







练习题
1.金陵十三钗
问题描述
在电影《金陵十三钗》中有十二个秦淮河的女人要自我牺牲代替十二个女学生去赴日本人的死亡宴会。为了不让日本人发现,自然需要一番乔装打扮。但由于天生材质的原因,每个人和每个人之间的相似度是不同的。由于我们这是编程题,因此情况就变成了金陵n钗。给出n个女人和n个学生的相似度矩阵,求她们之间的匹配所能获得的最大相似度。
所谓相似度矩阵是一个n*n的二维数组like[i][j]。其中i,j分别为女人的编号和学生的编号,皆从0到n-1编号。like[i][j]是一个0到100的整数值,表示第i个女人和第j个学生的相似度,值越大相似度越大,比如0表示完全不相似,100表示百分之百一样。每个女人都需要找一个自己代替的女学生。
最终要使两边一一配对,形成一个匹配。请编程找到一种匹配方案,使各对女人和女学生之间的相似度之和最大。
输入格式
第一行一个正整数n表示有n个秦淮河女人和n个女学生
接下来n行给出相似度,每行n个0到100的整数,依次对应二维矩阵的n行n列。
输出格式
仅一行,一个整数,表示可获得的最大相似度。
样例输入
4
97 91 68 14
8 33 27 92
36 32 98 53
73 7 17 82
样例输出
354
数据规模和约定
对于70%的数据,n<=10
对于100%的数据,n<=13
样例说明
最大相似度为91+92+98+73=354
思路:这和n皇后问题相似,皇后在行和列上不能有冲突,但是这里对角线上可以有。通过回溯深度搜索,cur遍历每一个位置(从第0列开始),若有不符合(这个行和之前有重复)则回溯到上一层,判断下一个位置(下一行)。当遍历到最后一列时,加上每个的相似度,进行比较选出最大值,最后输出即可。
def queen(cur=0):
global max_sum,n
if cur==n:#所有的皇后都正确放置完毕,输出每个皇后所在的位置
sum=0
for i in range(n):
sum+=a[i][b[i]]
if sum>max_sum:
max_sum=sum
return 0
for i in range(n):#i为列下标,cur为行下标
flag=True
for j in range(cur):#检测本次所放的行位置是否和之前的同列
if b[j]==i:#是的话,该位置不能放,向上回溯
flag=False
break
if flag:#如果没有产生矛盾
b[cur]=i#记录该行所要的列下标
queen(cur+1)#则继续放下一个
max_sum=0
n=int(input())
a=[list(map(int,input().split())) for _ in range(n)]
b=[0 for _ in range(n)]#用来存放每一列所要的行下标
queen()
print(max_sum)
思想应该是这样的,但是在蓝桥杯练习系统是提交,显示超时了!
还有改进的地方,先掌握好思想吧
2.成绩排名(结构体)
问题描述
给出n个学生的成绩,将这些学生按成绩排序,
排序规则,优先考虑数学成绩,高的在前;数学相同,英语高的在前;数学英语都相同,语文高的在前;三门都相同,学号小的在前
输入格式
第一行一个正整数n,表示学生人数
接下来n行每行3个0~100的整数,第i行表示学号为i的学生的数学、英语、语文成绩
输出格式
输出n行,每行表示一个学生的数学成绩、英语成绩、语文成绩、学号
按排序后的顺序输出
样例输入
2
1 2 3
2 3 4
样例输出
2 3 4 2
1 2 3 1
数据规模和约定
n≤100
n=int(input())
ls=[[] for _ in range(n)]
for i in range(n):
ls[i].extend(map(int,input().split()))
ls[i].append(i+1)
ls.sort(key=lambda x:x[3],reverse=True)#从高到低
ls.sort(key=lambda x:x[2],reverse=True)
ls.sort(key=lambda x:x[1],reverse=True)
ls.sort(key=lambda x:x[0],reverse=True)
for i in range(n):
for j in ls[i]:
print(j,end=' ')
print()
注意一些函数的用法
3.最长滑雪道
问题描述
小袁非常喜欢滑雪, 因为滑雪很刺激。为了获得速度,滑的区域必须向下倾斜,而且当你滑到坡底,你不得不再次走上坡或者等待升降机来载你。 小袁想知道在某个区域中最长的一个滑坡。区域由一个二维数组给出。数组的每个数字代表点的高度。如下:
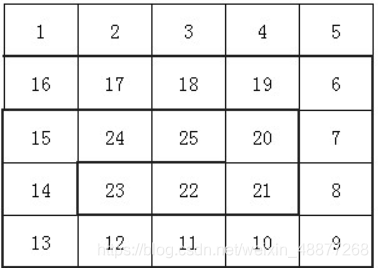
一个人可以从某个点滑向上下左右相邻四个点之一,当且仅当高度减小。在上面的例子中,一条可滑行的滑坡为24-17-16-1。当然25-24-23-…-3-2-1更长。事实上,这是最长的一条。
你的任务就是找到最长的一条滑坡,并且将滑坡的长度输出。 滑坡的长度定义为经过点的个数,例如滑坡24-17-16-1的长度是4。
输入格式
输入的第一行表示区域的行数R和列数C(1<=R, C<=10)。下面是R行,每行有C个整数,依次是每个点的高度h(0<= h <=10000)。
输出格式
只有一行,为一个整数,即最长区域的长度。
样例输入
5 5
1 2 3 4 5
16 17 18 19 6
15 24 25 20 7
14 23 22 21 8
13 12 11 10 9
样例输出
25
思路:这是一题深度递归搜索,对于区域内每个点进行dfs,对于每个点来说dfs遍历四个方向,取最大值,然后取所有点为起点的最大长度的最大值,即为答案
def dfs(x,y):
max_height=1
if dp[x][y]>0:#如果已经有了当前位置出发的最大距离,则直接返回
return dp[x][y]
for k in range(4):
tx=x+next_[k][0]
ty=y+next_[k][1]
if tx<0 or tx>=row or ty<0 or ty>=col:#越界情况
continue
if arr[tx][ty]>=arr[x][y]:#不符合高到低的情况
continue
max_height=max(max_height,dfs(tx,ty)+1)#符合,递归搜索下一个
dp[x][y]=max_height#最终距离放在此矩阵中保存
return dp[x][y]#返回该位置下的最大距离
row,col=map(int,input().split())
dp=[[0 for _ in range(col)] for _ in range(row)]#二维数组dp保存每个点对应的最大高度,初始化都为0
arr=[list(map(int,input().split())) for _ in range(row)]#输入二维数组
next_=[[0,1],[1,0],[0,-1],[-1,0]]#四个方向 右,上,左,下
ans=0
for i in range(row):
for j in range(col):
ans=max(ans,dfs(i,j))
print(ans)
4.天天向上
问题描述
A同学的学习成绩十分不稳定,于是老师对他说:“只要你连续4天成绩有进步,那我就奖励给你一朵小红花。”可是这对于A同学太困难了。于是,老师对他放宽了要求:“只要你有4天成绩是递增的,我就奖励你一朵小红花。”即只要对于第i、j、k、l四天,满足i<j<k<l并且对于成绩wi<wj<wk<wl,那么就可以得到一朵小红花的奖励。现让你求出,A同学可以得到多少朵小红花。
输入格式
第一行一个整数n,表示总共有n天。第二行n个数,表示每天的成绩wi。
输出格式
一个数,表示总共可以得到多少朵小红花。
样例输入
6
1 3 2 3 4 5
样例输出
6
数据规模和约定
对于40%的数据,n<=50;
对于100%的数据,n<=2000,0<=wi<=109。
def dfs(index,depth):
total=0
if depth==3:
return 1
if dp[index][depth]!=0:#如果之前已经有记录了,则直接返回
return dp[index][depth]
for i in range(index+1,n):#否则,从后面这个位置开始深度搜索
if ls[index]<ls[i]:
total+=dfs(i,depth+1)
dp[index][depth]=total#记录这个深度下的总长度
return total
n=int(input())
ls=list(map(int,input().split()))
ans=0
dp=[[0 for _ in range(4)] for _ in range(2000)]
#二维数组dp[index][depth],存放该下标下长度为depth的个数,可避免后面重复计算
for i in range(n):#依次遍历每一个数,当成起点开始
ans+=dfs(i,0)
print(ans)
python怎么又超时了,伤心
5.回形取数
问题描述
回形取数就是沿矩阵的边取数,若当前方向上无数可取或已经取过,则左转90度。一开始位于矩阵左上角,方向向下。
输入格式
输入第一行是两个不超过200的正整数m, n,表示矩阵的行和列。接下来m行每行n个整数,表示这个矩阵。
输出格式
输出只有一行,共mn个数,为输入矩阵回形取数得到的结果。数之间用一个空格分隔,行末不要有多余的空格。
样例输入
3 3
1 2 3
4 5 6
7 8 9
样例输出
1 4 7 8 9 6 3 2 5
样例输入
3 2
1 2
3 4
5 6
样例输出
1 3 5 6 4 2
