







VLA模型最早见于机器人行业。2023年7月28日,谷歌DeepMind发布了全球首个控制机器人的视觉语言动作(VLA)模型RT-2。其后,这个模型概念快速扩散到智驾领域。
VLA模型是在视觉语言模型(VLM)的基础上发展而来的。VLM是一种能够处理图像和自然语言文本的机器学习模型,它可以将一张或多张图片作为输入,并生成一系列标记来表示自然语言。然而,VLA不仅限于此,它还利用了机器人或汽车运动轨迹的数据,进一步训练这些现有的VLM,以输出可用于机器人或汽车控制的动作序列。通过这种方式,VLA可以解释复杂的指令并在物理世界中执行相应的动作。
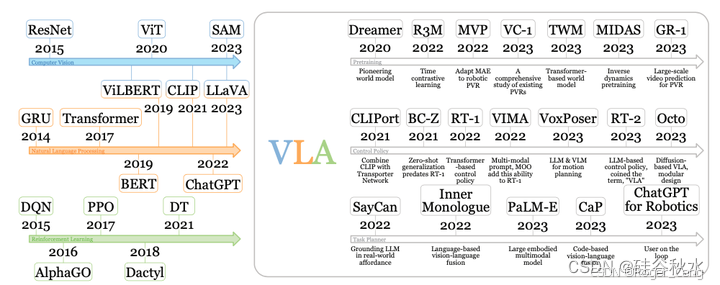
从单模态模型到多模态模型的演变,为 VLA 模型的引入奠定了基础。
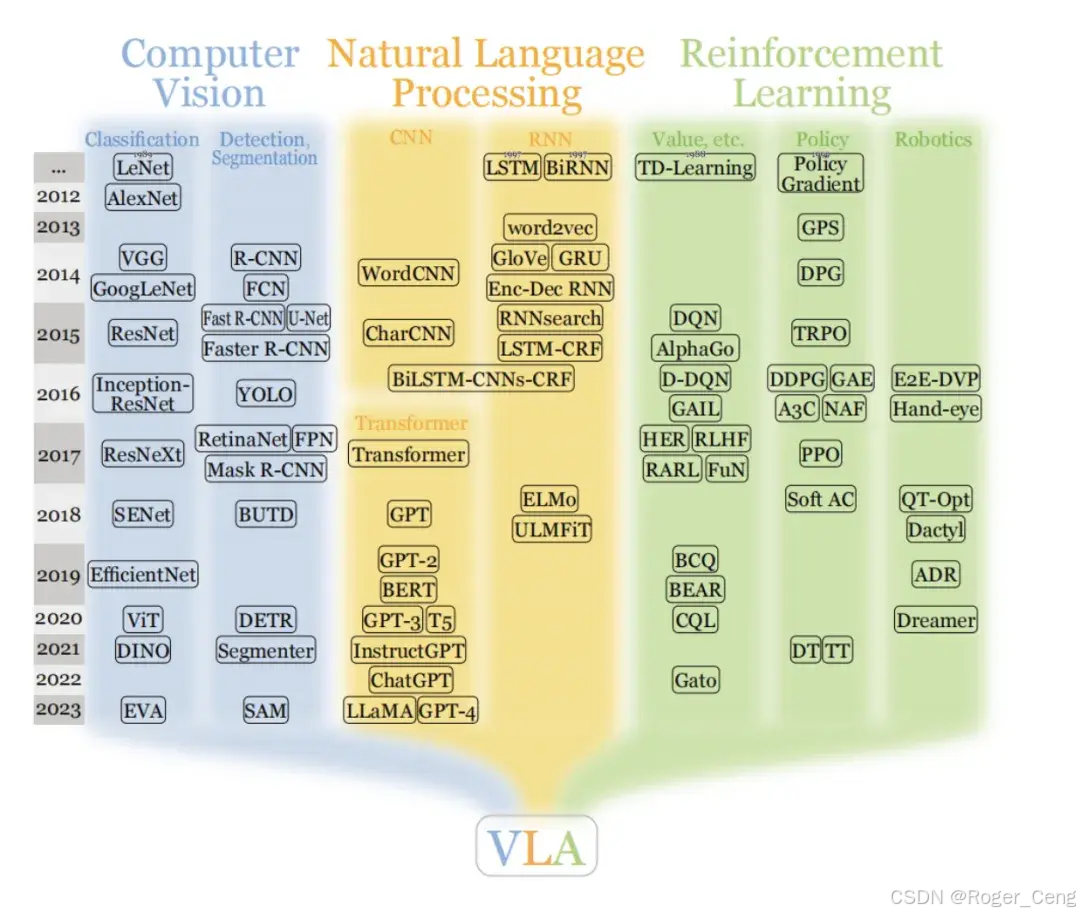
计算机视觉领域的关键进步(蓝色)包括 ResNet [85]、ViT [86] 和 SAM [87]。
自然语言处理领域的开创性工作(橙色)包括 GRU [88]、Transformer [66]、BERT [89]、ChatGPT [62] 等。
强化学习(绿色)中,DQN [90]、AlphaGo [91]、PPO [92]、Dactyl [93] 和 DT [94] 做出了显著贡献。
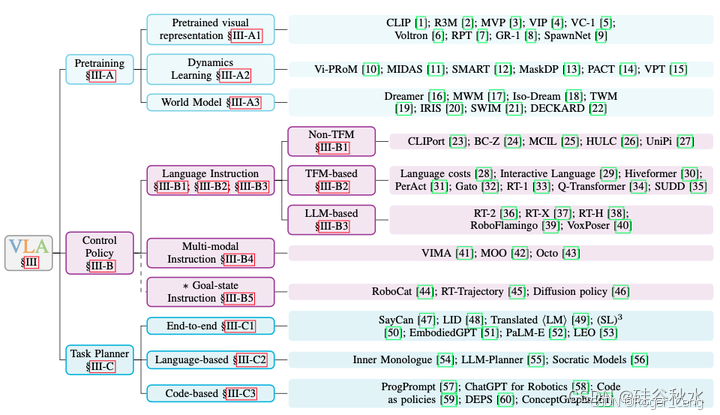
视觉语言模型已成为多模态模型的重要类别,例如 ViLBERT [95]、CLIP [1] 和 LLaVA [96]。VLA 的三个主要方向是:预训练、控制策略和任务规划器。
