







参数处理
数据集的规划
训练集训练模型,测试集评估模型,验证集应用模型,在big data时代,数据规模可能是百万级,那么取百分之一做测试集或者验证集即可。
偏差和方差
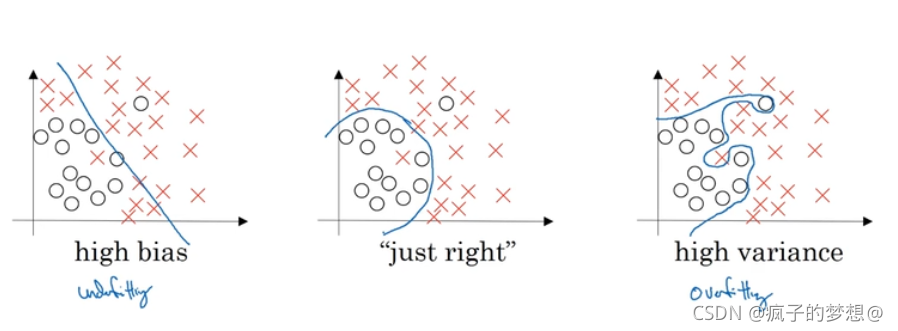
下图是数据集,做一个直线划分,不能很好的拟合,这就是偏差高的情况。称为欠拟合。如下图中的最左侧图
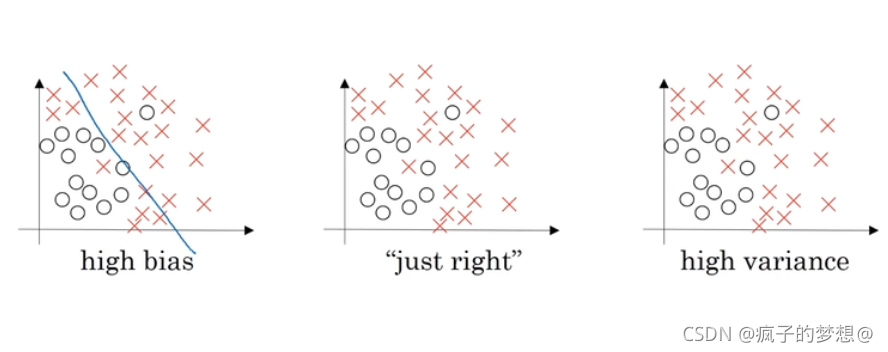
使用多种复杂分类器,进行分类,完美区分,称为过拟合,如下图最右侧所示。
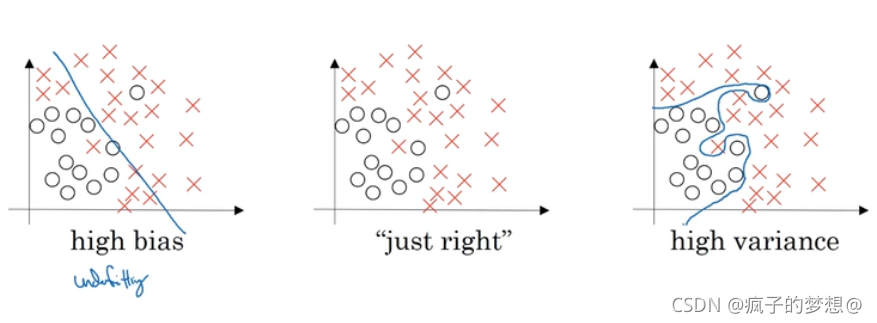
适度拟合,复杂度和偏差度都适中,如下图中间的图。
下图我们识别猫来举例,训练集的误差只有百分之1,验证集误差百分之11,这就是高方差。

