







1 字符的编码方式
1.1 ASCII
是“American Standard Code for Information Interchange”的缩写,美国信息交换标准代码。电脑毕竟是西方人发明的,他们常用字母就 26 个,区分大小写、加上标点符号也没超过 127 个,每个字符用一个字节来表示就足够了。**一个字节的 7 位就可以表示 128 个数值,在 ASCII 码中最高位永远是 0**。
1.2 ANSI
ASNI 是 ASCII 的扩展,向下包含 ASCII。对于 ASCII 字符仍以一个字节来表示,对于非 ASCII 字符则使用 2 字节来表示,对于一个字符 bit7 是0则为ASCII, bit7 是1则为非ASCII,会用两个字节来表示一个非ASCII字符。并没有固定的 ASNI 编码,它跟“本地化”(locale)密切相关。比如在中国大陆地区,ANSI 的默认编码是 GB2312;在港澳台地区默认编码是 BIG5。以数值“0xd0d6”为例,对于 GB2312 编码它表示“中”;对于 BIG5 编码它表示“笢”。所以对于 ANSI 编码的 TXT 文件,如果你打开它发现乱码,那么还得再次细分它的具体编码。
使用 Notepad 打开后,选择不同的编码(或称为字符集),有不一样的显示,如下:
这仅仅是在中国地区就出现这些不兼容的问题。对于不同国家,它们默认的ANSI 编码各不相同,所以同一个 TXT 文件在不同国家就很有可能出现乱码。根本的原理在于没有“统一的编码”,那解决方法自然就是使用“统一的编码”:UNICODE。
1.3 UNICODAE
在 ANSI 标准中,很多种文字都有自己的编码标准,汉字简体字有 GB2312、繁体字BIG5,这难免同一个数值对应不同字符。比如数值“0xd0d6”,对于GB2312 编码它表示“中”;对于 BIG5 编码它表示“笢”。这造成了使用 ANSI 编码保存的文件,不适合跨地区交流。
UNICODE 编码就是解决这类问题:对于地球上任意一个字符,都给它一个唯一的数值。
UNICODE 仍然向下兼容 ASCII,但是对于其他字符会有对应的数值,比如对于“中”、“笢”,它们的数值分别是:0x4e2d、0x7b22UNICODE 中的数值范围是 0x0000 至 0x10FFFF,有 1,114,111 即 100 多万个数值,可以表示 100 多万个字符,足够地球人使用了。
2 UNICODAE编码实现
2.1使用 3 个字节表示一个 UNICODE
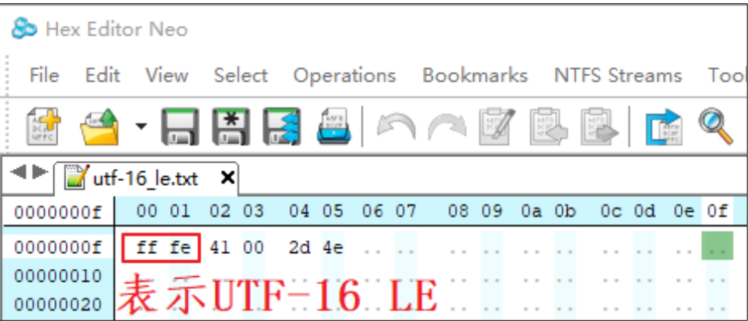
2.2 UCS-2 Little endian/UTF-16 LE
2.3UCS-2 Big endian/UTF-16 BE

