






游戏中的匹配问题
背景
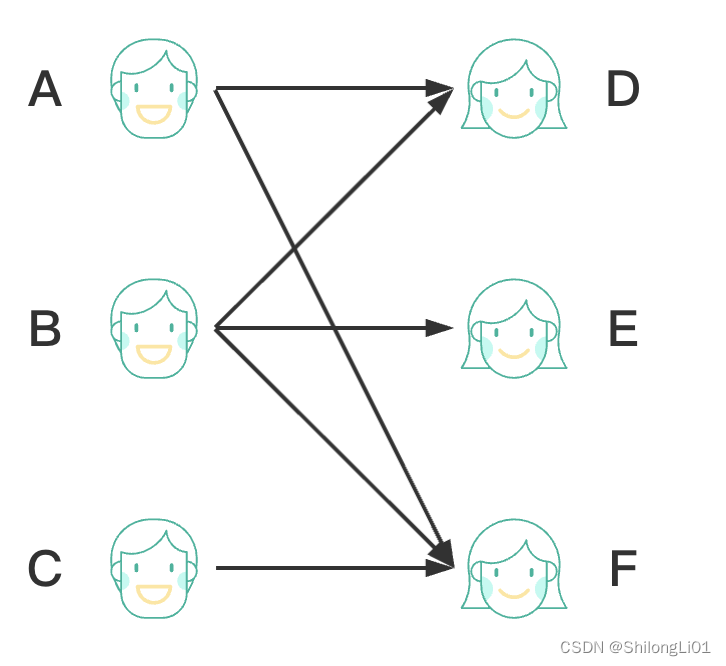
在之前的游戏组队业务中,产品提了个需求,要进行玩家匹配,每个玩家有自己的区服段位性别等信息,并且还有组队要求。例如一男玩家只想找性别女的,qq区的,分段是最强王者的,一女玩家只想找男玩家,微信区的,分段是星耀的,还有的玩家想找同性别的,等等需求不同的玩家构成了一个匹配集合,我们需要解决的就是如何把符合需求的玩家尽可能的匹配到一起。
案例引述
这是一个相亲网站,有n个男孩和m个女孩,每个男孩👦选择若干个女孩作为可选择的目标,然后每个👧选择若干个男孩作为可选择的目标,注意⚠️,男孩不能选男孩,女孩不能选女孩,如何每次在这一批男孩女孩中匹配最多对数的情侣🧑🤝🧑。
二分图最大匹配
二分图
首先对上面的问题我们可以抽象一下,每个人作为一个点,如果有两个人互相喜爱,那么从男士向女士建立一条有向边,代表此男士可以选择此女士,女士也接受该选择。
结果如下:
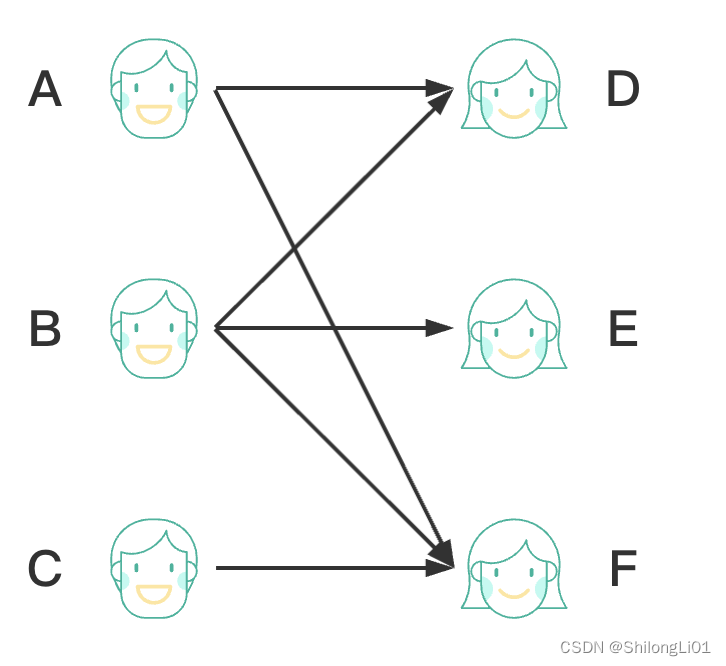
我们称这样的图为二分图, 设G=(V,E)是一个无向图(两条有向边),如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
简而言之,就是顶点集V可分割为两个互不相交的子集,并且图中每条边依附的两个顶点都分属于这两个互不相交的子集,两个子集内的顶点不相邻。在我们的例子中就是男孩和男孩之间没有边是一个不相交的子集,女孩和女孩之间没有边是一个不相交的子集,这样的图就叫二分图。
图的存储
我们如何在计算机中存储和表示这样的图呢。
邻接矩阵
| D | E | F | |
|---|---|---|---|
| A | 1 | 0 | 1 |
| B | 1 | 1 | 1 |
| C | 0 | 0 | 1 |
矩阵的第i行第j列为1时,代表从i行所在的节点到j列所在的节点有一条单向边,为0,代表没有边。优点,简单易懂,缺点存储空间浪费。
邻接表
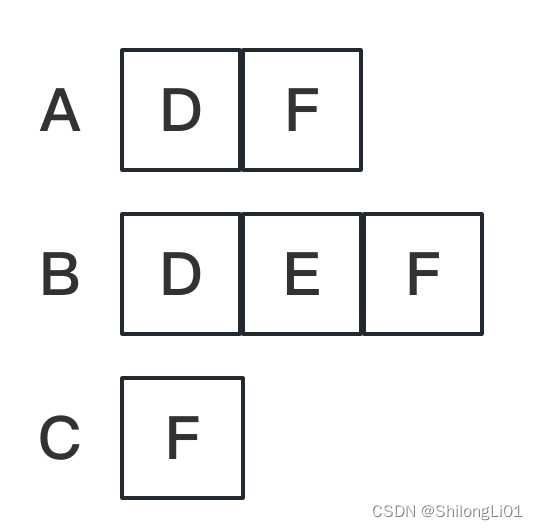