思路:这题就是在逆时针打印矩阵,需要找到打印规律。可以先分为四个顺序方向遍历并打印,遍历到时,需要将其标记为-1,以此判断每次打印的范围。每个顺序打印完需要修改row,col的值,因为循环条件结束时可能越界了,要修改用于下一个顺序。判断什么时候都遍历完,可以设置count计数,当值为m*n表示都打印出来,结束。
m,n=map(int,input().split())
row,col,count=0,0,0
matrix=[list(map(int,input().split())) for _ in range(m)]#存放输入的矩阵
while count<m*n:
while row<m and matrix[row][col]!=-1:#向下取数
print(matrix[row][col],end=' ')
matrix[row][col]=-1#将来过的位置标记为-1
row+=1
count+=1
row-=1#row结束时为m,越界了需要减1
col+=1#col向右移一步
while col<n and matrix[row][col]!=-1:#向右取数
print(matrix[row][col],end=' ')
matrix[row][col]=-1
col+=1
count+=1
col-=1#col结束时为n,越界需要减1
row-=1#向上退一行
while row>=0 and matrix[row][col]!=-1:#向上取数
print(matrix[row][col],end=' ')
matrix[row][col]=-1
row-=1
count+=1
row+=1#row结束时为-1,越界需要加1
col-=1#往左退一行
while col>=0 and matrix[row][col]!=-1:
print(matrix[row][col],end=' ')
matrix[row][col]=-1
col-=1
count+=1
col+=1#上个循环使col变为-1,越界需要+1变回来
row+=1#向下退一行
6.学霸的迷宫
问题描述
学霸抢走了大家的作业,班长为了帮同学们找回作业,决定去找学霸决斗。但学霸为了不要别人打扰,住在一个城堡里,城堡外面是一个二维的格子迷宫,要进城堡必须得先通过迷宫。因为班长还有妹子要陪,磨刀不误砍柴功,他为了节约时间,从线人那里搞到了迷宫的地图,准备提前计算最短的路线。可是他现在正向妹子解释这件事情,于是就委托你帮他找一条最短的路线。
输入格式
第一行两个整数n, m,为迷宫的长宽。
接下来n行,每行m个数,数之间没有间隔,为0或1中的一个。0表示这个格子可以通过,1表示不可以。假设你现在已经在迷宫坐标(1,1)的地方,即左上角,迷宫的出口在(n,m)。每次移动时只能向上下左右4个方向移动到另外一个可以通过的格子里,每次移动算一步。数据保证(1,1),(n,m)可以通过。
输出格式
第一行一个数为需要的最少步数K。
第二行K个字符,每个字符∈{U,D,L,R},分别表示上下左右。如果有多条长度相同的最短路径,选择在此表示方法下字典序最小的一个。
样例输入
Input Sample 1:
3 3
001
100
110
Input Sample 2:
3 3
000
000
000
样例输出
Output Sample 1:
4
RDRD
Output Sample 2:
4
DDRR
数据规模和约定
有20%的数据满足:1<=n,m<=10
有50%的数据满足:1<=n,m<=50
有100%的数据满足:1<=n,m<=500。
思路:宽度优先搜索BFS,每一步都有四个选择,按字典顺序搜索D、L、R、U,有新的节点放入队列中,将走过的节点存放在集合里,后面遇到了可以减枝。直到终点,打印出路径,退出循环。
广度搜索,最先到满足结束条件的肯定是最短的那一个路径。
需要注意一下题目n,m的顺序,n是行数,m是列数
提交的时候就是写反了,导致有几个测试用例通过不了。
class Node:
def __init__(self,x,y,w):
self.x=x#x为横坐标
self.y=y#y为纵坐标
self.w=w
def __str__(self):
return self.w#输出路径
def up(node):
return Node(node.x,node.y-1,node.w+"U")
def down(node):
return Node(node.x,node.y+1,node.w+"D")
def left(node):
return Node(node.x-1,node.y,node.w+"L")
def right(node):
return Node(node.x+1,node.y,node.w+"R")
if __name__=='__main__':
n,m=map(int,input().split())
visited=set()#记录访问过的点,集合
queue=[]#队列
map_int=[[0]*(m+1)]
for i in range(1,n+1):
map_int.append([0]*(m+1))
nums=input()
nums='0'+nums
for j in range(0,m+1):
map_int[i][j]=ord(nums[j])-48#ord转换为ascii码
node = Node(1, 1, "") # 设置起点
queue.append(node)
while len(queue) != 0:
moveNode = queue[0]
queue.pop(0)
moveStr = str(moveNode.x) + " " + str(moveNode.y) # 用于记录当前坐标是否走过
if moveStr not in visited:#减去不必要的枝节
visited.add(moveStr)#访问过的点放进set
if moveNode.x == m and moveNode.y == n: # 若到达终点则输出并退出循环
print(len(moveNode.__str__())) # 步数
print(moveNode) # 打印路径
break
if moveNode.y < n: # 首先顺序为下
if map_int[moveNode.y + 1][moveNode.x] == 0:
queue.append(down(moveNode))
if moveNode.x > 1: # 第二顺序为左
if map_int[moveNode.y][moveNode.x - 1] == 0:
queue.append(left(moveNode))
if moveNode.x < m: # 第三顺序为右
if map_int[moveNode.y][moveNode.x + 1] == 0:
queue.append(right(moveNode))
if moveNode.y > 1: # 最后顺序为上
if map_int[moveNode.y - 1][moveNode.x] == 0:
queue.append(up(moveNode))
7.不同字串
一个字符串的非空子串是指字符串中长度至少为1
的连续的一段字符组成的串。例如,字符串aaab
有非空子串a, b, aa, ab, aaa, aab, aaab,一共
7个。 注意在计算时,只算本质不同的串的个数。
请问,字符串0100110001010001
有多少个不同的非空子串?
这是一道结果填空的题,你只需要算出结果后提交即可。
本题的结果为一 个整数,在提交答案时只填写这个整数,
填写多余的内容将无法得分。
思路:设置步数sep来遍历所有可能,并用集合来去重
注意下标的取值范围,不清楚的话,可以先画图去推范围
s='aaab'
sep=1#步数为sep个的子串
count=0#记录个数
set1=set()#空集合存放找到的子串,利用集合的不重复性
while sep<=len(s):
set1.add(s[0:sep])
for i in range(len(s)-sep):#i的范围为[0,len(s)-sep-1]
set1.add(s[i+1:i+sep+1])#注意i+sep+1是可以越界大于下标的,没有错误
sep+=1
count+=len(set1)
print(set1)
set1.clear()
print(count)
"""
{'a', 'b'}
{'aa', 'ab'}
{'aab', 'aaa'}
{'aaab'}
7
"""
8.年号字串
小明用字母A 对应数字1,B 对应2,以此类推,用Z 对应26。对于27以上的数字,小明用两位或更长位的字符串来对应,例如AA 对应27,AB 对应28,AZ 对应52,LQ 对应329。
请问2019 对应的字符串是什么?
思路:进制转换,一般都是用除K取余法
ls.append()是在最后位置添加元素,要反转一下才是答案
year=2019
ls=[]
while year!=0:
ls.append(chr(ord('A')+year%26-1))
year=year//26
ls.reverse()
#print(ls)#输出为['B', 'Y', 'Q']
print(*ls)#输出为B Y Q
#可以发现,在列表前加*号,会将列表拆分成一个一个的独立元素,不光是列表,元组、字典也是
9.K好数
如果一个自然数N的K进制表示中任意的相邻的两位都不是相邻的数字,那么我们就说这个数是K好数。求L位K进制数中K好数的数目。例如K = 4,L = 2的时候,所有K好数为11、13、20、22、30、31、33 共7个。由于这个数目很大,请你输出它对1000000007取模后的值。
输入格式
输入包含两个正整数,K和L。
输出格式
输出一个整数,表示答案对1000000007取模后的值。
样例输入
4 2
样例输出
7
数据规模与约定
对于30%的数据,KL <= 106;
对于50%的数据,K <= 16, L <= 10;
对于100%的数据,1 <= K,L <= 100。
思路:动态规划DP问题
