





目录
原文地址
EfficientViT: 高分辨率密集预测的多尺度线性注意力
摘要
高分辨率密集预测能够实现许多吸引人的实际应用,如计算摄影、自动驾驶等。然而,庞大的计算开销使得在硬件设备上部署最先进的高分辨率密集预测模型变得困难。本研究提出了EfficientViT,一种具有新颖的多尺度线性注意力的高分辨率视觉模型系列。与以往依赖于重型softmax注意力、硬件效率低下的大卷积核卷积,或复杂的拓扑结构来获得良好性能的高分辨率密集预测模型不同,我们的多尺度线性注意力通过轻量级且高效的操作实现了全局感受野和多尺度学习(对于高分辨率密集预测的两个理想特征)。因此,EfficientViT在各种硬件平台上实现了显著的性能提升,并且速度明显提升,包括移动CPU、边缘GPU和云GPU。在Cityscapes数据集上,我们的EfficientViT相对于SegFormer和SegNeXt实现了高达13.9倍和6.2倍的GPU延迟降低,而性能没有损失。对于超分辨率,EfficientViT相对于Restormer实现了高达6.4倍的加速,并提高了0.11dB的PSNR。对于任何分割任务,EfficientViT在GPU上提供了与ViT-Huge相似的zero-shot图像分割质量,但吞吐量提高了84倍。
PSNR 是 Peak Signal to Noise Ratio 的缩写,即峰值信噪比。它是一种评估数字图像或视频质量的常用指标之一,通常用来度量经过压缩或处理后的图像和原始图像相似程度的好坏。
1.引言
高分辨率密集预测是计算机视觉中的一个基本任务,在现实世界中具有广泛的应用,包括自动驾驶、医学图像处理、计算摄影等。因此,在硬件设备上部署最先进的高分辨率密集预测模型可以使许多应用受益。
SOTA模型(State-of-the-Art model)指的是在特定领域中目前拥有最佳性能的模型,它代表了当前技术的最高水平,并且通常由领域内的顶级研究团队或公司开发。
然而,SOTA高分辨率密集预测模型所需的计算成本与硬件设备的有限资源之间存在很大的差距。这使得在实际应用中使用这些模型不切实际。特别是,高分辨率密集预测模型需要高分辨率图像和强大的上下文信息提取能力才能发挥良好的作用[1,2,3,4,5,6]。因此,直接从图像分类中移植高效的模型架构并不适合高分辨率密集预测。
本研究引入了EfficientViT,一种用于高效高分辨率密集预测的新型视觉变换器模型族。EfficientViT的核心是一个新的多尺度线性注意模块,它通过硬件高效的操作实现了全局感受野和多尺度学习。我们的模块受到先前SOTA高分辨率密集预测模型的启发。
这些模型证明了多尺度学习[3,4]和全局感受野[7]对于改善模型性能至关重要。然而,在设计模型时,它们并未考虑硬件效率,而这对于实际应用非常重要。例如,SegFormer [7]在骨干网络中引入了softmax注意力[8],以实现全局感受野。然而,它的计算复杂度与输入分辨率的平方成正比,使其无法高效处理高分辨率图像。SegNeXt [9]提出了一个多支路模块,其使用大卷积核(卷积核尺寸高达21)实现了大感受野和多尺度学习。然而,大卷积核需要在硬件上提供特殊支持才能实现良好的效率[10,11],而这通常在硬件设备上不可用。
因此,我们模块的设计原则是在避免硬件效率低下的操作的同时,实现这两个关键特性。具体而言,我们提出使用轻量级的ReLU线性注意力[12]来替代低效的softmax注意力,以实现全局感受野。通过利用矩阵乘法的关联性质,ReLU线性注意力可以将计算复杂度从二次降低到线性,并保持功能性。此外,它避免了像softmax这样的硬件效率低下的操作,使其更适合于硬件部署(图4)。
然而,单独使用ReLU线性注意力由于缺乏局部信息提取和多尺度学习能力而受到限制。因此,我们提出使用卷积增强ReLU线性注意力,并引入多尺度线性注意力模块来解决ReLU线性注意力的容量限制问题。具体而言,我们使用小卷积核对附近的标记进行聚合,生成多尺度标记。然后,我们对多尺度标记进行ReLU线性注意力操作(图2),将全局感受野与多尺度学习相结合起来。我们还在FFN层中插入深度卷积,进一步提高局部特征提取能力。
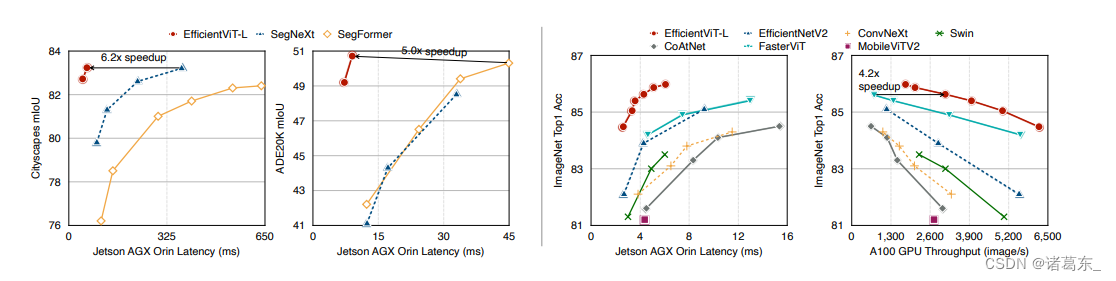
