







一、项目背景
随着信息技术的迅猛发展,建筑行业对于数字化、智能化的需求日益增强。电子签章作为数字化转型的关键环节,能够显著提升业务流程的效率和安全性。本文旨在探讨RPA(机器人流程自动化)在建筑行业电子签章解决方案中的应用,包括电子签章自动化流程、实名认证与授权管理、签章安全与加密技术、高效文件处理与传输、签章过程监控与追溯、跨平台与系统集成性、用户体验与操作便捷性,以及法律法规遵循与合规性等方面。
二、需求分析
- 电子签章自动化流程
通过RPA技术的应用,建筑行业的电子签章流程实现了自动化。RPA机器人能够模拟人工操作,自动完成文件的上传、签章申请、签章执行、签章验证等一系列流程。这不仅大大提高了工作效率,还减少了人为错误和干预,确保签章流程的准确性和可靠性。
- 高效文件处理与传输
建筑行业涉及大量的文件和文档处理。RPA技术能够自动完成文件的识别、分类、提取和处理等操作,提高文件处理的效率和准确性。同时,通过电子签章系统,我们还可以实现文件的快速传输和共享,打破地域和时间的限制,提高协作效率。
- 签章过程监控与追溯
电子签章系统具备签章过程监控和追溯功能。通过RPA技术,我们可以实时记录签章过程中的关键信息和操作日志,包括签章时间、签章人、签章内容等。这使得签章过程可追溯、可审计,有助于解决争议和纠纷,并为管理决策提供有力支持。
- 跨平台与系统集成性
建筑行业使用的软件和系统种类繁多,因此电子签章解决方案需要具备良好的跨平台性和系统集成性。RPA技术能够适应不同平台和系统的特点,实现与其他系统的无缝对接和集成。这有助于打通数据壁垒,实现信息的共享和协同工作,提高整体业务效率。
- 用户体验与操作便捷性
用户体验和操作便捷性对于电子签章解决方案的成功至关重要。RPA技术通过优化流程设计、简化操作步骤、提供友好的用户界面等方式,提升用户的使用体验。同时,我们还可以提供详细的操作指南和技术支持,帮助用户快速掌握和使用电子签章系统。
- 法律法规遵循与合规性
在建筑行业中应用电子签章需要遵循相关法律法规和行业标准。RPA技术可以确保电子签章过程符合相关法律法规的要求,如电子签名法、电子合同法等。同时,我们还可以根据客户的实际需求,提供合规性咨询和解决方案,确保电子签章在建筑行业的合规应用。
综上所述,RPA在建筑行业电子签章解决方案中发挥了重要作用。通过自动化流程、高效文件处理与传输、过程监控与追溯、跨平台与系统集成性、用户体验与操作便捷性以及法律法规遵循与合规性等方面的综合应用,我们为建筑行业提供了安全、高效、合规的电子签章解决方案,推动了行业的数字化转型和发展。
三、项目技术方案
3.1、总体设计原则
本项目将采用成熟的、先进的、开放的及符合国际标准的系统结构、计算机技术和网络安全技术,并遵守甲方的信息化规范要求来建设,以保证系统具有先进水平;同时项目遵从领先性、高性能、实用性、经济性、一致性、可扩展性等原则进行建设。
本项目不仅满足当前业务场景需求,并适应后续RPA业务场景的持续发展,也考虑到未来的技术发展方向。
本项目规划是一个RPA系统平台,系统的软件建设应首先是符合标准的,符合技术发展方向的,开放并易于集成的。其次,系统须具有良好的平台无关性,可应用到各类系统中。各业务之间有着相当密切的关系,因此在开发过程中必须遵循“总体分析与设计”的要求,遵循总体设计原则,以确保系统的整体性。
四、项目设计思路
4.1、设计思路
项目的涉及思路主要是通过模块化的设计进行实现,可以大致分为:配置模块、识别模块、登录模块、数据处理模块等模块来实现整个项目的自动化流程。配置模块包含对数据源的路径、OCR的参数配置;识别模块包含对数据源的字段提取、数据存储;登录模块包含自动登录操作系统、自动切换操作系统;数据处理模块包含文件的上传下发、数据信息录入、事件点击等。
相关实现步骤截图如下:
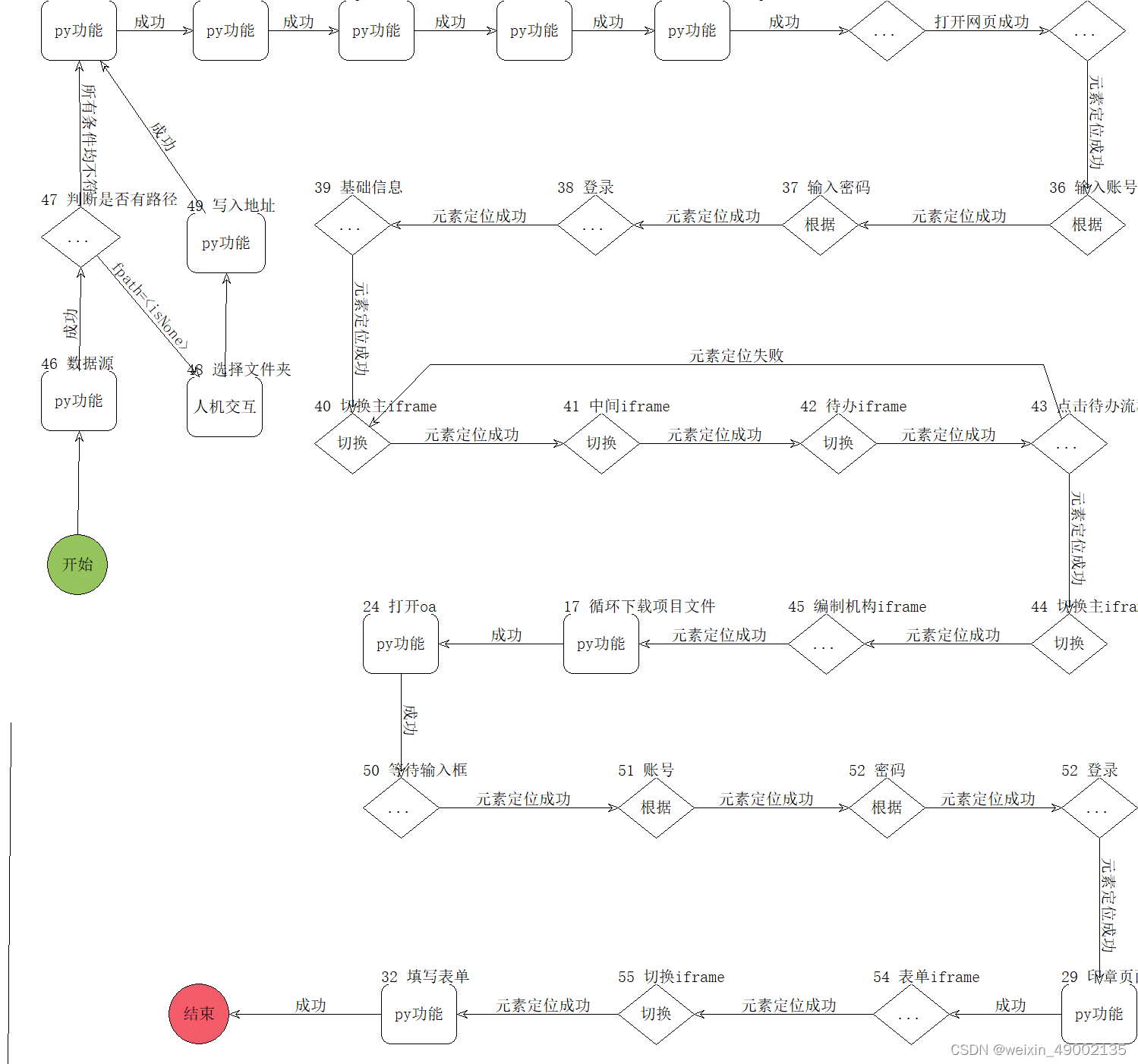
图3.1-1自动化的流程图
代码展示:
配置OCR:
from aip import AipOcr
def get_file_content(img_path):
with open(img_path, "rb") as fp:
return fp.read()
class Ocr_baidu_img:
def __init__(self):
self.options = None
self.APP_ID = '******'
self.API_KEY = '********'
self.SECRET_KEY = '*********************'
self.client = AipOcr(self.APP_ID, self.API_KEY, self.SECRET_KEY)
def set_options(self, options=''):
if not options:
self.options = {"language_type": "CHN_ENG", "paragraph": "true"}
else:
self.options = options
def go(self, img):
return self.client.basicGeneral(img, self.options)PDF处理:
import shutil
from pdf2image import convert_from_path
import os
import re
def extract_text_from_scan(pdf_file_path, Ocr_img, img_socth):
# 使用 pdf2image 将 PDF 页面转换为图像
images = convert_from_path(pdf_file_path)
# 提取类型
type_list = set()