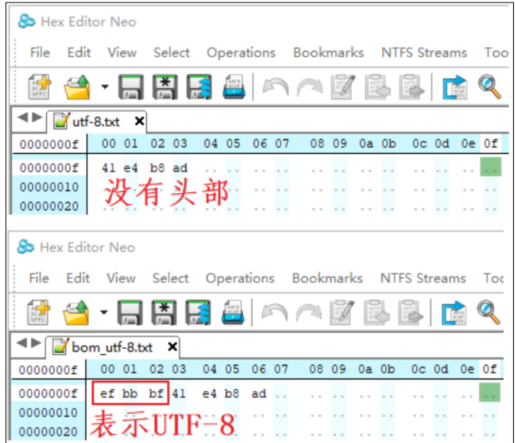
2.4UTF8

3 点阵字符的显示
3.1 ASCII 字符的显示
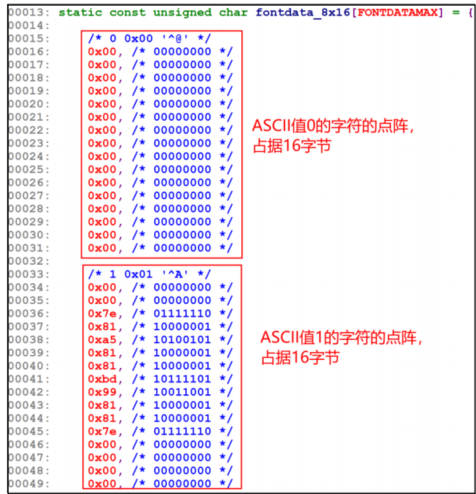

void lcd_put_ascii(int x, int y, unsigned char c)
{
unsigned char *dots = (unsigned char *)&fontdata_8x16[c*16]; //找到该ASCII的点阵
int i, b;
unsigned char byte;
for (i = 0; i < 16; i++)//16行 一行8个bit=1个字节
{
byte = dots[i];//取每一行的数据
for (b = 7; b >= 0; b--)//8列 bit顺序:7 6 5 4 3 2 1 0
{
if (byte & (1<<b)) //判断该位置的led灯亮或不亮
{
/* show */
lcd_put_pixel(x+7-b, y+i, 0xffffff); /* 白 */
}
else
{
/* hide */
lcd_put_pixel(x+7-b, y+i, 0); /* 黑 */
}
}
}
}3.1.1 获取点阵
对于字符 c,char c,它的点阵获取方法如下:
unsigned char *dots = (unsigned char *)&fontdata_8x16[c*16];3.1.2 描点
for (i = 0; i < 16; i++)//16行 一行8个bit=1个字节
{
byte = dots[i];//取每一行的数据
for (b = 7; b >= 0; b--)//8列 bit顺序:7 6 5 4 3 2 1 0
{
if (byte & (1<<b)) //判断该位置的led灯亮或不亮
{
/* show */
lcd_put_pixel(x+7-b, y+i, 0xffffff); /* 白 */
}
else
{
/* hide */
lcd_put_pixel(x+7-b, y+i, 0); /* 黑 */
}
}
}3.1.3 main 函数
int main(int argc, char **argv)
{
fd_fb = open("/dev/fb0", O_RDWR); //打开Framebuffer
if (fd_fb < 0)
{
printf("can't open /dev/fb0\n");
return -1;
}
if (ioctl(fd_fb, FBIOGET_VSCREENINFO, &var))
{
printf("can't get var\n");
return -1;
}
line_width = var.xres * var.bits_per_pixel / 8;
pixel_width = var.bits_per_pixel / 8;
screen_size = var.xres * var.yres * var.bits_per_pixel / 8;
fbmem = (unsigned char *)mmap(NULL , screen_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd_fb, 0);
if (fbmem == (unsigned char *)-1)
{
printf("can't mmap\n");
return -1;
}
/* 清屏: 全部设为黑色 */
memset(fbmem, 0, screen_size);
lcd_put_ascii(var.xres/2, var.yres/2, 'A'); /*在屏幕中间显示8*16的字母A*/
munmap(fbmem , screen_size);
close(fd_fb);
return 0;
}3.2 中文字符的点阵显示
3.2.1 指定编码格式
-finput-charset=GB2312
-finput-charset=UTF-8-fexec-charset=GB2312
-fexec-charset=UTF-83.2.2编码格式实验
#include <stdio.h>
#include <string.h>
int main(int argc, char **argv)
{
char *str = "A中";
int i;
printf("str's len = %d\n", (int)strlen(str));
printf("Hex code: ");
for (i = 0; i < strlen(str); i++)
{
printf("%02x ", (unsigned char)str[i]);
}
printf("\n");
return 0;
}3.2.2.1 默认编码
book@100ask:~/09_show_chinese$ gcc -o test_charset_ansi test_charset_ansi.c
book@100ask:~/09_show_chinese$ ./test_charset_ansi
str's len = 3
Hex code: 41 d6 d0
book@100ask:~/09_show_chinese$ gcc -o test_charset_utf8 test_charset_utf8.c
book@100ask:~/09_show_chinese$ ./test_charset_utf8
str's len = 4
Hex code: 41 e4 b8 ad3.2.2.2 GB2312 转为 UTF-8
book@100ask:~/09_show_chinese$ gcc -finput-charset=GB2312 -fexec-charset=UTF-8 -o test_charset_ansi test_charset_ansi.c
book@100ask:~/09_show_chinese$ ./test_charset_ansi str's len = 4 Hex code: 41 e4 b8 ad
book@100ask:~/09_show_chinese$ gcc -finput-charset=GB2312 -fexec-charset=UTF-8 -o test_charset_utf8 test_charset_utf8.c
cc1: error: failure to convert GB2312 to UTF-83.2.2.3 UTF-8 转为 GB2312
book@100ask:~/09_show_chinese$ gcc -finput-charset=UTF-8 -fexec-charset=GB2312 -o test_charset_ansi test_charset_ansi.c
test_charset_ansi.c: In function ‘main’:
test_charset_ansi.c:6:14: error: converting to execution character set: Invalid or in complete multibyte or wide character
char *str = "A▒▒";
^~~~~
book@100ask:~/09_show_chinese$ gcc -finput-charset=UTF-8 -fexec-charset=GB2312 -o test_charset_utf8 test_charset_utf8.c
book@100ask:~/09_show_chinese$ ./test_charset_utf8
str's len = 3
Hex code: 41 d6 d03.2.3 汉字区位码

