







章节目录:
一、DSL语法
Elastisearch提供了一个可以执行查询的Json风格的DSL(domain-specific language 领域特定语言) 。这个被称为Query DSL。
- 典型结构:
QUERY_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
- 针对某个字段进行查询的结构:
{
QUERY_NAME:{
FIELD_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
}
}
- 基本结构 - 请求说明:
match_all:查询类型(代表查询所有),Es 中可以在query中组合非常多的查询类型完成复杂查询。from+size: 限定,完成分页功能;从第几条数据开始,每页有多少数据。sort:多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准。_source:指定返回结果中包含的字段名。
- 需求:查询索引名为 bank 的数据,根据 account_number 字段进行倒序排序,获取两条查询结果,并指定返回 balance、firstname 字段。
- 具体示例:
GET bank/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2,
"sort": [
{
"account_number": {
"order": "desc"
}
}
],
"_source": [
"balance",
"firstname"
]
}
- 结果查看:

二、match 匹配查询
2.1 match
2.1.1 精确匹配 -> 基本数据类型(非文本)。
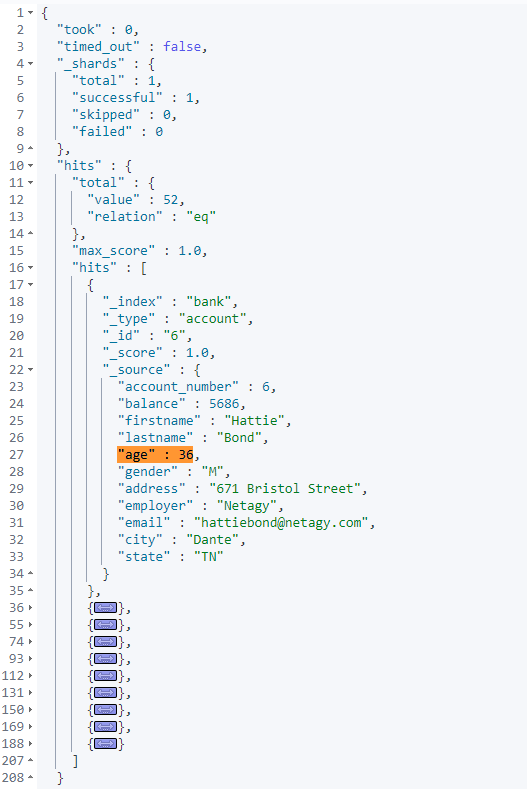
- 需求:查找匹配 age 为 36 的数据(非文本检索推荐使用
term)。 - 请求示例:
GET bank/_search
{
"query": {
"match": {
"age": 36
}
}
}
- 结果查看:
2.1.2 精确匹配 -> 文本字符串:
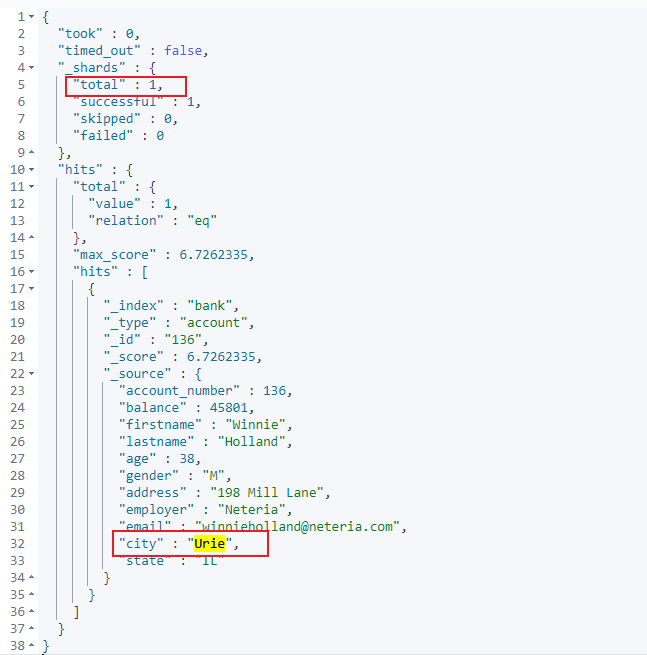
- 需求:查找匹配 city 为 Urie 的数据。
- 精确查找:
FIELD_NAME.keyword只有完全匹配时才会查找出存在的记录。 - 请求示例:
GET bank/_search
{
"query": {
"match": {
"city.keyword": "Urie"
}
}
}
- 结果查看:
2.1.3 模糊匹配 -> 文本字符串:
- 需求:查找匹配 city 包含 Urie 或 Lopezo 的数据。
match即全文检索,对检索字段进行分词匹配,会按照响应的评分_score排序,原理是倒排索引。- 请求示例:
GET bank/_search
{
"query": {
"match": {
"city": "Urie Lopezo"
}
}
}
- 结果查看:

2.2 match_phrase
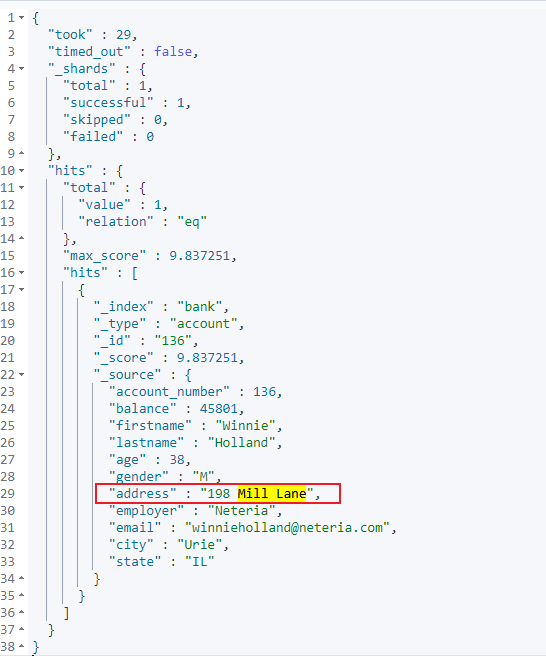
- 短语匹配:将需要匹配的值当成一整个单词(不分词)进行检索。
- 需求:检索 address 匹配包含短语 mill lane 的数据。
- 请求示例:
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill lane"
}
}
}
- 结果查看:
2.3 multi_math
- 多字段匹配:会对查询条件分词。
- 需求:检索 city 或 address 匹配包含 mill 的数据。
- 请求示例:
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": [
"city",
"address"
]
}
}
}
- 结果查看:

2.4 bool
-
复合查询:复合语句可以合并任何其他查询语句。这也就意味着,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑。
-
must:必须满足must所列举的所有条件。 -
must_not:必须不匹配must_not所列举的所有条件。 -
should:应该满足should所列举的条件。 -
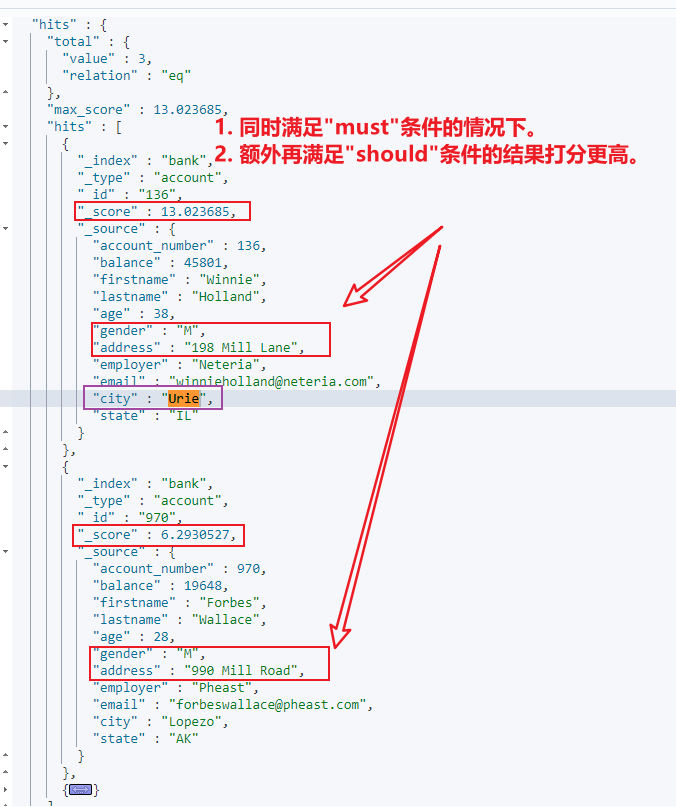
需求:查询 gender 为 M 且 address 包含 mill ,而 city 应该为 Urie 的数据。
-
请求示例:
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"should": [
{
"match": {
"city": "Urie"
}
}
]
}
}
}
- 结果查看:
三、filter 结果过滤
- 并不是所有的查询都需要产生分数,特别是某些仅用于
filtering过滤的文档,为了不计算分数,Es会自动检查场景并且优化查询的执行。 filter对结果进行过滤,且不计算相关性得分。- 需求:查询所有匹配 address 包含 mill 的文档,再根据 10000<=balance<=20000 进行过滤查询结果。
- 请求示例:
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
}
],
"filter": {
"range": {
"balance": {
"gte": "10000",
"lte": "20000"
}
}
}
}
}
}
- 结果查看:

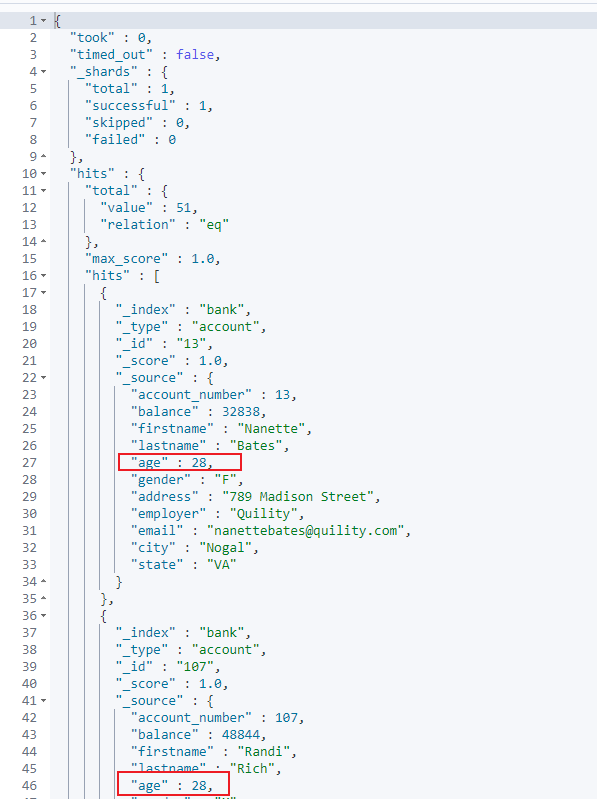
四、term 精确检索
- Es官方推荐使用
term来对于非文本字段进行精确检索。 - 注意事项:避免使用
term查询文本字段,如果要查询文本字段值,请使用 match 查询代替。 - 需求:查找 age 为 28 的数据。
- 请求示例:
GET bank/_search
{
"query": {
"term": {
"age": "28"
}
}
}
- 结果查看:
五、Aggregation 执行聚合
- 聚合语法:
GET /my-index-000001/_search
{
"aggs":{
"aggs_name":{ # 这次聚合的名字,方便展示在结果集中
"AGG_TYPE":{ # 聚合的类型(avg,term,terms)
}
}
}
}
- 需求:搜索 address 中包含 mill 的所有人的年龄分布、平均年龄及平均收支水平。
- 请求说明:
{"aggs":{"ageAgg":{"terms":{"field":"age","size":10}}}}- 聚合名为 ageAgg,聚合类型为
terms,聚合字段为 age,取聚合后前10个数据。 - 若
"size": 0则表示不显示命中结果,只看聚合信息。
- 具体示例:
GET bank/_search
{
"query": {
"match": {
"address": "Mill"
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10
}
},
"ageAvg": {
"avg": {
"field": "age"
}
},
"balanceAvg": {
"avg": {
"field": "balance"
}
}
},
"size": 0
}
- 结果查看:

六、基于Java的Es实战
