





目录
ConViT:利用软卷积归纳偏差改进视觉转换器
摘要
卷积架构已经被证明在视觉任务中非常成功。它们的硬归纳偏差能够实现高效的样本学习,但也可能导致性能上限较低。视觉转换器(ViTs)依赖于更灵活的自注意力层,并且最近在图像分类中超过了卷积神经网络(CNNs)。然而,它们需要在大型外部数据集上进行昂贵的预训练或者从已经训练好的卷积网络进行蒸馏。在本文中,我们提出了以下问题:是否可能在避免它们各自的限制的同时结合这两种架构的优势?为此,我们引入了门控位置自注意力(GPSA),这是一种带有“软”卷积归纳偏差的位置自注意力形式。我们将GPSA层初始化为模拟卷积层的局部性,然后通过调整控制对位置和内容信息关注的门控参数,使每个注意力头具有逃逸局部性的自由度。由此产生的类似卷积的ViT架构,即ConViT,在ImageNet上优于DeiT(Touvron等,2020),同时提供了更高的样本效率。我们进一步研究了学习中局部性的作用,首先量化了自注意力层中如何鼓励局部性,然后分析了GPSA层如何逃逸局部性。最后,我们提出了各种消融实验来更好地理解ConViT的成功。我们的代码和模型在https://github.com/facebookresearch/convit上公开发布。
1.引言
过去十年来深度学习的成功在很大程度上得益于具有强大的归纳偏差的模型,使得跨领域的训练变得高效(Mitchell,1980; Goodfellow et al.,2016)。卷积神经网络(CNNs)的使用(LeCun et al.,1998; 1989)自2012年AlexNet的成功以来,在计算机视觉领域已经变得无处不在(Krizhevsky 等,2017),这体现了这一趋势。归纳偏差是以两个强约束权重的形式硬编码到CNN的架构结构中:局部性和权重共享。通过鼓励平移等变性(在无池层情况下)和平移不变性(在池层情况下)(Scherer 等,2010; Schmidhuber,2015; Goodfellow等,2016),卷积的归纳偏差使模型更具样本效率和参数效率(Simoncelli&Olshausen,2001; Ruderman&Bialek,1994)。类似地,对于基于序列的任务,具有硬编码记忆单元的循环网络(LSTMs)显示出简化了学习长程依赖关系的能力,并在多种情况下优于普通循环神经网络(Gers 等,1999; Sundermeyer 等,2012; Greff 等,2017)。
然而,近年来纯粹基于注意力的模型的崛起对硬编码的归纳偏差的必要性提出了质疑。注意力最初作为递归神经网络用于序列到序列模型的附加组件被引入(Bahdanau等,2014),它通过自注意力(Self-Attention,SA)在自然语言处理中取得了突破,而Transformer模型正是依赖于这种特殊的注意力机制(Vaswani等,2017)。当这些模型在大型数据集上进行预训练后表现出的强大性能,迅速使得基于Transformer的方法成为优于像LSTMs一样的递归模型的默认选择(Devlin等,2018)。
在视觉任务中,CNN(卷积神经网络)的局部性损害了捕捉长距离依赖关系的能力,而注意力机制没有这个限制。Chen等人(2018)和Bello等人(2019)利用这种互补性,在卷积层中增加了注意力机制。最近,Ramaschandran等人(2019)进行了一系列实验,用注意力替换了ResNets中的一些或所有卷积层,并发现表现最好的模型在早期层使用卷积,而在后期层使用注意力。Vision Transformer(ViT),由Dosovitskiy等人(2020)引入,完全摒弃了卷积的归纳偏差,并通过对像素块嵌入进行自注意力操作。ViT能够达到或超过CNN的性能,但需要在大量数据上进行预训练。更近期的Data-efficient Vision Transformer(DeiT)(Touvron等,2020)能够在不对补充数据进行任何预训练的情况下达到类似的性能,而是依靠从卷积教师进行知识蒸馏(Hinton等,2015)来实现。
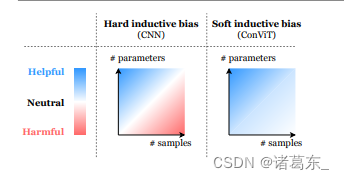
图1. 软归纳偏差可以帮助模型在不限制性能的情况下进行学习。硬归纳偏差,比如CNN的架构约束,可以极大地提高学习的样本效率,但当数据集的大小不是问题时,它们可能限制模型的表现。ConViT引入的软归纳偏差通过在不需要时消失来避免这种限制。
软引导偏置,ViT的最近成功表明,在小数据领域,卷积约束可以实现强大的样本效率训练,但是随着数据集大小不再是问题,卷积约束也会变得限制性。在数据丰富的领域中,硬性引导偏见可能过于严格,学习最合适的引导偏见可能更加有效。因此,从业者面临一个窘境,要在卷积模型(具有高性能底部和可能较低的性能天花板,因为有硬性引导偏差)与基于自我注意力的模型(具有较低的底部但较高的天花板)之间做出选择。这个窘境引出以下问题:是否能够同时获得卷积引导偏差的优点并避免其局限性(参见图1)?
在这个方向上,一个成功的方法是将两种架构组合成“混合”模型。这些模型交替或组合卷积层和自注意力层,并在各种任务上取得了成功结果(Carion等人,2020;胡等人,2018a;Ramachan dran等人,2019;陈等人,2020;Locatello等人,2020;孙等人,2019;Srinivas等人,2021;吴等人,2020)。另一种方法是知识蒸馏(Hinton等人,2015),最近被应用于将卷积教师的归纳偏置转移给学生Transformers(Touvron等人,2020)。虽然这两种方法提供了一个有趣的折衷方案,它们也会将卷积引导偏差强制应用于Transformers中,可能会影响Transformers并带来局限性。
在本文中,我们采取了一种新的方法,通过引入一种新的方法“柔性”地将卷积的归纳偏差引入ViT,以缩小CNN和Transformer之间的差距。这个想法是让每个自注意力层根据上下文决定是否表现为卷积层。我们的贡献如下:
1.我们提出了一种新型SA层,名为门控位置自注意力(Gated Positional Self-Attention,GPSA),可以初始化为卷积层。然后,每个注意力头都有自由调整门控参数来恢复表达能力的机会。
2.然后,我们基于DeiT(Touvron等,2020)进行了一系列实验,其中一定数量的SA层被GPSA层替换。结果形成的卷积视觉Transformer(ConViT)在性能上优于DeiT,并且具有更高的样本效率(图2)。
3.我们定量分析了香草ViTs中如何自然地促进局部注意力,然后研究了ConViT的内部运作,并进行了实验以探究其如何从卷积初始化中受益。
总体而言,我们的研究证明了“软”归纳偏差尤其在低数据情况下的有效性,因为在这种情况下学习模型高度欠指定(参见图1),并鼓励进一步探索诱导这些偏差的方法。
相关工作:我们的研究思路是将纯Transformer模型(Dosovitskiy等,2020)的最近成功与SA和卷积之间的形式化关系相结合。事实上,Cordonnier等人(2019)表明,如果每个头部都集中于卷积核块中的一个像素,则具有Nh个头部的SA层可以表示卷积层,其内核大小为√Nh。通过研究在CIFAR-10上训练的模型的注意图的定性方面,研究人员发现,具有相对位置编码的SA层自然地趋向于类似于卷积的配置,这表明一定程度的卷积归纳偏差是有益的。
相反,Elsayed等人(2020)已经证明了严格的局部约束的限制性。已经采取了大量方法将非局部性融入CNN架构中(Hu等,2018b;c;Wang等,2018;Wu等,2020)。另一方面,诱导卷积归纳偏差是不同架构的另一条研究线。例如,Neyshabur(2020)使用一种正则化方法,在整个训练过程中鼓励全连接网络(FCNs)从头开始学习卷积。
