






背景
随着互联网和社交媒体的迅猛发展,在线评分与评论已成为消费者决策过程中的重要参考因素,尤其是在电影行业。IMDb、豆瓣、Rotten Tomatoes等平台汇集了全球观众的评分和评论,形成了一个庞大的数据池,反映了电影在不同观众群体中的接受度和口碑。这些在线评分和评论不仅能影响观众的观看决策,还对电影的票房表现产生重要影响。因此,深入分析和理解这些评价数据,对于电影制作方、发行公司以及观众本身都具有重要意义。
在电影评分和评论分析中,全球评分通常是基于大规模用户群体的综合评分,反映了观众整体对电影的态度。而用户评论则提供了更为详细的反馈,评论文本中蕴含了观众的情感倾向,分为正面、负面和中立评价,能够揭示观众的具体喜好和不满之处。专业影评人则从艺术性、技术性和创意性等方面给出评价,这些评价通常影响着电影的声誉和未来的票房走势。
本研究旨在通过对IMDb等平台上电影的评分、评论和影评和评分的分析,揭示不同电影票房差异、用户情感倾向与电影票房之间的关系,并利用情感分析技术对评论进行分类与标注。此外,研究将使用可视化方法,如词云和情感分布图,来直观展示电影评价的特点,为电影行业相关决策提供数据支持。
实现思路
对票房和评论进行数据采集、数据的清洗、分析与可视化,主要步骤包括:
数据采集:从IMDb:获取电影的全球评分、用户评论和专业影评人的评价以及票房数据等,并存为excel。
数据清洗与处理:从Excel文件加载票房数据和电影信息。通过去除符号(如“$”,“,”)和替换缺失数据(“–”)处理票房数据,并将其转为整数类型。同时,过滤掉二级地区为“Re-release”的记录。
数据汇总与分组:根据“二级地区”和“一级地区”对票房数据进行分组汇总,计算各地区的总票房。对于电影数据,根据发布年份汇总总票房。
地区映射与可视化:通过字典将“二级地区”映射为中文国家名称,输出并保存处理后的数据。利用pyecharts绘制世界地图(展示各国票房)和饼图(展示一级地区票房占比)。