图1: 延迟/吞吐量与性能之间的关系。所有性能结果都是使用单一模型和单一比例推理获得的。GPU延迟/吞吐量结果是在一个边缘GPU(Jetson AGX Orin)和一个云GPU(A100)上,使用TensorRT和fp16获得的。在Cityscapes、ADE20K和ImageNet上,EfficientViT在提供相同/更高性能的同时,在不同的硬件平台上始终能够显著提高速度,超过了以前的分割/分类模型。
我们对EfficientViT在两个流行的高分辨率密集预测任务上进行了广泛的评估,包括语义分割和超分辨率。EfficientViT相比于以前的最先进高分辨率密集预测模型,能够显著提升性能。更重要的是,EfficientViT不涉及硬件效率低下的操作,因此我们的FLOPs(浮点运算数)减少可轻松转化为硬件设备上的延迟降低(参见图1)。
除了传统的高分辨率密集预测任务以外,我们还将EfficientViT应用到“Segment Anything”[13]这一新兴的可提示分割任务中,该任务允许在许多视觉任务中进行零样本迁移。EfficientViT相比ViT-Huge[13]在A100 GPU上实现84倍的加速,同时保持可比的零样本图像分割质量。我们的贡献总结如下:
• 我们引入了一种新的多尺度线性注意力模块,用于高效的高分辨率密集预测。它实现了全局感受野和多尺度学习,同时保持硬件上的高效性。据我们所知,我们的工作是首次证明线性注意力在高分辨率密集预测中的有效性。
• 我们基于提出的多尺度线性注意力模块,设计了EfficientViT,这是一种新的高分辨率视觉模型系列。
• 我们的模型在语义分割、超分辨率、Segment Anything 和 ImageNet分类等多种硬件平台上(移动CPU、边缘GPU和云GPU)相比之前的领先模型表现出显著的加速效果。
2.方法
该部分首先介绍了多尺度线性注意力模块。与之前的研究不同,我们的多尺度线性注意力通过只使用硬件高效的操作,同时实现了全局感受野和多尺度学习。基于多尺度线性注意力,我们提出了一种名为EfficientViT的新一代视觉转换器模型,用于高分辨率密集预测。
2.1 多尺度线性注意力
我们的多尺度线性注意力平衡了高效的高分辨率密集预测的两个关键方面,即性能和效率。具体而言,从性能的角度来看,全局感受野和多尺度学习是必不可少的。以往的高分辨率密集预测模型通过启用这些特性来提供强大的性能,但效率并不理想。我们的模块通过在一定程度上牺牲容量来显著提高效率来解决这个问题。
图2(右侧)提供了所提出的多尺度线性注意力模块的示意图。具体而言,我们提出使用ReLU线性注意力[12]来实现全局感受野,而不是使用复杂的softmax注意力[8]。尽管ReLU线性注意力[12]和其他线性注意力模块[14, 15, 16, 17]在其他领域中得到了探索,但它从未成功应用于高分辨率密集预测。据我们所知,EfficientViT是第一个在高分辨率密集预测中证明ReLU线性注意力有效性的工作。此外,我们的工作还引入了新的设计来解决容量限制问题。

图2:EfficientViT的基本块(左)和多尺度线性注意力(右)。左:EfficientViT的基本块由多尺度线性注意力模块和带深度卷积的FFN(FFN+DWConv)组成。多尺度线性注意力负责捕捉上下文信息,而FFN+DWConv捕捉局部信息。右:通过线性投影层获取Q/K/V令牌后,我们通过轻量级的小内核卷积聚合附近令牌来生成多尺度令牌。对多尺度令牌应用ReLU线性注意力,将输出连接并输入最终的线性投影层进行特征融合。
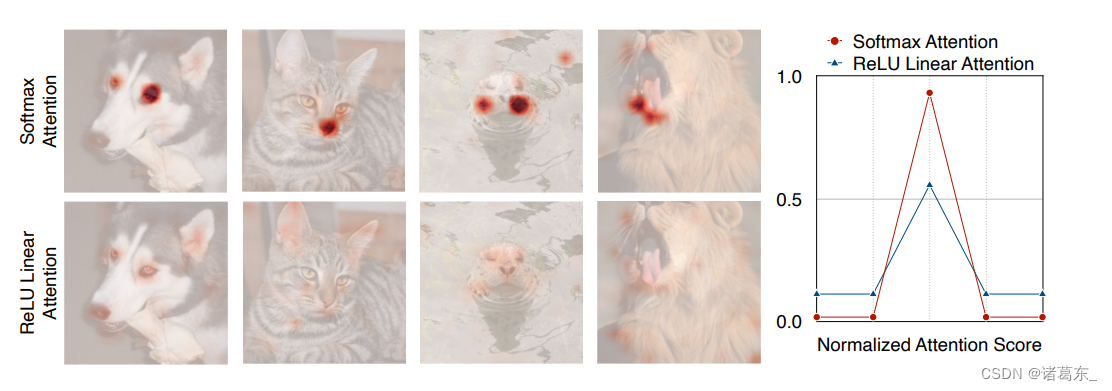
图3: Softmax注意力和ReLU线性注意力。与softmax注意力不同,由于缺乏非线性相似性函数,ReLU线性注意力无法产生尖锐的注意力分布。因此,它的局部信息提取能力弱于softmax注意力。
通过ReLU线性注意力实现全局感受野。给定输入x ∈ R N×f ,softmax注意力的广义形式可以写为:
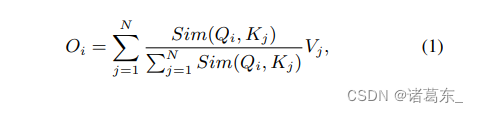
其中,Q = xWQ,K = xWK,V = xWV,且 WQ/WK/WV ∈ Rf×d是可学习的线性投影矩阵。Oi 表示矩阵 O 的第 i 行。Sim(·, ·) 是相似性函数。当使用相似性函数 Sim(Q, K) = exp( QKT/ √d ) 时,公式 (1) 变成了原始的 softmax 注意力 [8]。
