









文章目录
一、Elasticsearch集群
1、Elasticsearch集群概念
- 当索引足够大时,需要建立ES集群,此时需要将索引拆分成多分,分别放入不同的服务器中,几台服务器维护同一个索引。每一台服务器为一个节点,每一台服务器中的数据称为一个分片。
- 如果某个节点故障,则会造成集群崩溃,所以每个节点的分片往往还会创建副本,存放在其他节点中,此时一个节点崩溃就不会影响整个集群的正常运行了。即分片和该分片的副本不会存放在同一个节点上。
- 1)节点(node):一个节点是集群中的一台服务器,是集群的一部分。它存储数据,参与集群的索引和搜索功能。集群中有一个主节点,主节点通过ES集群内部选举产生。
2)集群(cluster):一组节点组织在一起称为一个集群,它们共同持有整个的数据,并一起提供索引和搜索功能。
3)分片(shards):ES可以把完整的索引分成多个分片,分别存储在不同的节点上。
4)副本(replicas):ES可以为每个分片创建副本,提高查询效率,保证在分片数据丢失后的恢复。
分片数量只能在索引创建时指定,索引创建后不能再更改分片数量,但可以改变副本的数量。
2、Elasticsearch集群安装
-
下载Elasticsearch7.17.7版本:
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.7-linux-x86_64.tar.gz
因为8.6.2版本,与springboot整合ES的版本不一致无法解析响应正文,而且7.17.7也是比较新的 -
将该压缩包通过Mobax终端上传到目录/中,进入到目录/中,然后解压到目录/usr/local/中:
tar -zxvf elasticsearch-7.17.7-linux-x86_64.tar.gz -C /usr/local/ -
安装ik分词器到该ES服务中:
1)下载IKAnalyzer:https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.7/elasticsearch-analysis-ik-7.17.7.zip
2)通过mobax上传至虚拟机的目录/,进入到目录/中,然后进行解压缩:unzip elasticsearch-analysis-ik-7.17.7.zip -d /usr/local/elasticsearch-7.17.7/plugins/analysis-ik -
安装拼音分词器到该ES服务中:
1)下载拼音分词器:https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.17.7/elasticsearch-analysis-pinyin-7.17.7.zip
2)通过mobax上传到虚拟机的/目录,进入到目录/中,解压到elasticsearch的plugins/analysis-pinyin目录下:unzip elasticsearch-analysis-pinyin-7.17.7.zip -d /usr/local/elasticsearch-7.17.7/plugins/analysis-pinyin -
给es用取得该文件件的权限:
chown -R es:es /usr/local/elasticsearch-7.17.7 -
修改配置文件:
vim /usr/local/elasticsearch-7.17.7/config/elasticsearch.yml,添加如下#集群名称,保证唯一 cluster.name: my_elasticsearch #节点名称,必须不一样 node.name: node1 #可以访问该节点的ip地址 network.host: 0.0.0.0 #该节点服务端口号 http.port: 9200 #集群间通信端口号 transport.tcp.port: 9300 #候选主节点的设备地址 discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"] #候选主节点的节点名 cluster.initial_master_nodes: ["node1","node2","node3"] #关闭安全认证,才能访问es xpack.security.enabled: false xpack.security.http.ssl: enabled: false -
将elasticsearch-7.17.7文件夹修改名字为myes1:
mv /usr/local/elasticsearch-7.17.7/ /usr/local/myes1 -
切换为es用户:
su es -
后台启动第一个ES节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes1/bin/elasticsearch -d,默认占用4G,只是为了搭建集群而搭建集群,所以设置512m的内存。 -
测试ES服务是否正常启动:
curl 127.0.0.1:9200 -
切换为root用户:
su root -
进入到目录/中,然后将ES压缩包解压到目录/usr/local/中:
tar -zxvf elasticsearch-7.17.7-linux-x86_64.tar.gz -C /usr/local/ -
进入到目录/中,然后将ik分词器压缩包进行解压缩:
unzip elasticsearch-analysis-ik-7.17.7.zip -d /usr/local/elasticsearch-7.17.7/plugins/analysis-ik -
进入到目录/中,然后将pinyin分词器解压到elasticsearch的plugins/analysis-pinyin目录下:
unzip elasticsearch-analysis-pinyin-7.17.7.zip -d /usr/local/elasticsearch-7.17.7/plugins/analysis-pinyin -
给es用取得该文件件的权限:
chown -R es:es /usr/local/elasticsearch-7.17.7 -
修改配置文件:
vim /usr/local/elasticsearch-7.17.7/config/elasticsearch.yml,添加如下#集群名称,保证唯一 cluster.name: my_elasticsearch #节点名称,必须不一样 node.name: node2 #可以访问该节点的ip地址 network.host: 0.0.0.0 #该节点服务端口号 http.port: 9201 #集群间通信端口号 transport.tcp.port: 9301 #候选主节点的设备地址 discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"] #候选主节点的节点名 cluster.initial_master_nodes: ["node1","node2","node3"] #关闭安全认证,才能访问es xpack.security.enabled: false xpack.security.http.ssl: enabled: false -
将elasticsearch-7.17.7文件夹修改名字为myes2:
mv /usr/local/elasticsearch-7.17.7/ /usr/local/myes2 -
进入到目录/中,然后将ES压缩包解压到目录/usr/local/中:
tar -zxvf elasticsearch-7.17.7-linux-x86_64.tar.gz -C /usr/local/ -
进入到目录/中,然后将ik分词器压缩包进行解压缩:
unzip elasticsearch-analysis-ik-7.17.7.zip -d /usr/local/elasticsearch-7.17.7/plugins/analysis-ik -
进入到目录/中,然后将pinyin分词器解压到elasticsearch的plugins/analysis-pinyin目录下:
unzip elasticsearch-analysis-pinyin-7.17.7.zip -d /usr/local/elasticsearch-7.17.7/plugins/analysis-pinyin -
给es用取得该文件件的权限:
chown -R es:es /usr/local/elasticsearch-7.17.7 -
修改配置文件:
vim /usr/local/elasticsearch-7.17.7/config/elasticsearch.yml,添加如下#集群名称,保证唯一 cluster.name: my_elasticsearch #节点名称,必须不一样 node.name: node3 #可以访问该节点的ip地址 network.host: 0.0.0.0 #该节点服务端口号 http.port: 9202 #集群间通信端口号 transport.tcp.port: 9302 #候选主节点的设备地址 discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"] #候选主节点的节点名 cluster.initial_master_nodes: ["node1","node2","node3"] #关闭安全认证,才能访问es xpack.security.enabled: false xpack.security.http.ssl: enabled: false -
将elasticsearch-7.17.7文件夹修改名字为myes3:
mv /usr/local/elasticsearch-7.17.7/ /usr/local/myes3 -
切换为es用户:
su es -
后台启动第二个ES节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes2/bin/elasticsearch -d -
后台启动第三个ES节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes3/bin/elasticsearch -d -
查看集群是否搭建成功,访问浏览器:
http://192.168.126.24:9200/_cat/nodes -
查看集群的状态:
curl -uelastic:pwd -XGET "http://127.0.0.1:9200/_cluster/health?pretty"
3、安装Kibana
- 在Elasticsearch官网下载linux版的kibana:
https://artifacts.elastic.co/downloads/kibana/kibana-7.17.7-linux-x86_64.tar.gz - 切换到root用户:
su root - 在目录/中上传该压缩包,然后在目录/下解压缩到目录/usr/local/中:
tar -zxvf kibana-7.17.7-linux-x86_64.tar.gz -C /usr/local/ - 修改配置文件
1)进入到config目录下:cd /usr/local/kibana-7.17.7-linux-x86_64/config
2)修改配置文件:vim kibana.yml
3)添加kibana主机ip:server.host: "192.168.126.24"
添加Elasticsearch路径:elasticsearch.hosts: ["http://127.0.0.1:9200","http://127.0.0.1:9201","http://127.0.0.1:9202"] - 给es用户设置kibana目录权限:
chown -R es:es /usr/local/kibana-7.17.7-linux-x86_64/ - 切换到es用户:
su es - 确保启动Elasticsearch后,再启动kibana:
/usr/local/kibana-7.17.7-linux-x86_64/bin/kibana - 在浏览器中访问kibana:
http://192.168.126.24:5601/
4、测试集群状态
-
创建product索引
PUT /product { "settings": { "number_of_shards": 5, "number_of_replicas": 1 }, "mappings": { "properties": { "id": { "type": "integer", "store": true, "index": true }, "productName": { "type": "text", "store": true, "index": true }, "productDesc": { "type": "text", "store": true, "index": true } } } }“number_of_shards”: 5,即设置该索引的分片数量为5,“number_of_replicas”: 1,每个分片的副本数为1。
-
查看集群健康状态:
GET /_cat/health?v -
查看索引状态:
GET /_cat/indices?v -
查看分片状态:
GET /_cat/shards?v -
ES集群可以自动进行故障应对,即可以自动进行水平扩容。
-
改变每个分片的副本数
PUT /product/_settings { "number_of_replicas": 2 }分片数不能改变,但是分片的副本数可以改变。
二、Elasticsearch优化
1、磁盘选择
- Elasticsearch重度使用磁盘,磁盘的效率越高,Elasticsearch的执行效率就越高。
- 优化磁盘:
1)使用SSD(固态硬盘)。
2)使用RAID0模式,即将连续的数据分散到多个硬盘存储,这样可以并行进行IO操作。代价是一块硬盘发生故障就会引发系统故障。
3)不要使用远程挂载的存储。即在ES服务器中,而非ES服务器之外的存储。
2、分片策略
-
每个分片的底层都是一个Lucene索引,会消耗一定的系统资源。搜索请求需要命中索引中的所有分片,分片过多会降低搜索的性能。
-
分片原则:
1)每个分片占用的磁盘容量不超过ES的JVM的最大堆空间设置(一般设置不超过32G)。
2)分片数一般不超过节点数的三倍。
3)推迟分片分配:节点中断后集群会重新分配分片。但默认集群会等待一分钟来查看节点是否重新加入。可以设置等待的时长,减少分配的次数。PUT /product/_settings { "settings":{ "index.unassigned.node_left.delayed_timeout": "5m" } }
- 减少副本数量:进行写入操作时,需要把写入的数据都同步到副本中,副本越多写入的效率就越慢。进行大批量写入操作时可以先设置副本数为0,写入完成后再修改回正常的状态。
3、内存设置
- ES默认占用内存时4G,可以修改config/jvm.option文件设置ES的堆内存大小。
- 1)Xms表示堆内存的初始大小,Xmx表示可分配的最大内存。
2)Xmx和Xms的大小设置为相同时,可以减轻伸缩堆大小带来的压力。
3)Xmx和Xms不要超过物理内存的50%,因为ES内部的Lucene也要占据一部分物理内存。
4)Xmx和Xms不要超过32G,由于JAVA语言的特性,堆内存超过32G会浪费大量系统资源,所以在内存足够的情况下,最终都会采用设置为31G。
三、Elasticsearch实践
1、ES自动补全
-
自动补全对性能要求极高,ES不是通过倒排索引来实现的,所以需要将对应的查询字段类型设置为completion。
-
创建索引,添加自动补全字段
PUT /product2 { "mappings": { "properties": { "id": { "type": "integer", "store": true, "index": true }, "productName": { "type": "completion", "store": true, "index": true }, "productDesc": { "type": "text", "store": true, "index": true } } } } POST /product2/_doc { "id":1, "productName":"elasticsearch1", "productDesc":"elasticsearch1 is a good search engine" } POST /product2/_doc { "id":2, "productName":"elasticsearch2", "productDesc":"elasticsearch2 is a good search engine" } -
