







 文章提出了一个新的声纹识别中音频伪造的分类法,从应用场景出发,区分假冒攻击和伪装欺骗,并根据伪造音频的生成和评价方法进行细分。研究关注了ASVspoof竞赛在推动反伪造策略发展的作用,旨在提高声纹识别系统的安全性。
文章提出了一个新的声纹识别中音频伪造的分类法,从应用场景出发,区分假冒攻击和伪装欺骗,并根据伪造音频的生成和评价方法进行细分。研究关注了ASVspoof竞赛在推动反伪造策略发展的作用,旨在提高声纹识别系统的安全性。
声纹识别,又称说话人识别,是根据语音信号中的声纹特征来识别话者身份的过程,也是一种重要的生物认证手段。历经几十年的研究,当前声纹识别系统已取得了令人满意的性能表现,并在安防、司法、金融、家居等诸多领域中完成部署,有着广阔的应用前景。
然而,大量证据表明,这些系统在实际应用中容易受到恶意伪造行为的影响,致使系统的安全性存在很大隐患,在很大程度上限制了声纹识别技术的大规模推广应用。为了解决这一安全隐患,当前研究界和产业界从技术导向出发,对伪造攻击进行分类,探索相应的对抗策略。其中,ASVspoof竞赛系列最具代表。该赛事聚焦在声纹识别中的假冒闯入攻击与对策任务,提供了一个公平的评测平台(包括标准的数据、协议和评价),极大地促进了研究社区的发展,也积累了诸多有效的技术手段。
本文从应用导向出发,对声纹识别中的音频伪造问题进行梳理,提出了一种新的分类法,并介绍了各类伪造技术的基本概念和代表对策。该研究工作《An Application-Oriented Taxonomy on Spoofing, Disguise and Countermeasures in Speaker Recognition》近期已在领域权威杂志《APSIPA Transactions on Signal and Information Processing》上发表。这项工作的主要贡献包括:
- 从不同的应用场景(Application)出发,衍生出不同的伪造行为(Fake action)。这些应用场景包括访问控制、监听和司法,伪造行为分为假冒攻击(Spoofing attack)和伪装欺骗(Disguise cheating)两大类。
- 进一步,根据伪造音频的生成模式(Production,来自人还是机器)和评价方法(Evaluation,通过听觉感知还是自动检测)的不同,对两大类伪造行为进一步细分,划分出不同的伪造技术手段(Technique),形成了从应用层到技术层的五层概念图(如下图所示)。
- 本工作更多是以应用为导向,对音频伪造进行宏观划分;因此面向读者可以是领域内的专家或技术人员,也可以是对领域感兴趣的学生或工程师。
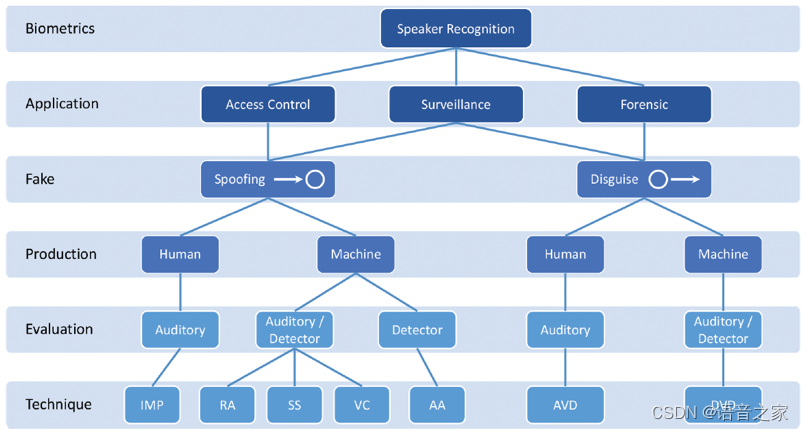
以应用为导向,声纹识别中的音频伪造分类图
原文链接(可下载全文):
https://www.nowpublishers.com/article/Details/SIP-2022-0017
参考文献:
Lantian Li, Xingliang Cheng, Thomas Fang Zheng. An Application-Oriented Taxonomy on Spoofing, Disguise and Countermeasures in Speaker Recognition. In APSIPA Transactions on Signal and Information Processing, 11(2), 2022.

















 2740
2740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









