



前置知识
KWDB有比较多的新概念,这与传统的数据库有所不同。为了更好的理解KWDB,所以在介绍KWDB之前,我会提前介绍一些前置知识,这会让后面看到KWDB的时候就能了解它的作用。
什么是多模数据库
多模数据库(Multimodal Database)是一种能够支持多种不同数据模型(如关系型、文档型、图形型、键值型等)并允许这些数据模型共存并在同一数据库系统中进行交互的数据库。与传统的单一数据模型数据库不同,多模数据库提供了更大的灵活性,可以在不同类型的数据存储需求之间进行切换和集成。
多模数据库的主要特点:
- 支持多种数据模型:可以同时处理关系型数据(如表格数据)、非关系型数据(如文档、图、键值对等)以及其他数据类型。这样,用户可以根据数据的特点选择最合适的数据模型,而不必依赖于单一的数据结构。
- 灵活性和兼容性:多模数据库能够处理不同来源和格式的数据,因此能够更好地支持多样化的数据分析需求。例如,它可以同时处理结构化数据(如传统的SQL表格)和半结构化或非结构化数据(如JSON文档、图形数据等)。
- 统一查询接口:尽管多模数据库支持不同类型的数据模型,但它们通常提供统一的查询接口,允许用户在多个数据模型间进行跨类型查询。例如,用户可以在关系型数据和图数据之间联合查询。
- 简化数据管理:多模数据库通过集成多个数据模型,可以减少数据存储和管理系统的复杂性。它使得用户无需使用多个不同的数据库系统(例如,一个用于关系型数据,另一个用于文档数据),从而简化了系统架构和运维工作。
- 适应复杂应用场景:多模数据库非常适合那些需要处理不同类型数据的复杂应用场景,例如物联网、大数据分析、社交网络、金融分析等场景,这些场景中的数据结构常常是多样化的。
什么是分布式数据库
分布式数据库(Distributed Database)是指将数据分布在多个物理位置或节点上,并能够通过网络进行互联的数据库系统。它通过协调多个数据库节点之间的数据存储和管理,实现数据的高可用性、可扩展性和容错性。分布式数据库使得数据存储和访问不再局限于单一机器或服务器,而是分布在多个位置上,可以是不同的服务器、数据中心或地理位置。
分布式数据库的主要特点:
-
数据分布性:
- 数据被划分并存储在多个物理节点上。每个节点可以存储数据库的一部分数据,也可以是完整的副本。数据的分布通常是透明的,用户不需要关心数据存放的位置。
-
高可用性和容错性:
- 分布式数据库系统通过数据复制和冗余机制保证高可用性。当某个节点发生故障时,其他节点可以接管工作,系统仍然可以提供服务。
- 数据的副本在多个节点上同步更新,确保即使部分节点发生故障,系统仍然能够保证数据的持续可访问性。
-
水平扩展性:
- 分布式数据库能够通过增加更多的节点来水平扩展,以适应不断增长的数据量和查询需求。这与传统的单一数据库系统的垂直扩展(增加硬件资源)不同。
