







RPA(Robotic Process Automation,机器人流程自动化)在财务领域的对账流程可以显著提高效率和准确性。以下是一个典型的RPA财务对账流程:
- 自动获取数据:RPA财务机器人能够自动登录到各种财务系统、银行系统或其他相关数据源,获取需要进行对账的数据。这些数据可能包括银行账户信息、交易记录、发票、账单等。
- 数据预处理:RPA财务机器人会按照预设的规则,对获取的数据进行清洗、整理、分类和格式化,以便进行后续的对账操作。
- 自动对账:RPA财务机器人会根据预设的对账规则,自动进行银行对账单和企业内部账簿的核对。这可能包括初始核对(比较银行对账单上的期末余额与企业内部账簿上的银行存款余额是否一致)、明细核对(逐条对照银行对账单和企业内部账簿,检查每一笔交易是否准确无误)等步骤。
- 异常处理:在对账过程中,如果RPA财务机器人发现任何异常或不一致的情况,如未达账项、重复记录、遗漏记录等,它会将这些异常情况进行标注,并生成相应的报告或通知,以便财务人员进行进一步的处理。
- 差异分析:如果存在对账差异,RPA财务机器人可以协助财务人员进行分析,找出差异产生的原因,如记账错误、银行处理滞后等,并准备相应的调整分录。
- 往来款项确认:RPA财务机器人还可以协助财务人员对企业的应收账款和应付账款进行核实,与客户的往来对账单进行核对,确保双方账目的相符性。
- 生成报告:根据对账结果,RPA财务机器人可以自动生成详细的对账报告,包括对账时间、对账对象、对账内容、存在的差异、处理结果等。这些报告可以供财务人员进行审核和确认。
下面分享一下在项目中的代码:
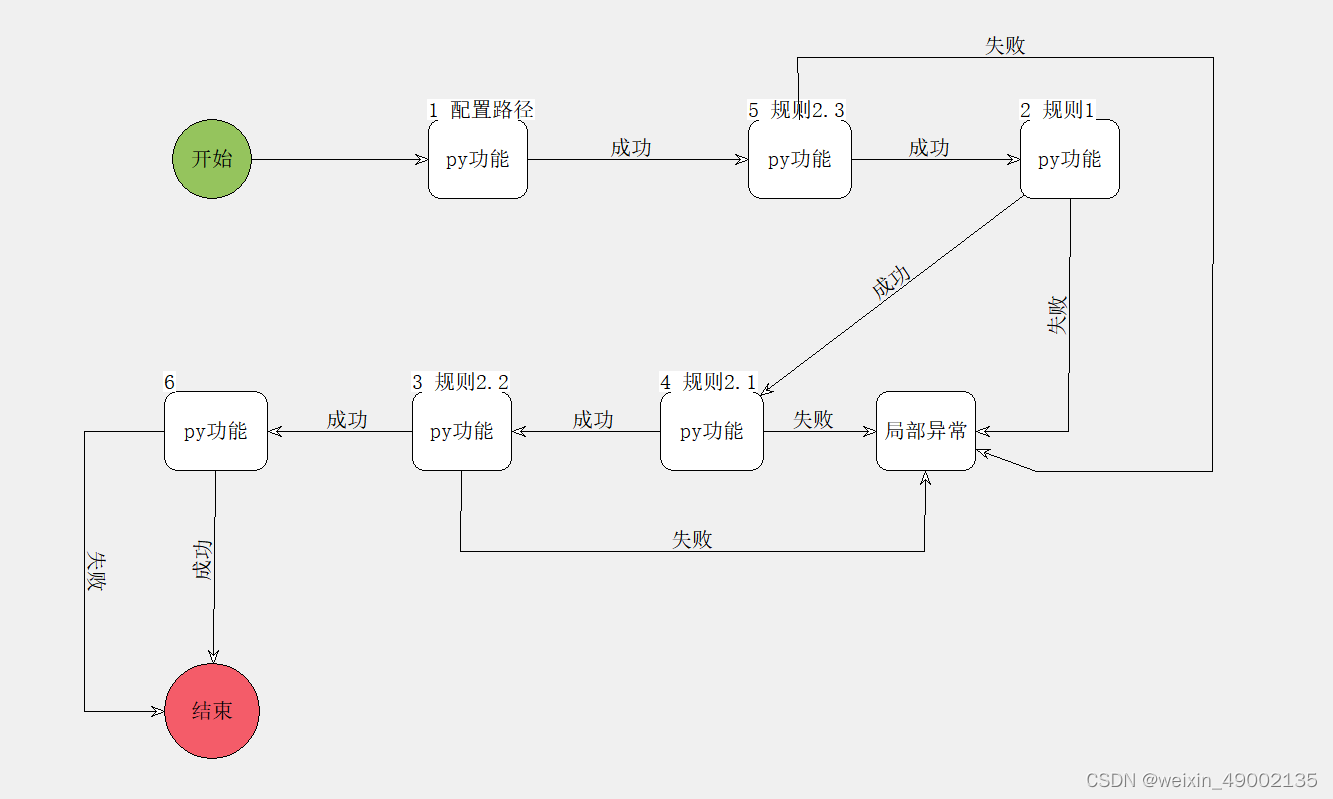
图1 项目流程图
其中规则2.3代码如下,其功能是在两张源表格数据中,两边以指定的关键字进行筛选,对筛选出来的数据进行一个金额的对比,如果金额不相等或者金额在总表中找不到,则将该数据存储到新的表格中。更多的就不分享了,都是类似的。
import pandas as pd
import re
from openpyxl import load_workbook,Workbook
def check_income_amounts(df_a, df_b, pattern_income, pattern_reproduction, output_path):
# 筛选行,确保'摘要'字段包含'门诊收入-农行现金'且不包含'生殖中心'
i = 0
filtered_df = df_a[(df_a['摘要'].str.contains(pattern_income, na=False)) &
(~df_a['摘要'].str.contains(pattern_reproduction, na=False))]
# 创建一个空的DataFrame来存储不匹配的行
mismatched_rows = pd.DataFrame(columns=df_a.columns)
for index, row in filtered_df.iterrows():
summary = row['摘要']
match = re.search(r'年(\d{2})月(\d{2})日', summary)
if match:
date_part = match.group(1) + match.group(2)
sum_borrow_amount = row['借方']
# 筛选表格b中符合条件的数据
filtered_df_b = df_b[(df_b['交易用途'].str.contains('门-' + date_part, na=False))]
sum_income_amount = filtered_df_b['收入金额'].sum() if not filtered_df_b.empty else 0
# 检查金额是否相等
if sum_borrow_amount != sum_income_amount:
# 将不匹配的行添加到mismatched_rows
mismatched_rows = mismatched_rows.append(row, ignore_index=True)
else:
print('No match found in summary:', summary)
# 如果mismatched_rows不为空,则将其写入到Excel文件
if not mismatched_rows.empty:
mismatched_rows.to_excel(output_path, index=False)
return mismatched_rows
def check_outcome_amounts(df_a, df_b, pattern_income, output_path):
# 筛选行,确保'摘要'字段包含'住院收入'
i = 0
filtered_df = df_a[(df_a['摘要'].str.contains(pattern_income, na=False))]
# 创建一个空的DataFrame来存储不匹配的行
mismatched_rows = pd.DataFrame(columns=df_a.columns)
for index, row in filtered_df.iterrows():
summary = row['摘要']
match = re.search(r'年(\d{2})月(\d{2})日', summary)
if match:
date_part = match.group(1) + match.group(2)
sum_borrow_amount = row['借方']
# 筛选表格b中符合条件的数据
filtered_df_b = df_b[(df_b['交易用途'].str.contains('住-' + date_part, na=False))]
sum_income_amount = filtered_df_b['收入金额'].sum() if not filtered_df_b.empty else 0
# 检查金额是否相等
if sum_borrow_amount != sum_income_amount:
# 将不匹配的行添加到mismatched_rows
mismatched_rows = mismatched_rows.append(row, ignore_index=True)
else:
print('No match found in summary:', summary)
# 如果mismatched_rows不为空,则将其写入到Excel文件
if not mismatched_rows.empty:
#mismatched_rows.to_excel(output_path, index=False)
# 创建一个新的工作簿用于写入
wb = load_workbook(output_path)
ws = wb.active
# 获取最后一行数据的行号
last_row = ws.max_row
# 将inequal_data DataFrame的数据写入工作表的当前行下方
for row in mismatched_rows.itertuples(index=False, name=None):
ws.append(row)
print("插入成功")
# 保存工作簿
wb.save(output_path)
return mismatched_rows
# 使用函数
output_path = newfile
file_a = filea
file_b = fileb
pattern_income = '门诊收入-农行现金'
pattern_reproduction = '生殖中心'
pattern_outcome = '住院收入'
df_a = pd.read_excel(file_a, engine='xlrd' if file_a.endswith('.xls') else 'openpyxl')
df_b = pd.read_excel(file_b, engine='xlrd' if file_b.endswith('.xls') else 'openpyxl')
mismatched_data = check_income_amounts(df_a, df_b, pattern_income, pattern_reproduction, output_path)
mismatched_data_ = check_outcome_amounts(df_a, df_b, pattern_outcome, output_path)

















 3085
3085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











