






# 文本预处理

d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine():
"""将时间机器数据集加载到文本行的列表中"""
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines] # 对每行文本进行处理,将非字母字符替换为空格、去除首尾空格,并将文本转换为小写。
lines = read_time_machine()
print(f'# 文本总行数: {len(lines)}')
print(lines[0])
print(lines[10])def tokenize(lines, token='word'): # lines是上述代码中的一个存储文本数据的一个列表
"""将文本行拆分为单词或字符词元"""
if token == 'word':
return [line.split() for line in lines] # 如果 token 为 'word',则使用 line.split() 对每行文本进行按空格拆分,将结果存储为一个单词列表。
elif token == 'char':
return [list(line) for line in lines] # 如果 token 为 'char',则将每行文本转换为字符列表,其中每个字符都是一个词元。
else:
print('错误:未知词元类型:' + token)
tokens = tokenize(lines)
for i in range(11):
print(tokens[i]) 输出结果 计算机比较擅长计算,所以我们将词条转换为数字
计算机比较擅长计算,所以我们将词条转换为数字
class Vocab:
"""文本词表"""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None): # tokens:包含文本词元的列表。min_freq:最小出现频率,低于此频率的词元将被忽略。reserved_tokens:保留的特殊词元列表(如<pad>填充词元、<bos>序列开始词元、<eos>序列结束词元等)。
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# 按出现频率排序
counter = count_corpus(tokens) # 统计文本词元(tokens)的频率
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True) # counter.items()将counter字典中的键-值对转换为一个列表,其中每个元素是一个元组,元组的第一个元素是词元(键),第二个元素是该词元出现的频率(值)。key=lambda x: x[1]是一个排序关键字函数,它告诉sorted函数按照每个元组的第二个元素(即频率)进行排序。reverse=True参数表示按降序排序,即频率最高的词元排在前面。
# 未知词元的索引为0
self.idx_to_token = ['<unk>'] + reserved_tokens # self.idx_to_token,这是一个包含词表中所有词元的列表,包括已知的词元和未知的词元
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)} # 创建了一个字典 token_to_idx,它将词表中的每个词元映射到其整数索引。
for token, freq in self._token_freqs:
if freq < min_freq:
break # ,检查每个词元的出现频率 freq 是否大于或等于 min_freq。如果 freq 不满足这个条件,就终止循环(因为列表已经按频率降序排列,后面的词元频率肯定更小)
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1 # len(self.idx_to_token) 表示当前词表中已经包含的词元数量(不包括新添加的 token),通过减去1,可以得到新词元 token 的整数索引。这样,新词元就被添加到了词表的末尾,并分配了相应的索引。
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens): # 如果输入是单个词元(字符串),它返回该词元在词表中的整数索引,如果词元不在词表中,它返回 self.unk,即未知词元的整数索引(通常是0)。如果输入是词元的列表或元组,__getitem__ 方法将使用递归方式处理每个词元,最终返回整数索引的列表。
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices): # 如果 indices 是单个整数,它返回该整数索引对应的词元。如果 indices 是整数索引的列表或元组,它将使用列表推导来生成对应的词元列表,然后返回这个词元列表。
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # 未知词元的索引为0
return 0
@property
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens): # 它接受一个名为 tokens 的输入,这个输入可以是一个一维列表(1D),也可以是一个二维列表(2D)。
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 将词元列表展平成一个列表
tokens = [token for line in tokens for token in line] # 如果 tokens 是一个二维列表,函数会将它展平成一个一维列表。
return collections.Counter(tokens) # 使用 collections.Counter 来计算每个词元的出现频率,并返回一个字典,其中词元是键,它们的出现次数是对应的值。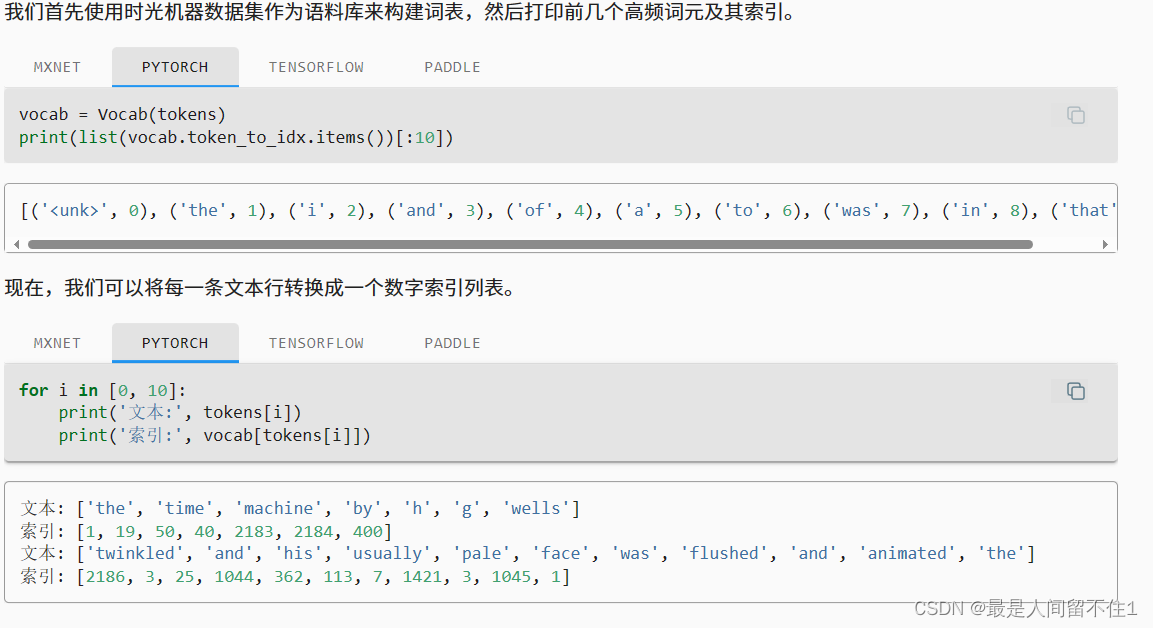
def load_corpus_time_machine(max_tokens=-1): #@save
"""返回时光机器数据集的词元索引列表和词表"""
lines = read_time_machine() # 从时光机器数据集中读取文本行。
tokens = tokenize(lines, 'char') # 使用 tokenize 函数将文本行拆分为字符词元。
vocab = Vocab(tokens) # 创建一个 Vocab 对象 vocab,它用于构建词表。
# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,
# 所以将所有文本行展平到一个列表中
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens] # 如果指定了 max_tokens 参数,并且大于0,那么截断 corpus 列表,只保留前 max_tokens 个词元。
return corpus, vocab
corpus, vocab = load_corpus_time_machine()
len(corpus), len(vocab)# 语言模型