3.2.4 汉字点阵显示实现
3.2.4.1 打开汉字库文件
fd_hzk16 = open("HZK16", O_RDONLY);//打开当前目录的字库文件:HZK16
if (fd_hzk16 < 0)
{
printf("can't open HZK16\n");
return -1;
}
if(fstat(fd_hzk16, &hzk_stat)) //获得文件的状态信息,里面含有文件长度,这在后面的 mmap 中用到
{
printf("can't get fstat\n");
return -1;
}
//使用 mmap 映射文件,以后就可以像访问内存一样读取文件内容;mmap 的返回结果保存在 hzkmem 中,它将作为字库的基地址。
hzkmem = (unsigned char *)mmap(NULL , hzk_stat.st_size, PROT_READ, MAP_SHARED, fd_hzk16, 0);
if (hzkmem == (unsigned char *)-1)
{
printf("can't mmap for hzk16\n");
return -1;
}3.2.4.2 编写显示汉字的函数
void lcd_put_chinese(int x, int y, unsigned char *str)
{
unsigned int area = str[0] - 0xA1; //保存区码:确定该汉字属于哪个区
unsigned int where = str[1] - 0xA1; //保存位码:确定它是该区中哪一个汉字
//得到该汉字的点阵起始地址。每个区中有 94 个汉字,每个汉字在字库中占据 32 字节
unsigned char *dots = hzkmem + (area * 94 + where)*32;
unsigned char byte;
int i, j, b;
for (i = 0; i < 16; i++)//16 行
for (j = 0; j < 2; j++) //一行有2个字节
{
byte = dots[i*2 + j];
//处理一个字节中的8位,对于每一位它等于 1 时对应的像素被设置为白色,它等于 0 时对应的像素被设置为黑色。
for (b = 7; b >=0; b--)
{
if (byte & (1<<b))
{
/* show */
lcd_put_pixel(x+j*8+7-b, y+i, 0xffffff); /* 白 */
}
else
{
/* hide */
lcd_put_pixel(x+j*8+7-b, y+i, 0); /* 黑 */
}
}
}
}3.2.4.3 使用 lcd_put_chinese 函数
unsigned char str[] = "中";
printf("chinese code: %02x %02x\n", str[0], str[1]);
lcd_put_chinese(var.xres/2 + 8, var.yres/2, str);3.2.4.4 使用lcd_put_str 函数显示字符串
void lcd_put_str(int x, int y, unsigned char *str, int colour)
{
int i;
unsigned char str2[2];
for(i=0; *str != '\0'; i++)
{
if(*str >= 0xa1){
str2[0] = *str;
str++;
str2[1] = *str;
lcd_put_chinese(x+i*8, y, str2, 0xff00ff);
i++;
}else{
lcd_put_ascii(x+i*8, y, *str);
}
str++;
}
}4. 使用 freetype 显示单个文字
4.1 矢量字体引入
使用点阵字库显示英文字母、汉字时,大小固定,如果放大缩小则会模糊甚至有锯齿出现,为了解决这个问题,引用矢量字体。
矢量字体形成分三步:
第1步 确定关键点,
第2步 使用数学曲线(贝塞尔曲线)连接头键点,
第3步 填充闭合区线内部空间。
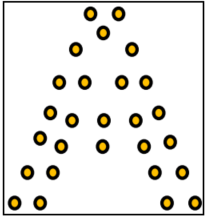
什么是关键点?以字母“A”为例,它的的关键点如图中的黄色所示。
再用数学曲线(比如贝塞尔曲线)将关键点都连接起来,得到一系列的封闭的曲线,如图所示:

最后把封闭空间填满颜色,就显示出一个 A 字母,如图所示

如果需要放大或者缩小字体,关键点的相对位置是不变的,只要数学曲线平滑,字体就不会变形。
4.2 Freetype 介绍
Freetype 是开源的字体引擎库,它提供统一的接口来访问多种字体格式文件,从而实现矢量字体显示。我们只需要移植这个字体引擎,调用对应的 API 接口,提供字体文件,就可以让 freetype 库帮我们取出关键点、实现闭合曲线,填充颜色,达到显示矢量字体的目的。
关 键 点 (glyph) 存 在 字 体 文 件 中 , Windows 使 用 的 字 体 文 件 在 c:\Windows\Fonts 目录下,扩展名为 TTF 的都是矢量字库,本次使用实验使用的是新宋字体 simsun.ttc。
给定一个字符,怎么在字体文件中找到它的关键点?
首先要确定该字符的编码值:比如 ASCII 码、GB2312 码、UNICODE 码。如果字体文件支持某种编码格式(charset),就可以使用这类编码值去找到该字符的关键点(glyph)。有些字体文件支持多种编码格式(charset),这在文件中被称为 charmaps(注意:这个单词是复数,意味着可能支持多种 charset)。
以 simsun.ttc 为例,该字体文件的格如下:头部含有 charmaps,可以使用某种编码值去 charmaps 中找到它对应的关键点。下图中的“A、B、中、国、韦”等只是 glyph 的示意图,表示关键点。