“L位K进制数”:如“2位4进制数”,它是指这个数是个两位数,其中个位数是4进制(即从[0,3]中取一个数作为个位),十位数也是4进制数。
K好数要求:任意相邻的两位不是相邻的数字。
核心:dp[i][j]=dp[i][j]+dp[i-1][k]
当前位置的数总数=当前位置的数的数目+前一个位置的数的总数。
dp[i][j]表示长度为i+1,以j开头的数有多少个,h用来遍历每种进制数
当k=4,l=2时候 j = 0 就是加入0之后 有三种情况 00 02 03 (因为是k进制所以最大为k-1)
j=1时 有组合 11 13 两种 j = 2的时候 有 20 22 两种 j =3 30 31 33 三种
所以状态转移方程为dp[i][j] = dp[i][j] + dp[i-1][h]
h就是从0开始到k-1遍历的数字 同时必须满足 abs(h-j) != 1 因为这样才不会相邻
最后答案为7 → 7 = 2 + 2 + 3 不要加上j=0的情况,当长度大于等于2时 0不能作为数字的开头
所以那三种情况不能算
def count(length,kind,ans):
for i in range(1,kind):
dp[0][i]=1
for i in range(1,length):
for j in range(kind):
for k in range(kind):
if abs(j-k)!=1:
if j-1==0 and k==0:#排除首位为0的情况
continue
dp[i][j]=dp[i][j]+dp[i-1][k]
dp[i][j]%=MOD
for i in range(kind):
ans+=dp[length-1][i]
ans%=MOD
return ans
K,L=map(int,input().split())
ans=0
MOD=1000000007
dp=[[0 for _ in range(max(L,K))] for _ in range(max(L,K))]
if K==1 and L==1:#1不是K好数
print(0)
elif K>1 and L==1:#1位的K进制的K好数总数就是K个
print(K)
elif L>1:
print(count(L,K,ans))
10.分割项链
问题描述
两个强盗刚刚抢到一条十分珍贵的珍珠项链,正在考虑如何分赃。由于他们不想破坏项链的美观,所以只想把项链分成两条连续的珍珠链。然而亲兄弟明算账,他们不希望因为分赃不均导致不必要的麻烦,所以他们希望两条珍珠链的重量尽量接近。于是他们找到了你,希望让你帮忙分赃。
我们认为珍珠项链是由n颗不同的珍珠组成的,我们可以通过称重,分别称出每颗珍珠的重量(我们忽略连接珍珠的“链”的重量)。你要求的是每个人至少能得到多重的珍珠(即分赃少的那个人能得到多重的珍珠)。
输入格式
第一行一个整数n,表示这个珍珠项链有多少颗珍珠。第二行n个整数,顺时针给出每颗珍珠的重量wi。(你要注意的是,第一课珍珠和最后一颗珍珠是相连的)
输出格式
一个整数,表示分赃少的那个人能得到多重的珍珠。
样例输入
7
1 2 3 4 3 2 1
样例输出
7
数据规模和约定
对于30%的数据,n<=200;
对于60%的数据,n<=2000;
对于100%的数据,n<=50000,0<wi<=1000。
r%n解决循环取数,
n=int(input())
ls=list(map(int,input().split()))
all=sum(ls)
su=all//2
an,sum,nu=0,0,0
l,r=0,0
while 1:
while sum<su:
sum+=ls[r%n]
r+=1
while sum>su:
sum-=ls[l%n]
l+=1
an=max(an,sum)
nu+=1
if nu==2*n:
break
print(an)
11.丑数
题目:我们把只包含因子2,3和5的数称作丑数(Ugly Number)。求按从小到大的顺序的第1500个丑数。例如6,8都是丑数,但14不是,因为它包含因子7,习惯上我们把1当做第一个丑数。
解题思路:如果是逐个判断,直观但不高效。即使一个数字不是丑数,我们还是需要对它求余数和除法操作。
换一种思路,只需要计算丑数,而不在非丑数上花费时间。根据丑数的定义,丑数应该是另一个数乘以2,3,或者5的结果(1除外)。因此我们可以创建一个数组,里面的数字是排好序的丑数,每一个丑数都是前面的丑数乘以2,3,或者5得到的。这种思路的关键在于怎样确保数组里面的数是排好序的。假设若干个丑数已经拍好序存放在数组中,并把最大的丑数记为M。首先考虑把已有的丑数乘以2.在乘以2时,能得到若干个小于或等于M的结果,这些已经在按顺序生成的数组中了,不用考虑。只有考虑若干个大于M的结果,我们只需要第一个大于M的结果,记为M2,。同样,我们把已有的每一个丑数乘以3,5,能得到第一个大于M的结果为M3,M5。那么下一个丑数应该是M2,M3,M5三者的最小值。利用三个指针,记住丑数的位置,去更新这些位置。
这种方法以较小的空间消耗换取了时间效率的提升。
def GetUglyNumber(index):
if index<=0:
return 0
uglyNumber=[ 0 for i in range(1500)]#需要能容纳1500个丑数的数组
uglyNumber[0]=1
nextindex=1
p2,p3,p5=0,0,0
while nextindex<index:
ls = []
ls=[uglyNumber[p2]*2,uglyNumber[p3]*3,uglyNumber[p5]*5]
min1=min(ls)
uglyNumber[nextindex]=min1
while uglyNumber[p2]*2<=min1:
p2+=1
while uglyNumber[p3]*3<=min1:
p3+=1
while uglyNumber[p5]*5<=min1:
p5+=1
print(uglyNumber[nextindex])
nextindex+=1
ugly=uglyNumber[nextindex-1]
return ugly
print("第1500个丑数为",GetUglyNumber(1500))#找第1500个丑数
12.数组中的逆序对
题目:在数组中的两个数字如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
解题思路:如果是按顺序扫描整个数组,每扫描到一个数字的时候,逐个比较该数字和它后面的数字的大小。时间复杂度为o(n^2),我们可以找更快的方法。
我们可以先将数组拆分成两个子数组,一直继续拆分,直到分解为两个长度为1的子数组,把长度为1的子数组合并、排序、并统计逆序对,把长度为2的子数组合并、排序、并统计逆序对…
我们先用两个指针分别指向两个子数组的末尾,并每次比较两个指针指向的数字。如果第一个子数组中的数字大于第二个子数组中的数字,则构成逆序对,并且逆序对的数目第二个数组中剩余数字的个数。如果是小于等于,则不构成逆序对。在每一次比较的时候,我们都把较大的数字从后往前复制到一个辅助数组中去,确保辅助数组中的数字是递增排序的。对应的指针要向前移动一位,进行接下一轮的比较。其实这个排序的过程实际上就是归并排序,其时间复杂度为O(nlogn)。
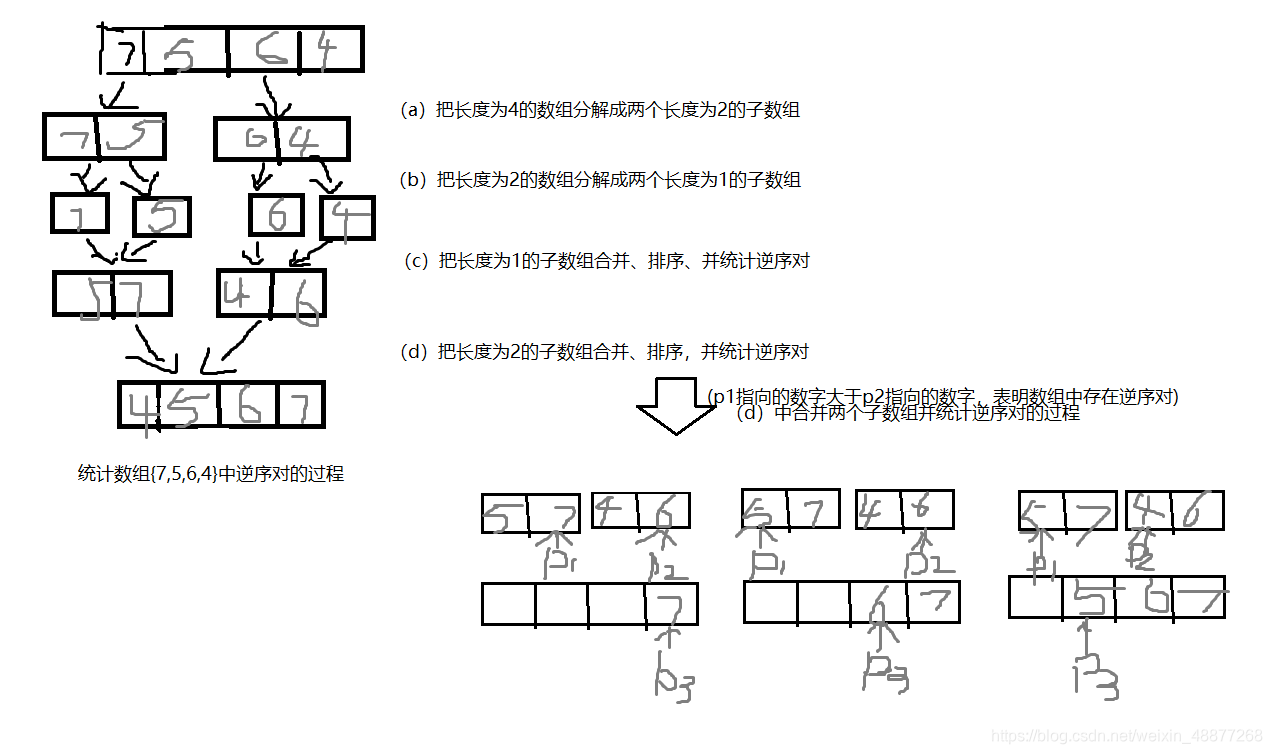
def InversePairsCore(data,copy,start,end):
if start==end:
copy[start]=data[start]
return 0
length=(end-start)//2
left=InversePairsCore(copy,data,start,start+length)
right=InversePairsCore(copy,data,start+length+1,end)
#i初始化为前半段最后一个数字的下标
i=start+length
#j初始化为后半段最后一个数字的下标
j=end
indexcopy=end
count=0
while (i>=start)and(j>=start+length+1):
if data[i]>data[j]:
copy[indexcopy]=data[i]
indexcopy-=1
i-=1
count+=j-start-length
else:
copy[indexcopy]=data[j]
indexcopy-=1
j-=1
while i>=start:
copy[indexcopy]=data[i]
indexcopy-=1
i-=1
while j>=start+length+1:
copy[indexcopy]=data[j]
indexcopy-=1
j-=1
return left+right+count
def InversePairs(data,length):
if length<0:
return 0
copy=[0 for i in range(length)]
for i in range(length):
copy[i]=data[i]
count=InversePairsCore(data,copy,0,length-1)
return count
data=[7,5,6,4]
print(InversePairs(data,4))
13.绘制地图(已知前中序找后序)
问题描述
最近,WYF正准备参观他的点卡工厂。WYF集团的经理氰垃圾需要帮助WYF设计参“观”路线。现在,氰垃圾知道一下几件事情:
1.WYF的点卡工厂构成一颗二叉树。
2.一共有n座工厂。
3.他需要把这颗树上的点以后序遍历的方法列出来,才能绘制地图。
还好,最近他的属下给了他先序遍历和中序遍历的数据。可是,氰垃圾最近还要帮㊎澤穻解决一些问题,没有时间。请你帮帮他,替他完成这项任务。由于氰垃圾的一些特殊的要求,WYF的参观路线将会是这棵树的后序遍历。