-
透明性:
- 位置透明性:用户不需要知道数据存储在具体哪个节点上,可以像访问本地数据库一样访问分布式数据库。
- 访问透明性:用户可以无缝地查询和修改数据,系统会自动将请求路由到合适的节点。
- 复制透明性:多个副本的管理对用户透明,用户无需关心数据是否被复制。
-
一致性:
- 分布式数据库需要在多个节点间保持数据一致性,常见的一致性模型有强一致性、最终一致性等。分布式事务协议(如两阶段提交、Paxos协议等)确保跨节点的操作具有一致性。
-
并发控制和事务管理:
- 分布式数据库通常需要处理并发访问问题,保证多个客户端访问数据时不产生冲突或数据不一致。分布式事务和锁机制确保在多个节点间的事务能得到有效管理。
分布式数据库的类型:
-
共享存储型(Shared Storage):
- 所有节点都共享一个中央存储系统,节点之间通过网络访问数据。它的优点是数据访问非常快速,但扩展性相对较差。
-
共享无存储型(Shared Nothing):
- 每个节点都有自己独立的存储,数据分布在不同的节点上,节点之间通过网络交换数据。这种架构提供了更好的可扩展性和容错性,是现代分布式数据库的主流架构。
-
混合型:
- 结合了共享存储和共享无存储的特点,部分数据可能共享存储,部分数据分布在各个节点上。
分布式数据库的优势:
- 高可用性:系统能够在部分节点故障时继续运行,确保服务的不中断。
- 弹性扩展:可以根据需求增加或减少节点,实现水平扩展。
- 数据冗余:通过数据复制和备份机制,提高数据的可靠性和容错能力。
- 分布式计算:可以在多个节点上并行处理数据,提升系统性能。
总的来说,分布式数据库能够处理大规模的数据存储和查询需求,是现代大数据应用和云计算环境中的核心技术。
KWDB产品介绍
KaiwuDB 是一款面向 AIoT 场景的分布式、多模融合、支持原生 AI 的数据库产品,支持同一实例同时建立时序库和关系库并融合处理多模数据,具备时序数据高效处理能力,具有稳定安全、高可用、易运维等特点。面向工业物联网、数字能源、车联网、智慧产业等领域,KaiwuDB 提供一站式数据存储、管理与分析的基座。
KWDB产品架构
相比传统的数据库,KaiwuDB 提供多模数据管理能力,支持不同数据模型的统一存储,助力企业跨部门、跨业务统一管理数据,实现多业务数据融合,支撑多样化的应用服务。KaiwuDB 的产品架构如下图所示:
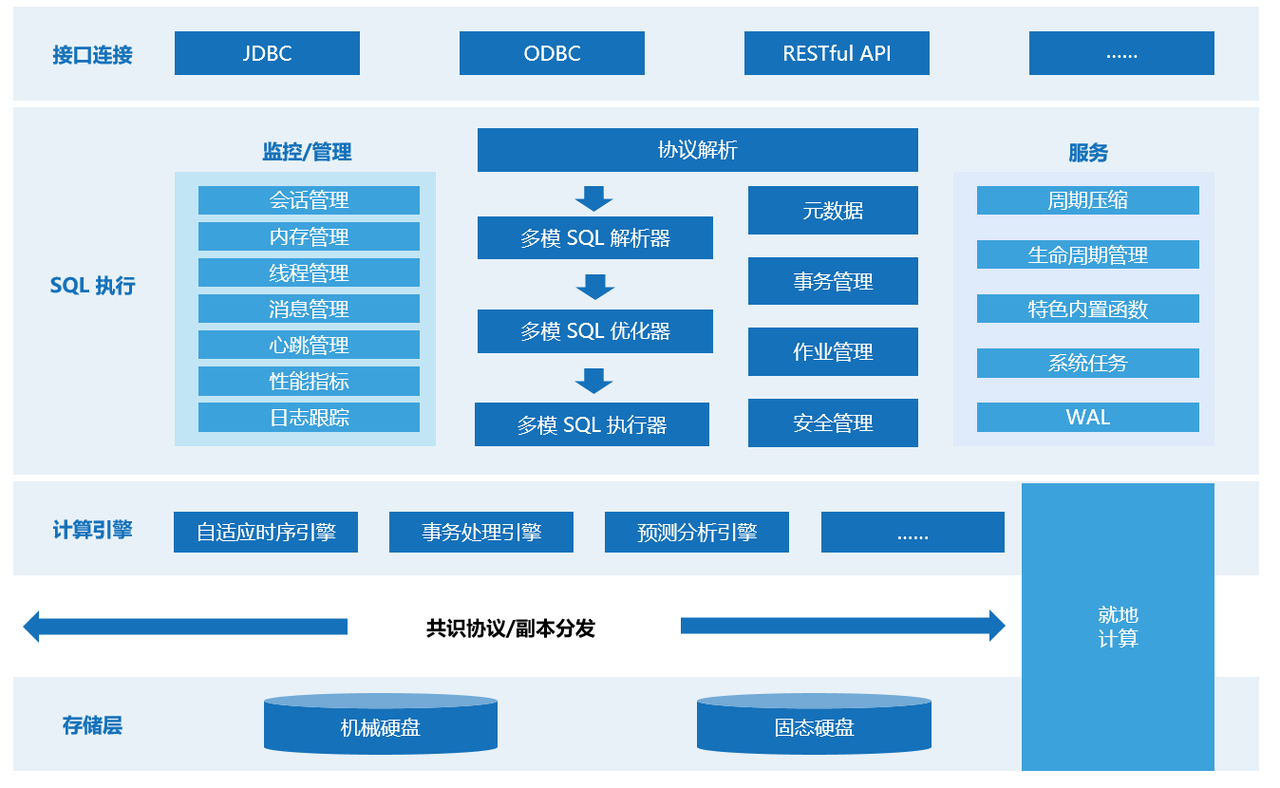
- 数据存储:采用行列混存架构,支持固态硬盘、机械硬盘等各类存储设备。
- 数据副本:采用 Shared Nothing 架构,基于 Raft 协议的高可用、多副本架构,支持数据均衡及容错,保障数据服务不中断。
