







正则化主要是在损失函数中引入了第二个部分,模型复杂度,具体就是对w参数赋予了权值,并求和,再乘上一个超参数。
(利用给w加上权值,弱化训练数据的噪声)
大概可以理解为这个意思
假设模型有两个参数矩阵——w1,w2
使用L2正则化
loss = loss_mse + 超参数*loss_regularization
# 其中loss_regularization就是对两个参数矩阵正则化后求和
# loss_regularization=tf.reduce_sum[(tf.nn.l2_loss(w1),tf.nn.l2_loss(w2)]
01本文先介绍了训练集情况
02介绍了几个预备知识点
03进行实例展示(正则化之前,和正则化之后)
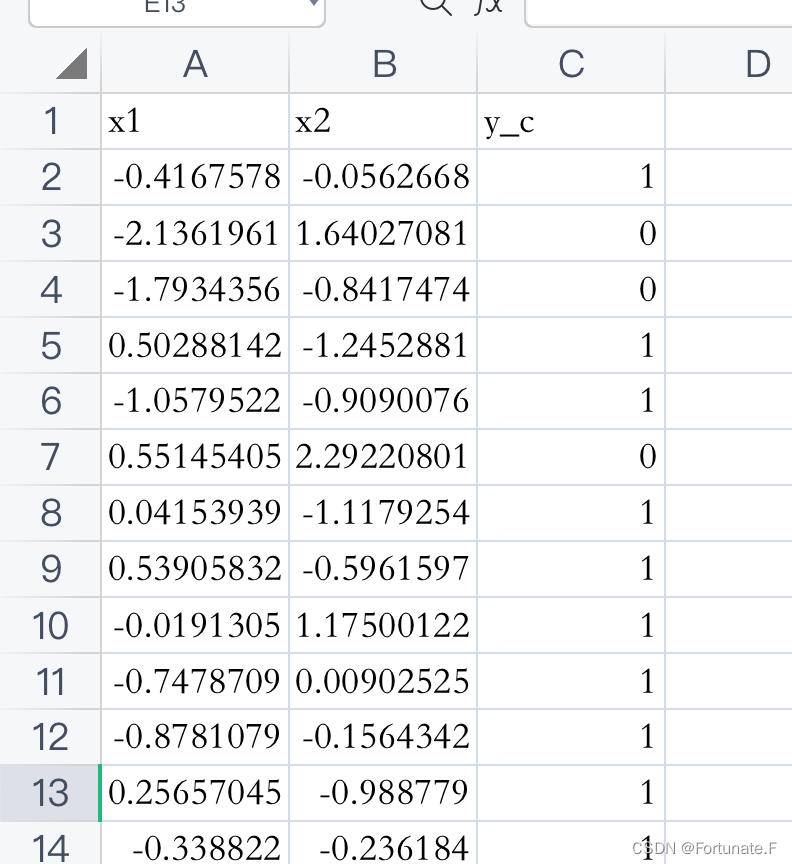
训练集dot.csv数据大概如下,可以随机生成
【包含特征值x1,x2和对应的标签y_c,共300组】
预备知识点
【01】 np.ravel()和np.flatten()
两者的功能是一致的,将多维数组降为一维
两者的区别是返回拷贝还是返回视图
np.flatten()返回一份拷贝,对拷贝所做修改不会影响原始矩阵
np.ravel()返回的是视图,修改时会影响原始矩阵(后面实例使用这个)
【02】np.r_[a,b]和np.c_[a,b]
np.r_是按列连接两个矩阵,要求列数相等。
np.c_是按行连接两个矩阵,要求行数相等。(后面实例使用这个)
(记忆:c是行!)
