









一.概念
模型选择是机器学习中的重要环节,它涉及到从各种统计,机器学习或深度学习模型中选取最佳模型的过程。这涉及到许多关键概念,包括偏差与方差,过拟合与欠拟合,训练误差和泛化误差,交叉验证,正则化,以及不同的模型选择标准。
1.1欠拟合与过拟合
欠拟合和过拟合是机器学习中经常遇到的两个问题,它们都是模型的训练结果不理想导致的。
1.1.1欠拟合
指模型无法学习到数据的有效特征,无法很好地拟合训练数据集。
这种情况通常发生在模型的复杂度较低,或者训练数据集过小的情况下。欠拟合的表现是模型在训练集和测试集上都表现不佳,误差较高,无法准确预测新数据。解决欠拟合的方法一般是增加模型的复杂度,如增加模型的层数、增加神经元数量、引入更多的特征等。
1.1.2过拟合
指模型过于复杂,过分关注训练数据集中的噪声或随机误差,导致在训练数据集上表现很好,但在测试数据集上表现不佳,无法泛化到新的数据。(相当于只记住了训练集的内容)
过拟合的表现是模型在训练集上表现很好,但在测试集上误差很大,可能会出现过度拟合训练集的现象,如拟合训练集中的噪声数据。解决过拟合的方法一般是增加训练数据集的大小,或者使用正则化等技术限制模型的复杂度,如L1正则化、L2正则化、Dropout等。
1.1.3示例
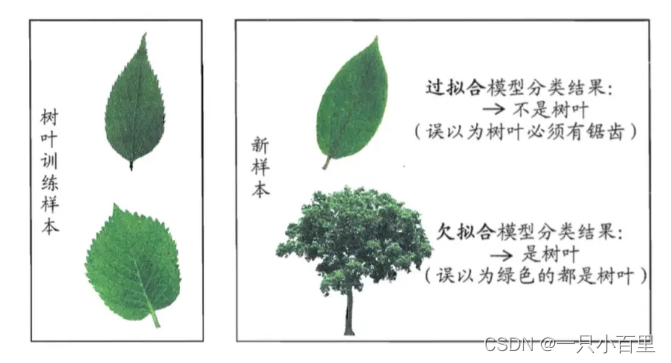
1.2 训练误差与泛化误差
训练误差和泛化误差是机器学习中常用的两个误差指标,用于衡量模型在训练集和测试集上的性能表现。在模型选择和优化中,我们需要平衡训练误差和泛化误差,以获得更好的模型性能。
1.2.1训练误差
训练误差(Training Error):是模型在训练集上的误差,也称为经验误差。它是指模型在训练数据集上的预测结果与实际结果之间的差异。训练误差越小,说明模型在训练集上的表现越好,能够更准确地预测训练集中的数据。
1.2.2泛化误差
泛化误差(Generalization Error):是模型在测试集上的误差,也称为测试误差。它是指模型对于新数据的预测能力,即模型在未见过的数据集上的表现。泛化误差越小,说明模型在新数据上的表现越好,能够更准确地预测未知数据。
1.2.3总结
一个好的模型应该在训练集和测试集上都能够表现良好,即训练误差和泛化误差都要尽可能地小。但是实际上,当模型过于复杂时,可能会出现在训练集上表现很好,但在测试集上表现不佳的情况,即过拟合问题。解决过拟合问题的方法包括增加训练数据集的大小、使用正则化等技术限制模型的复杂度。
1.2.4与偏差和方差的区别和联系
训练误差和泛化误差与偏差和方差是相关概念,但并不完全相同。
训练误差和泛化误差是指模型在训练集和测试集上的表现,分别用于衡量模型的拟合能力和泛化能力。训练误差主要反映了模型对训练数据的拟合程度,泛化误差则反映了模型对未知数据的预测能力。我们希望模型能够在训练集和测试集上都表现良好,即训练误差和泛化误差都要尽可能小。
偏差和方差是指模型的预测结果与真实结果之间的差异,用于描述模型的复杂度和拟合能力。偏差度量模型的拟合能力,即模型对真实关系的逼近程度;方差度量模型的稳定性,即模型对数据中噪声的敏感程度。过高的偏差意味着模型欠拟合,过高的方差意味着模型过拟合。我们希望找到一个偏差和方差都适中的模型,以达到最佳的预测效果。
在机器学习中,偏差和方差与训练误差和泛化误差的关系密切。偏差较高的模型通常在训练集和测试集上都表现不佳,即训练误差和泛化误差都较高;方差较高的模型通常在训练集上表现较好,但在测试集上表现不佳,即训练误差较低,但泛化误差较高。因此,我们需要在偏差和方差之间寻找平衡,以获得最佳的模型性能。
1.3验证数据集和测试数据集
1.3.1验证数据集
验证数据集(Validation Set):在模型训练过程中,我们通常需要对模型进行调参,即调整模型的超参数以达到最佳的性能。训练集用于训练模型,验证集用于评估模型的性能表现和调整超参数。验证数据集通常是从训练数据集中划分出来的,大小通常为训练数据集的10%~30%。
1.3.2测试数据集
在训练结束后,我们需要对模型进行最终的评估和验证,以评估模型的泛化能力。训练集用于训练模型,验证集用于调整超参数,测试集用于最终的评估和验证。测试数据集通常是从原始数据集中划分出来的,大小通常为原始数据集的10%~30%。