- 执行计算:融合多种数据计算引擎,根据不同模型数据特征选择不同的存储、计算模式,对外提供统一的接口,提供多种分析计算能力,提升查询效率。
- 自适应时序引擎:支持多种时序数据特色的复杂查询和多维聚合方式。与传统关系数据库相比,KaiwuDB 具备优异的查询性能。另外,KaiwuDB 提供 5-30 倍的压缩能力,数据压缩后无需解压缩即可使用。
- 事务处理引擎:支持分布式事务和 MVCC(Multi-Version Concurrency Control,多版本并发控制),具备注释、视图、约束、索引、序列等功能。
- 预测分析引擎:提供模型生命周期管理、模型训练、模型推理预测等功能。任何拥有数据库应用开发背景的开发人员都可以轻松地完成模型管理和预测等操作。
- 系统管理:提供系统连接、身份认证、权限管理、资源管理等多种系统管理方式。
- 生态工具与兼容:提供数据库操作、监控管理等可视化工具,兼容 EMQXopen in new window、Kafkaopen in new window、Telegrafopen in new window 等第三方工具。
KWDB产品特性
- 更高的处理性能
- 优化海量时序数据的高速读写,具备时序数据高效处理能力。
- 提供插值查询、数学函数查询等丰富的时序特色查询。
- 简化查询分析难度,提高应用效率,提升用户使用体验。
- 更低的运管成本
- 提供多模数据管理能力,统一存储不同数据模型,实现多业务数据融合,支撑多样化的应用服务。
- 企业采用一套数据库系统就能够跨部门、跨业务统一管理数据,降低企业信息化设施的采购成本和运维成本。
- 更低的存储成本
- 支持 5-30 倍压缩比和数据生命周期管理。
- 根据数据的重要程度,灵活制定数据保存策略,使用最少的的节点和资源满足业务需求,极大地降低存储成本。
- 支持多级存储策略,进一步优化存储资源的利用,降低存储开销。
- 更高的数据价值
- 轻量化内置自治优化引擎,用 AI 驱动数据库自治。
- 提供一站式可插拔的 AI 预测分析引擎,通过 SQL 函数灵活导入并部署预训练模型,用 AI 驱动对海量多模数据的挖掘,提升数据整体的价值。
- 更安全的管理
- 支持数据库审计与加密等功能以保证安全性,保障数据库在业务场景下稳定安全的运行。
- 支持多种身份认证方式协同工作,用户密码复杂度、用户名和密码的有效期、最大连接错误次数等均可灵活配置。
- 支持开启三权分立模式,降低因单一用户或角色权限过大而引发的安全风险。
- 更简易的使用
- 为系统管理员提供细粒度全方位的数据库监控接口,大幅降低管理成本。
- 为运维人员提供多种异构数据库的数据快速迁移方案,降低数据迁移成本。
- 为数据分析专家提供多样化编程接口和 AI 集成能力,提高数据挖掘的便捷性。
- 为开发者提供简单接口,与第三方工具无缝集成,降低开发难度,提升开发使用效率。