import random
import torch
from d2l import torch as d2l
tokens = d2l.tokenize(d2l.read_time_machine()) # 首先使用d2l.read_time_machine()读取时光机器数据集,然后使用d2l.tokenize()将文本行拆分为词元(在这种情况下是单词)。
corpus = [token for line in tokens for token in line] # 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
vocab = d2l.Vocab(corpus) # 使用d2l.Vocab(corpus)创建了一个词表(vocab),该词表包含了数据集中所有词元的频率信息。
vocab.token_freqs[:10] # 这些词元按照出现频率从高到低排列。 
词频以明显的方式迅速衰减。

看看二元组的效果。
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])] # 这一行代码使用列表推导式创建bigram词元对,zip(corpus[:-1], corpus[1:])将相邻的两个词元配对,存储在 bigram_tokens 列表中。
bigram_vocab = d2l.Vocab(bigram_tokens) # 使用 bigram_tokens 创建了一个新的词表 bigram_vocab,这个词表包含了所有的bigram词元对。
bigram_vocab.token_freqs[:10] # 打印了 bigram_vocab 中最常见的bigram词元对,以便查看它们的频率。这些bigram词元对可以帮助分析文本中的词元之间的相关性和共现情况。
看看三元组的效果。
trigram_tokens = [triple for triple in zip(
corpus[:-2], corpus[1:-1], corpus[2:])] # )将连续出现的三个词元配对,存储在 trigram_tokens 列表中。
trigram_vocab = d2l.Vocab(trigram_tokens) # 使用 trigram_tokens 创建了一个新的词表 trigram_vocab,这个词表包含了所有的trigram词元对。
trigram_vocab.token_freqs[:10] # 查看它们的频率。
随机采样
def seq_data_iter_random(corpus, batch_size, num_steps): # corpus:数据集,一个包含词元的列表。batch_size:每个小批量中的子序列数。num_steps:每个子序列的时间步数(序列长度)。
# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):] # 从一个随机的偏移量开始对数据集 corpus 进行分区,并设置随机范围为 [0, num_steps-1]。这确保了每个小批量的子序列的起始位置是随机的,以增加样本的多样性。
num_subseqs = (len(corpus) - 1) // num_steps # num_subseqs 表示在分区后数据集中包含的非重叠子序列的数量。减去1,是因为我们需要考虑标签
initial_indices = list(range(0, num_subseqs * num_steps, num_steps)) # 用于存储子序列的随机起始索引。长度为num_steps的子序列的起始索引
# 在随机抽样的迭代过程中,
# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
random.shuffle(initial_indices) # 。在该函数调用之后,initial_indices 中的元素将被随机排列,从而打破了原始的顺序。
def data(pos):
# 返回从pos位置开始的长度为num_steps的序列
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size # 计算了在给定的 num_subseqs(总子序列数)和 batch_size(批量大小)下,有多少个小批量数据可以生成。它通过整数除法 // 来计算,确保结果是一个整数。
for i in range(0, batch_size * num_batches, batch_size): # 通过这个循环,数据迭代器将生成多个小批量,每个小批量都包含 batch_size 个子序列对 (X, Y),供模型训练使用。
# 在这里,initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y) 吧














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