import numpy as np
a = np.array([[1,2,3],[7,8,9]])
b = np.array([[4,5,6],[1,2,3]])
print("a:\n",a)
print("b:\n",b)
c=np.c_[a,b]
d=np.r_[a,b]
print("c:\n",c)
print("d:\n",d)
输出:
a:
[[1 2 3]
[7 8 9]]
b:
[[4 5 6]
[1 2 3]]
c:
[[1 2 3 4 5 6]
[7 8 9 1 2 3]]
d:
[[1 2 3]
[7 8 9]
[4 5 6]
[1 2 3]]
【03】np.mgrid[a: b :c]
返回多维结构,常见的如2D图形,3D图形
【04】np.squeeze()
squeeze v.挤压
np.squeeze()函数可以删除数组形状中的单维度条目,就是把数组shape中等于1的维度去掉,但是对非1的维度不起作用。
#例3
>>> d = np.arange(10).reshape(1,2,5)
>>> d
array([[[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]]])
>>> d.shape
(1, 2, 5)
>>> np.squeeze(d)
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
>>> d.shape
(2, 5)
【05】plt.contour(X, Y, Z, [levels], 其他参数)
这个函数用于绘制等高线,也可以说是分界线
plt就是matplotlib.pyplot
X, Y表示的是坐标位置(这里是可选的,但是如果不传入的话就是python根据传入的高度数组(Z)的大小自动生成的坐标),一般很多会使用二维数组,但是实际上一维数组也可以的
Z代表每个坐标对应的高度值,是一个二维数组。其中每个值表示的是每个坐标对应的高度。就相当于函数值y。对应x1和x2两个参数。
levels有两种传入形式。
一种是传入一个整数,这个整数表示你想绘制的等高线的条数,但是显示结果可能并不是完全和传入的整数的条数一样,是大致差不多的条数(可能相差一两条)(为什么是大致条数呢?可能是python帮你默认生成的比较合适的几条等高线吧)。
另一种方式是传入一个包含高度值Z的一维数组,这样python便会画出传入的高度值对应的等高线。(下面代码使用的是这个方式)
实例展示——正则化以前
实例内容是:一个坐标点二分类问题。
训练集是上述表格文件,根据已知的数据x1,x2作为横纵坐标点训练
对应的标签1类标记为红色,0类标记为蓝色
测试集数据直接用二维坐标系上正负三范围内的坐标点
在这个区间内标记处红色蓝色的点,最终勾勒呈现出两种颜色的分界线
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
# 读入dot.csv文件的数据 300个
# x_date是两个特征值300*2
# y_date是特征值对应的标签300*1
df = pd.read_csv('/Users/sgfile/Downloads/BaiduNetdisk/人工智能实践:Tensorflow笔记20221224/class2(1)/class2/dot.csv')
x_date = np.array(df[['x1', 'x2']])
y_date = np.array(df['y_c'])