输入格式
第一行一个整数n,表示一共又n座工厂。
第二行n个整数,表示先序遍历。
第三行n个整数,表示中序遍历。
输出格式
输出共一行,包含n个整数,为后序遍历。
样例输入
8
1 2 4 5 7 3 6 8
4 2 7 5 1 8 6 3
样例输出
4 7 5 2 8 6 3 1
数据规模和约定
0<n<100000,。保证先序遍历和中序遍历合法,且均为1~n。
解题思路:重建二叉树,我们需要知道几种遍历方法的特点:A.对于前序遍历,第一个肯定是根节点;B.对于后序遍历,最后一个肯定是根节点;C.利用前序或后序,确定根节点,在中序遍历中,根节点的两边就可以分出左子树和右子树;D.对左子树和右子树分别做前面3点的分析和拆分,相当于递归,即可重建出完整的二叉树。
python中,可以用对列表切片的方式,得到左右子树,很方便,再进行递归。但是在蓝桥杯系统里面对有100000个结点的测试用例来说,python的递归就超时了,会失分一点。
class TreeNode:
def __init__(self,x):
self.val=x
self.left=None
self.right=None
class Solution:
# 返回构造的TreeNode根节点
def reConstructBinaryTree(self,pre,tin):
if len(pre)==0:
return None
root=TreeNode(pre[0])#先序的第一个元素为根节点
TinIndex=tin.index(pre[0])
root.left=self.reConstructBinaryTree(pre[1:TinIndex+1],tin[0:TinIndex])
root.right=self.reConstructBinaryTree(pre[TinIndex+1:],tin[TinIndex+1:])
return root
def PostTraversal(self,root):#后序遍历
if root!=None:
self.PostTraversal(root.left)
self.PostTraversal(root.right)
print(root.val,end=' ')
# pre=[1,2,4,7,3,5,6,8]
# tin=[4,7,2,1,5,3,8,6]
#后序=4 7 5 2 8 6 3 1
n=input()
pre=input().split()
tin=input().split()
S=Solution()
root=S.reConstructBinaryTree(pre,tin)
S.PostTraversal(root)
14.带分数
问题描述
100 可以表示为带分数的形式:100 = 3 + 69258 / 714。
还可以表示为:100 = 82 + 3546 / 197。
注意特征:带分数中,数字1~9分别出现且只出现一次(不包含0)。
类似这样的带分数,100 有 11 种表示法。
输入格式
从标准输入读入一个正整数N (N<1000*1000)
输出格式
程序输出该数字用数码1~9不重复不遗漏地组成带分数表示的全部种数。
注意:不要求输出每个表示,只统计有多少表示法!
样例输入1
100
样例输出1
11
解题思路:由题意知n=a+b/c,所以b=cn-ca=c(n-a)同时题目还要求,带分数中,数字1-9分别出现并且只出现一次。我们可以dsf_int()先遍历a(即整数部分)的值,然后在每一个a一定的情况下来遍历讨论分母的值,同时在dsf_score_mom()遍历每一个分母的同时,通过check(a,c)函数讨论当前的整数部分a和分母部分c是否满足要求,如满足要求就ans+=1,最后返回ans的值即可。
在深度回溯搜索过程中,要注意以下几个要求:
1.因为每个数字只出现一次,所以我们可以使用st=set()记录1~9在n,c,b中出现的情况和出现的次数。
2.a的值介于1~n-1之间
3.a,b,c三个数中一定不会包含数0
4.b的值一定大于a,c的值,同时b可以被c或者(n-a)所整除。这一点,可以用于减枝操作:因为b>=c,所以c的位数一定小于等于b的位数。在搜索过程中如果长度超过,就可以减枝掉。
def withScore(n):
st = set() # 集合判断
ans = 0 # 统计符合的个数
def check(a, c): # 该函数用来检查整数a和分母c是否合法
b = (n - a) * c
if (not b) or b < c or '0' in str(b):
return False
backup = st.copy()
while b:
temp = int(b % 10)
if (not temp) or temp in backup:
return False
backup.add(temp) # 把b的每一位放入
b = int(b / 10)
for i in range(1, 10):
if i not in backup:
return False # 如果a,b,c三个数所有的位不包含全部的1,2,...9那么不合法
return True
def dsf_score_mom(a, len_a, c, len_c):
nonlocal ans#nonlocal声明的变量不是局部变量,也不是全局变量,而是外部嵌套函数内的变量。
if c != 0 and '0' in str(c): # c中不包含0
return
if check(a, c):
ans += 1 # 有符合的结果+1
for i in range(1, 10):
if i not in st and len_c < (9 - len_a) // 2: # 该位上的数还没有出现过
st.add(i)
dsf_score_mom(a, len_a, c * 10 + i, len_c + 1)
st.remove(i)
def dsf_int(a, len_a):
if a >= n or (a != 0 and '0' in str(a)):
return
if a:#在确定a的基础上,遍历每一个c
dsf_score_mom(a, len_a, 0, 0)
for i in range(1, 10):
if i not in st and len_a < min(7, len(str(n))):
st.add(i)
dsf_int(a * 10 + i, len_a + 1)
st.remove(i)
dsf_int(0, 0)
return ans
n=int(input())
print(withScore(n))
15.剪格子
资源限制
时间限制:1.0s 内存限制:256.0MB
问题描述
如下图所示,3 x 3 的格子中填写了一些整数。
±-–±-+
|10 1|52|
±-***–+
|20|30 1|
*******–+
| 1| 2| 3|
±-±-±-+
我们沿着图中的星号线剪开,得到两个部分,每个部分的数字和都是60。
本题的要求就是请你编程判定:对给定的m x n 的格子中的整数,是否可以分割为两个部分,使得这两个区域的数字和相等。
如果存在多种解答,请输出包含左上角格子的那个区域包含的格子的最小数目。
如果无法分割,则输出 0。
输入格式
程序先读入两个整数 m n 用空格分割 (m,n<10)。
表示表格的宽度和高度。
接下来是n行,每行m个正整数,用空格分开。每个整数不大于10000。
输出格式
输出一个整数,表示在所有解中,包含左上角的分割区可能包含的最小的格子数目。
样例输入1
3 3
10 1 52
20 30 1
1 2 3
样例输出1
3
解题思路:深度优先算法,注意可以剪枝的情况。用一个二维数组标记每个位置有没有访问过。
def dfs(i,j,temp_sum,cnt):#深度搜索 cnt记录已经搜索到的格子数
global ans
if temp_sum>Sum//2:#搜索到的和已经大于一半,#剪枝
return
if temp_sum==Sum//2:
ans=min(ans,cnt)#如果存在多种解答,请输出包含左上角格子的那个区域包含的格子的最小数目。
return
used[i][j]=1#标记这个点为已访问,深度搜索,判断它的四个方向
if i+1<n and used[i+1][j]==0:#如果现在不是最后一行,那么可以往下走
dfs(i+1,j,temp_sum+s[i][j],cnt+1)
if i-1>=0 and used[i-1][j]==0:#如果现在不是最顶上的一行,那么可以往上走
dfs(i-1,j,temp_sum+s[i][j],cnt+1)
if j-1>=0 and used[i][j-1]==0:#如果现在不是最左边的一列,那么可以往左边走
dfs(i,j-1,temp_sum+s[i][j],cnt+1)
if j+1<m and used[i][j+1]==0:#如果现在不是最右边的一列,那么可以往右边走
dfs(i,j+1,temp_sum+s[i][j],cnt+1)
used[i][j]=0#执行到这说明s[i][j]这个数字不行,还原为未使用状态
#m列n行
m,n=map(int,input().split())
s=[]
Sum=0
for i in range(n):
s.append(list(map(int,input().split())))
Sum+=sum(s[i])#求出该矩阵所有数据总和
used=[[0 for i in range(m)] for j in range(n)] #用来标记每个位置是否被访问过
ans=100#因为题目说n,m<10的,所以总的格子数不会超过100
dfs(0,0,0,0)#我们可以让搜索从左上角出发,这样遍历出来的每一种方案都是包含左上角块块的。
if ans<100:
print(ans)
else:
print(0)#没有分割,输出0
16.子串分值

