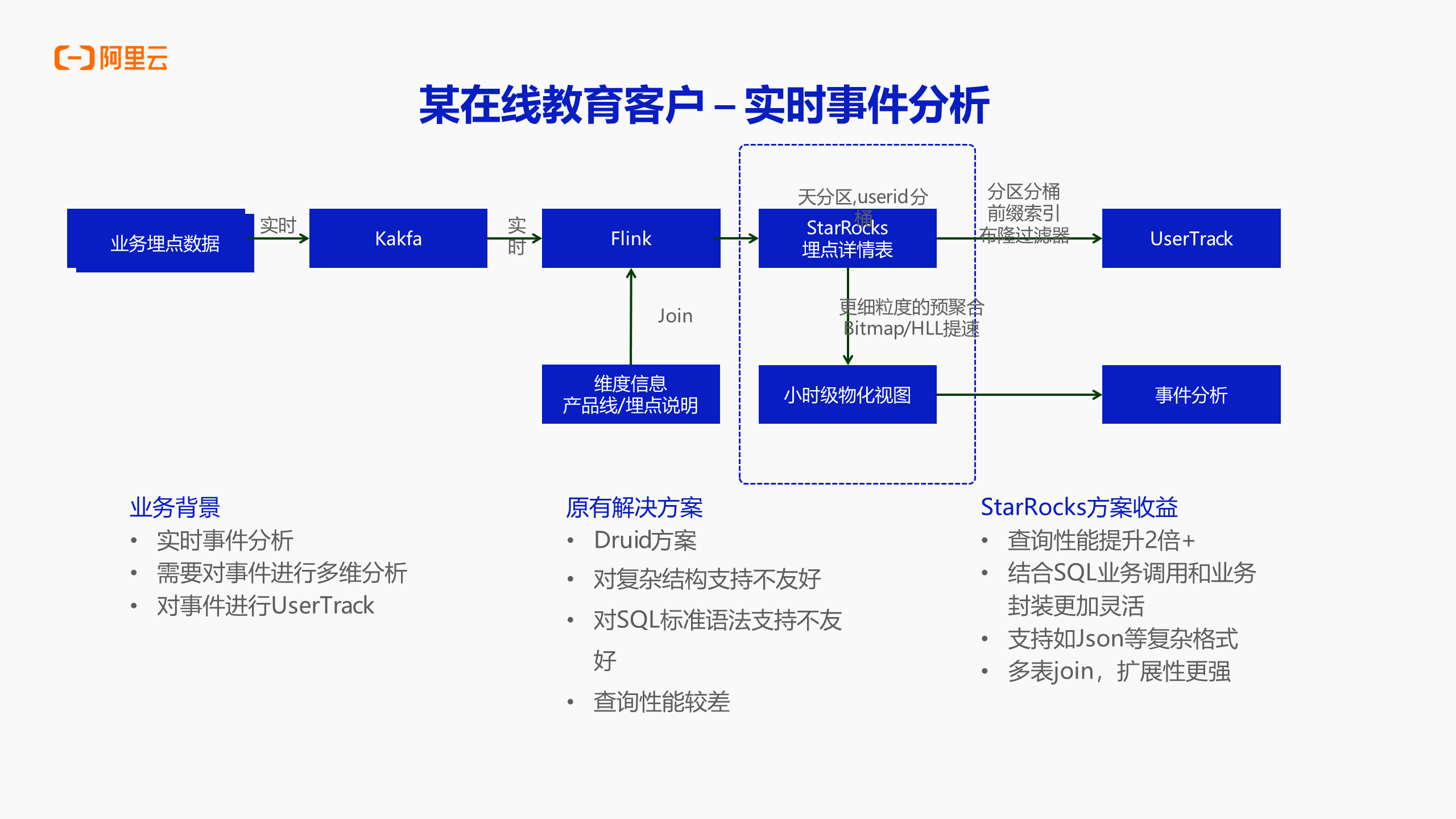
该案例的在线教育客户主要进行实时事件分析,即实时地将一些数据通过 Flink 直接写到 Serverless StarRocks 做事件分析。对于实时事件分析的场景,在之前用户会使用 Druid 方案当中一些相对较为复杂的结构,查询性能和 SQL 语法支持方面相对于 Serverless StarRocks 来说较弱。所以最后用户整体上使用了 Serverless StarRocks,用 Serverless StarRocks 替代了实时写入、实时查询、简单的域聚合等,在将所有东西嵌入到 Serverless StarRocks 之后,整体的查询性能有两倍以上的提升,SQL 的查询语法也是 Serverless StarRocks 所支持的,所以他的 SQL 灵活度也较高,可以随意使用一些组合,对用户实时写入、实时进行事件分析的场景较为适用。在日常生活当中能够见到的一些大屏也是实时写入的案例,同样使用的也是 Flink 加 Serverless StarRocks 的组合,对于类似的场景,使用这套组合也是极其稳定和保险的,同时也是 Serverless StarRocks 所擅长的核心场景。