除了使用 exp(QKT/ √d) 这种相似度函数,我们还可以使用其他的相似度函数。在这项工作中,我们使用 ReLU 线性注意力 [12] 来实现全局感受域和线性计算复杂度。在 ReLU 线性注意力中,相似度函数的定义如下:
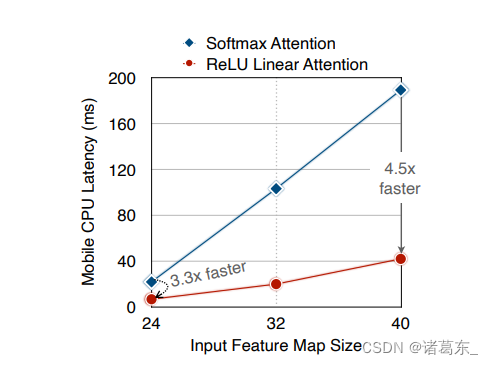
图4:Softmax注意力和ReLU线性注意力的延迟对比。由于去除了硬件不友好的操作(例如softmax),ReLU线性注意力比相似的计算下的softmax注意力快3.3-4.5倍,延迟方面表现更好。延迟是在搭配了TensorFlow-Lite、批次大小为1、浮点数精度为fp32的Qualcomm Snapdragon 855 CPU上测量得出的。
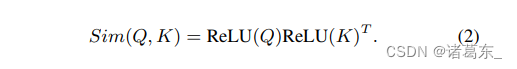
通过 Sim(Q, K) = ReLU(Q)ReLU(K)T,公式(1)可以被重写为:

然后,我们可以利用矩阵乘法的可结合性,将计算复杂度和内存占用从二次降低到线性,同时不改变其功能:

如公式(3)所示,我们只需要计算一次 (
∑
j
=
1
N
\sum_{j=1}^{N}
∑j=1NReLU(Kj)T Vj) ∈ Rd×d 和 (
∑
j
=
1
N
\sum_{j=1}^{N}
∑j=1NReLU(Kj)T) ∈ Rd×1,然后可以在每个查询中重复使用它们,因此只需要 O(N) 的计算成本和 O(N) 的内存。ReLU线性注意力的另一个重要优点是它不涉及像softmax那样的硬件不友好的操作,使其在硬件上更高效。例如,图4显示了softmax注意力和ReLU线性注意力之间的延迟比较。在类似的计算下,ReLU线性注意力在移动CPU上比softmax注意力快得多。
讨论ReLU线性注意力网络的局限性。 尽管ReLU线性注意力网络在计算复杂度和硬件延迟方面优于softmax注意力网络,但是它也具有局限性。图3显示了softmax注意力网络和ReLU线性注意力网络的注意力图。由于缺乏非线性相似性函数,ReLU线性注意力网络无法生成集中的注意力图,因此在捕捉局部信息方面效果较弱。
为了缓解它的局限性,我们提出使用卷积来增强ReLU线性注意力网络。具体而言,我们在每个FFN层中插入了一个深度卷积层。图2(左侧)展示了所得到的构建模块的概述,其中ReLU线性注意力网络捕捉上下文信息,而FFN+DWConv则捕捉局部信息。
此外,我们提出对附近的Q/K/V tokens进行信息聚合,以获取多尺度tokens,从而增强ReLU线性注意力网络的多尺度学习能力。这个信息聚合过程对于每个头中的每个Q、K和V是独立的。我们只使用小卷积核的深度可分离卷积 [18] 来进行信息聚合,以避免损害硬件效率。在实际实现中,独立执行这些聚合操作在GPU上效率低下。因此,我们利用分组卷积来减少总操作数。具体来说,所有DWConvs被融合成一个单独的DWConv,而所有1x1 Convs被合并成一个1x1分组卷积(图2右侧),其中组数为3×#heads,每个组中的通道数为d。在获取了多尺度tokens之后,我们对它们执行ReLU线性注意力,以提取多尺度全局特征。最后,我们沿着头维度连接这些特征,并将它们馈送到最终线性投影层中以融合这些特征。
2.2. 高效ViT架构
我们基于提出的多尺度线性注意力模块构建了一系列新的视觉变换器模型。核心构建块(称为“EfficientViT模块”)如图2(左)所示。EfficientViT的宏观架构如图5所示,我们采用标准的主干-头部/编码器-解码器架构设计。
• EfficientViT的主干遵循标准设计,包括输入干道和四个阶段,特征图大小逐渐减小,通道数量逐渐增加。我们将EfficientViT模块插入第三个和第四个阶段。对于降采样,我们使用带有步长2的MBConv。
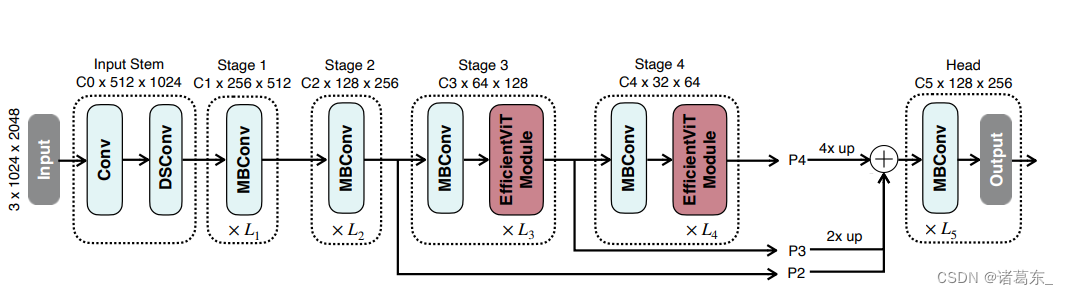
图5:EfficientViT的宏观架构。我们采用标准的主干-头部/编码器-解码器设计。在主干的第三个和第四个阶段中插入我们的EfficientViT模块。按照通用做法,我们将最后三个阶段(P2、P3和P4)的特征提供给头部。为了简单和高效,我们使用加法将这些特征融合起来。我们采用了一个简单的头部设计,包括若干MBConv块和输出层。