解题思路:首先注意这题里的子串的含义,虽然字母是一样的,但是所在位置不同,那也应该看成不同的子串,分别都要计算。我们主要就是计算每个位置上对S分支的贡献度,一般思维会想到按一个子串一个子串的看,就是按行,这样的做法遇到数据很大的时候会超时O(n^2)。如果我们是按列看,只用遍历每个字符一遍,就能算出分值,O(n)。某个字母标红,表示这个字母有贡献值+1,我们可以看出横着计算和竖着计算的结果应该是一样的。

我们需要从遍历到的字符,分别从左看和从右看,计算出各自到相同字符的长度,再左边的长度乘以右边的长度,就能得到此时这个字符的贡献值。再将其累加即可。

S=input()#输入字符串
sumvalue=0
#遍历计算一个字符的贡献值
for i in range(len(S)):
lvalue=0
rvalue=0
temp=S[i]#第i个字符
loc=i-1
while(loc>=0 and S[loc]!=temp):#从这个数左边算到重复这个数的长度
loc-=1
lvalue+=1
loc=i+1
while(loc<len(S) and S[loc]!=temp):#从这个数右边算到重复这个数的长度
loc+=1
rvalue+=1
sumvalue+=((lvalue+1)*(rvalue+1))#左边乘右边
print(sumvalue)
17.子串分值和

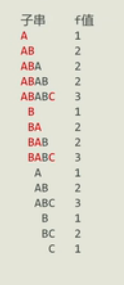
同理,如图将有贡献的字母标红(后面那几个也要标红的,图片上没标),和子串分值类似。把重复的字符都看成第一个字符的贡献。还是用这个字符(左边到重复字符的长度)X(这个字符右边的长度),累加即可。
S=input()
aindex={}#字典用来记录每个字符最后一次出现的位置
for i in S:
aindex[i]=0#先初始化,每个位置都还没有出现过
n=len(S)
ans=0
for i in range(1,n+1):#字符串S的下标为[1,2,....n]
ans+=(i-aindex[S[i-1]])*(n-i+1)
aindex[S[i-1]]=i
print(ans)
18.子集
(来自力扣78,难度中等)
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10
-10 <= nums[i] <= 10
nums 中的所有元素 互不相同
解题思路:回溯搜索算法,在每个字符的基础上,去深度遍历后面字符的位置,遍历到最后再返回到上一层。tem记录当前这个个子集,向里面添加后面的元素。tem记录在res里,记录每个子集结果。
def subset(i,tmp):
global n
res.append(tmp)
print(res)
for j in range(i,n):
subset(j+1,tmp+[nums[j]])#深度搜索找下一个位置
nums=input()#输入一个字符串会变为列表
n=len(nums)
res=[]#用来保存找到子集的结果
subset(0,[])
print(res)
"""
输入:abc
res队列里的变化:
[[]]
[[], ['a']]
[[], ['a'], ['a', 'b']]
[[], ['a'], ['a', 'b'], ['a', 'b', 'c']]
[[], ['a'], ['a', 'b'], ['a', 'b', 'c'], ['a', 'c']]
[[], ['a'], ['a', 'b'], ['a', 'b', 'c'], ['a', 'c'], ['b']]
[[], ['a'], ['a', 'b'], ['a', 'b', 'c'], ['a', 'c'], ['b'], ['b', 'c']]
[[], ['a'], ['a', 'b'], ['a', 'b', 'c'], ['a', 'c'], ['b'], ['b', 'c'], ['c']]
"""
19.子集II
(力扣90,难度中等,与上一题不同之处要去重)
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例 1:
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10
-10 <= nums[i] <= 10
解题思路:与前面那题的不同之处在于有重复元素,不能有重复子集。为解决这一问题,可以先将元素排序,再深度回溯搜索,如果遇到没有重复过的,再加入到res中。
def subset(i,tmp):
global n
if tmp not in res:#与前面那题不同:就加了个判断语句
res.append(tmp)
for j in range(i,n):
subset(j+1,tmp+[nums[j]])#深度搜索找下一个位置
nums=list(input())#输入一个字符串会变为列表
#与前面那题不同,要先排序,保证重复元素都挨在一起,这样可以避免后面有重复的
nums.sort()
n=len(nums)
res=[]#用来保存找到子集的结果
subset(0,[])
print(res)
20.修改数组