测试自动补全功能
GET /product2/_search { "suggest": { "prefix_suggestion": { "prefix": "elastic", "completion": { "field": "productName", "skip_duplicates": true, "size": 10 } } } }
2、创建索引
-
创建news索引
PUT /news { "settings": { "number_of_shards": 5, "number_of_replicas": 1, "analysis": { "analyzer": { "ik_pinyin": { "tokenizer": "ik_smart", "filter": "pinyin_filter" }, "tag_pinyin": { "tokenizer": "keyword", "filter": "pinyin_filter" } }, "filter": { "pinyin_filter": { "type": "pinyin", "keep_joined_full_pinyin":true, "keep_original": true, "remove_duplicated_term": true } } } }, "mappings": { "properties": { "id": { "type": "integer", "index": true }, "title": { "type": "text", "index": true, "analyzer": "ik_pinyin", "search_analyzer": "ik_smart" }, "content": { "type": "text", "index": true, "analyzer": "ik_pinyin", "search_analyzer": "ik_smart" }, "url": { "type": "keyword", "index": true }, "tags": { "type": "completion", "analyzer": "tag_pinyin" } } } }
3、安装logstash导入数据
-
通过命令行进入mysql中导入SQL文件:
source 绝对路径/xxx.sql; -
下载logstash:
https://artifacts.elastic.co/downloads/logstash/logstash-7.17.7-windows-x86_64.zip -
将logstash压缩包进行解压,在/logstash-7.17.7/config/目中下创建mysql.conf文件。写入以下脚本:
input { jdbc { jdbc_driver_library => "F:\SoftWare\mysql\mysql-connector-java-8.0.27.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql:///news" jdbc_user => "root" jdbc_password => "root" schedule => "* * * * *" jdbc_default_timezone => "Asia/Shanghai" statement => "SELECT * FROM news;" } } filter { mutate { split => {"tags" => ","} } } output { elasticsearch { hosts => ["192.168.126.24:9200","192.168.126.24:9201","192.168.126.24:9202"] index => "news" document_id => "%{id}" } } -
在解压路径/logstash-7.17.7下,打开cmd窗口,运行命令:
bin\logstash -f config\mysql.conf -
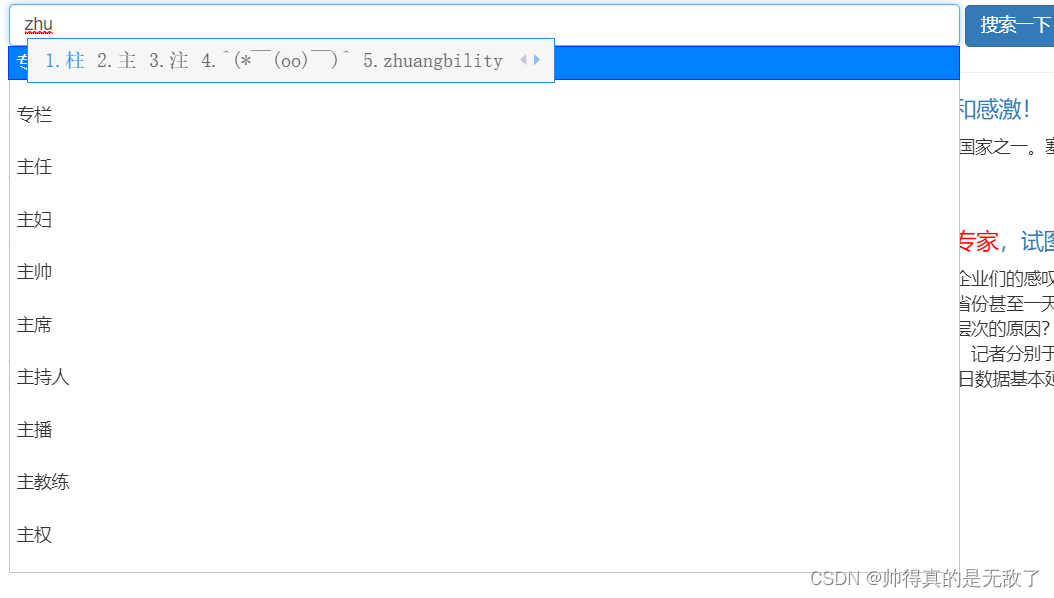
测试自动补齐功能
GET /news/_search { "suggest": { "YOUR_SUGGESTION": { "prefix": "zhu", //需要补全的关键词 "completion": { "field": "tags", "skip_duplicates": true,//去重复值 "size": 10 } } } }
4、项目搭建
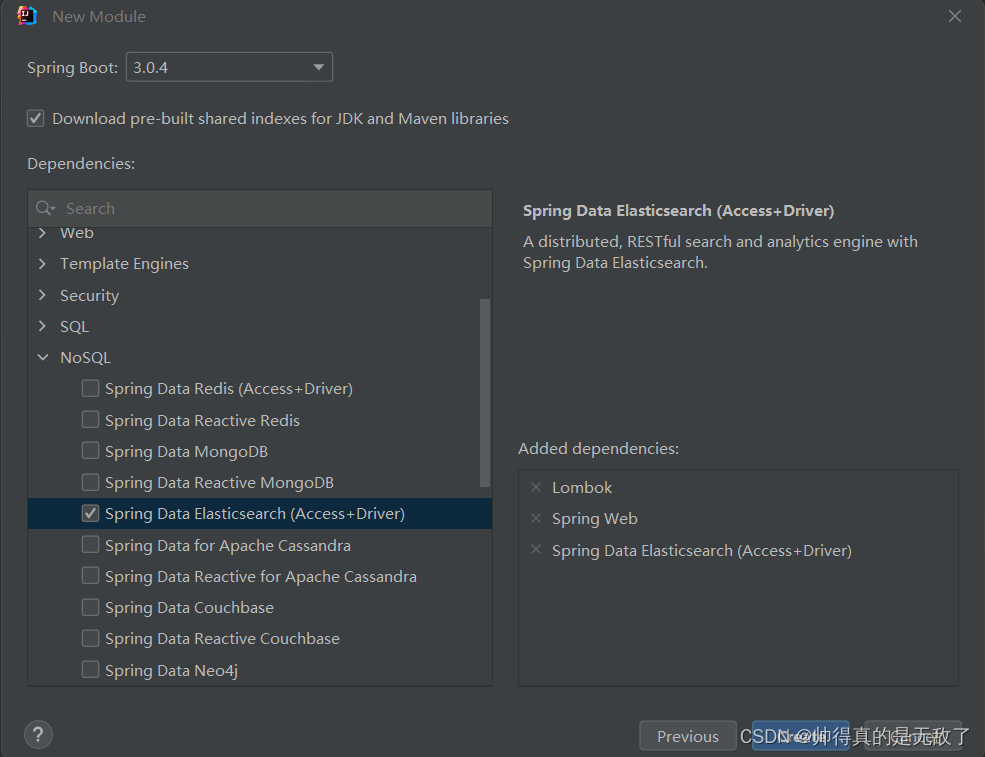
- 在myes空项目中,新建一个module,选择2.7.9版本的springboot项目,并且添加lombok,springweb,springdataES依赖
](https://img-blog.csdnimg.cn/64bec5332dc54879b293bdfa759f094a.png)
-