• 头部。P2、P3和P4分别表示第2、3和第4阶段的输出,形成一个特征金字塔。为了简化和提高效率,我们使用1x1卷积和标准的上采样操作(例如双线性/双三次上采样)来匹配它们的空间和通道大小,并通过加法将它们融合起来。由于我们的主干已经具有强大的上下文信息提取能力,我们采用了一个简单的头部设计,包括若干MBConv块和输出层(即预测和上采样)。在实验中,我们经验性地发现这种简单的头部设计足以达到SOTA性能。
除了密集预测之外,我们的模型还可以通过将主干与特定任务的头部相结合,应用于其他视觉任务,比如图像分类任务。
根据相同的宏观架构,我们设计了一系列具有不同大小的模型,以满足各种效率约束。分别命名为EfficientViT-B0、EfficientViT-B1、EfficientViT-B2和EfficientViT-B3。此外,我们还针对云平台设计了EfficientViT-L系列。这些模型的详细配置可以在我们的官方GitHub代码库中找到。
3. 实验
3.1. 实验设置
数据集。 我们对EfficientViT在三个代表性的高分辨率密集预测任务上进行了评估,包括语义分割、超分辨率和任意物体分割。
对于语义分割,我们使用了两个流行的基准数据集:Cityscapes [24] 和 ADE20K [25]。此外,我们还在两种超分辨率设置下评估了EfficientViT:轻量级超分辨率(SR)和高分辨率SR。我们在DIV2K [26] 上训练模型进行轻量级SR,并在BSD100 [27] 上测试。对于高分辨率SR,我们在FFHQ [28] 的前3000个训练图像上训练模型,并在FFHQ2的前500个验证图像上进行测试。
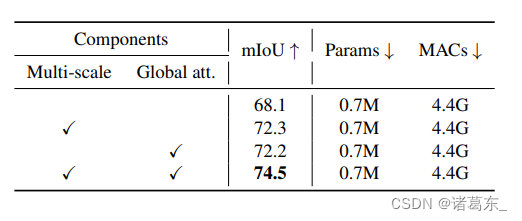
表1:消融研究。在1024x2048的输入分辨率下,我们在Cityscapes上测量mIoU和MACs。我们调整模型的宽度,使它们具有相同的MACs。多尺度学习和全局感受野对于获得良好的语义分割性能至关重要。
除了密集预测,我们还使用ImageNet数据集 [29]研究了EfficientViT在图像分类方面的有效性。
延迟测量。 我们在Qualcomm Snapdragon 8Gen1 CPU上使用Tensorflow Lite3、批量大小1和fp32测量移动延迟。我们使用TensorRT4和fp16来测量边缘GPU和云端GPU上的延迟。数据传输时间包含在报告的延迟/吞吐量结果中。
实现细节。 我们使用Pytorch [30]实现我们的模型,并在GPU上进行训练。我们使用AdamW优化器和余弦学习率衰减来训练我们的模型。对于多尺度线性注意力,我们使用两个分支的设计,以在性能和效率之间取得最佳平衡,其中5x5的相邻标记被聚合以生成多尺度标记。
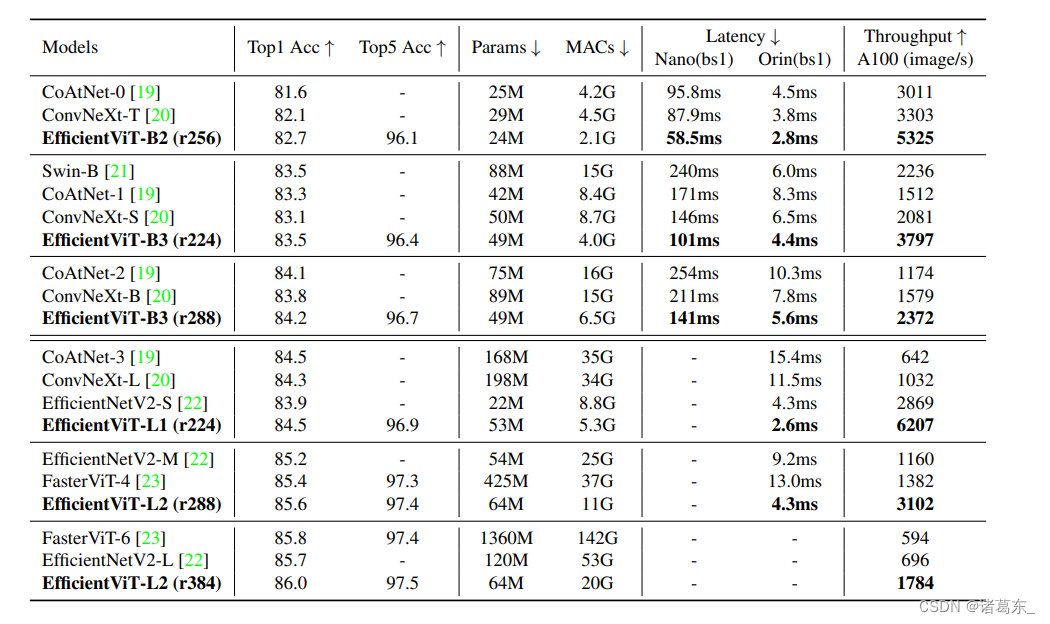
表2:在ImageNet分类任务上的主干性能。'r224'表示输入分辨率为224x224。'bs1'表示延迟是使用批量大小1进行测量的。
对于语义分割实验,我们使用平均交并比(mIoU)作为我们的评估指标。主干使用在ImageNet上预训练的权重进行初始化,头部随机初始化,遵循常见做法。
对于超分辨率,我们使用PSNR和SSIM作为评估指标,使用Y通道进行计算,与之前的工作[31]相同。模型使用随机初始化进行训练。
3.2. 削减实验
EfficientViT模块的有效性。 我们在Cityscapes上进行削减实验,研究我们的EfficientViT模块的两个关键设计组件,即多尺度学习和全局注意力的有效性。为了消除预训练的影响,我们所有的模型都是从随机初始化开始训练的。此外,我们重新调整模型的宽度,使它们具有相同的#MACs(乘加操作的数量)。结果总结在表1中。我们可以看到,去除全局注意力或多尺度学习中的任意一个都将显著影响性能。这表明它们都对在性能和效率之间实现更好的权衡是至关重要的。
在ImageNet上对骨干网络性能的评估。 为了了解EfficientViT的骨干网络在图像分类中的有效性,我们按照标准训练策略在ImageNet上训练我们的模型。我们总结了结果,并在表2中将我们的模型与SOTA图像分类模型进行了比较。