评论数据分析:对评论进行文本预处理(如小写化、去除特殊字符),然后进行分词,去除停用词,统计词频,并生成词云图展示。利用VADER情感分析工具计算评论的情感分数,分类为“Positive”、“Negative”或“Neutral”,最后通过饼图展示各情感分类的比例。
数据采集实现
数据采集分为电影信息采集和评论采集。其中电影信息采集通过爬虫技术从IMDb网站收集电影的基本信息。通过读取包含电影ID和名称的Excel文件,并逐一访问IMDb页面。发送带有适当请求头的GET请求,获取电影的详细信息,包括导演、编剧、演员、评分、评论数、电影描述、类型、时长、取景地、生产公司、语言等。信息通过XPath解析提取,并存储到一个字典中。爬取过程中使用了异常处理和重试机制以确保稳定性。最后,收集到的所有数据被保存到一个新的Excel文件中,共采集50部电影2000多条在各个地区国家票房数据。最后采集结果如下:
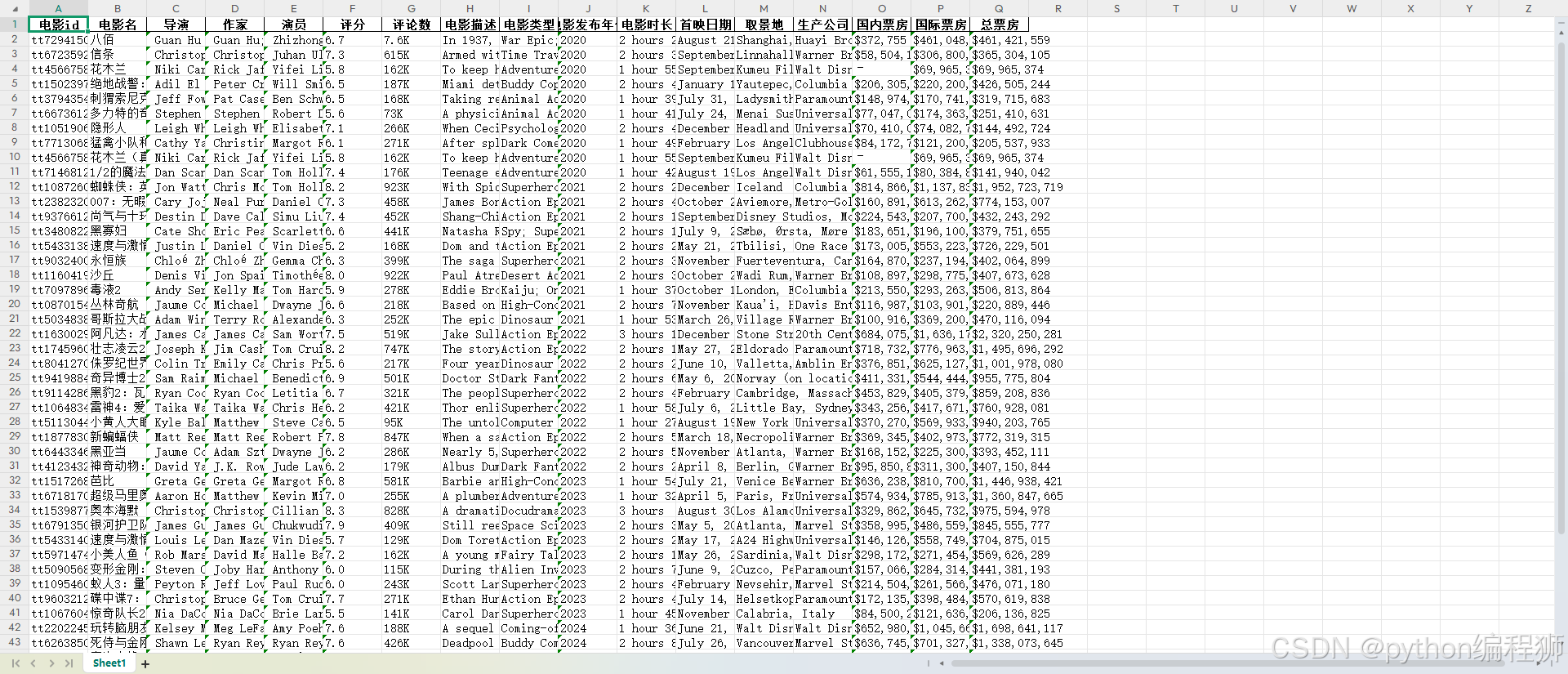
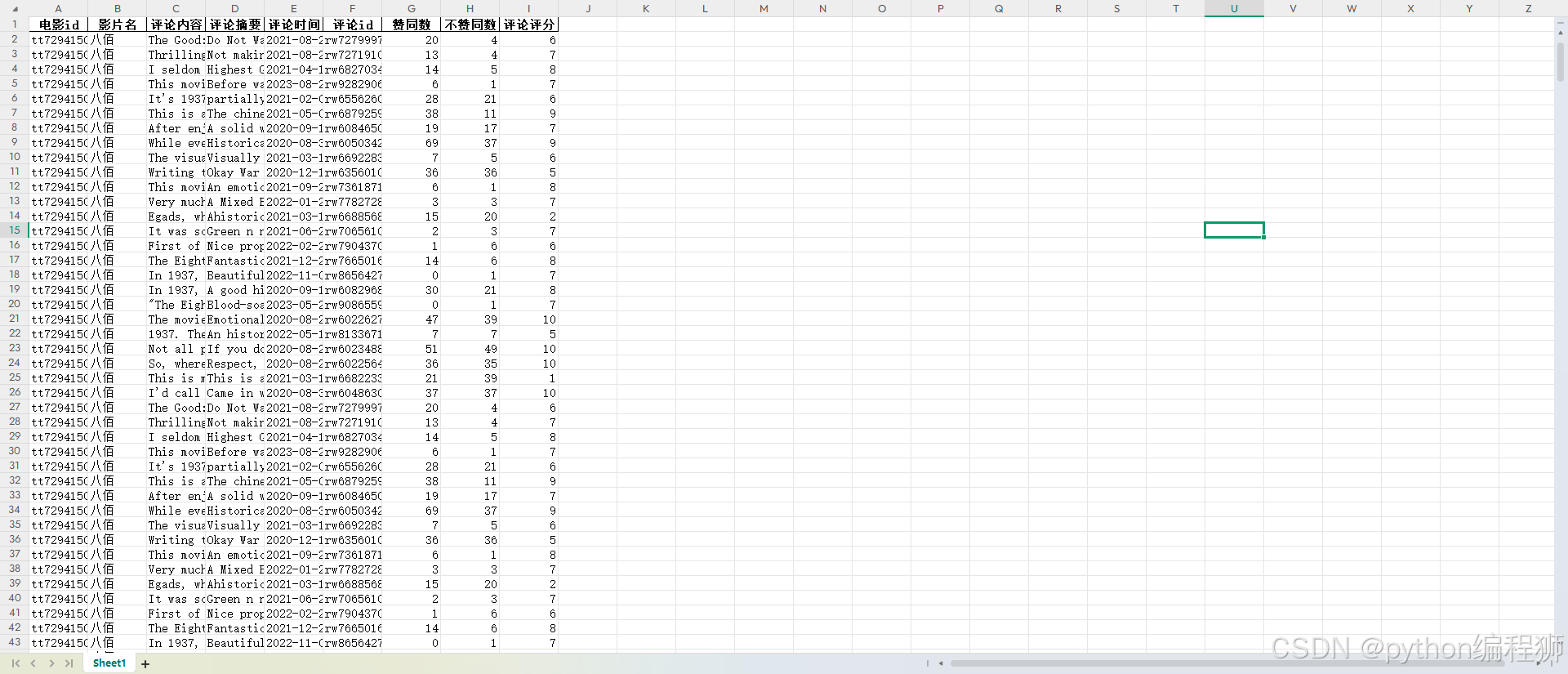
评论信息采集通过爬取IMDb的短评数据,获取电影的用户评论信息。从Excel文件中读取电影的ID和名称,然后构建GraphQL请求接口,向IMDb的缓存服务发送请求,获取评论数据。通过循环遍历多个页面,获取每页的评论内容、评论摘要、评论时间、点赞数、评分、评论者信息等。每条评论数据通过JSON格式解析后存储到字典中,并添加到结果列表中。爬取过程中使用了分页处理,直到没有更多页面为止。最终,所有评论信息被保存到Excel文件中。该过程包括错误处理和重试机制,以确保数据采集的稳定性。最终采集得11万条评论数据,如下图所示:
数据清洗和处理实现
整个过程通过多种方法对数据进行了清洗和处理,具体包括:
1、数据格式清洗:通过 str.replace() 去除特殊字符,转换数据类型。
2、数据过滤:通过条件过滤去除不需要的数据。