6.1 依赖引入
<!--Es7 client-->
<properties>
<elasticsearch.version>7.4.2</elasticsearch.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
6.2 编写配置类
@Configuration
public class ElasticSearchConfig {
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient esRestClient() {
RestClientBuilder builder = RestClient.builder(
new HttpHost("yourIp", 9200, "http"));
return new RestHighLevelClient(builder);
}
}
6.3 测试配置类注入
@SpringBootTest
@RunWith(SpringRunner.class)
public class ElasticSearchTests {
@Resource
RestHighLevelClient esClient;
@Test
public void contextLoads() {
Assert.assertNotNull(esClient);
}
}
6.4 测试数据存储
@SpringBootTest
@RunWith(SpringRunner.class)
public class ElasticSearchTests {
@Data
static class User {
private String name;
private Integer age;
}
@Resource
RestHighLevelClient esClient;
/**
* 测试存储数据到索引
*/
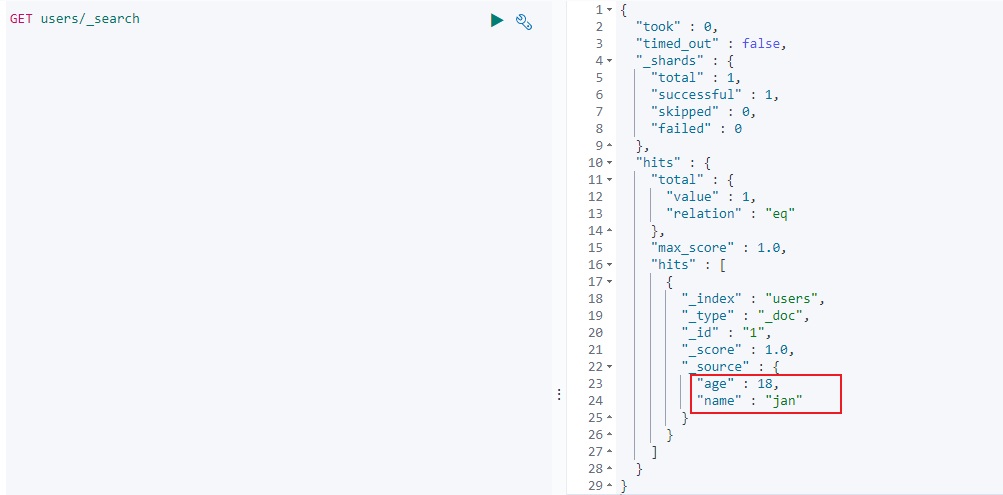
@Test
public void indexData() throws IOException {
// 创建index name id
IndexRequest indexRequest = new IndexRequest("users");
indexRequest.id("1");
// 将pojo转为Json进行封装
ElasticSearchTests.User user = new ElasticSearchTests.User();
user.setName("jan");
user.setAge(18);
String jsonString = JSON.toJSONString(user);
indexRequest.source(jsonString, XContentType.JSON);
// 执行操作
IndexResponse index = esClient.index(indexRequest, MallElasticSearchConfig.COMMON_OPTIONS);
System.out.println(index);
}
}
- 结果查看:
6.5 测试复杂条件检索
同本章第五节:<Aggregation 执行聚合> 需求一致,只是以API的方式进行实现。
@SpringBootTest
@RunWith(SpringRunner.class)
public class ElasticSearchTests {
@Resource
RestHighLevelClient esClient;
/* *
* 测试复杂条件检索
* 检索 `address` 中带有 `mill` 的人员年龄分布和平均收支水平
*/
@Test
public void searchData() throws IOException {