尽管EfficientViT是为高分辨率密集预测而设计的,但在ImageNet分类任务上取得了非常竞争的性能。特别是,EfficientViT-L2-r384在ImageNet上获得了86.0的top1准确率,相比EfficientNetV2-L提高了0.3准确率,并在A100 GPU上实现了2.6倍的加速。
3.3. 语义分割
语义分割,也称为密集预测或像素级分类,是一项计算机视觉任务,旨在为图像中的每个像素分配语义标签。它通过将图像分割成不同的区域,对应于不同的对象类别或语义概念,使对视觉场景的理解更为详细。
EfficientViT在语义分割任务中也展现出了出色的性能。通过利用多尺度学习和全局注意力组件,模块实现了精确且高效的分割结果。
我们在Cityscapes数据集上进行了实验,以评估EfficientViT模块在语义分割中的有效性。结果表明,相比先前的SOTA语义分割模型,EfficientViT实现了显著的效率提升,而不会牺牲性能。具体来说,与SegFormer相比,在边缘GPU(Jetson AGX Orin)上,EfficientViT实现了高达13倍的MACs节省和8.8倍的延迟降低,并获得了更高的mIoU。与SegNeXt相比,在边缘GPU(Jetson AGX Orin)上,EfficientViT提供高达2.0倍的MACs减少和3.8倍的加速,同时保持更高的mIoU。在A100 GPU上,EfficientViT的吞吐量比SegNeXt高出高达3.9倍,比SegFormer高出10.2倍,同时实现相同或更高的mIoU。具有类似的计算成本,EfficientViT也比之前的SOTA模型实现了显著的性能提升。例如,EfficientViT-B3比SegFormer-B1具有更低的MACs并实现了+4.5 mIoU的提升。
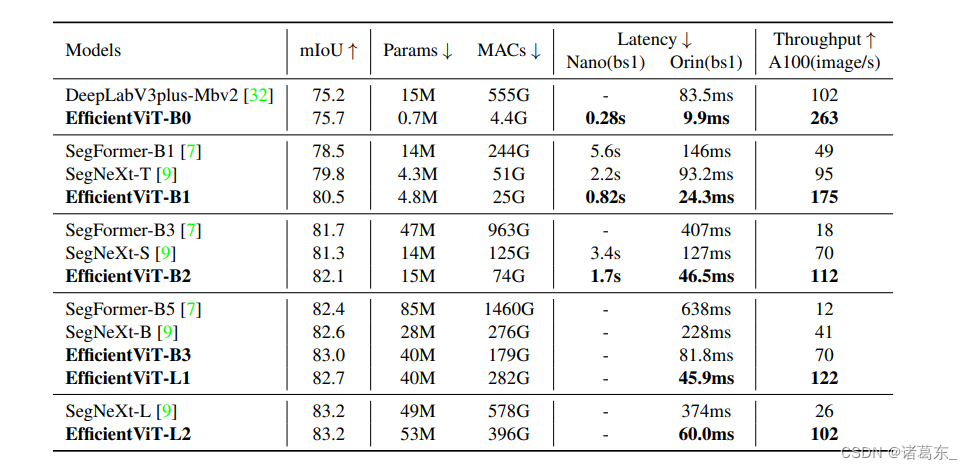
表格3:与Cityscapes数据集上SOTA语义分割模型的比较。所有模型的输入分辨率为1024x2048。具有相似mIoU的模型被分组以进行效率比较
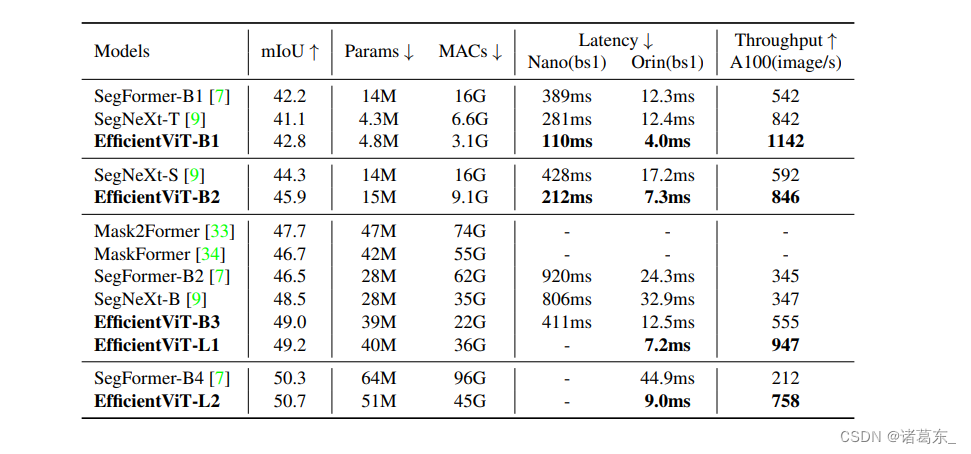
表格4:与ADE20K数据集上SOTA语义分割模型的比较。图像的较短边被调整为512,这是常见的做法。
除了定量结果外,我们还以定性方式在Cityscapes上对EfficientViT和基准模型进行可视化。结果如图6所示。我们可以发现,相比基准模型,EfficientViT能够更好地识别边界和小物体,同时在GPU上实现较低的延迟。
ADE20K。 表格4总结了EfficientViT和SOTA语义分割模型在ADE20K上的比较结果。与Cityscapes类似,我们可以看到EfficientViT在ADE20K上也实现了显著的效率提升。例如,EfficientViT-B1相比SegFormer-B1提高了0.6 mIoU,同时提供了5.2倍的MACs降低和高达3.5倍的GPU延迟降低。EfficientViT-B2相比SegNeXt-S提高了1.6 mIoU,需要的计算成本减少了1.8倍,Jetson AGX Orin GPU上的运行速度也加快了2.4倍。
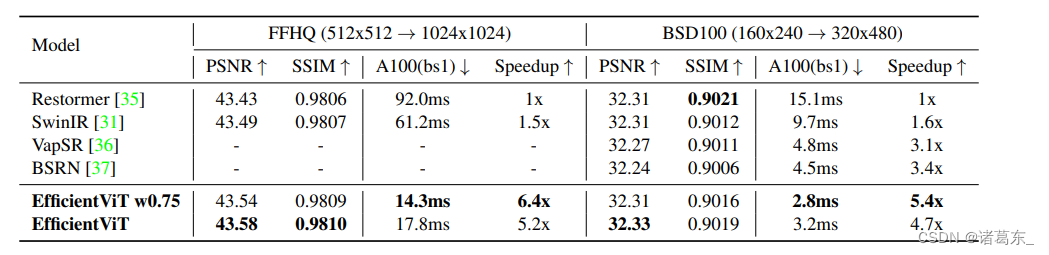
表格5:与SOTA超分辨率模型的比较
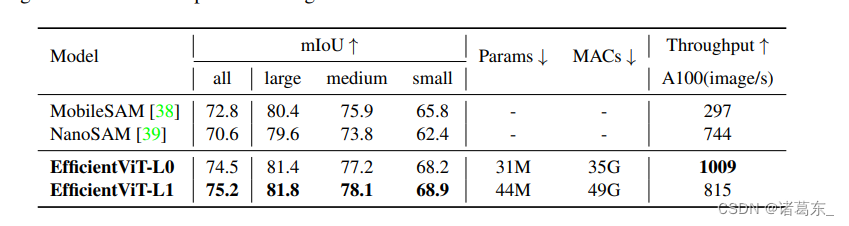
表格6:COCO val2017上的零样本图像分割结果。我们使用真实的物体边界框注释来提示SAM模型预测分割掩码。

图6:Cityscapes数据集上的定性结果展示
3.4 超分辨率
表格5展示了EfficientViT与当前最先进的ViT-based超分辨率方法(SwinIR [31]和Restormer [35])以及CNN-based超分辨率方法(VapSR [36]和BSRN [37])的比较结果。EfficientViT在延迟性能方面提供了比所有比较方法更好的平衡。
在轻量级超分辨率方面,EfficientViT在BSD100数据集上提供高达0.09dB的PSNR增益,与当前最先进的CNN-based超分辨率方法相比,GPU延迟相同或更低。与最先进的ViT-based超分辨率方法相比,EfficientViT在GPU上提供高达5.4倍的加速,并在BSD100数据集上保持相同的PSNR。