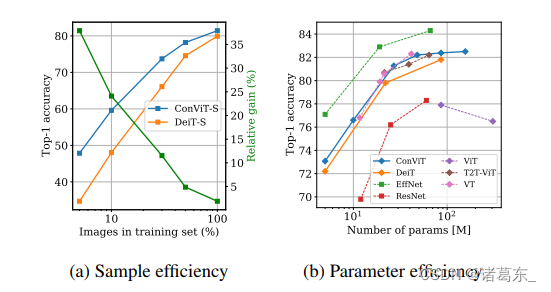
图2:ConViT在样本效率和参数效率方面均优于DeiT。左图:我们将ConViT-S(见表1)的样本效率与DeiT-S进行比较,通过在ImageNet-1k的受限部分上训练它们来进行比较,在这里我们只保留每个类别的一定比例的图像。两个模型都使用(Touvron等,2020)中报告的超参数进行训练。我们显示了ConViT相对于DeiT的相对改进,用绿色表示。右图:我们将我们的ConViT模型的top-1准确率与其他ViTs(用方块表示)和CNNs(用圆形表示)在ImageNet-1k上进行比较。其他模型在ImageNet上的表现取自(Touvron等,2020;He等,2016;Tan和Le,2019;Wu等,2020;Yuan等,2021)。
与我们的方法最相关的是,d’Ascoli等人(2019)探索了一种初始化FCN网络为CNN的方法。这使得结果FCN能够达到比标准初始化可实现的更高性能。此外,如果将FCN从部分训练的CNN初始化,则恢复的自由度允许FCN优于它来自的CNN。这种方法更普遍地与“热启动”方法相关,例如在尖峰张量模型中使用的方法(Anandkumar等,2016),其中使用包含问题先验信息的智能初始化来简化学习任务。
可重现性: 我们在以下地址提供我们方法的开源实现以及预训练模型:https://github.com/facebookresearch/convit。
2.背景
我们首先介绍SA层的基础知识,并展示了位置注意力如何使SA层能够表达卷积层。
多头自注意力机制基于一个可训练的关联记忆,其中包含(键,查询)向量对。通过内积,将长度为L1的“查询”嵌入序列Q ∈ RL1×Dh 与长度为L2的“键”嵌入序列K ∈ RL2×Dh 进行匹配。结果是一个注意力矩阵,其条目(ij)量化了Qi对于Kj的语义上的“相关性”。
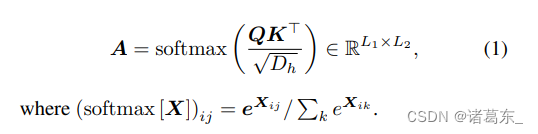
自注意力是注意力机制的一种特殊情况,在这种情况下,一个序列与自身进行匹配,以提取其部分之间的语义依赖关系。在ViT中,查询(queries)和键(keys)是由16×16像素补丁(X ∈ RL×Demb)的嵌入经过线性投影得到的。因此,我们有Q = WqryX和K = WkeyX,其中Wkey、Wqry ∈ RDemb×Dh。
多头自注意力层并行使用多个自注意头,允许学习不同类型的相互依赖关系。它们以L个嵌入(embedding)为输入,每个嵌入的维度为Demb = NhDh,并通过以下机制输出相同维度的L个嵌入:
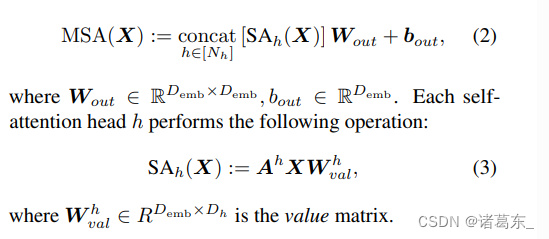
然而,在公式1的基础形式下,自注意力层是位置不可知的:它们不知道补丁是如何相对于彼此定位的。为了加入位置信息,有几种选项。一种是在嵌入时间将一些位置信息添加到输入中,然后通过SA层传播它:(Dosovitskiy等人,2020)在他们的ViT中使用了这种方法。另一个可能性是用相对位置编码rij(Ramachandran等人,2019)替换基本形式的自注意力层,使用位置自注意力(PSA):
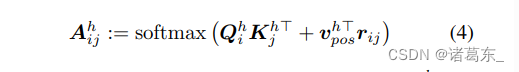
每个注意力头使用可训练的嵌入
v
p
o
s
h
v_{pos}^h
vposh ∈ RDpos,并且相对位置编码rij ∈ RDpos仅取决于像素i和j之间的距离,用二维向量δij表示。
Cordonnier等人在2019年的研究中展示了自注意机制作为一种广义卷积的能力。他们通过以下设置表明,具有Nh个头和可学习的相对位置编码(方程4,维度Dpos≥3)的多头自注意层可以表示任意过滤器尺寸为
N
h
\sqrt{Nh}
Nh ×
N
h
\sqrt{Nh}
Nh的卷积层:
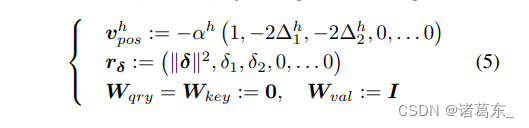
在上述文段中,
- 注意力中心∆h ∈ R2 是头部h相对于查询补丁最关注的位置。例如,在图3(c)中,从左到右的四个头部分别对应∆1 =(-1,1),∆2 =(-1,-1),∆3 =(1,1),∆4 =(1,-1)。
- 局部性强度αh > 0 确定了注意力围绕其中心∆h的集中程度(也可以理解为方程1中softmax的“温度”)。当αh较大时,注意力仅集中在∆h处的补丁上,如图3(d)所示;当αh较小时,注意力会扩散到一个更大的区域,如图3(c)所示。
这些句子描述了自注意机制中一些重要的概念。注意力中心表示头部在处理查询补丁时关注的位置相对于该补丁的偏移。局部性强度则决定了注意力的集中程度,即控制了注意力是否集中在中心位置附近或扩散到更大的区域。
这些信息对于理解自注意机制的工作原理以及头部在不同情况下的注意力分布是非常重要的。
因此,通过将注意力中心∆h设置为√Nh × √Nh卷积核的所有可能位置偏移量,并将局部性强度αh设定为较大的值,PSA层可以实现严格的卷积注意力图。
这句话的意思是,通过适当设置自注意层的注意力中心和局部性强度值,PSA层可以模拟卷积操作的注意力图。具体而言,可以通过将注意力中心∆h设置为卷积核的所有可能位置偏移,以及将局部性强度αh设置为较大的值,来产生严格满足卷积操作的注意力分布。
这一发现表明,PSA层可以通过调整注意力中心和局部性强度参数,以实现与卷积层类似的注意力分布,进而使得自注意机制能够表达卷积操作的特性。这为我们在使用自注意机制时,根据需要调整注意力的范围和分布提供了指导。
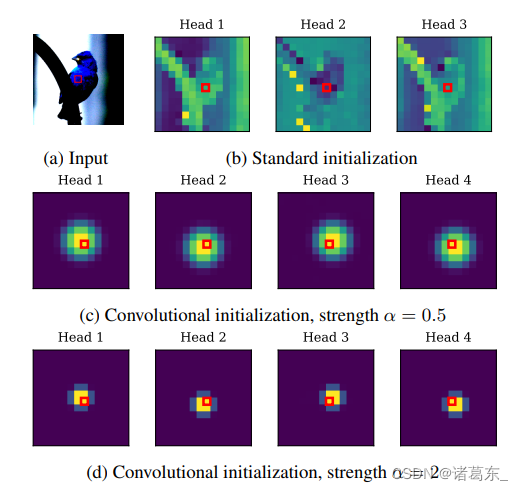
图3. 位置自注意层可以作为卷积层进行初始化。 (a):来自ImageNet的输入图像,其中查询补丁用红色框标出。 (b),(c),(d):未经训练的自注意层的注意力图(b)以及使用方程5的类似于卷积初始化方案的PSA层的注意力图。其中实验使用了不同局部性强度参数α的两个值(c,d)。请注意,在(b)中可以轻松区分图像的形状,但在纯粹定位注意力的情况下,(c)或(d)中不能区分。
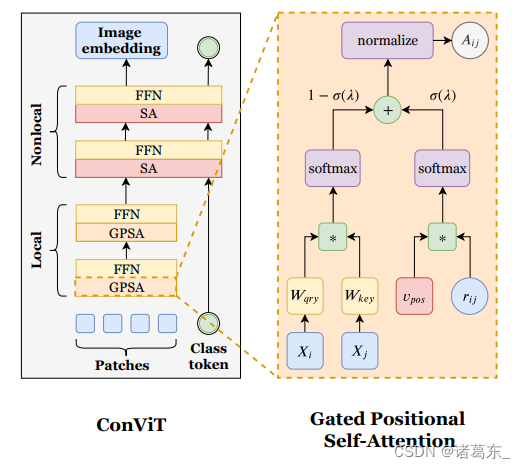
图4. ConViT的结构。ConViT(左)是ViT的一个版本,其中一些自注意力(SA)层被替换为门控的位置自注意力(GPSA)层(右)。由于GPSA层涉及位置信息,所以类别标记在最后一个GPSA层之后与隐藏表示连接。在本文中,我们通常使用10个GPSA层后跟2个普通的SA层。FFN:前馈神经网络(2个线性层,由GeLU激活函数分隔);Wqry:查询权重;Wkey:键权重;vpos:注意力中心和范围嵌入(可学习);rqk:相对位置编码(固定);λ:门控参数(可学习);σ:sigmoid函数。
3.方法
借鉴(Cordonnier et al.,2019)的洞察,我们引入了ConVit模型,这是一个ViT(Dosovitskiy et al.,2020)的变体,通过用我们称为门控位置自注意力(GPSA)层替换一些SA层得到。核心思想是在初始化时,在GPSA层中强制执行Eqs.5中的“知情”卷积配置,然后让它们决定是否保持卷积状。然而,PSA层的标准参数化(Eq. 4)存在两个限制,导致我们引入了两个修改。
自适应注意力范围是PSA中的第一个限制,涉及到大量的可训练参数,因为相对位置编码rδ的数量与补丁数量呈二次关系。这导致一些作者只将注意力限制在查询补丁周围的补丁子集中(Ramaschandran等人,2019),但这样做会失去远程信息。