3、数据聚合:使用 groupby 汇总数据,按地区、年份等维度计算票房。
4、映射转换:将英文地区名称映射为中文。
5、文本清洗和处理:对评论进行清洗、分词、去除停用词并统计词频。
6、情感分析:使用 VADER 情感分析对评论进行情感分类。
1. 数据类型转换和格式清洗
票房数据清洗:
在处理票房信息时,首先通过以下方法清理和转换数据:
去除美元符号:df['总票房'] = df['总票房'].str.replace('$', '')。这行代码去除了'总票房'列中的美元符号 ($)。
去除千位分隔符:df['总票房'] = df['总票房'].str.replace(',', '')这行代码去除了票房数值中的千位分隔符(,),这样能确保票房数据可以正确转换为数字。
替换特殊字符:df['总票房'] = df['总票房'].str.replace('–', '0')将票房数据中的破折号(–)替换为 0,因为破折号通常表示票房数据缺失或不可用。
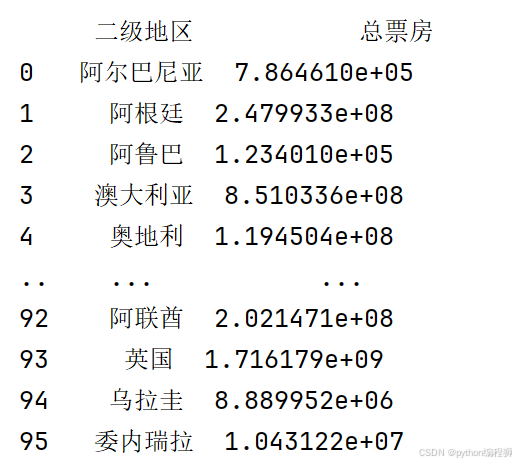
转换为整数类型:df['总票房'] = df['总票房'].astype(int)。将清洗后的票房数据转换为整数类型,以便后续的计算和分析。票房数据清洗后结果如下图:
2. 数据过滤
去除包含“Re-release”的数据:df = df[~df['二级地区'].str.contains('Re-release')]。通过 str.contains() 方法过滤掉了 二级地区 列中包含 "Re-release" 字符串的行,避免了重复计算与重新发行相关的票房数据。
3. 数据聚合
按地区汇总票房数据:df1 = df.groupby('二级地区')['总票房'].sum().reset_index():该行代码对票房数据按“二级地区”进行分组,并计算每个地区的总票房。
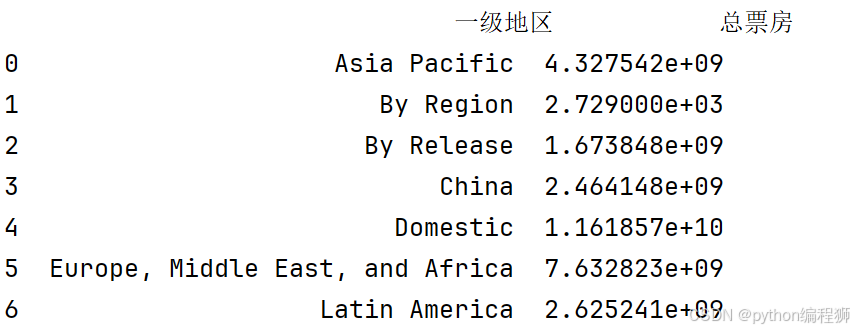