在高分辨率超分辨率任务中,EfficientViT相较于之前的基于ViT的超分辨率方法的优势更加显著。与Restormer相比,EfficientViT在GPU上实现了高达6.4倍的加速,并在FFHQ数据集上提供了0.11dB的PSNR增益。
3.5. 分割任何东西
为了简化起见,我们使用预训练的SAM-ViT-H [13]提取的图像嵌入作为训练目标来训练我们的图像编码器。我们使用与SAM-ViT-H [13]相同的提示编码器和掩码解码器。
在表6中,我们将EfficientViT与之前的高效Segment Anything模型进行了比较,包括MobileSAM和NanoSAM。EfficientViT在COCO val2017数据集上获得了更高的零示例图像分割结果,并且比MobileSAM和NanoSAM运行速度更快。
此外,我们在图7、图8和图9中可视化了EfficientViT Segment Anything模型的输出。我们可以看到,EfficientViT在A100 GPU上的吞吐量显著提高,同时实现了与ViT-H [13]相似的零示例图像分割质量。
4. 相关工作
像素级稠密预测(High-Resolution Dense Prediction) 像素级稠密预测的目的是在给定输入图像的情况下为每个像素生成预测结果。它可以被视为从对整个图像的预测扩展到对每个像素进行预测的图像分类方法的拓展。过去已经进行了大量研究,以提高基于CNN的高分辨率像素级稠密预测模型的性能 [1, 2, 3, 4, 5, 6]。

图 7: 使用边界框作为提示的“Segment Anything”模型的可视化展示

图 8: 使用点作为提示的“Segment Anything”模型的可视化展示
此外,还有一些工作致力于提高高分辨率像素级稠密预测模型的效率 [40,41,42,43]。虽然这些模型提供了良好的效率,但它们的性能远远落后于最先进的高分辨率像素级稠密预测模型。
与这些工作相比,我们的模型通过启用全局感受野和轻量级操作的多尺度学习,提供了更好的性能和效率之间的权衡。
高效的视觉Transformer。 虽然ViT在高计算区域表现出色,但在低计算区域通常劣于以前的高效CNN模型[44,45,46,47]。为了弥合差距,MobileViT [48]提出了通过用Transformer进行全局处理来替代卷积中的局部处理,以将CNN和ViT的优势相结合。MobileFormer [49]提议在MobileNet和Transformer之间引入一个双向桥梁来进行特征融合。NASViT [50]则提出利用神经架构搜索来搜索高效的ViT架构。
然而,这些模型主要关注图像分类,并且仍然依赖于具有二次计算复杂度的softmax注意力机制,因此不适用于高分辨率的像素级稠密预测任务。
高效深度学习。 我们的工作也与高效深度学习相关,该领域旨在提高深度神经网络的效率,以便我们可以将其部署在资源受限的硬件平台上,例如手机和物联网设备。高效深度学习中的典型技术包括网络剪枝[51, 52, 53],量化[54],高效模型架构设计[18, 55]和训练技术[56, 57, 58]。除手动设计外,许多最近的工作使用自动机器学习技术[59, 60, 61]来自动设计[46],剪枝[62]和量化[63]神经网络。

图9: 使用Segment Anything模型自动生成掩码
5. 结论
在本工作中,我们研究了高分辨率密集预测的高效架构设计。我们引入了一个轻量级的多尺度注意力模块,它同时实现了全局感受野和轻量级硬件高效操作的多尺度学习,从而在各种硬件设备上提供了显著的加速,而不会损失性能,超过了当前最先进的高分辨率密集预测模型。对于未来的工作,我们将探索将EfficientViT应用到其他视觉任务,并进一步扩展我们的EfficientViT模型的规模。
致谢
我们感谢MIT-IBM Watson AI实验室、MIT AI硬件计划、亚马逊和MIT Science Hub、高通创新奖学金、美国国家科学基金会对本研究的支持。
参考文献
[1] Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla.