案例三:某金融公司-OLAP 组件统一提速
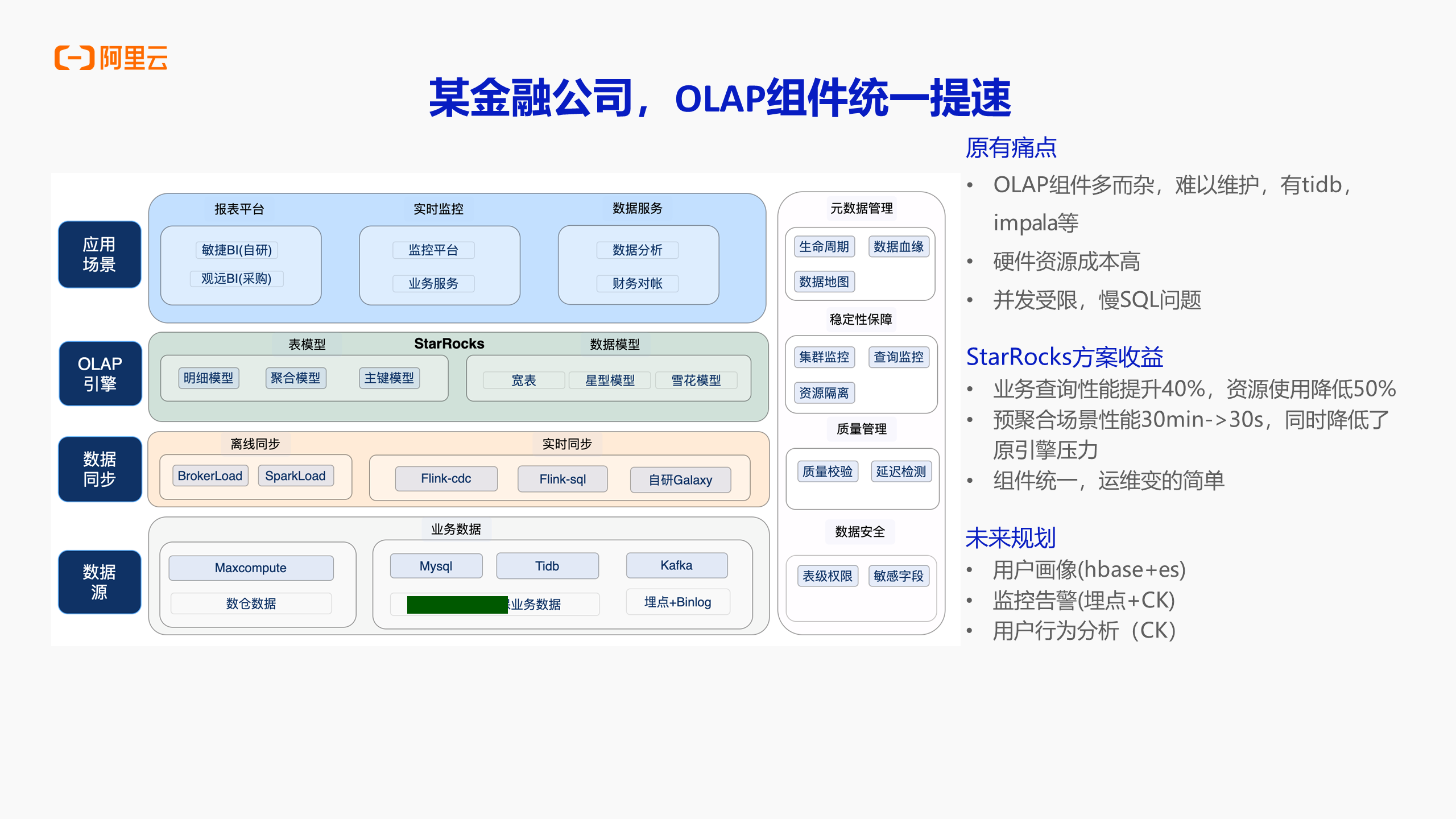
本案例中该用户的初衷是对 OLAP 组件统一提速,这也和 EMR Serverless StarRocks 所宣传的概念一致。该客户是一个金融公司,对于金融公司来说可能会有较多的 OLAP 组件,就会存在相应隐患。较多的 OLAP 组件对于公司来说第一个缺点是运维较为复杂,第二个缺点就是存在大量实例,会消耗极大一部分的硬件资源成本,在某些场景当中并发会受限,慢 SQL 运行的也会比较慢,以上内容都是该用户所面临的痛点,总结起来就是组件过多难以维护,需要部署的集群过多成本较高。
最后该公司决定将整个 OLAP 相关的明细或数据等所有业务数据都关联到 EMR Serverless StarRocks 当中,通过 Serverless StarRocks 做统一的 OLAP 组件,在此操作之下对该用户的业务性能查询提升也是较为明显的,整体提升40%左右,资源使用率降低达到50%,主要在于 Tidb 方面节省的成本。