为了避免这个问题,我们保持相对位置编码rδ不变,只训练确定注意力头中心和范围的嵌入向量
v
p
o
s
h
v_{pos}^h
vposh;这种方法类似于Sukhbaatar等人(2019)在语言Transformer中引入的自适应注意力范围。rδ和vhpos的初始值由公式5给出,我们取Dpos = 3以去除无用的零分量。由于Dpos << Dh,位置注意力所涉及的参数数量与内容注意力所涉及的参数数量相比微不足道。这是有道理的,因为内容相互作用本质上比位置相互作用简单得多。
位置门控第二个问题是标准PSA中的内容项和位置项在公式4中可能具有不同的量级,这种情况下,softmax函数将忽略其中一个较小的项。特别地,上面讨论的卷积初始化方案涉及高度集中的注意力分数,即softmax函数中的高量级值。在实践中,我们观察到在普通PSA层上使用卷积初始化方案会在早期epochs中提高性能,但由于注意机制懒惰地忽略内容信息,会导致后期性能下降(参见附录A)。
为了避免这个问题,GPSA层在softmax之后对内容项和位置项进行求和,它们的相对重要性由可学习的门控参数λh(每个注意力头一个)控制。最后,我们对矩阵的和进行归一化(其项都是正的),以确保得到的注意力分数构成一个概率分布。因此,得到的GPSA层的参数化如下(也可以参考图4):

其中,(normalize [A])ij = Aij / ∑k Aik, σ : x → 1/(1+e(-x)) 是sigmoid函数。通过在初始化时将门控参数λh设置为一个较大的正值,可以得到σ(λh)⋍1:GPSA完全基于位置进行注意力计算,不需要将Wqry和Wkey设置为零,如公式5所述。然而,为了避免ConViT停留在λh≫1的情况下,我们将所有层和所有头的λh初始化为1。
架构细节:ViT将大小为224的输入图像切割为16×16个不重叠的14×14像素的补丁,并使用卷积处理器将它们嵌入到维度为Demb = 64Nh的向量中。然后,它将这些补丁传递到12个块中,块的维度保持不变。每个块由一个SA层组成,后面跟着一个带有GeLU激活函数的2层前馈网络(FFN),两者都带有残差连接。ConViT简单地是一个ViT,其中前10个块将SA层替换为具有卷积初始化的GPSA层。
和类似于BERT(Devlin等人,2018)这样的语言Transformer一样,ViT使用额外的“分类标记”,附加到补丁序列上以预测输入的类。由于这个类标记不携带任何位置信息,ViT的SA层不使用位置注意力:相反,在第一层之前将位置信息注入到每个补丁中,通过添加一个可学习的维度为Demb的位置嵌入。由于GPSA层涉及位置注意力,所以它们不适用于类标记方法。我们通过在最后一个GPSA层之后将类标记附加到补丁上来解决这个问题,与(Touvron等人,2021b)中所做的类似(参见图4)。
为了公平起见,并且它们在计算上便宜,我们在ConViT中保持ViT的绝对位置嵌入是激活的。但是,如SM.F所示,ConViT更少地依赖于它们,因为GPSA层已经使用相对位置编码。因此,可以轻松地去除绝对位置嵌入,省去在更改输入分辨率时插值嵌入的需要(只需要根据公式5重新采样相对位置编码,并在我们的开源实现中自动执行)。
训练细节:我们基于DeiT(Touvron等人,2020)构建了ConViT,DeiT是一个超参数优化的ViT版本,已经开源。由于DeiT能够在不使用任何外部数据的情况下取得竞争性的结果,它既是一个优秀的基准线,而且相对容易训练:最大模型(DeiT-B)只需要在8个GPU上训练几天即可。
为了模拟2×2、3×3和4×4卷积滤波器,我们考虑了三个不同的ConViT模型,分别使用4、9和16个注意力头(参见表1)。它们的头数略大于Touvron等人(2020)的DeiT-Ti、ConViT-S和ConViT-B,它们分别使用3、6和12个注意力头。为了获得相似大小的模型,我们使用了两种比较方法。
• 为了与Touvron等人(2020)进行直接比较,我们将ConViT的嵌入维度降低到Demb/Nh = 48,而不是DeiT使用的64。重要的是,我们保持所有的超参数(调度、数据增强、正则化)与(Touvron等人,2020)中的设定保持不变,以便进行公正的比较。得到的模型分别命名为ConViT-Ti、ConViT-S和ConViT-B。
• 我们还使用相同数量的注意力头和Demb/Nh = 64对DeiT和ConViT进行训练,以确保ConViT的改进不仅仅是由于更多的注意力头(Touvron等人,2021b)。这导致在表1中用“+”注释的模型略大。为了在8个GPU上适应这些模型的训练,我们将学习率从0.0005降低到0.0004,并将批大小从1024降低到512。这些最小的超参数更改导致DeiT-B+的性能不如DeiT-S+,而ConViT不是这种情况,这表明对超参数更改的稳定性更高。
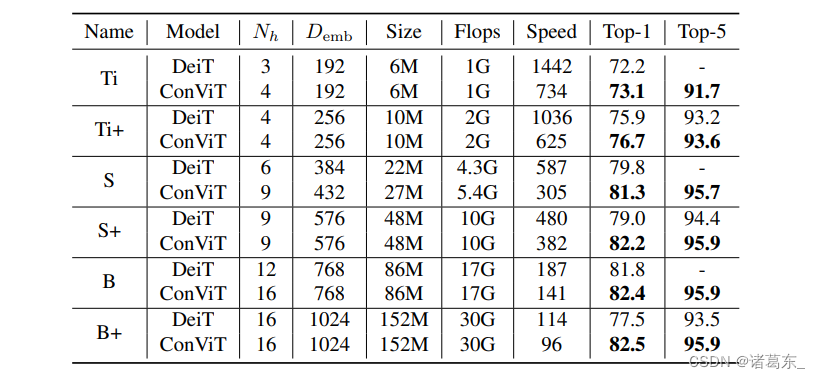
表1. 考虑的模型在ImageNet上从头开始训练的性能。速度是在Nvidia Quadro GP100 GPU上以批大小128处理的图像数。在不经过蒸馏的ImageNet-1k测试集上测量Top-1精度(有关蒸馏,请参见SM. B)。DeiT-Ti、DeiT-S和DeiT-B的结果是从(Touvron等人,2020)报告的。
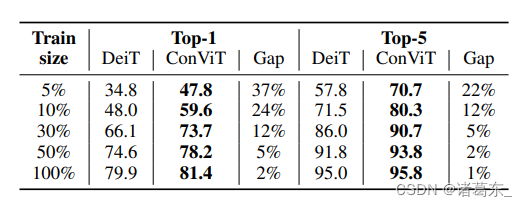
表2. 卷积归纳偏差极大提高了样本效率。我们比较了使用DeiT的原始超参数(Touvron等人,2020)训练的ConViT-S和DeiT-S的Top-1和Top-5精度,以及ConViT相对于DeiT的改进程度。这两个模型均在ImageNet-1k的子采样版本上进行训练,我们在训练中仅保留每个类别的图片的一个可变比例(最左列)。
ConViT在Tab. 1中的性能,我们展示了这些模型在经过300个周期的训练后,在ImageNet测试集上实现的Top-1准确率,以及它们的参数数量、计算量和吞吐量。每个ConViT都以较大的幅度超过了与其大小和计算量相同的DeiT。重要的是,虽然位置自注意力确实降低了ConViT的吞吐量,但它们也在相同的吞吐量下超过了DeiT。例如,ConViT-S+的Top-1准确率达到了82.2%,超过了参数较少、吞吐量较高的原始DeiT-B。在没有任何调整的情况下,ConViT在CIFAR100上也达到了较高的性能,请参见SM. C中我们也报道了学习曲线。
请注意,我们的ConViT与Touvron等人(2020)引入的蒸馏方法兼容,而无需额外成本。如SM. B所示,硬蒸馏可以提高性能,使硬蒸馏的ConViT-S+达到82.9%的Top-1准确率,与参数数量减少一半的硬蒸馏的DeiT-B持平。然而,虽然蒸馏要求在训练的每个步骤中对预训练的CNN进行额外前向传播,但ConViT没有这样的要求,提供了与蒸馏类似的好处,而无需额外的计算要求。
在表2中,我们通过以系统的方式对ImageNet-1k数据集的每个类别进行子抽样(f = {0.05, 0.1, 0.3, 0.5, 1}),同时将训练纪元的数量乘以1/f,以使呈现给模型的图像总数保持不变,来研究ConViT的样本效率。正如人们所期望的那样,DeiT-S及其ConViT-S同行的Top-1精度随着f的减少而下降。然而,ConViT的下降要小得多:当仅使用10%的数据进行训练时,ConVit的Top-1精度达到了59.5%,而DeiT同行的精度为46.5%。