title_list = set()
data_dic = {}
# 遍历每个图像并使用 Tesseract OCR 提取文本
for i, img in enumerate(images):
# 将图像保存为临时文件
imges_path = f"{img_socth}\\page_{i}.png"
img.save(imges_path, "PNG")
img_base = get_file_content(imges_path)
# 使用 OCR 识别图像中的文本
text_list = Ocr_img.go(img_base)['words_result']
text = '\n'.join([w['words'] for w in text_list])
# print(text)
# print('-------------------------------------------')
# 使用正则表达式提取标题
pattern_title = r"\n\s*(.*?)方案\s*"
title_match = re.search(pattern_title, text, re.DOTALL)
if title_match:
#title = title_match.group(1).replace("(", "(").replace(")", ")").strip().replace('\n', '') + '方案'
title = title_match.group(1).strip().replace('\n', '') + '方案'
print('文书标题--->', title.replace('\n', ''))
title_list.add(title)
else:
title = ''
print('未提取到标题')
print('-------------------------------------------')
#print(text)
# 使用正则表达式提取类型
pattern = r"工程名称:\s*(.*?)\s工程地点"
print("+++"*100)
print(text)
type_match = re.search(pattern, text, re.DOTALL)
if type_match.group(1):
#class_name = type_match.group(1).replace("O", "0").replace("(", "(").replace(")", ")").replace("\n", '').strip()
class_name = type_match.group(1).replace("O", "0").replace("\n", '').strip()
print('11111111111', class_name)
type_list.add(class_name)
temp_path = img_socth + '\\' + class_name
if not os.path.exists(temp_path):
os.makedirs(temp_path)
shutil.move(imges_path, temp_path + '\\' + os.path.basename(imges_path))
print(f"已将 {imges_path} 移动到 {temp_path}")
else:
class_name = ''
print(f"未找到类型:{imges_path}")
print("-" * 50)
print(text)
if class_name in data_dic:
if title not in data_dic[class_name]:
data_dic[class_name].append(title)
else:
data_dic[class_name] = [title]
# 打印识别到的文本
print(f"Page {i + 1}:")
print("\n")
# 删除临时文件
#os.remove(img_path)
type_list = list(type_list)
title_list = list(title_list)
print('单位列表--->', type_list)
print('标题列表--->', title_list)
return data_dic
ocr = Ocr_baidu_img()
# 指定 PDF 文件路径
#scan_pdf_file_path = r'D:\pythonProject\reptile_project\数据处理\pdf文件拆分\2.pdf'
# images_path = r'D:\pythonProject\reptile_project\数据处理\pdf文件拆分\DataPath'
# 调用函数读取 PDF 内容
data_dict = {}
for f in file_list:
print(f)
temp_dict = extract_text_from_scan(f, ocr, pro_path)
data_dict.update(temp_dict)数据处理:
import sm_pywebpageoperate
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import os, shutil
import zipfile
from itertools import groupby
from openpyxl import load_workbook
def get_max_v(lst):