- 提供 MCP Server,通过自然语言与 KaiwuDB、大模型及服务实现高效交互和商业智能。
KWDB产品体验
介绍了那么多的KWDB特性,功能,接下来就开始上手使用。
使用Docker快速安装KWDB
官方提供了Docker安装脚本,我们直接使用脚本就能快速的进行KWDB安装,直接按照这个示例使用就行。
➜ docker docker run -d --privileged --name kwdb \
-p 26257:26257 \
-p 8080:8080 \
-v /var/lib/kaiwudb:/kaiwudb/deploy/kaiwudb-container \
--ipc shareable \
-w /kaiwudb/bin \
kwdb/kwdb \
./kwbase start-single-node \
--insecure \
--listen-addr=0.0.0.0:26257 \
--http-addr=0.0.0.0:8080 \
--store=/kaiwudb/deploy/kaiwudb-container
Unable to find image 'kwdb/kwdb:latest' locally
latest: Pulling from kwdb/kwdb
9b857f539cb1: Pull complete
24fd278016bd: Pull complete
e915a1b38e6a: Pull complete
Digest: sha256:9dda946922a69557e20be9f1d99c504c467fba6351bb8af0a34fe42711cde73f
Status: Downloaded newer image for kwdb/kwdb:latest
a7f598722140c5b31dab0df03b1def6ace3cd50eb8547e74aca46885bc58660b
参数说明:
-d:后台运行容器并返回容器 ID。--name kaiwudb:指定容器名称为kaiwudb,便于后续管理。--privileged:给予容器扩展权限。--ulimit memlock=-1:取消容器内存大小限制。--ulimit nofile=$max_files:设置容器内进程可以打开的最大文件数。-p $db_port:26257:将容器的 26257 端口(数据库主端口)映射到主机的指定端口。-p $http_port:8080: 将容器的 8080 端口(HTTP 端口)映射到主机的指定端口。-v:设置容器目录映射:- 将主机的
/var/lib/kaiwudb目录挂载到容器内的/kaiwudb/deploy/kaiwudb-container目录,用于持久化数据存储。 - 安全模式下,将主机的