对于每个左侧的顶点创建一个vector数组,数组中存储该顶点能到达的点的信息,例如A能到达D、F,那么A的数组中存储D、F,且可以通过结构体存储更多信息,例如边的权重等等。B、C同理。
链式前向星
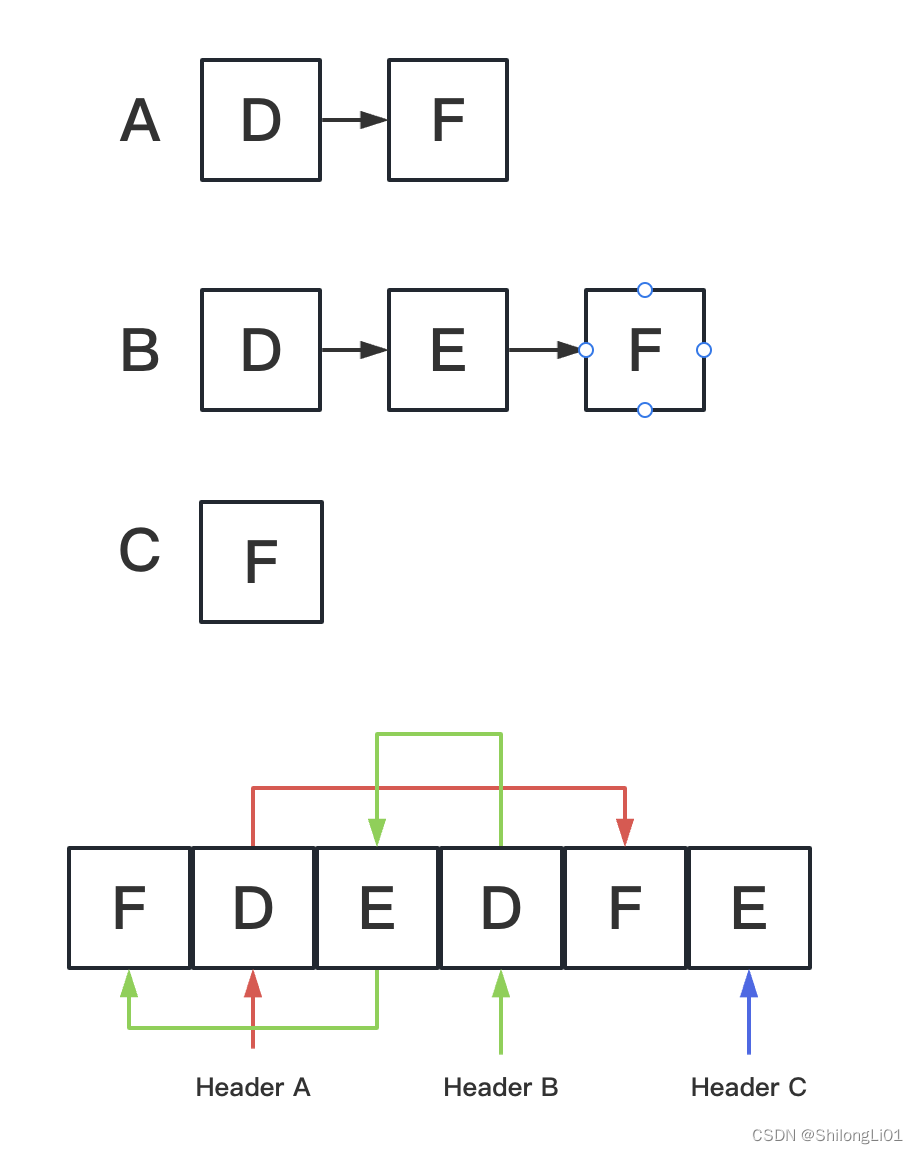
链式前向星是链表形式的邻接表,修改效率更高。其把所有边存在一个数组内,并用Header指向该节点的第一条边,例如A节点,他的头加点是D,也就是说他有一条到D的边,然后根据D节点中存的next,获取到了下一个节点F,说明A还有一条连接F的边,F没有next了,说明A就这两条边。B,C以此类推。
匈牙利匹配算法
算法流程
图我们画出来了,也用相应的结构表示出来了我们就可以进行匹配了。
在匹配之前我们先了解几个概念:
假设M为图G的一个匹配。(红色为匹配边)
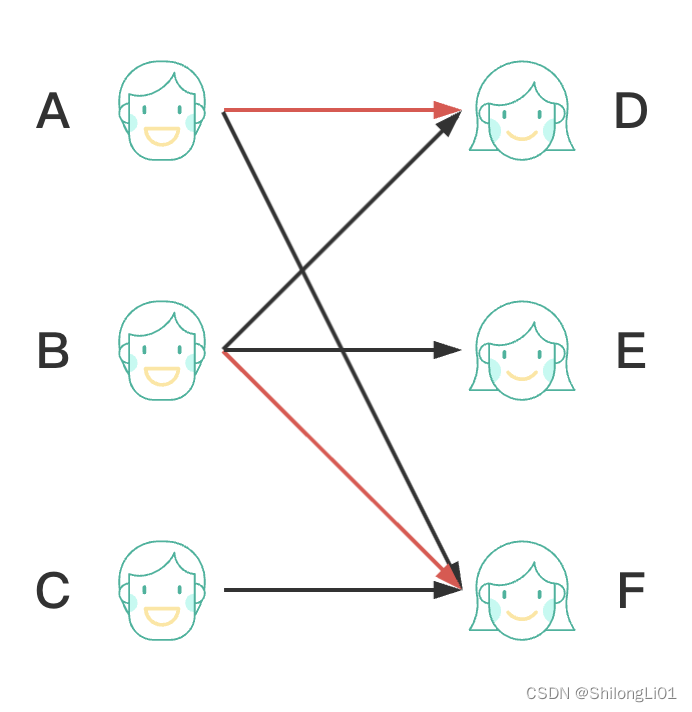
M-交错路:p是G的一条通路,如果p中的边为属于M中的边与不属于M但属于G中的边交替出现,则称p是一条M-交错路。如:A->D->B->F
M-饱和点:如果v与M中的某条边关联,则称v是M-饱和点,否则称v是非M-饱和点。如A,B,D,F都属于M-饱和点,而其它点都属于非M-饱和点。
M-可增广路:p是一条M-交错路,如果p的起点和终点都是非M-饱和点,则称p为M-可增广路。如C->F->B->E。
我们可通过不断获取可增广路进行增广,直到无增广路为止就是最大匹配了。
算法流程:
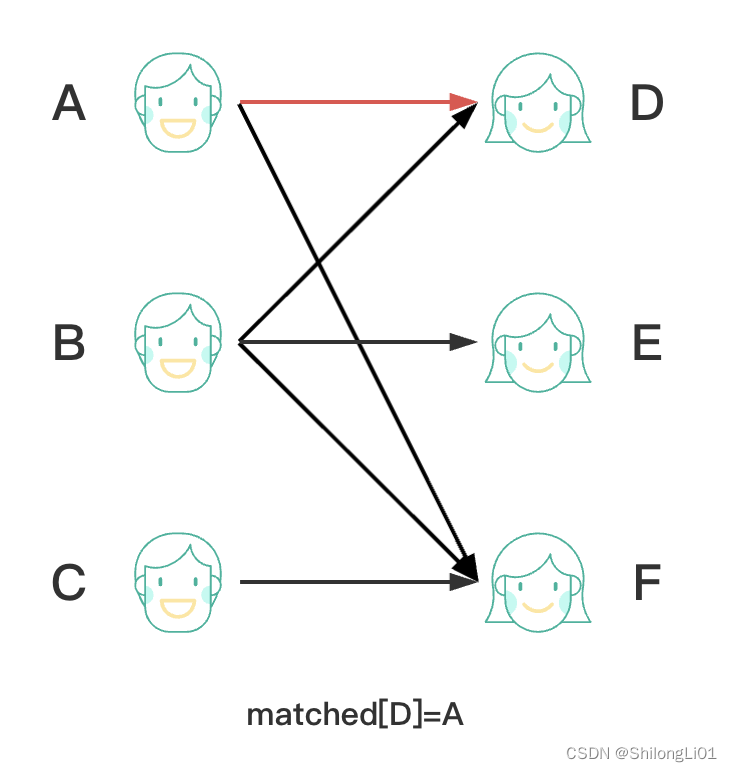
遍历左右左侧顶点,如果有未匹配的点,那么进行以下操作match(A)。
从A开始匹配,遍历A所有的边,当遍历第一条边时,发现D未被匹配,找到一条增广路,那么A直接与D匹配,并记录D的匹配这为A,matched[D]=A,算法返回。
然后开始B点的匹配,B点首先匹配他的第一条边B->D,发现D被匹配了,那么先标记D点为visit状态(访问过了,之后的点不要访问了),递归进行下一个操作match(matched[D]) 也就是 match(A),解释一下,这里B发现D点被占用了,B可以让A先去找找其他人匹配,如果A找到了其他人匹配,那么B就可以匹配D了,这样的话匹配数就会加1,所以重新进行match(A)操作,那么到A这里,A先遍历第一条边A->D,由于D点被访问过了(visit状态),所以跳过,A遍历下一条边A->F,发现F未匹配,匹配后进行返回,返回递归后,上一层B发现A匹配成功,那么D点被让出,则B匹配D点。