# 筛选版本号
# 过滤lst中不带'V'的元素
filtered_lst = [x for x in lst if 'V' in x]
# 对带'V'的元素进行分组,元素中'V'前面字符串一致的为一组
grouped_lst = {k: list(g) for k, g in groupby(sorted(filtered_lst), key=lambda x: x.split('V')[0])}
# 分别提取出各组中'V'后面值最大的元素
result = []
for group in grouped_lst.values():
max_value = max(int(x.split('V')[1]) for x in group)
result.append([x for x in group if int(x.split('V')[1]) == max_value][0])
return result
def get_classname(file_path, flag='单位') -> dict:
orange_df1 = pd.read_excel(file_path, header=0)
df = orange_df1.fillna('') # 对NAN进行填
df[f'ocr识别到的{flag}'] = df[f'ocr识别到的{flag}'].apply(lambda x: x.replace('\n', ''))
df[f'实际{flag}'] = df[f'实际{flag}'].apply(lambda x: x.replace('\n', ''))
name_dict = df.set_index(f'ocr识别到的{flag}')[f'实际{flag}'].to_dict()
return name_dict
def extract_all_zips(folder_path):
"""
遍历指定文件夹中的所有zip文件,并将它们解压到当前文件夹下。
参数:
folder_path (str): 要遍历的文件夹路径。
"""
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
# 检查文件是否是zip压缩包
if filename.endswith(".zip"):
# 构建zip文件的完整路径
zip_file_path = os.path.join(folder_path, filename)
# 创建一个与zip文件同名的文件夹,并在当前文件夹下解压zip文件
with zipfile.ZipFile(zip_file_path, "r") as zip_obj:
for member in zip_obj.infolist():
member.filename = member.filename.encode('cp437').decode('gbk')
zip_obj.extract(member, folder_path)
print(f"已解压文件: {filename} 到 {folder_path}")
#os.remove(zip_file_path)
def is_down_over(download_dir, start_max_wait_time=200*3, end_max_wait_time=60*5 ,suffix='.crdownload', start_step=0.005, end_step=1):
# 开始下载
wait_time = 0
while True:
files = os.listdir(download_dir)
print(files)
if any(filename.endswith(suffix) for filename in files):
print("下载开始")
break
if wait_time >= start_max_wait_time:
print("下载出错")
return 0
time.sleep(start_step)
wait_time += 1
# 判断文件是否下载完成
wait_time = 0
while True:
files = os.listdir(download_dir)
if not any(filename.endswith(suffix) for filename in files):
print("下载完成")
return 1
if wait_time >= end_max_wait_time:
print("下载超时")
return 0
# 每隔一秒检查一次下载目录
time.sleep(end_step)
wait_time += 1
def clear_folder_contents(folder_path):
# 遍历文件夹中的所有文件和子文件夹
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
# 如果是文件,直接删除
if os.path.isfile(file_path):
os.remove(file_path)
# 如果是文件夹,递归删除
elif os.path.isdir(file_path):
shutil.rmtree(file_path)
def move_file(f_dir, m_path):
"""
移动文件
f_dir:源文件夹
m_path: 目标文件夹
"""
# 如果文件夹不存在,则创建它
print(f_dir)
print(m_path)
if not os.path.exists(m_path):
os.makedirs(m_path)
for file_ in os.listdir(f_dir):
shutil.move(os.path.join(f_dir, file_), os.path.join(m_path, file_))