当训练集数据误差到百分之15,验证集误差到百分之16,我们这时可以称为高偏差,这是数据欠拟合。当训练集误差百分之15,验证集误差百分之30,我们可以称这是高偏差,高方差的情况。当训练集和验证集误差都在百分之1,我们可以称偏差和方差都很低。
正则化
正则化有助于避免过度拟合,或减少网络误差。
例如使用logistic回归的思想,求成本函数J的最小值,红框内就是加入了正则化。λ是正则化参数。这是L2正则化,通常使用验证集来寻找正则化参数。
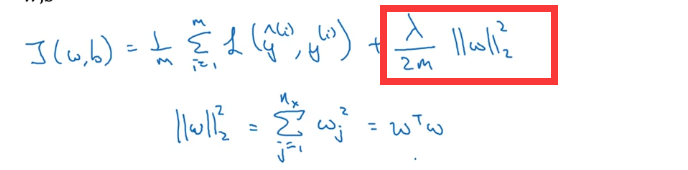
L1正则化如下图所示。最终w是会变稀疏的,即w向量中有很多0.
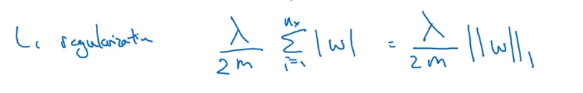
dropout(随机失活)正则化
假设下图的神经网络存在过拟合,遍历每个神经元节点,使某些节点失去作用被消除,这个节点被保留和消除的概率都是百分之50.然后去掉从该节点进出的连线,最后得到一个节点更少,规模更小的网络。
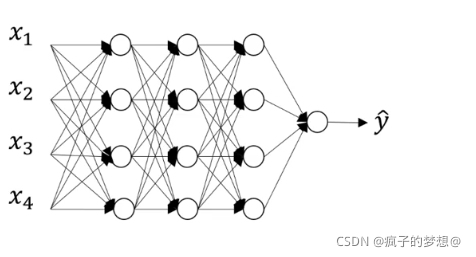
这是我们精简后的网络。然后使用这个精简后的网络进行神经网络的训练。
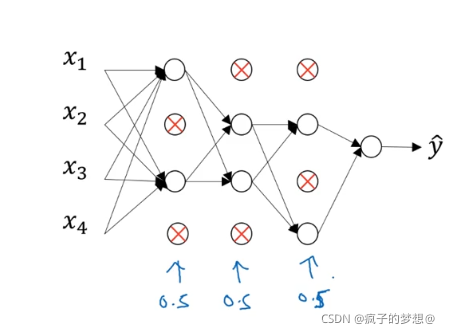
实现dropout
假设我们应用在一个三层的神经网络,那么我们需要定义一个参数d
^ [3],是一个三层的只有0和1的矩阵,然后看他里边的数是否小于一个参数(keep-prob),这个keep-prob在上图中我们设置的是0.5.用来表示保留某个隐藏单元的概率。然后还有一个参数a^ [3] 我们使用a3=a3*b3的形式来过滤掉d3=0的情况。最后用a3/keep-prob在更新a3参数。
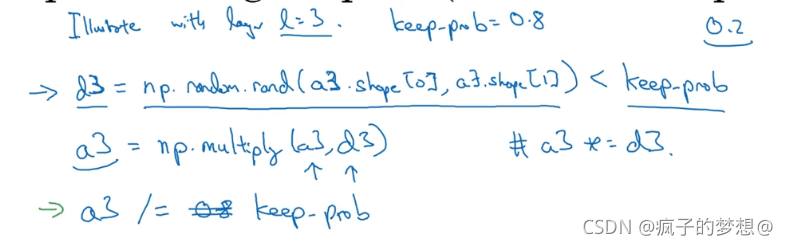
为什么最后一步要a3/keep-prop呢,假设我们的网络层数是3,那么最后一层输出层z4的计算公式如下,我们的a3只保留了百分之80,为了不使z4的期望值受影响,所以我们要除以百分之80,修正或弥补我们所丢失的那百分之20.
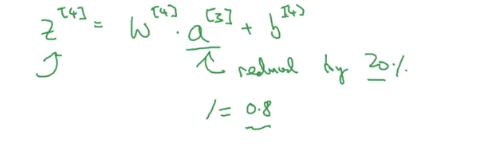
注意:测试阶段,不执行dropout来调整数值范围。有一个缺点就是成本函数J不再明确被定义。通常是会设置keep-prop为1,然后关掉dropout函数,然后运行成本函数J,确保J单调递减来调试模型。
其他正则化方法
为了解决过拟合问题,可以使用增加训练集的方法,可作为正则化方法使用。
还有一种方法叫early stopping,训练梯度下降时,我们可以绘制训练误差函数,当我们还可以同时绘制验证集误差,验证集误差一般是一个开口向上的曲线,所以early stopping作用就是在其中的某个低点,停止我们的迭代训练过程。
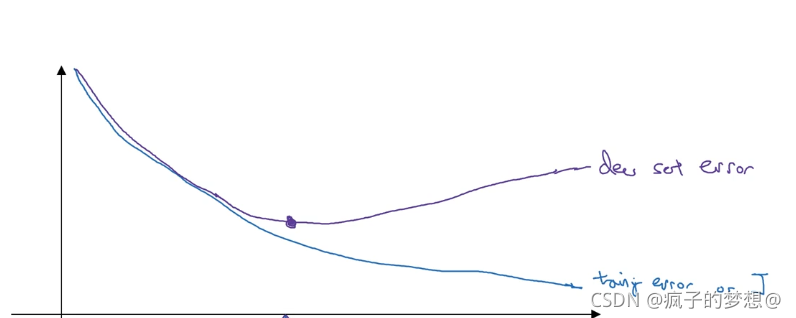
注意:early stopping是提前停止了成本函数J的降低,来换取解决数据过拟合的问题。
加速训练的方法
数据归一化
归一化输入是其中的一个方法,解决的是输入特征值范围相差过大的问题。假设我们有一个训练集,他的输入特征x是二维的