该阶段实际上就是在找B的增广路径,B从一条未匹配边(B->D)出发,到另一条未匹配边(A->F)结束,则找到一条增广路径,然后进行增广,增广过程实际上就是对每条边取反,匹配变未匹配,未匹配变匹配,最后匹配数加一。
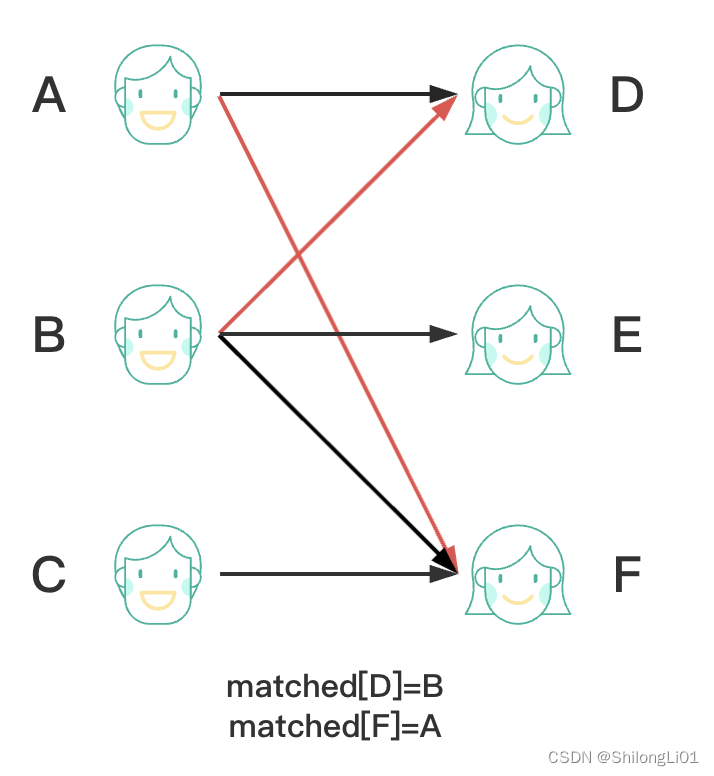
最后开始C点的匹配,我们不一个一个向前推,直接找一条增广路径,可以看出从C出发走C–>F==>A–>D==>B–>E是一条增广路径,代表匹配边,我们可以直接对这条增广路径上的边取反即可增加一条匹配边即C>F–>A==>D–>B==>E。
最终的结果为:
代码实现:二分图匹配
复杂度:O(n*m)
其他匹配算法
hopcroft-karp算法,先通过bfs找到多条增广路径,同时增广,每次增广花费时间m,被证明最多sqrt(n)次增广后完成最大匹配,因此算法复杂度略优于匈牙利算法,但是两者原理相同,此算法相当于匈牙利算法的多路增广优化版。
代码实现:二分图匹配
复杂度:O(sqrt(n)*m)
二分图最大权匹配
实际中的情况更加复杂,两个人之间的喜欢或者是否合适不能仅用0和1来表达,可能A和D之间门当户对,A和F之间是云泥之别,不是不能配,得硬配。所以,为了解决这些情况,我们引入了权,每条边上有一条权重,代表两个人的合适程度。我们的任务是找出权重之和最大的匹配方案,当所有边的权重都相同时特殊化为普通的二分图最大匹配。
这样的话,我们依然以之前的方式存图,只不过边上,不仅要存下一个顶点的编号,还要存边的权重。[图的存储](# 图的存储)
KM算法
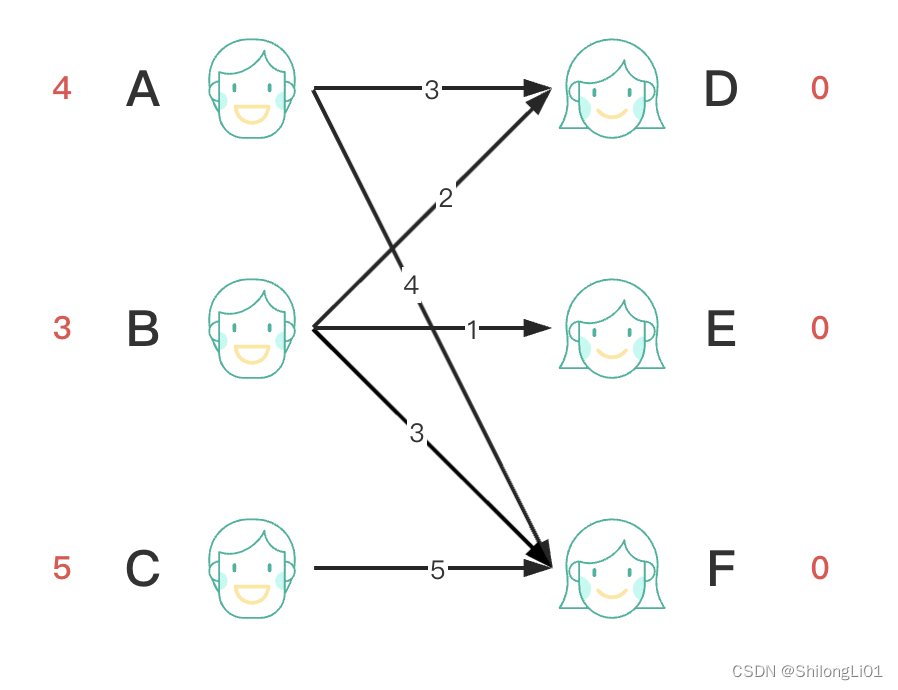
首先我们把每条边附加上相应的权重,权重越大说明两个人更加合适,然后我们给左侧的每个男士初始化一个期望值,该值等于与A所有连接的边中权重最大的边的权重,代表该男士期望的匹配的权重(刚开始都希望匹配最好的),给每个右侧的女士初始化一个附加期望值,代表该女生的期望值,刚开始都是0,代表只要该男生选择了该女生合适度即可,我们规定,两个人的期望值相加等于边的权重时进行匹配,如果小于,说明两人不合适,如果大于期望先找到更好的。