ConViT的Top-1准确率达到了56.4%,因此在样本效率方面非常有竞争力。这些结果与我们的假设一致,即卷积归纳偏差在小型数据集上最有帮助,如图1所示。这个结果可以直接与(Zhai等人,2019)进行比较,该研究在测试了数千个卷积模型后,达到了56.4%的Top-1准确率。因此,ConViT在样本效率方面非常有竞争力。这些结果证实了我们的假设,即卷积归纳偏差在小型数据集上最有帮助,如图1所示。
4. 探究局部性的作用
在这一部分中,我们展示了在标准的自注意力层中自然地鼓励了局部性,并研究了ConViT如何从初始化时的局部性受益。
SA层向局部性靠拢
我们首先研究了一个假设,即在训练过程中,PSA层会自然地趋向于变得“局部”(Cordonnier等人,2019)。我们进一步探究了是否对于ViTs中使用的不具有位置注意力的原始SA层,这一假设仍然成立。为了量化这一点,我们定义了一个“非局部性”的度量,通过对每个查询块i,按照其与所有关键块j的距离kδijk加权计算它们的注意力分数Aij。我们通过对查询块上得到的数值求平均来计算头部h的非局部性指标,然后可以对注意力头部求平均来计算整个层`的非局部性。
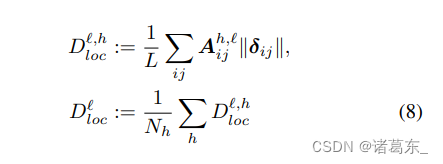
直观地说,Dloc是注意力中心和查询块之间的补丁数:注意力头越远离查询块,非局部性就会越高。
在图5(左侧面板)中,我们展示了在ImageNet上进行了300个周期训练的DeiT-S的12个层中非局部性度量随着训练的演变。在最初的几个周期中,所有层的非局部性都从初始值下降,证实了DeiT变得更加“卷积”。在训练的后期阶段,较低层的非局部性指标保持较低水平,并逐渐上升至较高层,揭示了后者捕捉了远距离的依赖关系,这与语言Transformer(Sukhbaatar等人,2019)的观察结果一致。
当检查注意力图时,这些观察结果尤其明显(参见补充材料的图15),并指出了较低层中局部性的有益效果。在补充材料的图10中,我们还展示了使用来自卷积网络的蒸馏进行训练时,非局部性度量较低,这也支持了Touvron等人(2020)所述的局部性从教师网络部分转移到学生网络(Abnar等人,2020)。
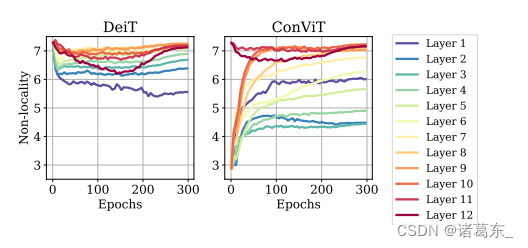
图5中,SA层试图变得局部化,而GPSA层则远离局部性。我们绘制了在一个批次的1024张图像上平均计算的非局部性度量,即方程8中定义的度量指标:数值越高,注意力头距离查询像素越远。我们在ImageNet上对DeiT-S和ConViT-S进行了300个周期的训练。SM中展示了DeiT-Ti/ConViT-Ti和DeiT-B/ConViT-B的类似结果。
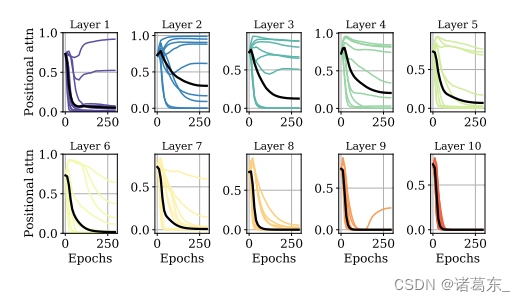
图6. 门控参数揭示了ConViT的内部运作方式。对于每一层,彩色线条(每个注意力头对应一条线)量化了注意力头h关注位置信息与内容信息的程度,即σ(λh)的值,见方程7。黑线代表所有注意力头的平均值。我们在ImageNet上对ConViT-S进行了300个周期的训练。SM D中展示了ConViT-Ti和ConViT-B的类似结果。
GPSA层避免局部性 在ConViT中,由于卷积初始化,GPSA层在训练开始时会强加强局部性。在图5的右侧面板中,我们可以看到在整个训练过程中,所有的GPSA层都呈现出非局部性度量的增长。然而,最终训练出的非局部性度量比DeiT低,表明一些初始化信息在整个训练过程中得以保存。有趣的是,与DeiT不同,最终的非局部性度量并不是在所有层中单调递增的。第一层和最后一层呈现强的非局部性,而中间层(特别是第二层)则更局部化。
为了更好地理解,我们在图6中研究了门控参数的动态变化。我们可以看到,在所有的层中,平均门控参数Ehσ(λh)(用黑色表示)即对位置信息与内容信息的平均关注程度,在整个训练过程中逐渐减小。
在第6-10层,这个数值达到了0,意味着位置信息基本上被忽略了。然而,在第1-5层中,一些注意力头仍然保持较高的σ(λh)值,因此能够利用位置信息。有趣的是,ConViT-Ti只在前4层使用位置信息,而ConViT-B在前6层使用位置信息(请参见附录D),这表明中等规模的模型-更具模糊性-更能从卷积先验中受益。这些观察结果突显了门控参数在可解释性方面的有用性。
通过图7中的注意力图,我们进一步揭示了ConViT的内部工作原理。这些图像是通过将嵌入的输入图像传递到各个层,并选择图像中心的查询补丁来获得的。在第10层(底部一行),DeiT和ConViT的注意力图在定性上看起来相似:它们都执行基于内容的注意力。然而,在第2层(顶部一行),ConViT的注意力图更加多样:一些头部关注内容(头部1和2),而其他头部主要关注位置(头部3和4)。在关注位置的头部中,有些保持高度局部化(头部4),而其他头部的关注范围则扩大(头部3)。感兴趣的读者可以在SM中找到更多的注意力图。
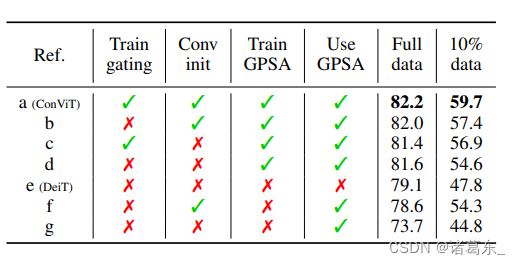
表3。门控和卷积初始化很好地配合使用。我们对ConViT-S+进行了消融研究,训练了300个时期的完整ImageNet训练集和10%的训练数据。从左列到右列,我们尝试将门控参数冻结为0,删除卷积初始化,冻结GPSA层以及完全删除GPSA层。
强的局部性是可取的。接下来,我们研究了ConViT的两个重要超参数对其性能的影响:局部性强度α,它确定了注意力头在其关注中心周围的聚焦程度,以及替换SA层的GPSA层的数量。我们研究了这些超参数对在ImageNet的前100类上训练的ConViT-S的影响。如图8(a)所示,最终的测试准确度随着局部性强度和GPSA层数的增加而增加;换句话说,卷积越多,性能越好。
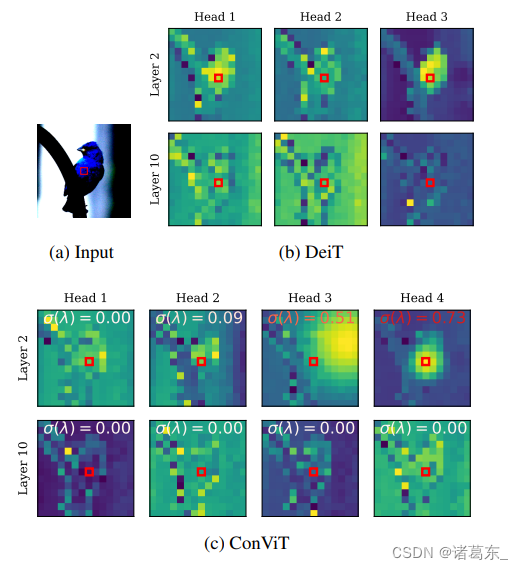
图7。ConViT学习到更多多样化的注意力图。 左侧:图像输入,被嵌入后传入模型。查询补丁由红色框突出显示,并且颜色映射是对数尺度的,以更好地显示细节。中间:在ImageNet上经过300个时期训练的DeiT-Ti所获得的注意力图。右侧:ConViT-Ti的注意力图。在每个图中,我们用从白色(表示关注内容的头部)到红色(表示关注位置的头部)的颜色变化来表示门控参数的值。更多图像和头部的注意力图可在SM中查看。
在图8(b)中,我们展示了在训练的各个阶段中,GPSA层的存在对性能的影响。我们可以看到,在训练的早期阶段,由于GPSA层的存在,性能提升尤为显著:在经过20个时期的训练后,使用9个GPSA层的测试准确率几乎翻倍,这表明卷积初始化为模型提供了实质性的“快速启动”。这种加速在实践中具有重要意义,除了最终性能的提升之外。
消融实验:在表3中,我们对ConViT进行了消融实验,以[a]表示。我们试验了移除位置门控[b] 4,卷积初始化[c],两者门控和卷积初始化[d],以及完全移除GPSA层[e](这样我们就只剩下了一个普通的DeiT)。
令人惊讶的是,在完整的ImageNet上,没有门控的GPSA [d]相对DeiT已经带来了显著的好处(+2.5),而通过卷积初始化轻微地增加了一些效果([b],+2.9)。至于门控,在存在卷积初始化的情况下有一定帮助([a],+3.1),否则没有帮助。这些由于门控和卷积初始化的轻微改进(很可能是因为在80% top-1以上的性能饱和)在低数据区间更加清晰。在这里,仅GPSA带来了+6.8的增益,门控增加了额外的+2.3,卷积初始化增加了+2.8,两者结合在一起则增加了+5.1,显示了它们的互补性。
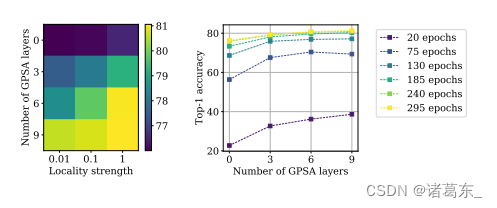
图8。局部性的有益效果。左图:随着我们增加局部性的强度(即每个注意力头对其关联补丁的注意力集中程度)和GPSA层的数量,ConViT-S+的最终 top-1 准确率显著提高。右图:局部性的有益效果在早期时期尤为明显。