首先是进行零均值化,最后移动的数据集变为下图所示。
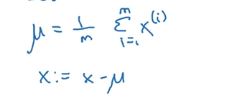
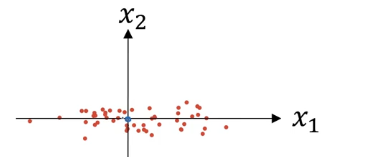
第二步是归一化方差,最后数据集变为下图所示

梯度爆炸与消失
如果我们权重矩阵w内的数,只比1大一点点,那么深度神经网络的激活函数将爆炸式增长,只比1小一点点,激活函数将指数级递减,那么这也等同于相关的导数或梯度函数增长或减少。
神经网络的权重初始化
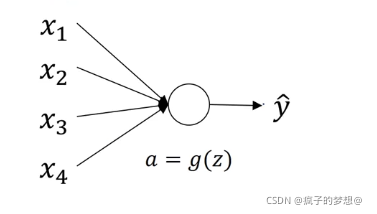
以一个神经元为例,有四个输入特征,从x1到x4,最后得到预测值。
下图是我们求z的公式,那么我们知道z是wx的累加,我们希望n变大,wn的值变小,一个方法就是设置w=1/n,n表示神经元的输入特征数量。
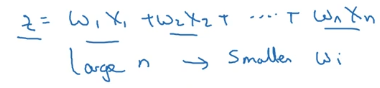
梯度的数值逼近
先看一个函数,f(θ),我们在θ的左侧和右侧取偏移量为0.01的点
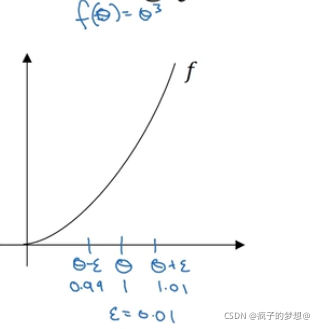
我们将数据代入f(θ)得到如下结构,计算结果。
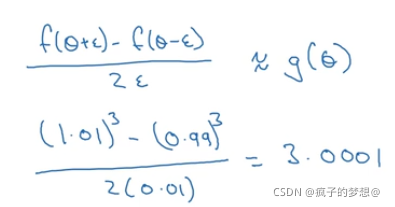
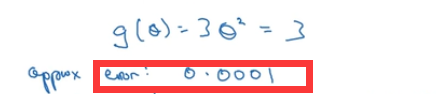
最后我们与在θ点的值对比,发现误差只有0.001,这是叫考虑双边公差,与以往只考虑单边公差(即用【f(θ)-f(θ-ε)】/ε)情况不同,我们这样大大缩小了误差。
梯度检验(grad check)
要做的就是每个参数进行双边公差检验,如对J(θ),我们对每个θ^ [i]都遍历,使用如下公式
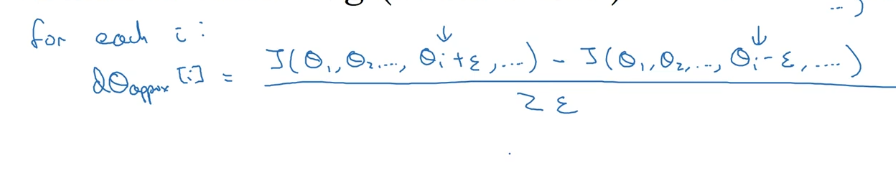
这个值应该逼近下式
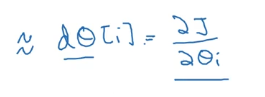
如何检查是否逼近呢,使用下式
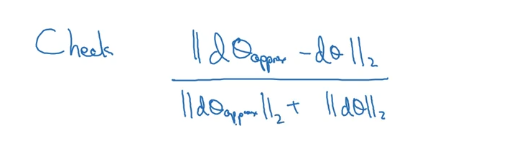















 4991
4991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