算法流程
下面我们开始匹配,主要流程仍然是匈牙利匹配的流程,首选我们从A点遍历A的所有边,首先A匹配D,4+0>3,不相等,不匹配,A心里打小算盘,不急,没准有更合适的,于是继续往下找,在这之前记了一下slack = E[A] + E[D] - 3 = 4 + 0 - 3 = 1,slack代表A此次匹配中最小的期望差,之后如果最合适的被抢了那么就根据这个降低一点期望找差一点的,会根据这个slack降低自己的期望。A再找,找到了F,4 + 0 = 4,完美,直接匹配。
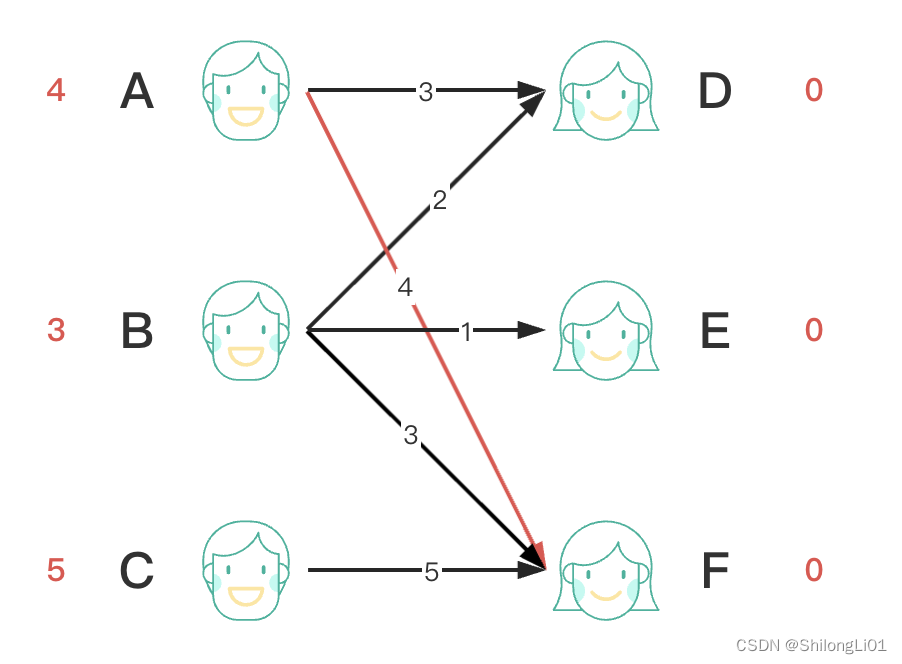
再看B,B配D绰绰有余,先记一下slack = 3 + 0 - 2 = 1,下次再说,然后看E,情况相同,slack = 2,最后看F,最合适的被A抢了,于是B让A匹配其他的点,A发现没有其他的点可以匹配,但是B想和A抢一下F点,发生了冲突怎么办。
从常识的角度思考:其实我们寻找最大权匹配的过程,也就是帮每个人找到他们最合适的伴侣,但是,有些会冲突,比如现在,B和A对F的般配程度都是最高,这时我们应该让A或者B换一个人,总有一个人要离开,虽然这样会降低总体的匹配权重,但是没办法,我们现在只要求最大权匹配,所以,如果A换一个人降低的权比较少的话,我们是能接受的(对B同样如此)。
所以我们把A,B的点期望降低1,让他们先找其他次优人选,然后右边的F点权重加1,保证F仍然能和A和B进行匹配。对于左侧降低期望的节点来说,他们可以找到其他次优人选,对于右侧升高附加期望的节点来说没有任何影响,她仍然可以和任何符合的人选进行匹配,附加期望的主要意义是代表此节点已被抢占,所有想要匹配该节点的左侧节点,必然降低期望值才能继续匹配。如A,B挣抢F节点,A和B降低期望后,当其中一个找到可匹配点时,另一个仍然可以和F进行匹配。如果C争抢F点,由于F点被抢占,那么他必须降低一点自己的期望才可以(5+1-5!=0)。
节点的权重修改后为:
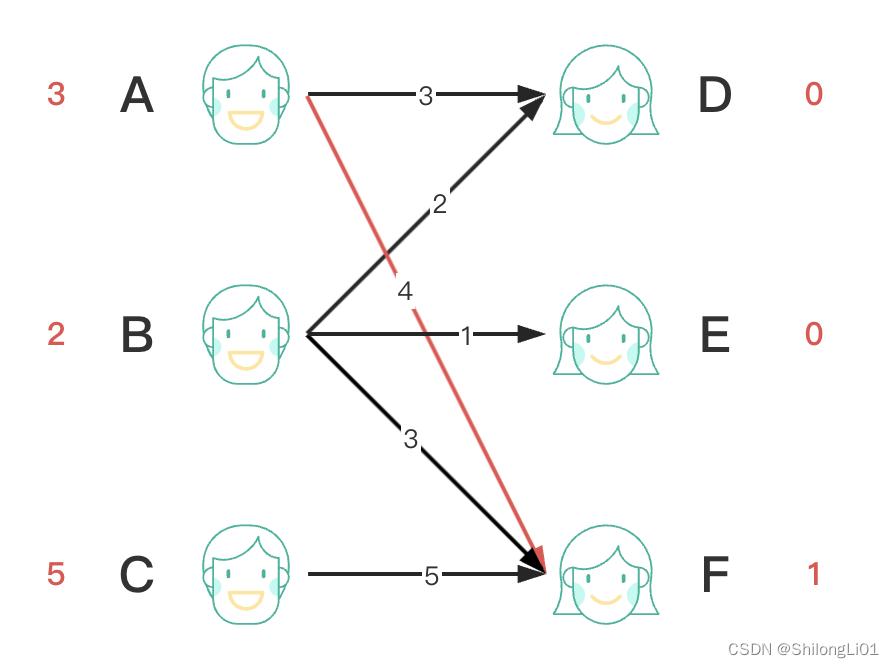