第二次遇到这题了,还是很妙的方法,并查集。
def find_set(x):
if x!=S[x]:
S[x]=find_set(S[x])
return S[x]
N=1000002
S=[]
n=int(input())
A=input().split()
for i in range(N):
S.append(i)
for i in range(n):
A[i]=int(A[i])
root=find_set(A[i])
A[i]=root
S[root]=find_set(root+1)
for i in A:
print(i,end=' ')
"""
输入:
5
2 1 1 3 4
输出:
2 1 3 4 5
"""
21.合根植物
问题描述
w星球的一个种植园,被分成 m * n 个小格子(东西方向m行,南北方向n列)。每个格子里种了一株合根植物。
这种植物有个特点,它的根可能会沿着南北或东西方向伸展,从而与另一个格子的植物合成为一体。
如果我们告诉你哪些小格子间出现了连根现象,你能说出这个园中一共有多少株合根植物吗?
输入格式
第一行,两个整数m,n,用空格分开,表示格子的行数、列数(1<m,n<1000)。
接下来一行,一个整数k,表示下面还有k行数据(0<k<100000)
接下来k行,第行两个整数a,b,表示编号为a的小格子和编号为b的小格子合根了。
格子的编号一行一行,从上到下,从左到右编号。
比如:5 * 4 的小格子,编号:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
17 18 19 20
样例输入
5 4
16
2 3
1 5
5 9
4 8
7 8
9 10
10 11
11 12
10 14
12 16
14 18
17 18
15 19
19 20
9 13
13 17
样例输出
5
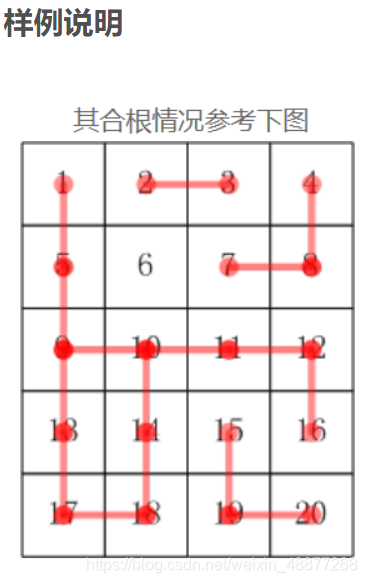
解题思路:
并查集题目,因为题目给的两个整数是有关联的,所以一直循环找每两个节点的父节点,如果父节点不一样就将它们两个点合并,合并一次,集合里的节点数就少一个。再继续去判断其他的两个点。最后剩下的节点数,就是合根植物的个数。
def Find(x):#找到x的父节点
p=x
while x!=pre[x]:#如果x不是他本身,就一直循环找到父节点为止 注意这里必须用while
x=pre[x]
while p!=x:#路径压缩,用来优化,也可以不加
p,pre[p]=pre[p],x
return x
m,n=input().split()
all=int(m)*int(n)
pre=[i for i in range(all)]+[0]*10000#初始化一个足够大的列表,并查集
k=int(input())
for i in range(k):
a,b=map(int,input().split())
aa=Find(a)
bb=Find(b)
if aa!=bb:#如果父节点不一样就合并,同时合并的话,集合就会少一个
pre[aa]=pre[bb]
all-=1
print(all)
22.杨辉三角
样例输入
4
样例输出
1
1 1
1 2 1
1 3 3 1
数据规模与约定
1 <= n <= 34。
n=int(input())
A=[[0]*n for _ in range(n)]
for i in range(n):
A[i][0]=1
A[i][i]=1
for x in range(2,n):
y=1
while y<x:
A[x][y]=A[x-1][y-1]+A[x-1][y]
y+=1
for a in range(n):
b=A[a][:a+1]
for c in b:
print(c,end=' ')
print()
23.字母图形
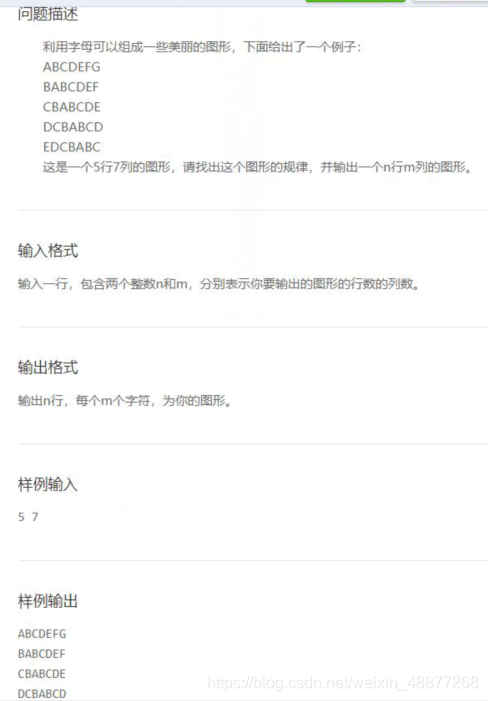
解题思路:找规律,把要打印的东西看成两部分的拼接,每次修改字符串的值。注意i的范围
s='ABCDEFGHIJKLMNOPQRSTUVWXYZ'
n,m=input().split()
a=s[0:eval(m)]
for i in range(1,eval(n)+1):
print(a)
a=s[i]+a[0:-1]
24.寻找2020

解题思路:填空题,就可以用暴力解法,依次挨个判断有没有符合的,有的话个数+1。从这题中,学会如何读取文件,去掉头尾空格换行。
def check(s):
return s=='2020'
data=[]
with open('test.txt',mode='r',encoding='utf-8') as fp:#学会读文件写法
for line in fp:
line=list(line.strip())#strip()用于移除开头或结尾的字符(默认为空格和换行)
data.append(line)
#print(data)
m,n=len(data),len(data[0])#m行,n列 学会如何获取一个矩阵的行列
count=0
for i in range(m):
for j in range(n):
#行
if i+3<n and check(data[i][j]+data[i+1][j]+data[i+2][j]+data[i+3][j]):
count+=1
#列
if j+3<m and check(data[i][j]+data[i][j+1]+data[i][j+2]+data[i][j+3]):
count+=1
#斜
if i+3<n and j+3<m and check(data[i][j]+data[i+1][j+1]+data[i+2][j+2]+data[i+3][j+3]):
count+=1
print(count)
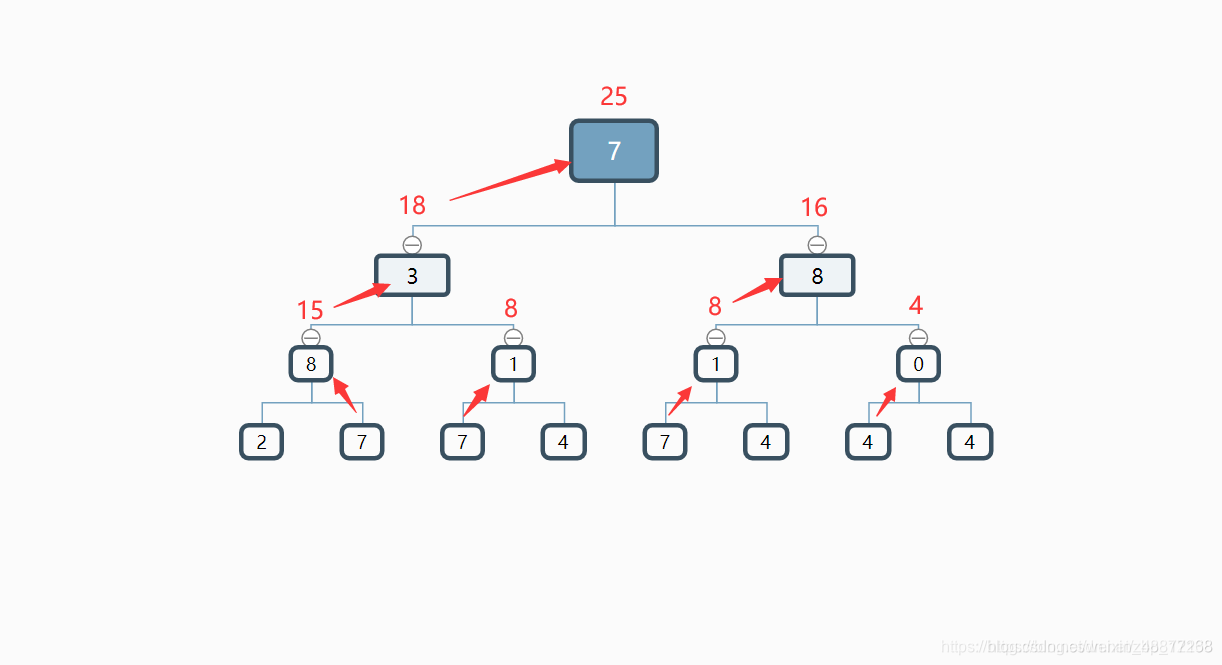
25.数字三角形
问题描述
(图3.1-1)示出了一个数字三角形。 请编一个程序计算从顶至底的某处的一条路
径,使该路径所经过的数字的总和最大。
●每一步可沿左斜线向下或右斜线向下走;
●1<三角形行数≤100;
●三角形中的数字为整数0,1,…99;

