










背景
基于Django和Bootstrap的电影推荐系统结合了用户协同过滤算法,通过爬虫技术获取电影数据,并在可视化后台展示推荐结果。该系统旨在提供个性化的电影推荐服务,帮助用户发现符合其喜好的电影。
用户协同过滤算法是一种常用的推荐算法,通过分析用户的历史行为数据,如电影评分和浏览记录,来推荐类似兴趣的电影给用户。结合Django框架,系统可以实现用户注册、登录、电影推荐等功能,提升用户体验。
通过Bootstrap框架,系统可以实现响应式设计,确保在不同设备上的良好展示效果。爬虫技术用于从各种数据源获取电影信息,保持电影库的更新和完整性。可视化后台提供管理员管理推荐算法、查看推荐结果等功能,使系统更易于操作和管理。
这样的电影推荐系统将为用户提供个性化推荐体验,帮助他们快速找到感兴趣的电影,同时为管理员提供管理工具,帮助他们更好地监控和优化推荐算法。系统的结合了多种技术和功能,旨在为用户和管理员提供便捷、有效的电影推荐服务。
主要功能
基于Django和Bootstrap的电影推荐系统结合了基于用户的协同过滤算法,具备爬虫和可视化后台功能,主要功能包括:
-
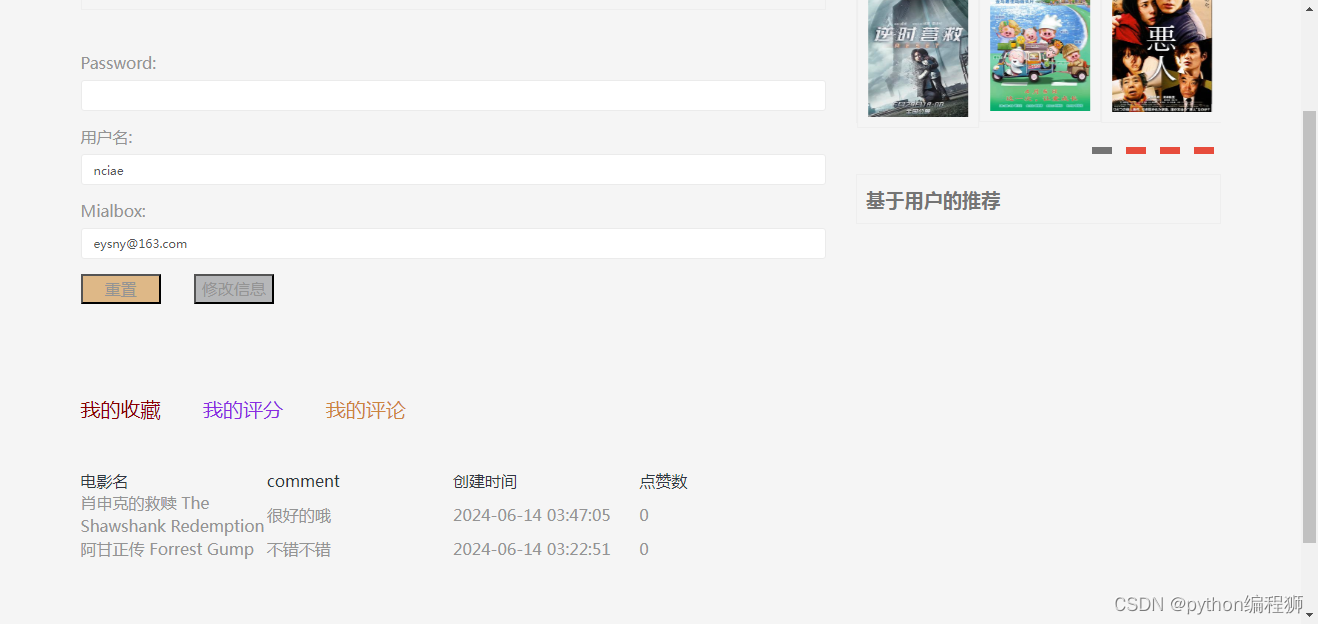
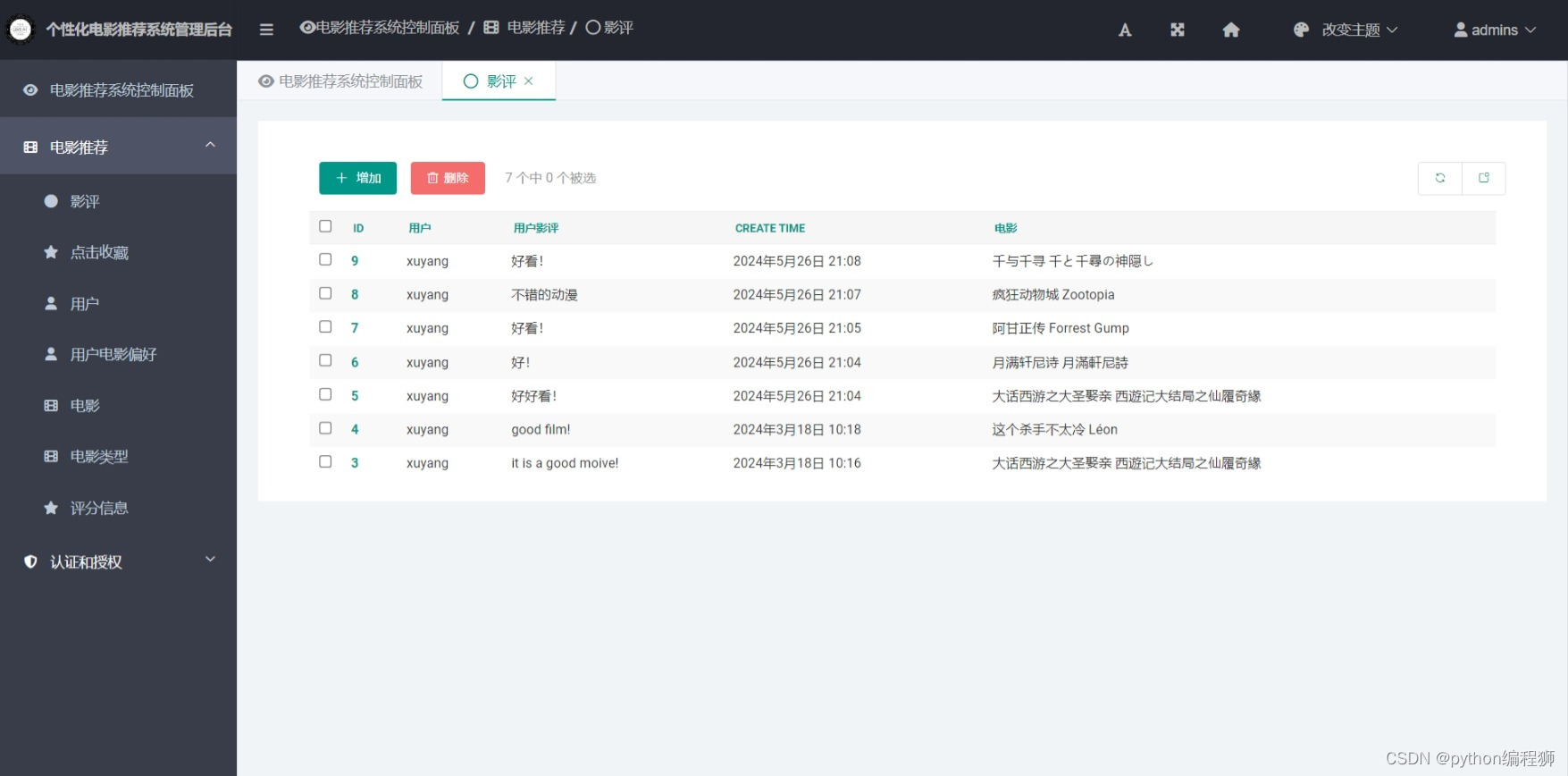
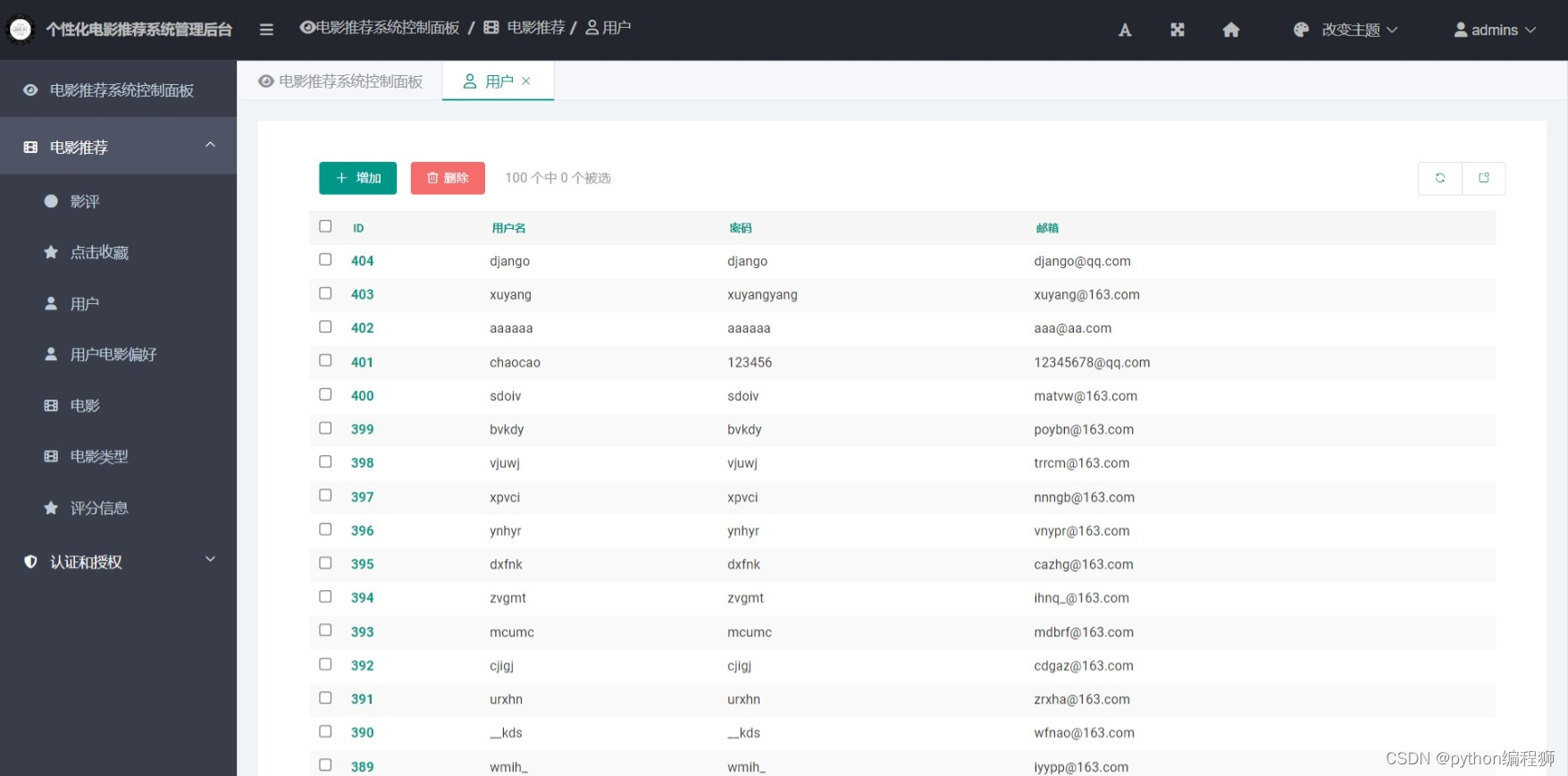
用户注册与登录:用户可以注册账户并登录系统,以便记录其个性化的电影偏好和行为数据。
-
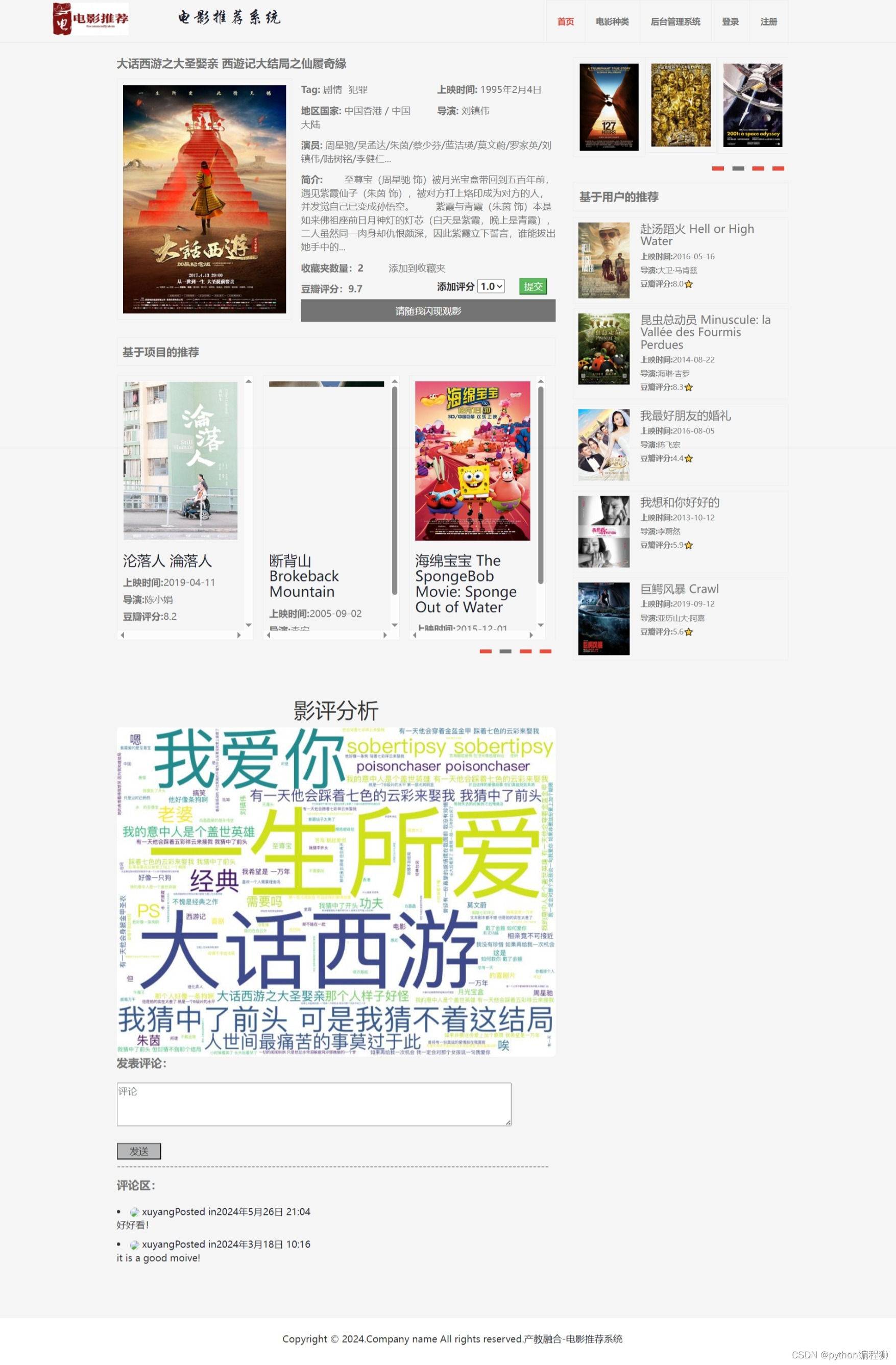
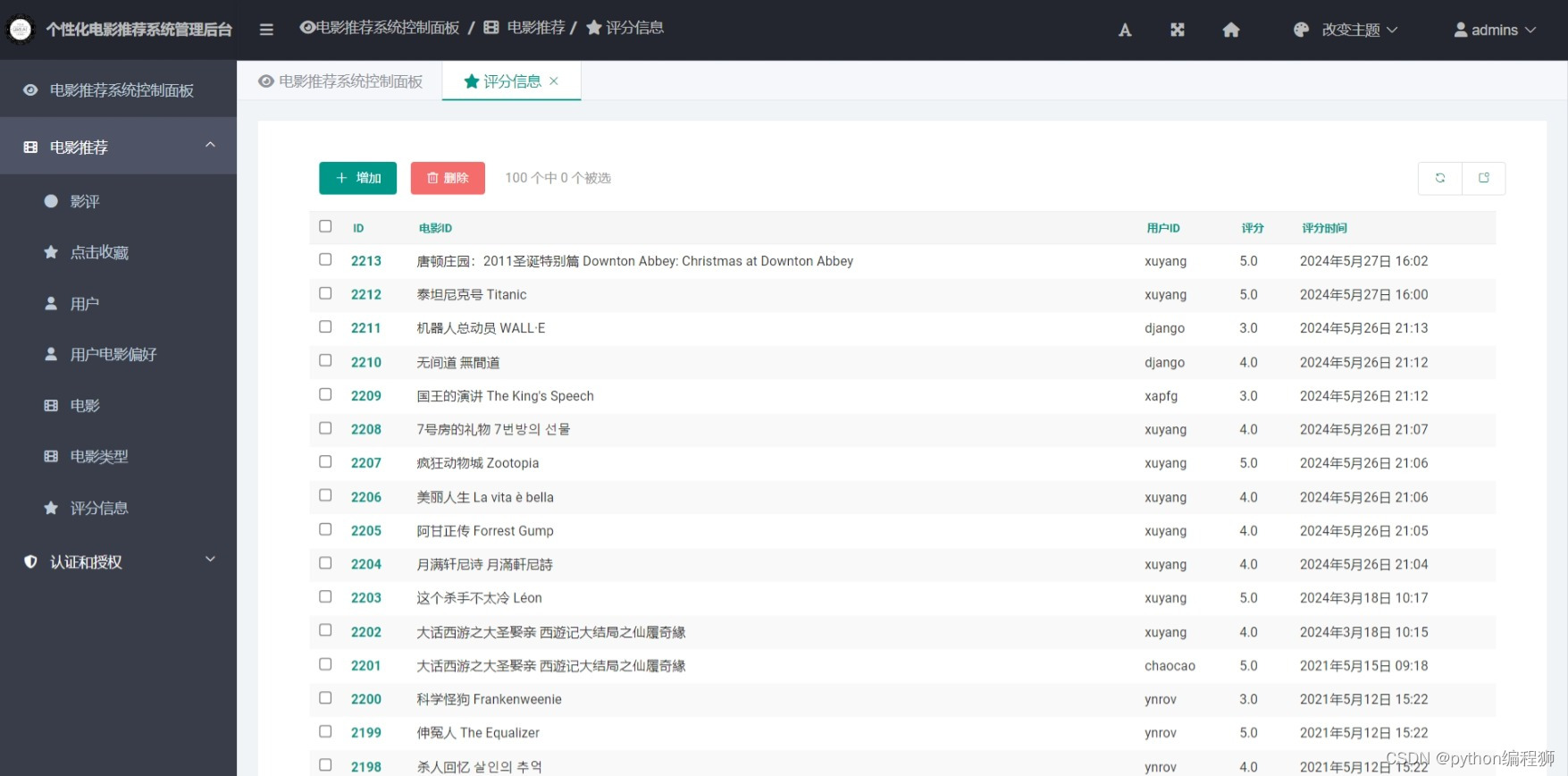
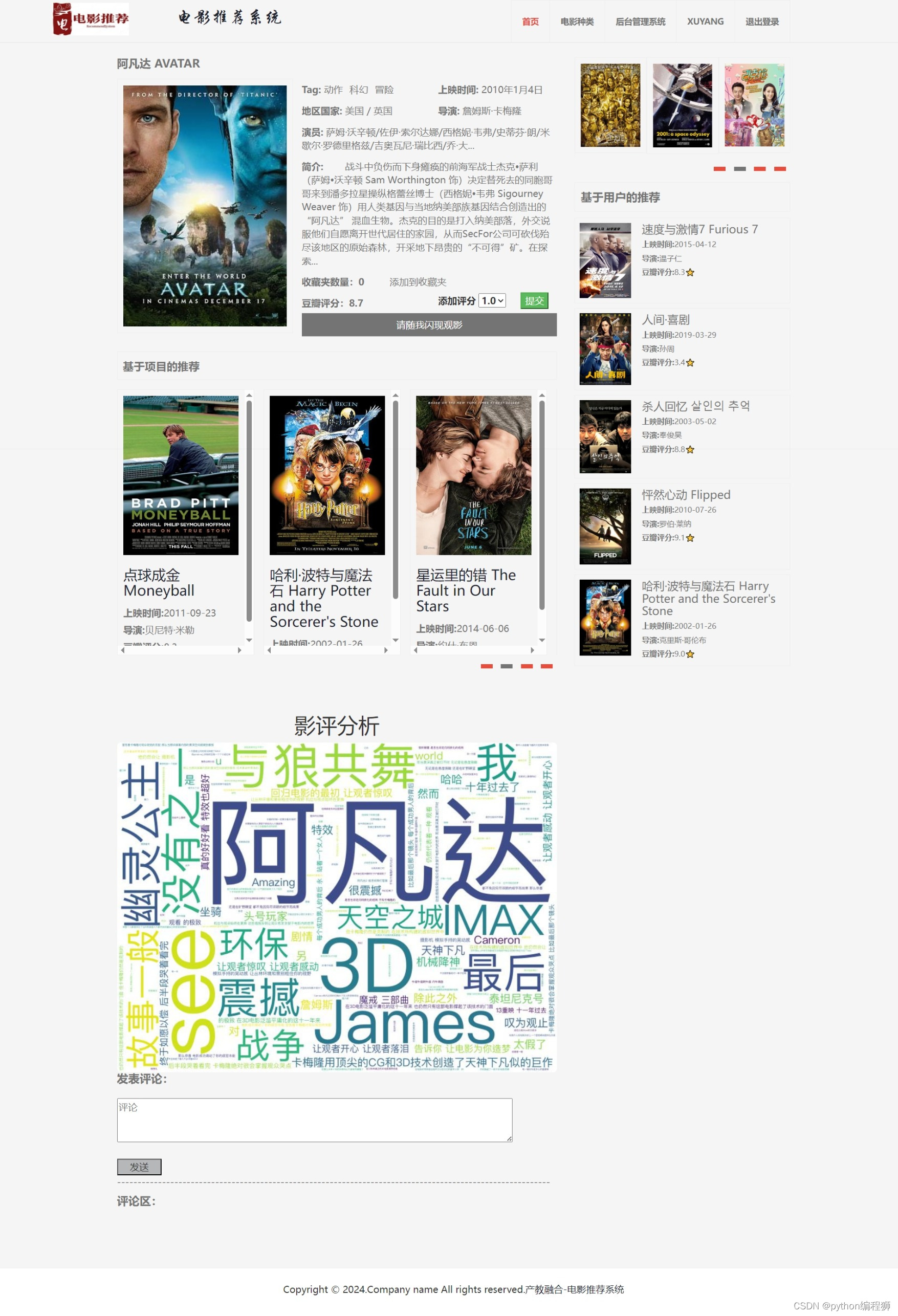
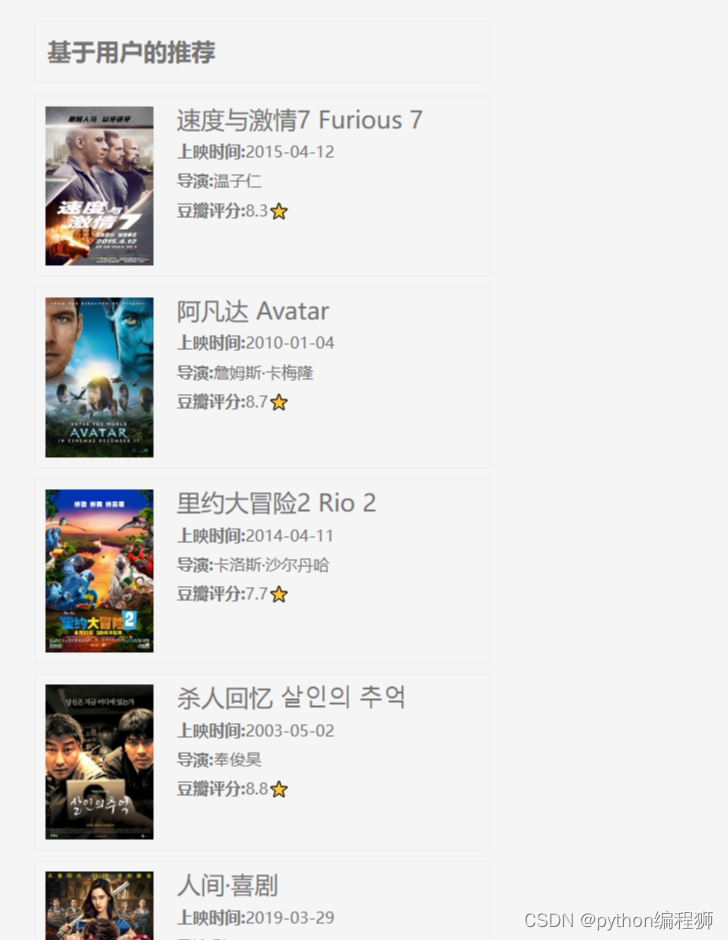
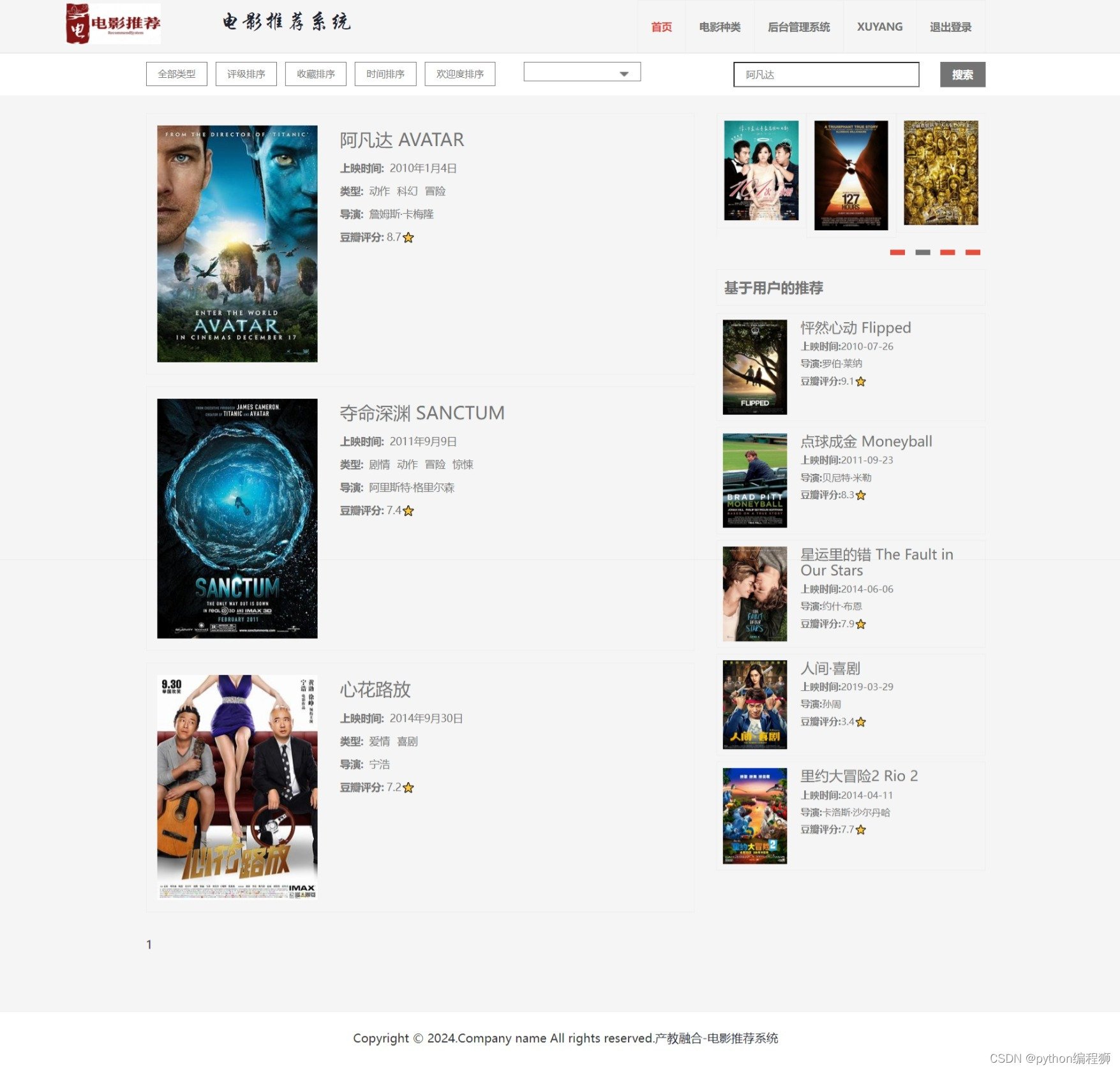
电影推荐:基于用户协同过滤算法,系统能够分析用户的历史行为数据,为用户推荐可能感兴趣的电影,提供个性化推荐服务。