然后我们继续匹配,B–>F==>A,我们从A出发看是否能找到一个可以匹配的非匹配边,形成一条增广路径,显然,A降低期待后,可以和D点进行匹配,于是形成了,B–>F==>A–>D的增广路径,我们对路径上的边取反,B==>F–>A==>D,就形成了新的匹配交错路,使得匹配数量加1,总体权重减一(原本A和B都选择最大的边,发生冲突之后,只能降低期望找次优解)。结果如下:
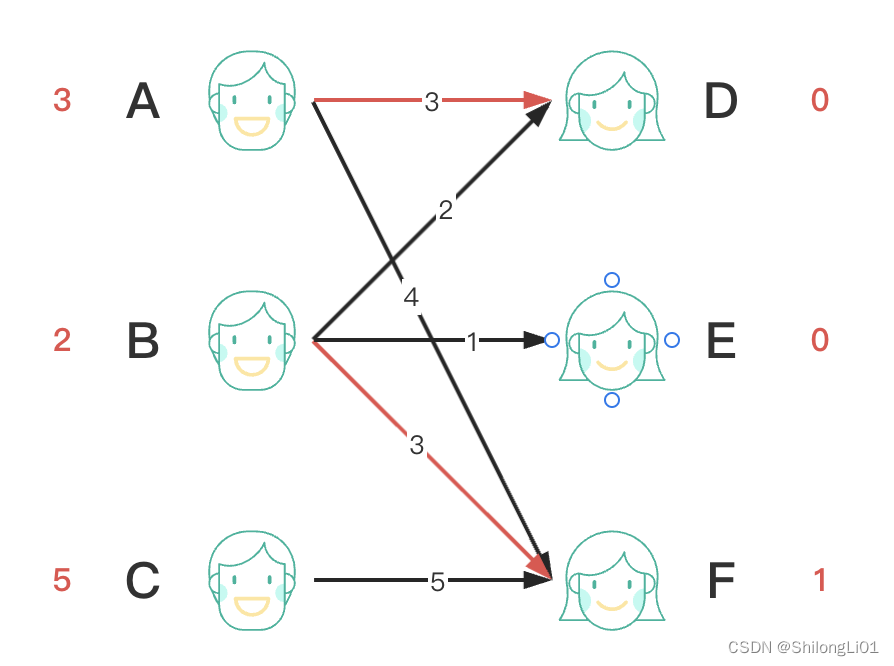
最后匹配C节点,遍历C所有的边,发现C和F不能进行匹配(5+1-5!=0),所以C降低一点自己的期待值,降低后4+1-5=0可以进行匹配,后又发现B抢占了F点,于是让B看看在不降低期望的情况下能不能匹配其他的点,同理B通过D又找到了A让其在不降低期望的情况下看看能不能匹配到其他的点。发现都没有找到,于是所有相关的左侧的点期望减少1,右侧有冲突的点权重加1,于是结果如下:
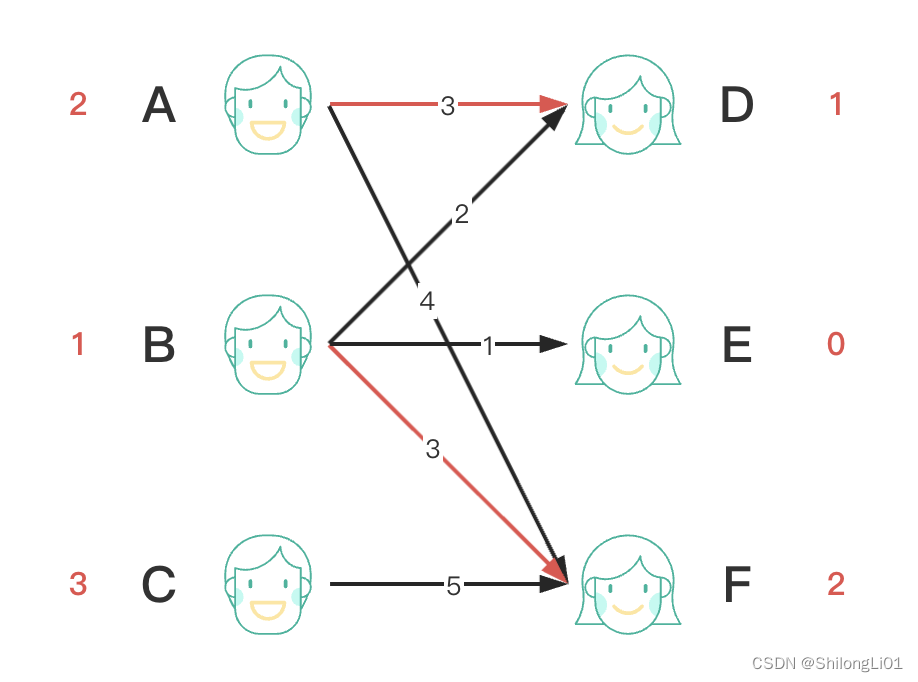
修改完权重之后,我们重新从C点进行匹配,发现F点冲突,于是让B点找,B点发现第一条边D点冲突于是让A找,A找了所有的边没发现有能被匹配的,于是放弃让A点找,于是B点遍历第二条边发现能和E匹配,则B和E匹配,F点让出C和F匹配,实际上仍然是找增广路径的过程,C–>F==>B–>E是一条增广路径,通过增广后变成C==>F–>B==>E。所以最终结果如下,最终权重为三条边的权重之合3+1+5=9。
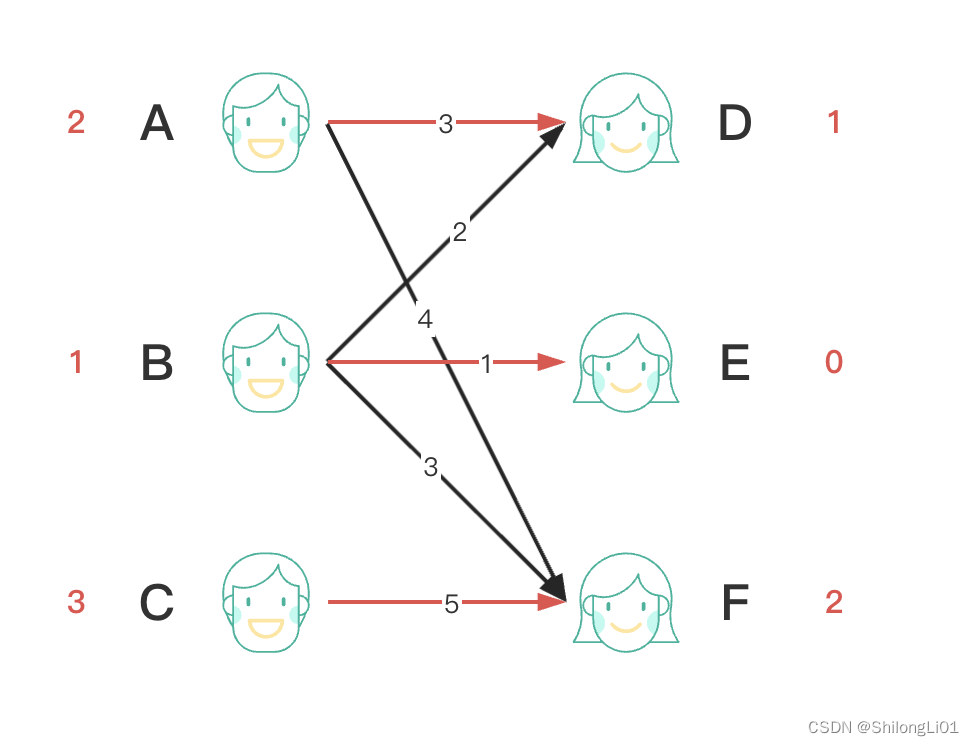
显然有一个可以优化的点,那就是每次权重降低1好像有点麻烦,如果每条边的权重数字相差非常大,那么每次1的降低,次数太多了,不如一次多降低点,所以我们之前定义的slack就起了作用,每次降低所有slack中最小的那个就可以一次完成了。
代码实现:二分图匹配
算法复杂度:O(n^3)
一般图的最大匹配
但是在通常情况下,比如说这次的游戏组队业务中很难把游戏玩家分成互不相交的两个部分,每个玩家都是一个独立个体,而且每个玩家之间都可以进行匹配,这样的情况下我们使用一般图的最大匹配算法带花树算法进行解决。一般图的最大匹配仍然是基于寻找增广路的。类比二分图最大匹配的增广路算法,如果我们找到了一条增广路,那么将这条增广路的边取反(匹配的变成非匹配,非匹配的变成匹配),那么匹配数会恰好+1,如果全图不存在增广路,也就说明当前已经是一个最大匹配了。
