






大家注意:因为微信最近又改了推送机制,经常有小伙伴说错过了之前被删的文章,比如前阵子冒着风险写的爬虫,再比如一些限时福利,错过了就是错过了。
所以建议大家加个星标,就能第一时间收到推送。👇
今天给大家推荐一个Streamlit带导航的网页应用制作方法。
streamlit-option-menu是一个全新的网页导航制作模块包,安装方法:
pip install streamlit_option_menu今天的实现效果
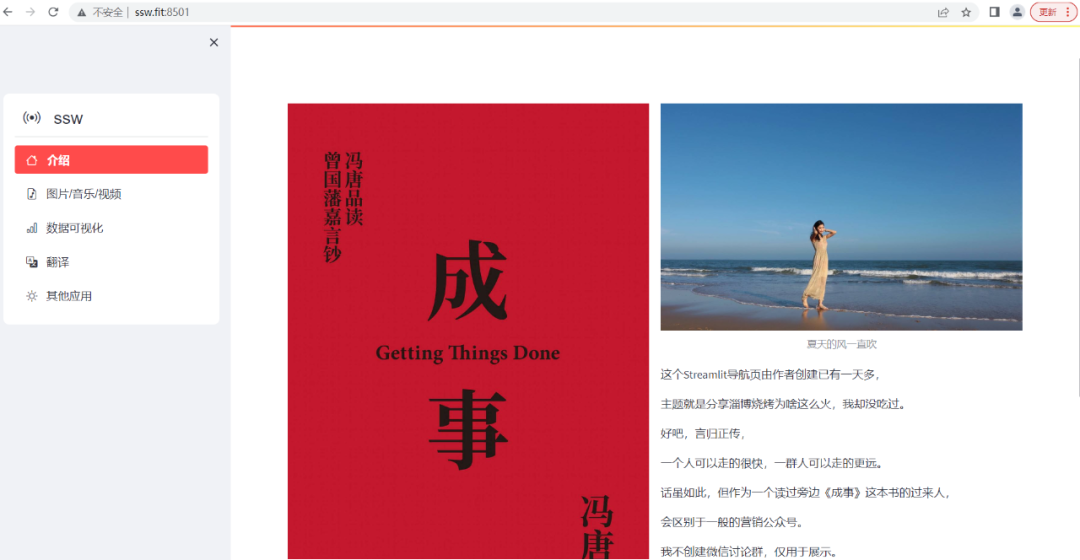
已部署到linux服务器上 http://www.ssw.fit:8501/
今天的实现效果.mp4
可以一个小脚本,很简单就做一个侧边导航栏、自我介绍、浏览图片音频视频、单词翻译、可视化、在线浏览PDF文档等等。
比较来说,它比用django、flask等框架搭一个站点,或docsify、vuepress、pelican等博客建设工具来的快。很多时候,我们只需要简单展示一些东西,收集几首有趣的歌曲,帮我翻译个单词,如此如此就好啦,不要给我搞得太麻烦!
侧边导航栏
import streamlit as st,requests,json
from streamlit_option_menu import option_menu
import streamlit.components.v1 as html
st.set_page_config(page_title="桃花朵朵开", page_icon="💖", layout="wide")
sysmenu = '''
<style>
#MainMenu {visibility:hidden;}
footer {visibility:hidden;}
'''
st.markdown(sysmenu,unsafe_allow_html=True)
with st.sidebar:
choose = option_menu("ssw", ["介绍", "图片/音乐/视频", "数据可视化", "翻译", "其他应用"],
icons=['house', 'file-earmark-music', 'bar-chart', 'translate', 'brightness-high'],
menu_icon="broadcast", default_index=0)第一个参数是文字提示。第二个参数是一个列表,用于列出你的导航栏中有哪些内容,可以理解为提纲。第三个参数是第二个参数对应的图标,这些图标可以从bootstrap网站找到。https://icons.bootcss.com/