-
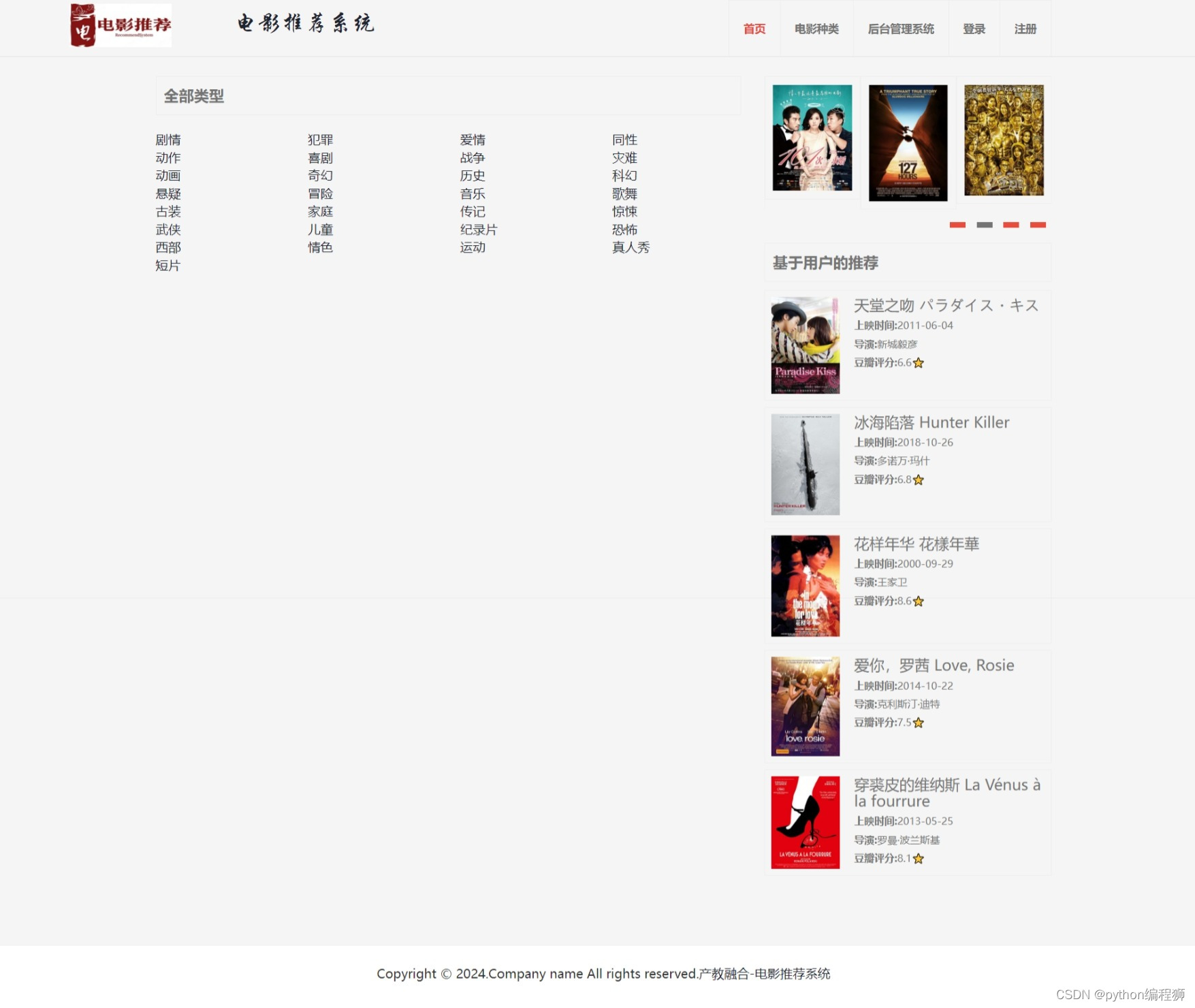
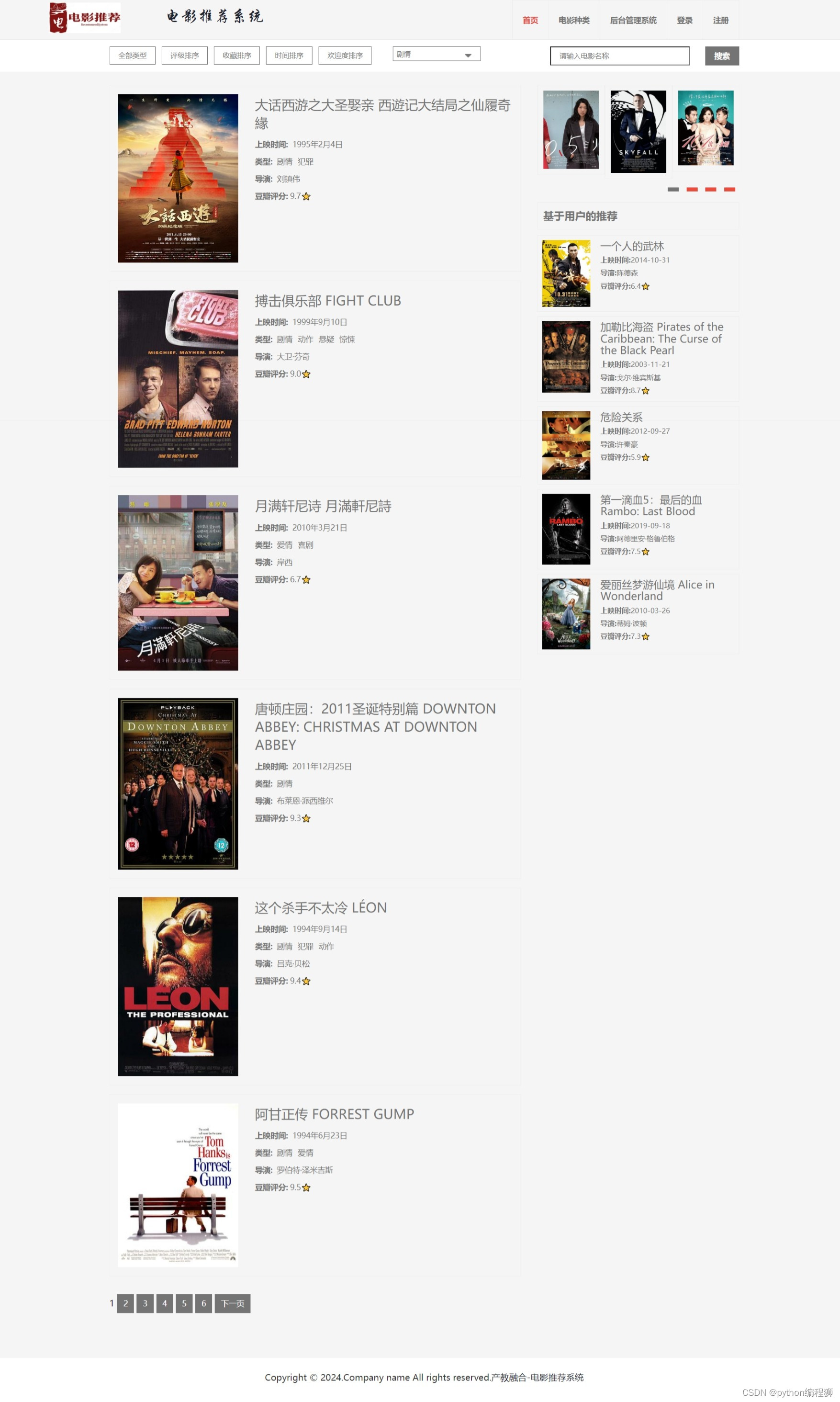
电影信息展示:系统展示丰富的电影信息,包括电影名称、海报、简介、评分等,帮助用户了解电影内容。
-
爬虫数据更新:通过爬虫技术,系统可以定期从各种数据源获取最新的电影信息,确保电影库的更新和完整性。
-
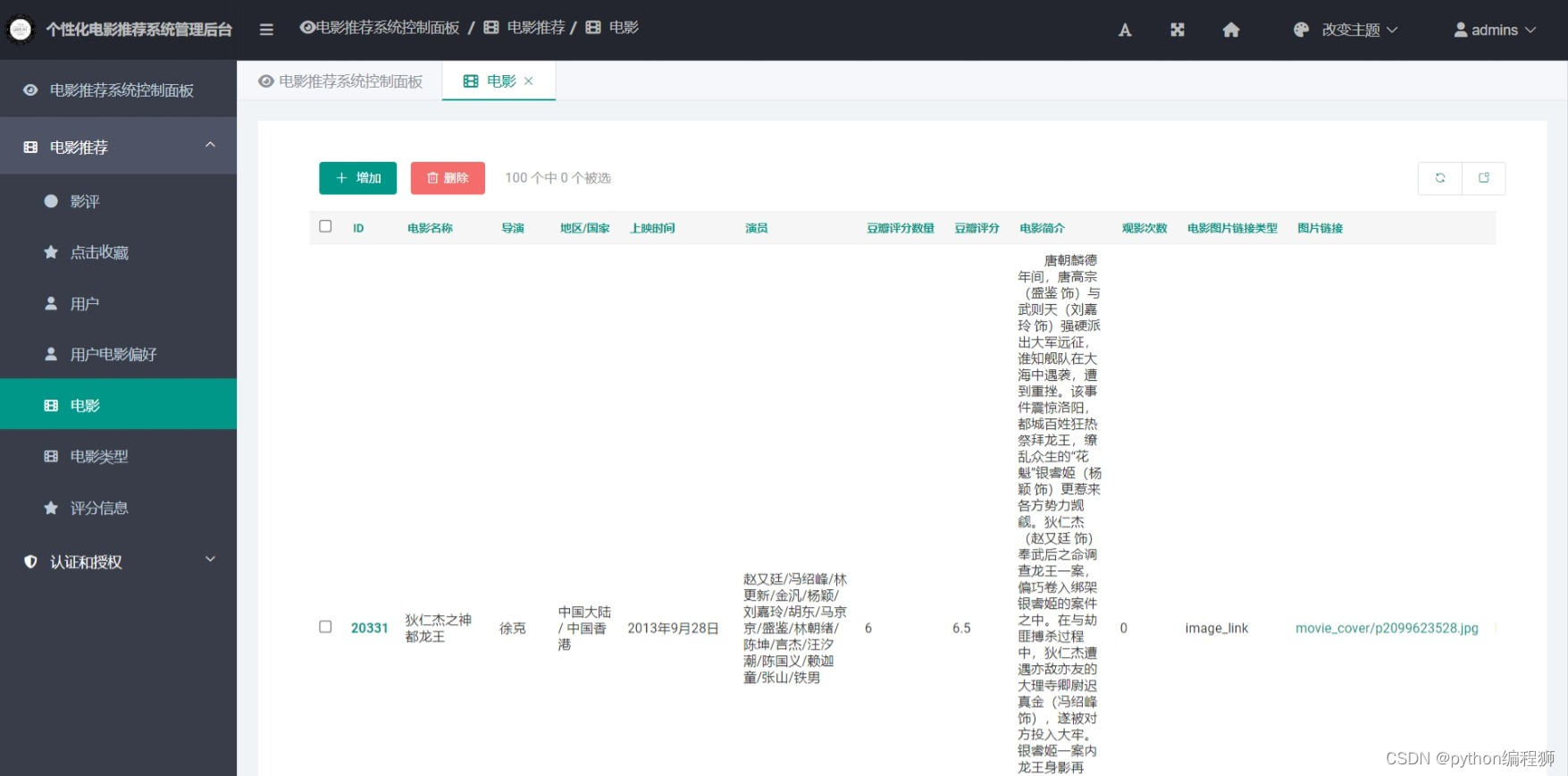
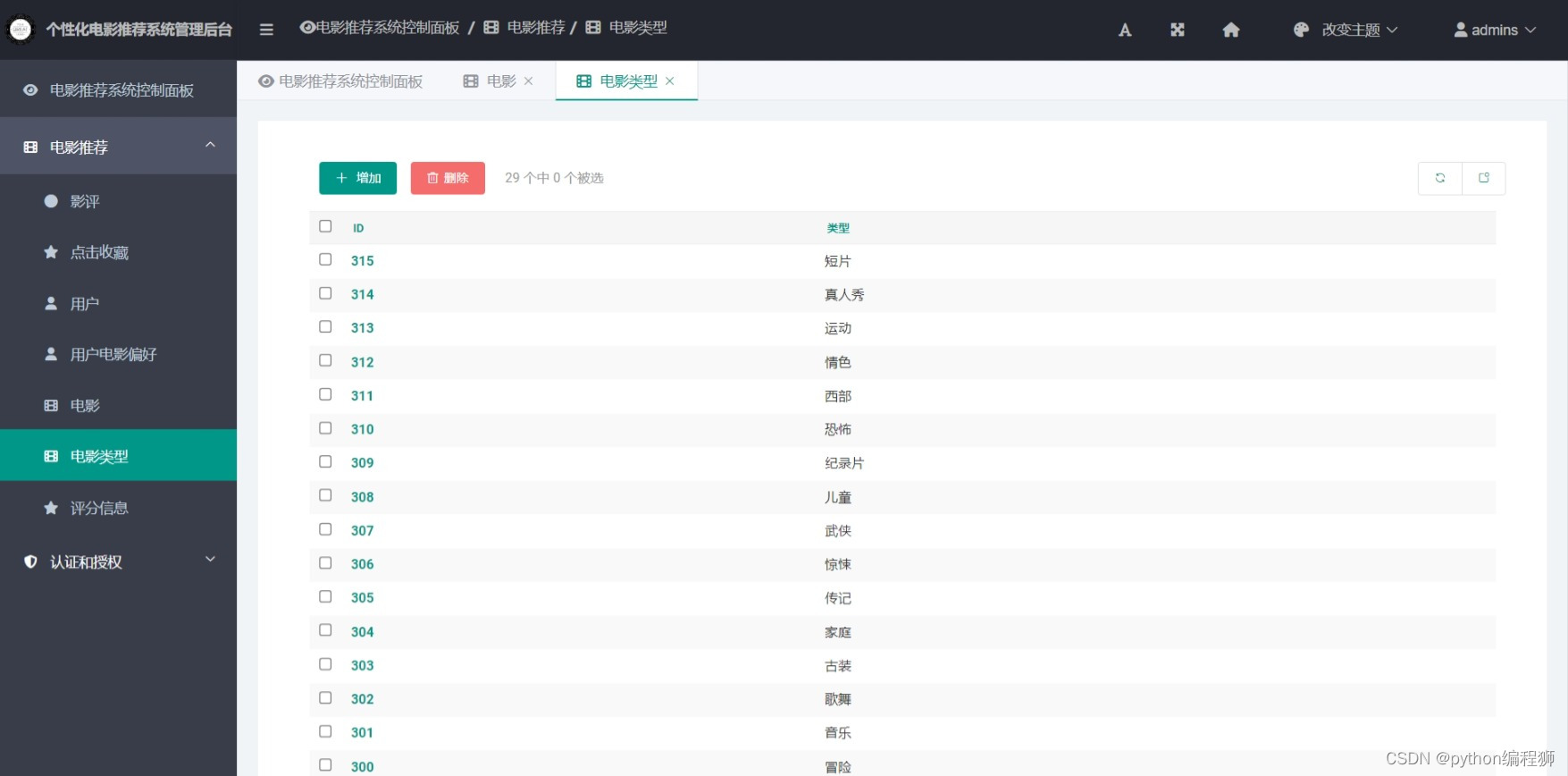
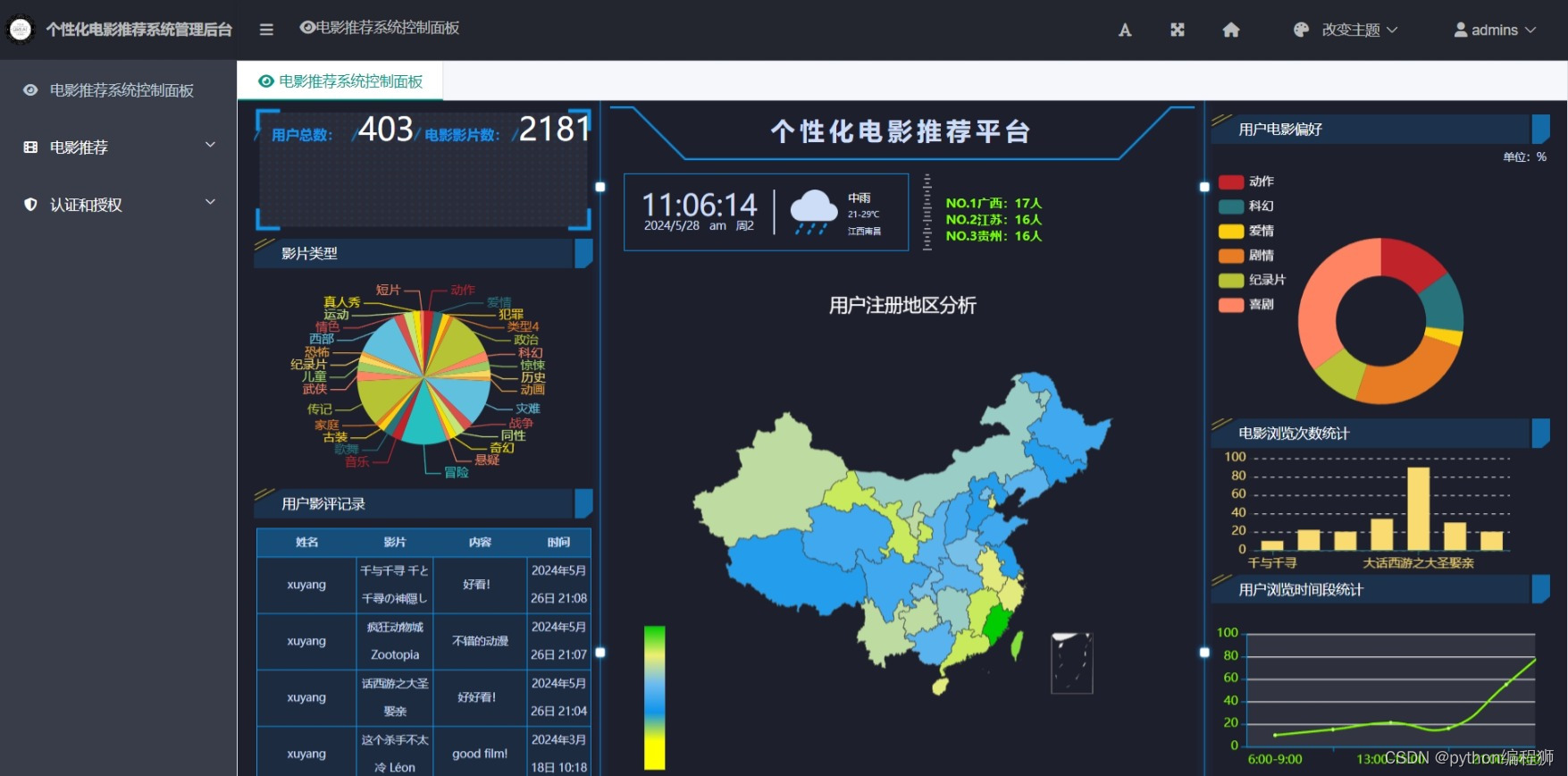
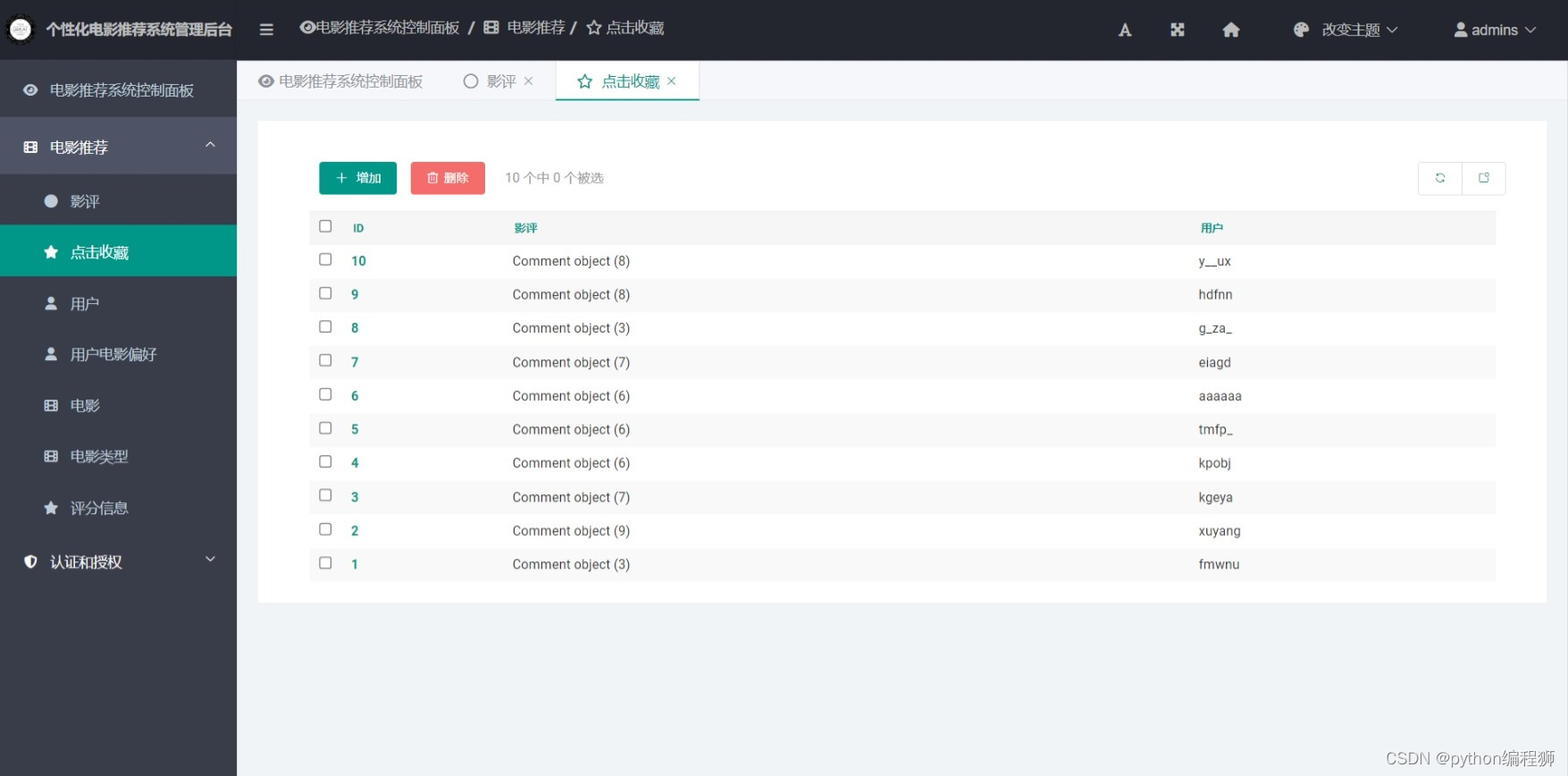
可视化后台:系统提供可视化后台管理界面,管理员可以通过后台对推荐算法进行调整和管理,查看推荐结果,监控系统运行情况等。
-