我们还对所有GPSA层冻结的ConViT性能进行了研究,只训练前10层的FFNs。可以预期,在完整数据范围内,如果我们随机初始化GPSA层([f]),性能会显著下降(相比DeiT,下降了5.4)。然而,卷积初始化使得冻结的ConViT能够达到非常不错的性能,几乎与DeiT相当([e],下降了0.5)。换句话说,用随机的“卷积”替换SA层几乎不会对性能产生影响。在低数据范围内,冻结的ConViT甚至比DeiT表现更好(增加了6.5)。这自然引出了一个问题:注意力对于ViTs的成功真的关键吗(Dong et al., 2021; Tolstikhin et al., 2021; Touvron et al., 2021a)?
5. 结论和展望
本研究探讨了初始化和归纳偏差在使用视觉转换器进行学习中的重要性。通过展示我们可以以柔性方式利用卷积约束,我们结合了架构先验和表达能力的优点。结果是一个简单的方法,提高了模型的可训练性和样本效率,而无需增加模型大小或进行任何调整。
我们的方法可以概括如下:与混合模型中将卷积层与SA层交错使用不同,我们通过调整一组门控参数来让层自行决定是否采用卷积方式。更一般地,结合不同架构的偏差,并让模型选择对于给定任务最合适的架构,可能成为一个有前景的方向,减少了贪婪的架构搜索需求,同时提供更高的可解释性。
在未来的研究中,还将探索另一个方向:如果SA层从随机卷积中进行初始化可以获益,那么将它们初始化为预训练卷积是否能更极端地降低其样本复杂度呢?
致谢 我们感谢Herve J ´ egou和Francisco Massa的有益讨论。SD和GB感谢法国政府在Agence Nationale de la Recherche的管理下提供的资助,作为“未来投资”计划的一部分,参考编号ANR-19-P3IA-0001(PRAIRIE 3IA学院)。
参考文献
Abnar, S., Dehghani, M., and Zuidema, W. Transferring
inductive biases through knowledge distillation. arXiv
preprint arXiv:2006.00555, 2020.
Anandkumar, A., Deng, Y., Ge, R., and Mobahi, H.
Homotopy analysis for tensor pca. arXiv preprint
arXiv:1610.09322, 2016.
Bahdanau, D., Cho, K., and Bengio, Y. Neural machine
translation by jointly learning to align and translate. arXiv
preprint arXiv:1409.0473, 2014.
Bello, I., Zoph, B., Vaswani, A., Shlens, J., and Le, Q. V.
Attention augmented convolutional networks. In Proceedings of the IEEE International Conference on Computer
Vision, pp. 3286–3295, 2019.
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov,
A., and Zagoruyko, S. End-to-end object detection with
transformers. arXiv preprint arXiv:2005.12872, 2020.
Chen, Y., Kalantidis, Y., Li, J., Yan, S., and Feng, J.
A2-nets: Double attention networks. arXiv preprint
arXiv:1810.11579, 2018.
Chen, Y.-C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z.,
Cheng, Y., and Liu, J. Uniter: Universal image-text representation learning. In European Conference on Computer
Vision, pp. 104–120. Springer, 2020.
Cordonnier, J.-B., Loukas, A., and Jaggi, M. On the relationship between self-attention and convolutional layers.
arXiv preprint arXiv:1911.03584, 2019.
d’Ascoli, S., Sagun, L., Biroli, G., and Bruna, J. Finding the
needle in the haystack with convolutions: on the benefits
of architectural bias. In Advances in Neural Information
Processing Systems, pp. 9334–9345, 2019.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert:
Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805,
2018.
Dong, Y., Cordonnier, J.-B., and Loukas, A. Attention is
not all you need: Pure attention loses rank doubly exponentially with depth. arXiv preprint arXiv:2103.03404,
2021.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn,
D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M.,
Heigold, G., Gelly, S., et al. An image is worth 16x16
words: Transformers for image recognition at scale. arXiv
preprint arXiv:2010.11929, 2020.
Elsayed, G., Ramachandran, P., Shlens, J., and Kornblith, S.
Revisiting spatial invariance with low-rank local connectivity. In International Conference on Machine Learning,
pp. 2868–2879. PMLR, 2020.
Gers, F. A., Schmidhuber, J., and Cummins, F. Learning to
forget: Continual prediction with lstm. 1999.
Goodfellow, I., Bengio, Y., and Courville, A. Deep Learning.
MIT Press, 2016.