/etc/kaiwudb/certs目录挂载到容器内的/kaiwudb/certs目录,用于存放证书和密钥。
- 将主机的
--ipc shareable:允许其他容器共享此容器的IPC命名空间。-w /kaiwudb/bin:将容器内的工作目录设置为/kaiwudb/bin。$kaiwudb_image:容器镜像变量,需替换为实际的镜像名称及标签, 例如kaiwudb:2.2.0。./kwbase start: 容器内运行的数据库启动命令, 根据安全模式和非安全模式有所不同:--insecure:(仅非安全模式)指定以非安全模式运行。--certs-dir=/kaiwudb/certs:(安全模式)指定证书目录位置。--listen-addr=0.0.0.0:26257:指定数据库监听的地址和端口。--http-addr=0.0.0.0:8080:指定 HTTP 接口监听的地址和端口。--store=/kaiwudb/deploy/kaiwudb-container:指定数据存储位置。--tlcp:(TLCP 安全模式)使用 TLCP 加密协议。
使用dbeaver连接到KWDB
注意,上面的docker安装使用的事非安全模式,所以是没有密码的,数据库的端口为26257,使用pg协议,所以在使用 dbeaver 连接的时候,可以直接使用postgre数据库类型进行连接。PS:当然了,kwdb也提供了连接工具,因为我个人电脑里面已经有了dbeaver了,直接使用就行。如果你喜欢navicat 也可以直接使用navicat进行连接,就不做多的解释了。
首先打开dbeaver,选择postgreSQL连接数据类型。
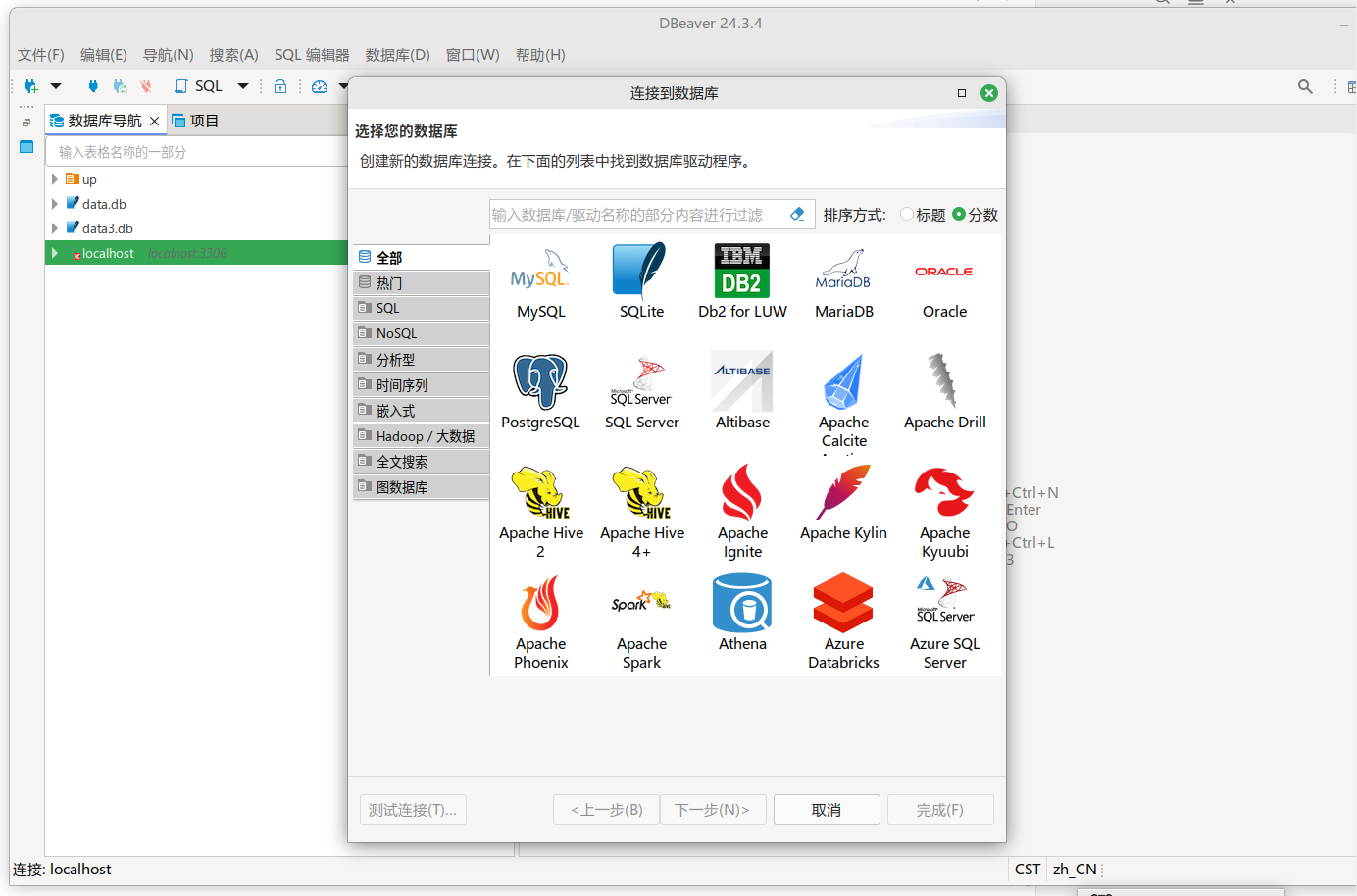
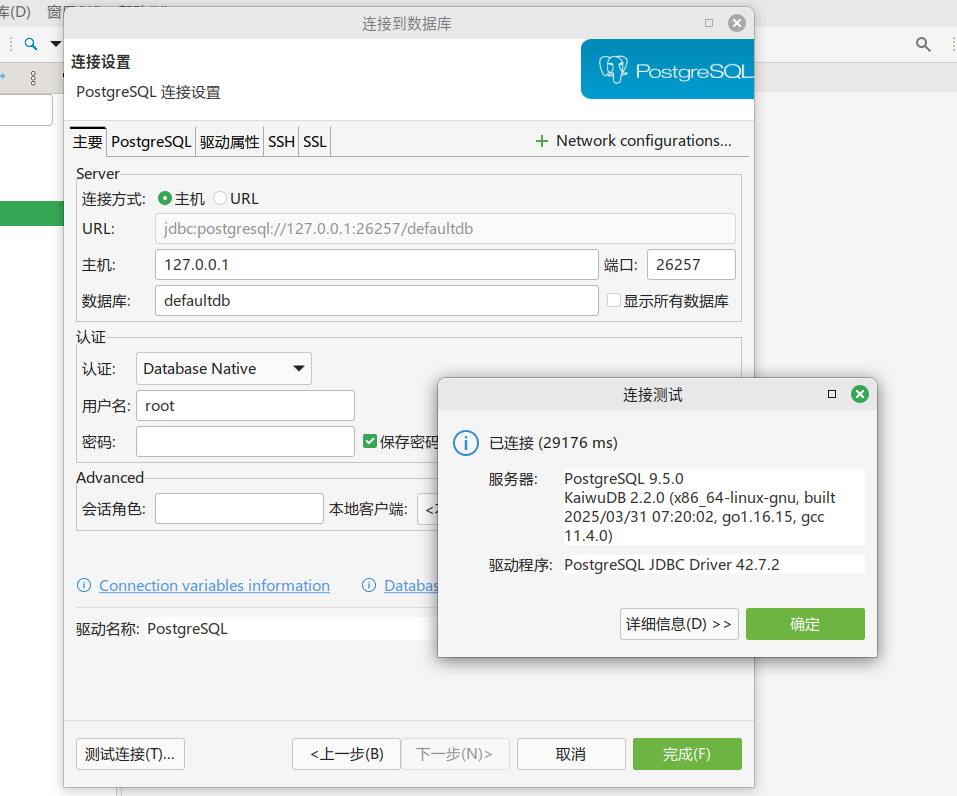
设置主机为本机127.0.0.1,端口为26257,数据库为defaultdb,用户名为root,密码为空(非安全模式),测试链接后可能需要下载驱动,下载完成再点击测试连接,弹出成功连接到kuaiwudb提示就OK了。点击确定到下一步
成功打开数据库
KWDB基础使用
作为一款多模数据库系统,KaiwuDB 支持用户在一个 KaiwuDB 实例中创建一个或多个数据库对象(Database)用来管理时序和关系数据。其中专门用于存储和管理时间数据的数据库对象为时序数据库(Time Series Database)。时序数据库中包括 public 模式和用户自定义的时序表。
KWDB关系数据库操作
新建数据表
创建一个user表
CREATE TABLE public.user (
id SERIAL NOT NULL,
"name" varchar(20) COLLATE "en-US" NOT NULL,
age int4 NOT NULL,