一般图
一般图匹配和二分图匹配(bipartite matching)不同的是,图可能存在奇环。
二分图:
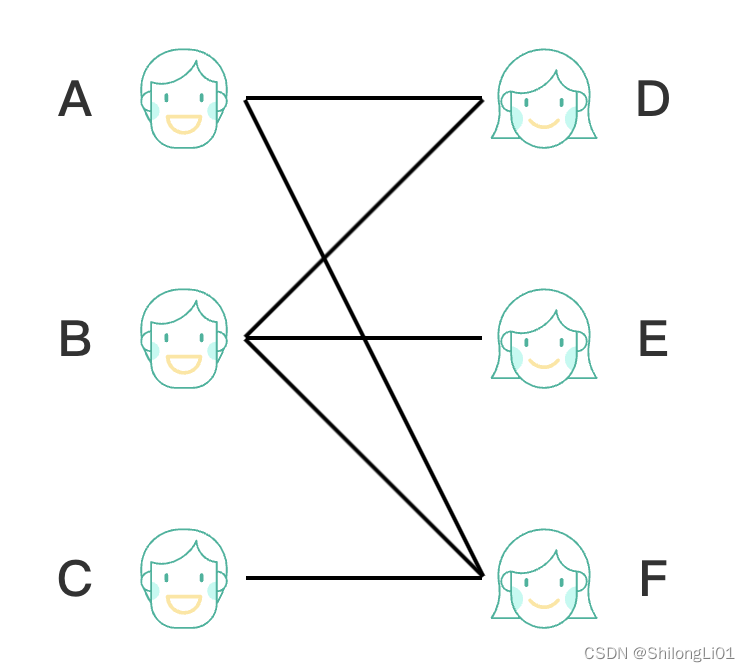
一般图:
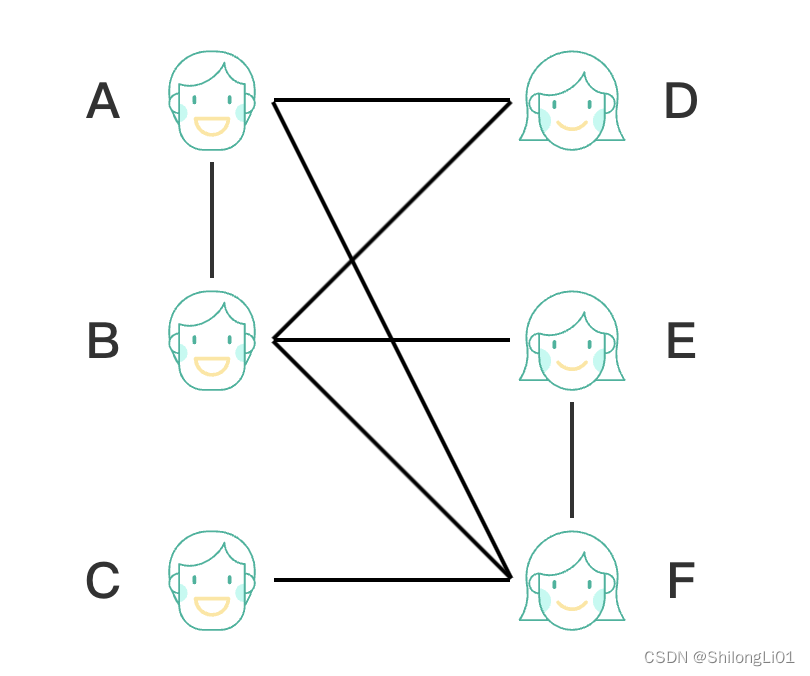
可以发现,如果不限制玩家匹配的话,那么任意两个玩家可以匹配,那么就会出现一般图,图中总会出现奇环,例如A-D-B-A这个环,他从左侧出发,左右左,奇数次使其成环。
而且,我们知道,对于一个三角恋(不考虑性别)来说,最好的匹配是让他们中的其中两人成为一对,然后另一个人向外匹配,那么这是最好的结果。所以我们可以通过把这样的奇环缩成一个点对外进行匹配。
常用的缩点算法使用tarjan缩点,原理是当遍历节点时从一个当前遍历点找下一个点时发现了一个已经遍历过的点,那么说明有环存在,那么从当前遍历点traceback,把该环上所有的路径点染成一个颜色,重新建图,对颜色不同的点建边,颜色相同的不建边,最终达到缩点的目的。
我们为了简单,不重新建图,直接用LCA和并查集进行染色,环上所有的节点的并查集所存储的就是他们的LCA节点也就是对外匹配的节点。LCA就是两个节点的最近公共祖先,就是从两个节点沿着他们遍历过的路径返回直到找到第一个都经过的几点。并查集就是用来存储两个节点的公共祖先是否相同的。
LCA:LCA算法
并查集:并查集算法
带花树算法流程
仍然是从每个未匹配的点开始寻找增广路,不过我们采用BFS的方式,每个点均设为无色,端点染成黑色
设当前点为u(黑色),枚举与它相邻的点v
考虑v是否已经被访问过
若v尚未访问过(v为无色)
如果v尚未匹配,说明我们找到了一条增广路,直接返回修改。
如果v已经匹配,那么将v染成白色,v的匹配点x加入队列,继续寻找增广路,x染成黑色。
容易看出,根据上面的过程,我们只会对于黑点枚举出边,并且我们访问的路径形成了一棵黑白点交错的树。
若v已经访问过(有颜色),说明我们找到了一个环。
如果它是一个偶环(v为白色),那么v显然已经被找过了,无需再找一次。