输入格式
文件中首先读到的是三角形的行数。
接下来描述整个三角形
输出格式
最大总和(整数)
样例输入
5
7
3 8
8 1 0
2 7 4 4
4 5 2 6 5
样例输出
30
解题思路:题目说找顶至底的某一条路径,换个思路,可以从底至顶。把大的问题看成许多个小问题,从下往上找,每次选出最大值,那么根节点就是所求的最大值。
n=int(input())
arr=[]
for i in range(n):
ls=list(map(int,input().split()))
arr.append(ls)
#注意range倒序输出写法,也可以reversed(range(0,n))
for i in range(n-1,0,-1):#i的取值n-1,n-2...3,2,1
for j in range(i):#j的取值0,1,2...i-1
arr[i-1][j]=arr[i-1][j]+max(arr[i][j],arr[i][j+1])
print(arr[0][0])
26.字典统计词频

解题思路:直接用dic.get()
freqDict=eval(input())
word=list(input().split())
for i in word:
freqDict[i]=freqDict.get(i,0)+1#注意get()用法
print(freqDict)
27.摩斯电码转换


解题思路:建立字典,找对应关系。
dict1 = {'a':'.-' , 'b':'-...', 'c':'-.-.', 'd':'-.' , 'e':'.' ,
'f':'..-.', 'g':'--.' , 'h':'....', 'i':'..' , 'j':'.---',
'k':'-.-' , 'l':'.-..', 'm':'--' , 'n':'-.' , 'o':'---' ,
'p':'.--.', 'q':'--.-', 'r':'.-.' , 's':'...' , 't':'-' ,
'u':'..-' , 'v':'...-', 'w':'.--' , 'x':'-..-', 'y':'-.--', 'z':'--..',
'0':'-----' , '1':'.----' , '2':'..---' , '3': '...--', '4': '....-' ,
'5': '.....', '6': '-....', '7': '--...', '8': '---..', '9': '----.' }
letters=input().lower()#将字符串中的大写字母转换为小写
for letter in letters:
message=''
if letter not in dict1:
print(letter,end='')
else:
print(dict1[letter],end='')
28.音节判断
小明对类似于 hello 这种单词非常感兴趣,
这种单词可以正好分为四段,
第一段由一个或多个辅音字母组成,
第二段由一个或多个元音字母组成,
第三段由一个或多个辅音字母组成,
第四段由一个或多个元音字母组成。
给定一个单词,请判断这个单词是否也是这种单词,如果是请输出yes,否则请输出no。
元音字母包括 a, e, i, o, u,共五个,其他均为辅音字母。
【输入格式】
输入一行,包含一个单词,单词中只包含小写英文字母。
【输出格式】
输出答案,或者为yes,或者为no。
【样例输入】lanqiao
【样例输出】yes
【样例输入】world
【样例输出】no
解题思路:将单词的辅音标记为0,元音标记为1,那么符合要求的单词形态为0+1+0+1,在限定的开头必须为0,最后必须为1 的情况下,01交替为3次,即前后元素相加结果为1的次数为3。(这个思路真妙)
word=input().strip()
h=[int(c in 'aeiou') for c in word]
#首字母不能是元音 尾字母不能是辅音
if h[0]==1 or h[-1]==0:
print('no')
exit()
count=0
for i in range(1,len(h)):
if h[i-1]+h[i]==1:
count+=1
if count==3:
print('yes')
else:
print('no')
29.数字9
问题描述】在1至2019中,有多少个数的数位中包含数字9?
- 注意,有的数中的数位中包含多个9,这个数只算一次。例如,1999这个数包含数字9,在计算只是算一个数。
- 【答案提交】这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
count=0
for i in range(9,2020):
if '9' in str(i):
count+=1
print(count)
#答案:544
30.打印&、3、*

解题思路:这题目感觉有点问题,打印出来的都是最后一个数为3的,为什么3不能在前面呢,例如31这种,是我理解有问题吗?
主要的考察点就是,判断是不是质数,及如何在字符串前面,结尾,添加后打印。
import math
def iszhishu(a):
if a<=2:#1,2是质数
return 1
for i in range(2,int(math.sqrt(a))+1):
if a%i==0:#看一个数能不能被整除,用%,能整除说明不是质数
return 0
return 1
for i in range(3,1000,10):
if '3' not in str(i):
continue
target=iszhishu(i)
if target==1 and '33' in str(i):
print('&'+str(i)+'*')
elif '33' in str(i):
print('&'+str(i))
elif target==1:
print(str(i)+'*')
else:
print(str(i))
31.单词分析

解题思路:(桶排序)搞一个列表,长度为26,记录每个字符出现的次数,遍历单词,每个字母的ASCLL码值-97作为索引存入对应的arr,找出arr中最大的即为最多次数,有相同的无所谓,找最大值对应的索引,默认返回从左到右数第一个匹配的值的索引,此时即为字典序最小。对应的索引值+97即为对应的字符。
word=input()
ls=[0 for i in range(26)]#26个位置,每个位置初始化值为0
for i in word:
ls[ord(i)-97]+=1#ord()返回单个字符的ascii值(0-255)
maxnum=max(ls)
print(chr(ls.index(maxnum)+97))#chr()输入一个整数(0-255)返回其对于的ascii符号
print(maxnum)
32.填空题
(1)A.门牌制作

强转字符串
count=0
for i in range(1,2021):
count+=str(i).count('2')
print(count)
#624
(2)C.跑步锻炼