CONSTRAINT newtable_pk PRIMARY KEY (id ASC)
);
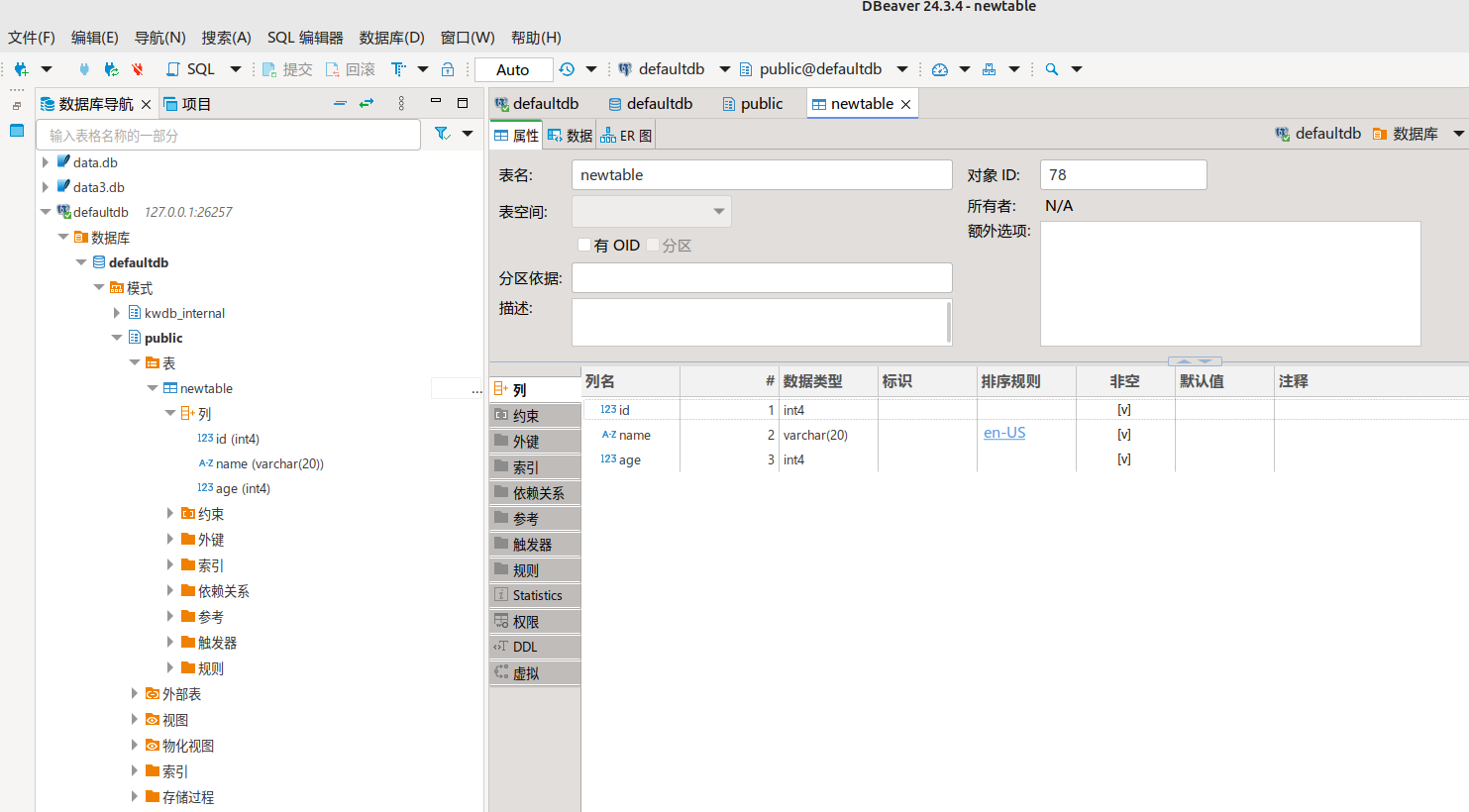
插入一条数据
插入几条数据
INSERT INTO public."user" ("name",age)
VALUES ('张三',18);
INSERT INTO public."user" ("name",age)
VALUES ('李四',28);
INSERT INTO public."user" ("name",age)
VALUES ('王五',30);
查询数据
select * from public."user" u where u.age = 18;
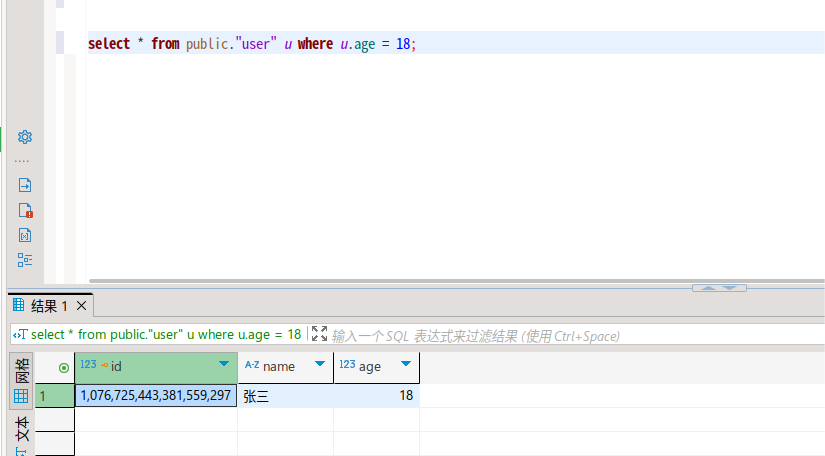
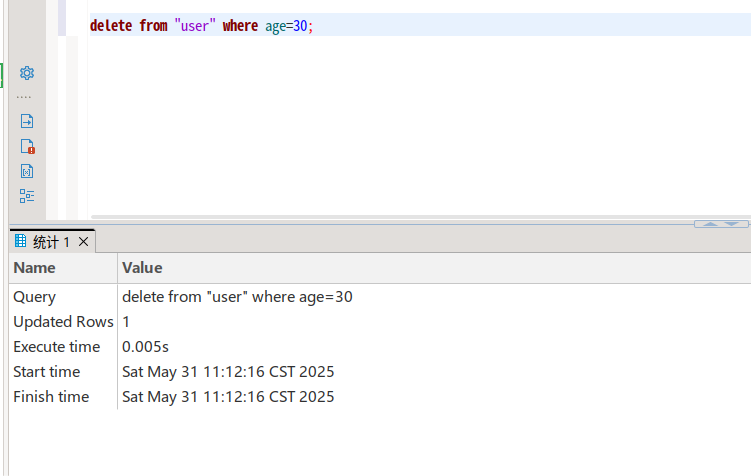
删除数据
delete from "user" where age=30;
总结
目前来看,KWDB的基本数据是没有任何问题,很丝滑。
KWDB时序数据库操作
时序数据库前置知识点
在时序数据库中,tag 和 列(column)是两个重要的概念,它们用于存储和组织数据,但在结构和用途上有所不同。
-
Tag:
- 定义:在时序数据库中,
tag是一种元数据,用来标识和描述时间序列数据的不同特征。它通常用于存储一些定性的、标识性的字段,比如设备ID、位置、用户ID等。 - 用途:
tag用于数据查询时的过滤或分组。通过标签可以非常方便地对数据进行分类,进而高效地进行查询。 - 特点:
tag是索引字段,查询时可以帮助快速定位相关数据。它通常是定性的,不会随着时间发生变化。 - 例子:假设你在监控设备的温度数据,每个设备有不同的ID和位置作为
tag: textCopy Codetemperature,device_id=device_1,location=office value=22.5
- 定义:在时序数据库中,
-
列(Column):
- 定义:
列是实际存储的数值数据字段,通常包含时间序列中记录的测量值。例如,设备的温度、湿度、压力等。 - 用途:
列存储的是具体的数值数据,通常是度量值。它们是时间序列的核心数据部分,可以是数值类型、字符串类型等。 - 特点:
列通常是随着时间变化的,存储了具体的度量数据,并且在查询时会进行数值计算(如求平均值、最大值等)。 - 例子:上述
temperature数据中的value就是一个列,它存储的是具体的温度数据。
- 定义:
总结关系:
- Tag 是描述数据特征的元数据,通常用于标识或分类数据,而 列 存储的是时间序列数据的实际度量值。
tag是索引字段,帮助快速定位数据,列是核心数据字段,记录着具体的度量数值。- 在查询时,你通常会使用