Greff, K., Srivastava, R. K., Koutn´ık, J., Steunebrink, B. R.,
and Schmidhuber, J. LSTM: A Search Space Odyssey.
IEEE Transactions on Neural Networks and Learning Systems, 28(10):2222–2232, October 2017. ISSN 2162-2388.
doi: 10.1109/TNNLS.2016.2582924. Conference Name:
IEEE Transactions on Neural Networks and Learning
Systems.
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE
conference on computer vision and pattern recognition,
pp. 770–778, 2016.
Hinton, G., Vinyals, O., and Dean, J. Distilling
the knowledge in a neural network. arXiv preprint
arXiv:1503.02531, 2015.
Hu, H., Gu, J., Zhang, Z., Dai, J., and Wei, Y. Relation
networks for object detection. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition,
pp. 3588–3597, 2018a.
Hu, J., Shen, L., Albanie, S., Sun, G., and Vedaldi, A.
Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks. In Bengio, S., Wallach, H.,
Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 31, pp. 9401–9411. Curran Associates, Inc.,
2018b.
Hu, J., Shen, L., and Sun, G. Squeeze-and-Excitation Networks. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7132–7141, June 2018c.
doi: 10.1109/CVPR.2018.00745. ISSN: 2575-7075.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. Imagenet
classification with deep convolutional neural networks.
Communications of the ACM, 60(6):84–90, 2017.
LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard,
R. E., Hubbard, W., and Jackel, L. D. Backpropagation applied to handwritten zip code recognition. Neural
computation, 1(4):541–551, 1989.
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. Gradientbased learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
Locatello, F., Weissenborn, D., Unterthiner, T., Mahendran,
A., Heigold, G., Uszkoreit, J., Dosovitskiy, A., and Kipf,
T. Object-centric learning with slot attention. arXiv
preprint arXiv:2006.15055, 2020.
Mitchell, T. M. The need for biases in learning generalizations. Department of Computer Science, Laboratory for
Computer Science Research . . . , 1980.
Neyshabur, B. Towards learning convolutions from scratch.
Advances in Neural Information Processing Systems, 33,
2020.
Radosavovic, I., Kosaraju, R. P., Girshick, R., He, K., and
Dollar, P. Designing network design spaces. In ´ Proceedings of the IEEE/CVF Conference on Computer Vision
and Pattern Recognition, pp. 10428–10436, 2020.
Ramachandran, P., Parmar, N., Vaswani, A., Bello, I., Levskaya, A., and Shlens, J. Stand-alone self-attention in
vision models. arXiv preprint arXiv:1906.05909, 2019.
Ruderman, D. L. and Bialek, W. Statistics of natural images:
Scaling in the woods. Physical review letters, 73(6):814,
1994.
Scherer, D., Muller, A., and Behnke, S. Evaluation of ¨
Pooling Operations in Convolutional Architectures for
Object Recognition. In Diamantaras, K., Duch, W., and
Iliadis, L. S. (eds.), Artificial Neural Networks – ICANN
2010, Lecture Notes in Computer Science, pp. 92–101,
Berlin, Heidelberg, 2010. Springer. ISBN 978-3-642-
15825-4. doi: 10.1007/978-3-642-15825-4 10.
Schmidhuber, J. Deep learning in neural networks:
An overview. Neural Networks, 61:85–117, January
2015. ISSN 0893-6080. doi: 10.1016/j.neunet.2014.09.
003. URL http://www.sciencedirect.com/
science/article/pii/S0893608014002135.
Simoncelli, E. P. and Olshausen, B. A. Natural image statistics and neural representation. Annual review of neuroscience, 24(1):1193–1216, 2001.
Srinivas, A., Lin, T.-Y., Parmar, N., Shlens, J., Abbeel, P.,
and Vaswani, A. Bottleneck Transformers for Visual
Recognition. arXiv e-prints, art. arXiv:2101.11605, January 2021.
Sukhbaatar, S., Grave, E., Bojanowski, P., and Joulin, A.
Adaptive attention span in transformers. arXiv preprint
arXiv:1905.07799, 2019.
Sun, C., Myers, A., Vondrick, C., Murphy, K., and Schmid,
C. Videobert: A joint model for video and language
representation learning. In Proceedings of the IEEE International Conference on Computer Vision, pp. 7464–7473,
2019.
Sundermeyer, M., Schluter, R., and Ney, H. LSTM neural ¨
networks for language modeling. In Thirteenth annual
conference of the international speech communication
association, 2012.
Tan, M. and Le, Q. Efficientnet: Rethinking model scaling
for convolutional neural networks. In International Conference on Machine Learning, pp. 6105–6114. PMLR,
2019.
Tolstikhin, I., Houlsby, N., Kolesnikov, A., Beyer, L., Zhai,
X., Unterthiner, T., Yung, J., Keysers, D., Uszkoreit, J.,
Lucic, M., et al. Mlp-mixer: An all-mlp architecture for
vision. arXiv preprint arXiv:2105.01601, 2021.
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles,
A., and Jegou, H. Training data-efficient image trans- ´
formers & distillation through attention. arXiv preprint
arXiv:2012.12877, 2020.
Touvron, H., Bojanowski, P., Caron, M., Cord, M., ElNouby, A., Grave, E., Joulin, A., Synnaeve, G., Verbeek,
J., and Jegou, H. Resmlp: Feedforward networks for ´
image classification with data-efficient training. arXiv
preprint arXiv:2105.03404, 2021a.
Touvron, H., Cord, M., Sablayrolles, A., Synnaeve, G., and
Jegou, H. Going deeper with image transformers, 2021b. ´
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Attention is all you need. In Advances in neural information
processing systems, pp. 5998–6008, 2017.
Wang, X., Girshick, R., Gupta, A., and He, K. Nonlocal Neural Networks. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.
7794–7803, Salt Lake City, UT, USA, June 2018. IEEE.
ISBN 978-1-5386-6420-9. doi: 10.1109/CVPR.2018
00813. URL https://ieeexplore.ieee.org/
document/8578911/.
Wu, B., Xu, C., Dai, X., Wan, A., Zhang, P., Tomizuka, M.,
Keutzer, K., and Vajda, P. Visual Transformers: Tokenbased Image Representation and Processing for Computer
Vision. arXiv:2006.03677 [cs, eess], July 2020. URL
http://arxiv.org/abs/2006.03677. arXiv:
2006.03677.
Yuan, L., Chen, Y., Wang, T., Yu, W., Shi, Y., Tay, F. E.,
Feng, J., and Yan, S. Tokens-to-token vit: Training vision
transformers from scratch on imagenet. arXiv preprint
arXiv:2101.11986, 2021.
Zhai, X., Oliver, A., Kolesnikov, A., and Beyer, L. S4l: Selfsupervised semi-supervised learning. In Proceedings of
the IEEE/CVF International Conference on Computer
Vision, pp. 1476–1485, 2019.
Zhao, S., Zhou, L., Wang, W., Cai, D., Lam, T. L., and
Xu, Y. Splitnet: Divide and co-training. arXiv preprint
arXiv:2011.14660, 2020.