在进行简单的数据处理加工时,进行预聚合的时间原来需要三十分钟,现在只需要三十秒,所达到的提升有原来的几十倍。所以对该用户来说,性能也提升了,成本也降低了,原来的预聚合场景的性能提升也非常快,所以消耗的资源也就变少了。
此案例也有越来越多的客户在选型时进行参考,尤其是在选择新业务的时候,基本上就会选择 Serverless StarRocks。对于用户来说,节省了成本,在后期的技术当中也能做得更为统一。本案例中的客户还希望实现对用户行为进行分析、监控、报警、用户画像的功能,该用户也就是期望所有 OLAP 相关的能力都可以由 Serverless StarRocks 统一管理和维护。
案例四:某游戏公司-广告投放
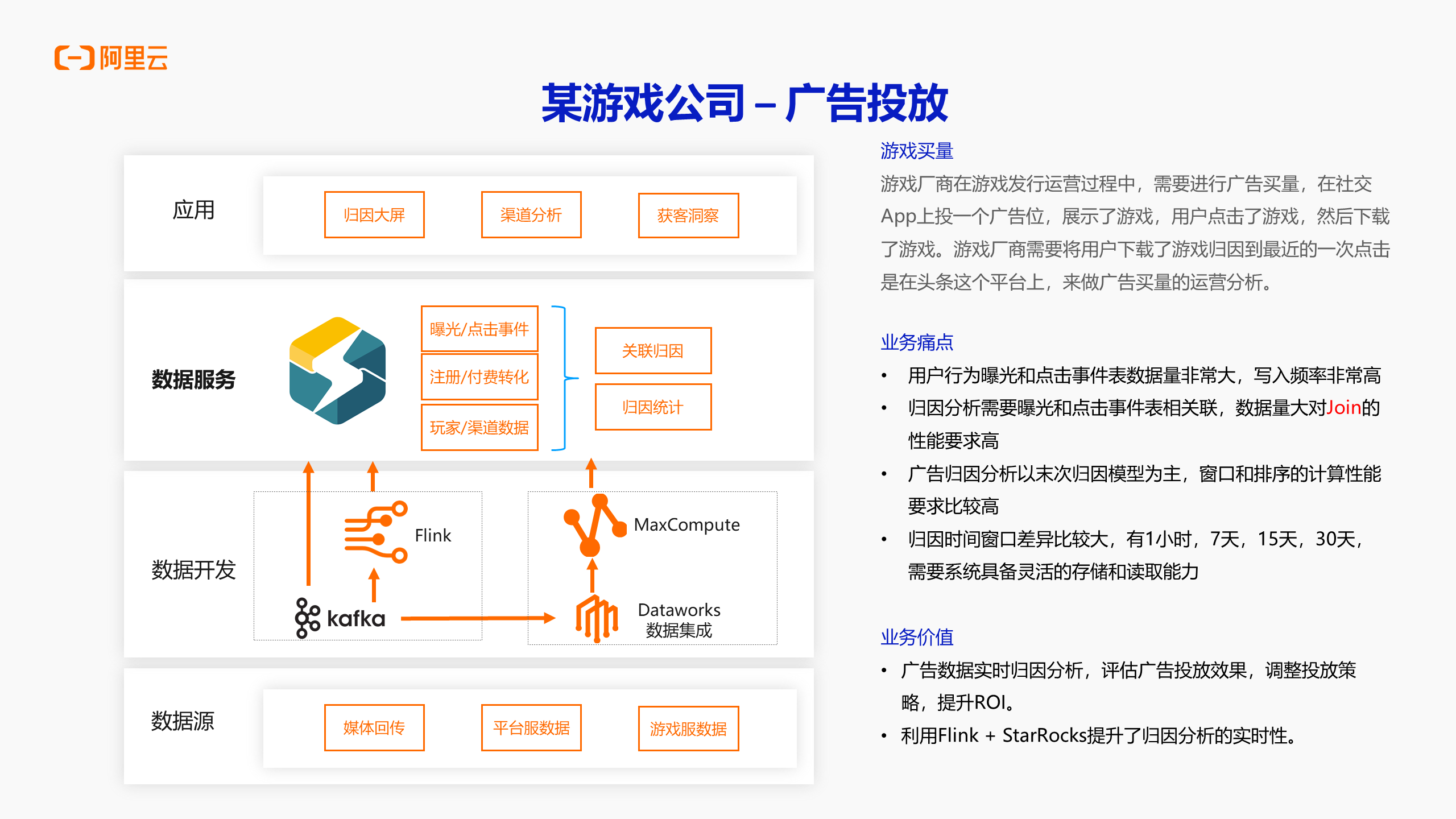
该用户是一个偏具体的场景,从技术角度来看,有两个数据量较大的表,数据写入频率也较高。在需要多表、专业的性能要求较高、写入的性能要求较高的场景下,就比较适用于 Serverless StarRocks,对用户来说,将这部分数据切到了 Serverless StarRocks,提升了整个数据链路的实时性,提升了整体的查询性能,业务使用查询性能提升也较为明显,成本也相对较低。
以上就是 EMR Serverless StarRocks 部分案例场景。
目前也存在一种现象,越来越多的用户会直接将相应的数据放到 Serverless StarRocks 进行建仓,进行存算分离的用户也越来越多,或使用 Serverless StarRocks 去构建一整套的小型数仓场景,即直接使用湖仓新范式直接去落地。
产品导航
-
EMR Serverless StarRocks 版官网:https://www.aliyun.com/product/bigdata/starrocks
-
产品文档:https://help.aliyun.com/zh/emr/emr-serverless-starrocks/
EMR Serverless StarRocks钉钉交流群(群号:24010016636)















 1338
1338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









