






你有没有这种感觉?看了很多Transformer、LLM的文章,却总觉得云里雾里?今天我们来聊聊大型语言模型(LLM)中的一个核心概念——Token。直到我真正理解了“Token”和“分词器”,这才是我学懂Transformer的第一次顿悟,这可能是我整个大模型学习过程中唯一一次一口气看懂的内容。虽然它看起来“基础”,但却是所有大模型推理、训练和优化的底层起点。不管是deepseek还是claude,Token都是它们能读懂和生成文字的关键。无论你是刚入门的大模型爱好者,还是在实践中苦于 Token 限制的开发者,这篇文章都会帮你从根本上理清思路。
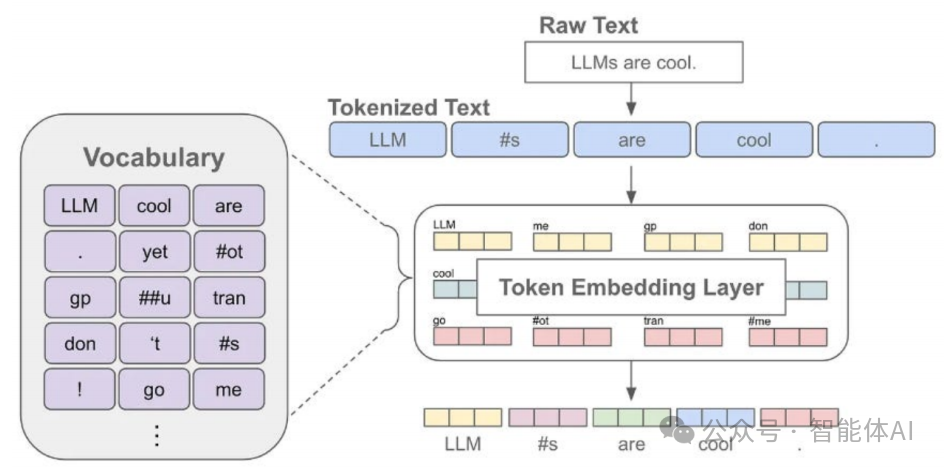
一、Token是什么?——文字的“积木块”
Token,说白了就是文本的最小单位。想象你在读一本书,书里满满都是单词。在LLM里,Token有时候就是一个完整的单词,比如“苹果”或者“你好”;有时候是单词的一部分,比如“unhappiness”可能被拆成“un”和“happiness”;甚至有时候,每个字母都算一个Token,比如“apple”被拆成“a”、“p”、“p”、“l”、“e”。
为什么Token有这么多玩法呢?因为不同的语言和任务需要不同的“颗粒度”。像英语这种单词边界清楚的语言,用整个单词做Token挺方便。但像中文这种没有明显分隔的语言,可能就需要把词拆得更细。
二、分词器——把文字“翻译”给AI的能手
那这些Token是怎么从一堆文字里蹦出来的呢?这就得靠分词器(Tokenizer)了。你可以把分词器想象成一个翻译官,它的任务是把我们写的句子变成一串串Token,让AI能看懂。分词器有几种常见的“翻译”方法:
-
字典分词:就像查字典,把句子里的词跟一个预先准备好的词表对上号。
-
BPE(Byte-Pair Encoding):从字符开始,把最常出现的字符组合起来,慢慢拼成更大的词块。
-
SentencePiece:有点像BPE,但更灵活,不管什么语言都能用。
-
WordPiece:BERT模型爱用的方式,也是把词拆成小块再组合。
举个例子:拿“Hello, I'm an AI assistant.”这句话来说,用BPE分词器可能会把它拆成这样:['Hello', ',', ' I', "'m", ' an', ' AI', ' assistant', '.']。每个小块就是一个Token,AI就靠这些小块理解整句话。
三、中文的分词
对于中文来说,分词是个很有挑战性的任务,因为中文没有像英语那样用空格来分隔单词。那么,LLM是怎么处理中文的呢?
-
字符级别分词:最简单的方法是把每个中文字符当作一个Token。例如,“你好”会被分成“[你, 好]”。这种方法虽然简单,但无法捕捉词汇的语义信息。
-
词级别分词:使用词典或统计方法将文本分割成词。例如,“长沙欢迎你”会被分成“[长沙, 欢迎, 你]”。这种方法需要一个好的词典或分词模型。
-
子词级别分词:类似于BPE(字节对编码),将常见的字符序列组合成Token。例如,“我爱长沙”可能会被分成“[我, 爱, 长, 沙]”或更大的子词。
在LLM中,子词级别分词通常是最常用的方法,因为它可以处理未登录词(out-of-vocabulary words),并且在效率和效果上都有很好的平衡。
对于中文,LLaMA系列模型使用子词分词器来处理。通过将常见的字符序列组合成Token,模型可以有效地处理中文文本。虽然这种方法在处理未登录词和提高效率方面有优势,但有时可能无法完美捕捉中文的词汇结构。例如,某些多音节词可能被不正确地拆分或合并,如“的事”被错误合并而非正确识别为“事物” (To Merge or Not to Merge)。
四、特殊Token——文字里的“交通标志”
除了普通的Token,LLM里还有一些“特殊Token”,它们就像路上的交通标志,告诉模型一些特别的信息。常见的几种有:
-
[CLS]:表示一段文字的开头。
-
[SEP]:用来分开不同的句子。
-
[PAD]:如果句子长度不够,就用这个填充一下。
-
[UNK]:遇到不认识的词,就用这个代替。
-
[MASK]:有些模型(比如BERT)用这个来玩“填空游戏”,训练时遮住一部分词。
这些特殊Token就像给AI指路的小助手,让它知道句子的结构和重点。
五、Token计数——为什么数量这么重要?