1.4交叉验证
交叉验证是一种评估模型性能和进行模型选择的常用方法。它将数据集划分为k个子集,然后通过将模型在k-1个子集上进行训练,并在剩余的子集上进行测试,来估计模型的性能。这个过程重复k次,每次使用不同的子集进行测试。然后,将这k次测试的结果取平均,以得到更稳定、可靠的模型性能估计。
1.5正则化
正则化是一种用于防止过拟合的技术,它通过在模型的损失函数中添加一个惩罚项来限制模型的复杂度。
正则化的基本思想是在优化模型的损失函数时,除了最小化训练误差之外,还要最小化正则项,以平衡模型的拟合能力和泛化能力。正则化的一般形式为L1正则化和L2正则化。
-
L1正则化(L1 Regularization):也称为Lasso正则化,它通过在损失函数中添加L1范数的正则项,来限制模型系数的大小,从而使得某些参数变为0,达到特征选择的目的。L1正则化可以帮助我们提取重要的特征,减少特征数量,避免过拟合。
-
L2正则化(L2 Regularization):也称为Ridge正则化,它通过在损失函数中添加L2范数的正则项,来限制模型系数的平方和,从而使得模型的参数值更加平滑,避免过拟合。L2正则化可以帮助我们缓解特征之间的共线性问题,提高模型的泛化能力。
二.模型选择
模型选择的目标是在给定的数据集上找到一个性能最好的模型,同时避免过度拟合。在机器学习中,我们通常在评估几个候选模型后选择最终的模型。 这个过程叫做模型选择。
2.1模型复杂度对欠拟合和过拟合的影响
模型复杂度对模型的性能和泛化能力有很大的影响。如果模型过于简单,则可能无法对数据进行很好的拟合,出现欠拟合问题;如果模型过于复杂,则可能对训练数据过度拟合,出现过拟合问题。因此,我们需要在模型复杂度和模型泛化能力之间寻找平衡点,以获得最佳的模型性能。
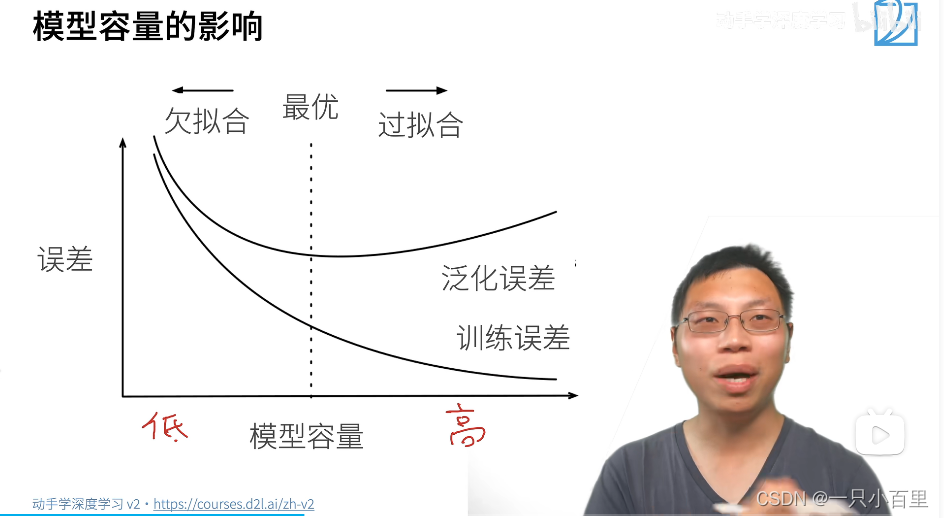
在实际应用中,我们通常使用交叉验证等方法来评估模型的性能和泛化能力,并选择最佳的模型复杂度。对于某些特定的应用场景,例如处理小规模数据集或对模型复杂度要求较高的场景,我们可能需要使用较简单的模型来避免过拟合问题。

2.2示例——多项式回归
实际操作和代码见链接
4.4. 模型选择、欠拟合和过拟合 — 动手学深度学习 2.0.0 documentation
2.3小结
-
欠拟合是指模型无法继续减少训练误差。过拟合是指训练误差远小于验证误差。
-
由于不能基于训练误差来估计泛化误差,因此简单地最小化训练误差并不一定意味着泛化误差的减小。机器学习模型需要注意防止过拟合,即防止泛化误差过大。
-
验证集可以用于模型选择,但不能过于随意地使用它。
-
我们应该选择一个复杂度适当的模型,避免使用数量不足的训练样本。















 964
964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