tag来过滤数据并选择特定的时间序列,使用列来读取或计算具体的数值数据。
简单来说,tag 是用来标识或分类的字段,而 列 是用来存储数值数据的字段。
KaiwuDB 时序数据库支持数据类型
- 时间类型
- 数值类型
- 布尔类型
- 字符类型
下表列出了 KaiwuDB 支持修改的时序数据类型、默认宽度、最大宽度、可转换的数据类型和特殊要求。
| 原数据类型 | 默认宽度 | 最大宽度 | 支持转换的数据类型 | 说明 |
|---|---|---|---|---|
| TIMESTAMP | - | - | TIMESTAMPTZ、INT8、FLOAT4、FLOAT8 | 标签不支持该类型。TIMESTAMP 转 INT8 时,输出结果固定为毫秒精度的数字,即 13 位数字。TIMESTAMP 转 FLOAT4 时,输出结果只能保证约前 7 位有效数字的精度。TIMESTAMP 转 FLOAT8 时,输出结果只能保证约前 15-17 位有效数字的精度。 |
| TIMESTAMPTZ | - | - | TIMESTAMP、INT8、FLOAT4、FLOAT8 | 标签不支持该类型。TIMESTAMPTZ 转 INT8 时,输出结果固定为毫秒精度的数字,即 13 位数字。TIMESTAMPTZ 转 FLOAT4 时,输出结果只能保证约前 7 位有效数字的精度。TIMESTAMPTZ 转 FLOAT8 时,输出结果只能保证约前 15-17 位有效数字的精度。 |
| INT2 | 2 字节 | - | INT4、INT8、VARCHAR | INT2 转 VARCHAR 时,VARCHAR 的最小宽度为 6。 |
| INT4 | 4 字节 | - | INT8、VARCHAR | INT4 转 VARCHAR 时,VARCHAR 的最小宽度为 11。 |
| INT8 | 8 字节 | - | VARCHAR | INT8 转 VARCHAR 时,VARCHAR 的最小宽度为 20。 |
| FLOAT4 | 4 字节 | - | FLOAT、VARCHAR | REAL 转 VARCHAR 时,VARCHAR 的最小宽度为 30。 |
| FLOAT8 | 8 字节 | - | VARCHAR | FLOAT 转 VARCHAR 时,VARCHAR 的最小宽度为 30。 |
| CHAR | 1 字节 | 1023 | NCHAR、VARCHAR、NVARCHAR | CHAR 转 NCHAR 或 NVARCHAR 时,NCHAR 或 NVARCHAR 的宽度不得小于原宽度的 ¼。 |
| VARCHAR | 254 字节 | 65536 字节 | CHAR、NCHAR、NVARCHAR、INT2、INT4、INT8、REAL、FLOAT | VARCHAR 转 NCHAR 或 NVARCHAR 时,NCHAR 和 NVARCHAR 的宽度不得小于原宽度的 ¼。 |