// 1. 创建检索请求
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("bank");
// 指定DSL(检索条件)
// 条件一:address 包含 mill
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));
// 条件二:聚合年龄值分布
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);
sourceBuilder.aggregation(ageAgg);
// 条件三:聚合平均收支水平
AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");
sourceBuilder.aggregation(balanceAvg);
System.out.println(" 检索条件: " + sourceBuilder);
searchRequest.source(sourceBuilder);
// 2. 执行检索
SearchResponse searchResponse = esClient.search(searchRequest, MallElasticSearchConfig.COMMON_OPTIONS);
// 3. 分析结果
System.out.println(" 响应结果: " + searchResponse);
// 3.1 获取所有的查询记录
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
// 数据字符串
String jsonString = hit.getSourceAsString();
System.out.println(" 命中的数据字符串: " + jsonString);
}
// 3.2 获取检索的分析信息(聚合数据等)
/* *
* 示例:
"buckets":[
{
"key":38,
"doc_count":2
},
{
"key":28,
"doc_count":1
},
{
"key":32,
"doc_count":1
}
]
*/
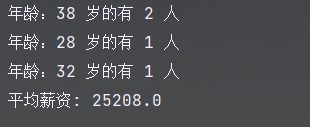
Aggregations aggregations = searchResponse.getAggregations();
Terms ageAgg1 = aggregations.get("ageAgg");
for (Terms.Bucket bucket : ageAgg1.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
System.out.println("年龄:" + keyAsString + " 岁的有 " + bucket.getDocCount() + " 人");
}
/* *
* 示例:
*
"avg#balanceAvg":{
"value":25208
}
*/
Avg balanceAvg1 = aggregations.get("balanceAvg");
System.out.println("平均薪资: " + balanceAvg1.getValue());
}
}
- 结果查看:
6.6 官方手册
其他使用说明,详见官方文档:https://www.elastic.co/cn/elasticsearch/
七、结束语
“-------怕什么真理无穷,进一寸有一寸的欢喜。”
微信公众号搜索:饺子泡牛奶。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