x_train = np.vstack(x_date).reshape(-1, 2)
# 参数-1表示自动匹配,也就是我只需要指定列数2,行数自动计算
# np.vstack():在竖直方向上堆叠
# np.hstack():在水平方向上堆叠
y_train = np.vstack(y_date).reshape(-1, 1)
# 给标签值标记颜色 如果标签为1则是红色,0为蓝色
Y_c = [['red' if y else 'blue'] for y in y_train]
# 转换x数据的类型,方便后面矩阵相乘
x_train = tf.cast(x_train, dtype=tf.float32)
y_train = tf.cast(y_train, dtype=tf.float32)
# 切片数据,将特征与标签配对,并打包,生成训练集
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
# 构建神经网络
# 输入层2个神经元——————隐藏层11个神经元————输出层1个神经元
# w1=[2*11] b1=11 w2=[11*1],b2=1
#
w1 = tf.Variable(tf.random.normal([2, 11], dtype=tf.float32))
b1 = tf.Variable(tf.constant(0.01, shape=[11]))
w2 = tf.Variable(tf.random.normal([11, 1], dtype=tf.float32))
b2 = tf.Variable(tf.constant(0.01, shape=[1]))
lr = 0.005
epoch = 800
for epoch in range(epoch):
for step, (x_train, y_train) in enumerate(train_db):
# 记录梯度信息
with tf.GradientTape() as tape:
# 记录神经网络乘加运算第一层
h1 = tf.matmul(x_train, w1) + b1
# 激活函数relu
h1 = tf.nn.relu(h1)
# 记录神经网络乘加运算第二层
y = tf.matmul(h1, w2) + b2
# 采用均方误差损失函数mse
loss_mse = tf.reduce_mean(tf.square(y_train - y))
# 梯度更新四个参数
# step1——计算梯度信息
grads = tape.gradient(loss, [w1, b1, w2, b2])
# step2——实现梯度更新参数
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
# 没有使用正则化,loss只有一个部分
loss=loss_mse
# 每20轮,打印loss信息
if epoch % 20 == 0:
print("epoch:", epoch, "loss:", float(loss))
# ------------------------至此,神经网络四个参数训练完成
输出结果:
epoch: 0 loss: 2.4265878200531006
epoch: 20 loss: 0.43145981431007385
epoch: 40 loss: 0.16190886497497559
epoch: 60 loss: 0.08229479938745499
epoch: 80 loss: 0.05829337239265442