A. 位置门控的重要性
在正文中,我们讨论了使用GPSA层而不是标准的PSA层的重要性,其中在softmax之前将内容和位置信息相加,导致注意力头只关注位置信息。我们在图9中提供了此命令的证据,在该图中,我们在ImageNet上对ConViT-B进行了300个时期的训练,但用标准的PSA替换了GPSA。虽然仍然通过PSA的卷积初始化在训练早期给ConViT带来了很大的优势,但ConViT仍然停留在卷积配置中,并忽略内容信息,这可以通过查看注意力图(未显示)来看到。在训练后期,DeiT利用内容信息赶上并超越了ConViT。

图9. 在没有GPSA的情况下,卷积初始化在训练早期是有益的,但会降低最终的性能。我们在ImageNet上对ConViT-B及其DeiT-B对应模型进行了300个时期的训练,并用标准的PSA层替换了ConViT-B的GPSA层。
B. 蒸馏的影响
非局部性 在图10中,我们将主文中图5的非局部性曲线与通过从RegNetY-16GF(84M参数)(Radosavovic等人,2020)对DeiT进行硬蒸馏得到的曲线进行了比较,就像Touvron等人的研究中所做的那样。在蒸馏设置中,非局部性在训练的早期仍然下降,但相比没有蒸馏,它在后期的增加程度较小。因此,由于蒸馏,DeiT的最终内部状态更“局部”。这表明,知识蒸馏将卷积教师的局部性传递给了学生,与(Abnar等人,2020)的结果一致。
性能 Touvron et al.(2020)中引入的硬蒸馏大大提高了DeiT的性能。我们验证了他们的蒸馏方法与我们的ConViT的互补性。与DeiT论文中一样,我们使用了RegNet-16GF作为教师模型,并在ImageNet上进行了300个时期的硬蒸馏实验。我们得到的结果在表4中总结。

表4:在ImageNet上训练300个周期,将ConViT-S+与训练的DeiT-S和DeiT-B的Top-1准确率进行比较
就像DeiT一样,ConViT也受益于蒸馏,尽管受益程度稍逊于DeiT,从DeiT-B表现不如ConViT-S+(没有蒸馏)可以看出,在使用蒸馏后,DeiT-B的表现更好。这表明从教师模型传递的卷积归纳偏差与其自身的卷积先验是冗余的。
然而,ConViT通过硬蒸馏所获得的性能改进表明,在模型中直接实例化软性归纳偏差可以产生除了通过蒸馏间接实例化该偏差获得的好处之外的额外益处。
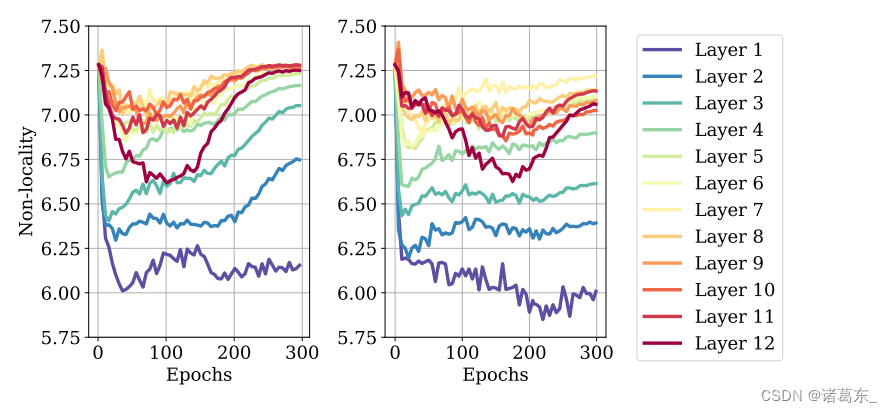
图10. 蒸馏将DeiT向更局部的配置拉动。我们绘制了在ImageNet上训练的DeiT-S在整个训练过程中定义的非局部性指标(在公式8中定义)。左边:常规训练。右边:使用RegNet教师的硬蒸馏训练,通过(Touvron等人,2020)中介绍的蒸馏方法。
C. 进一步的性能结果
在图11中,我们展示了我们的ConViT+模型在CIFAR100、ImageNet和子采样的ImageNet上的top-1精度随时间的演化情况,并与相应的DeiT+模型进行比较。
对于CIFAR100,我们保持所有超参数不变,但将图像重新调整为224×224并增加了epochs的数量(相应地调整学习率计划),以模拟ImageNet场景。在1000个epochs之后,ConViTs显示出明显的过拟合迹象,但达到了令人印象深刻的性能水平(使用10M个参数时的82.1%的top-1精度,比(Zhao等人,2020)中报告的EfficientNets更好)。
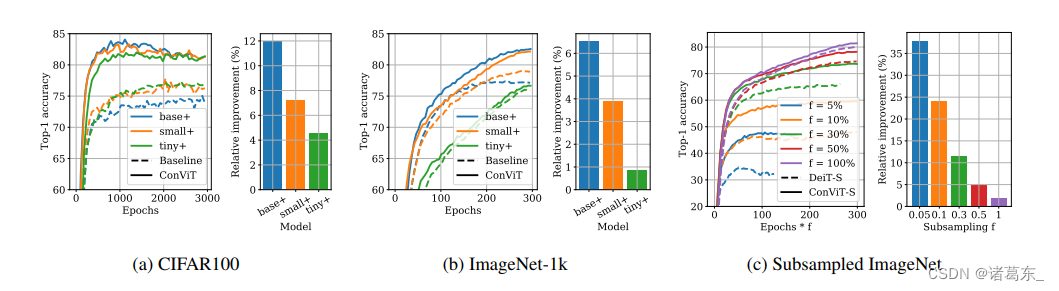
图11。对于应用于小型数据集的大型模型,卷积感应偏差尤其有用。每个板块显示了ConViT+模型和相应的DeiT+在训练过程中的top-1精度,以及DeiT+达到的最佳top-1精度与ConViT+达到的最佳top-1精度之间的相对改进。左侧:在CIFAR100上进行了3000个epochs的小型、中等和基础模型训练。中间:在ImageNet-1k上进行了300个epochs的小型、中等和基础模型训练。随着模型大小的增加,ConViT相对于DeiT的改进程度也增加。右侧:在ImageNet-1k的子样本版本上进行了小型模型训练,其中我们只保留了每个类别图像的一部分f ∈ {0.05, 0.1, 0.3, 0.5, 1}。随着数据集变小,ConViT相对于DeiT的改进程度也增加。
在图12中,我们研究了ConViT中各种组成部分(GPSA层的存在和数量、门控参数、卷积初始化)对学习动态的影响。
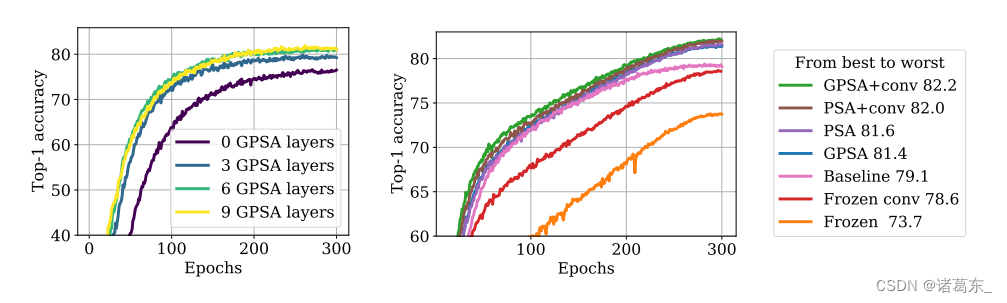
图12。ConViT各种组成部分对学习动态的影响。在两种情况下,我们在ImageNet的前100个类别上对ConViT-S+进行了300个epochs的训练。左侧:关于GPSA层数量的消融,如图8所示。右侧:关于ConViT的各种组成部分的消融,如Tab. 3所示。基准是DeiT-S+(粉色)。我们进行了实验:(i)将前10个SA层替换为GPSA层(“GPSA”);(ii)冻结GPSA层的门控参数(“frozen gate”);(iii)去除卷积初始化(“conv”);(iv)冻结GPSA层中的所有注意力模块(“frozen”)。图例中报告了各种训练模型的最终top-1精度。