Charmaps 表示字符映射表,字体文件可能支持哪一些编码,GB2312、UNICODE、BIG5 或其他。如果字体文件支持该编码,使用编码值通过 charmap 就可以找到对应的 glyph,一般而言都支持 UNICODE 码。
有了以上基础,一个文字的显示过程可以概括如下:
1.给定一个字符可以确定它的编码值(ASCII、UNICODE、GB2312);
2.设置字体大小;
3.根据编码值,从文件头部中通过 charmap 找到对应的关键点(glyph),它会根据字体大小调整关键点;
4.把关键点转换为位图点阵;
5.在 LCD 上显示出来
如何使用 freetype 库,总结出下列步骤:
1.初始化:FT_InitFreetype
2.加载(打开)字体 Face:FT_New_Face
3.设置字体大小:FT_Set_Char_Sizes 或 FT_Set_Pixel_Sizes
4.选择 charmap:FT_Select_Charmap
5.根据编码值 charcode 找到 glyph_index:glyph_index = FT_Get_Char_Index(face,charcode)
6.根据 glyph_index 取出 glyph:FT_Load_Glyph(face,glyph_index)
7.转为位图:FT_Render_Glyph
8.移动或旋转:FT_Set_Transform
9.最后显示出来。
上面的5、6、7可以使用一个函数代替:FT_Load_Char(face, charcode, FT_LOAD_RENDER),它就可以得到位图。
4.3 在 LCD 上显示一个矢量字体
4.3.1 使用 wchar_t 获得字符的 UNICODE 值
char *str = “中”;#include <stdio.h>
#include <string.h>
#include <wchar.h>
int main( int argc, char** argv)
{
wchar_t *chinese_str = L"中gif";
unsigned int *p = (wchar_t *)chinese_str;
int i;
printf("sizeof(wchar_t) = %d, str's Uniocde: \n", (int)sizeof(wchar_t));
for (i = 0; i < wcslen(chinese_str); i++)
{
printf("0x%x ", p[i]);
}
printf("\n");
return 0;
}
book@100ask:~/10_freetype/01_wchar$ gcc -o test_wchar test_wchar.c
book@100ask:~/10_freetype/01_wchar$ ./test_wchar
sizeof(wchar_t) = 4, str's Uniocde:
0x4e2d 0x67 0x69 0x66gcc -finput-charset=GB2312 -fexec-charset=UTF-8 -o test_wchar test_wchar.c4.3.2 使用 freetype 得到位图
/* 显示矢量字体 */
error = FT_Init_FreeType( &library ); //初始化 freetype 库 /* initialize library */
/* error handling omitted */
//加载字体文件,argv[1]保存字体文件的路径,字体保存在&face 中
error = FT_New_Face( library, argv[1], 0, &face ); /* create face object */
/* error handling omitted */
slot = face->glyph;//从 face 中获得 FT_GlyphSlot,后面的代码中文字的位图就是保存在 FT_GlyphSlot 里
//设置字体大小有2个函数,FT_Set_Char_Sizes以1/64个point为单位,FT_Set_Pixel_Sizes以像素为单位
FT_Set_Pixel_Sizes(face, font_size, 0);//设置字体大小
/* 确定座标:
*/
//pen.x = 0;
//pen.y = 0;
/* set transformation *///因为不涉及旋转,不涉及多个文字一起显示,所以不需要调用FT_Set_Transform
//FT_Set_Transform( face, 0, &pen);
/* load glyph image into the slot (erase previous one) */
error = FT_Load_Char( face, chinese_str[0], FT_LOAD_RENDER );//根据编码值得到位图
if (error)
{
printf("FT_Load_Char error\n");
return -1;
}4.3.3 在屏幕上显示位图
draw_bitmap( &slot->bitmap,
var.xres/2,
var.yres/2);//在屏幕上显示位图
draw_bitmap( FT_Bitmap* bitmap,
FT_Int x,
FT_Int y)
{
FT_Int i, j, p, q;
FT_Int x_max = x + bitmap->width;
FT_Int y_max = y + bitmap->rows;
//printf("x = %d, y = %d\n", x, y);
for ( j = y, q = 0; j < y_max; j++, q++ ) //位图行数
{
for ( i = x, p = 0; i < x_max; i++, p++ ) //位图列数
{
if ( i < 0 || j < 0 ||
i >= var.xres || j >= var.yres )
continue;
//对于i,j坐标上的像素,在位图找到对应数据作为颜色传给lcd_put_pixel描绘像素颜色
//image[j][i] |= bitmap->buffer[q * bitmap->width + p];
lcd_put_pixel(i, j, bitmap->buffer[q * bitmap->width + p]);
}
}
}编译:
arm-buildroot-linux-gnueabihf-gcc -o freetype_show_font freetype_show_font.c -lfreetype运行:
./freetype_show_font ./simsun.ttc 300./freetype_show_font ./simsun.ttc4.3.4 在 LCD 上令矢量字体旋转某个角度
FT_Library library;
double angle;2.设置角度值:
angle = ( 1.0* strtoul(argv[2], NULL, 0) / 360 ) * 3.14159 * 2; /* use 25 degrees */3.设置矩阵、变形、加载位图:
/* set up matrix *///设置矩阵
matrix.xx = (FT_Fixed)( cos( angle ) * 0x10000L );
matrix.xy = (FT_Fixed)(-sin( angle ) * 0x10000L );
matrix.yx = (FT_Fixed)( sin( angle ) * 0x10000L );
matrix.yy = (FT_Fixed)( cos( angle ) * 0x10000L );
/* set transformation *///变形
FT_Set_Transform( face, &matrix, &pen);
/* load glyph image into the slot (erase previous one) */
error = FT_Load_Char( face, chinese_str[0], FT_LOAD_RENDER );//得到位图
if (error)
{
printf("FT_Load_Char error\n");
return -1;
}编译:
arm-buildroot-linux-gnueabihf-gcc -o freetype_show_font_angle freetype_show_font_angle.c -lfreetype -lm运行:
./freetype_show_font_angle ./simsun.ttc 90 2004.4 使用freetype 显示一行文字
4.4.1 笛卡尔坐标系