epoch: 100 loss: 0.048353154212236404
epoch: 120 loss: 0.040947575122117996
epoch: 140 loss: 0.03630096837878227
epoch: 160 loss: 0.03280305117368698
epoch: 180 loss: 0.030033906921744347
epoch: 200 loss: 0.02776075340807438
epoch: 220 loss: 0.026936165988445282
epoch: 240 loss: 0.02629946731030941
epoch: 260 loss: 0.025844631716609
epoch: 280 loss: 0.02554425597190857
epoch: 300 loss: 0.025302037596702576
epoch: 320 loss: 0.02517053484916687
epoch: 340 loss: 0.02507457695901394
epoch: 360 loss: 0.024986503645777702
epoch: 380 loss: 0.02490798570215702
epoch: 400 loss: 0.024857262149453163
epoch: 420 loss: 0.024823719635605812
epoch: 440 loss: 0.02479807287454605
epoch: 460 loss: 0.0247130636125803
epoch: 480 loss: 0.024589741602540016
epoch: 500 loss: 0.024555539712309837
epoch: 520 loss: 0.02451319247484207
epoch: 540 loss: 0.02456258237361908
epoch: 560 loss: 0.02463117428123951
epoch: 580 loss: 0.024696240201592445
epoch: 600 loss: 0.024768143892288208
epoch: 620 loss: 0.024842776358127594
epoch: 640 loss: 0.02491491474211216
epoch: 660 loss: 0.024984782561659813
epoch: 680 loss: 0.02505091391503811
epoch: 700 loss: 0.025109589099884033
epoch: 720 loss: 0.025105630978941917
epoch: 740 loss: 0.025101713836193085
epoch: 760 loss: 0.0251059141010046
epoch: 780 loss: 0.025111591443419456
# 预测部分
print("**************[predict]****************")
# 生成网格坐标点,规格是:正负3的坐标系,0.1*0.1的网格
xx, yy = np.mgrid[-3:3:0.1, -3:3:0.1]
# 将xx,yy拉直,合并配对为二维张量grid,表示二维坐标点
grid = np.c_[xx.ravel(), yy.ravel()]