df2 = df.groupby('一级地区')['总票房'].sum().reset_index():同理,按“一级地区”对票房数据进行分组汇总。
按年份汇总票房数据:通过 data1 = data.groupby('电影发布年份')['总票房'].sum().reset_index(),按电影发布年份对票房数据进行分组并计算每年总票房。聚合效果如下图:
4. 映射转换
地区名称映射到中文:定义了一个字典 region_to_country,用于将英文的地区名称映射为中文名称。通过 df1['二级地区'] = df1['二级地区'].map(region_to_country),将汇总后的“二级地区”列中的英文地区名称转换为中文名称,便于后续分析和可视化。
5. 文本数据处理
评论数据处理的文本清洗:使用正则表达式 re.sub(r'[^a-z\s]', '', text) 清除所有非字母字符,并将文本转为小写。
分词和去除停用词:通过 nltk.tokenize.word_tokenize() 将评论内容进行分词。使用 stopwords.words('english') 获取英文停用词并过滤掉这些无意义的词。
词频统计:通过 Counter(filtered_words) 统计每个词出现的频次,生成词频统计结果。运行结果如下:

6. 情感分析
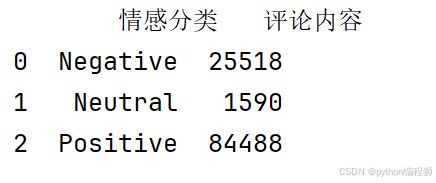
使用 VaderSentiment 库中的 SentimentIntensityAnalyzer 对评论内容进行情感分析,计算每条评论的情感分数(compound 值),该值用于表示综合情感。根据 compound 情感分数的值,将评论分类为“Positive”(正面)、“Negative”(负面)和“Neutral”(中性)。通过 df3 = dn.groupby('情感分类')['评论内容'].count().reset_index() 汇总每种情感分类的评论数量运行结果如下图:
数据可视化实现
1、各个国家地区票房可视化
在实现“各个国家地区票房可视化”时,使用 pyecharts 的 Map 图表,通过数据映射将票房数据展示在世界地图上。先对票房数据进行预处理,将非数字字符(如美元符号、逗号等)去除,并将二级地区名称映射到对应的中文国家名称。使用 Map 类将数据以国家为单位展示,使用 add() 方法将各国家地区的票房数据绑定到地图上,并通过 visualmap_opts 来设置票房数值的视觉范围。这样,用户可以直观地看到不同国家和地区的票房表现。效果如下图:
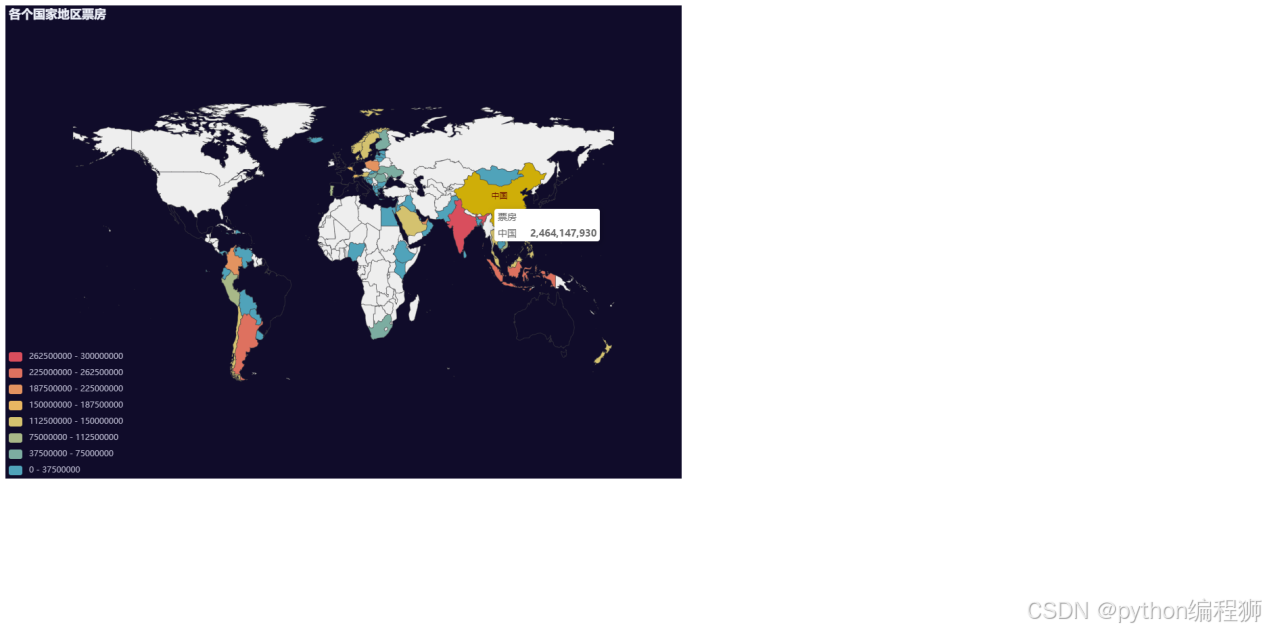
根据各个国家和地区的票房数据,可以得出:全球电影市场表现活跃,尤其是中国、美国和日本,这些国家的票房收入远超其他地区。中国的票房收入遥遥领先,总额达到约246亿人民币。美国和日本也保持强劲的市场表现,分别为约170亿和80亿人民币。欧洲地区,如法国、德国和英国的票房收入较为稳定,但与亚洲及拉美地区相比,差距较大。拉美地区(如巴西、阿根廷和墨西哥)在票房表现上也有所突出。电影行业在全球范围内蓬勃发展,尤其是亚洲和美洲市场的贡献尤为突出。
2、各地区票房占比可视化
“各地区票房占比可视化”使用了 pyecharts 的 Pie 图表。通过 groupby 操作,将票房数据按地区汇总,计算每个地区的总票房。然后,使用 Pie() 类创建饼图,将每个地区的票房占比显示出来。饼图的标签格式化选项 formatter 被用来增强展示效果,使得每个扇形区域不仅显示地区名称,还展示票房数值和百分比。此图使得用户能够一目了然地看到各地区票房的相对大小。效果如下图:
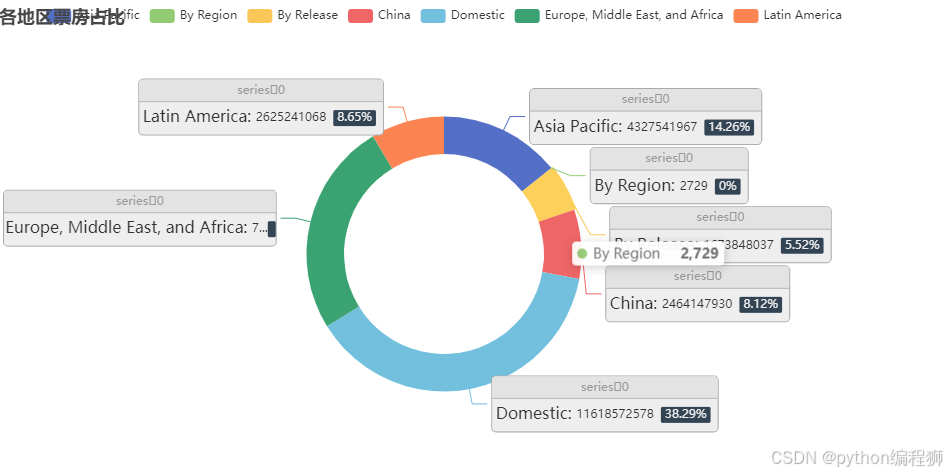