if file_.endswith('.pdf'):
os.rename(os.path.join(m_path, file_), os.path.join(m_path, '处理记录.pdf'))
# dw_list = ['哥弟家元B区']
# title_list = ['[测试][哥弟家元B区施工总承包][JSFA-202404-7397][危大工']
#data_dict = {"白云机场三期扩建工程周边临空经济产业园区基础设施二期工程(平西二期安置区)施工总承包(标段二)": ['测试'], '哥弟家元B区': ['[测试][哥弟家元B区施工总承包][JSFA-202404-7397][危大工']}
s1= sm_pywebpageoperate.webpageoprate.driver
s1.implicitly_wait(5)
name_dict = get_classname(classname_path)
title_dict = get_classname(titlename_path, flag='标题')
for dw, title_list in data_dict.items():
# 切换主iframe
s1.switch_to.default_content()
# 切换机构iframe
iframe_ = s1.find_element_by_xpath("//div[@class='iframe_main show']/iframe")
s1.switch_to.frame(iframe_)
# 读取映射表
dw = name_dict[dw] if dw in name_dict else dw
# 点击机构
s1.find_element(By.XPATH, "//input[@style='width: 401.75px;']/following-sibling::img[1]").click()
time.sleep(0.5)
# 定位到 input 元素
input_element = s1.find_element(By.XPATH, "//input[@id='ID_GTP_Workflow_OrgTree_Mon_edQuery']")
# 清除输入框中的内容
input_element.clear()
# 往输入框中写入值
input_element.send_keys(dw)
# 显式等待直到元素可见
#//div[@class='x-grid-empty' and text()='没有数据']
try:
WebDriverWait(s1, 5).until(EC.visibility_of_element_located((By.XPATH, f"//span[contains(text(), '{dw}')]/../../preceding-sibling::td[1]//div[@class='x-grid3-row-checker']")))
except Exception as e:
wb = load_workbook(classname_path)
ws = wb["Sheet1"]
ws.append([dw,])
wb.save(classname_path)
wb.close()
continue
# 打勾
s1.find_element(By.XPATH, f"//span[contains(text(), '{dw}')]/../../preceding-sibling::td[1]//div[@class='x-grid3-row-checker']").click()
# 点击确定进行搜索
s1.find_element(By.XPATH, "//button[text()='确定']").click()
time.sleep(0.5)
# 输入主题
for title in title_list:
# 替换标题--->标题映射表
title = title_dict[title] if title in title_dict else title
sx_element = s1.find_element(By.XPATH, "//input[@id='ID_GTP_Workflow_EditFilter']")
# 清除输入框中的内容
sx_element.clear()
# 输入内容
sx_element.send_keys(title)
#sx_element.send_keys('123')
time.sleep(0.5)
# 模拟按下回车键
sx_element.send_keys(Keys.RETURN)
# 等待搜索结果
try:
WebDriverWait(s1, 5).until(EC.visibility_of_element_located((By.XPATH, f"//a[@class='g-link' and contains(text(), '{title}')]")))
except Exception as e:
print('未找到数据')
WebDriverWait(s1, 5).until(EC.visibility_of_element_located((By.XPATH, "//div[@class='x-grid-empty' and text()='没有数据']")))
wb = load_workbook(titlename_path)
ws = wb["Sheet1"]
ws.append([title,])
wb.save(titlename_path)
wb.close()
continue