Segnet: A deep convolutional encoder-decoder architecture
for image segmentation. IEEE transactions on pattern analysis and machine intelligence, 39(12):2481–2495, 2017. 1,
9
[2] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. Unet: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted
Intervention–MICCAI 2015: 18th International Conference,
Munich, Germany, October 5-9, 2015, Proceedings, Part III
18, pages 234–241. Springer, 2015. 1, 9
[3] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos,
Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image
segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern
analysis and machine intelligence, 40(4):834–848, 2017. 1,
9
[4] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang
Wang, and Jiaya Jia. Pyramid scene parsing network. In
Proceedings of the IEEE conference on computer vision and
pattern recognition, pages 2881–2890, 2017. 1, 9
[5] Yuhui Yuan, Xilin Chen, and Jingdong Wang. Objectcontextual representations for semantic segmentation. In
European conference on computer vision, pages 173–190.
Springer, 2020. 1, 9
[6] Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang,
Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui
Tan, Xinggang Wang, et al. Deep high-resolution representation learning for visual recognition. IEEE transactions
on pattern analysis and machine intelligence, 43(10):3349–
3364, 2020. 1, 9
[7] Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar,
Jose M Alvarez, and Ping Luo. Segformer: Simple and
efficient design for semantic segmentation with transformers. Advances in Neural Information Processing Systems,
34, 2021. 1, 7
[8] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia
Polosukhin. Attention is all you need. In NeurIPS, 2017. 1,
2, 3
[9] Meng-Hao Guo, Cheng-Ze Lu, Qibin Hou, Zheng-Ning Liu,
Ming-Ming Cheng, and Shi min Hu. Segnext: Rethinking convolutional attention design for semantic segmentation. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave,
and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. 1, 7
[10] Xiaohan Ding, Xiangyu Zhang, Yizhuang Zhou, Jungong
Han, Guiguang Ding, and Jian Sun. Scaling up your kernels
to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE conference on computer vision and pattern
recognition, 2022. 1
[11] Yihan Wang, Muyang Li, Han Cai, Wei-Ming Chen, and
Song Han. Lite pose: Efficient architecture design for 2d
human pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2022. 1
[12] Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and
Franc¸ois Fleuret. Transformers are rnns: Fast autoregressive
transformers with linear attention. In International Conference on Machine Learning, pages 5156–5165. PMLR, 2020.
1, 2, 3
[13] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao,
Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023. 2, 8
[14] Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao
Zhang, and Judy Hoffman. Hydra attention: Efficient attention with many heads. In Computer Vision–ECCV 2022
Workshops: Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part VII, pages 35–49. Springer, 2023. 2
[15] Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter
Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser,
et al. Rethinking attention with performers. arXiv preprint
arXiv:2009.14794, 2020. 2
[16] Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi,
and Hongsheng Li. Efficient attention: Attention with linear complexities. In Proceedings of the IEEE/CVF winter
conference on applications of computer vision, pages 3531–
3539, 2021. 2
[17] Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and
Hao Ma. Linformer: Self-attention with linear complexity.
arXiv preprint arXiv:2006.04768, 2020. 2
[18] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry
Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv
preprint arXiv:1704.04861, 2017. 4, 9
[19] Zihang Dai, Hanxiao Liu, Quoc V Le, and Mingxing Tan.
Coatnet: Marrying convolution and attention for all data
sizes. Advances in Neural Information Processing Systems,
34:3965–3977, 2021. 6
[20] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the
2020s. In Proceedings of the IEEE conference on computer
vision and pattern recognition, 2022. 6
[21] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng
Zhang, Stephen Lin, and Baining Guo. Swin transformer:
Hierarchical vision transformer using shifted windows. In
Proceedings of the IEEE/CVF International Conference on
Computer Vision, pages 10012–10022, 2021. 6
[22] Mingxing Tan and Quoc Le. Efficientnetv2: Smaller models
and faster training. In International Conference on Machine
Learning, pages 10096–10106. PMLR, 2021. 6
[23] Ali Hatamizadeh, Greg Heinrich, Hongxu Yin, Andrew Tao,
Jose M Alvarez, Jan Kautz, and Pavlo Molchanov. Fastervit:
Fast vision transformers with hierarchical attention. arXiv
preprint arXiv:2306.06189, 2023. 6
[24] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo
Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe
Franke, Stefan Roth, and Bernt Schiele. The cityscapes
dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern
recognition, pages 3213–3223, 2016. 5
[25] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela
Barriuso, and Antonio Torralba. Scene parsing through
ade20k dataset. In Proceedings of the IEEE conference on
computer vision and pattern recognition, pages 633–641,
2017. 5
[26] Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge
on single image super-resolution: Dataset and study. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 126–135, 2017. 5
[27] David Martin, Charless Fowlkes, Doron Tal, and Jitendra
Malik. A database of human segmented natural images
and its application to evaluating segmentation algorithms and
measuring ecological statistics. In Proceedings Eighth IEEE
International Conference on Computer Vision. ICCV 2001,
volume 2, pages 416–423. IEEE, 2001. 5
[28] Tero Karras, Samuli Laine, and Timo Aila. A style-based
generator architecture for generative adversarial networks.
