






一 介绍
在机器人领域,视觉-语言-动作 (VLA) 模型的发展经历了显著的演变,这得益于计算机视觉和自然语言处理领域的进步。VLA 模型代表了一类旨在处理多模态输入的模型,整合了来自视觉、语言和动作的信息。这些模型对于实现具身智能至关重要,使机器人能够理解物理世界并与之互动。
以下是 VLA 模型发展的时间线:
早期阶段: 计算机视觉和自然语言处理的集成大约在 2015 年开始,随着视觉问答 (VQA) 系统的出现。这些系统可以回答关于图像的问题,标志着结合视觉和语言理解的早期步骤。
VLM 的进步: Transformer 架构以及 ViT(视觉 Transformer)和 CLIP(对比语言-图像预训练)等模型的引入,极大地推动了 VLM 的发展。谷歌的 PaLI(路径语言-图像模型)通过执行各种跨模态任务,进一步推动了该领域的发展。
向 VLA 过渡: PaLIX 和 PaLME(路径语言模型具身)将大规模的视觉语言预训练与机器人数据相结合,促进了从 VLM 到 VLA 的转变。
关键的 VLA 模型:
- RT1(机器人 Transformer 1): 标志着 VLA 领域的一个关键步骤,展示了使用预训练的视觉语言模型来指导机器人动作。
- RT2(机器人 Transformer 2): 是 RT1 的升级版,表现出更强的泛化能力,尤其是在不熟悉的环境中。它引入了一种“思维链”机制,提高了长期规划和低级技能的学习。RT2 是第一个控制机器人的 VLA 模型,实现了符号理解、推理和人类识别等能力。
- TinyVLA: 是一种更紧凑的 VLA 模型解决方案,减少了对大量预训练数据的需求,并提高了推理速度。它解决了双手动环境中的挑战,无需改变网络结构即可适应不同的动作维度。
现状: VLA 模型是具身智能中指令跟随任务的基础,依赖于视觉编码器、语言编码器和动作解码
器。目前的研究重点是获取高质量的预训练视觉表征、增强低级控制策略以及改进长期任务规划。
VLA 模型允许单个模型执行感知、决策和控制的整个计算过程。将动作数据作为一种模态使得机器人动作成为思维链的一部分,从而在决策和控制之间形成更流畅和逻辑的连接。
二 例子
Octo模型:🐙 Octo: An Open-Source Generalist Robot Policy
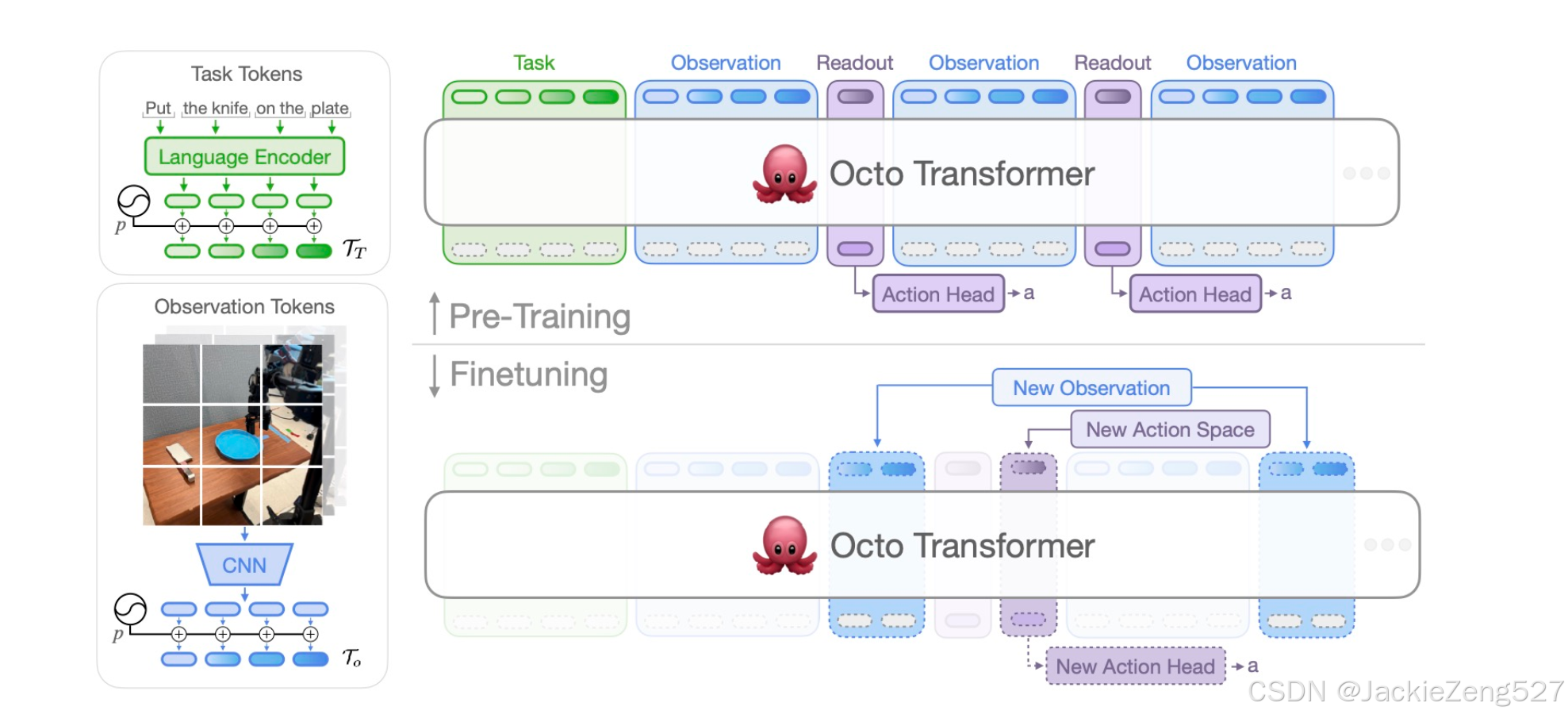
- 通过预训练在多样化的机器人数据集上的大型策略,可以将机器人学习转变为:不需要从头开始训练新的策略,这样的通用机器人策略可以通过少量领域内数据进行微调,并广泛泛化。
- 为了在各种机器人学习场景、环境和任务中广泛适用,这样的策略需要处理多样化的传感器和动作空间,适应各种常用的机器人平台,并能够快速高效地在新领域进行微调。
- 引入了Octo,一个基于Transformer的大型策略,它在Open X-Embodiment数据集中训练了800k个轨迹,这是迄今为止最大的机器人操作数据集。
三 核心原理
VLA(Vision-Language-Action)模型的核心算法原理涉及将视觉信息、语言指令和动作决策有效地整合,从而提升机器人对复杂环境的理解和适应能力[5]. VLA模型能够直接从给定的语言指令和视觉信号生成机器人可执行的动作[5].