根据各地区票房数据,可以看出电影市场的主要贡献来自于“Domestic”(国内)地区,总票房达到约116亿,明显领先其他地区。其次是“Europe, Middle East, and Africa”(欧洲、中东和非洲)地区,总票房为约76亿。亚太地区(Asia Pacific)以43亿的票房紧随其后,展现出强劲的市场表现。拉丁美洲(Latin America)地区贡献约26亿票房。中国作为单一市场贡献巨大,占据全球市场的重要份额。国内市场和欧洲市场为全球票房的主要推动力。
3、电影发布年份票房可视化
在“电影发布年份票房可视化”中,我们使用 pyecharts 的 Bar 图来展示不同年份的总票房趋势。首先,按电影发布年份对数据进行汇总,计算每年总票房的总和。然后,通过 add_xaxis() 和 add_yaxis() 方法将年份和票房数据传入柱状图进行展示。为了更清晰的展示趋势,我们配置了轴的显示选项,设置了工具箱和图例,使得用户可以方便地查看每年的票房变化情况。效果如下图:
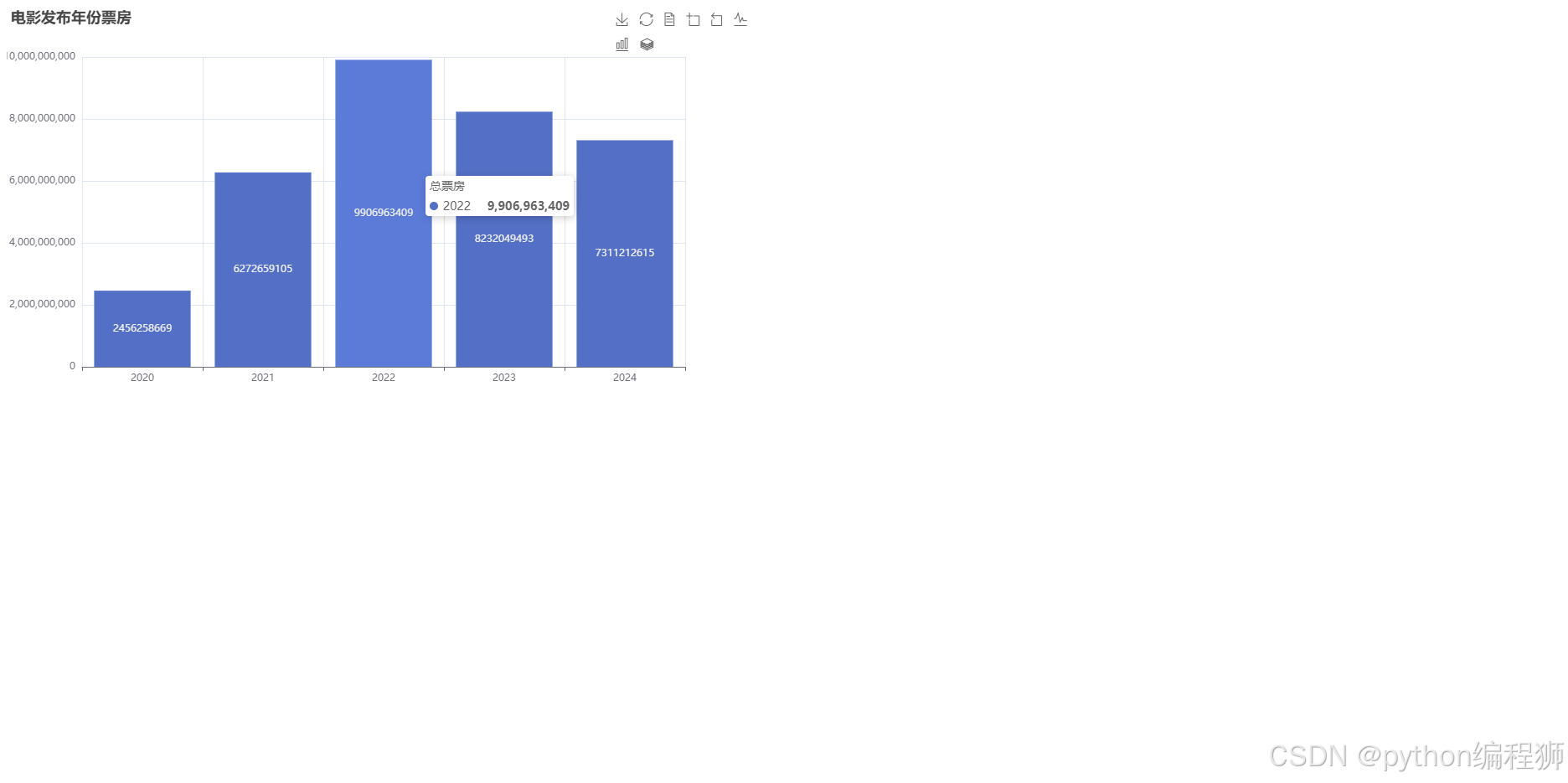
根据电影发布年份的票房数据,2022年是票房表现最强劲的一年,总票房达到约99亿。紧随其后的是2023年,总票房为约82亿,表现也相当出色。2024年票房稍微下降,约为73亿。2021年和2020年相较于2022年和2023年,票房略显逊色,分别为约63亿和25亿。这一趋势反映了疫情后的市场复苏,特别是2022年和2023年,电影行业逐步回暖,观众需求强劲。
4、评论词频分析可视化
“评论词频分析可视化”使用 pyecharts 的 WordCloud 图表展示评论数据中的关键词频率。评论文本被预处理为小写,去除特殊字符,并分词后过滤掉常见的无意义词。接着,使用 Counter 对每个单词进行计数,获取最常见的词汇。通过 WordCloud() 图表类,将词频数据展示为词云,词频高的词会以更大的字体显示,帮助用户直观了解评论中最频繁出现的关键词。效果图如下:

根据评论词频分析,可以看出“movie”和“film”是最常出现的词,表明评论内容主要集中在电影本身。常见的形容词如“good”、“great”、“really”和“amazing”反映了观众对电影的积极评价。关于情节和角色,词汇如“story”、“characters”和“plot”频繁出现,强调了电影的叙事和人物设定的重要性。许多评论还涉及到“action”和“scenes”,暗示动作和场面是观众关注的重点。此外,“marvel”和“mcu”表明漫威宇宙对影迷有着巨大影响。
5、总票房与评分关系可视化
“总票房与评分关系可视化”通过 pyecharts 的 Scatter 散点图实现,展示电影的评分与票房之间的关系。从数据中提取出电影的评分和总票房数据,并按评分进行排序。使用 add_xaxis() 和 add_yaxis() 方法将评分和票房数据展示在散点图中,每个点代表一部电影,通过坐标位置反映其评分和票房情况。散点图帮助用户理解评分是否与票房之间存在一定的相关性。效果图如下:
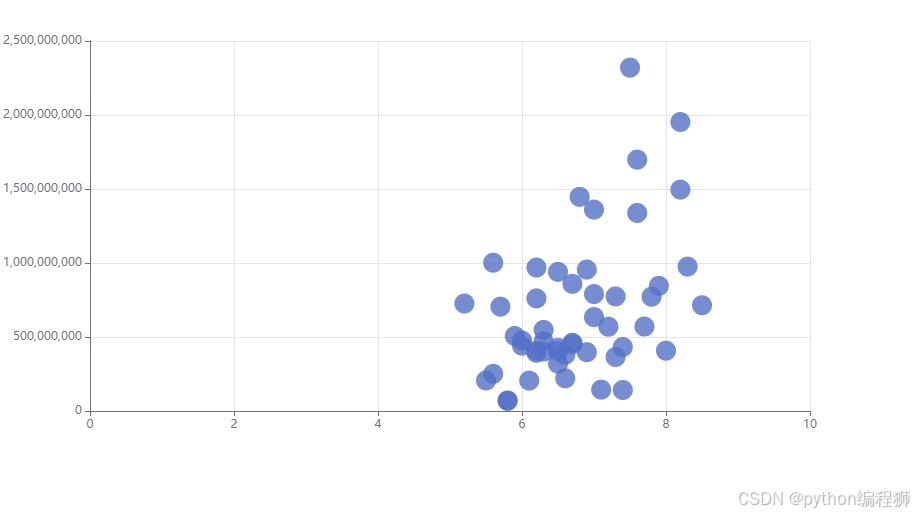
根据评分与总票房的关系散点图分析,可以看出较高评分的电影通常表现出较高的票房。例如,评分在7.5以上的电影(如评分为8.2和8.3的电影)获得了显著的票房收入,分别达到了近20亿和15亿美金。整体来看,评分在6.5到7.5之间的电影普遍票房较为稳定,处于较高的收入区间。低评分(如评分在5.5以下)则通常伴随着较低的票房表现,显示出观众对电影质量与票房的强烈关联。
6、情感分析饼图可视化
在“情感分析饼图可视化”中,我们利用 VADER Sentiment Analysis 对评论进行情感分析。情感分析后的结果被分类为正面、负面和中性。通过 pyecharts 的 Pie 图展示情感分类的分布情况。每个类别的大小代表了对应情感类型的评论数量,帮助用户了解评论的总体情感倾向。通过设置 label_opts,展示每个情感类别的数量,使得图表更加直观。效果图如下:
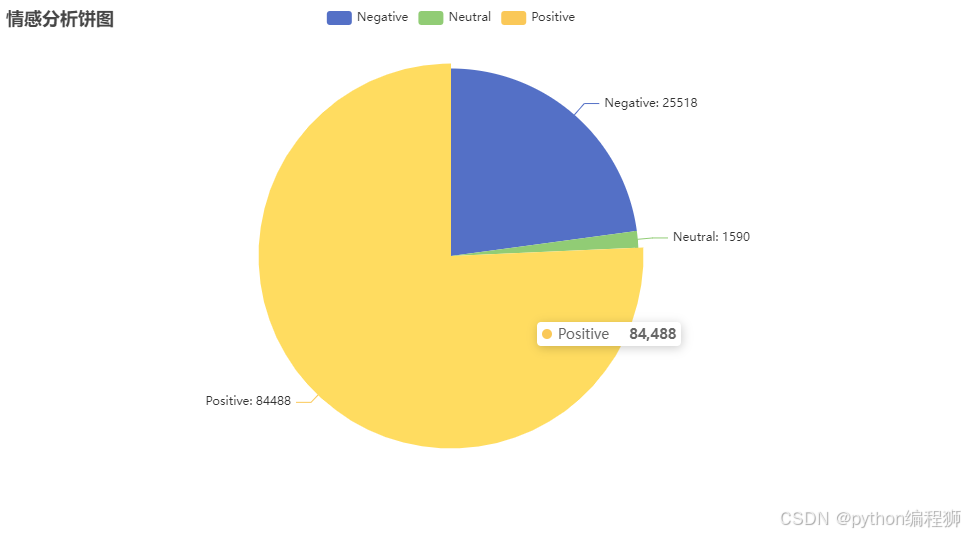