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019. 5
[29] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li,
and Li Fei-Fei. Imagenet: A large-scale hierarchical image
database. In CVPR, 2009. 5
[30] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer,
James Bradbury, Gregory Chanan, Trevor Killeen, Zeming
Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
5
[31] Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc
Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1833–1844,
2021. 6, 8
[32] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian
Schroff, and Hartwig Adam. Encoder-decoder with atrous
separable convolution for semantic image segmentation. In
Proceedings of the European conference on computer vision
(ECCV), pages 801–818, 2018. 7
[33] Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask
transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition, pages 1290–1299, 2022. 7
[34] Bowen Cheng, Alex Schwing, and Alexander Kirillov. Perpixel classification is not all you need for semantic segmentation. Advances in Neural Information Processing Systems,
34, 2021. 7
[35] Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang.
Restormer: Efficient transformer for high-resolution image
restoration. In Proceedings of the IEEE/CVF Conference
on Computer Vision and Pattern Recognition, pages 5728–
5739, 2022. 8
[36] Lin Zhou, Haoming Cai, Jinjin Gu, Zheyuan Li, Yingqi Liu,
Xiangyu Chen, Yu Qiao, and Chao Dong. Efficient image
super-resolution using vast-receptive-field attention. arXiv
preprint arXiv:2210.05960, 2022. 8
[37] Zheyuan Li, Yingqi Liu, Xiangyu Chen, Haoming Cai, Jinjin
Gu, Yu Qiao, and Chao Dong. Blueprint separable residual
network for efficient image super-resolution. In Proceedings
of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 833–843, 2022. 8
[38] Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim,
Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong.
Faster segment anything: Towards lightweight sam for mobile applications. arXiv preprint arXiv:2306.14289, 2023.
8
[39] NVIDIA-AI-IOT. Nanosam. https://github.com/
NVIDIA-AI-IOT/nanosam, 2023. 8
[40] Hengshuang Zhao, Xiaojuan Qi, Xiaoyong Shen, Jianping
Shi, and Jiaya Jia. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European conference on computer vision (ECCV), pages 405–
420, 2018. 9
[41] Rudra PK Poudel, Stephan Liwicki, and Roberto Cipolla.
Fast-scnn: Fast semantic segmentation network. arXiv
preprint arXiv:1902.04502, 2019. 9
[42] Hanchao Li, Pengfei Xiong, Haoqiang Fan, and Jian Sun.
Dfanet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the IEEE/CVF conference on
computer vision and pattern recognition, pages 9522–9531,
2019. 9
[43] Changqian Yu, Jingbo Wang, Chao Peng, Changxin Gao,
Gang Yu, and Nong Sang. Bisenet: Bilateral segmentation
network for real-time semantic segmentation. In Proceedings of the European conference on computer vision (ECCV),
pages 325–341, 2018. 9
[44] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model
scaling for convolutional neural networks. In ICML, 2019. 9
[45] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh
Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu,
Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. In ICCV, 2019. 9
[46] Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and
Song Han. Once for all: Train one network and specialize it
for efficient deployment. In ICLR, 2020. 9
[47] Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing
Xu, and Chang Xu. Ghostnet: More features from cheap
operations. In Proceedings of the IEEE/CVF conference on
computer vision and pattern recognition, pages 1580–1589,
2020. 9
[48] Sachin Mehta and Mohammad Rastegari. Mobilevit: Lightweight, general-purpose, and mobile-friendly vision transformer. In International Conference on Learning Representations, 2022. 9
[49] Yinpeng Chen, Xiyang Dai, Dongdong Chen, Mengchen
Liu, Xiaoyi Dong, Lu Yuan, and Zicheng Liu. Mobileformer: Bridging mobilenet and transformer. In Proceedings of the IEEE conference on computer vision and pattern
recognition, 2022. 9
[50] Chengyue Gong, Dilin Wang, Meng Li, Xinlei Chen,
Zhicheng Yan, Yuandong Tian, qiang liu, and Vikas Chandra. NASVit: Neural architecture search for efficient vision
transformers with gradient conflict aware supernet training.
In International Conference on Learning Representations,
2022. 9
[51] Song Han, Jeff Pool, John Tran, and William Dally. Learning
both weights and connections for efficient neural network. In
NeurIPS, 2015. 9
[52] Yihui He, Xiangyu Zhang, and Jian Sun. Channel pruning
for accelerating very deep neural networks. In ICCV, 2017.
9
[53] Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang,
Shoumeng Yan, and Changshui Zhang. Learning efficient
convolutional networks through network slimming. In ICCV,
2017. 9
[54] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning,
trained quantization and huffman coding. In ICLR, 2016. 9
[55] Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun.
Shufflenet v2: Practical guidelines for efficient cnn architecture design. In ECCV, 2018. 9
[56] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint
arXiv:1503.02531, 2015. 9
[57] Han Cai, Chuang Gan, Ji Lin, and Song Han. Network augmentation for tiny deep learning. arXiv preprint
arXiv:2110.08890, 2021. 9
[58] Han Cai, Chuang Gan, Ligeng Zhu, and Song Han. Tinytl:
Reduce memory, not parameters for efficient on-device
learning. Advances in Neural Information Processing Systems, 33:11285–11297, 2020. 9
[59] Barret Zoph and Quoc V Le. Neural architecture search with
reinforcement learning. In ICLR, 2017. 9
[60] Han Cai, Tianyao Chen, Weinan Zhang, Yong Yu, and Jun
Wang. Efficient architecture search by network transformation. In AAAI, 2018. 9
[61] Han Cai, Ligeng Zhu, and Song Han. ProxylessNAS: Direct
neural architecture search on target task and hardware. In
ICLR, 2019. 9
[62] Yihui He, Ji Lin, Zhijian Liu, Hanrui Wang, Li-Jia Li, and
Song Han. Amc: Automl for model compression and acceleration on mobile devices. In ECCV, 2018. 9
[63] Tianzhe Wang, Kuan Wang, Han Cai, Ji Lin, Zhijian Liu,
Hanrui Wang, Yujun Lin, and Song Han. Apq: Joint search
for network architecture, pruning and quantization policy. In
CVPR, 2020. 9

















 1958
1958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