如果它是一个奇环(v为黑色),这就有问题了
怎么办呢?
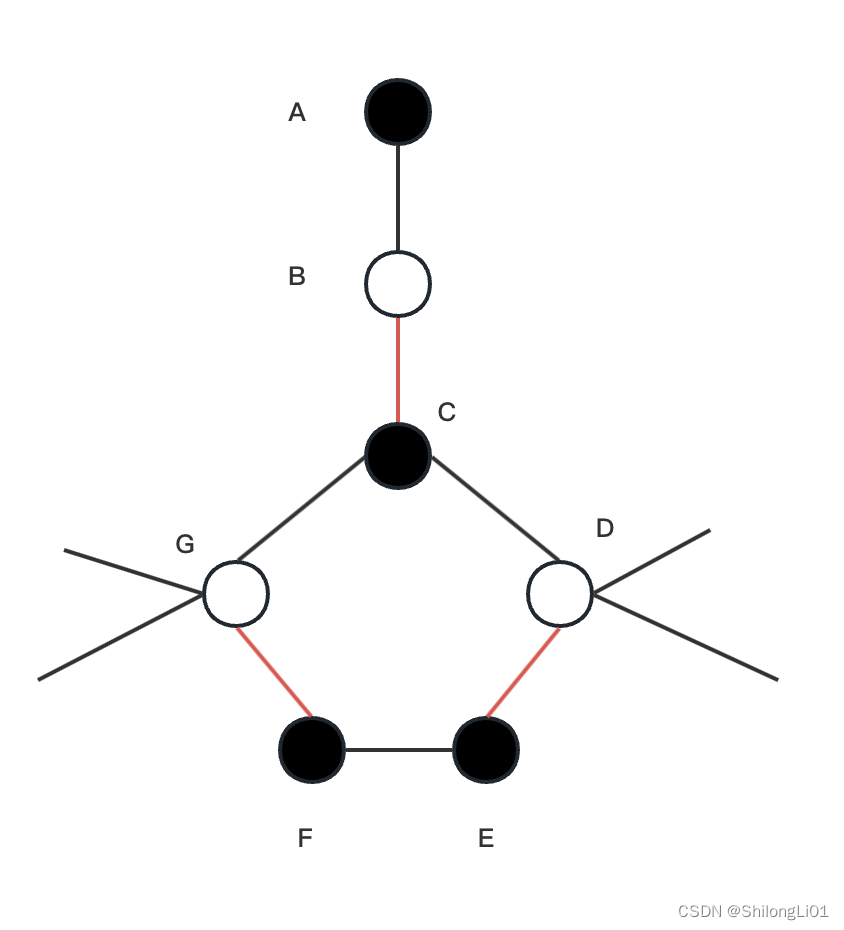
图中红色为匹配边,我们从A点出发通过bfs方式进行匹配。我们发现B点已经被匹配,染成白色,取他的匹配点C扔进队列,从C开始匹配发现G被匹配,扔F进队列,发现D被匹配,扔E进队列,最后遍历F的时候发现E已经访问过,且同为黑色,则遇到奇环。
注意对于一个奇环,我们一定是从一个黑点进入,最后也在黑点碰头(u,v)。当我们从白点进入的环的时候,一定会在环没有结束的时候就找到了增广路径。下面进行证明:
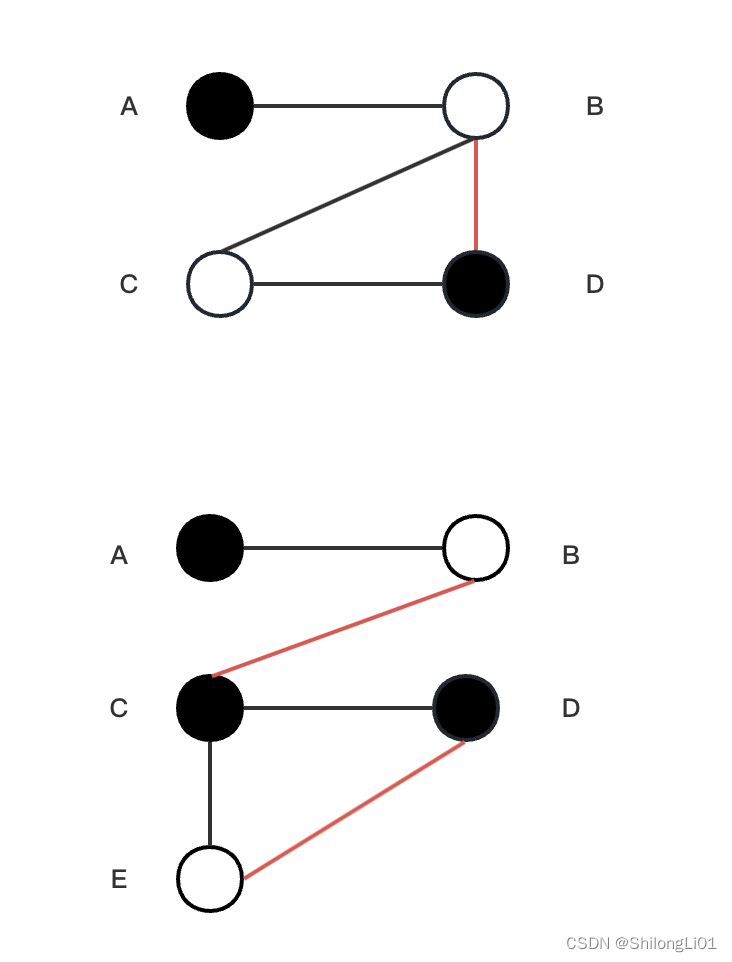
如上图所示,同为奇环,上面的图不会走完奇环,因为A->B发现B被匹配,pushB的匹配点D到队列,然后弹出D进行匹配,发现C点为匹配,那么找到一条增广路,A–>B==>D–>C,可进行增广。可以说从白点进入环,白点是匹配点,那么他从匹配边进入,从未匹配边出,匹配 未匹配 未匹配(最后还是未匹配),由于边为奇数,根据匹配未匹配的交错路,那么一定可以在中间找到一条未匹配路径形成一条增广路,所以不能形成发现奇环。
在第二张图,我们发现B点被匹配,pushC进队列,遍历C发现E被匹配,染E为白,后染D为黑,遍历D时发现D为黑,自己也为黑,两个黑色相遇,则发现奇数环。所以,奇数环一定从黑点进入。
问题在于,此时对于整个奇环的颜色都不确定了,我们令这个奇环的顶点为最顶上的那一个黑点,那么考虑u上方的这一个白点,我们既可以走从顶点走一条非匹配边到它,它作为一个黑点,也可以从另一边转一圈到它,此时这个它变成了黑点,它是需要加入队列继续走的
也就是说,对于一个奇环,它上面的点都可以成为黑点。
继续观察可以发现,整个奇环的匹配状态只与顶点的匹配状态有关,如果在后来的某一次寻找时奇环上的匹配被改变了,那么顶点的颜色唯一决定了整个环的匹配边是如何走的。
也就是说,整个环就可以用一个顶点表示了,也就意味着我们可以将这个环缩掉,缩掉的环就称为“花”,缩环就是开花
我们不妨对于每一个白点x,记pre[x]表示x是由哪一个黑点走过来的,也就是记录了增广路上的非匹配边。
对于每一个点,记match[x]表示x的匹配点是谁。