| NCHAR | 1 字符 | 254 字符 | CHAR、VARCHAR、NVARCHAR | NCHAR 转 CHAR 或 VARCHAR 时,CHAR 和 VARCHAR 的宽度不得小于原宽度的 4 倍。 |
| NVARCHAR | 63 字符 | 16384 字符 | CHAR、VARCHAR、NCHAR | NVARCHAR 转 CHAR 或 VARCHAR 时,CHAR 和 VARCHAR 的宽度不得小于原宽度的 4 倍。标签不支持该类型。 |
创建时序数据库
CREATE TS DATABASE ts_db;
SHOW databases;
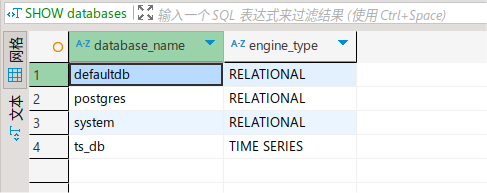
创建时序数据表
use ts_db;
CREATE TABLE sensor_data (
k_timestamp TIMESTAMP NOT NULL,
temperature FLOAT NOT NULL,
humidity FLOAT,
pressure FLOAT
) TAGS (
sensor_id INT NOT NULL,
sensor_type VARCHAR(30) NOT NULL
) PRIMARY TAGS (sensor_id);
show tables;
插入时序数据
INSERT INTO public.sensor_data (k_timestamp,temperature,humidity,pressure,sensor_id,sensor_type)
VALUES ('now()',2.0,3.0,4.0,3,'2');
查询时序数据
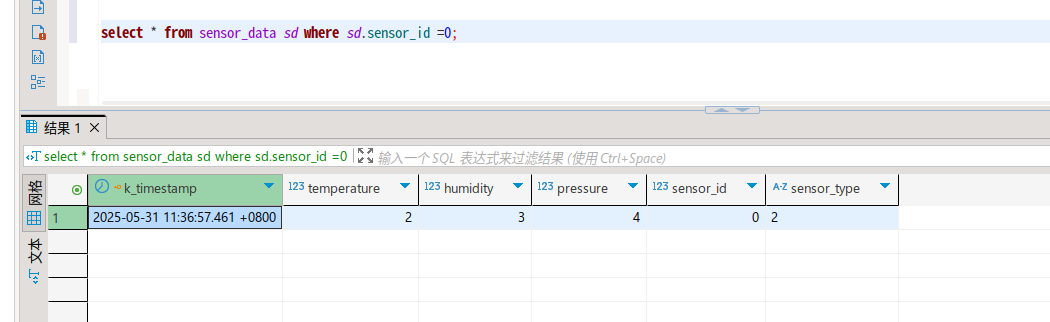
select * from sensor_data sd where sd.sensor_id =0;
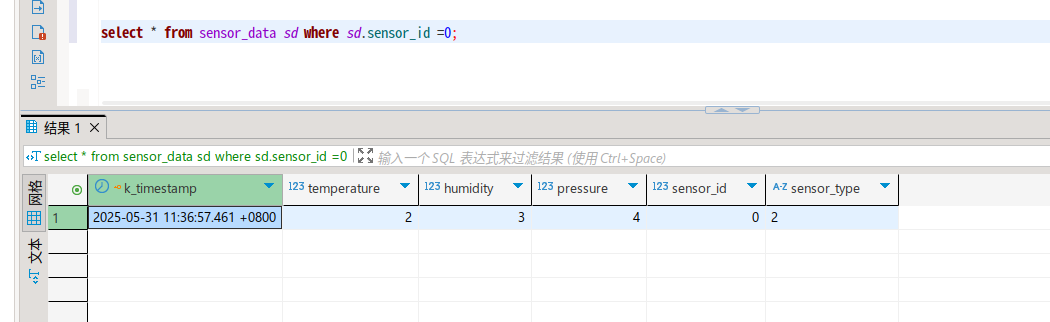
删除数据
delete from sensor_data sd where sd.sensor_id = 0;
总结
从初见KWDB到使用KWDB,KWDB非常的棒,目前已经浅试了一下,在关系数据库和时序数据库的存储上非常优秀,因为兼容PG协议,这使得也不需要额外的学习成本,可以快速的上手KWDB,还能和其他的业务数据库进行快速的迁移替换。另外作为国产数据库,能够达到这样的水准。特别是超高的压缩率,和分布式的扩展能力,还有完整的解决方案,生态能力。我相信,KWDB肯定会越来越好。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