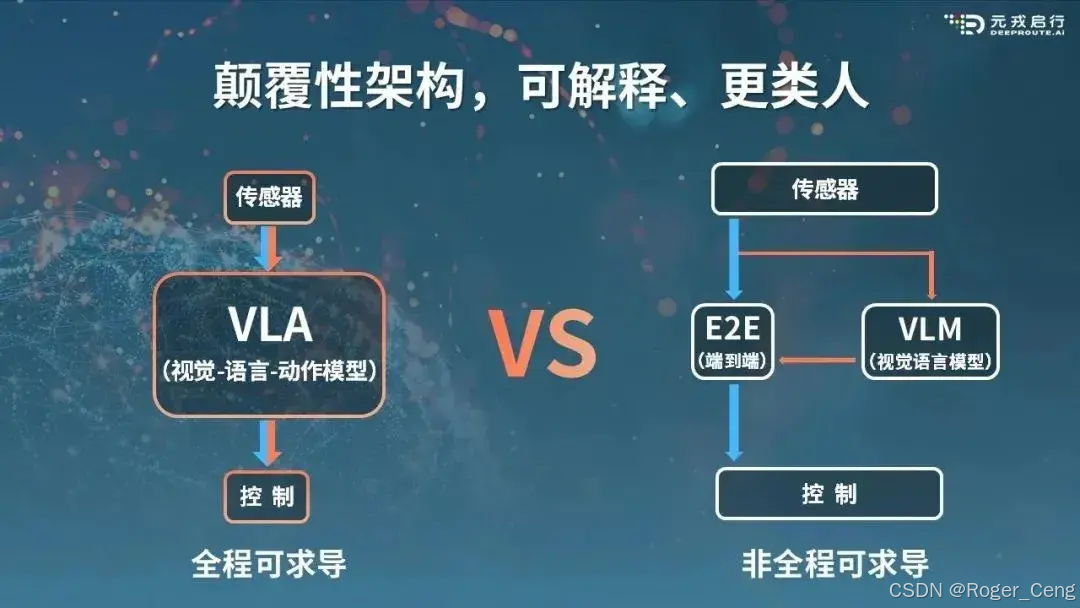
端到端大模型2.0 - VLA (Vision Language Action) 是一种先进的多模态机器学习模型,它结合了视觉、语言和动作三种能力,旨在实现从感知输入直接映射到机器人控制动作的完整闭环能力。这一技术的发展标志着自动驾驶和其他智能系统向更加自主化迈进的重要一步。VLA模型被开发用于解决具身智能中的指令跟随任务。与以ChatGPT为代表的聊天AI不同,具身智能需要控制物理实体并与环境交互。机器人是具身智能最突出的领域。在语言为条件的机器人任务中,策略必须具备理解语言指令、视觉感知环境并生成适当动作的能力,这就需要VLA的多模态能力。
VLA的特点与优势
1. 端到端架构
首先,VLA是一个端到端的大模型,这意味着它可以简化传统上需要多个独立模块才能完成的任务流程。例如,在自动驾驶领域,传统的做法是将感知、预测、规划等步骤分开处理,而VLA则试图用一个统一的框架来替代这种分立的方法。这不仅可以提高系统的效率,还能增强其灵活性和适应性。
2. 泛化能力
其次,VLA具有强大的泛化能力。以谷歌DeepMind推出的RT-2为例,该模型可以在新的物体、背景和环境中表现出显著改善的性能。它可以理解并响应那些在训练数据集中未曾出现过的命令,并基于底层语言模型提供的思路链进行推理,从而做出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