D. 模型大小的影响
在图13中,我们展示了迷你和基础模型的类比版本,类似于主文第5图。结果在质量上与小型模型观察到的结果相似。有趣的是,DeiT-B和ConViT-B的第一层的非局部性比DeiT-Ti和ConViT-Ti的第一层显著高。
在图14中,我们展示了迷你和基础模型的主文第6图的类比版本。同样,结果在质量上相似:位置关注的平均权重Ehσ(λh)随时间减少,因此更多的关注被转向图像内容。需要注意的是,在ConViT-Ti中,只有前4层在训练结束时仍然关注位置(平均门控参数小于1),而对于ConViT-S,前5层仍然关注位置,而对于ConViT-B,前6层仍然关注位置。这表明,模型越大(即规范化约束越少),使用卷积先验的层数也越多。
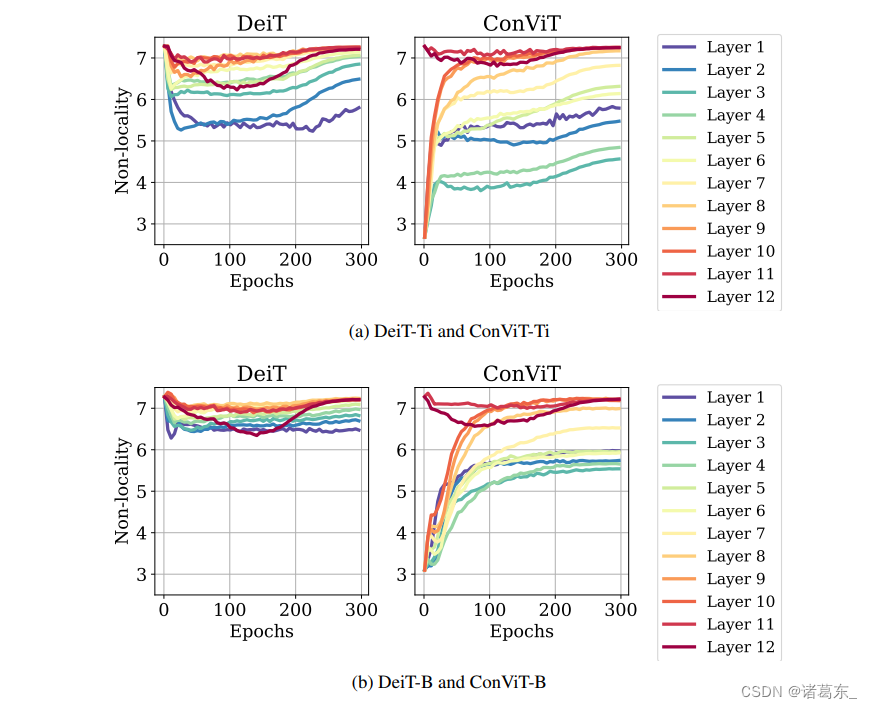
图13. 模型越大,注意力越非局部。我们绘制了在ImageNet-1k上进行300个训练时期期间定义在主文中的方程8中的非局部性度量(数值越高,注意力头离查询像素的距离越远)。
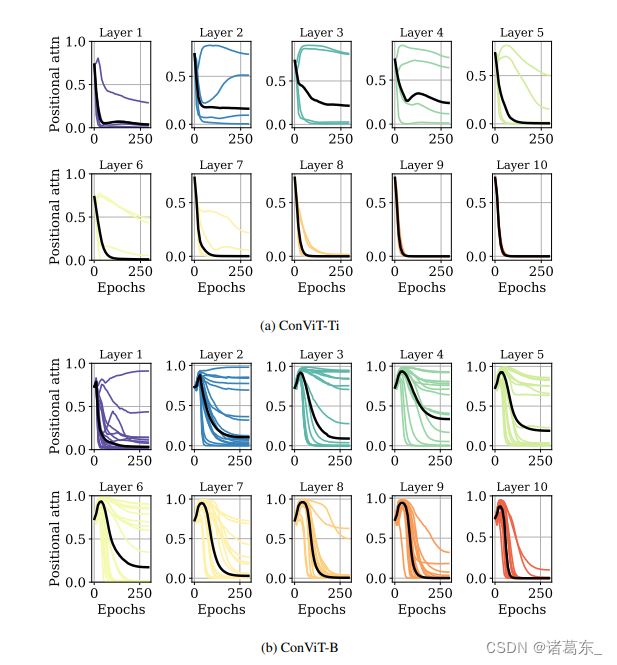
图14. 模型越大,越多的层次关注位置信息。我们绘制了各个头部和各个层次的门控参数,与主文第6图类似(数值越低,对位置信息的关注越少),在ImageNet-1k的300个训练时期期间进行绘制。需要注意的是,ConViT-Ti只有4个注意力头,而ConViT-B有16个,因此曲线的数量不同。
E. 注意力图
DeiT的注意力图显示出局部性。在图15中,我们提供了一些视觉证据,证明了DeiT的普通SA层通过对100个图像的第一层和第十层的注意力图求平均来提取局部信息。在训练之前,这些图看起来基本上是随机的。然而,在训练之后,大多数第一层的注意力头部聚焦在查询像素及其周围,而第十层的注意力头部捕捉到了长距离的依赖关系。
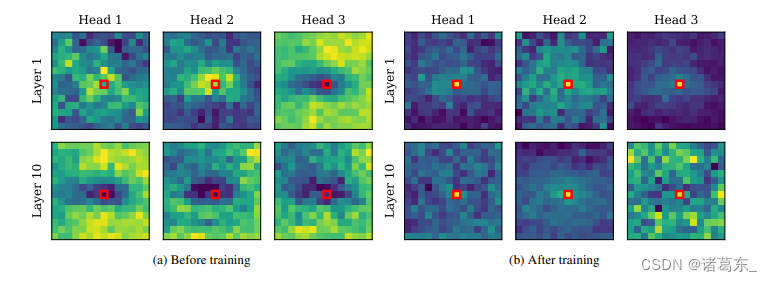
图15. 训练结束时,DeiT的平均注意力图显示出局部性。为了更好地可视化关注的中心,我们对100幅图像的注意力图进行了平均。顶部:在训练之前,注意力模式呈现出随机结构。底部:经过训练后,大部分注意力集中在查询像素上,其余部分则集中在其周围的区域。
ConViT的注意力图显示出注意力头部的多样性。在图16中,我们展示了ImageNet验证集不同图像的Deit-Ti和ConViT-Ti的注意力图比较。在图17中,我们比较了DeiT-S和ConViT-S的注意力图。
在所有情况下,结果在定性上都相似:DeiT的注意力图在不同头部和不同层之间看起来相似,而ConViT的注意力图执行非常不同的操作。请注意,在第二层中,第三和第四头部保持局部化,而前两个头部关注内容。在最后一层中,所有头部都忽略位置信息,只关注内容。
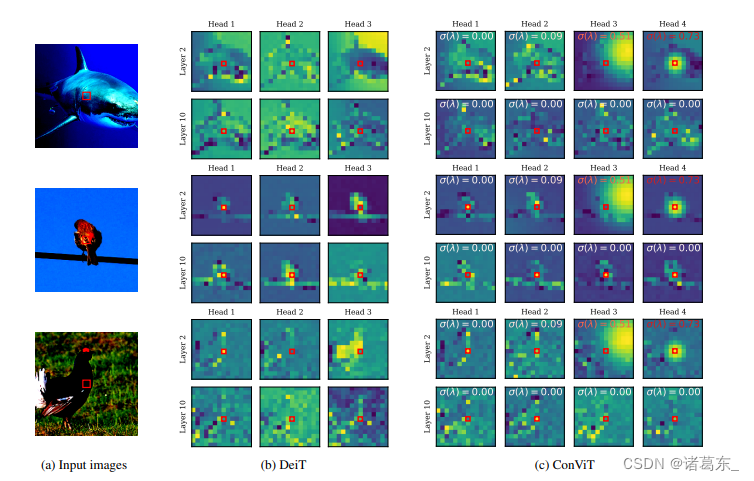
图16. 左侧: 输入图像被嵌入并送入模型。查询补丁由红色框标出,颜色图是对数尺度以更好地显示细节。中间: 在ImageNet上进行了300个训练轮次后,DeiT-Ti获得的注意力图。右侧: ConViT-Ti的注意力图。在每个图中,我们使用从白色(表示关注内容的头部)到红色(表示关注位置的头部)变化的颜色指示了门控参数的值。

图17. 在ImageNet上进行了300个训练轮次后,DeiT-S和ConViT-S获得的注意力图。在每个图中,我们使用从白色(表示关注内容的头部)到红色(表示关注位置的头部)变化的颜色指示了门控参数的值。
F. 进一步的消融实验
在这一部分中,我们探索了对网络的各个部分进行屏蔽,以理解哪些部分是最关键的。
在表5中,我们探讨了在DeiT和ConViT中注入输入的绝对位置嵌入的重要性。我们发现,在测试时屏蔽它们对于ConViT的准确性产生了轻微的影响,但对于DeiT来说影响很大,这是预期的,因为ConViT已经在每个GPSA层中具有相对位置信息。这也表明,嵌入中包含的绝对位置信息并不是非常有用。
在表6中,我们探讨了通过在测试时屏蔽相对重要性的位置和内容信息。为此,我们手动将门控参数σ(λ)设置为1(没有内容关注)或0(没有位置关注)。在第一个GPSA层中,两个过程对性能影响相似,表明位置和内容信息都很有用。然而,在最后一个GPSA层中,屏蔽内容信息会破坏性能,而屏蔽位置信息则不会,证实了内容信息更加关键。

表5. 在测试时屏蔽位置嵌入的ImageNet性能
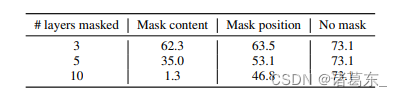
表6. 在测试时屏蔽ConViT-Ti在ImageNet上的位置或内容注意力的性能。
















 1373
1373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