根据情感分类分析结果,评论内容主要集中在积极情感上,其中“Positive”情感评论占据绝大多数,达到84,488条,占比显著。其次是“Negative”情感评论,数量为25,518条,表明虽然有一部分负面反馈,但整体情感偏向正面。“Neutral”中立评论相对较少,仅为1,590条。这一数据表明,大部分观众对电影或作品持积极态度,显示出影片在观众群体中的受欢迎程度。然而,仍有一定比例的观众提出负面意见,提示电影可能在某些方面存在改进空间。总体来说,正面评价占据主导地位,表明影片或作品在市场上获得了较高的认可度。
7、各地区电影评分分析可视化
在“各地区电影评分分析可视化”中,我们使用 pyecharts 的 Bar 图来展示不同地区的平均电影评分趋势。首先,按不同地区对数据进行汇总,计算每个地区的电影平均评分。然后,通过 add_xaxis() 和 add_yaxis() 方法将地区和平均评分数据传入柱状图进行展示。为了更清晰的展示趋势,我们配置了轴的显示选项,设置了工具箱和图例,使得用户可以方便地查看每个地区评分变化情况。效果图如下:
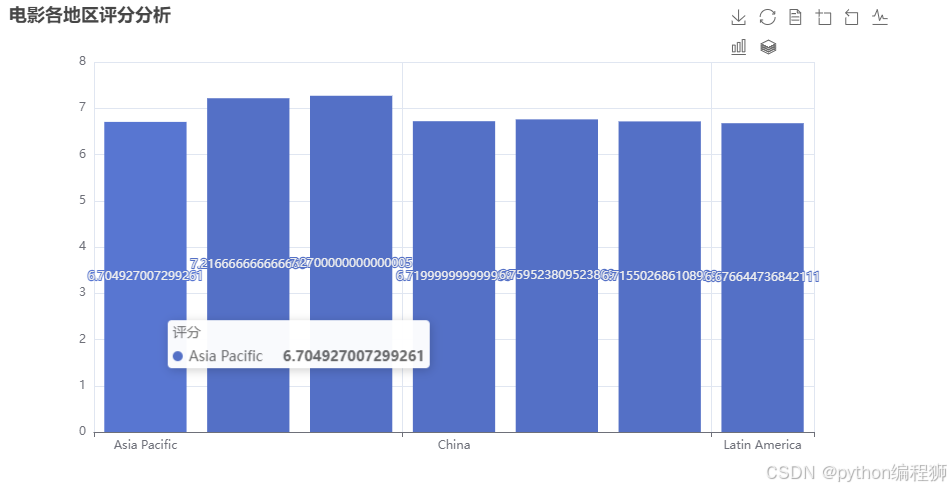
根据各地区电影的平均评分数据,可以看出,不同地区的电影评分差异较小,但也有一些微妙的区别。总体而言,“By Release”地区的评分最高,为7.27,可能代表的是按上映时间划分的全球评分,体现了更为广泛的观众基础和评价。然而,亚洲太平洋地区(6.70)和中国地区(6.72)的评分相对较低,可能受到文化背景和观众偏好的影响。欧洲、中东和非洲(6.72)以及拉丁美洲(6.68)的评分与亚洲地区相近,显示出全球观众在评价电影时的趋同性。总体来看,评分差异并不显著,但不同地区的文化差异可能会在电影评价中有所体现。

















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