VLA模型主要分为三类范式:
- 显式端到端 VLA:这是最常见和最经典的范式。它通常将视觉和语言信息压缩成联合的表征,然后基于这个表征重新映射到动作空间,生成对应的动作[5]. 这类端到端的范式依赖于先前广泛的研究先验,通过不同的架构(diffusion/ transformer/dit),不同的模型大小,不同的应用场景(2D/3D),不同的任务需求(从头训练/下游微调),产生不同的方案,并取得了不错的性能[5].
- 隐式端到端 VLA
- 分层端到端 VLA
VLA模型由视觉感知处理模块、语言指令理解模块以及生成机器人可执行动作的策略网络构成[5]. 视觉-语言模型预测控制(VLMPC)是一种机器人操作框架,它利用视觉语言模型(VLM)强大的感知能力,并将其与模型预测控制(MPC)相结合。VLMPC 采用条件动作采样模块,该模块以目标图像或语言指令作为输入,并利用 VLM 来采样一组候选动作序列[1]. 然后,设计一个轻量级的动作条件视频预测模型,以生成一组以候选动作序列为条件的未来帧[1]. VLMPC 借助 VLM,通过分层成本函数生成最佳动作序列,该函数制定了当前观察和目标图像之间的像素级和知识级一致性[1].
为了进一步改进 VLA 模型,可以通过在线强化学习 (RL) 进行微调。一种名为 iRe-VLA 的框架,在强化学习和监督学习之间迭代,以有效地改进 VLA 模型,利用 RL 的探索性优势,同时保持监督学习的稳定性[2].
总的来说,VLA 模型的核心在于利用大型预训练模型,结合视觉和语言信息,通过不同的策略网络生成可执行的机器人动作,并可以通过强化学习等方法不断优化[2][5].
Citations:
[1] https://www.roboticsproceedings.org/rss20/p106.pdf
[2] Improving Vision-Language-Action Model with Online Reinforcement Learning
[3] 2025年,自动驾驶即将开“卷”的端到端大模型 2.0 - VLA (Vision Language Action) - OFweek人工智能网
[4] https://cs.gmu.edu/~xiao/papers/vlm_social_nav.pdf
[5] 国内首个!面向工业与科研的视觉语言动作VLA算法实战教程!-CSDN博客
[6] QUAR-VLA: Vision-Language-Action Model for Quadruped Robots
[7] https://arxiv.org/pdf/2405.14093.pdf
[8] https://alinlab.kaist.ac.kr/resource/2024_FALL_AI602/AI602_Lec6_VLA.pdf
[9] 复现OpenVLA:开源的视觉-语言-动作模型及原理详解-CSDN博客
[10] VLAS: Vision-Language-Action Model with Speech Instructions for Customized Robot Manipulation | OpenReview
[11] https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/00808.pdf
[12] Diffusion-VLA:通过统一扩散与自回归方法扩展机器人基础模型 - PNP ROBOTICS集智联机器人 Franka机器人官方合作
[13] https://www.youtube.com/watch?v=o5ONDdbReAA
[14] https://www.researchgate.net/figure/The-Design-Variables-for-VLA-Design-Optimization-Formulation_tbl1_297758923
[15] Diffusion-VLA:通过统一扩散和自回归扩展机器人基础模型_牛喀网-具身智能开发者生态
[16] FAST: Efficient Action Tokenization for Vision-Language-Action Models
[17] DeeR-VLA: Dynamic Inference of Multimodal Large Language Models for Efficient Robot Execution | OpenReview
[18] https://www.eet-china.com/mp/a239666.html
[19] https://www.researchgate.net/publication/388459733_Improving_Vision-Language-Action_Model_with_Online_Reinforcement_Learning
[20] 清华新VLA框架加速破解具身智能止步实验室"魔咒",LLM内存开销平均降低4-6倍。 | 量子位

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