缩环具体怎么缩呢?
如果直接修改原本的连边比较麻烦,我们考虑采用并查集,记录每个点所在的奇环的顶点,初始时就是它自己。缩环的时候,我们直接将环上的所有点并查集父亲连向奇环的顶点,并将环上的白点都变成黑点,并且加入队列。
此外,由于奇环可以双向走,因此我们的pre边也要变成双向的。
缩完点之后就可以继续走之后的匹配流程了。
匹配流程
从每个未匹配的点BFS寻找增广路,每个点均设为无色,端点染成黑色
枚举与当前点u(黑色)相邻的点v
考虑v是否已经被访问过
若v尚未访问过(v为无色)
如果v尚未匹配,找到了一条增广路,直接返回修改。
如果v已经匹配,将v染成白色,将v的匹配点x加入队列,继续寻找增广路,x染成黑色。
若v在当次增广已经访问过,找到环
v为白色,是一个偶环,跳过。
v为黑色且u,v所在的奇环已经缩过了,那么也跳过。
否则,v为黑色,找到一个新的奇环,那么找到u,v所在奇环的环顶(即它们在BFS上跑出来的交错树的lca,称之为最近公共花祖先),将u到环顶的路径以及v到环顶的路径修改掉,白点染成黑点,加入队列,并将环上的点(或者是某个已经缩了的环顶)并查集父亲指向lca。

以此图为例,当F-E相遇时,把所有的点缩成一个点,然后把所有白点染成黑色,push进队列中进行对外匹配,最终的效果是,A发现B点匹配,把B的匹配点C染成黑色,push,然后C所在的整个环缩到点C上,然后相当于C点对外进行匹配。通过这个流程不断查找增广路径,当无增广路径时,即得到最大匹配。
代码实现:一般图匹配
算法复杂度:O(|E|*|V|^2)
一般图最大权匹配
一般图的最大匹配解决之后,就可以带权匹配了,带权匹配和二分图相同,把带花树算法和KM算法结合起来即可,原理和二分图最大权匹配相同,进行期望的加减,唯一额外考虑缩点时的权重即可,这里不多赘述。
可能产品想每次匹配质量最高,而不是匹配最快的时候可以用此算法,所有边权重相同时,特殊化为最大匹配。
代码实现:带花树最大权匹配
算法复杂度:O(|E|*|V|^2)

















 9629
9629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