在resources目录下,创建配置文件application.yml,添加如下配置:
spring: elasticsearch: uris: http://192.168.126.24:9200,http://192.168.126.24:9201,http://192.168.126.24:9202 logging: pattern: console: '%d{HH:mm:ss.SSS} %clr(%-5level) --- [%-15thread] %cyan(%-50logger{50}):%msg%n' -
创建com.zzx.escase.document包,在包下创建实体类News
package com.zzx.escase.document; import lombok.Data; import org.springframework.data.annotation.Id; import org.springframework.data.annotation.Transient; import org.springframework.data.elasticsearch.annotations.CompletionField; import org.springframework.data.elasticsearch.annotations.Document; import org.springframework.data.elasticsearch.annotations.Field; import org.springframework.data.elasticsearch.core.suggest.Completion; @Document(indexName = "news") @Data public class News { @Id private Integer id; @Field private String title; @Field private String content; @Field private String url; @CompletionField @Transient private Completion tags; } -
创建com.zzx.escase.repository包,在包下创建接口Repository
package com.zzx.escase.repository; import com.zzx.escase.document.News; import org.springframework.data.elasticsearch.repository.ElasticsearchRepository; public interface NewsRepository extends ElasticsearchRepository<News,Integer> { }
5、自动补全功能
-
创建com.zzx.escase.service包,在包下创建类NewsService
package com.zzx.escase.service; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.common.text.Text; import org.elasticsearch.search.suggest.Suggest; import org.elasticsearch.search.suggest.SuggestBuilder; import org.elasticsearch.search.suggest.SuggestBuilders; import org.elasticsearch.search.suggest.completion.CompletionSuggestionBuilder; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate; import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates; import org.springframework.stereotype.Service; import java.util.List; import java.util.stream.Collectors; @Service public class NewsService { @Autowired private ElasticsearchRestTemplate template; //自动补齐 public List<String> autoSuggest(String keyword){ // 1.创建补齐请求 SuggestBuilder suggestBuilder = new SuggestBuilder(); // 2.构建补齐条件 CompletionSuggestionBuilder suggestionBuilder = SuggestBuilders.completionSuggestion("tags").prefix(keyword).skipDuplicates(true).size(10); suggestBuilder.addSuggestion("prefix_suggestion",suggestionBuilder); // 3.发送请求 SearchResponse response = template.suggest(suggestBuilder, IndexCoordinates.of("news")); // 4.处理结果 List<String> result = response.getSuggest().getSuggestion("prefix_suggestion").getEntries().get(0).getOptions().stream() .map(Suggest.Suggestion.Entry.Option::getText) .map(Text::toString) .collect(Collectors.toList()); return result; } } -