图片音频视频
elif choose == "图片/音乐/视频":
selecte1 = option_menu(None, ["图片", "音乐", "视频"],
icons=['house', 'cloud-upload', "list-task"],
menu_icon="cast", default_index=0, orientation="horizontal")
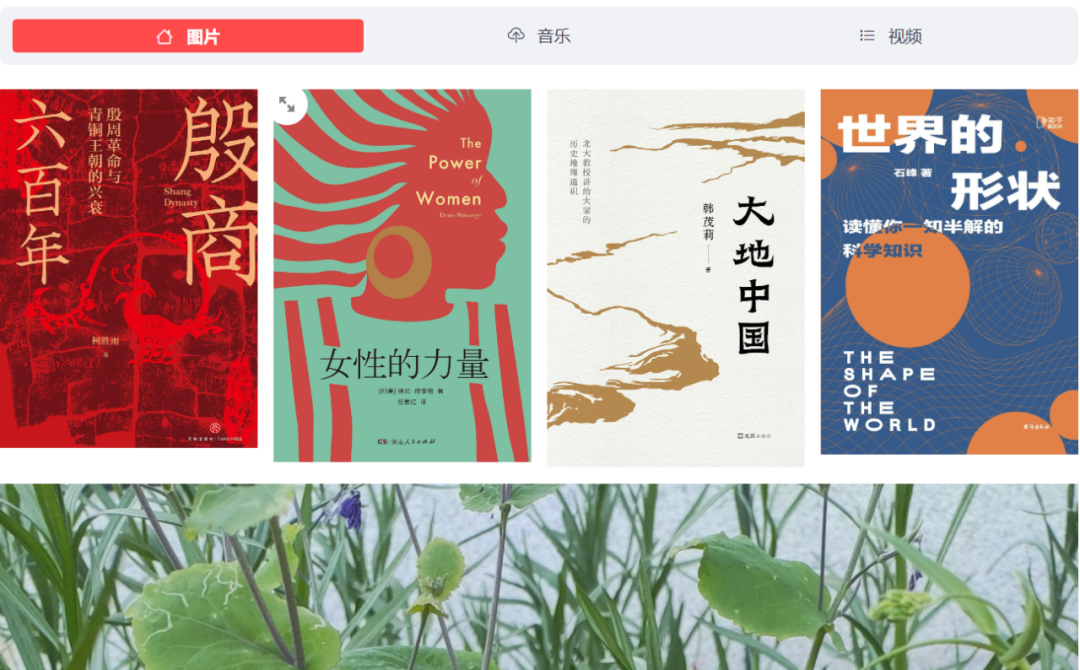
if selecte1 == "图片":
with st.container():
col1 = st.columns(1)
with col1:
st.image("./图片/1.jpg")
with st.container():
st.image("./图片/5.jpg")
elif selecte1 == "音乐":
st.write("1. Day By Day")
st.audio("./音乐/1.flac")
elif selecte1 == "视频":
st.video("./视频/1.mp4")数据可视化
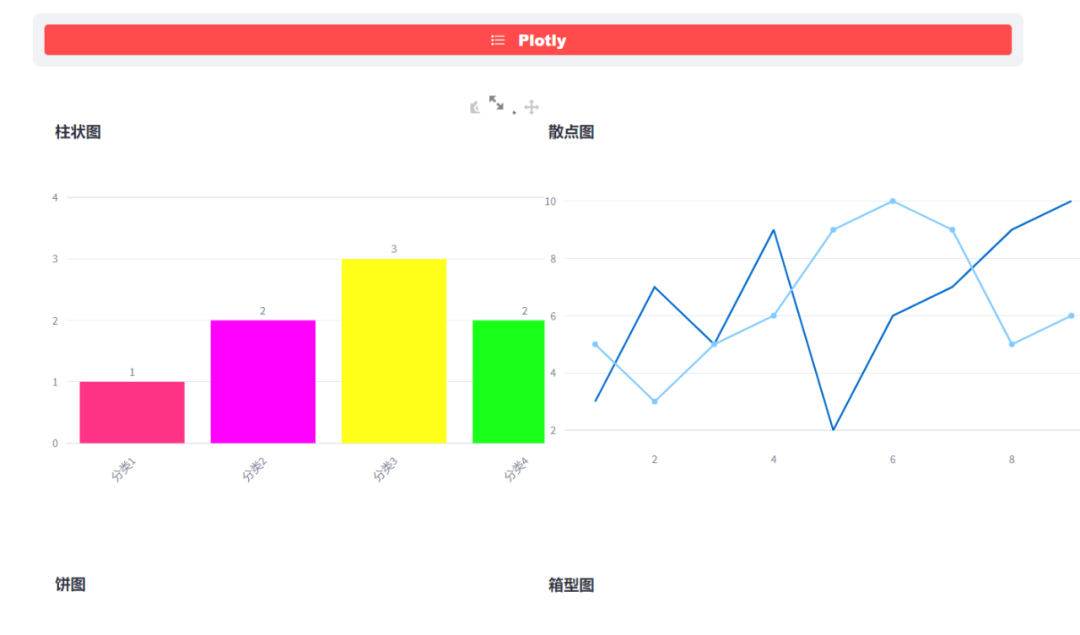
可以结合Echarts、Plotly等,如Plotly柱状图:
elif choose == "数据可视化":
selecte2 = option_menu(None, ["Plotly"],
icons=["list-task"],
menu_icon="cast", default_index=0, orientation="horizontal")
if selecte2 == "Plotly":
import plotly.graph_objs as go
c1, c2, c3, c4, c5 = st.columns([0.05, 1.5, 0.2, 1.5, 0.2])
with c1:
st.empty()
with c2:
# 柱状图
trace_basic = [go.Bar(
。。略单词翻译
结合Streamlit,可以花几分钟时间打造出我们自己的中英单词互翻工具。原理如下:
使用requests.get构造一个请求,把我们要查询的内容发送到指定的网址
然后使用json.loads功能把返回的对象转换为json对象
最后从json格式数据中提取出我们自己需要的key和paraphrase对象值