4.4.2 每个字符的大小可能不同
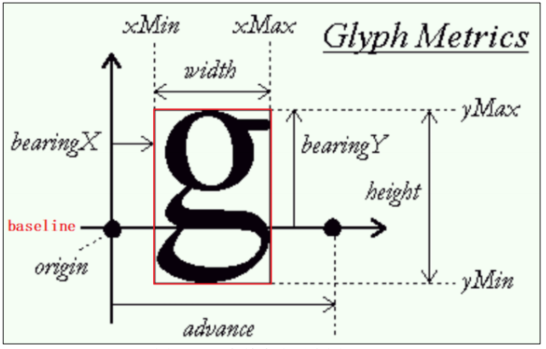

4.4.3 怎么在指定位置显示一行文字

(x',y')-(0,0)= (x,y) - (x-x',y-y')
左上角 pen 左上角 pen4.4.4 freetype 的几个重要数据结构
FT_Library library; /* 对应 freetype 库 */
error = FT_Init_FreeType( &library ); /* 初始化 freetype 库 */2 FT_Face
error = FT_New_Face(library, font_file, 0, &face ); /* 加载字体文件 */3 FT_GlyphSlot
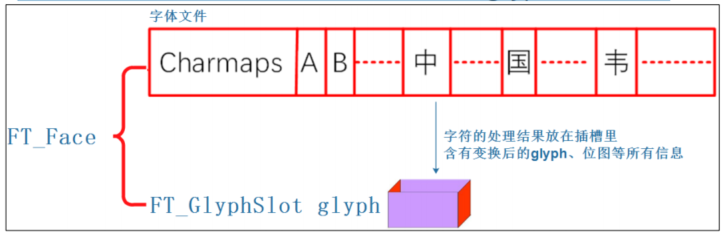
FT_GlyphSlot slot = face->glyph; /* 插槽: 字体的处理结果保存在这里 */4 FT_Glyph
error = FT_Get_Glyph(slot , &glyph);5 FT_BBox