在Test根目录下,创建com.zzx.escase.service包,在包下创建NewsServiceTest测试类
package com.zzx.escase.service; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import java.util.List; @SpringBootTest public class NewsServiceTest { @Autowired private NewsService newsService; @Test public void testAutoSuggest(){ List<String> list = newsService.autoSuggest("zhu"); list.forEach(System.out::println); } }即打印出tags域中自动补齐的10个关键词
6、高亮搜索关键字功能
-
在com.zzx.escase.repository的接口Repository下,添加高亮搜索关键字方法
@Highlight(fields = {@HighlightField(name = "title"),@HighlightField(name="content")}) List<SearchHit<News>> findByTitleMatchesOrContentMatches(String title, String content); -
在com.zzx.escase.service的接口NewsService下,添加高亮搜索关键字方法
//查询关键字 public List<News> highLightSearch(String keyword){ List<SearchHit<News>> result = newsRepository.findByTitleMatchesOrContentMatches(keyword, keyword); //处理结果,封装News类型的集合 ArrayList<News> newsList = new ArrayList(); for (SearchHit<News> newsSearchHit : result) { News news = newsSearchHit.getContent(); //高亮字段 Map<String, List<String>> highlightFields = newsSearchHit.getHighlightFields(); if(highlightFields.get("title") != null){ news.setTitle(highlightFields.get("title").get(0)); } if(highlightFields.get("content") != null){ news.setTitle(highlightFields.get("content").get(0)); } newsList.add(news); } return newsList; }将elasticsearch内部的处理高亮的结果封装到News实体类中,然后返回
-
在Test根目录下的com.zzx.escase.service包的NewsServiceTest测试类中添加高亮测试方法
@Test public void testHighLightSearch(){ List<News> newsList = newsService.highLightSearch("演员"); newsList.forEach(System.out::println); }此时每个演员的关键字都会被套上em的标签,再由前端对em标签进行渲染。
-
创建com.zzx.escase.controller包,在包下创建类NewsController
package com.zzx.escase.controller; import com.zzx.escase.document.News; import com.zzx.escase.service.NewsService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import java.util.List; @RestController public class NewsController { @Autowired private NewsService newsService; @GetMapping("/autoSuggest") public List<String> autoSuggest(String term){ return newsService.autoSuggest(term); } @GetMapping("/highLightSearch") public List<News> highLightSearch(String term){ return newsService.highLightSearch(term); } } -