elif choose == "翻译":
selecte3 = option_menu(None, ["单词翻译"],
icons=['house'],
menu_icon="cast", default_index=0, orientation="horizontal")
if selecte3 == "单词翻译":
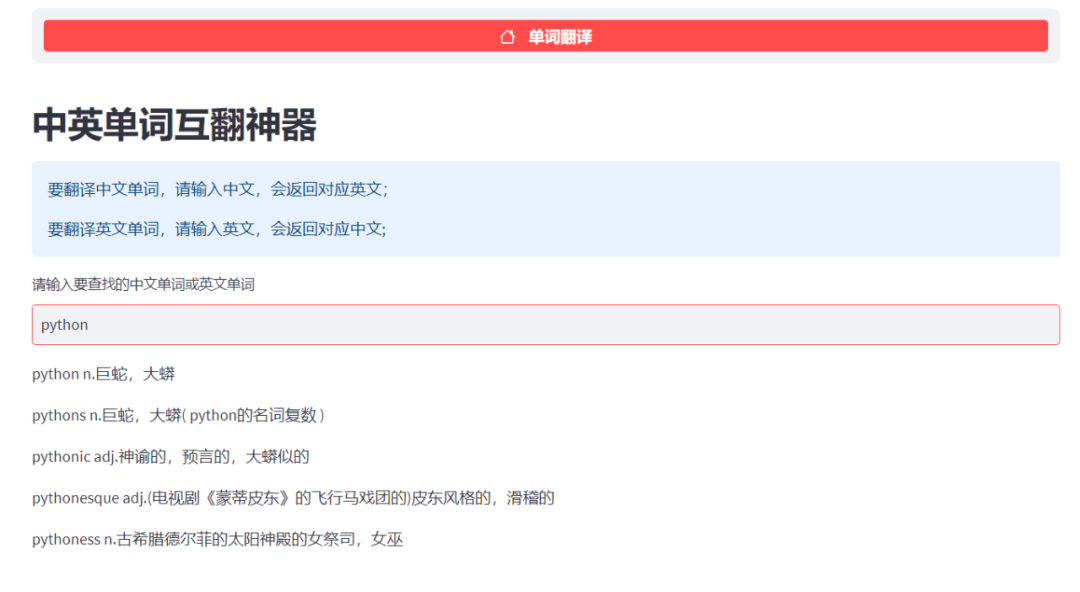
st.header("中英单词互翻神器")
st.info("要翻译中文单词,请输入中文,会返回对应英文;\n\n\n\n要翻译英文单词,请输入英文,会返回对应中文;")
danci = st.text_input("请输入要查找的中文单词或英文单词")
fanhui = requests.get("http://dict.iciba.com/dictionary/word/suggestion?word=" + danci)
data1 = fanhui.text
data2 = json.loads(data1)
for i in range(len(data2["message"])):
st.write(data2["message"][i]["key"], data2["message"][i]["paraphrase"])
# 隐藏按钮及底部链接
sysmenu = '''
<style>
#MainMenu {visibility:hidden;}
footer {visibility:hidden;}
'''
st.markdown(sysmenu, unsafe_allow_html=True)结合Javascript
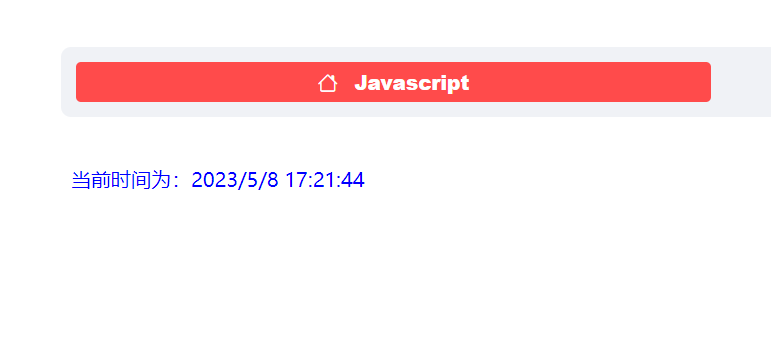
此案例使用streamlit.components.v1组件直接调用我们写好的javascript代码:
elif choose == "其他应用":
selecte5 = option_menu(None, ["Javascript", "嵌入PDF"],
icons=['house', "list-task"],
menu_icon="cast", default_index=0, orientation="horizontal")
if selecte5 == "Javascript":
from streamlit.components.v1 import html
html("""
<script>