你可能会问,Token多了少了有什么关系?其实关系可大了!在LLM里,Token数量直接影响计算时间和费用。比如GPT-3用的是BPE分词,平均一个单词大概分成1.3个Token。如果你输入100个Token,AI再回你50个Token,那总共就是150个Token。很多AI服务的收费就是按Token算的,Token越多,钱包越“疼”。
举个例子:你问AI“今天天气怎么样?”,可能就10个Token,但如果写一篇长文丢进去,可能就几百个Token了。所以用AI的时候,Token计数是个得留心的点。
以下是一个Token计数的示例:
| 文本 | Token数量 | 分词结果 |
|---|---|---|
| Hello, I'm an AI assistant. | 8 | ['Hello', ',', ' I', "'m", ' an', ' AI', ' assistant', '.'] |
| 今天天气很好 | 5 | ['今', '天', '天', '气', '很', '好'] |
六、LLaMA系列模型的分词器演进
现在我们来看看具体的模型。LLaMA系列是Meta(前Facebook AI)开发的大型语言模型,目前已经发布了Llama 2和Llama 3。我们来看看它们的分词器是怎么演进的。
1、Llama 2的分词器:BPE和SentencePiece
Llama 2使用了基于字节对编码(Byte Pair Encoding, BPE)算法的分词器。BPE是一种无监督的分词算法,通过迭代地合并语料库中最频繁出现的字符对来构建词汇表。具体来说,Llama 2的分词器从字符级别开始,找出语料库中出现频率最高的字符对并合并,将合并后的字符对加入词汇表,然后重复这个过程,直到达到预设的词汇表大小(约32,000个Token)或无法继续合并为止 (Understanding the Llama2 Tokenizer).
除了BPE,Llama 2的分词器还使用了SentencePiece。SentencePiece是一个无监督的文本编码器,提供了统一的接口,支持BPE、WordPiece和Unigram等多种分词算法。SentencePiece的优势在于其灵活性和一致性。它直接在原始文本上操作,不依赖于预处理或语言特定的特征(如空格),因此可以轻松地适应不同的语言和领域。
2、Llama 3的分词器:更大的词汇量和Tiktoken
在Llama 3中,分词器进行了显著的升级。首先,词汇量从Llama 2的32,000个令牌大幅增加到了128,256个令牌。更大的词汇量使得模型能够更精细地编码输入和输出文本,提高了编码效率和下游任务性能 (Llama 3 Tokenizer).
其次,Llama 3从SentencePiece转向了Tiktoken。Tiktoken是由OpenAI开发的现代分词和编码工具,旨在更高效、更灵活地处理各种语言和文本数据。Llama 3选择Tiktoken可能基于其在编码效率和多语言支持方面的优势,以及与GPT系列模型保持一致的考虑 (In-depth understanding of Llama Tokenizer).
3、Llama 4的分词器:尚未公布
截至目前,Meta尚未公开LLaMA 4的全部细节,但据行业推测,LLaMA 4的分词器可能具备以下特征:
-
继续使用Tiktoken,优化多语言处理;
-
词汇表可能进一步扩大,覆盖更广泛的词汇;
-
在分词效率、中文支持和噪声控制方面进行深度优化;
-
更好地支持“指令跟随(Instruction Tuning)”等复杂任务。
七、总结
Token和分词器是LLM的“幕后英雄”。Token是AI处理文字的基本单位,分词器则是把文字变成Token的魔法师。从早期的WordPiece、BPE,到SentencePiece与Tiktoken,我们可以看到:分词器并不是一件小事。它影响的不只是文本编码效率,更深刻地决定了模型理解语言的方式、训练成本以及推理表现。希望这篇文章让你对Token和分词器有了清晰的认识!只有真正理解了 Token,我们才能更好地驾驭大模型,让它为我们的任务所用。如果你还想学习更多的AI大模型知识,这里我也贴心的为大家准备了一份学习资料。无偿分享给大家,VX扫描以下二维码即可领取

















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