响应式设计:使用Bootstrap实现响应式设计,确保系统在不同设备上都能有良好的展示效果。
-
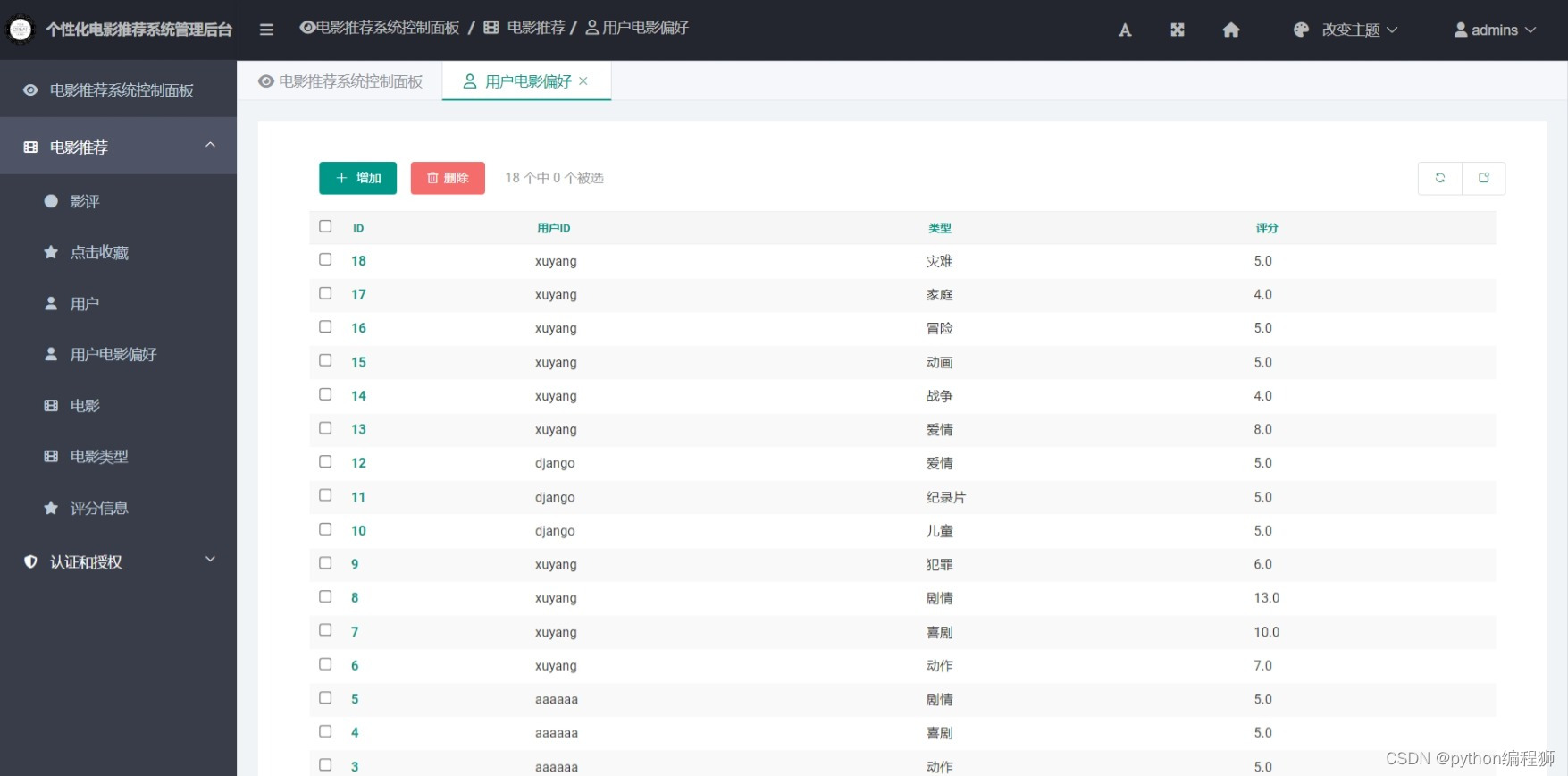
个人化设置:用户可以设置个性化的偏好和关注的电影类型,系统会根据这些设置进行推荐。
这些功能共同构建了一个功能完善的电影推荐系统,旨在提供用户友好的界面和个性化的推荐体验,同时为管理员提供方便的管理工具,以优化推荐算法和提升系统效率。
技术栈
Django
MySQL
Bootstrap
echarts
基于用户的协同过滤算法
主要代码
class ItemBasedCF:
# 初始化参数
def __init__(self):
# 找到相似的20部电影,为目标用户推荐10部电影
self.n_sim_movie = 100
self.n_rec_movie = 15
# 用户相似度矩阵
self.movie_sim_matrix = defaultdict(lambda: defaultdict(float))