function startTime(){
var today=new Date();
var current_time=today.toLocaleString();
document.getElementById('txt').innerHTML="当前时间为:"+current_time;
t=setTimeout(function(){startTime()},500);
}
function checkTime(i){
if (i<10){
i="0" + i;
}
return i;
}
</script>
</head>
<body onload="startTime()">
<p id="txt" style="color:blue"></p>
""")浏览PDF
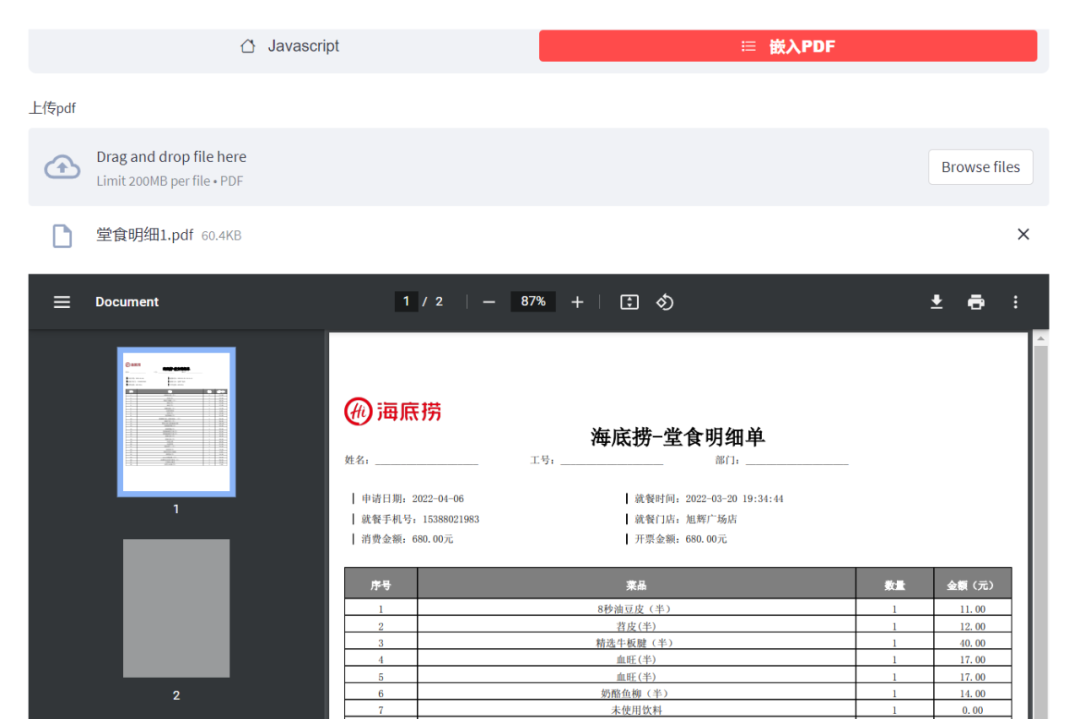
嵌入PDF文档的原理是,使用base64模块对PDF文档进行了编解码操作,然后使用html中的embed方法,把编解码后的信息进行显示
elif selecte5 == "嵌入PDF":
import base64
uploaded_file = st.file_uploader("上传pdf", type=["pdf"])
if uploaded_file is not None:
base64_pdf = base64.b64encode(uploaded_file.read()).decode('utf-8')
pdf_display = f'<embed src="data:application/pdf;base64,{base64_pdf}" width="100%" height="1000" type="application/pdf">'
st.markdown(pdf_display, unsafe_allow_html=True)交流群
时隔2个月,摸鱼学习交流群再次限时开放了。
Python技术交流群(技术交流、摸鱼、白嫖课程为主)又不定时开放了,感兴趣的朋友,可以在下方公号内回复:666,即可进入,一起 100 天计划!
老规矩,酱友们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!

【神秘礼包获取方式】
识别下方公众号,回复:1024















 3326
3326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