- datetime.datetime(year=2000, month=1,
day=1)作用:返回一个datetime类型,表示指定的日期和时间,可以精确到微秒。 - datetime.timedelta()对象代表两个时间之间的时间差,这个方法来前后移动时间,可用的参数有weeks,days,hours,minutes,seconds,microseconds等。
datetime转str格式:
datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
‘2018-06-18 16:58:46’
str格式转datetime格式:
print (datetime.datetime.strptime(“2018-06-18
16:58:46”,"%Y-%m-%d %H:%M:%S") )
2018-06-18 16:58:46
import datetime
distances=0
start_time=datetime.datetime(year=2000,month=1,day=1)#2000年1月1日00:00周六
dela=datetime.timedelta(days=1)
end_time=datetime.datetime(year=2020,month=10,day=1)#到2020年10月2日00:00这样包括10月1号周四
#start_time.weekday()返回数字0~6,0代表星期一,以此类推
while start_time<=end_time:#start_time.day表示每个月的号数
if start_time.day==1 or start_time.weekday()==0:
#1号或周一
distances+=2
else:
distances+=1
start_time+=dela
print(distances)
#8879
C.字母阵列(八个方向)
题目描述
仔细寻找,会发现:在下面的8x8的方阵中,隐藏着字母序列:“LANQIAO”。
SLANQIAO
ZOEXCCGB
MOAYWKHI
BCCIPLJQ
SLANQIAO
RSFWFNYA
XIFZVWAL
COAIQNAL
我们约定: 序列可以水平,垂直,或者是斜向;
并且走向不限(实际上就是有一共8种方向)。
上图中一共有4个满足要求的串。
下面有一个更大的(100x100)的字母方阵。
你能算出其中隐藏了多少个“LANQIAO”吗?
(见代码)
结果:41
s=[]
with open('eight.txt',mode='r',encoding='utf-8') as fp:
for line in fp:
line=list(line.strip())
s.append(line)
#dis=[[-1,-1],[-1,0],[-1,1],[0,1],[1,1],[1,0],[1,-1],[0,-1]]
dis = [
[(-i, -i) for i in range(7)],
[(-i, 0) for i in range(7)],
[(-i, i) for i in range(7)],
[(0, i) for i in range(7)],
[(i, i) for i in range(7)],
[(i, 0) for i in range(7)],
[(i, -i) for i in range(7)],
[(0, -i) for i in range(7)]
]
#遍历八个方向,且长度为0,1,2,3...6。‘LANQIAO’长度为7
#print(dis)
ans=0
for y in range(100):
for x in range(100):
for i in dis:#依次遍历八个方向
if s[y][x]=='L':
st=''
for dy,dx in i:#再遍历这个方向的不同步长
y1=y+dy
x1=x+dx
if 0<=y1<=99 and 0<=x1<=99:
st+=s[y1][x1]
else:
break
if st=='LANQIAO':
ans+=1
print(ans)
(3)D.蛇形填数

手算,发现数学规律:奇数列和偶数行的数值与他们位置有数学关系,n(n+1)/2递增,要计算20列上的,可以先算20+19=39奇数列上的,他的前面第19个数就是20行20列
D.第几个幸运数(只含因子3,5,7)
题目描述
到x星球旅行的游客都被发给一个整数,作为游客编号。
x星的国王有个怪癖,他只喜欢数字3,5和7。
国王规定,游客的编号如果只含有因子:3,5,7,就可以获得一份奖品。
我们来看前10个幸运数字是:
3 5 7 9 15 21 25 27 35 45
因而第11个幸运数字是:49
小明领到了一个幸运数字 59084709587505,他去领奖的时候,人家要求他准确地说出这是第几个幸运数字,否则领不到奖品。
请你帮小明计算一下,59084709587505是第几个幸运数字。
需要提交的是一个整数,请不要填写任何多余内容。
结果:1905
ls=[0 for i in range(10000000)]
ls[0]=1
p3,p5,p7=0,0,0
nextnum=0
nextindex=1
while nextnum!=59084709587505:
nextnum=min([ls[p3]*3,ls[p5]*5,ls[p7]*7])
ls[nextindex]=nextnum
while ls[p3]*3<=nextnum:
p3+=1
while ls[p5]*5<=nextnum:
p5+=1
while ls[p7]*7<=nextnum:
p7+=1
nextindex+=1
print(nextindex-1)
(4)E.排序

冒泡排序 条件:相邻交换 交换100次 只有小写字母 不重复 最短 字典序最小
首先,相邻交换,只有小写字母,不重复,最短可以初步从直接逆序开始找,因为这样短的串可以交换最多的次数。逆序的交换次数为n(n-1)/2,当n=15时,全部逆序可以交换105次,即onmlkjihgfedcba,从这个字符串出发,开始移动字母位置。
现在要交换100次,所以这个o肯定要往右移,很容易想到nmlkjoihgfedcba,这样是100次
但是,再看条件:字典序最小,所以要尽可能把小的往左移,考虑到多了五次,我们就把第五个字母j放在最后,这样jonmlkihgfedcba,每次交换都少移动五次,最后到j时恢复到逆序。
答案:jonmlkihgfedcba
还是用手算的,下面的代码用来验证,正确。
def bubbl_sort(alist, count):
for i in range(len(alist) - 1):
for j in range(len(alist) - 1 - i):
if alist[j] > alist[j+1]:
count += 1
alist[j], alist[j+1] = alist[j+1], alist[j]
#print(alist)
return (alist, count)
count = 0
print(bubbl_sort(list('jonmlkihgfedcba'), count))
#(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o'], 100)
33.编程题
次数差
题目描述
x星球有26只球队,分别用a~z的26个字母代表。他们总是不停地比赛。
在某一赛段,哪个球队获胜了,就记录下代表它的字母,这样就形成一个长长的串。
国王总是询问:获胜次数最多的和获胜次数最少的有多大差距?(当然,他不关心那些一次也没获胜的,认为他们在怠工罢了)
输入,一个串,表示球队获胜情况(保证串的长度<1000)
要求输出一个数字,表示出现次数最多的字母比出现次数最少的字母多了多少次。
比如:
输入:
abaabcaa
则程序应该输出:
4
解释:a出现5次,最多;c出现1次,最少。5-1=4
再比如:
输入:
bbccccddaaaacccc
程序应该输出:
6
s=input()
dic={}
for i in s:#要遍历字符串,统计
dic[i]=dic.get(i,0)+1
ls=sorted(dic,key=lambda x:dic[x])#排序
print(dic[ls[-1]]-dic[ls[0]])
sorted(d.items(), key=lambda x: x[1]) 中
d.items() 为待排序的对象;
key=lambda x: x[1] 为对前面的对象中的第二维数据(即value)的值进行排序。
key=lambda 变量:变量[维数] 。维数可以按照自己的需要进行设置。
print(sorted(dic)) #如果是字典,则返回排序过后的key
reverse;是否倒叙.True:倒叙,False:正序 (默认False)
F.成绩统计


round()是python自带的一个函数,用于数字的四舍五入。
四舍五入,不同的数可能会有点差异,先不深究,一般那种数据出现会比较少。
使用方法:round(number,digits)
digits>0,四舍五入到指定的小数位
digits=0, 四舍五入到最接近的整数
digits<0 ,在小数点左侧进行四舍五入
如果round()函数只有number这个参数,等同于digits=0
注意审题,优秀的人也要算在及格的人里
n=int(input())
jige=0
youxiu=0
for i in range(n):
num=int(input())
if num>=85:
youxiu+=1
elif 60<=num:
jige+=1
pjige=round(((jige+youxiu)/n)*100)
pyouxiu=round((youxiu/n)*100)
print(pjige,'%',sep='')#中间不分隔
print(pyouxiu,'%',sep='')
#print()中有两个默认参数sep和end。其中sep函数是设置分隔符,默认为sep=’’(空格)
I.平面切分

规律:在同一个平面内,如果添加的每一条直线互不相交,就会增加一个平面;当添加一条直线时,这条直线与当前平面内已有直线每产生一个不同位置的交点时,这条直线对平面总数量的贡献会额外增多一个。
思路:建一个类,存放直线的A和B,表示一条直线,从第2条直线开始循环判断与它前边的所有直线的位置关系,记录下不重复的交点的个数。最后累加个数再加上本身贡献量1
class Straight:
def __init__(self,a,b):
self.a=a
self.b=b
def relation(line1,line2):
if linel.a==line2.a:
#平行
return
#不平行,求交点
x=-(line1.b-line2.b)/(line1.a-line2.a)
y=line1.a*x+line1.b
point.add((x,y))#添加交点
n=int(input())
line=[]
for i in range(n):
a,b=list(map(int,input().split()))
line.append(Straight(a,b))#把每条线,存入到列表中
res=0
if line:#如果存放线的列表不为空
res=2
for i in range(1,len(line)):
point=set()
for j in range(i):
relation(line[i],line[j])
res+=len(point)+1
print(res)

















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