grid = tf.cast(grid, tf.float32)
# 把网格的坐标当作数据集送入训练好的神经网络,进行预测,输出存入列表probs
probs = []
for x_test in grid:
# 使用训练好的参数进行预测
h1 = tf.matmul([x_test], w1)+b1
h1 = tf.nn.relu(h1)
y = tf.matmul(h1, w2)+b2
probs.append(y)
# 绘制散点图
# 取x_data的第0列给x1,第1列给x2
x1 = x_date[:, 0]
x2 = x_date[:, 1]
# probs的形状调整为和xx一致
probs = np.array(probs).reshape(xx.shape)
plt.scatter(x1,x2,color=np.squeeze(Y_c))
# squeeze去掉纬度是1的纬度
# 相当于去掉[['red'],[''blue]],内层括号变为['red','blue']
# 把坐标xx yy和对应的值probs放入plt.contour()函数————用于画等高线的(也可以看做边界线)
# 给probs值为0.5的所有点上色——也就是上面那条线
# plt点show后 显示的是红蓝点的分界线
plt.contour(xx,yy,probs,levels=[0.5]) #预测值y为0.5
plt.show()
输出:
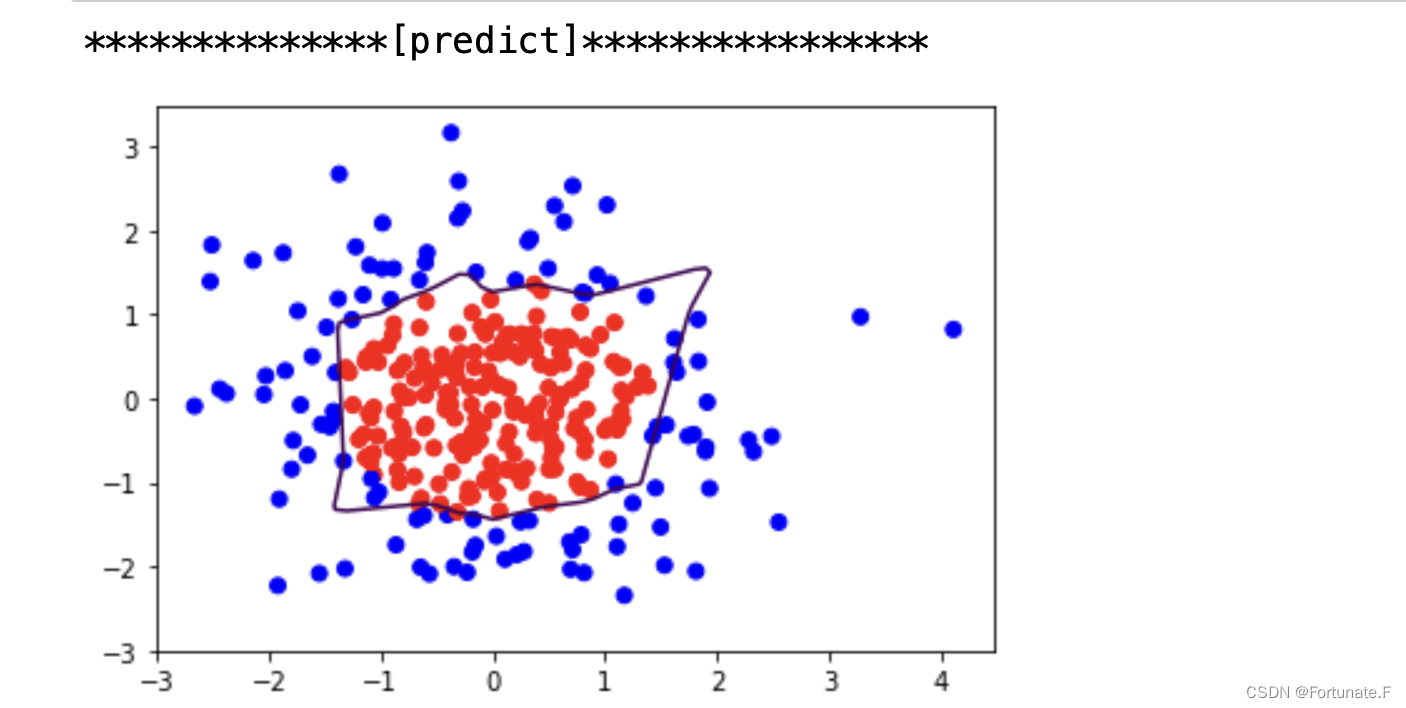 可以看到分割线轮廓不够平滑,存在过拟合现象
可以看到分割线轮廓不够平滑,存在过拟合现象
实例展示——正则化以后
仅需在以上代码的with结构中加入正则化
以下是更新后的with结构,对参数w1,w2使用了L2正则化
with tf.GradientTape() as tape:
# 记录神经网络乘加运算第一层
h1 = tf.matmul(x_train, w1) + b1
# 激活函数relu
h1 = tf.nn.relu(h1)
# 记录神经网络乘加运算第二层
y = tf.matmul(h1, w2) + b2
# 采用均方误差损失函数mse
loss_mse = tf.reduce_mean(tf.square(y_train - y))
# 添加L2正则化————tf.nn.l2_loss(w)=sum(w**2)/2
loss_regularization=[]
loss_regularization.append(tf.nn.l2_loss(w1))
loss_regularization.append(tf.nn.l2_loss(w2))
# 求和
loss_regularization=tf.reduce_sum(loss_regularization)
# 经过正则化后的loss包含两部分
# 一个是衡量预测值与标准答案差距的均方误差loss_mse
# 一个是表示各个参数权重和的正则化loss_regularization*超参数
loss = loss_mse+0.03*loss_regularization
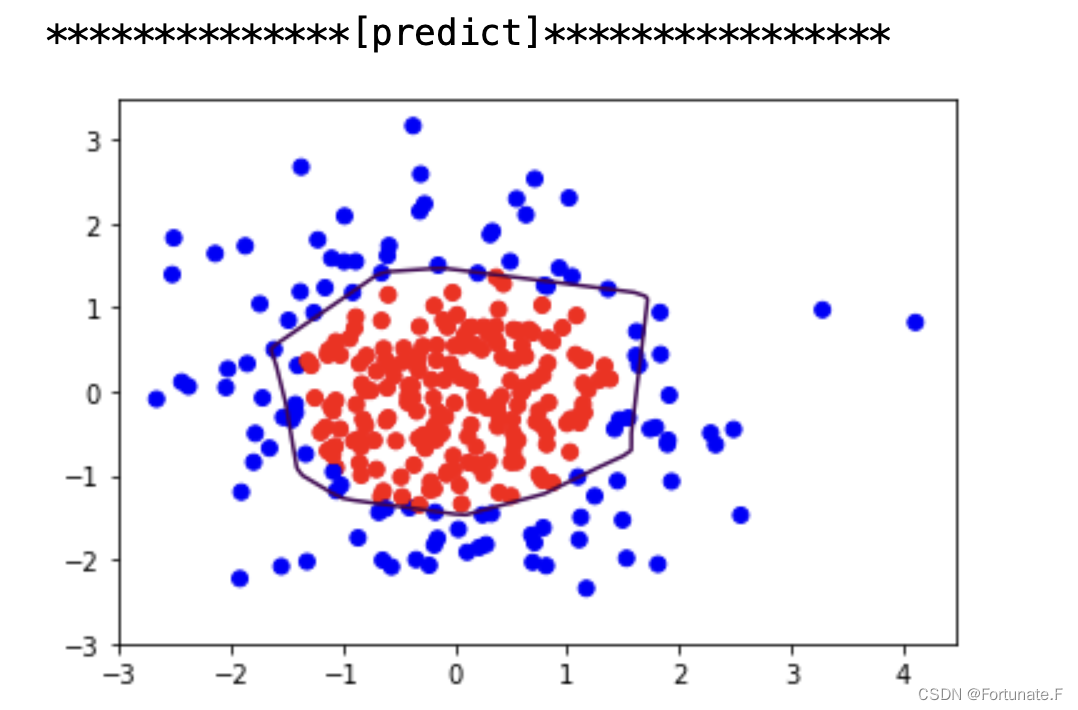 可以见到,加入L2正则化后的曲线更平缓,缓解了过拟合现象
可以见到,加入L2正则化后的曲线更平缓,缓解了过拟合现象















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