FT_Glyph_Get_CBox(glyph, FT_GLYPH_BBOX_TRUNCATE, &bbox ); FT_Library library; /* 对应freetype库 */
FT_Face face; /* 对应字体文件 */
FT_GlyphSlot slot; /* 对应字符的处理结果: 含glyph和位图 */
FT_Glyph glyph; /* 对应字符经过处理后的glyph即外形、轮廓 */
FT_BBox bbox; /* 字符的外框 */
FT_Vector pen; /* 字符的原点 */
error = FT_Init_FreeType( &library ); /* 初始化freetype库 */
error = FT_New_Face(library, font_file, 0, &face ); /* 加载字体文件 */
slot = face->glyph; /* 插槽: 字体的处理结果保存在这里 */
FT_Set_Pixel_Sizes(face, 24, 0); /* 设置大小 */
/* 确定坐标 */
pen.x = 0; /* 单位: 1/64 像素 */
pen.y = 0; /* 单位: 1/64 像素 */
FT_Set_Transform( face, 0, &pen); /* 变形 */
/* 根据font_code加载字符, 得到新的glyph和位图, 结果保存在slot中 */
error = FT_Load_Char(face, font_code, FT_LOAD_RENDER);
error = FT_Get_Glyph(slot, &glyph); /* 从slot中得到新的glyph */
FT_Glyph_Get_CBox(glyph, FT_GLYPH_BBOX_TRUNCATE, &bbox ); /* 从glyph中得到字符外框 */
draw_bitmap(&slot->bitmap, lcd_x, lcd_y); /* 位图也保存在slot->bitmap中 */4.4.5 计算一行文字的外框
int compute_string_bbox(FT_Face face, wchar_t *wstr, FT_BBox *abbox)
{
int i;
int error;
FT_BBox bbox;
FT_BBox glyph_bbox;
FT_Vector pen;
FT_Glyph glyph;
FT_GlyphSlot slot = face->glyph;
/* 初始化 */
bbox.xMin = bbox.yMin = 32000;
bbox.xMax = bbox.yMax = -32000;
/* 指定原点为(0, 0) */
pen.x = 0;
pen.y = 0;
/* 计算每个字符的bounding box */
/* 先translate, 再load char, 就可以得到它的外框了 */
for (i = 0; i < wcslen(wstr); i++)
{
/* 转换:transformation */
FT_Set_Transform(face, 0, &pen);
/* 加载位图: load glyph image into the slot (erase previous one) */
error = FT_Load_Char(face, wstr[i], FT_LOAD_RENDER);
if (error)
{
printf("FT_Load_Char error\n");
return -1;
}
/* 取出glyph */
error = FT_Get_Glyph(face->glyph, &glyph);
if (error)
{
printf("FT_Get_Glyph error!\n");
return -1;
}
/* 从glyph得到外框: bbox */
FT_Glyph_Get_CBox(glyph, FT_GLYPH_BBOX_TRUNCATE, &glyph_bbox);
/* 更新外框 */
if ( glyph_bbox.xMin < bbox.xMin )
bbox.xMin = glyph_bbox.xMin;
if ( glyph_bbox.yMin < bbox.yMin )
bbox.yMin = glyph_bbox.yMin;
if ( glyph_bbox.xMax > bbox.xMax )
bbox.xMax = glyph_bbox.xMax;
if ( glyph_bbox.yMax > bbox.yMax )
bbox.yMax = glyph_bbox.yMax;
/* 计算下一个字符的原点: increment pen position */
pen.x += slot->advance.x;
pen.y += slot->advance.y;
}
/* return string bbox */
*abbox = bbox;
}
4.4.6 调整原点并绘制
int display_string(FT_Face face, wchar_t *wstr, int lcd_x, int lcd_y)
{
int i;
int error;
FT_BBox bbox;
FT_Vector pen;
FT_Glyph glyph;
FT_GlyphSlot slot = face->glyph;
/* 把LCD坐标转换为笛卡尔坐标 */
int x = lcd_x;
int y = var.yres - lcd_y;
/* 计算外框 */
compute_string_bbox(face, wstr, &bbox);
/* 反推原点:外框左上角坐标是(xMin,yMax)所以新origin坐标是(x-xMin, y-yMax) */
pen.x = (x - bbox.xMin) * 64; /* 单位: 1/64像素 */
pen.y = (y - bbox.yMax) * 64; /* 单位: 1/64像素 */
/* 处理每个字符 */
for (i = 0; i < wcslen(wstr); i++)
{
/* 转换:transformation */
FT_Set_Transform(face, 0, &pen);
/* 加载位图: load glyph image into the slot (erase previous one) */
error = FT_Load_Char(face, wstr[i], FT_LOAD_RENDER);
if (error)
{
printf("FT_Load_Char error\n");
return -1;
}
/* 在LCD上绘制: 使用LCD坐标 */
draw_bitmap( &slot->bitmap,
slot->bitmap_left,
var.yres - slot->bitmap_top);
/* 计算下一个字符的原点: increment pen position */
pen.x += slot->advance.x;
pen.y += slot->advance.y;
}
return 0;
}编译:
arm-buildroot-linux-gnueabihf-gcc -o show_line show_line.c -lfreetype运行:
./show_line ./simsun.ttc 10 200 804.4.7 main函数
int main(int argc, char **argv)
{
wchar_t *wstr = L"百问网www.100ask.net";
FT_Library library;
FT_Face face;
int error;
FT_BBox bbox;
int font_size = 24;
int lcd_x, lcd_y;
if (argc < 4)
{
printf("Usage : %s <font_file> <lcd_x> <lcd_y> [font_size]\n", argv[0]);
return -1;
}
lcd_x = strtoul(argv[2], NULL, 0);
lcd_y = strtoul(argv[3], NULL, 0);
if (argc == 5)
font_size = strtoul(argv[4], NULL, 0);
fd_fb = open("/dev/fb0", O_RDWR);
if (fd_fb < 0)
{
printf("can't open /dev/fb0\n");
return -1;
}
if (ioctl(fd_fb, FBIOGET_VSCREENINFO, &var))
{
printf("can't get var\n");
return -1;
}
if (ioctl(fd_fb, FBIOGET_FSCREENINFO, &fix))
{
printf("can't get fix\n");
return -1;
}
line_width = var.xres * var.bits_per_pixel / 8;
pixel_width = var.bits_per_pixel / 8;
screen_size = var.xres * var.yres * var.bits_per_pixel / 8;
fbmem = (unsigned char *)mmap(NULL , screen_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd_fb, 0);
if (fbmem == (unsigned char *)-1)
{
printf("can't mmap\n");
return -1;
}
/* 清屏: 全部设为黑色 */
memset(fbmem, 0, screen_size);
error = FT_Init_FreeType( &library ); /* initialize library */
error = FT_New_Face( library, argv[1], 0, &face ); /* create face object */
FT_Set_Pixel_Sizes(face, font_size, 0);
display_string(face, wstr, lcd_x, lcd_y);
return 0;
}














 9707
9707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