# 物品共现矩阵
self.cooccur = defaultdict(lambda: defaultdict(int))
self.movie_popular = defaultdict(int)
self.movie_count = 0
print('Similar user number = %d' % self.n_sim_movie)
print('Recommended user number = %d' % self.n_rec_movie)
self.calc_movie_sim()
# 计算电影之间的相似度
def calc_movie_sim(self):
model_path = 'item_rec.pkl'
# 已有的话,就不重新计算
# try:
# 重新计算
# except FileNotFoundError:
users = User.objects.all()
for user in users:
movies = Rate.objects.filter(user=user).values_list('movie_id', flat=True)
for movie in movies:
self.movie_popular[movie] += 1
self.movie_count = len(self.movie_popular)
print("Total user number = %d" % self.movie_count)
for user in users:
movies = Rate.objects.filter(user=user).values_list('movie_id', flat=True)
for m1 in movies:
for m2 in movies:
if m1 == m2:
continue
self.cooccur[m1][m2] += 1
# self.movie_sim_matrix[m1][m2] += 1
print("Build co-rated users matrix success!")
# 计算电影之间的相似性
print("Calculating user similarity matrix ...")
for m1, related_movies in self.cooccur.items():
for m2, count in related_movies.items():
# 注意0向量的处理,即某电影的用户数为0
if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:
self.movie_sim_matrix[m1][m2] = 0
else:
# 根据公式计算w[i][j]
self.movie_sim_matrix[m1][m2] = count / sqrt(self.movie_popular[m1] * self.movie_popular[m2])
print('Calculate user similarity matrix success!')
# 保存模型
with open(model_path, 'wb')as opener:
pickle.dump(dict(self.movie_sim_matrix), opener)
print('保存模型成功!')运行效果

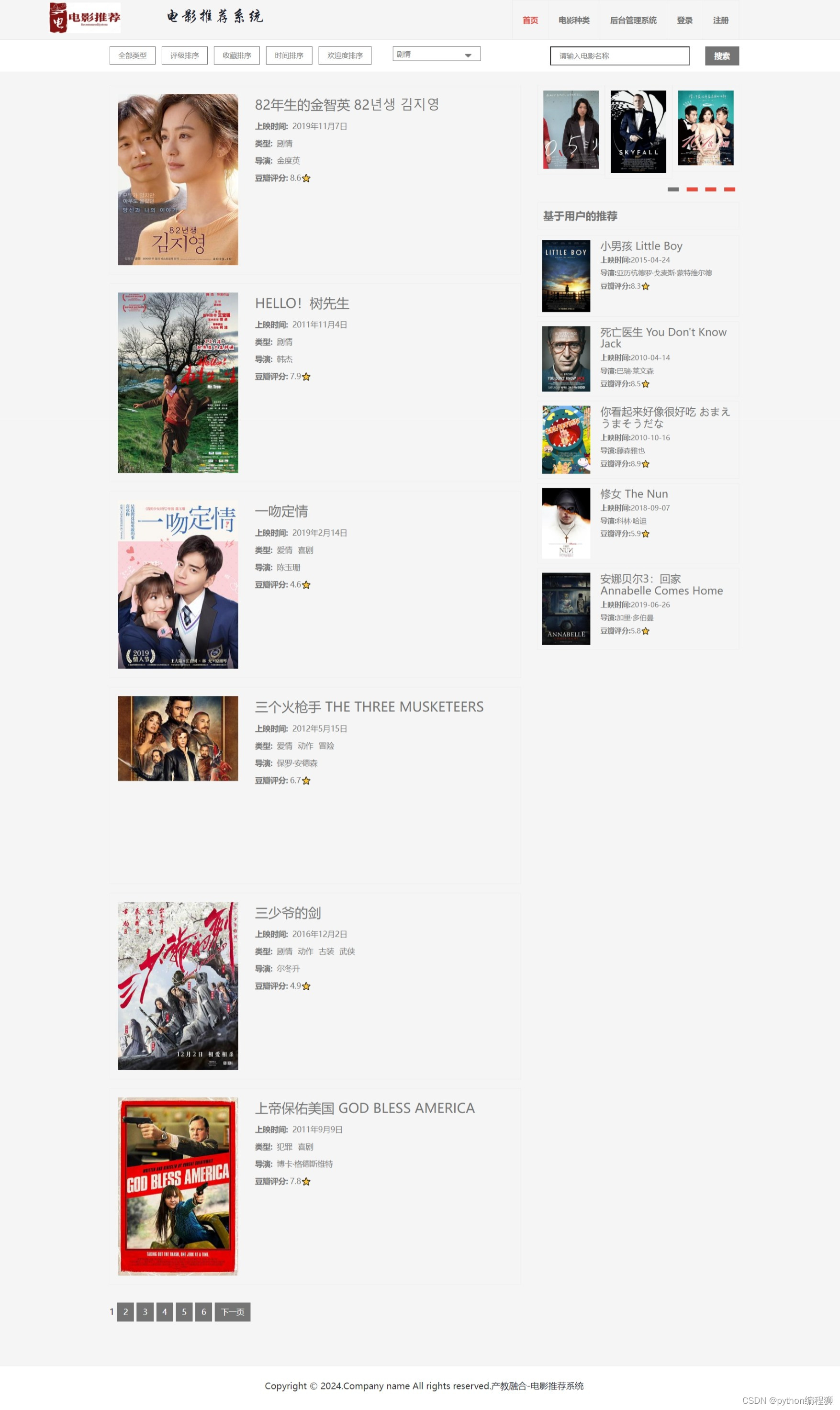

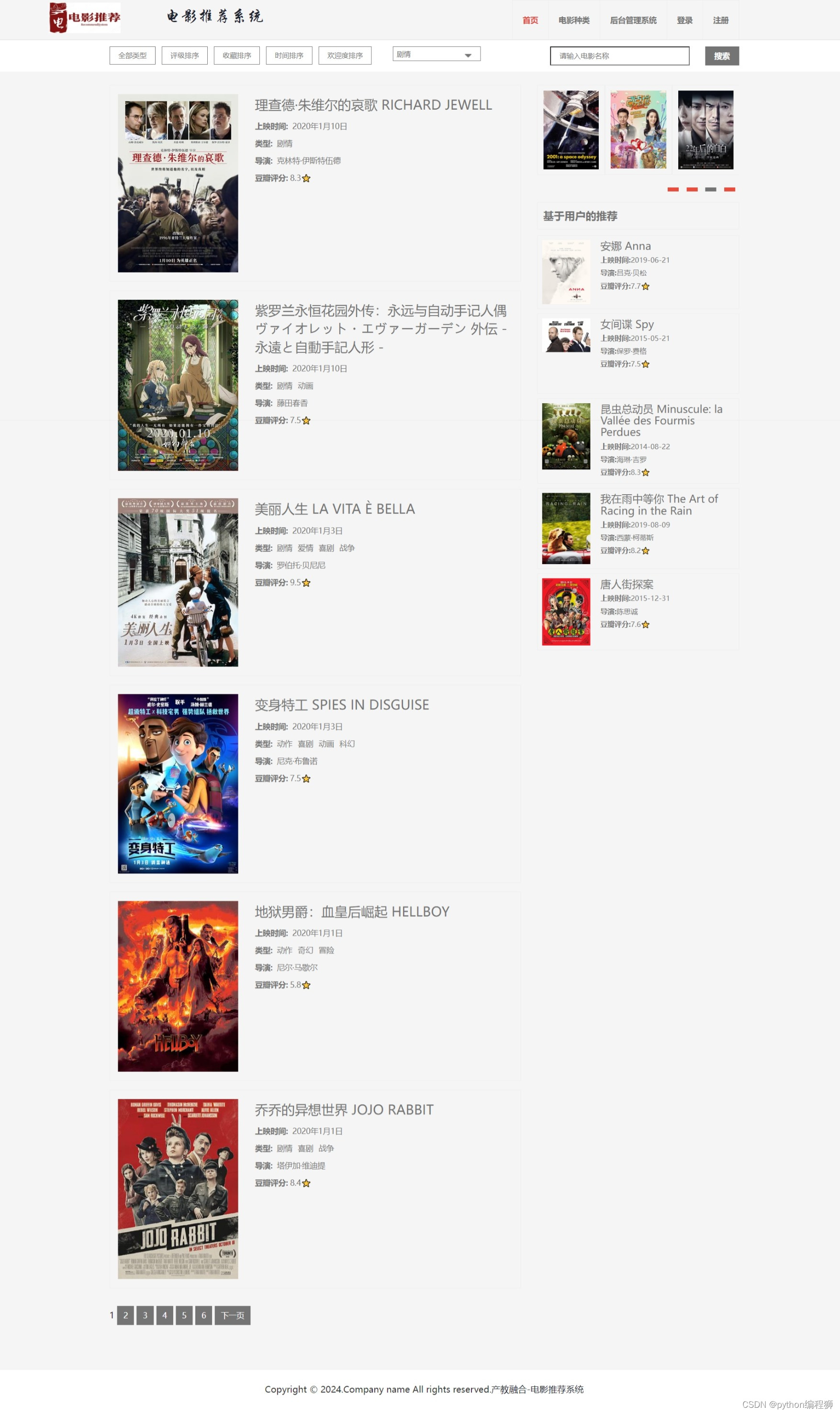
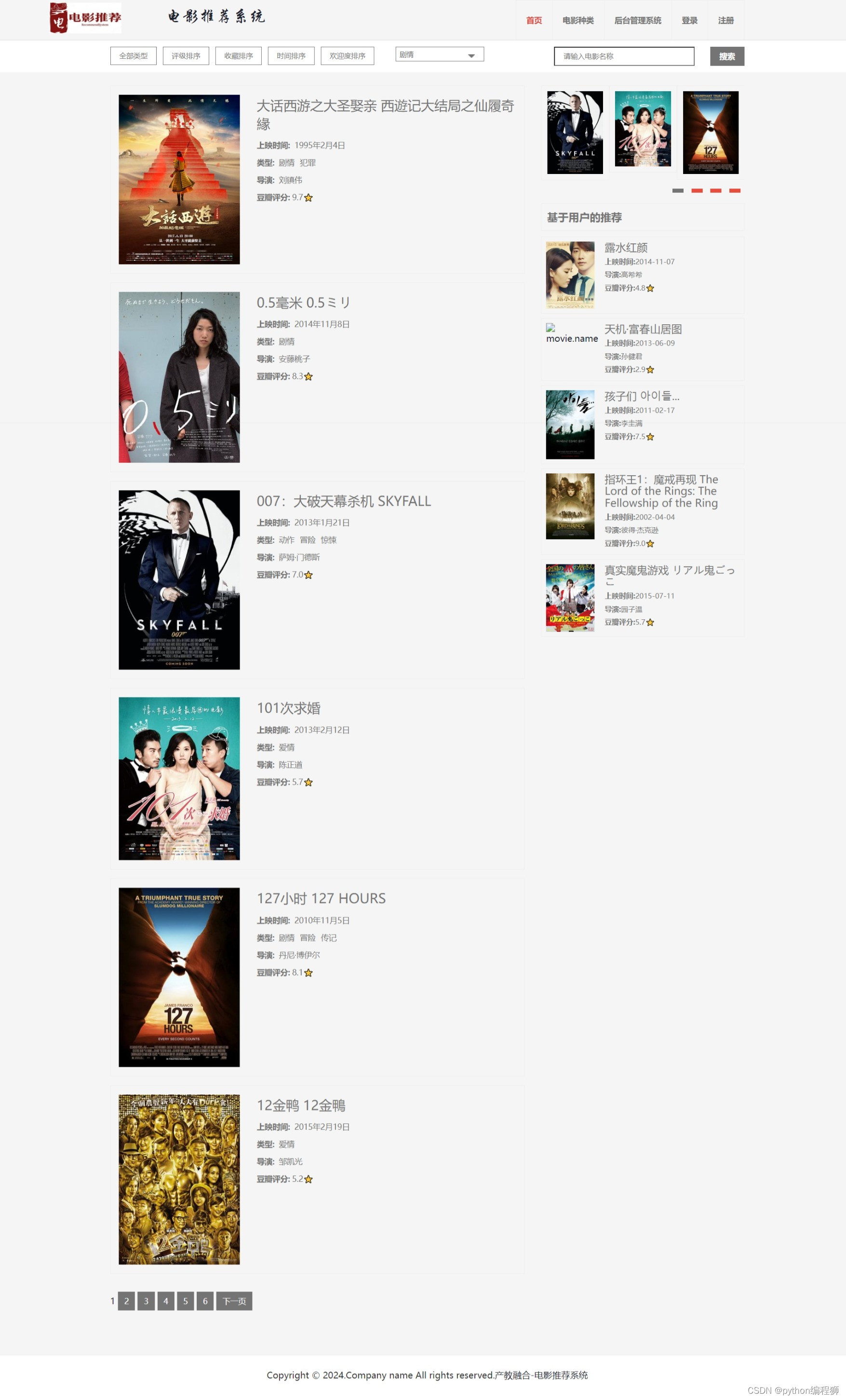
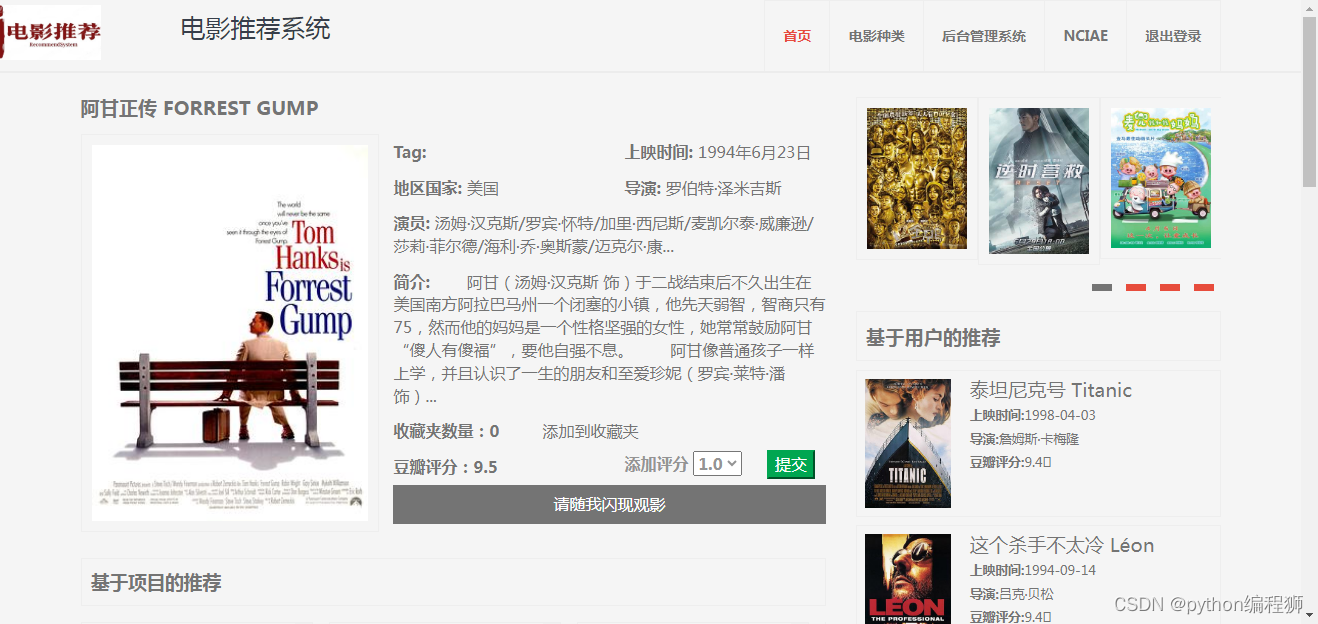
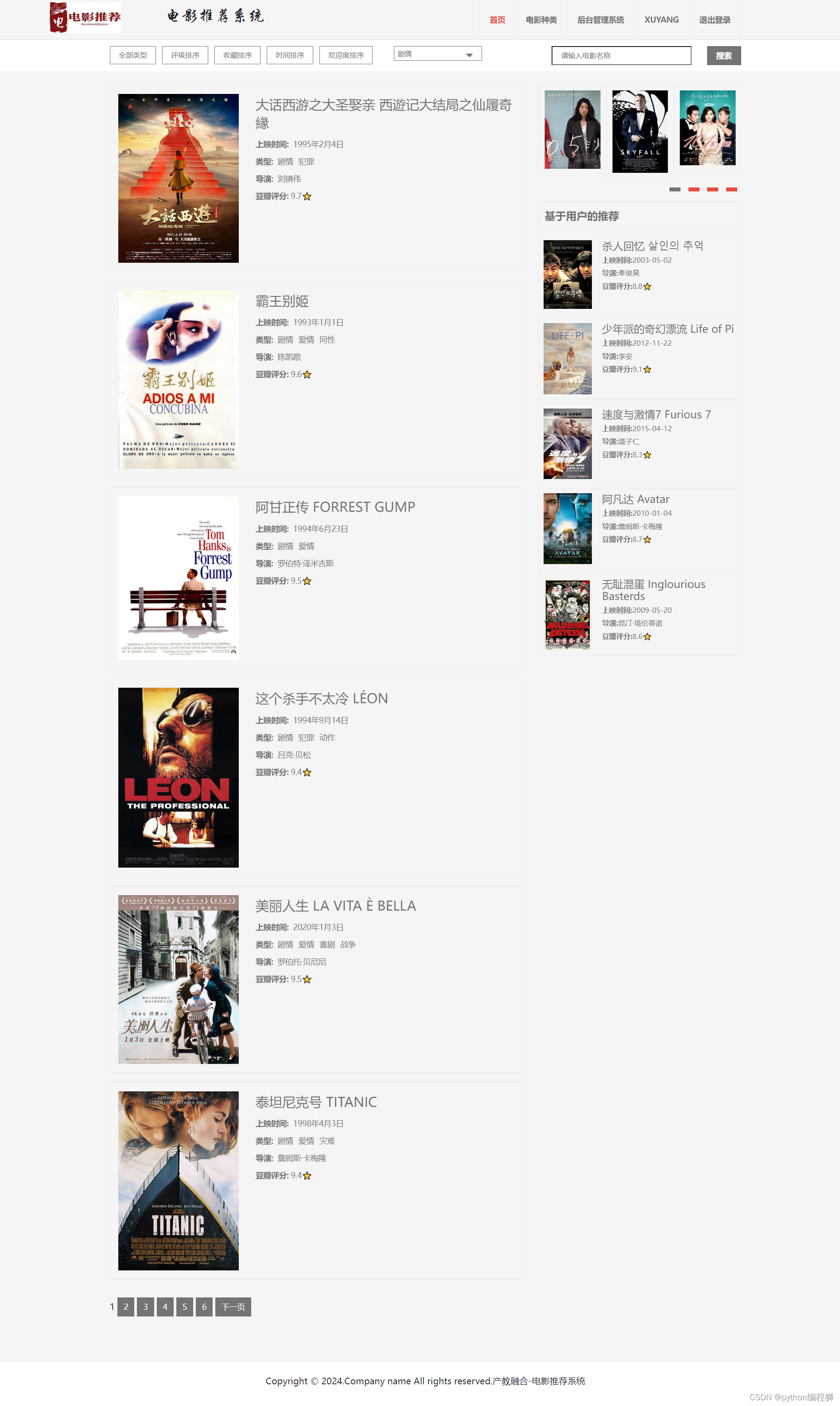


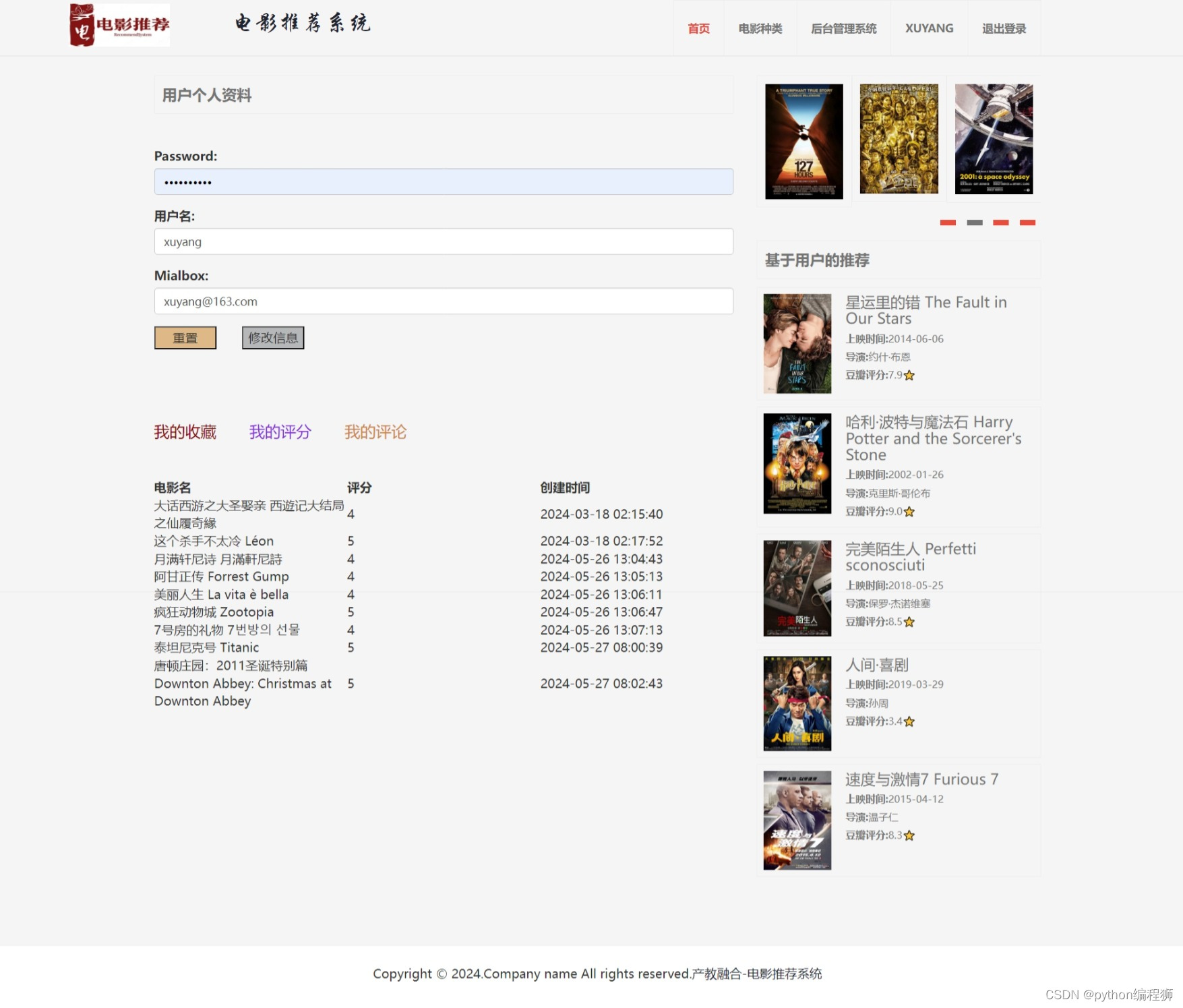
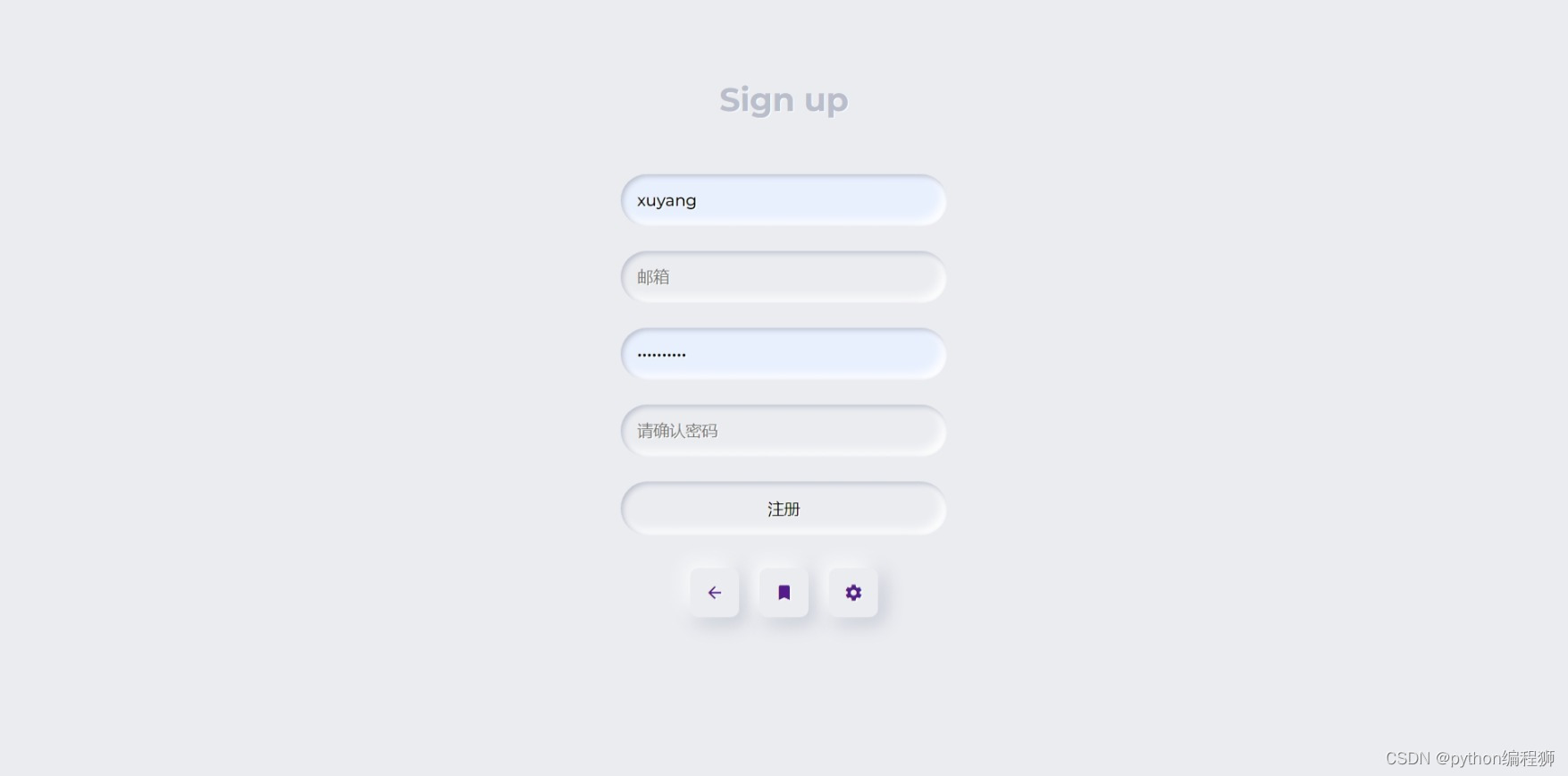















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