启动该springboot项目,然后在浏览器中查看:
http://localhost:8080/autoSuggest?term="zhu"
以及http://localhost:8080/highLightSearch?term="演员"
7、页面展示
-
前端页面代码:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>结果</title> <link rel="stylesheet" type="text/css" href="css/jquery-ui.min.css"/> <link rel="stylesheet" type="text/css" href="css/bootstrap.min.css"/> <script src="js/jquery-2.1.1.min.js"></script> <script src="js/jquery-ui.min.js"></script> <style> body { padding-left: 14px; padding-top: 14px; } ul, li { list-style: none; padding: 0; } li { padding-bottom: 16px; } a, a:link, a:visited, a:hover, a:active { text-decoration: none; } em { color: red; font-style: normal; } </style> </head> <body> <div> <input id="newsTag" class="form-control" style="display: inline; width: 50%;" name="keyword"> <button class="btn btn-primary" onclick="search()">搜索一下</button> </div> <hr> <div> <ul id="news"> </ul> </div> </body> <script> $("#newsTag").autocomplete({ source: "/autoSuggest", // 请求路径 delay: 100, //请求延迟 minLength: 1 //最少输入多少字符像服务器发送请求 }) function search() { var term = $("#newsTag").val(); $.get("/highLightSearch", {term: term}, function (data) { var str = ""; for (var i = 0; i < data.length; i++) { var document = data[i]; str += "<li>" + " <h4>" + " <a href='" + document.url + "' target='_blank'>" + document.title + "</a>" + " </h4> " + " <p>" + document.content + "</p>" + " </li>"; } $("#news").html(str); }) } </script> </html>给输入文本框绑定自动补齐autocomplete函数,以及给搜索按钮绑定search函数,用以展示数据。

总结:
- 当索引足够大时,需要建立ES集群,此时需要将索引拆分成多分,分别放入不同的服务器中,几台服务器维护同一个索引。每一台服务器为一个节点,每一台服务器中的数据称为一个分片。防止节点故障导致集群无法正常运行,分片和该分片的副本不会存放在同一个节点上。
- 安装完ES服务后,再安装分词器,然后修改ES的配置文件elasticsearch.yml,配置成集群的参数即可完成集群的搭建。
安装Kibana需要修改Kibana的配置文件kiabana.yml,配置集群的连接即可。
在创建索引时,可以指定索引的分片数和分片的副本数,创建后只能修改分片的副本数。 - ES优化可以通过优化磁盘、分片策略、内存设置进行优化。
1)优化磁盘,就是选择SSD或者使用RAID0模式;
2)分片策略,就是每个分片占用的磁盘容量一般不超过32G。
分片数一般不超过节点数的三倍。
推迟分片分配。
减少副本数量,以及大批量写入时,副本先设置为0,写完再复原。
3)内存设置,就是Xmx和Xms的大小设置为相同。
Xmx和Xms不要超过物理内存的50%。
Xmx和Xms不要超过32G。 - 自动补全功能,指定的某个域作为源数据,因为该功能对性能要求极高,所以需要设置该域的类型为completion。在mysql数据库中的数据可以通过logstash导入到ES服务中。
- 搭建springboot整合的Elasticserach项目时,需要配置application.yml配置文件来指定集群。并且使用SuggestBuilder对象。
- 给搜索框绑定autocomplete函数,用以实现自动补齐功能;以及给搜索按钮绑定search函数,用以展示有高亮显示关键词的数据。















 789
789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