# 下载处理记录
# 清空临时文件夹
clear_folder_contents(download_)
s1.find_element(By.XPATH, "//button[text()='处理记录']").click()
time.sleep(2)
sm_pywebpageoperate.webpageoprate.WebPageSwitchOperWinrun(1)
# 切换回主iframe
s1.switch_to.default_content()
s1.find_element(By.XPATH, "//button[text()='打印处理记录']").click()
time.sleep(2)
sm_pywebpageoperate.webpageoprate.WebPageSwitchOperWinrun(2)
# 切换回主iframe
s1.switch_to.default_content()
# iframe0
iframe0 = s1.find_element_by_xpath("//iframe[@id='frmWorkflowFlowStepFrame']")
s1.switch_to.frame(iframe0)
# 导出文件
s1.find_element(By.XPATH, "//span[@title='导出pdf']").click()
# 等待下载pdf完成
is_down_over(download_, 200*2, suffix='.tmp', start_step=0.005)
s1.close()
time.sleep(1)
sm_pywebpageoperate.webpageoprate.WebPageSwitchOperWinrun(1)
time.sleep(2)
s1.execute_script("window.close();")
sm_pywebpageoperate.webpageoprate.WebPageSwitchOperWinrun(0)
time.sleep(1)
# 切换回主iframe
s1.switch_to.default_content()
# iframe1
iframe1 = s1.find_element_by_xpath("//div[@class='iframe_main show']/iframe")
s1.switch_to.frame(iframe1)
# 点击进入项目
s1.find_elements(By.XPATH, "//a[@class='g-link' and contains(text(), '测试')]")[0].click()
time.sleep(5)
# 切换回主iframe
s1.switch_to.default_content()
time.sleep(1)
# iframe1
iframe1 = s1.find_element_by_xpath("//div[@class='iframe_main show']/iframe")
s1.switch_to.frame(iframe1)
time.sleep(1)
# iframe2
iframe2 = s1.find_element_by_xpath("//form//iframe[@src]")
s1.switch_to.frame(iframe2)
# 点击附件信息
s1.find_element(By.XPATH, "//span[text()='附件信息']").click()
# 全部打勾
#s1.find_element(By.XPATH, "//div[@class='x-grid3-hd-inner x-grid3-hd-checker']/div[@class='x-grid3-hd-checker']").click()
a_list = s1.find_elements_by_xpath('//div[@class="x-grid3-cell-inner x-grid3-col-col_DisplayName x-unselectable"]//a')
a_text_list = [ele.text for ele in a_list]
print('需要下载的文件', a_text_list)
downlist = get_max_v(a_text_list)
for t in downlist:
s1.find_element_by_xpath(f"//a[text()='{t}']/../../preceding-sibling::td//div[@class='x-grid3-row-checker']").click()
#break
# 点击下载
s1.find_element(By.XPATH, "//button[text()='下载']").click()
# 等待zip下载完成
flag = is_down_over(download_, start_max_wait_time=2000*5, suffix='.crdownload', start_step=0.005)
if flag:
move_file(download_, os.path.join(pro_path, dw))
extract_all_zips(os.path.join(pro_path, dw))
# 切换回主iframe
s1.switch_to.default_content()
# 关闭详情页
s1.find_elements(By.XPATH, "//input[@title='关闭']")[-1].click()
print('ok')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











